scrapy获取当当网多页的获取
结合上节,网多页的获取只需要修改
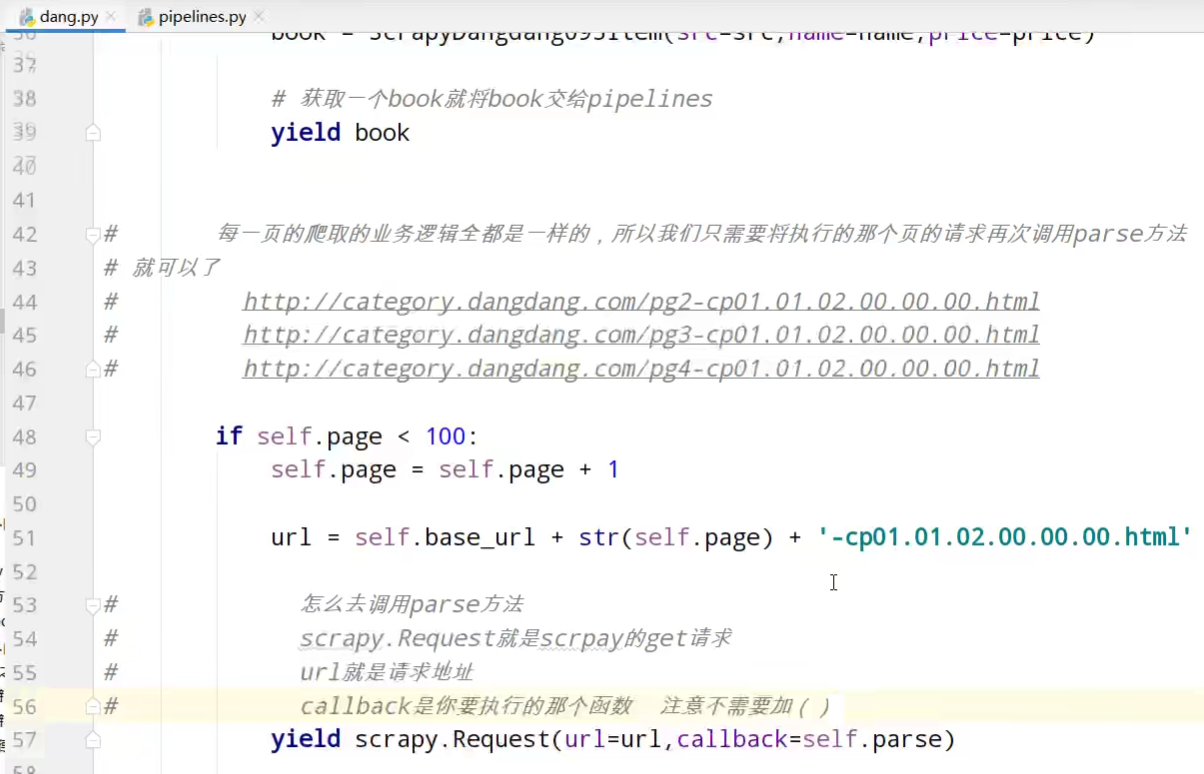
dang.py
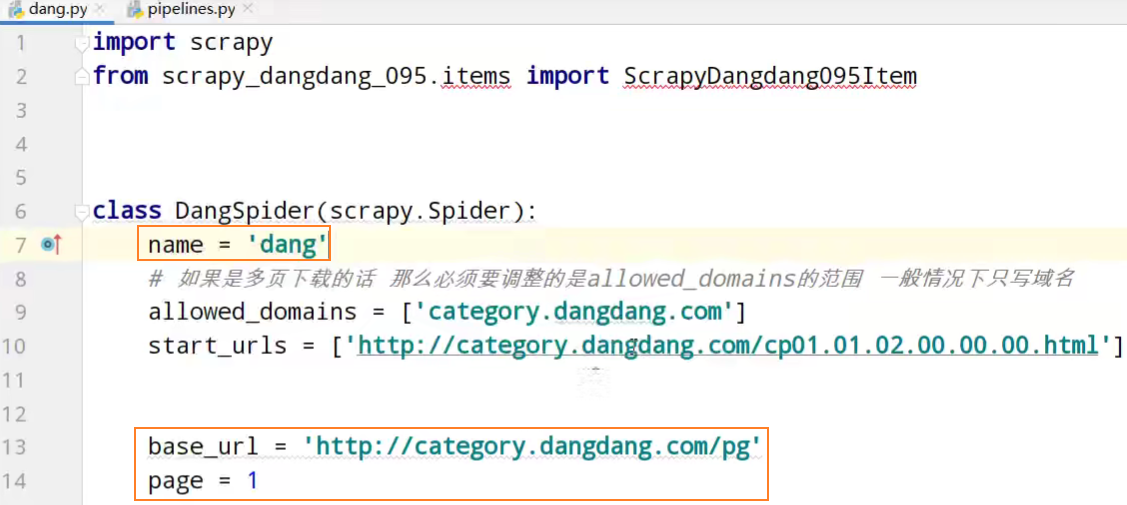
import scrapy
from scrapy_dangdang.items import ScrapyDangdang095Item class DangSpider(scrapy.Spider):
name = 'dang'
# 如果是多页下载的话 那么必须要调整的是allowed_domains的范围 一般情况下只写域名
allowed_domains = ['category.dangdang.com']
start_urls = ['http://category.dangdang.com/cp01.01.02.00.00.00.html'] base_url = 'http://category.dangdang.com/pg'
page = 1 def parse(self, response):
# pipelines 下载数据
# items 定义数据结构的
# src = //ul[@id="component_59"]/li//img/@src
# alt = //ul[@id="component_59"]/li//img/@alt
# price = //ul[@id="component_59"]/li//p[@class="price"]/span[1]/text()
# 所有的seletor的对象 都可以再次调用xpath方法
li_list = response.xpath('//ul[@id="component_59"]/li') for li in li_list:
src = li.xpath('.//img/@data-original').extract_first()
# 第一张图片和其他的图片的标签的属性是不一样的
# 第一张图片的src是可以使用的 其他的图片的地址是data-original
if src:
src = src
else:
src = li.xpath('.//img/@src').extract_first() name = li.xpath('.//img/@alt').extract_first()
price = li.xpath('.//p[@class="price"]/span[1]/text()').extract_first() book = ScrapyDangdang095Item(src=src,name=name,price=price) # 获取一个book就将book交给pipelines
yield book # 每一页的爬取的业务逻辑全都是一样的,所以我们只需要将执行的那个页的请求再次调用parse方法就可以了
# http://category.dangdang.com/pg2-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg3-cp01.01.02.00.00.00.html
# http://category.dangdang.com/pg4-cp01.01.02.00.00.00.html if self.page < 100:
self.page = self.page + 1 url = self.base_url + str(self.page) + '-cp01.01.02.00.00.00.html' # 怎么去调用parse方法
# scrapy.Request就是scrpay的get请求
# url就是请求地址
# callback是你要执行的那个函数 注意不需要加()
yield scrapy.Request(url=url,callback=self.parse)
运行


Ctrl+z暂定
多页下载完毕

scrapy获取当当网多页的获取的更多相关文章
- scrapy获取当当网中数据
yield 1. 带有 yield 的函数不再是一个普通函数,而是一个生成器generator,可用于迭代 2. yield 是一个类似 return 的关键字,迭代一次遇到yield时就返回yiel ...
- C#获取外网IP地址;C#获取所在IP城市地址
public static string GetIP() { using (var webClient = new WebClient()) ...
- Python 爬虫 当当网图书 scrapy
目标站点需求分析 获取当当网每个图书名字和评论数 涉及的库 scrapy,mysql 获取解析单页源码 保存到数据库中 结果
- Python爬虫库Scrapy入门1--爬取当当网商品数据
1.关于scrapy库的介绍,可以查看其官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/ 2.安装:pip install scrapy 注意这 ...
- scrapy项目3:爬取当当网中机器学习的数据及价格(spider类)
1.网页解析 当当网中,人工智能数据的首页url如下为http://category.dangdang.com/cp01.54.12.00.00.00.html 点击下方的链接,一次观察各个页面的ur ...
- scrapy 当当网 爬虫
前言 好久没有写实战博客了,因为前几个月在公司实习,博客更新就耽搁了下来,现在又受疫情影响无法返校,但是技能还是不能丢的,今天就写一篇使用scrapy爬取当当网的实战练习吧. 创建scrapy项目 目 ...
- dotnet获取PDF文件的页数
#region 获取PDF文件的页数 private int BytesLastIndexOf(Byte[] buffer, int length, string Search) { if (buff ...
- c#获取外网IP地址的方法
1.如果你是通过路由上网的,可以通过访问ip138之类的地址来获取外网IP 2.如果是通过PPPOE拨号上网的,可以使用以下代码获取IP //获取宽带连接(PPPOE拨号)的IP地址,timeout超 ...
- C#获取内网和外网IP
写了个小客户端,里面用到了获取内网和外网的IP地址,代码如下: // InnerIP var ipHost = Dns.Resolve(Dns.GetHostName()); ]; innerIP = ...
随机推荐
- Redis5种常用数据类型的使用以及内部编码
String 字符串类型是redis的最基本类型,首先无论值是什么数据类型,其键都是字符串,且其他数据类型的数据结构都是在字符串的基础上搭建的,相信读者能够体会到字符串在redis的地位是有多么的重要 ...
- 题解 [AGC017C] Snuke and Spells
题目传送门 Description 有 \(n\) 个球排在一起,每个球有颜色 \(a_i\),若当前有 \(k\) 个球,则会将所有 \(a_i=k\) 的球删掉.有 \(m\) 次查询,每次将 \ ...
- 回归本心QwQ背包问题luogu1776
今天在这里说一下多重背包问题 对 之前一直没有怎么彻底理解 首先多重背包是什么?这里就不做过多的赘述了 朴素的多重背包的复杂度是\(O(n*m*\sum s[i])\),其中\(s[i]\)是每一件物 ...
- epoll实现快速ping
概述 在VOIP的运营过程中,最常见的一类问题就是语音质量问题,网络间的丢包.延迟.抖动都会造成语音质量的体验下降. 当现网出现语音质量问题的时候,我们有没有工具能够快速的界定问题的边界,缩小排查的范 ...
- 分布式事物SAGA
目录 概述SAGA SAGA的执行方式 存在的问题 重试机制 SAGA VS TCC 实现SAGA的框架 概述SAGA SAGA是1987 Hector & Kenneth 发表的论文,主要是 ...
- 按键检测GPIO输入
1. 项目 通过按键控制开关LED灯,按下按键灯亮,再按一下灯灭. 2. 代码 mian.c #include "stm32f10x.h" //相当于51单片机中的 #includ ...
- 【UE4】基础概念——文件结构、类型、反射、编译、接口、垃圾回收、序列化
新标签打开或者下载看大图 思维导图 Engine Structure Pipeline Programming Pipeline Blueprint Pipeline
- Java:包装类小记
Java:包装类 对 Java 中的 包装类 这个概念,做一个微不足道的小小小小记 基本数据&包装类 四类八种基本数据类型: 数据类型 关键字 内存占用 取值范围 字节型 byte 1个字节 ...
- dwr简单应用及一个反向ajax消息推送
由于项目中最近需要用到dwr实现一些功能,因此在网上和dwr官网上找了一些资料进行学习.在此记录一下.(此处实现简单的dwr应用和dwr消息反向推送) 一.引入dwr的包 <dependency ...
- 在浏览器上开发GO和Vue!(基于code-server)
在浏览器上开发GO和Vue!(基于code-server) 曾几何时,开发者们都被安装编程环境苦恼,尽管现在很多语言的开发环境已经不难装了,但是如果我们能有一个运行在云端的编译器,那么我们就可以随时随 ...