Rainbond通过插件整合ELK/EFK,实现日志收集
前言
ELK 是三个开源项目的首字母缩写:Elasticsearch、Logstash 和 Kibana。但后来出现的 FileBeat 可以完全替代 Logstash的数据收集功能,也比较轻量级。本文将介绍 EFK: Elasticsearch、Filebeat 和 Kibana
Elasticsearch:分布式搜索和分析引擎,具有高可伸缩、高可靠和易管理等特点。基于 Apache Lucene 构建,能对大容量的数据进行接近实时的存储、搜索和分析操作。通常被用作某些应用的基础搜索引擎,使其具有复杂的搜索功能;
Kibana:数据分析和可视化平台。与 Elasticsearch 配合使用,对其中数据进行搜索、分析和以统计图表的方式展示;
Filebeat:Filebeat 是一个轻量级的传送器,用于转发和集中日志数据。Filebeat 作为代理安装在您的服务器上,监控您指定的日志文件或位置,收集日志事件,并将它们转发到 Elasticsearch 或 Logstash 以进行索引。
通过本文了解如何将运行在 Rainbond 上的应用,通过开启 FileBeat 插件的方式收集应用日志并发送到 Elasticsearch 中。
整合架构
在收集日志时,需要在应用中启用 FileBeat 插件进行收集,FileBeat收集日志有三种方式:
- 指定日志路径
- 收集所有容器日志
- 指定 Label 自动发现
本文使用 指定日志路径进行收集,这种方式我们可以自定义收集日志的规则等。
我们将 FileBeat 制作成 Rainbond 的 一般类型插件 ,在应用启动之后,插件也随之启动并自动收集日志发送至 Elasticsearch,整个过程对应用容器无侵入,且拓展性强。对接其他日志收集也可以用类似方式,用户通过替换插件实现对接不同的日志收集工具。
下图展示了在Rainbond使用FileBeat插件收集应用日志并发送到 Elasticsearch 的结构。
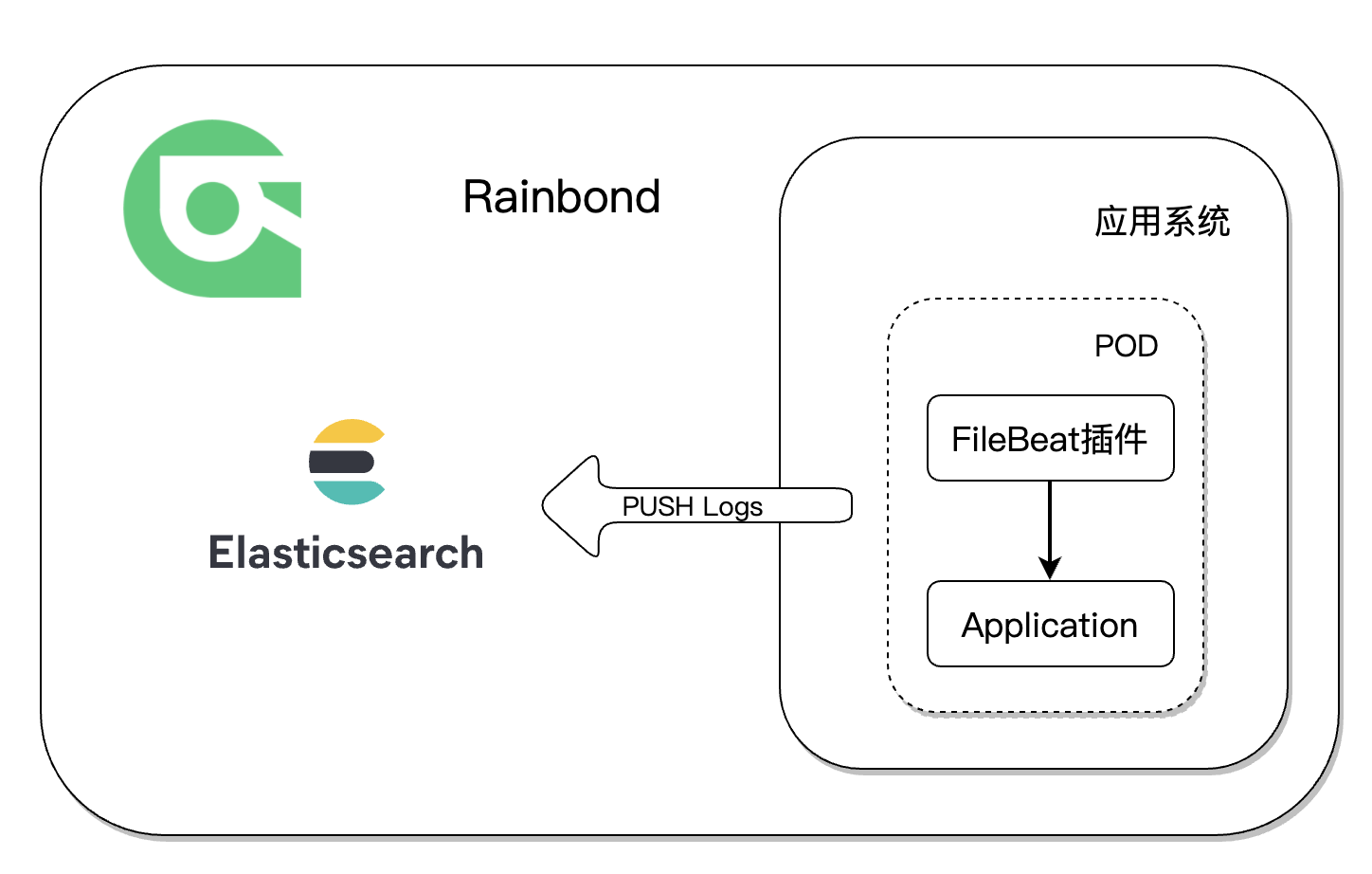
插件实现原理解析
Rainbond插件体系是相对于Rainbond应用模型的一部分,插件主要用来实现应用容器扩展运维能力。由于运维工具的实现有较大的共性,因此插件本身可以被复用。插件必须绑定到应用容器时才具有运行时状态,用以实现一种运维能力,比如性能分析插件、网络治理插件、初始化类型插件。
具有运行时的插件的运行环境与所绑定的组件从以下几个方面保持一致:
- 网络空间 这个一个至关重要的特性,网络空间一致使插件可以对组件网络流量进行旁路监听和拦截,设置组件本地域名解析等。
- 存储持久化空间 这个特性使得插件与组件之间可以通过持久化目录进行文件交换。
- 环境变量 这个特性使得插件可以读取组件的环境变量。
在制作 FileBeat 插件的过程中,使用到了 一般类型插件,可以理解为一个POD启动两个 Container,Kubernetes原生支持一个POD中启动多个 Container,但配置起来相对复杂,在Rainbond中通过插件实现使用户操作简单。
通过Rainbond 应用商店一键安装 EK
我们已将 elasticsearch + Kibana 制作为应用并发布至应用市场,用户可基于开源应用商店一键安装。
- 安装 Rainbond
- 在开源应用商店搜索 elasticsearch,点击安装即可一键安装;

elasticsearch默认启用了 xpack 安全模块来保护我们的集群,所以我们需要一个初始化的密码。我们进入elasticsearchWeb终端执行如下所示的命令,Web终端内运行bin/elasticsearch-setup-passwords命令来生成默认的用户名和密码:
bin/elasticsearch-setup-passwords 参数
auto 自动生成
interactive 手动填写
- 进入
Kibana组件的环境变量中,修改默认连接elasticsearch的环境变量ELASTICSEARCH_PASSWORD。
收集应用日志
使用 Nginx 作为本文的演示应用,在Rainbond上使用镜像创建组件,
- 镜像地址:
nginx:latest - 挂载存储:
/var/log/nginx,将Nginx日志持久化,Filebeat插件可读取到该日志文件。
制作 FileBeat 插件
在Rainbond团队界面点击插件后进入插件界面,点击新建插件,创建一般类型插件。
- 镜像地址:docker.elastic.co/beats/filebeat:7.15.2
- 其他自定义即可。
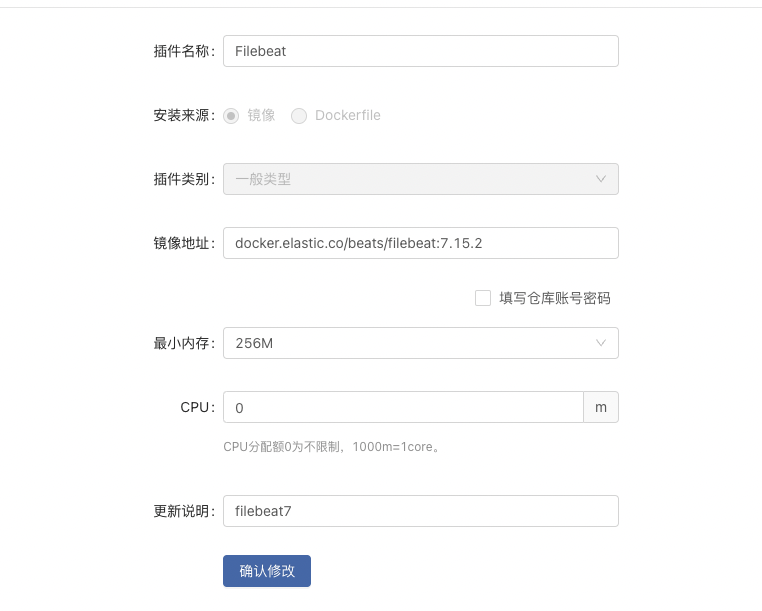
创建插件并构建,构建成功后我们在 Nginx组件的插件中开通 FileBeat 插件。
在Nginx组件的环境配置中,添加 FileBeat 配置文件 如下,更多配置可参考 官方文档
- 配置文件挂载路径:/usr/share/filebeat/filebeat.yml
- 配置文件权限:644
filebeat.inputs:
- type: log
paths:
- /var/log/nginx/*.log
output.elasticsearch:
hosts: '127.0.0.1:9200'
username: "elastic"
password: "elastic"
建立依赖关系
将 Nginx 与 elasticsearch 建立依赖关系,使其能通过 127.0.0.1地址与 elasticsearch 通信,更新Nginx组件使依赖生效。
访问Kibana
Kibana默认已汉化
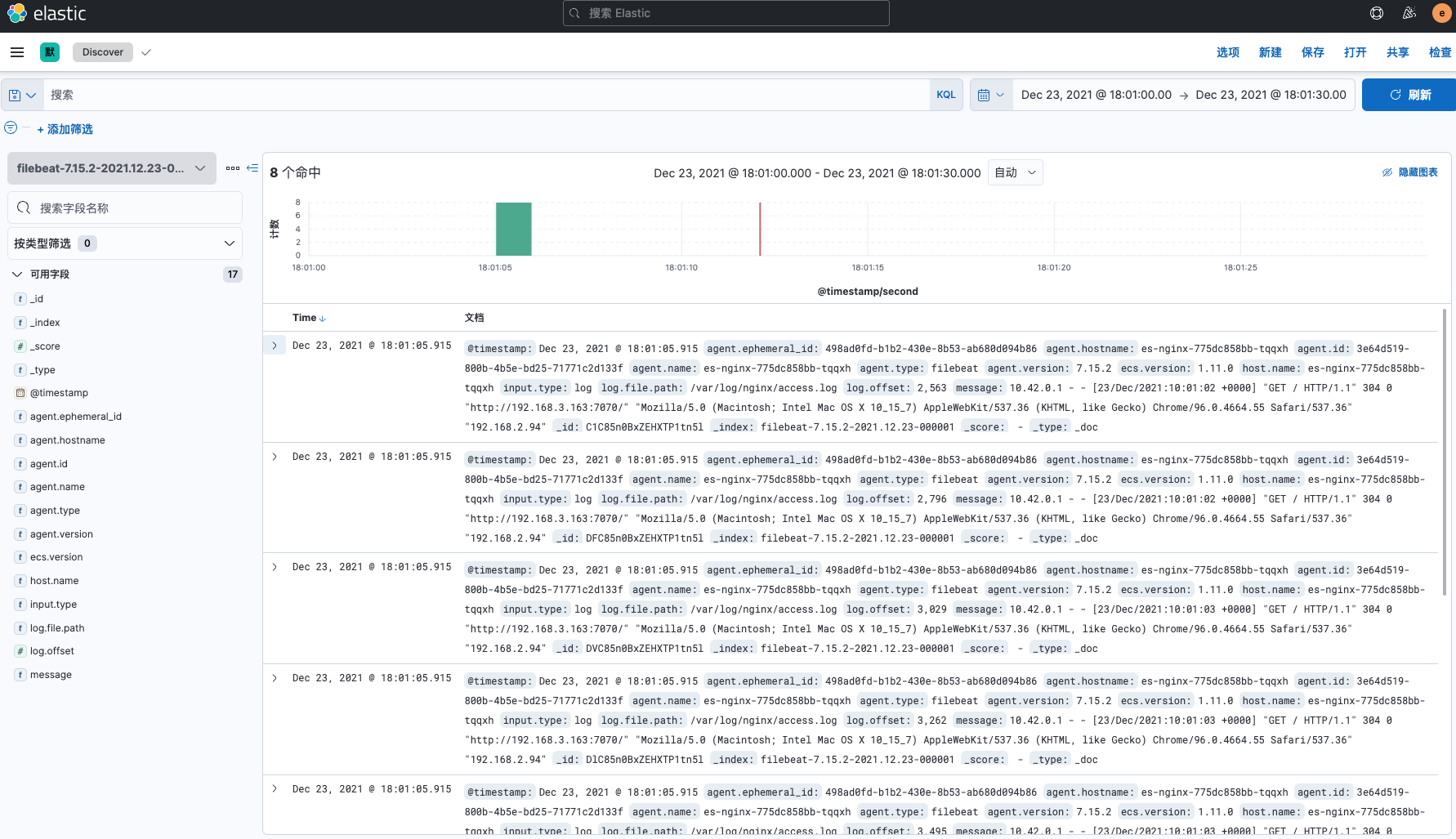
点击
Stack Management> 索引管理,可看到我们的filebeat索引已存在。Stack Management> 索引模式,创建filebeat索引模式。Discover页面即可看到日志信息。
总结
基于Rainbond的插件机制与 EFK 结合,使用户可以快速的通过EFK收集应用日志进行分析,并且可灵活的将插件 FileBeat 替换为 Logstash。
除此之外,Rainbond的插件机制具有开放性,通过插件机制对应用治理功能进行扩展,例如网络治理类、数据备份类插件,在对原应用逻辑无侵入的情况下,能够通过网络治理类插件对服务的性能进行分析,对接ELK等日志收集系统;对于数据库等组件而言,使用备份插件对数据进行备份。
关于Rainbond
Rainbond 是一个开源的云原生应用管理平台,使用简单,不需要懂容器和Kubernetes,支持管理多个Kubernetes集群,提供企业级应用的全生命周期管理,功能包括应用开发环境、应用市场、微服务架构、应用持续交付、应用运维、应用级多云管理等。
Github:https://github.com/goodrain/rainbond
Rainbond通过插件整合ELK/EFK,实现日志收集的更多相关文章
- ELK+kafka构建日志收集系统
ELK+kafka构建日志收集系统 原文 http://lx.wxqrcode.com/index.php/post/101.html 背景: 最近线上上了ELK,但是只用了一台Redis在 ...
- ELK+Kafka 企业日志收集平台(一)
背景: 最近线上上了ELK,但是只用了一台Redis在中间作为消息队列,以减轻前端es集群的压力,Redis的集群解决方案暂时没有接触过,并且Redis作为消息队列并不是它的强项:所以最近将Redis ...
- Rainbond通过插件整合SkyWalking,实现APM即插即用
作者:张震 一. 简介 SkyWalking 是一个开源可观察性平台,用于收集.分析.聚合和可视化来自服务和云原生基础设施的数据.支持分布式追踪.性能指标分析.应用和服务依赖分析等:它是一种现代 AP ...
- ELK系列~Nxlog日志收集加转发(解决log4日志换行导致json转换失败问题)
本文章将会继承上一篇文章,主要讲通过工具来进行日志的收集与发送,<ELK系列~NLog.Targets.Fluentd到达如何通过tcp发到fluentd> Nxlog是一个日志收集工具, ...
- 转: 基于elk 实现nginx日志收集与数据分析
原文链接:https://www.cnblogs.com/wenchengxiaopenyou/p/9034213.html 一.背景 前端web服务器为nginx,采用filebeat + logs ...
- ELK Stack 企业级日志收集平台
ELK Stack介绍 大型项目,多产品线的日志收集 ,分析平台 为什么用ELK? 1.开发人员排查问题,服务器上查看权限 2.项目多,服务器多,日志类型多 ELK 架构介绍 数据源--->lo ...
- 05 . ELK Stack+Redis日志收集平台
环境清单 IP hostname 软件 配置要求 网络 备注 192.168.43.176 ES/数据存储 elasticsearch-7.2 内存2GB/硬盘40GB Nat,内网 192.168. ...
- ELK之生产日志收集构架(filebeat-logstash-redis-logstash-elasticsearch-kibana)
本次构架图如下 说明: 1,前端服务器只启动轻量级日志收集工具filebeat(不需要JDK环境) 2,收集的日志不进过处理直接发送到redis消息队列 3,redis消息队列只是暂时存储日志数据,不 ...
- Logback+ELK+SpringMVC搭建日志收集服务器
(转) 1.ELK是什么? ELK是由Elasticsearch.Logstash.Kibana这3个软件的缩写. Elasticsearch是一个分布式搜索分析引擎,稳定.可水平扩展.易于管理是它的 ...
随机推荐
- JAVA中复制数组的方法
在JAVA里面,可以用复制语句"A=B"给基本类型的数据传递值,但是如果A,B是两个同类型的数组,复制就相当于将一个数组变量的引用传递给另一个数组;如果一个数组发生改变,那么 引用 ...
- HDC2021技术分论坛:异构组网如何解决共享资源冲突?
作者:lijie,HarmonyOS软总线领域专家 相信大家对HarmonyOS的"超级终端"比较熟悉了.那么,您知道超级终端场景下的多种设备在不同环境下是如何组成一个网络的吗?这 ...
- 日常Java 2021/11/15
Applet类 每一个Applet都是java.applet Applet类的子类,基础的Applet类提供了供衍生类调用的方法,以此来得到浏览器上下文的信息和服务.这些方法做了如下事情: 得到App ...
- 日常Java 2021/10/19
Java集合框架 Java 集合框架主要包括两种类型的容器,一种是集合(Collection),存储一个元素集合,另一种是图(Map),存储键/值对映射. Collection接口又有3种子类型,Li ...
- 日常Java 2021/10/6
声明自定义异常 class zidingyiException extends Exception{}//定义自己的异常类 单继承 public class A {} public class B ...
- Vue2全家桶+Element搭建的PC端在线音乐网站
目录 1,前言 2,已有功能 3,使用 4,目录结构 5,页面效果 登录页 首页 排行榜 歌单列表 歌单详情 歌手列表 歌手详情 MV列表 MV详情 搜索页 播放器 1,前言 项目基于Vue2全家桶及 ...
- Spark产生数据倾斜的原因以及解决办法
Spark数据倾斜 产生原因 首先RDD的逻辑其实时表示一个对象集合.在物理执行期间,RDD会被分为一系列的分区,每个分区都是整个数据集的子集.当spark调度并运行任务的时候,Spark会为每一个分 ...
- 字节面试问我如何高效设计一个LRU,当场懵
首发公众号:bigsai 转载请放置作者和原文(本文)链接 前言 大家好,我是bigsai,好久不见,甚是想念! 最近有个小伙伴跟我诉苦,说他没面到LRU,他说他很久前知道有被问过LRU的但是心想自己 ...
- [PE]结构分析与代码实现
PE结构浅析 知识导向: 程序最开始是存放在磁盘上的,运行程序首先需要申请4GB的内存,将程序从磁盘copy到内存,但不是直接复制,而是进行拉伸处理. 这也就是为什么会有一个文件中地址和一个Virtu ...
- HelloWorldDynamic
package mbeanTest; import java.lang.reflect.Method; import javax.management.Attribute; import javax. ...