VAE变分自编码器实现
- 导入必要的模块。本方法中,需要调用 Numpy、Matplolib 和 TensorFlow 函数:

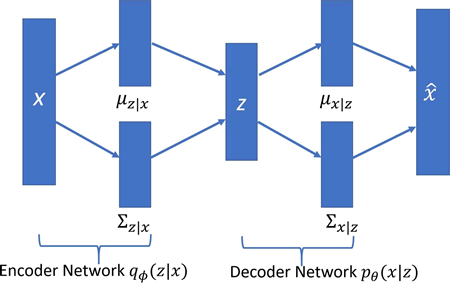
- 定义 VariationalAutoencoder 类。采用 __init__ 类方法来定义超参数,如学习率、批量大小、用于输入的占位符、编码器及解码器网络的权重和偏置变量。它还根据 VAE 的网络体系结构建立计算图。在本方法中使用 Xavier 初始化器初始化权重。与使用自己定义的方法进行 Xavier 初始化不同,本方法使用 tf.contrib.layers.xavier_initializer() 来进行初始化。最后,定义损失(生成和潜在)及优化器操作:

- 创建网络编码器和网络解码器。网络编码器的第一层接收输入并生成输入的递减式潜在表示;第二层将输入映射到高斯分布。网络学习这些转变:

- VariationalAutoencoder 类还包含一些帮助函数来生成和重建数据,并适应 VAE:

- 一旦 VAE 类完成,定义一个函数序列,它使用 VAE 类对象并通过给定的数据进行训练:

- 使用 VAE 类和序列函数。采用 MNIST 数据集:

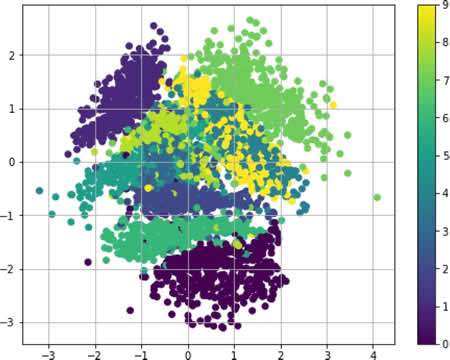
- 定义网络架构,并在 MNIST 数据集上进行 VAE 的训练。在这种情况下,为了简单保留了潜在维度 2。

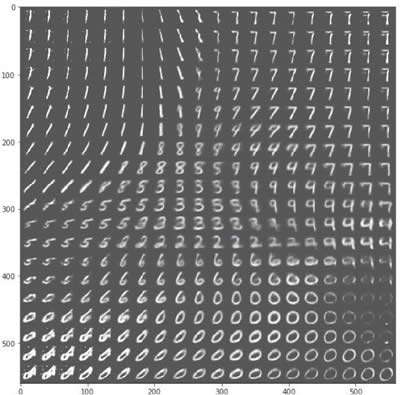
- 看一下 VAE 是否重构了输入。输出表明那些数字确实被重构了,而且由于使用了二维的潜在空间,所以图像显得模糊了:


- 以下是使用经过训练的 VAE 生成的手写数字样本:



VAE变分自编码器实现的更多相关文章
- VAE变分自编码器
我在学习VAE的时候遇到了很多问题,很多博客写的不太好理解,因此将很多内容重新进行了整合. 我自己的学习路线是先学EM算法再看的变分推断,最后学VAE,自我感觉这个线路比较好理解. 一.首先我们来宏观 ...
- Variational Auto-encoder(VAE)变分自编码器-Pytorch
import os import torch import torch.nn as nn import torch.nn.functional as F import torchvision from ...
- (转) 变分自编码器(Variational Autoencoder, VAE)通俗教程
变分自编码器(Variational Autoencoder, VAE)通俗教程 转载自: http://www.dengfanxin.cn/?p=334&sukey=72885186ae5c ...
- 变分自编码器(Variational Autoencoder, VAE)通俗教程
原文地址:http://www.dengfanxin.cn/?p=334 1. 神秘变量与数据集 现在有一个数据集DX(dataset, 也可以叫datapoints),每个数据也称为数据点.我们假定 ...
- 4.keras实现-->生成式深度学习之用变分自编码器VAE生成图像(mnist数据集和名人头像数据集)
变分自编码器(VAE,variatinal autoencoder) VS 生成式对抗网络(GAN,generative adversarial network) 两者不仅适用于图像,还可以 ...
- 变分自编码器(Variational auto-encoder,VAE)
参考: https://www.cnblogs.com/huangshiyu13/p/6209016.html https://zhuanlan.zhihu.com/p/25401928 https: ...
- 基于变分自编码器(VAE)利用重建概率的异常检测
本文为博主翻译自:Jinwon的Variational Autoencoder based Anomaly Detection using Reconstruction Probability,如侵立 ...
- 变分推断到变分自编码器(VAE)
EM算法 EM算法是含隐变量图模型的常用参数估计方法,通过迭代的方法来最大化边际似然. 带隐变量的贝叶斯网络 给定N 个训练样本D={x(n)},其对数似然函数为: 通过最大化整个训练集的对数边际似然 ...
- 基于图嵌入的高斯混合变分自编码器的深度聚类(Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedding, DGG)
基于图嵌入的高斯混合变分自编码器的深度聚类 Deep Clustering by Gaussian Mixture Variational Autoencoders with Graph Embedd ...
随机推荐
- Java基础常用类深度解析(包含常见排序算法)
目录 一.工具类 1.1.工具类的设计 1.1.1.公共静态方法 1.2.单例模式 二.包装类 2.1.基本类型的包装类 2.1.1.Integer 2.1.1.1.Integer >> ...
- php抽象类,接口,特性的比较
php抽象类 抽象方法必须被子类继承实现,所以不能为私有,只能是受保护的或公有的; 抽象类子类的方法访问控制级别必须和抽象类相等或更宽松.例如,父类的抽象方法是受保护的,子类实现时则必须为受保护的或者 ...
- 看了这篇还不会Linux性能分析和优化,你来打我
前言 一般互联网的项目都是部署在linux服务器上的,如果linux服务器出了问题,那么咱们平时学习的高并发,稳定性之类的是没有任何意义的,所以对linux性能的把握就显得非常重要,当然很多同学可能觉 ...
- hdu4560 不错的建图,二分最大流
题意: 我是歌手 Time Limit: 6000/2000 MS (Java/Others) Memory Limit: 65535/32768 K (Java/Others) Total Subm ...
- hdu1251 hash或者字典树
题意: 统计难题 Problem Description Ignatius最近遇到一个难题,老师交给他很多单词(只有小写字母组成,不会有重复的单词出现),现在老师要他统计出以某个字符串为前缀的单词数量 ...
- hdu4810
题意: 给你n个数,让你输出n个数,没一次输出的是在这n个数里面取i个数异或的和(所有情况<C n中取i>). 思路: 首先把所有的数都拆成二进制,然后把他们在某一位上 ...
- POJ2594 最小路径覆盖
题意: 题意就是给你个有向无环图,问你最少放多少个机器人能把图全部遍历,机器人不能走回头路线. 思路: 如果直接建图,跑一遍二分匹配输出n - 最大匹配数会跪,原因是这个题目和以 ...
- 【python】Leetcode每日一题-丑数
[python]Leetcode每日一题-丑数 [题目描述] 给你一个整数 n ,请你判断 n 是否为 丑数 .如果是,返回 true :否则,返回 false . 丑数 就是只包含质因数 2.3 和 ...
- (数据科学学习手札120)Python+Dash快速web应用开发——整合数据库
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 这是我的系列教程Python+Dash快速web ...
- 【DB宝51】CentOS7修改网卡名称
目录 1.修改/etc/default/grub文件 2.修改/etc/udev/rules.d/70-persistent-net.rules文件 3.修改网卡配置文件 4.重启服务器 需求:原来的 ...