Theoretically Principled Trade-off between Robustness and Accuracy
@article{zhang2019theoretically,
title={Theoretically Principled Trade-off between Robustness and Accuracy},
author={Zhang, Hongyang and Yu, Yaodong and Jiao, Jiantao and Xing, Eric P and Ghaoui, Laurent El and Jordan, Michael I},
journal={arXiv: Learning},
year={2019}}
概
从二分类问题入手, 拆分\(\mathcal{R}_{rob}\)为\(\mathcal{R}_{nat},\mathcal{R}_{bdy}\), 通过\(\mathcal{R}_{rob}-\mathcal{R}_{nat}^*\)的上界建立损失函数,并将这种思想推广到一般的多分类问题.
主要内容
符号说明
\(X, Y\): 随机变量;
\(x\in \mathcal{X}, y\): 样本, 对应的标签(\(1, -1\));
\(f\): 分类器(如神经网络);
\(\mathbb{B}(x, \epsilon)\): \(\{x'\in \mathcal{X}:\|x'-x\| \le \epsilon\}\);
\(\mathbb{B}(DB(f),\epsilon)\): \(\{x \in \mathcal{X}: \exist x'\in \mathbb{B}(x,\epsilon), \mathrm{s.t.} \: f(x)f(x')\le0\}\) ;
\(\psi^*(u)\): \(\sup_u\{u^Tv-\psi(u)\}\), 共轭函数;
\(\phi\): surrogate loss.
Error
\mathcal{R}_{rob}(f):= \mathbb{E}_{(X,Y)\sim \mathcal{D}}\mathbf{1}\{\exist X' \in \mathbb{B}(X, \epsilon), \mathrm{s.t.} \: f(X')Y \le 0\},
\]
其中\(\mathbf{1}(\cdot)\)表示指示函数, 显然\(\mathcal{R}_{rob}(f)\)是关于分类器\(f\)存在adversarial samples 的样本的点的测度.
\mathcal{R}_{nat}(f) :=\mathbb{E}_{(X,Y)\sim \mathcal{D}}\mathbf{1}\{f(X)Y \le 0\},
\]
显然\(\mathcal{R}_{nat}(f)\)是\(f\)正确分类真实样本的概率, 并且\(\mathcal{R}_{rob} \ge \mathcal{R}_{nat}\).
\mathcal{R}_{bdy}(f) :=\mathbb{E}_{(X,Y)\sim \mathcal{D}}\mathbf{1}\{X \in \mathbb{B}(DB(f), \epsilon), \:f(X)Y > 0\},
\]
显然
\mathcal{R}_{rob}-\mathcal{R}_{nat}=\mathcal{R}_{bdy}.
\]
因为想要最优化\(0-1\)loss是很困难的, 我们往往用替代的loss \(\phi\), 定义:
\mathcal{R}^*_{\phi}(f):= \min_f \mathcal{R}_{\phi}(f).
\]
Classification-calibrated surrogate loss
这部分很重要, 但是篇幅很少, 我看懂, 等回看了引用的论文再讨论.


引理2.1

定理3.1
在假设1的条件下\(\phi(0)\ge1\), 任意的可测函数\(f:\mathcal{X} \rightarrow \mathbb{R}\), 任意的于\(\mathcal{X}\times \{\pm 1\}\)上的概率分布, 任意的\(\lambda > 0\), 有
& \mathcal{R}_{rob}(f) - \mathcal{R}_{nat}^* \\
\le & \psi^{-1}(\mathcal{R}_{\phi}(f)-\mathcal{R}_{\phi}^*) + \mathbf{Pr}[X \in \mathbb{B}(DB(f), \epsilon), f(X)Y >0] \\
\le & \psi^{-1}(\mathcal{R}_{\phi}(f)-\mathcal{R}_{\phi}^*) + \mathbb{E} \quad \max _{X' \in \mathbb{B}(X, \epsilon)} \phi(f(X')f(X)/\lambda). \\
\end{array}
\]
最后一个不等式, 我知道是因为\(\phi(f(X')f(X)/\lambda) \ge1.\)
定理3.2

结合定理\(3.1, 3.2\)可知, 这个界是紧的.
由此导出的TRADES算法
二分类问题, 最优化上界, 即:
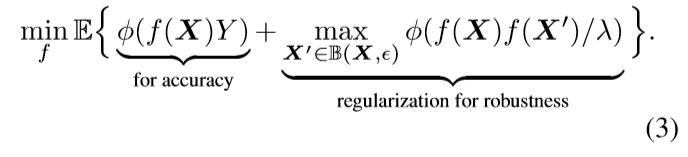
扩展到多分类问题, 只需:
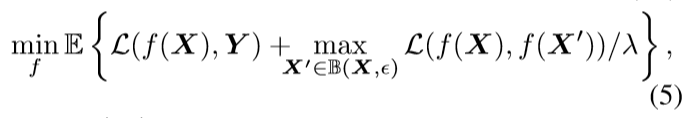
算法如下:

实验概述
5.1: 衡量该算法下, 理论上界的大小差距;
5.2: MNIST, CIFAR10 上衡量\(\lambda\)的作用, \(\lambda\)越大\(\mathcal{R}_{nat}\)越小, \(\mathcal{R}_{rob}\)越大, CIFAR10上反映比较明显;
5.3: 在不同adversarial attacks 下不同算法的比较;
5.4: NIPS 2018 Adversarial Vision Challenge.
代码
import torch
import torch.nn as nn
def quireone(func): #a decorator, for easy to define optimizer
def wrapper1(*args, **kwargs):
def wrapper2(arg):
result = func(arg, *args, **kwargs)
return result
wrapper2.__doc__ = func.__doc__
wrapper2.__name__ = func.__name__
return wrapper2
return wrapper1
class AdvTrain:
def __init__(self, eta, k, lam,
net, lr = 0.01, **kwargs):
"""
:param eta: step size for adversarial attacks
:param lr: learning rate
:param k: number of iterations K in inner optimization
:param lam: lambda
:param net: network
:param kwargs: other configs for optim
"""
kwargs.update({'lr':lr})
self.net = net
self.criterion = nn.CrossEntropyLoss()
self.opti = self.optim(self.net.parameters(), **kwargs)
self.eta = eta
self.k = k
self.lam = lam
@quireone
def optim(self, parameters, **kwargs):
"""
quireone is decorator defined below
:param parameters: net.parameteres()
:param kwargs: other configs
:return:
"""
return torch.optim.SGD(parameters, **kwargs)
def normal_perturb(self, x, sigma=1.):
return x + sigma * torch.randn_like(x)
@staticmethod
def calc_jacobian(loss, inp):
jacobian = torch.autograd.grad(loss, inp, retain_graph=True)[0]
return jacobian
@staticmethod
def sgn(matrix):
return torch.sign(matrix)
def pgd(self, inp, y, perturb):
boundary_low = inp - perturb
boundary_up = inp + perturb
inp.requires_grad_(True)
out = self.net(inp)
loss = self.criterion(out, y)
delta = self.sgn(self.calc_jacobian(loss, inp)) * self.eta
inp_new = inp.data
for i in range(self.k):
inp_new = torch.clamp(
inp_new + delta,
boundary_low,
boundary_up
)
return inp_new
def ipgd(self, inps, ys, perturb):
N = len(inps)
adversarial_samples = []
for i in range(N):
inp_new = self.pgd(
inps[[i]], ys[[i]],
perturb
)
adversarial_samples.append(inp_new)
return torch.cat(adversarial_samples)
def train(self, trainloader, epoches=50, perturb=1, normal=1):
for epoch in range(epoches):
running_loss = 0.
for i, data in enumerate(trainloader, 1):
inps, labels = data
adv_inps = self.ipgd(self.normal_perturb(inps, normal),
labels, perturb)
out1 = self.net(inps)
out2 = self.net(adv_inps)
loss1 = self.criterion(out1, labels)
loss2 = self.criterion(out2, labels)
loss = loss1 + loss2
self.opti.zero_grad()
loss.backward()
self.opti.step()
running_loss += loss.item()
if i % 10 is 0:
strings = "epoch {0:<3} part {1:<5} loss: {2:<.7f}\n".format(
epoch, i, running_loss
)
print(strings)
running_loss = 0.
Theoretically Principled Trade-off between Robustness and Accuracy的更多相关文章
- 近年Recsys论文
2015年~2017年SIGIR,SIGKDD,ICML三大会议的Recsys论文: [转载请注明出处:https://www.cnblogs.com/shenxiaolin/p/8321722.ht ...
- real-Time Correlative Scan Matching
启发式算法(heuristic algorithm)是相对于最优化算法提出的.一个问题的最优算法求得该问题每个实例的最优解.启发式算法可以这样定义:一个基于直观或经验构造的算法,在可接受的花费(指计算 ...
- [Tensorflow] Object Detection API - retrain mobileNet
前言 一.专注话题 重点话题 Retrain mobileNet (transfer learning). Train your own Object Detector. 这部分讲理论,下一篇讲实践. ...
- [转]Introduction to Learning to Trade with Reinforcement Learning
Introduction to Learning to Trade with Reinforcement Learning http://www.wildml.com/2018/02/introduc ...
- Introduction to Learning to Trade with Reinforcement Learning
http://www.wildml.com/2015/12/implementing-a-cnn-for-text-classification-in-tensorflow/ The academic ...
- Accuracy, Precision, Resolution & Sensitivity
Instrument manufacturers usually supply specifications for their equipment that define its accuracy, ...
- Certified Adversarial Robustness via Randomized Smoothing
目录 概 主要内容 定理1 代码 Cohen J., Rosenfeld E., Kolter J. Certified Adversarial Robustness via Randomized S ...
- caffe的python接口学习(7):绘制loss和accuracy曲线
使用python接口来运行caffe程序,主要的原因是python非常容易可视化.所以不推荐大家在命令行下面运行python程序.如果非要在命令行下面运行,还不如直接用 c++算了. 推荐使用jupy ...
- HDOJ 1009. Fat Mouse' Trade 贪心 结构体排序
FatMouse' Trade Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
随机推荐
- 日常Java 2021/10/25
ArrayList存储数字 import java.util.ArrayList; public class Arr_test { public static void main(String[] a ...
- A Child's History of England.18
But, although she was a gentle lady, in all things worthy to be beloved - good, beautiful, sensible, ...
- CRLF漏洞浅析
部分情况下,由于与客户端存在交互,会形成下面的情况 也就是重定向且Location字段可控 如果这个时候,可以向Location字段传点qqgg的东西 形成固定会话 但服务端应该不会存储,因为后端貌似 ...
- Linux学习 - 系统定时任务
1 crond服务管理与访问控制 只有打开crond服务打开才能进行系统定时任务 service crond restart chkconfig crond on 2 定时任务编辑 crontab [ ...
- HongYun-ui搭建记录
vue项目windows环境初始化 Element-ui使用 vue2 页面路由 vue SCSS 在VUE项目中使用SCSS ,对SCSS的理解和使用(简单明了) vue axios vue coo ...
- BigDecimal 计算注意事项
BigDecimal 在进行除法运算(divide)时一定要注意:如果被除数为变量,一定要指定精度 和 舍入模式,否则会报:Non-terminating decimal expansion; no ...
- vue 中使用import导入 script 在线链接
一般我们在vue中导入另外一个文件或者文件中的方法,我们都是使用import来实现他的,那么问题来了,现在我们要导入的不是另外的一个文件,而是在线链接,这该怎么办?我们也使用了 import * as ...
- 如何利用EL表达式获取list,map,对象等值
<%@ page import="com.hopetesting.domain.User" %><%@ page import="java.util.* ...
- Spring中Bean的装配方式
一.基于xml的装配 Student.java package com.yh; public class Student implements People { public void breath( ...
- 如何完成符合ISO 26262要求的基于模型设计(MBD)的测试
背景介绍 随着汽车行业的迅速发展,汽车的复杂程度不断增加,越来越多的汽车电子控制系统具有与安全相关的功能,因此对ECU的安全要求也越来越高.复杂的软件功能,将会带来大量的软件风险问题,如何保证软件的安 ...