Pytorch_Part5_迭代训练
VisualPytorch beta发布了!
功能概述:通过可视化拖拽网络层方式搭建模型,可选择不同数据集、损失函数、优化器生成可运行pytorch代码
扩展功能:1. 模型搭建支持模块的嵌套;2. 模型市场中能共享及克隆模型;3. 模型推理助你直观的感受神经网络在语义分割、目标探测上的威力;4.添加图像增强、快速入门、参数弹窗等辅助性功能
修复缺陷:1.大幅改进UI界面,提升用户体验;2.修改注销不跳转、图片丢失等已知缺陷;3.实现双服务器访问,缓解访问压力
访问地址:http://sunie.top:9000
发布声明详见:https://www.cnblogs.com/NAG2020/p/13030602.html
一、学习率调整策略
梯度下降: \(w_{i+1} = w_i-LR *g(w_i)\),学习率(learning rate)控制更新的步伐
pytorch中所有学习率控制都继承与class _LRScheduler
主要属性及函数:
- optimizer:关联的优化器
- last_epoch:记录epoch数
- base_lrs:记录初始学习率
- step():更新下一个epoch的学习率
- get_lr():虚函数,计算下一个epoch的学习率
scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size=10, gamma=0.1) # 设置学习率下降策略
for epoch in range(MAX_EPOCH):
...
for i, data in enumerate(train_loader):
...
scheduler.step() # 更新学习率,注意在每个epoch调用,而不是每个iteration
1. 有序调整——Step, MultiStep, Exponential & CosineAnnealing
StepLR
功能:等间隔调整学习率
主要参数:
• step_size:调整间隔数
• gamma:调整系数
\(lr = lr_0 * gamma**(epoch//step\_size)\)

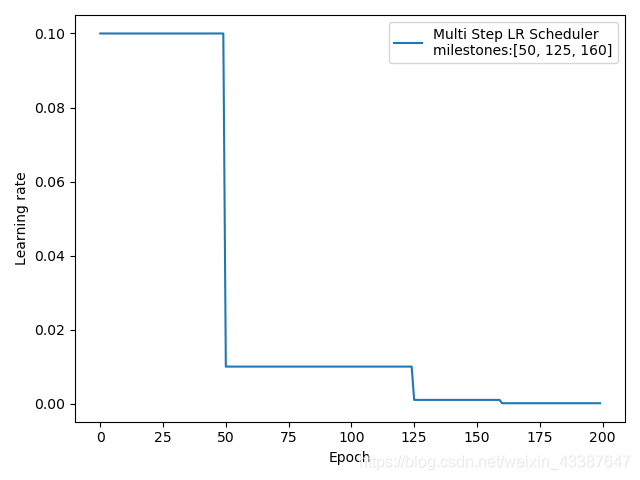
MultiStepLR
功能:按给定间隔调整学习率
主要参数:
• milestones:设定调整时刻数
• gamma:调整系数
\(lr = lr * gamma\)
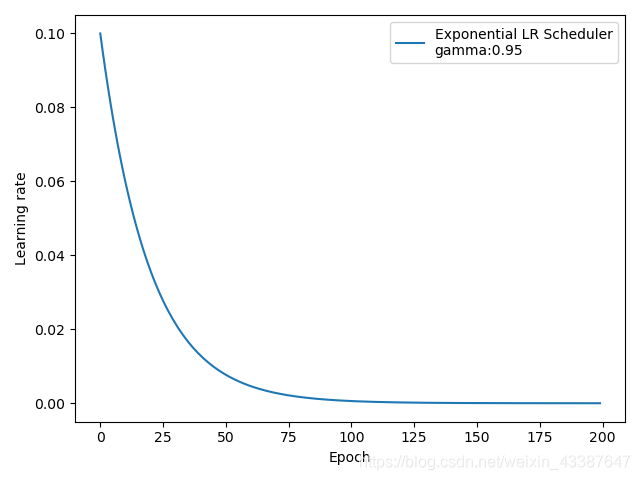
ExponentialLR
功能:按指数衰减调整学习率
主要参数:
• gamma:指数的底
\(lr = lr_0 * gamma**epoch\)
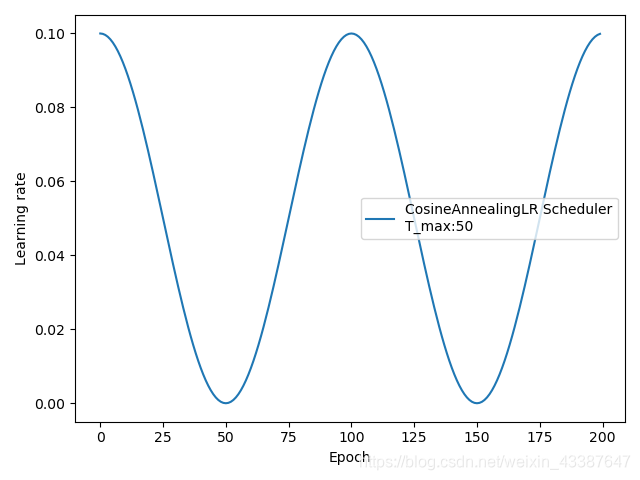
CosineAnnealingLR
功能:余弦周期调整学习率
主要参数:
• T_max:下降周期,如图所示下降周期为50epoch
• eta_min:学习率下限
\(\eta_t=\eta_{min}+\frac{1}{2}(\eta_{max}-\eta_{min})(1+cos(\frac{T_{cur}}{T_{max}}\pi))\)
2. 自适应调整——ReduceLROnPleateau
ReduceLRonPlateau
功能:监控指标,当指标不再变化则调整
主要参数:
• mode:min/max 两种模式,min表示监控指标不再减小则调整
• factor:调整系数
• patience:“耐心 ”,接受几次不变化
• cooldown:“冷却时间”,停止监控一段时间
• verbose:是否打印日志
• min_lr:学习率下限
• eps:学习率衰减最小值
scheduler_lr = optim.lr_scheduler.ReduceLROnPlateau(optimizer, factor=0.1, mode="min", patience=10,cooldown=10, min_lr=1e-4, verbose=True)
for epoch in range(max_epoch):
for i in range(iteration):
# train(...)
optimizer.step()
optimizer.zero_grad()
if epoch == 5:
loss_value = 0.4
scheduler_lr.step(loss_value)
'''
Epoch 16: reducing learning rate of group 0 to 1.0000e-02.
Epoch 37: reducing learning rate of group 0 to 1.0000e-03.
Epoch 58: reducing learning rate of group 0 to 1.0000e-04.
'''
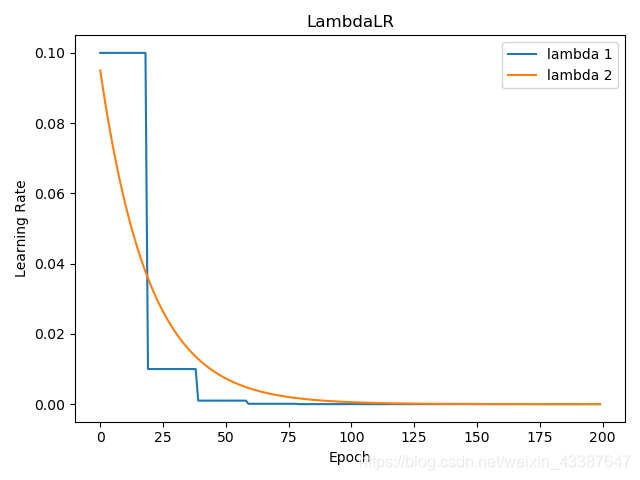
3. 自定义调整——Lambda
LambdaLR
功能:自定义调整策略,对多组参数采用不同的学习率调整方式
主要参数:
• lr_lambda:function or list
optimizer = optim.SGD([
{'params': [weights_1]},
{'params': [weights_2]}], lr=lr_init)
lambda1 = lambda epoch: 0.1 ** (epoch // 20)
lambda2 = lambda epoch: 0.95 ** epoch
scheduler = torch.optim.lr_scheduler.LambdaLR(optimizer, lr_lambda=[lambda1, lambda2])
二、TensorBoard可视化
0. Tensorboard的安装
pip install tensorbord
pip install future


在含有runs的文件夹下命令行输入 tensorboard --logdir=./,即可打开,如下图所示。
1. 标量&直方图
- add_scalar()
功能:记录标量
• tag:图像的标签名,图的唯一标识
• scalar_value:要记录的标量
• global_step:x轴 - add_scalars()
• main_tag:该图的标签
• tag_scalar_dict:key是变量的tag,value是变量的值 - add_histogram()
功能:统计直方图与多分位数折线图
• tag:图像的标签名,图的唯一标识
• values:要统计的参数
• global_step:y轴 • bins:取直方图的bins
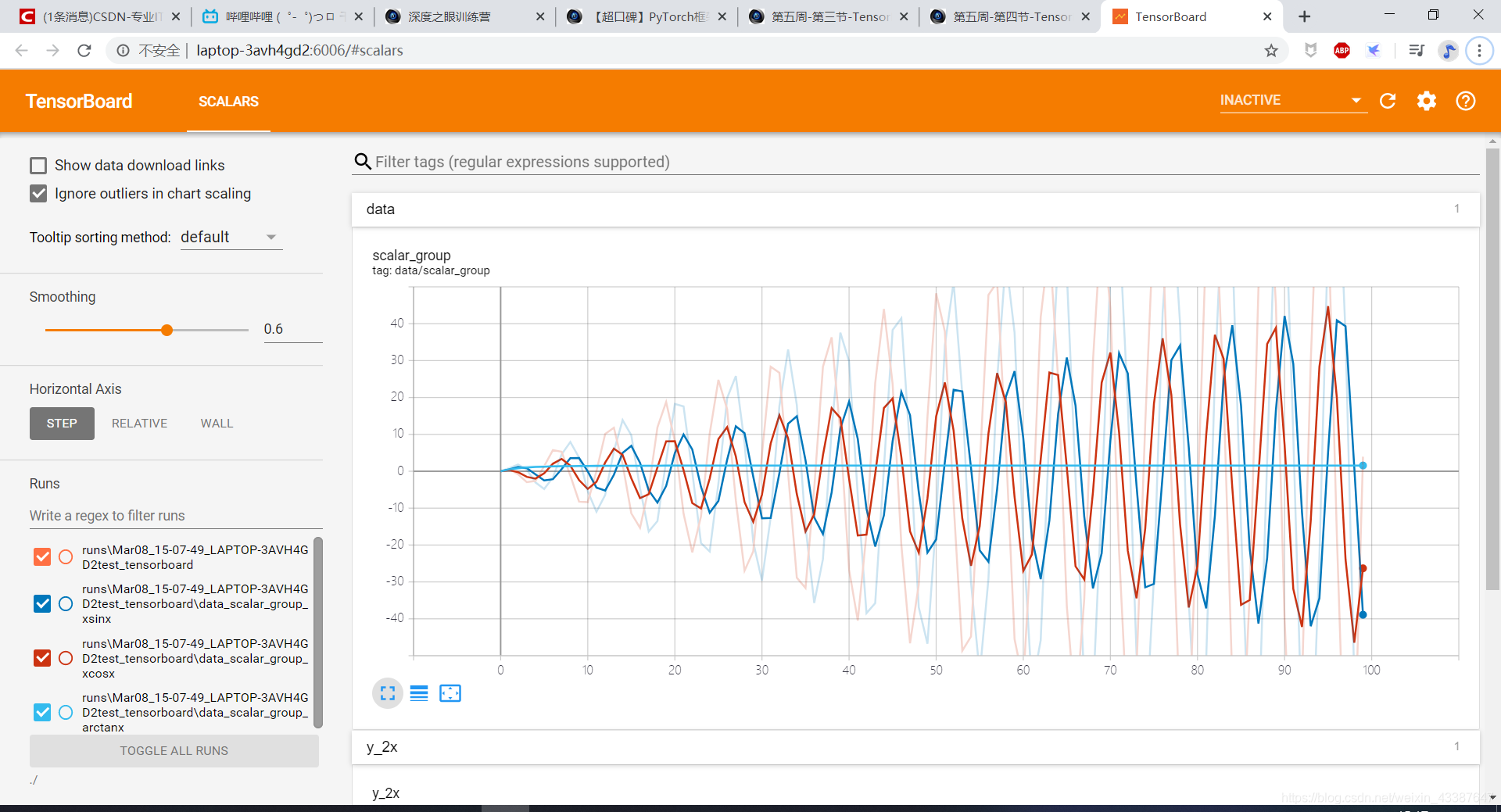
可视化任意网络模型训练的Loss,及Accuracy曲线图,Train与Valid必须在同一个图中(节选人民币分类训练部分):
# 构建 SummaryWriter
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
for epoch in range(MAX_EPOCH):
loss_mean = 0.
correct = 0.
total = 0.
net.train()
for i, data in enumerate(train_loader):
...
# 记录数据,保存于event file
writer.add_scalars("Loss", {"Train": loss.item()}, iter_count)
writer.add_scalars("Accuracy", {"Train": correct / total}, iter_count)
# 每个epoch,记录梯度,权值
for name, param in net.named_parameters():
writer.add_histogram(name + '_grad', param.grad, epoch)
writer.add_histogram(name + '_data', param, epoch)
scheduler.step() # 更新学习率
通过matplotlib直接绘制的曲线(训练集和验证集,iteration为单位),第二张是tensorbord。可以发现,如果没有排除离群点和平滑,两个图是一致的。
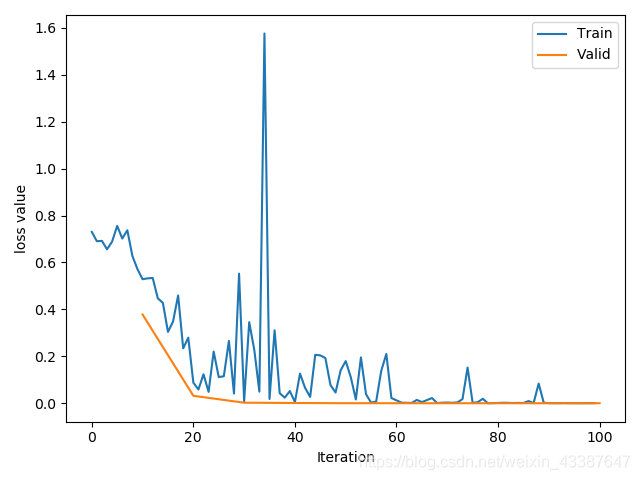
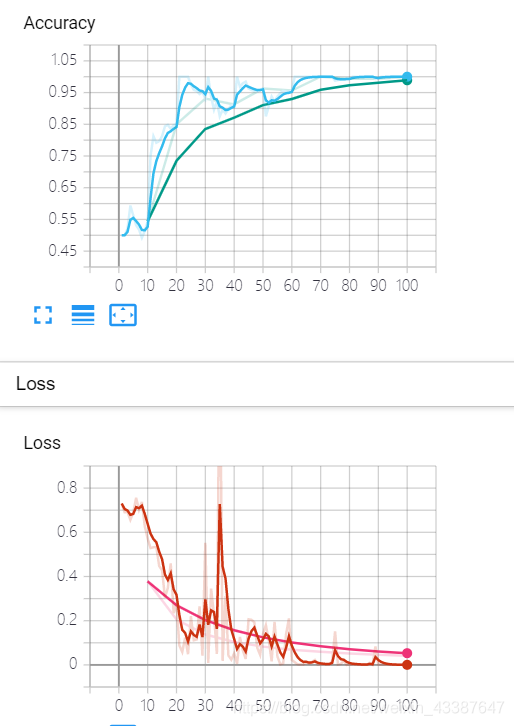
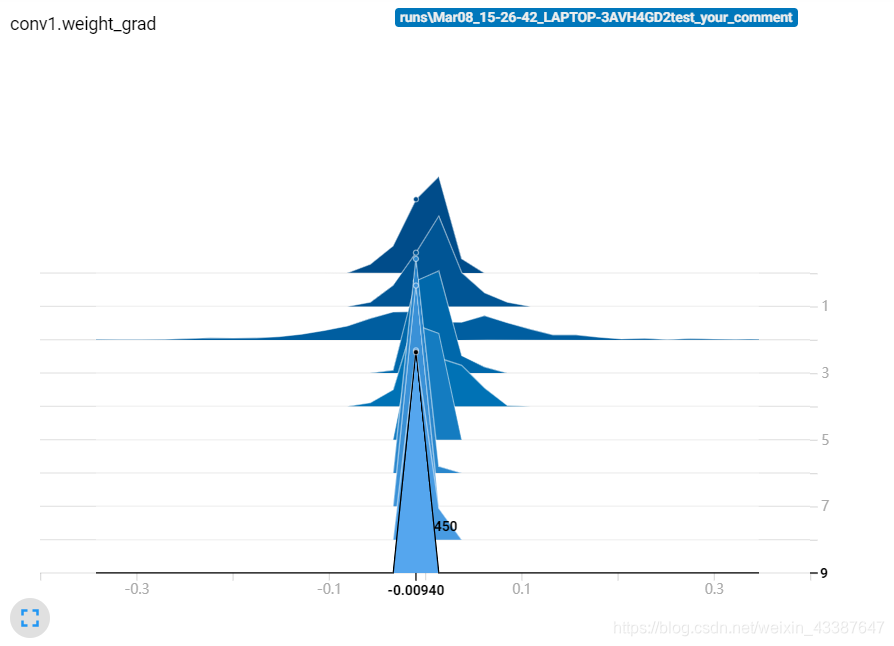
可以看到,随着迭代次数的增加梯度越来越小,并不是梯度消失,而是本身Loss已经达到1e-4.
2. 卷积核&特征图
add_image()
功能:记录图像
• tag:图像的标签名,图的唯一标识
• img_tensor:图像数据,注意尺度。只要该图像有>1的像素点,不再对该图像*255标准化
• global_step:x轴 • dataformats:数据形式,CHW,HWC,HW
torchvision.utils.make_grid()
功能:制作网格图像
• tensor:图像数据, B*C*H*W形式
• nrow:行数(列数自动计算)
• padding:图像间距(像素单位)
• normalize:是否将像素值标准化
• range:标准化范围
• scale_each:是否单张图维度标准化
• pad_value:padding的像素值
writer = SummaryWriter(comment='test_your_comment', filename_suffix="_test_your_filename_suffix")
alexnet = models.alexnet(pretrained=True)
kernel_num = -1
for sub_module in alexnet.modules():
if isinstance(sub_module, nn.Conv2d):
kernel_num += 1
kernels = sub_module.weight
c_out, c_int, k_w, k_h = tuple(kernels.shape)
# 每一个卷积核单独绘制三个通道
for o_idx in range(c_out):
kernel_idx = kernels[o_idx, :, :, :].unsqueeze(1) # make_grid需要 BCHW,这里拓展C维度
kernel_grid = vutils.make_grid(kernel_idx, normalize=True, scale_each=True, nrow=c_int)
writer.add_image('{}_Convlayer_split_in_channel'.format(kernel_num), kernel_grid, global_step=o_idx)
# 所有卷积核一起绘制
kernel_all = kernels.view(-1, 3, k_h, k_w) # 3, h, w
kernel_grid = vutils.make_grid(kernel_all, normalize=True, scale_each=True, nrow=8) # c, h, w
writer.add_image('{}_all'.format(kernel_num), kernel_grid, global_step=322)
print("{}_convlayer shape:{}".format(kernel_num, tuple(kernels.shape)))
# 模型, 特征图的可视化
alexnet = models.alexnet(pretrained=True)
# forward
convlayer1 = alexnet.features[0]
fmap_1 = convlayer1(img_tensor)
# 预处理
fmap_1.transpose_(0, 1) # bchw=(1, 64, 55, 55) --> (64, 1, 55, 55)
fmap_1_grid = vutils.make_grid(fmap_1, normalize=True, scale_each=True, nrow=8)
writer.add_image('feature map in conv1', fmap_1_grid, global_step=322)
writer.close()

3. 模型可视化
add_graph()
功能:可视化模型计算图
• model:模型,必须是 nn.Module
• input_to_model:输出给模型的数据
• verbose:是否打印计算图结构信息
注意使用该方法对环境有所限制,torch版本必须>=1.3,在该版本下运行生成runs文件夹后,可更换为原环境运行tensorboard.
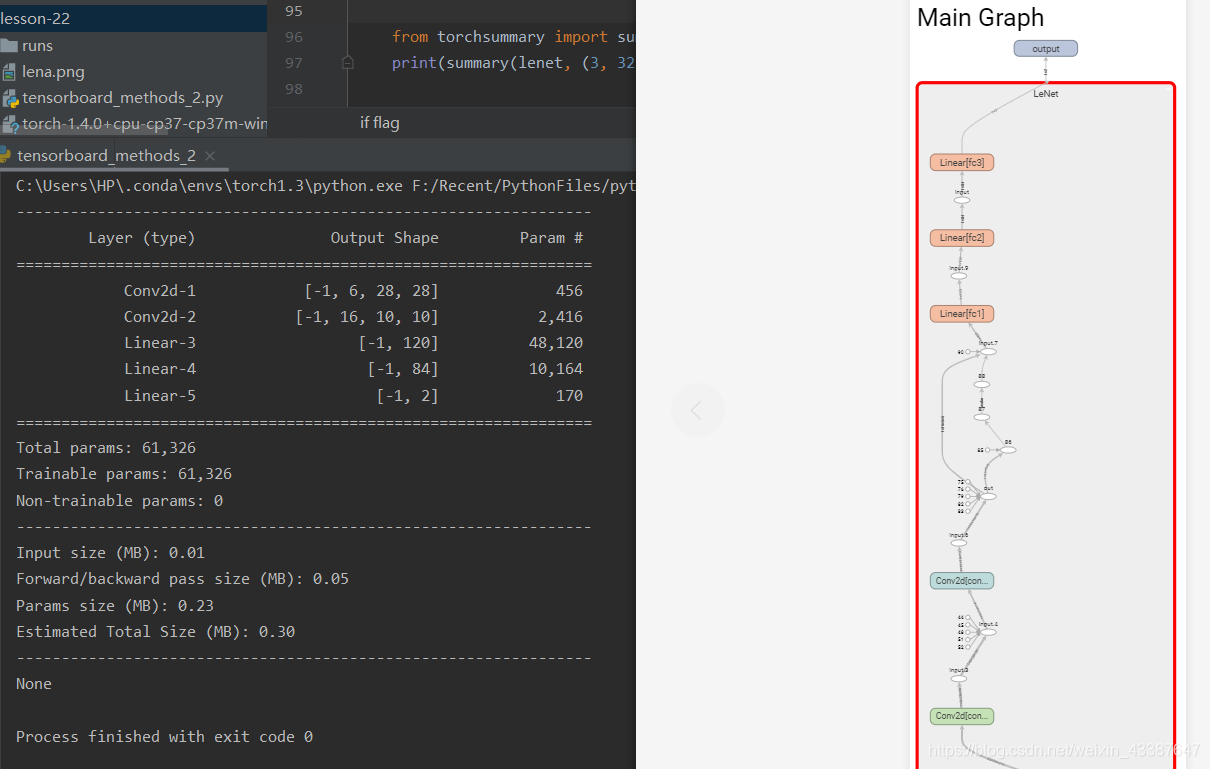
torchsummary
功能:查看模型信息,便于调试
• model:pytorch模型
• input_size:模型输入size
• batch_size:batch size
• device:“cuda” or “cpu”
三、Hook函数及CAM可视化
1. 张量Hook
Tensor.register_hook
功能:注册一个反向传播hook函数,为了不修改主体而实现特定的功能
Hook函数仅一个输入参数,为张量的梯度
w = torch.tensor([1.], requires_grad=True)
x = torch.tensor([2.], requires_grad=True)
a = torch.add(w, x)
b = torch.add(w, 1)
y = torch.mul(a, b)
a_grad = list()
def grad_hook(grad):
a_grad.append(grad)
def grad_hook(grad):
grad *= 2
return grad*3 # 返回值会覆盖掉原来的grad,故最后w.grad = 6*5 = 30
handle = w.register_hook(grad_hook)
handle = a.register_hook(grad_hook)
y.backward()
# 查看梯度
print("gradient:", w.grad, x.grad, a.grad, b.grad, y.grad) # 30 2 None None None
print("a_grad[0]: ", a_grad[0]) # 2
handle.remove()
2. Module Hook
| Function | Parameter | Usage |
|---|---|---|
| Module.register_forward_hook | module, input, output | 注册module的前向传播hook函数 |
| register_forward_pre_hook | module, input | 注册module前向传播前的hook函数 |
| register_backward_hook | module, input, output | 注册module反向传播的hook函数 |
参数:
• module: 当前网络层
• input:当前网络层输入数据
• output:当前网络层输出数据
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 2, 3)
self.pool1 = nn.MaxPool2d(2, 2)
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
def forward_hook(module, data_input, data_output):
fmap_block.append(data_output)
input_block.append(data_input)
def forward_pre_hook(module, data_input):
print("forward_pre_hook input:{}".format(data_input))
def backward_hook(module, grad_input, grad_output):
print("backward hook input:{}".format(grad_input))
print("backward hook output:{}".format(grad_output))
# 初始化网络
net = Net()
net.conv1.weight[0].detach().fill_(1)
net.conv1.weight[1].detach().fill_(2)
net.conv1.bias.data.detach().zero_()
# 注册hook
fmap_block = list()
input_block = list()
net.conv1.register_forward_hook(forward_hook)
net.conv1.register_forward_pre_hook(forward_pre_hook)
net.conv1.register_backward_hook(backward_hook)
# inference
fake_img = torch.ones((1, 1, 4, 4)) # batch size * channel * H * W
output = net(fake_img)
loss_fnc = nn.L1Loss()
target = torch.randn_like(output)
loss = loss_fnc(target, output)
loss.backward()
3. Hook实现机制
以register_forward_hook为例,在output = net(fake_img) 时调用过程如下:
在net.conv1.register_forward_hook(forward_hook)注册以后,net中_modules参数已经有了对应的_forword_hooks
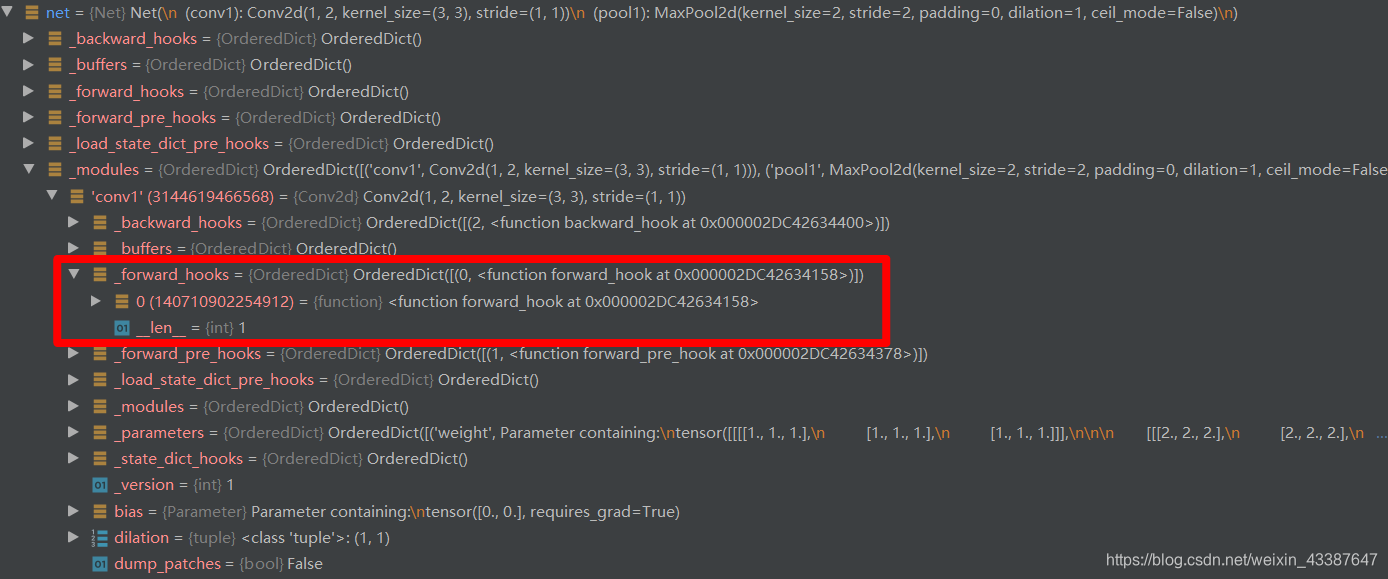
- 进入net对应
Modules.__call__(),此函数分为4个步骤,net中不含hooks,进入forward
def __call__(self, *input, **kwargs):
# 1. _forward_pre_hooks
for hook in self._forward_pre_hooks.values():
result = hook(self, input)
if result is not None:
if not isinstance(result, tuple):
result = (result,)
input = result
# 2. forward
if torch._C._get_tracing_state():
result = self._slow_forward(*input, **kwargs)
else:
result = self.forward(*input, **kwargs)
# 3. _forward_hooks
for hook in self._forward_hooks.values():
hook_result = hook(self, input, result)
if hook_result is not None:
result = hook_result
# 4. _backward_hooks
if len(self._backward_hooks) > 0:
var = result
while not isinstance(var, torch.Tensor):
if isinstance(var, dict):
var = next((v for v in var.values() if isinstance(v, torch.Tensor)))
else:
var = var[0]
grad_fn = var.grad_fn
if grad_fn is not None:
for hook in self._backward_hooks.values():
wrapper = functools.partial(hook, self)
functools.update_wrapper(wrapper, hook)
grad_fn.register_hook(wrapper)
return result
Net.forward调用第一个卷积层
def forward(self, x):
x = self.conv1(x)
x = self.pool1(x)
return x
- 得到对应的模块之后,再一次调用
Modules.__call__(),此时在forward后会调用相应的hook函数,即我们在主程序中定义的
4. CAM可视化
CAM:类激活图,class activation map: 在普通的网络层最后改成了GAP得到最后的权重层,再由全连接层进行softmax。最后直接对特征图进行加权平均。

Grad-CAM:CAM改进版,利用梯度作为特征图权重:不用再修改网络结构
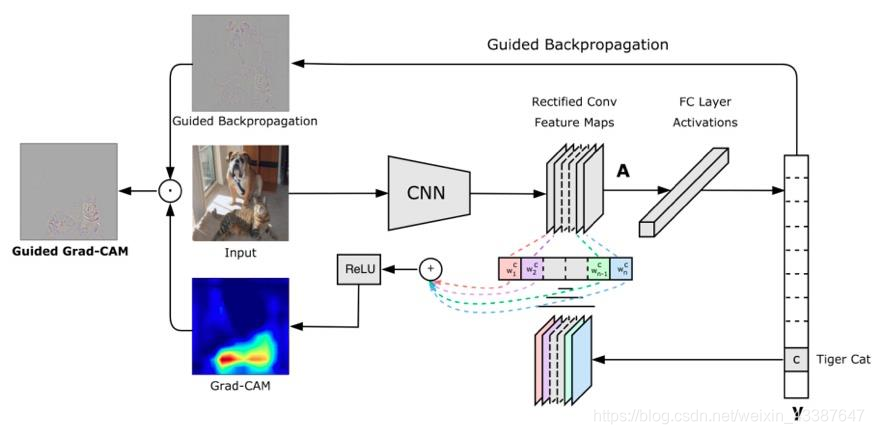

我们得到以上有趣的分析,发现模型预测飞机的存在不是飞机本身,而是蓝色的天空,代码实现详见PyTorch的hook及其在Grad-CAM中的应用
Pytorch_Part5_迭代训练的更多相关文章
- Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练
Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练 目录 Alink漫谈(十七) :Word2Vec源码分析 之 迭代训练 0x00 摘要 0x01 前文回顾 1.1 上文总体流程图 1 ...
- 【OpenCV】opencv3.0中的SVM训练 mnist 手写字体识别
前言: SVM(支持向量机)一种训练分类器的学习方法 mnist 是一个手写字体图像数据库,训练样本有60000个,测试样本有10000个 LibSVM 一个常用的SVM框架 OpenCV3.0 中的 ...
- Tesseract训练笔记
[参考] http://www.cnblogs.com/samlin/p/Tesseract-OCR.html https://code.google.com/p/tesseract-ocr/wiki ...
- TensorFlow从1到2(七)线性回归模型预测汽车油耗以及训练过程优化
线性回归模型 "回归"这个词,既是Regression算法的名称,也代表了不同的计算结果.当然结果也是由算法决定的. 不同于前面讲过的多个分类算法或者逻辑回归,线性回归模型的结果是 ...
- 【算法】Bert预训练源码阅读
Bert预训练源码 主要代码 地址:https://github.com/google-research/bert create_pretraning_data.py:原始文件转换为训练数据格式 to ...
- AI佳作解读系列(一)——深度学习模型训练痛点及解决方法
1 模型训练基本步骤 进入了AI领域,学习了手写字识别等几个demo后,就会发现深度学习模型训练是十分关键和有挑战性的.选定了网络结构后,深度学习训练过程基本大同小异,一般分为如下几个步骤 定义算法公 ...
- py-faster-rcnn 训练参数修改(转)
faster rcnn默认有三种网络模型 ZF(小).VGG_CNN_M_1024(中).VGG16 (大) 训练图片大小为500*500,类别数1. 一. 修改VGG_CNN_M_1024模型配置文 ...
- 基于word2vec训练词向量(二)
转自:http://www.tensorflownews.com/2018/04/19/word2vec2/ 一.基于Hierarchical Softmax的word2vec模型的缺点 上篇说了Hi ...
- 梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python)
梯度迭代树(GBDT)算法原理及Spark MLlib调用实例(Scala/Java/python) http://blog.csdn.net/liulingyuan6/article/details ...
随机推荐
- Ubuntu20.04linux内核(5.4.0版本)编译准备与实现过程-编译过程(2)
前面因为博客园维修,所以内核编译过程一直没有发出来,现在把整个内核过程分享出来.本随笔给出内核的编译实现过程,在编译前需要参照我前面一篇随笔: Ubuntu20.04linux内核(5.4.0版本)编 ...
- C# yield return 原理探究
天需要些一个小工具,需要使用到多线程读写程序集,接口方法返回值类型需要为"IEnumerable<string>"这里用到了"yield return&quo ...
- 真会C#微信小程序的习题数据JSON文件下载链接
完全没有精力去维护了,所以小程序停掉,集中精力做一件事. 链接: https://pan.baidu.com/s/1xL45KxDzR5oEQM6nwBA5rw 提取码: qv6n
- Kubernetes 实战 —— 04. 副本机制和其他控制器:部署托管的 pod
保持 pod 健康 P84 只要 pod 调度到某个节点,该节点上的 Kubelet 就会运行 pod 的容器,从此只要该 pod 存在,就会保持运行.如果容器的主进程奔溃, Kubelet 就会自动 ...
- 在 .NET Core 中使用 ViewConfig 调试配置
介绍 .NET Core 中的配置包含了多个配置提供程序,包括了 appsettings.json,环境变量,命令行参数等,还有一些扩展的自定义提供程序,比如说 ApolloConfig,AgileC ...
- 极简实用的Asp.NetCore模块化框架新增CMS模块
简介 关于这个框架的背景,在前面我已经交代过了.不清楚的可以查看这个链接 极简实用的Asp.NetCore模块化框架决定免费开源了 在最近一段时间内,对这个框架新增了以下功能: 1.新增了CMS模块, ...
- 围绕 Kubernetes 的 8 大 DevOps 生产关键实践
本文主要介绍 DevOps 的 8 大关键实践在 Kubernetes 平台下如何落地,结合我们目前基于 Kubernetes 平台的 DevOps 实践谈谈是如何贯彻相关理念的,这里不会对其具体实现 ...
- 敏捷史话(十三):我被 Facebook 解雇了——Kent Beck
2011年,Kent Beck 加入了 Facebook .那时候的他已年过半百,几十年的经验让他自认为非常了解软件行业.在 Facebook 的新手训练营期间,Kent 开始意识到,Facebook ...
- [SIGIR2020] Sequential Recommendation with Self-Attentive Multi-Adversarial Network
这篇论文主要提出了一个网络,成为Multi-Factor Generative Adversarial Network,直接翻译过来的话就是多因子生成对抗网络.主要是期望能够探究影响推荐的其他因子(因 ...
- python基础(一):变量和常量
变量 什么是变量 变量,用于在内存中存放程序数据的容器.计算机的核心功能就是"计算",CPU是负责计算的,而计算需要数据吧?数据就存放在内存里,例如:将梁同学的姓名,年龄存下来,让 ...