ES系列(五):获取单条数据get处理过程实现
前面讲的都是些比较大的东西,即框架层面的东西。今天咱们来个轻松点的,只讲一个点:如题,get单条记录的es查询实现。
1. get语义说明
get是用于搜索单条es的数据,是根据主键id查询数据方式。类比关系型数据库中的sql则相当于:
select * from test where id = #{id};
当然了,es中每个关键词,都有相当多的附加描述词汇。比如:指定输出字段,版本号。。。
2. get的实现简要说明
从语义上讲,get的结果至多只有一条记录。所以,虽然es是集群存储数据的,但此处都需要从某节点取得一条数据即可。所以,理论上,只要能够快速定位到数据在哪个es节点上,然后向其发起请求,即可获取到结果了。
另外,对于使用主键id来进行查询数据,只要数据结构设计得当,应该会有非常高效的查询能力。
所以,通过本功能的实现方式分析,我们可以简要理解es key的分布方式。
3. get的具体实现
get只是es语法中的一个小点,根据上一节我们分析,知道了如何可以找到处理get的处理器。此处,我们简单再回顾下:


// org.elasticsearch.rest.RestController#dispatchRequest
@Override
public void dispatchRequest(RestRequest request, RestChannel channel, ThreadContext threadContext) {
try {
// 尝试所有可能的处理器
tryAllHandlers(request, channel, threadContext);
} catch (Exception e) {
try {
// 发生异常则响应异常信息
channel.sendResponse(new BytesRestResponse(channel, e));
} catch (Exception inner) {
inner.addSuppressed(e);
logger.error(() ->
new ParameterizedMessage("failed to send failure response for uri [{}]", request.uri()), inner);
}
}
}
// org.elasticsearch.rest.RestController#tryAllHandlers
private void tryAllHandlers(final RestRequest request, final RestChannel channel, final ThreadContext threadContext) throws Exception {
// 读取 header 信息
for (final RestHeaderDefinition restHeader : headersToCopy) {
final String name = restHeader.getName();
final List<String> headerValues = request.getAllHeaderValues(name);
if (headerValues != null && headerValues.isEmpty() == false) {
final List<String> distinctHeaderValues = headerValues.stream().distinct().collect(Collectors.toList());
if (restHeader.isMultiValueAllowed() == false && distinctHeaderValues.size() > 1) {
channel.sendResponse(
BytesRestResponse.
createSimpleErrorResponse(channel, BAD_REQUEST, "multiple values for single-valued header [" + name + "]."));
return;
} else {
threadContext.putHeader(name, String.join(",", distinctHeaderValues));
}
}
}
// error_trace cannot be used when we disable detailed errors
// we consume the error_trace parameter first to ensure that it is always consumed
if (request.paramAsBoolean("error_trace", false) && channel.detailedErrorsEnabled() == false) {
channel.sendResponse(
BytesRestResponse.createSimpleErrorResponse(channel, BAD_REQUEST, "error traces in responses are disabled."));
return;
} final String rawPath = request.rawPath();
final String uri = request.uri();
final RestRequest.Method requestMethod;
try {
// Resolves the HTTP method and fails if the method is invalid
requestMethod = request.method();
// Loop through all possible handlers, attempting to dispatch the request
// 获取可能的处理器,主要是有正则或者索引变量的存在,可能匹配多个处理器
Iterator<MethodHandlers> allHandlers = getAllHandlers(request.params(), rawPath);
while (allHandlers.hasNext()) {
final RestHandler handler;
// 一个处理器里支持多种请求方法
final MethodHandlers handlers = allHandlers.next();
if (handlers == null) {
handler = null;
} else {
handler = handlers.getHandler(requestMethod);
}
if (handler == null) {
// 未找到处理器不代表不能处理,有可能需要继续查找,如果确定不能处理,则直接响应客户端返回
if (handleNoHandlerFound(rawPath, requestMethod, uri, channel)) {
return;
}
} else {
// 找到了处理器,调用其方法
dispatchRequest(request, channel, handler);
return;
}
}
} catch (final IllegalArgumentException e) {
handleUnsupportedHttpMethod(uri, null, channel, getValidHandlerMethodSet(rawPath), e);
return;
}
// If request has not been handled, fallback to a bad request error.
// 降级方法调用
handleBadRequest(uri, requestMethod, channel);
}
// org.elasticsearch.rest.RestController#dispatchRequest
private void dispatchRequest(RestRequest request, RestChannel channel, RestHandler handler) throws Exception {
final int contentLength = request.contentLength();
if (contentLength > 0) {
final XContentType xContentType = request.getXContentType();
if (xContentType == null) {
sendContentTypeErrorMessage(request.getAllHeaderValues("Content-Type"), channel);
return;
}
if (handler.supportsContentStream() && xContentType != XContentType.JSON && xContentType != XContentType.SMILE) {
channel.sendResponse(BytesRestResponse.createSimpleErrorResponse(channel, RestStatus.NOT_ACCEPTABLE,
"Content-Type [" + xContentType + "] does not support stream parsing. Use JSON or SMILE instead"));
return;
}
}
RestChannel responseChannel = channel;
try {
// 熔断判定
if (handler.canTripCircuitBreaker()) {
inFlightRequestsBreaker(circuitBreakerService).addEstimateBytesAndMaybeBreak(contentLength, "<http_request>");
} else {
inFlightRequestsBreaker(circuitBreakerService).addWithoutBreaking(contentLength);
}
// iff we could reserve bytes for the request we need to send the response also over this channel
responseChannel = new ResourceHandlingHttpChannel(channel, circuitBreakerService, contentLength);
// TODO: Count requests double in the circuit breaker if they need copying?
if (handler.allowsUnsafeBuffers() == false) {
request.ensureSafeBuffers();
}
if (handler.allowSystemIndexAccessByDefault() == false && request.header(ELASTIC_PRODUCT_ORIGIN_HTTP_HEADER) == null) {
// The ELASTIC_PRODUCT_ORIGIN_HTTP_HEADER indicates that the request is coming from an Elastic product with a plan
// to move away from direct access to system indices, and thus deprecation warnings should not be emitted.
// This header is intended for internal use only.
client.threadPool().getThreadContext().putHeader(SYSTEM_INDEX_ACCESS_CONTROL_HEADER_KEY, Boolean.FALSE.toString());
}
// 调用handler处理方法,该handler可能会被过滤器先执行
handler.handleRequest(request, responseChannel, client);
} catch (Exception e) {
responseChannel.sendResponse(new BytesRestResponse(responseChannel, e));
}
}
// org.elasticsearch.xpack.security.rest.SecurityRestFilter#handleRequest
@Override
public void handleRequest(RestRequest request, RestChannel channel, NodeClient client) throws Exception {
if (licenseState.isSecurityEnabled() && request.method() != Method.OPTIONS) {
// CORS - allow for preflight unauthenticated OPTIONS request
if (extractClientCertificate) {
HttpChannel httpChannel = request.getHttpChannel();
SSLEngineUtils.extractClientCertificates(logger, threadContext, httpChannel);
} final String requestUri = request.uri();
authenticationService.authenticate(maybeWrapRestRequest(request), ActionListener.wrap(
authentication -> {
if (authentication == null) {
logger.trace("No authentication available for REST request [{}]", requestUri);
} else {
logger.trace("Authenticated REST request [{}] as {}", requestUri, authentication);
}
secondaryAuthenticator.authenticateAndAttachToContext(request, ActionListener.wrap(
secondaryAuthentication -> {
if (secondaryAuthentication != null) {
logger.trace("Found secondary authentication {} in REST request [{}]", secondaryAuthentication, requestUri);
}
RemoteHostHeader.process(request, threadContext);
restHandler.handleRequest(request, channel, client);
},
e -> handleException("Secondary authentication", request, channel, e)));
}, e -> handleException("Authentication", request, channel, e)));
} else {
// 转发到下一处理器责任链
restHandler.handleRequest(request, channel, client);
}
}
一般地,很多具体的处理器都会继承 BaseRestHandler, 即 handleRequest() 整体调用时序图如下:
handleRequest() 整体调用时序图
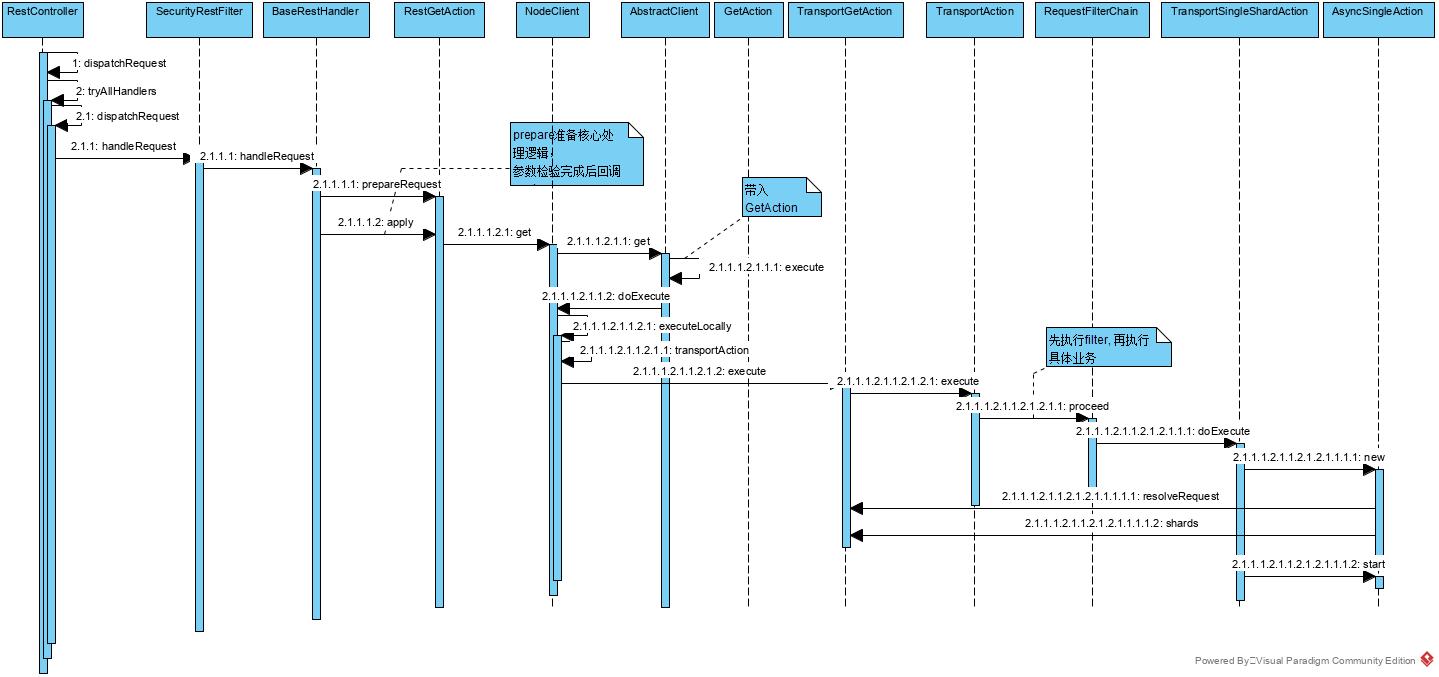
具体代码实现如下:
// org.elasticsearch.rest.BaseRestHandler#handleRequest
@Override
public final void handleRequest(RestRequest request, RestChannel channel, NodeClient client) throws Exception {
// prepare the request for execution; has the side effect of touching the request parameters
// 看起来叫准备请求,实际非常重要,它会组装后续的请求逻辑
final RestChannelConsumer action = prepareRequest(request, client); // validate unconsumed params, but we must exclude params used to format the response
// use a sorted set so the unconsumed parameters appear in a reliable sorted order
final SortedSet<String> unconsumedParams =
request.unconsumedParams().stream().filter(p -> !responseParams().contains(p)).collect(Collectors.toCollection(TreeSet::new)); // validate the non-response params
if (!unconsumedParams.isEmpty()) {
final Set<String> candidateParams = new HashSet<>();
candidateParams.addAll(request.consumedParams());
candidateParams.addAll(responseParams());
throw new IllegalArgumentException(unrecognized(request, unconsumedParams, candidateParams, "parameter"));
} if (request.hasContent() && request.isContentConsumed() == false) {
throw new IllegalArgumentException("request [" + request.method() + " " + request.path() + "] does not support having a body");
} usageCount.increment();
// execute the action
// 即此处仅为调用前面设置好的方法
action.accept(channel);
}
而处理get的处理器,我们实际上可以通过在最初注册的时候,可以看到是 RestGetAction, 它实现的 prepareRequest() 体现了其处理方法。
// org.elasticsearch.rest.action.document.RestGetAction#prepareRequest
@Override
public RestChannelConsumer prepareRequest(final RestRequest request, final NodeClient client) throws IOException {
GetRequest getRequest;
if (request.hasParam("type")) {
deprecationLogger.deprecate("get_with_types", TYPES_DEPRECATION_MESSAGE);
getRequest = new GetRequest(request.param("index"), request.param("type"), request.param("id"));
} else {
getRequest = new GetRequest(request.param("index"), request.param("id"));
} getRequest.refresh(request.paramAsBoolean("refresh", getRequest.refresh()));
getRequest.routing(request.param("routing"));
getRequest.preference(request.param("preference"));
getRequest.realtime(request.paramAsBoolean("realtime", getRequest.realtime()));
if (request.param("fields") != null) {
throw new IllegalArgumentException("the parameter [fields] is no longer supported, " +
"please use [stored_fields] to retrieve stored fields or [_source] to load the field from _source");
}
final String fieldsParam = request.param("stored_fields");
if (fieldsParam != null) {
final String[] fields = Strings.splitStringByCommaToArray(fieldsParam);
if (fields != null) {
getRequest.storedFields(fields);
}
} getRequest.version(RestActions.parseVersion(request));
getRequest.versionType(VersionType.fromString(request.param("version_type"), getRequest.versionType())); getRequest.fetchSourceContext(FetchSourceContext.parseFromRestRequest(request));
// 封装具体业务处理方法
// 交由 NodeClient 处理
return channel -> client.get(getRequest, new RestToXContentListener<GetResponse>(channel) {
@Override
protected RestStatus getStatus(final GetResponse response) {
return response.isExists() ? OK : NOT_FOUND;
}
});
}
// org.elasticsearch.search.fetch.subphase.FetchSourceContext#parseFromRestRequest
public static FetchSourceContext parseFromRestRequest(RestRequest request) {
Boolean fetchSource = null;
String[] sourceExcludes = null;
String[] sourceIncludes = null; String source = request.param("_source");
if (source != null) {
if (Booleans.isTrue(source)) {
fetchSource = true;
} else if (Booleans.isFalse(source)) {
fetchSource = false;
} else {
sourceIncludes = Strings.splitStringByCommaToArray(source);
}
} String sIncludes = request.param("_source_includes");
if (sIncludes != null) {
sourceIncludes = Strings.splitStringByCommaToArray(sIncludes);
} String sExcludes = request.param("_source_excludes");
if (sExcludes != null) {
sourceExcludes = Strings.splitStringByCommaToArray(sExcludes);
} if (fetchSource != null || sourceIncludes != null || sourceExcludes != null) {
return new FetchSourceContext(fetchSource == null ? true : fetchSource, sourceIncludes, sourceExcludes);
}
return null;
}
上面就是get的处理实现前奏,可以看出其支持的参数:type, id, refresh, routing, preference, fields, stored_fields, version_type, _source, _source_includes... 果然还是有点复杂,选择越多,越麻烦。
其中,url的请求方式,我们可以从es的route信息中看到:
// org.elasticsearch.rest.action.document.RestGetAction#routes
@Override
public List<Route> routes() {
return unmodifiableList(asList(
new Route(GET, "/{index}/_doc/{id}"),
new Route(HEAD, "/{index}/_doc/{id}"),
// Deprecated typed endpoints.
new Route(GET, "/{index}/{type}/{id}"),
new Route(HEAD, "/{index}/{type}/{id}")));
}
最终,会得到一个 TransportGetAction 的内部处理器。
// org.elasticsearch.action.support.TransportAction#execute
/**
* Use this method when the transport action call should result in creation of a new task associated with the call.
*
* This is a typical behavior.
*/
public final Task execute(Request request, ActionListener<Response> listener) {
/*
* While this version of execute could delegate to the TaskListener
* version of execute that'd add yet another layer of wrapping on the
* listener and prevent us from using the listener bare if there isn't a
* task. That just seems like too many objects. Thus the two versions of
* this method.
*/
final Releasable unregisterChildNode = registerChildNode(request.getParentTask());
final Task task;
try {
task = taskManager.register("transport", actionName, request);
} catch (TaskCancelledException e) {
unregisterChildNode.close();
throw e;
}
execute(task, request, new ActionListener<Response>() {
@Override
public void onResponse(Response response) {
try {
Releasables.close(unregisterChildNode, () -> taskManager.unregister(task));
} finally {
listener.onResponse(response);
}
} @Override
public void onFailure(Exception e) {
try {
Releasables.close(unregisterChildNode, () -> taskManager.unregister(task));
} finally {
listener.onFailure(e);
}
}
});
return task;
} /**
* Use this method when the transport action should continue to run in the context of the current task
*/
public final void execute(Task task, Request request, ActionListener<Response> listener) {
ActionRequestValidationException validationException = request.validate();
if (validationException != null) {
listener.onFailure(validationException);
return;
} if (task != null && request.getShouldStoreResult()) {
listener = new TaskResultStoringActionListener<>(taskManager, task, listener);
} RequestFilterChain<Request, Response> requestFilterChain = new RequestFilterChain<>(this, logger);
requestFilterChain.proceed(task, actionName, request, listener);
}
TransportGetAction 继承了 TransportSingleShardAction 继承了 TransportAction . , 所以 doExecute 调用了 TransportSingleShardAction 的方法。
// org.elasticsearch.action.support.single.shard.TransportSingleShardAction#doExecute
@Override
protected void doExecute(Task task, Request request, ActionListener<Response> listener) {
new AsyncSingleAction(request, listener).start();
}
// org.elasticsearch.action.support.single.shard.TransportSingleShardAction.AsyncSingleAction
private AsyncSingleAction(Request request, ActionListener<Response> listener) {
this.listener = listener; ClusterState clusterState = clusterService.state();
if (logger.isTraceEnabled()) {
logger.trace("executing [{}] based on cluster state version [{}]", request, clusterState.version());
}
nodes = clusterState.nodes();
ClusterBlockException blockException = checkGlobalBlock(clusterState);
if (blockException != null) {
throw blockException;
} String concreteSingleIndex;
// 解析 index 参数
if (resolveIndex(request)) {
concreteSingleIndex = indexNameExpressionResolver.concreteSingleIndex(clusterState, request).getName();
} else {
concreteSingleIndex = request.index();
}
// 组装内部请求
this.internalRequest = new InternalRequest(request, concreteSingleIndex);
resolveRequest(clusterState, internalRequest);
// 再次检测集群阻塞状态
blockException = checkRequestBlock(clusterState, internalRequest);
if (blockException != null) {
throw blockException;
}
// 获取所有分片信息,向集群发起请求
this.shardIt = shards(clusterState, internalRequest);
}
// org.elasticsearch.cluster.metadata.IndexNameExpressionResolver#concreteSingleIndex
/**
* Utility method that allows to resolve an index expression to its corresponding single concrete index.
* Callers should make sure they provide proper {@link org.elasticsearch.action.support.IndicesOptions}
* that require a single index as a result. The indices resolution must in fact return a single index when
* using this method, an {@link IllegalArgumentException} gets thrown otherwise.
*
* @param state the cluster state containing all the data to resolve to expression to a concrete index
* @param request The request that defines how the an alias or an index need to be resolved to a concrete index
* and the expression that can be resolved to an alias or an index name.
* @throws IllegalArgumentException if the index resolution lead to more than one index
* @return the concrete index obtained as a result of the index resolution
*/
public Index concreteSingleIndex(ClusterState state, IndicesRequest request) {
String indexExpression = CollectionUtils.isEmpty(request.indices()) ? null : request.indices()[0];
Index[] indices = concreteIndices(state, request.indicesOptions(), indexExpression);
if (indices.length != 1) {
throw new IllegalArgumentException("unable to return a single index as the index and options" +
" provided got resolved to multiple indices");
}
return indices[0];
} // org.elasticsearch.cluster.metadata.IndexNameExpressionResolver#concreteIndices
/**
* Translates the provided index expression into actual concrete indices, properly deduplicated.
*
* @param state the cluster state containing all the data to resolve to expressions to concrete indices
* @param options defines how the aliases or indices need to be resolved to concrete indices
* @param indexExpressions expressions that can be resolved to alias or index names.
* @return the resolved concrete indices based on the cluster state, indices options and index expressions
* @throws IndexNotFoundException if one of the index expressions is pointing to a missing index or alias and the
* provided indices options in the context don't allow such a case, or if the final result of the indices resolution
* contains no indices and the indices options in the context don't allow such a case.
* @throws IllegalArgumentException if one of the aliases resolve to multiple indices and the provided
* indices options in the context don't allow such a case.
*/
public Index[] concreteIndices(ClusterState state, IndicesOptions options, String... indexExpressions) {
return concreteIndices(state, options, false, indexExpressions);
} public Index[] concreteIndices(ClusterState state, IndicesOptions options, boolean includeDataStreams, String... indexExpressions) {
Context context = new Context(state, options, false, false, includeDataStreams,
isSystemIndexAccessAllowed());
return concreteIndices(context, indexExpressions);
} Index[] concreteIndices(Context context, String... indexExpressions) {
if (indexExpressions == null || indexExpressions.length == 0) {
indexExpressions = new String[]{Metadata.ALL};
}
Metadata metadata = context.getState().metadata();
IndicesOptions options = context.getOptions();
// If only one index is specified then whether we fail a request if an index is missing depends on the allow_no_indices
// option. At some point we should change this, because there shouldn't be a reason why whether a single index
// or multiple indices are specified yield different behaviour.
final boolean failNoIndices = indexExpressions.length == 1 ? !options.allowNoIndices() : !options.ignoreUnavailable();
List<String> expressions = Arrays.asList(indexExpressions);
for (ExpressionResolver expressionResolver : expressionResolvers) {
expressions = expressionResolver.resolve(context, expressions);
} if (expressions.isEmpty()) {
if (!options.allowNoIndices()) {
IndexNotFoundException infe;
if (indexExpressions.length == 1) {
if (indexExpressions[0].equals(Metadata.ALL)) {
infe = new IndexNotFoundException("no indices exist", (String)null);
} else {
infe = new IndexNotFoundException((String)null);
}
} else {
infe = new IndexNotFoundException((String)null);
}
infe.setResources("index_expression", indexExpressions);
throw infe;
} else {
return Index.EMPTY_ARRAY;
}
} boolean excludedDataStreams = false;
final Set<Index> concreteIndices = new LinkedHashSet<>(expressions.size());
for (String expression : expressions) {
IndexAbstraction indexAbstraction = metadata.getIndicesLookup().get(expression);
if (indexAbstraction == null ) {
if (failNoIndices) {
IndexNotFoundException infe;
if (expression.equals(Metadata.ALL)) {
infe = new IndexNotFoundException("no indices exist", expression);
} else {
infe = new IndexNotFoundException(expression);
}
infe.setResources("index_expression", expression);
throw infe;
} else {
continue;
}
} else if (indexAbstraction.getType() == IndexAbstraction.Type.ALIAS && context.getOptions().ignoreAliases()) {
if (failNoIndices) {
throw aliasesNotSupportedException(expression);
} else {
continue;
}
} else if (indexAbstraction.getType() == IndexAbstraction.Type.DATA_STREAM &&
context.includeDataStreams() == false) {
excludedDataStreams = true;
continue;
} if (indexAbstraction.getType() == IndexAbstraction.Type.ALIAS && context.isResolveToWriteIndex()) {
IndexMetadata writeIndex = indexAbstraction.getWriteIndex();
if (writeIndex == null) {
throw new IllegalArgumentException("no write index is defined for alias [" + indexAbstraction.getName() + "]." +
" The write index may be explicitly disabled using is_write_index=false or the alias points to multiple" +
" indices without one being designated as a write index");
}
if (addIndex(writeIndex, context)) {
concreteIndices.add(writeIndex.getIndex());
}
} else if (indexAbstraction.getType() == IndexAbstraction.Type.DATA_STREAM && context.isResolveToWriteIndex()) {
IndexMetadata writeIndex = indexAbstraction.getWriteIndex();
if (addIndex(writeIndex, context)) {
concreteIndices.add(writeIndex.getIndex());
}
} else {
if (indexAbstraction.getIndices().size() > 1 && !options.allowAliasesToMultipleIndices()) {
String[] indexNames = new String[indexAbstraction.getIndices().size()];
int i = 0;
for (IndexMetadata indexMetadata : indexAbstraction.getIndices()) {
indexNames[i++] = indexMetadata.getIndex().getName();
}
throw new IllegalArgumentException(indexAbstraction.getType().getDisplayName() + " [" + expression +
"] has more than one index associated with it " + Arrays.toString(indexNames) +
", can't execute a single index op");
} for (IndexMetadata index : indexAbstraction.getIndices()) {
if (shouldTrackConcreteIndex(context, options, index)) {
concreteIndices.add(index.getIndex());
}
}
}
} if (options.allowNoIndices() == false && concreteIndices.isEmpty()) {
IndexNotFoundException infe = new IndexNotFoundException((String)null);
infe.setResources("index_expression", indexExpressions);
if (excludedDataStreams) {
// Allows callers to handle IndexNotFoundException differently based on whether data streams were excluded.
infe.addMetadata(EXCLUDED_DATA_STREAMS_KEY, "true");
}
throw infe;
}
checkSystemIndexAccess(context, metadata, concreteIndices, indexExpressions);
return concreteIndices.toArray(new Index[concreteIndices.size()]);
} // org.elasticsearch.action.get.TransportGetAction#resolveRequest
@Override
protected void resolveRequest(ClusterState state, InternalRequest request) {
// update the routing (request#index here is possibly an alias)
request.request().routing(state.metadata().resolveIndexRouting(request.request().routing(), request.request().index()));
// Fail fast on the node that received the request.
if (request.request().routing() == null && state.getMetadata().routingRequired(request.concreteIndex())) {
throw new RoutingMissingException(request.concreteIndex(), request.request().type(), request.request().id());
}
} @Override
protected ShardIterator shards(ClusterState state, InternalRequest request) {
return clusterService.operationRouting()
.getShards(clusterService.state(), request.concreteIndex(), request.request().id(), request.request().routing(),
request.request().preference());
} // org.elasticsearch.action.support.single.shard.TransportSingleShardAction.AsyncSingleAction#start
public void start() {
if (shardIt == null) {
// just execute it on the local node
final Writeable.Reader<Response> reader = getResponseReader();
transportService.sendRequest(clusterService.localNode(), transportShardAction, internalRequest.request(),
new TransportResponseHandler<Response>() {
@Override
public Response read(StreamInput in) throws IOException {
return reader.read(in);
} @Override
public void handleResponse(final Response response) {
listener.onResponse(response);
} @Override
public void handleException(TransportException exp) {
listener.onFailure(exp);
}
});
} else {
perform(null);
}
}
private void perform(@Nullable final Exception currentFailure) {
Exception lastFailure = this.lastFailure;
if (lastFailure == null || TransportActions.isReadOverrideException(currentFailure)) {
lastFailure = currentFailure;
this.lastFailure = currentFailure;
}
final ShardRouting shardRouting = shardIt.nextOrNull();
if (shardRouting == null) {
Exception failure = lastFailure;
if (failure == null || isShardNotAvailableException(failure)) {
failure = new NoShardAvailableActionException(null,
LoggerMessageFormat.format("No shard available for [{}]", internalRequest.request()), failure);
} else {
logger.debug(() -> new ParameterizedMessage("{}: failed to execute [{}]", null,
internalRequest.request()), failure);
}
listener.onFailure(failure);
return;
}
DiscoveryNode node = nodes.get(shardRouting.currentNodeId());
if (node == null) {
onFailure(shardRouting, new NoShardAvailableActionException(shardRouting.shardId()));
} else {
internalRequest.request().internalShardId = shardRouting.shardId();
if (logger.isTraceEnabled()) {
logger.trace(
"sending request [{}] to shard [{}] on node [{}]",
internalRequest.request(),
internalRequest.request().internalShardId,
node
);
}
final Writeable.Reader<Response> reader = getResponseReader();
transportService.sendRequest(node, transportShardAction, internalRequest.request(),
new TransportResponseHandler<Response>() {
@Override
public Response read(StreamInput in) throws IOException {
return reader.read(in);
}
@Override
public void handleResponse(final Response response) {
listener.onResponse(response);
}
@Override
public void handleException(TransportException exp) {
onFailure(shardRouting, exp);
}
});
}
}
sendRequest, 本意是向外部网络发起请求,得到结果的过程。但es针对本节点的请求当然不会真正向外请求,我们以请求本节点的时序图,来看看es处理get的sendRequest过程吧。
sendRequest 调用时序图
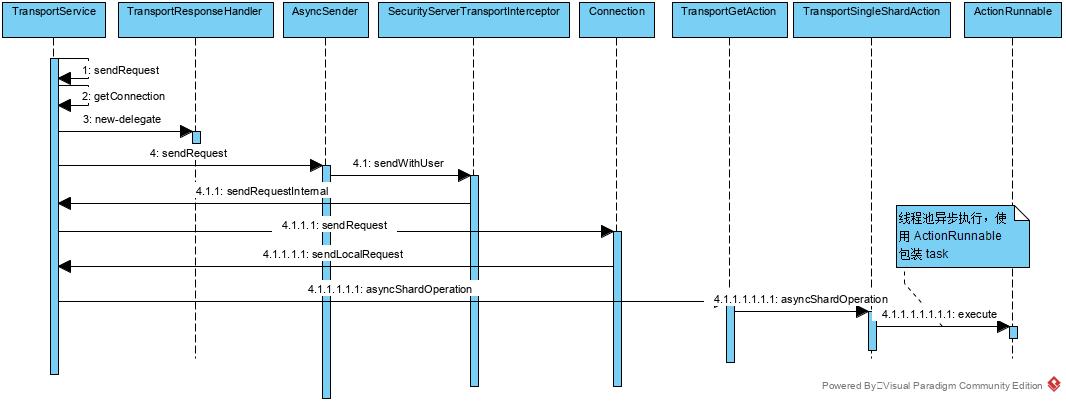
具体代码实现如下:
// org.elasticsearch.transport.TransportService#sendRequest
public <T extends TransportResponse> void sendRequest(final DiscoveryNode node, final String action,
final TransportRequest request,
final TransportResponseHandler<T> handler) {
sendRequest(node, action, request, TransportRequestOptions.EMPTY, handler);
} public final <T extends TransportResponse> void sendRequest(final DiscoveryNode node, final String action,
final TransportRequest request,
final TransportRequestOptions options,
TransportResponseHandler<T> handler) {
final Transport.Connection connection;
try {
connection = getConnection(node);
} catch (final NodeNotConnectedException ex) {
// the caller might not handle this so we invoke the handler
handler.handleException(ex);
return;
}
sendRequest(connection, action, request, options, handler);
} /**
* Returns either a real transport connection or a local node connection if we are using the local node optimization.
* @throws NodeNotConnectedException if the given node is not connected
*/
public Transport.Connection getConnection(DiscoveryNode node) {
// 如果是当前节点,直接返回当前service即可,无须再访问远程节点
if (isLocalNode(node)) {
return localNodeConnection;
} else {
return connectionManager.getConnection(node);
}
}
private boolean isLocalNode(DiscoveryNode discoveryNode) {
return Objects.requireNonNull(discoveryNode, "discovery node must not be null").equals(localNode);
} // org.elasticsearch.transport.TransportService#sendRequest
/**
* Sends a request on the specified connection. If there is a failure sending the request, the specified handler is invoked.
*
* @param connection the connection to send the request on
* @param action the name of the action
* @param request the request
* @param options the options for this request
* @param handler the response handler
* @param <T> the type of the transport response
*/
public final <T extends TransportResponse> void sendRequest(final Transport.Connection connection, final String action,
final TransportRequest request,
final TransportRequestOptions options,
final TransportResponseHandler<T> handler) {
try {
final TransportResponseHandler<T> delegate;
if (request.getParentTask().isSet()) {
// If the connection is a proxy connection, then we will create a cancellable proxy task on the proxy node and an actual
// child task on the target node of the remote cluster.
// ----> a parent task on the local cluster
// |
// ----> a proxy task on the proxy node on the remote cluster
// |
// ----> an actual child task on the target node on the remote cluster
// To cancel the child task on the remote cluster, we must send a cancel request to the proxy node instead of the target
// node as the parent task of the child task is the proxy task not the parent task on the local cluster. Hence, here we
// unwrap the connection and keep track of the connection to the proxy node instead of the proxy connection.
final Transport.Connection unwrappedConn = unwrapConnection(connection);
final Releasable unregisterChildNode = taskManager.registerChildConnection(request.getParentTask().getId(), unwrappedConn);
delegate = new TransportResponseHandler<T>() {
@Override
public void handleResponse(T response) {
unregisterChildNode.close();
handler.handleResponse(response);
} @Override
public void handleException(TransportException exp) {
unregisterChildNode.close();
handler.handleException(exp);
} @Override
public String executor() {
return handler.executor();
} @Override
public T read(StreamInput in) throws IOException {
return handler.read(in);
} @Override
public String toString() {
return getClass().getName() + "/[" + action + "]:" + handler.toString();
}
};
} else {
delegate = handler;
}
asyncSender.sendRequest(connection, action, request, options, delegate);
} catch (final Exception ex) {
// the caller might not handle this so we invoke the handler
final TransportException te;
if (ex instanceof TransportException) {
te = (TransportException) ex;
} else {
te = new TransportException("failure to send", ex);
}
handler.handleException(te);
}
} // org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor#interceptSender
@Override
public AsyncSender interceptSender(AsyncSender sender) {
return new AsyncSender() {
@Override
public <T extends TransportResponse> void sendRequest(Transport.Connection connection, String action, TransportRequest request,
TransportRequestOptions options, TransportResponseHandler<T> handler) {
final boolean requireAuth = shouldRequireExistingAuthentication();
// the transport in core normally does this check, BUT since we are serializing to a string header we need to do it
// ourselves otherwise we wind up using a version newer than what we can actually send
final Version minVersion = Version.min(connection.getVersion(), Version.CURRENT); // Sometimes a system action gets executed like a internal create index request or update mappings request
// which means that the user is copied over to system actions so we need to change the user
if (AuthorizationUtils.shouldReplaceUserWithSystem(threadPool.getThreadContext(), action)) {
securityContext.executeAsUser(SystemUser.INSTANCE, (original) -> sendWithUser(connection, action, request, options,
new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original)
, handler), sender, requireAuth), minVersion);
} else if (AuthorizationUtils.shouldSetUserBasedOnActionOrigin(threadPool.getThreadContext())) {
AuthorizationUtils.switchUserBasedOnActionOriginAndExecute(threadPool.getThreadContext(), securityContext,
(original) -> sendWithUser(connection, action, request, options,
new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original)
, handler), sender, requireAuth));
} else if (securityContext.getAuthentication() != null &&
securityContext.getAuthentication().getVersion().equals(minVersion) == false) {
// re-write the authentication since we want the authentication version to match the version of the connection
securityContext.executeAfterRewritingAuthentication(original -> sendWithUser(connection, action, request, options,
new ContextRestoreResponseHandler<>(threadPool.getThreadContext().wrapRestorable(original), handler), sender,
requireAuth), minVersion);
} else {
sendWithUser(connection, action, request, options, handler, sender, requireAuth);
}
}
};
}
// org.elasticsearch.xpack.security.transport.SecurityServerTransportInterceptor#sendWithUser
private <T extends TransportResponse> void sendWithUser(Transport.Connection connection, String action, TransportRequest request,
TransportRequestOptions options, TransportResponseHandler<T> handler,
AsyncSender sender, final boolean requireAuthentication) {
if (securityContext.getAuthentication() == null && requireAuthentication) {
// we use an assertion here to ensure we catch this in our testing infrastructure, but leave the ISE for cases we do not catch
// in tests and may be hit by a user
assertNoAuthentication(action);
throw new IllegalStateException("there should always be a user when sending a message for action [" + action + "]");
} try {
sender.sendRequest(connection, action, request, options, handler);
} catch (Exception e) {
handler.handleException(new TransportException("failed sending request", e));
}
}
// org.elasticsearch.transport.TransportService#sendRequestInternal
private <T extends TransportResponse> void sendRequestInternal(final Transport.Connection connection, final String action,
final TransportRequest request,
final TransportRequestOptions options,
TransportResponseHandler<T> handler) {
if (connection == null) {
throw new IllegalStateException("can't send request to a null connection");
}
DiscoveryNode node = connection.getNode(); Supplier<ThreadContext.StoredContext> storedContextSupplier = threadPool.getThreadContext().newRestorableContext(true);
ContextRestoreResponseHandler<T> responseHandler = new ContextRestoreResponseHandler<>(storedContextSupplier, handler);
// TODO we can probably fold this entire request ID dance into connection.sendReqeust but it will be a bigger refactoring
final long requestId = responseHandlers.add(new Transport.ResponseContext<>(responseHandler, connection, action));
final TimeoutHandler timeoutHandler;
if (options.timeout() != null) {
timeoutHandler = new TimeoutHandler(requestId, connection.getNode(), action);
responseHandler.setTimeoutHandler(timeoutHandler);
} else {
timeoutHandler = null;
}
try {
if (lifecycle.stoppedOrClosed()) {
/*
* If we are not started the exception handling will remove the request holder again and calls the handler to notify the
* caller. It will only notify if toStop hasn't done the work yet.
*/
throw new NodeClosedException(localNode);
}
if (timeoutHandler != null) {
assert options.timeout() != null;
timeoutHandler.scheduleTimeout(options.timeout());
}
// 请求发送
connection.sendRequest(requestId, action, request, options); // local node optimization happens upstream
} catch (final Exception e) {
// usually happen either because we failed to connect to the node
// or because we failed serializing the message
final Transport.ResponseContext<? extends TransportResponse> contextToNotify = responseHandlers.remove(requestId);
// If holderToNotify == null then handler has already been taken care of.
if (contextToNotify != null) {
if (timeoutHandler != null) {
timeoutHandler.cancel();
}
// callback that an exception happened, but on a different thread since we don't
// want handlers to worry about stack overflows. In the special case of running into a closing node we run on the current
// thread on a best effort basis though.
final SendRequestTransportException sendRequestException = new SendRequestTransportException(node, action, e);
final String executor = lifecycle.stoppedOrClosed() ? ThreadPool.Names.SAME : ThreadPool.Names.GENERIC;
threadPool.executor(executor).execute(new AbstractRunnable() {
@Override
public void onRejection(Exception e) {
// if we get rejected during node shutdown we don't wanna bubble it up
logger.debug(
() -> new ParameterizedMessage(
"failed to notify response handler on rejection, action: {}",
contextToNotify.action()),
e);
}
@Override
public void onFailure(Exception e) {
logger.warn(
() -> new ParameterizedMessage(
"failed to notify response handler on exception, action: {}",
contextToNotify.action()),
e);
}
@Override
protected void doRun() throws Exception {
contextToNotify.handler().handleException(sendRequestException);
}
});
} else {
logger.debug("Exception while sending request, handler likely already notified due to timeout", e);
}
}
}
// org.elasticsearch.transport.Transport.Connection#sendRequest
@Override
public void sendRequest(long requestId, String action, TransportRequest request, TransportRequestOptions options)
throws TransportException {
sendLocalRequest(requestId, action, request, options);
}
// org.elasticsearch.transport.TransportService#sendLocalRequest
private void sendLocalRequest(long requestId, final String action, final TransportRequest request, TransportRequestOptions options) {
final DirectResponseChannel channel = new DirectResponseChannel(localNode, action, requestId, this, threadPool);
try {
onRequestSent(localNode, requestId, action, request, options);
onRequestReceived(requestId, action);
// 获取 handler
final RequestHandlerRegistry reg = getRequestHandler(action);
if (reg == null) {
throw new ActionNotFoundTransportException("Action [" + action + "] not found");
}
final String executor = reg.getExecutor();
if (ThreadPool.Names.SAME.equals(executor)) {
//noinspection unchecked
reg.processMessageReceived(request, channel);
} else {
threadPool.executor(executor).execute(new AbstractRunnable() {
@Override
protected void doRun() throws Exception {
//noinspection unchecked
reg.processMessageReceived(request, channel);
} @Override
public boolean isForceExecution() {
return reg.isForceExecution();
} @Override
public void onFailure(Exception e) {
try {
channel.sendResponse(e);
} catch (Exception inner) {
inner.addSuppressed(e);
logger.warn(() -> new ParameterizedMessage(
"failed to notify channel of error message for action [{}]", action), inner);
}
} @Override
public String toString() {
return "processing of [" + requestId + "][" + action + "]: " + request;
}
});
} } catch (Exception e) {
try {
channel.sendResponse(e);
} catch (Exception inner) {
inner.addSuppressed(e);
logger.warn(
() -> new ParameterizedMessage(
"failed to notify channel of error message for action [{}]", action), inner);
}
}
}
// org.elasticsearch.transport.RequestHandlerRegistry#processMessageReceived
public void processMessageReceived(Request request, TransportChannel channel) throws Exception {
final Task task = taskManager.register(channel.getChannelType(), action, request);
Releasable unregisterTask = () -> taskManager.unregister(task);
try {
if (channel instanceof TcpTransportChannel && task instanceof CancellableTask) {
final TcpChannel tcpChannel = ((TcpTransportChannel) channel).getChannel();
final Releasable stopTracking = taskManager.startTrackingCancellableChannelTask(tcpChannel, (CancellableTask) task);
unregisterTask = Releasables.wrap(unregisterTask, stopTracking);
}
final TaskTransportChannel taskTransportChannel = new TaskTransportChannel(channel, unregisterTask);
handler.messageReceived(request, taskTransportChannel, task);
unregisterTask = null;
} finally {
Releasables.close(unregisterTask);
}
}
// org.elasticsearch.action.get.TransportGetAction#asyncShardOperation
@Override
protected void asyncShardOperation(GetRequest request, ShardId shardId, ActionListener<GetResponse> listener) throws IOException {
IndexService indexService = indicesService.indexServiceSafe(shardId.getIndex());
IndexShard indexShard = indexService.getShard(shardId.id());
if (request.realtime()) { // we are not tied to a refresh cycle here anyway
super.asyncShardOperation(request, shardId, listener);
} else {
indexShard.awaitShardSearchActive(b -> {
try {
super.asyncShardOperation(request, shardId, listener);
} catch (Exception ex) {
listener.onFailure(ex);
}
});
}
}
// org.elasticsearch.action.support.single.shard.TransportSingleShardAction#asyncShardOperation
protected void asyncShardOperation(Request request, ShardId shardId, ActionListener<Response> listener) throws IOException {
threadPool.executor(getExecutor(request, shardId))
.execute(ActionRunnable.supply(listener, () -> shardOperation(request, shardId)));
} // org.elasticsearch.action.get.TransportGetAction#shardOperation
// 该方法为实现get操作的真正方法
@Override
protected GetResponse shardOperation(GetRequest request, ShardId shardId) {
IndexService indexService = indicesService.indexServiceSafe(shardId.getIndex());
IndexShard indexShard = indexService.getShard(shardId.id()); if (request.refresh() && !request.realtime()) {
indexShard.refresh("refresh_flag_get");
}
// 核心 get 实现
GetResult result = indexShard.getService().get(request.type(), request.id(), request.storedFields(),
request.realtime(), request.version(), request.versionType(), request.fetchSourceContext());
// 使用 GetResponse 包装结果返回,方便结果响应输出
return new GetResponse(result);
}
以上,是 get 的处理框架,基本原理就是先看是否有路由配置,如果有按其规则来,如果没有直接向某个节点发起请求,即可获取到数据。整个get请求前置的转发过程,因为考虑大量的远程调用与复用,显示比较复杂。其中,es中大量使用了包装器模式和观察者模式,值得我们注意和学习。到最后最核心的get的实现,其实是 shardOperation() 方法。它又是如何与lucene交互获取数据的呢?稍后见分晓。
路由是es的一个我特性,而shard则是一个核心概念。接下来,我们看两个细节,即 es get 如何处理路由 和es get 如何处理shard问题。
// 处理路由问题, 请求方式如: curl -XGET 'http://localhost:9200/test_index/job/1?routing=user123'
// org.elasticsearch.action.get.TransportGetAction#resolveRequest
@Override
protected void resolveRequest(ClusterState state, InternalRequest request) {
// update the routing (request#index here is possibly an alias)
// 取出默认的 routing 规则,或者校验传入的routing规则
request.request().routing(state.metadata().resolveIndexRouting(request.request().routing(), request.request().index()));
// Fail fast on the node that received the request.
if (request.request().routing() == null && state.getMetadata().routingRequired(request.concreteIndex())) {
throw new RoutingMissingException(request.concreteIndex(), request.request().type(), request.request().id());
}
}
// org.elasticsearch.cluster.metadata.Metadata#resolveIndexRouting
/**
* Returns indexing routing for the given index.
*/
// TODO: This can be moved to IndexNameExpressionResolver too, but this means that we will support wildcards and other expressions
// in the index,bulk,update and delete apis.
public String resolveIndexRouting(@Nullable String routing, String aliasOrIndex) {
if (aliasOrIndex == null) {
return routing;
}
// 获取索引对应的元数据信息,用于判定是否是别名型索引
// 非别名型索引,routing 不变
IndexAbstraction result = getIndicesLookup().get(aliasOrIndex);
if (result == null || result.getType() != IndexAbstraction.Type.ALIAS) {
return routing;
}
IndexAbstraction.Alias alias = (IndexAbstraction.Alias) result;
if (result.getIndices().size() > 1) {
rejectSingleIndexOperation(aliasOrIndex, result);
}
AliasMetadata aliasMd = alias.getFirstAliasMetadata();
if (aliasMd.indexRouting() != null) {
// 一个 alias 不允许有多个 routing key
if (aliasMd.indexRouting().indexOf(',') != -1) {
throw new IllegalArgumentException("index/alias [" + aliasOrIndex + "] provided with routing value [" +
aliasMd.getIndexRouting() + "] that resolved to several routing values, rejecting operation");
}
if (routing != null) {
if (!routing.equals(aliasMd.indexRouting())) {
throw new IllegalArgumentException("Alias [" + aliasOrIndex + "] has index routing associated with it [" +
aliasMd.indexRouting() + "], and was provided with routing value [" + routing + "], rejecting operation");
}
}
// Alias routing overrides the parent routing (if any).
return aliasMd.indexRouting();
}
return routing;
} // 处理shard问题
// org.elasticsearch.action.get.TransportGetAction#shards
@Override
protected ShardIterator shards(ClusterState state, InternalRequest request) {
return clusterService.operationRouting()
.getShards(clusterService.state(), request.concreteIndex(), request.request().id(), request.request().routing(),
request.request().preference());
}
// org.elasticsearch.cluster.routing.OperationRouting#getShards
public ShardIterator getShards(ClusterState clusterState, String index, String id, @Nullable String routing,
@Nullable String preference) {
// 先获取shardingTable, 再生成Shard迭代器
return preferenceActiveShardIterator(shards(clusterState, index, id, routing), clusterState.nodes().getLocalNodeId(),
clusterState.nodes(), preference, null, null);
}
// org.elasticsearch.cluster.routing.OperationRouting#shards
protected IndexShardRoutingTable shards(ClusterState clusterState, String index, String id, String routing) {
int shardId = generateShardId(indexMetadata(clusterState, index), id, routing);
return clusterState.getRoutingTable().shardRoutingTable(index, shardId);
}
// org.elasticsearch.cluster.routing.OperationRouting#indexMetadata
protected IndexMetadata indexMetadata(ClusterState clusterState, String index) {
IndexMetadata indexMetadata = clusterState.metadata().index(index);
if (indexMetadata == null) {
throw new IndexNotFoundException(index);
}
return indexMetadata;
}
// 生成shardId
// org.elasticsearch.cluster.routing.OperationRouting#generateShardId
public static int generateShardId(IndexMetadata indexMetadata, @Nullable String id, @Nullable String routing) {
final String effectiveRouting;
final int partitionOffset; if (routing == null) {
assert(indexMetadata.isRoutingPartitionedIndex() == false) : "A routing value is required for gets from a partitioned index";
effectiveRouting = id;
} else {
effectiveRouting = routing;
} if (indexMetadata.isRoutingPartitionedIndex()) {
partitionOffset = Math.floorMod(Murmur3HashFunction.hash(id), indexMetadata.getRoutingPartitionSize());
} else {
// we would have still got 0 above but this check just saves us an unnecessary hash calculation
partitionOffset = 0;
} return calculateScaledShardId(indexMetadata, effectiveRouting, partitionOffset);
}
// org.elasticsearch.cluster.routing.OperationRouting#calculateScaledShardId
private static int calculateScaledShardId(IndexMetadata indexMetadata, String effectiveRouting, int partitionOffset) {
final int hash = Murmur3HashFunction.hash(effectiveRouting) + partitionOffset; // we don't use IMD#getNumberOfShards since the index might have been shrunk such that we need to use the size
// of original index to hash documents
// routingFactor默认为1
return Math.floorMod(hash, indexMetadata.getRoutingNumShards()) / indexMetadata.getRoutingFactor();
}
// org.elasticsearch.cluster.routing.RoutingTable#shardRoutingTable(java.lang.String, int)
/**
* All shards for the provided index and shard id
* @return All the shard routing entries for the given index and shard id
* @throws IndexNotFoundException if provided index does not exist
* @throws ShardNotFoundException if provided shard id is unknown
*/
public IndexShardRoutingTable shardRoutingTable(String index, int shardId) {
IndexRoutingTable indexRouting = index(index);
if (indexRouting == null) {
throw new IndexNotFoundException(index);
}
return shardRoutingTable(indexRouting, shardId);
}
// org.elasticsearch.cluster.routing.RoutingTable#shardRoutingTable
/**
* Get's the {@link IndexShardRoutingTable} for the given shard id from the given {@link IndexRoutingTable}
* or throws a {@link ShardNotFoundException} if no shard by the given id is found in the IndexRoutingTable.
*
* @param indexRouting IndexRoutingTable
* @param shardId ShardId
* @return IndexShardRoutingTable
*/
public static IndexShardRoutingTable shardRoutingTable(IndexRoutingTable indexRouting, int shardId) {
IndexShardRoutingTable indexShard = indexRouting.shard(shardId);
if (indexShard == null) {
throw new ShardNotFoundException(new ShardId(indexRouting.getIndex(), shardId));
}
return indexShard;
}
// org.elasticsearch.cluster.routing.OperationRouting#preferenceActiveShardIterator
private ShardIterator preferenceActiveShardIterator(IndexShardRoutingTable indexShard, String localNodeId,
DiscoveryNodes nodes, @Nullable String preference,
@Nullable ResponseCollectorService collectorService,
@Nullable Map<String, Long> nodeCounts) {
if (preference == null || preference.isEmpty()) {
return shardRoutings(indexShard, nodes, collectorService, nodeCounts);
}
if (preference.charAt(0) == '_') {
Preference preferenceType = Preference.parse(preference);
if (preferenceType == Preference.SHARDS) {
// starts with _shards, so execute on specific ones
int index = preference.indexOf('|'); String shards;
if (index == -1) {
shards = preference.substring(Preference.SHARDS.type().length() + 1);
} else {
shards = preference.substring(Preference.SHARDS.type().length() + 1, index);
}
String[] ids = Strings.splitStringByCommaToArray(shards);
boolean found = false;
for (String id : ids) {
if (Integer.parseInt(id) == indexShard.shardId().id()) {
found = true;
break;
}
}
if (!found) {
return null;
}
// no more preference
if (index == -1 || index == preference.length() - 1) {
return shardRoutings(indexShard, nodes, collectorService, nodeCounts);
} else {
// update the preference and continue
preference = preference.substring(index + 1);
}
}
preferenceType = Preference.parse(preference);
switch (preferenceType) {
case PREFER_NODES:
final Set<String> nodesIds =
Arrays.stream(
preference.substring(Preference.PREFER_NODES.type().length() + 1).split(",")
).collect(Collectors.toSet());
return indexShard.preferNodeActiveInitializingShardsIt(nodesIds);
case LOCAL:
return indexShard.preferNodeActiveInitializingShardsIt(Collections.singleton(localNodeId));
case ONLY_LOCAL:
return indexShard.onlyNodeActiveInitializingShardsIt(localNodeId);
case ONLY_NODES:
String nodeAttributes = preference.substring(Preference.ONLY_NODES.type().length() + 1);
return indexShard.onlyNodeSelectorActiveInitializingShardsIt(nodeAttributes.split(","), nodes);
default:
throw new IllegalArgumentException("unknown preference [" + preferenceType + "]");
}
}
// if not, then use it as the index
int routingHash = Murmur3HashFunction.hash(preference);
if (nodes.getMinNodeVersion().onOrAfter(Version.V_6_0_0_alpha1)) {
// The AllocationService lists shards in a fixed order based on nodes
// so earlier versions of this class would have a tendency to
// select the same node across different shardIds.
// Better overall balancing can be achieved if each shardId opts
// for a different element in the list by also incorporating the
// shard ID into the hash of the user-supplied preference key.
routingHash = 31 * routingHash + indexShard.shardId.hashCode();
}
if (awarenessAttributes.isEmpty()) {
return indexShard.activeInitializingShardsIt(routingHash);
} else {
return indexShard.preferAttributesActiveInitializingShardsIt(awarenessAttributes, nodes, routingHash);
}
} private ShardIterator shardRoutings(IndexShardRoutingTable indexShard, DiscoveryNodes nodes,
@Nullable ResponseCollectorService collectorService, @Nullable Map<String, Long> nodeCounts) {
if (awarenessAttributes.isEmpty()) {
if (useAdaptiveReplicaSelection) {
return indexShard.activeInitializingShardsRankedIt(collectorService, nodeCounts);
} else {
return indexShard.activeInitializingShardsRandomIt();
}
} else {
return indexShard.preferAttributesActiveInitializingShardsIt(awarenessAttributes, nodes);
}
}
// org.elasticsearch.cluster.routing.IndexShardRoutingTable#activeInitializingShardsRankedIt
/**
* Returns an iterator over active and initializing shards, ordered by the adaptive replica
* selection formula. Making sure though that its random within the active shards of the same
* (or missing) rank, and initializing shards are the last to iterate through.
*/
public ShardIterator activeInitializingShardsRankedIt(@Nullable ResponseCollectorService collector,
@Nullable Map<String, Long> nodeSearchCounts) {
final int seed = shuffler.nextSeed();
if (allInitializingShards.isEmpty()) {
return new PlainShardIterator(shardId,
rankShardsAndUpdateStats(shuffler.shuffle(activeShards, seed), collector, nodeSearchCounts));
} ArrayList<ShardRouting> ordered = new ArrayList<>(activeShards.size() + allInitializingShards.size());
List<ShardRouting> rankedActiveShards =
rankShardsAndUpdateStats(shuffler.shuffle(activeShards, seed), collector, nodeSearchCounts);
ordered.addAll(rankedActiveShards);
List<ShardRouting> rankedInitializingShards =
rankShardsAndUpdateStats(allInitializingShards, collector, nodeSearchCounts);
ordered.addAll(rankedInitializingShards);
return new PlainShardIterator(shardId, ordered);
}
4. get的内部逻辑
它是在 TransportGetAction 的 shardOperation() 中实现的同步调用:
先来看个整体的调用时序图:
get查找核心时序图

// org.elasticsearch.action.get.TransportGetAction#shardOperation
// 该方法为实现get操作的真正方法
@Override
protected GetResponse shardOperation(GetRequest request, ShardId shardId) {
IndexService indexService = indicesService.indexServiceSafe(shardId.getIndex());
IndexShard indexShard = indexService.getShard(shardId.id()); if (request.refresh() && !request.realtime()) {
indexShard.refresh("refresh_flag_get");
}
// 核心 get 实现
GetResult result = indexShard.getService().get(request.type(), request.id(), request.storedFields(),
request.realtime(), request.version(), request.versionType(), request.fetchSourceContext());
return new GetResponse(result);
}
// org.elasticsearch.indices.IndicesService#indexServiceSafe
/**
* Returns an IndexService for the specified index if exists otherwise a {@link IndexNotFoundException} is thrown.
*/
public IndexService indexServiceSafe(Index index) {
IndexService indexService = indices.get(index.getUUID());
if (indexService == null) {
throw new IndexNotFoundException(index);
}
assert indexService.indexUUID().equals(index.getUUID()) : "uuid mismatch local: " + indexService.indexUUID() +
" incoming: " + index.getUUID();
return indexService;
}
// org.elasticsearch.index.IndexService#getShard
/**
* Return the shard with the provided id, or throw an exception if it doesn't exist.
*/
public IndexShard getShard(int shardId) {
IndexShard indexShard = getShardOrNull(shardId);
if (indexShard == null) {
throw new ShardNotFoundException(new ShardId(index(), shardId));
}
return indexShard;
} // org.elasticsearch.index.shard.IndexShard#getService
public ShardGetService getService() {
return this.getService;
} // org.elasticsearch.index.get.ShardGetService#get
public GetResult get(String type, String id, String[] gFields, boolean realtime, long version,
VersionType versionType, FetchSourceContext fetchSourceContext) {
return
get(type, id, gFields, realtime, version, versionType, UNASSIGNED_SEQ_NO, UNASSIGNED_PRIMARY_TERM, fetchSourceContext);
}
// org.elasticsearch.index.get.ShardGetService#get
private GetResult get(String type, String id, String[] gFields, boolean realtime, long version, VersionType versionType,
long ifSeqNo, long ifPrimaryTerm, FetchSourceContext fetchSourceContext) {
currentMetric.inc();
try {
long now = System.nanoTime();
GetResult getResult =
innerGet(type, id, gFields, realtime, version, versionType, ifSeqNo, ifPrimaryTerm, fetchSourceContext); if (getResult.isExists()) {
existsMetric.inc(System.nanoTime() - now);
} else {
missingMetric.inc(System.nanoTime() - now);
}
return getResult;
} finally {
currentMetric.dec();
}
}
// org.elasticsearch.index.get.ShardGetService#innerGet
private GetResult innerGet(String type, String id, String[] gFields, boolean realtime, long version, VersionType versionType,
long ifSeqNo, long ifPrimaryTerm, FetchSourceContext fetchSourceContext) {
// 查询字段信息校验
fetchSourceContext = normalizeFetchSourceContent(fetchSourceContext, gFields);
// 支持无type搜索,即丢弃老版本的 type 字段, 一个索引下全是数据
if (type == null || type.equals("_all")) {
DocumentMapper mapper = mapperService.documentMapper();
type = mapper == null ? null : mapper.type();
} Engine.GetResult get = null;
if (type != null) {
Term uidTerm = new Term(IdFieldMapper.NAME, Uid.encodeId(id));
// 链式构造一个 Get 实例,调用 get() 方法查找doc
// 其中 indexShard 是前面根据shardId 推断出来的, 也是基于一个doc只能在一个shard上的前提
get = indexShard.get(new Engine.Get(realtime, realtime, type, id, uidTerm)
.version(version).versionType(versionType).setIfSeqNo(ifSeqNo).setIfPrimaryTerm(ifPrimaryTerm));
assert get.isFromTranslog() == false || realtime : "should only read from translog if realtime enabled";
if (get.exists() == false) {
get.close();
}
} if (get == null || get.exists() == false) {
return new GetResult(shardId.getIndexName(), type, id, UNASSIGNED_SEQ_NO, UNASSIGNED_PRIMARY_TERM, -1, false, null, null, null);
} try {
// break between having loaded it from translog (so we only have _source), and having a document to load
// 根据docId 查询具体的doc信息
return innerGetLoadFromStoredFields(type, id, gFields, fetchSourceContext, get, mapperService);
} finally {
get.close();
}
} /**
* decides what needs to be done based on the request input and always returns a valid non-null FetchSourceContext
*/
private FetchSourceContext normalizeFetchSourceContent(@Nullable FetchSourceContext context, @Nullable String[] gFields) {
if (context != null) {
return context;
}
if (gFields == null) {
return FetchSourceContext.FETCH_SOURCE;
}
for (String field : gFields) {
if (SourceFieldMapper.NAME.equals(field)) {
return FetchSourceContext.FETCH_SOURCE;
}
}
return FetchSourceContext.DO_NOT_FETCH_SOURCE;
}
// org.elasticsearch.index.shard.IndexShard#get
public Engine.GetResult get(Engine.Get get) {
// 当前集群状态判定, 是否可读, 如果是 red 状态则是不可读的
readAllowed();
DocumentMapper mapper = mapperService.documentMapper();
if (mapper == null || mapper.type().equals(mapperService.resolveDocumentType(get.type())) == false) {
return GetResult.NOT_EXISTS;
}
// wrapSearcher 实现查询结果封装
return getEngine().get(get, mapper, this::wrapSearcher);
}
// org.elasticsearch.index.shard.IndexShard#readAllowed
public void readAllowed() throws IllegalIndexShardStateException {
IndexShardState state = this.state; // one time volatile read
if (readAllowedStates.contains(state) == false) {
throw new IllegalIndexShardStateException(shardId, state, "operations only allowed when shard state is one of " +
readAllowedStates.toString());
}
}
// org.elasticsearch.index.shard.IndexShard#getEngine
Engine getEngine() {
Engine engine = getEngineOrNull();
if (engine == null) {
throw new AlreadyClosedException("engine is closed");
}
return engine;
}
/**
* NOTE: returns null if engine is not yet started (e.g. recovery phase 1, copying over index files, is still running), or if engine is
* closed.
*/
protected Engine getEngineOrNull() {
return this.currentEngineReference.get();
} private Engine.Searcher wrapSearcher(Engine.Searcher searcher) {
assert ElasticsearchDirectoryReader.unwrap(searcher.getDirectoryReader())
!= null : "DirectoryReader must be an instance or ElasticsearchDirectoryReader";
boolean success = false;
try {
final Engine.Searcher newSearcher = readerWrapper == null ? searcher : wrapSearcher(searcher, readerWrapper);
assert newSearcher != null;
success = true;
return newSearcher;
} catch (IOException ex) {
throw new ElasticsearchException("failed to wrap searcher", ex);
} finally {
if (success == false) {
Releasables.close(success, searcher);
}
}
} // org.elasticsearch.index.engine.InternalEngine#get
@Override
public GetResult get(Get get, DocumentMapper mapper, Function<Engine.Searcher, Engine.Searcher> searcherWrapper) {
assert Objects.equals(get.uid().field(), IdFieldMapper.NAME) : get.uid().field();
// 使用 ReentrantReadWriteLock 实现并发锁
try (ReleasableLock ignored = readLock.acquire()) {
// 确保未close
ensureOpen();
if (get.realtime()) {
final VersionValue versionValue;
try (Releasable ignore = versionMap.acquireLock(get.uid().bytes())) {
// we need to lock here to access the version map to do this truly in RT
versionValue = getVersionFromMap(get.uid().bytes());
}
// 版本号为空,以下大片逻辑就不走了
if (versionValue != null) {
if (versionValue.isDelete()) {
return GetResult.NOT_EXISTS;
}
if (get.versionType().isVersionConflictForReads(versionValue.version, get.version())) {
throw new VersionConflictEngineException(shardId, get.id(),
get.versionType().explainConflictForReads(versionValue.version, get.version()));
}
if (get.getIfSeqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO && (
get.getIfSeqNo() != versionValue.seqNo || get.getIfPrimaryTerm() != versionValue.term
)) {
throw new VersionConflictEngineException(shardId, get.id(),
get.getIfSeqNo(), get.getIfPrimaryTerm(), versionValue.seqNo, versionValue.term);
}
if (get.isReadFromTranslog()) {
// this is only used for updates - API _GET calls will always read form a reader for consistency
// the update call doesn't need the consistency since it's source only + _parent but parent can go away in 7.0
if (versionValue.getLocation() != null) {
try {
final Translog.Operation operation = translog.readOperation(versionValue.getLocation());
if (operation != null) {
return getFromTranslog(get, (Translog.Index) operation, mapper, searcherWrapper);
}
} catch (IOException e) {
maybeFailEngine("realtime_get", e); // lets check if the translog has failed with a tragic event
throw new EngineException(shardId, "failed to read operation from translog", e);
}
} else {
trackTranslogLocation.set(true);
}
}
assert versionValue.seqNo >= 0 : versionValue;
refreshIfNeeded("realtime_get", versionValue.seqNo);
}
return getFromSearcher(get, acquireSearcher("realtime_get", SearcherScope.INTERNAL, searcherWrapper));
} else {
// we expose what has been externally expose in a point in time snapshot via an explicit refresh
return getFromSearcher(get, acquireSearcher("get", SearcherScope.EXTERNAL, searcherWrapper));
}
}
}
// org.elasticsearch.index.engine.Engine#ensureOpen()
protected final void ensureOpen() {
ensureOpen(null);
}
protected final void ensureOpen(Exception suppressed) {
if (isClosed.get()) {
AlreadyClosedException ace = new AlreadyClosedException(shardId + " engine is closed", failedEngine.get());
if (suppressed != null) {
ace.addSuppressed(suppressed);
}
throw ace;
}
}
// org.elasticsearch.index.engine.LiveVersionMap#acquireLock
/**
* Acquires a releaseable lock for the given uId. All *UnderLock methods require
* this lock to be hold by the caller otherwise the visibility guarantees of this version
* map are broken. We assert on this lock to be hold when calling these methods.
* @see KeyedLock
*/
Releasable acquireLock(BytesRef uid) {
return keyedLock.acquire(uid);
}
// org.elasticsearch.common.util.concurrent.KeyedLock#acquire
/**
* Acquires a lock for the given key. The key is compared by it's equals method not by object identity. The lock can be acquired
* by the same thread multiple times. The lock is released by closing the returned {@link Releasable}.
*/
public Releasable acquire(T key) {
while (true) {
KeyLock perNodeLock = map.get(key);
if (perNodeLock == null) {
ReleasableLock newLock = tryCreateNewLock(key);
if (newLock != null) {
return newLock;
}
} else {
assert perNodeLock != null;
int i = perNodeLock.count.get();
// 最终基于 ReentrantLock 实现锁, KeyLock 实现了计数
if (i > 0 && perNodeLock.count.compareAndSet(i, i + 1)) {
perNodeLock.lock();
return new ReleasableLock(key, perNodeLock);
}
}
}
} // org.elasticsearch.common.util.concurrent.KeyedLock#tryCreateNewLock
private ReleasableLock tryCreateNewLock(T key) {
// KeyLock extends ReentrantLock
KeyLock newLock = new KeyLock(fair);
newLock.lock();
KeyLock keyLock = map.putIfAbsent(key, newLock);
if (keyLock == null) {
return new ReleasableLock(key, newLock);
}
return null;
}
// org.elasticsearch.index.engine.InternalEngine#getVersionFromMap
private VersionValue getVersionFromMap(BytesRef id) {
if (versionMap.isUnsafe()) {
synchronized (versionMap) {
// we are switching from an unsafe map to a safe map. This might happen concurrently
// but we only need to do this once since the last operation per ID is to add to the version
// map so once we pass this point we can safely lookup from the version map.
if (versionMap.isUnsafe()) {
refresh("unsafe_version_map", SearcherScope.INTERNAL, true);
}
versionMap.enforceSafeAccess();
}
}
return versionMap.getUnderLock(id);
}
// org.elasticsearch.index.engine.LiveVersionMap#getUnderLock(org.apache.lucene.util.BytesRef)
/**
* Returns the live version (add or delete) for this uid.
*/
VersionValue getUnderLock(final BytesRef uid) {
return getUnderLock(uid, maps);
} private VersionValue getUnderLock(final BytesRef uid, Maps currentMaps) {
assert assertKeyedLockHeldByCurrentThread(uid);
// First try to get the "live" value:
VersionValue value = currentMaps.current.get(uid);
if (value != null) {
return value;
} value = currentMaps.old.get(uid);
if (value != null) {
return value;
}
// 返回 null
return tombstones.get(uid);
}
// org.elasticsearch.index.engine.Engine#acquireSearcher
public Searcher acquireSearcher(String source, SearcherScope scope, Function<Searcher, Searcher> wrapper) throws EngineException {
SearcherSupplier releasable = null;
try {
// 获取 searcher , soure=realtime_get
SearcherSupplier reader = releasable = acquireSearcherSupplier(wrapper, scope);
Searcher searcher = reader.acquireSearcher(source);
releasable = null;
return new Searcher(source, searcher.getDirectoryReader(), searcher.getSimilarity(),
searcher.getQueryCache(), searcher.getQueryCachingPolicy(), () -> Releasables.close(searcher, reader));
} finally {
Releasables.close(releasable);
}
}
// org.elasticsearch.index.engine.Engine#acquireSearcherSupplier
/**
* Acquires a point-in-time reader that can be used to create {@link Engine.Searcher}s on demand.
*/
public SearcherSupplier acquireSearcherSupplier(Function<Searcher, Searcher> wrapper, SearcherScope scope) throws EngineException {
/* Acquire order here is store -> manager since we need
* to make sure that the store is not closed before
* the searcher is acquired. */
if (store.tryIncRef() == false) {
throw new AlreadyClosedException(shardId + " store is closed", failedEngine.get());
}
Releasable releasable = store::decRef;
try {
// 引用计数+1
ReferenceManager<ElasticsearchDirectoryReader> referenceManager = getReferenceManager(scope);
ElasticsearchDirectoryReader acquire = referenceManager.acquire();
SearcherSupplier reader = new SearcherSupplier(wrapper) {
@Override
public Searcher acquireSearcherInternal(String source) {
assert assertSearcherIsWarmedUp(source, scope);
return new Searcher(source, acquire, engineConfig.getSimilarity(), engineConfig.getQueryCache(),
engineConfig.getQueryCachingPolicy(), () -> {});
} @Override
protected void doClose() {
try {
referenceManager.release(acquire);
} catch (IOException e) {
throw new UncheckedIOException("failed to close", e);
} catch (AlreadyClosedException e) {
// This means there's a bug somewhere: don't suppress it
throw new AssertionError(e);
} finally {
store.decRef();
}
}
};
releasable = null; // success - hand over the reference to the engine reader
return reader;
} catch (AlreadyClosedException ex) {
throw ex;
} catch (Exception ex) {
maybeFailEngine("acquire_reader", ex);
ensureOpen(ex); // throw EngineCloseException here if we are already closed
logger.error(() -> new ParameterizedMessage("failed to acquire reader"), ex);
throw new EngineException(shardId, "failed to acquire reader", ex);
} finally {
Releasables.close(releasable);
}
}
// org.elasticsearch.index.engine.Engine.SearcherSupplier#acquireSearcher
public final Searcher acquireSearcher(String source) {
if (released.get()) {
throw new AlreadyClosedException("SearcherSupplier was closed");
}
// 新建 searcher
final Searcher searcher = acquireSearcherInternal(source);
return CAN_MATCH_SEARCH_SOURCE.equals(source) ? searcher : wrapper.apply(searcher);
}
// org.elasticsearch.index.engine.Engine.Searcher#Searcher
public Searcher(String source, IndexReader reader,
Similarity similarity, QueryCache queryCache, QueryCachingPolicy queryCachingPolicy,
Closeable onClose) {
super(reader);
setSimilarity(similarity);
setQueryCache(queryCache);
setQueryCachingPolicy(queryCachingPolicy);
this.source = source;
this.onClose = onClose;
}
// org.elasticsearch.index.shard.IndexShard#wrapSearcher
private Engine.Searcher wrapSearcher(Engine.Searcher searcher) {
assert ElasticsearchDirectoryReader.unwrap(searcher.getDirectoryReader())
!= null : "DirectoryReader must be an instance or ElasticsearchDirectoryReader";
boolean success = false;
try {
final Engine.Searcher newSearcher = readerWrapper == null ? searcher : wrapSearcher(searcher, readerWrapper);
assert newSearcher != null;
success = true;
return newSearcher;
} catch (IOException ex) {
throw new ElasticsearchException("failed to wrap searcher", ex);
} finally {
if (success == false) {
Releasables.close(success, searcher);
}
}
}
// org.elasticsearch.index.shard.IndexShard#wrapSearcher
static Engine.Searcher wrapSearcher(Engine.Searcher engineSearcher,
CheckedFunction<DirectoryReader, DirectoryReader, IOException> readerWrapper) throws IOException {
assert readerWrapper != null;
final ElasticsearchDirectoryReader elasticsearchDirectoryReader =
ElasticsearchDirectoryReader.getElasticsearchDirectoryReader(engineSearcher.getDirectoryReader());
if (elasticsearchDirectoryReader == null) {
throw new IllegalStateException("Can't wrap non elasticsearch directory reader");
}
NonClosingReaderWrapper nonClosingReaderWrapper = new NonClosingReaderWrapper(engineSearcher.getDirectoryReader());
DirectoryReader reader = readerWrapper.apply(nonClosingReaderWrapper);
if (reader != nonClosingReaderWrapper) {
if (reader.getReaderCacheHelper() != elasticsearchDirectoryReader.getReaderCacheHelper()) {
throw new IllegalStateException("wrapped directory reader doesn't delegate IndexReader#getCoreCacheKey," +
" wrappers must override this method and delegate to the original readers core cache key. Wrapped readers can't be " +
"used as cache keys since their are used only per request which would lead to subtle bugs");
}
if (ElasticsearchDirectoryReader.getElasticsearchDirectoryReader(reader) != elasticsearchDirectoryReader) {
// prevent that somebody wraps with a non-filter reader
throw new IllegalStateException("wrapped directory reader hides actual ElasticsearchDirectoryReader but shouldn't");
}
} if (reader == nonClosingReaderWrapper) {
return engineSearcher;
} else {
// we close the reader to make sure wrappers can release resources if needed....
// our NonClosingReaderWrapper makes sure that our reader is not closed
return new Engine.Searcher(engineSearcher.source(), reader,
engineSearcher.getSimilarity(), engineSearcher.getQueryCache(), engineSearcher.getQueryCachingPolicy(),
() -> IOUtils.close(reader, // this will close the wrappers excluding the NonClosingReaderWrapper
engineSearcher)); // this will run the closeable on the wrapped engine reader
}
}
获取到searcher实例后,再由其进行get操作。
// org.elasticsearch.index.engine.Engine#getFromSearcher
protected final GetResult getFromSearcher(Get get, Engine.Searcher searcher) throws EngineException {
final DocIdAndVersion docIdAndVersion;
try {
// 读取docId, version, 其实就是核心的读数据实现之一
docIdAndVersion = VersionsAndSeqNoResolver.loadDocIdAndVersion(searcher.getIndexReader(), get.uid(), true);
} catch (Exception e) {
Releasables.closeWhileHandlingException(searcher);
//TODO: A better exception goes here
throw new EngineException(shardId, "Couldn't resolve version", e);
} if (docIdAndVersion != null) {
// 检测版本是否冲突,如有则抛出异常
if (get.versionType().isVersionConflictForReads(docIdAndVersion.version, get.version())) {
Releasables.close(searcher);
throw new VersionConflictEngineException(shardId, get.id(),
get.versionType().explainConflictForReads(docIdAndVersion.version, get.version()));
}
if (get.getIfSeqNo() != SequenceNumbers.UNASSIGNED_SEQ_NO && (
get.getIfSeqNo() != docIdAndVersion.seqNo || get.getIfPrimaryTerm() != docIdAndVersion.primaryTerm
)) {
Releasables.close(searcher);
throw new VersionConflictEngineException(shardId, get.id(),
get.getIfSeqNo(), get.getIfPrimaryTerm(), docIdAndVersion.seqNo, docIdAndVersion.primaryTerm);
}
} if (docIdAndVersion != null) {
// don't release the searcher on this path, it is the
// responsibility of the caller to call GetResult.release
return new GetResult(searcher, docIdAndVersion, false);
} else {
Releasables.close(searcher);
return GetResult.NOT_EXISTS;
}
}
// org.elasticsearch.common.lucene.uid.VersionsAndSeqNoResolver#loadDocIdAndVersion
/**
* Load the internal doc ID and version for the uid from the reader, returning<ul>
* <li>null if the uid wasn't found,
* <li>a doc ID and a version otherwise
* </ul>
*/
public static DocIdAndVersion loadDocIdAndVersion(IndexReader reader, Term term, boolean loadSeqNo) throws IOException {
// feild: _id
PerThreadIDVersionAndSeqNoLookup[] lookups = getLookupState(reader, term.field());
List<LeafReaderContext> leaves = reader.leaves();
// iterate backwards to optimize for the frequently updated documents
// which are likely to be in the last segments
for (int i = leaves.size() - 1; i >= 0; i--) {
final LeafReaderContext leaf = leaves.get(i);
PerThreadIDVersionAndSeqNoLookup lookup = lookups[leaf.ord];
DocIdAndVersion result = lookup.lookupVersion(term.bytes(), loadSeqNo, leaf);
if (result != null) {
return result;
}
}
return null;
}
// org.elasticsearch.common.lucene.uid.VersionsAndSeqNoResolver#getLookupState
private static PerThreadIDVersionAndSeqNoLookup[] getLookupState(IndexReader reader, String uidField) throws IOException {
// We cache on the top level
// This means cache entries have a shorter lifetime, maybe as low as 1s with the
// default refresh interval and a steady indexing rate, but on the other hand it
// proved to be cheaper than having to perform a CHM and a TL get for every segment.
// See https://github.com/elastic/elasticsearch/pull/19856.
IndexReader.CacheHelper cacheHelper = reader.getReaderCacheHelper();
CloseableThreadLocal<PerThreadIDVersionAndSeqNoLookup[]> ctl = lookupStates.get(cacheHelper.getKey());
if (ctl == null) {
// First time we are seeing this reader's core; make a new CTL:
ctl = new CloseableThreadLocal<>();
CloseableThreadLocal<PerThreadIDVersionAndSeqNoLookup[]> other = lookupStates.putIfAbsent(cacheHelper.getKey(), ctl);
if (other == null) {
// Our CTL won, we must remove it when the reader is closed:
cacheHelper.addClosedListener(removeLookupState);
} else {
// Another thread beat us to it: just use their CTL:
ctl = other;
}
} PerThreadIDVersionAndSeqNoLookup[] lookupState = ctl.get();
if (lookupState == null) {
lookupState = new PerThreadIDVersionAndSeqNoLookup[reader.leaves().size()];
for (LeafReaderContext leaf : reader.leaves()) {
lookupState[leaf.ord] = new PerThreadIDVersionAndSeqNoLookup(leaf.reader(), uidField);
}
ctl.set(lookupState);
} if (lookupState.length != reader.leaves().size()) {
throw new AssertionError("Mismatched numbers of leaves: " + lookupState.length + " != " + reader.leaves().size());
} if (lookupState.length > 0 && Objects.equals(lookupState[0].uidField, uidField) == false) {
throw new AssertionError("Index does not consistently use the same uid field: ["
+ uidField + "] != [" + lookupState[0].uidField + "]");
} return lookupState;
}
// org.apache.lucene.index.IndexReader#leaves
/**
* Returns the reader's leaves, or itself if this reader is atomic.
* This is a convenience method calling {@code this.getContext().leaves()}.
* @see IndexReaderContext#leaves()
*/
public final List<LeafReaderContext> leaves() {
return getContext().leaves();
}
// org.apache.lucene.index.CompositeReader#getContext
@Override
public final CompositeReaderContext getContext() {
ensureOpen();
// lazy init without thread safety for perf reasons: Building the readerContext twice does not hurt!
if (readerContext == null) {
assert getSequentialSubReaders() != null;
readerContext = CompositeReaderContext.create(this);
}
return readerContext;
}
// org.apache.lucene.index.CompositeReaderContext#leaves
@Override
public List<LeafReaderContext> leaves() throws UnsupportedOperationException {
if (!isTopLevel)
throw new UnsupportedOperationException("This is not a top-level context.");
assert leaves != null;
return leaves;
}
// org.elasticsearch.common.lucene.uid.PerThreadIDVersionAndSeqNoLookup#lookupVersion
/** Return null if id is not found.
* We pass the {@link LeafReaderContext} as an argument so that things
* still work with reader wrappers that hide some documents while still
* using the same cache key. Otherwise we'd have to disable caching
* entirely for these readers.
*/
public DocIdAndVersion lookupVersion(BytesRef id, boolean loadSeqNo, LeafReaderContext context)
throws IOException {
assert context.reader().getCoreCacheHelper().getKey().equals(readerKey) :
"context's reader is not the same as the reader class was initialized on.";
// docId 是个整型?
int docID = getDocID(id, context); if (docID != DocIdSetIterator.NO_MORE_DOCS) {
final long seqNo;
final long term;
if (loadSeqNo) {
seqNo = readNumericDocValues(context.reader(), SeqNoFieldMapper.NAME, docID);
term = readNumericDocValues(context.reader(), SeqNoFieldMapper.PRIMARY_TERM_NAME, docID);
} else {
seqNo = UNASSIGNED_SEQ_NO;
term = UNASSIGNED_PRIMARY_TERM;
}
final long version = readNumericDocValues(context.reader(), VersionFieldMapper.NAME, docID);
return new DocIdAndVersion(docID, version, seqNo, term, context.reader(), context.docBase);
} else {
return null;
}
}
// org.elasticsearch.common.lucene.uid.PerThreadIDVersionAndSeqNoLookup#getDocID
/**
* returns the internal lucene doc id for the given id bytes.
* {@link DocIdSetIterator#NO_MORE_DOCS} is returned if not found
* */
private int getDocID(BytesRef id, LeafReaderContext context) throws IOException {
// termsEnum can possibly be null here if this leaf contains only no-ops.
// lucene 接口: seekExact
if (termsEnum != null && termsEnum.seekExact(id)) {
final Bits liveDocs = context.reader().getLiveDocs();
int docID = DocIdSetIterator.NO_MORE_DOCS;
// there may be more than one matching docID, in the case of nested docs, so we want the last one:
docsEnum = termsEnum.postings(docsEnum, 0);
for (int d = docsEnum.nextDoc(); d != DocIdSetIterator.NO_MORE_DOCS; d = docsEnum.nextDoc()) {
if (liveDocs != null && liveDocs.get(d) == false) {
continue;
}
docID = d;
}
return docID;
} else {
return DocIdSetIterator.NO_MORE_DOCS;
}
} // org.elasticsearch.common.lucene.uid.PerThreadIDVersionAndSeqNoLookup#readNumericDocValues
private static long readNumericDocValues(LeafReader reader, String field, int docId) throws IOException {
final NumericDocValues dv = reader.getNumericDocValues(field);
if (dv == null || dv.advanceExact(docId) == false) {
assert false : "document [" + docId + "] does not have docValues for [" + field + "]";
throw new IllegalStateException("document [" + docId + "] does not have docValues for [" + field + "]");
}
return dv.longValue();
}
// docId 包装
// org.elasticsearch.common.lucene.uid.VersionsAndSeqNoResolver.DocIdAndVersion
/** Wraps an {@link LeafReaderContext}, a doc ID <b>relative to the context doc base</b> and a version. */
public static class DocIdAndVersion {
public final int docId;
public final long version;
public final long seqNo;
public final long primaryTerm;
public final LeafReader reader;
public final int docBase; public DocIdAndVersion(int docId, long version, long seqNo, long primaryTerm, LeafReader reader, int docBase) {
this.docId = docId;
this.version = version;
this.seqNo = seqNo;
this.primaryTerm = primaryTerm;
this.reader = reader;
this.docBase = docBase;
}
}
// org.elasticsearch.index.VersionType#isVersionConflictForReads
@Override
public boolean isVersionConflictForReads(long currentVersion, long expectedVersion) {
return isVersionConflict(currentVersion, expectedVersion, false);
}
private boolean isVersionConflict(long currentVersion, long expectedVersion, boolean deleted) {
if (expectedVersion == Versions.MATCH_ANY) {
return false;
}
if (expectedVersion == Versions.MATCH_DELETED) {
return deleted == false;
}
if (currentVersion != expectedVersion) {
return true;
}
return false;
}
// 最后,构造 GetResult 返回
// org.elasticsearch.index.engine.Engine.GetResult#GetResult
public GetResult(Engine.Searcher searcher, DocIdAndVersion docIdAndVersion, boolean fromTranslog) {
this(true, docIdAndVersion.version, docIdAndVersion, searcher, fromTranslog);
} private GetResult(boolean exists, long version, DocIdAndVersion docIdAndVersion, Engine.Searcher searcher, boolean fromTranslog) {
this.exists = exists;
this.version = version;
this.docIdAndVersion = docIdAndVersion;
this.searcher = searcher;
this.fromTranslog = fromTranslog;
assert fromTranslog == false || searcher.getIndexReader() instanceof TranslogLeafReader;
}
前面根据id调用 lucene 接口获取到了docId, 接下来根据docId查询doc详情:
// org.elasticsearch.index.get.ShardGetService#innerGetLoadFromStoredFields
private GetResult innerGetLoadFromStoredFields(String type, String id, String[] storedFields, FetchSourceContext fetchSourceContext,
Engine.GetResult get, MapperService mapperService) {
assert get.exists() : "method should only be called if document could be retrieved"; // check first if stored fields to be loaded don't contain an object field
DocumentMapper docMapper = mapperService.documentMapper();
if (storedFields != null) {
for (String field : storedFields) {
Mapper fieldMapper = docMapper.mappers().getMapper(field);
if (fieldMapper == null) {
if (docMapper.mappers().objectMappers().get(field) != null) {
// Only fail if we know it is a object field, missing paths / fields shouldn't fail.
throw new IllegalArgumentException("field [" + field + "] isn't a leaf field");
}
}
}
} Map<String, DocumentField> documentFields = null;
Map<String, DocumentField> metadataFields = null;
BytesReference source = null;
DocIdAndVersion docIdAndVersion = get.docIdAndVersion();
// force fetching source if we read from translog and need to recreate stored fields
boolean forceSourceForComputingTranslogStoredFields = get.isFromTranslog() && storedFields != null &&
Stream.of(storedFields).anyMatch(f -> TranslogLeafReader.ALL_FIELD_NAMES.contains(f) == false);
// 构造字段访问器
FieldsVisitor fieldVisitor = buildFieldsVisitors(storedFields,
forceSourceForComputingTranslogStoredFields ? FetchSourceContext.FETCH_SOURCE : fetchSourceContext);
if (fieldVisitor != null) {
try {
// 一个字段读取
docIdAndVersion.reader.document(docIdAndVersion.docId, fieldVisitor);
} catch (IOException e) {
throw new ElasticsearchException("Failed to get type [" + type + "] and id [" + id + "]", e);
}
source = fieldVisitor.source(); // in case we read from translog, some extra steps are needed to make _source consistent and to load stored fields
if (get.isFromTranslog()) {
// Fast path: if only asked for the source or stored fields that have been already provided by TranslogLeafReader,
// just make source consistent by reapplying source filters from mapping (possibly also nulling the source)
if (forceSourceForComputingTranslogStoredFields == false) {
try {
source = indexShard.mapperService().documentMapper().sourceMapper().applyFilters(source, null);
} catch (IOException e) {
throw new ElasticsearchException("Failed to reapply filters for [" + id + "] after reading from translog", e);
}
} else {
// Slow path: recreate stored fields from original source
assert source != null : "original source in translog must exist";
SourceToParse sourceToParse = new SourceToParse(shardId.getIndexName(), type, id, source,
XContentHelper.xContentType(source), fieldVisitor.routing());
ParsedDocument doc = indexShard.mapperService().documentMapper().parse(sourceToParse);
assert doc.dynamicMappingsUpdate() == null : "mapping updates should not be required on already-indexed doc";
// update special fields
doc.updateSeqID(docIdAndVersion.seqNo, docIdAndVersion.primaryTerm);
doc.version().setLongValue(docIdAndVersion.version); // retrieve stored fields from parsed doc
fieldVisitor = buildFieldsVisitors(storedFields, fetchSourceContext);
for (IndexableField indexableField : doc.rootDoc().getFields()) {
IndexableFieldType fieldType = indexableField.fieldType();
if (fieldType.stored()) {
FieldInfo fieldInfo = new FieldInfo(indexableField.name(), 0, false, false, false, IndexOptions.NONE,
DocValuesType.NONE, -1, Collections.emptyMap(), 0, 0, 0, false);
StoredFieldVisitor.Status status = fieldVisitor.needsField(fieldInfo);
if (status == StoredFieldVisitor.Status.YES) {
if (indexableField.numericValue() != null) {
fieldVisitor.objectField(fieldInfo, indexableField.numericValue());
} else if (indexableField.binaryValue() != null) {
fieldVisitor.binaryField(fieldInfo, indexableField.binaryValue());
} else if (indexableField.stringValue() != null) {
fieldVisitor.objectField(fieldInfo, indexableField.stringValue());
}
} else if (status == StoredFieldVisitor.Status.STOP) {
break;
}
}
}
// retrieve source (with possible transformations, e.g. source filters
source = fieldVisitor.source();
}
} // put stored fields into result objects
if (!fieldVisitor.fields().isEmpty()) {
fieldVisitor.postProcess(mapperService::fieldType,
mapperService.documentMapper() == null ? null : mapperService.documentMapper().type());
documentFields = new HashMap<>();
metadataFields = new HashMap<>();
for (Map.Entry<String, List<Object>> entry : fieldVisitor.fields().entrySet()) {
if (mapperService.isMetadataField(entry.getKey())) {
metadataFields.put(entry.getKey(), new DocumentField(entry.getKey(), entry.getValue()));
} else {
documentFields.put(entry.getKey(), new DocumentField(entry.getKey(), entry.getValue()));
}
}
}
} if (source != null) {
// apply request-level source filtering
if (fetchSourceContext.fetchSource() == false) {
source = null;
} else if (fetchSourceContext.includes().length > 0 || fetchSourceContext.excludes().length > 0) {
Map<String, Object> sourceAsMap;
// TODO: The source might be parsed and available in the sourceLookup but that one uses unordered maps so different.
// Do we care?
Tuple<XContentType, Map<String, Object>> typeMapTuple = XContentHelper.convertToMap(source, true);
XContentType sourceContentType = typeMapTuple.v1();
sourceAsMap = typeMapTuple.v2();
sourceAsMap = XContentMapValues.filter(sourceAsMap, fetchSourceContext.includes(), fetchSourceContext.excludes());
try {
source = BytesReference.bytes(XContentFactory.contentBuilder(sourceContentType).map(sourceAsMap));
} catch (IOException e) {
throw new ElasticsearchException("Failed to get id [" + id + "] with includes/excludes set", e);
}
}
} if (!fetchSourceContext.fetchSource()) {
source = null;
} if (source != null && get.isFromTranslog()) {
// reapply source filters from mapping (possibly also nulling the source)
try {
source = docMapper.sourceMapper().applyFilters(source, null);
} catch (IOException e) {
throw new ElasticsearchException("Failed to reapply filters for [" + id + "] after reading from translog", e);
}
} if (source != null && (fetchSourceContext.includes().length > 0 || fetchSourceContext.excludes().length > 0)) {
Map<String, Object> sourceAsMap;
// TODO: The source might parsed and available in the sourceLookup but that one uses unordered maps so different. Do we care?
Tuple<XContentType, Map<String, Object>> typeMapTuple = XContentHelper.convertToMap(source, true);
XContentType sourceContentType = typeMapTuple.v1();
sourceAsMap = typeMapTuple.v2();
sourceAsMap = XContentMapValues.filter(sourceAsMap, fetchSourceContext.includes(), fetchSourceContext.excludes());
try {
source = BytesReference.bytes(XContentFactory.contentBuilder(sourceContentType).map(sourceAsMap));
} catch (IOException e) {
throw new ElasticsearchException("Failed to get type [" + type + "] and id [" + id + "] with includes/excludes set", e);
}
}
// 构造新的 GetResult 返回, source 就是最终查询的结果
return new GetResult(shardId.getIndexName(), type, id, get.docIdAndVersion().seqNo, get.docIdAndVersion().primaryTerm,
get.version(), get.exists(), source, documentFields, metadataFields);
} private static FieldsVisitor buildFieldsVisitors(String[] fields, FetchSourceContext fetchSourceContext) {
if (fields == null || fields.length == 0) {
return fetchSourceContext.fetchSource() ? new FieldsVisitor(true) : null;
} return new CustomFieldsVisitor(Sets.newHashSet(fields), fetchSourceContext.fetchSource());
}
最后,一点lucene的查找实现片段,供参考。
// 快速定位到指定id的文档位置,相当于索引定位
// org.apache.lucene.codecs.blocktree.SegmentTermsEnum#seekExact(org.apache.lucene.util.BytesRef)
@Override
public boolean seekExact(BytesRef target) throws IOException { if (fr.index == null) {
throw new IllegalStateException("terms index was not loaded");
} if (fr.size() > 0 && (target.compareTo(fr.getMin()) < 0 || target.compareTo(fr.getMax()) > 0)) {
return false;
} term.grow(1 + target.length); assert clearEOF(); // if (DEBUG) {
// System.out.println("\nBTTR.seekExact seg=" + fr.parent.segment + " target=" + fr.fieldInfo.name + ":" + brToString(target) + " current=" + brToString(term) + " (exists?=" + termExists + ") validIndexPrefix=" + validIndexPrefix);
// printSeekState(System.out);
// } FST.Arc<BytesRef> arc;
int targetUpto;
BytesRef output; targetBeforeCurrentLength = currentFrame.ord; if (currentFrame != staticFrame) { // We are already seek'd; find the common
// prefix of new seek term vs current term and
// re-use the corresponding seek state. For
// example, if app first seeks to foobar, then
// seeks to foobaz, we can re-use the seek state
// for the first 5 bytes. // if (DEBUG) {
// System.out.println(" re-use current seek state validIndexPrefix=" + validIndexPrefix);
// } arc = arcs[0];
assert arc.isFinal();
output = arc.output();
targetUpto = 0; SegmentTermsEnumFrame lastFrame = stack[0];
assert validIndexPrefix <= term.length(); final int targetLimit = Math.min(target.length, validIndexPrefix); int cmp = 0; // TODO: reverse vLong byte order for better FST
// prefix output sharing // First compare up to valid seek frames:
while (targetUpto < targetLimit) {
cmp = (term.byteAt(targetUpto)&0xFF) - (target.bytes[target.offset + targetUpto]&0xFF);
// if (DEBUG) {
// System.out.println(" cycle targetUpto=" + targetUpto + " (vs limit=" + targetLimit + ") cmp=" + cmp + " (targetLabel=" + (char) (target.bytes[target.offset + targetUpto]) + " vs termLabel=" + (char) (term.bytes[targetUpto]) + ")" + " arc.output=" + arc.output + " output=" + output);
// }
if (cmp != 0) {
break;
}
arc = arcs[1+targetUpto];
assert arc.label() == (target.bytes[target.offset + targetUpto] & 0xFF): "arc.label=" + (char) arc.label() + " targetLabel=" + (char) (target.bytes[target.offset + targetUpto] & 0xFF);
if (arc.output() != BlockTreeTermsReader.NO_OUTPUT) {
output = BlockTreeTermsReader.FST_OUTPUTS.add(output, arc.output());
}
if (arc.isFinal()) {
lastFrame = stack[1+lastFrame.ord];
}
targetUpto++;
} if (cmp == 0) {
final int targetUptoMid = targetUpto; // Second compare the rest of the term, but
// don't save arc/output/frame; we only do this
// to find out if the target term is before,
// equal or after the current term
final int targetLimit2 = Math.min(target.length, term.length());
while (targetUpto < targetLimit2) {
cmp = (term.byteAt(targetUpto)&0xFF) - (target.bytes[target.offset + targetUpto]&0xFF);
// if (DEBUG) {
// System.out.println(" cycle2 targetUpto=" + targetUpto + " (vs limit=" + targetLimit + ") cmp=" + cmp + " (targetLabel=" + (char) (target.bytes[target.offset + targetUpto]) + " vs termLabel=" + (char) (term.bytes[targetUpto]) + ")");
// }
if (cmp != 0) {
break;
}
targetUpto++;
} if (cmp == 0) {
cmp = term.length() - target.length;
}
targetUpto = targetUptoMid;
} if (cmp < 0) {
// Common case: target term is after current
// term, ie, app is seeking multiple terms
// in sorted order
// if (DEBUG) {
// System.out.println(" target is after current (shares prefixLen=" + targetUpto + "); frame.ord=" + lastFrame.ord);
// }
currentFrame = lastFrame; } else if (cmp > 0) {
// Uncommon case: target term
// is before current term; this means we can
// keep the currentFrame but we must rewind it
// (so we scan from the start)
targetBeforeCurrentLength = lastFrame.ord;
// if (DEBUG) {
// System.out.println(" target is before current (shares prefixLen=" + targetUpto + "); rewind frame ord=" + lastFrame.ord);
// }
currentFrame = lastFrame;
currentFrame.rewind();
} else {
// Target is exactly the same as current term
assert term.length() == target.length;
if (termExists) {
// if (DEBUG) {
// System.out.println(" target is same as current; return true");
// }
return true;
} else {
// if (DEBUG) {
// System.out.println(" target is same as current but term doesn't exist");
// }
}
//validIndexPrefix = currentFrame.depth;
//term.length = target.length;
//return termExists;
} } else { targetBeforeCurrentLength = -1;
arc = fr.index.getFirstArc(arcs[0]); // Empty string prefix must have an output (block) in the index!
assert arc.isFinal();
assert arc.output() != null; // if (DEBUG) {
// System.out.println(" no seek state; push root frame");
// } output = arc.output(); currentFrame = staticFrame; //term.length = 0;
targetUpto = 0;
currentFrame = pushFrame(arc, BlockTreeTermsReader.FST_OUTPUTS.add(output, arc.nextFinalOutput()), 0);
} // if (DEBUG) {
// System.out.println(" start index loop targetUpto=" + targetUpto + " output=" + output + " currentFrame.ord=" + currentFrame.ord + " targetBeforeCurrentLength=" + targetBeforeCurrentLength);
// } // We are done sharing the common prefix with the incoming target and where we are currently seek'd; now continue walking the index:
while (targetUpto < target.length) { final int targetLabel = target.bytes[target.offset + targetUpto] & 0xFF; final FST.Arc<BytesRef> nextArc = fr.index.findTargetArc(targetLabel, arc, getArc(1+targetUpto), fstReader); if (nextArc == null) { // Index is exhausted
// if (DEBUG) {
// System.out.println(" index: index exhausted label=" + ((char) targetLabel) + " " + toHex(targetLabel));
// } validIndexPrefix = currentFrame.prefix;
//validIndexPrefix = targetUpto; currentFrame.scanToFloorFrame(target); if (!currentFrame.hasTerms) {
termExists = false;
term.setByteAt(targetUpto, (byte) targetLabel);
term.setLength(1+targetUpto);
// if (DEBUG) {
// System.out.println(" FAST NOT_FOUND term=" + brToString(term));
// }
return false;
} currentFrame.loadBlock(); final SeekStatus result = currentFrame.scanToTerm(target, true);
if (result == SeekStatus.FOUND) {
// if (DEBUG) {
// System.out.println(" return FOUND term=" + term.utf8ToString() + " " + term);
// }
return true;
} else {
// if (DEBUG) {
// System.out.println(" got " + result + "; return NOT_FOUND term=" + brToString(term));
// }
return false;
}
} else {
// Follow this arc
arc = nextArc;
term.setByteAt(targetUpto, (byte) targetLabel);
// Aggregate output as we go:
assert arc.output() != null;
if (arc.output() != BlockTreeTermsReader.NO_OUTPUT) {
output = BlockTreeTermsReader.FST_OUTPUTS.add(output, arc.output());
} // if (DEBUG) {
// System.out.println(" index: follow label=" + toHex(target.bytes[target.offset + targetUpto]&0xff) + " arc.output=" + arc.output + " arc.nfo=" + arc.nextFinalOutput);
// }
targetUpto++; if (arc.isFinal()) {
//if (DEBUG) System.out.println(" arc is final!");
currentFrame = pushFrame(arc, BlockTreeTermsReader.FST_OUTPUTS.add(output, arc.nextFinalOutput()), targetUpto);
//if (DEBUG) System.out.println(" curFrame.ord=" + currentFrame.ord + " hasTerms=" + currentFrame.hasTerms);
}
}
} //validIndexPrefix = targetUpto;
validIndexPrefix = currentFrame.prefix; currentFrame.scanToFloorFrame(target); // Target term is entirely contained in the index:
if (!currentFrame.hasTerms) {
termExists = false;
term.setLength(targetUpto);
// if (DEBUG) {
// System.out.println(" FAST NOT_FOUND term=" + brToString(term));
// }
return false;
} currentFrame.loadBlock(); final SeekStatus result = currentFrame.scanToTerm(target, true);
if (result == SeekStatus.FOUND) {
// if (DEBUG) {
// System.out.println(" return FOUND term=" + term.utf8ToString() + " " + term);
// }
return true;
} else {
// if (DEBUG) {
// System.out.println(" got result " + result + "; return NOT_FOUND term=" + term.utf8ToString());
// } return false;
}
}
// org.apache.lucene.codecs.blocktree.SegmentTermsEnum#postings
@Override
public PostingsEnum postings(PostingsEnum reuse, int flags) throws IOException {
assert !eof;
//if (DEBUG) {
//System.out.println("BTTR.docs seg=" + segment);
//}
currentFrame.decodeMetaData();
//if (DEBUG) {
//System.out.println(" state=" + currentFrame.state);
//}
return fr.parent.postingsReader.postings(fr.fieldInfo, currentFrame.state, reuse, flags);
}
// 根据docId 获取文档的详情信息
// org.apache.lucene.index.FilterLeafReader#document
@Override
public void document(int docID, StoredFieldVisitor visitor) throws IOException {
ensureOpen();
in.document(docID, visitor);
}
// org.apache.lucene.index.CodecReader#document
@Override
public final void document(int docID, StoredFieldVisitor visitor) throws IOException {
checkBounds(docID);
getFieldsReader().visitDocument(docID, visitor);
}
// org.apache.lucene.codecs.compressing.CompressingStoredFieldsReader#visitDocument
@Override
public void visitDocument(int docID, StoredFieldVisitor visitor)
throws IOException { final SerializedDocument doc = document(docID); for (int fieldIDX = 0; fieldIDX < doc.numStoredFields; fieldIDX++) {
final long infoAndBits = doc.in.readVLong();
final int fieldNumber = (int) (infoAndBits >>> TYPE_BITS);
final FieldInfo fieldInfo = fieldInfos.fieldInfo(fieldNumber); final int bits = (int) (infoAndBits & TYPE_MASK);
assert bits <= NUMERIC_DOUBLE: "bits=" + Integer.toHexString(bits); switch(visitor.needsField(fieldInfo)) {
case YES:
readField(doc.in, visitor, fieldInfo, bits);
break;
case NO:
if (fieldIDX == doc.numStoredFields - 1) {// don't skipField on last field value; treat like STOP
return;
}
skipField(doc.in, bits);
break;
case STOP:
return;
}
}
}
// org.apache.lucene.codecs.compressing.CompressingStoredFieldsReader#document
SerializedDocument document(int docID) throws IOException {
// 定位文档位置,取出文档。。。
if (state.contains(docID) == false) {
fieldsStream.seek(indexReader.getStartPointer(docID));
state.reset(docID);
}
assert state.contains(docID);
return state.document(docID);
}
// org.apache.lucene.codecs.compressing.FieldsIndexReader#getStartPointer
@Override
long getStartPointer(int docID) {
FutureObjects.checkIndex(docID, maxDoc);
long blockIndex = docs.binarySearch(0, numChunks, docID);
if (blockIndex < 0) {
blockIndex = -2 - blockIndex;
}
return startPointers.get(blockIndex);
}
// org.apache.lucene.codecs.compressing.CompressingStoredFieldsReader.BlockState#document
/**
* Get the serialized representation of the given docID. This docID has
* to be contained in the current block.
*/
SerializedDocument document(int docID) throws IOException {
if (contains(docID) == false) {
throw new IllegalArgumentException();
} final int index = docID - docBase;
final int offset = Math.toIntExact(offsets[index]);
final int length = Math.toIntExact(offsets[index+1]) - offset;
final int totalLength = Math.toIntExact(offsets[chunkDocs]);
final int numStoredFields = Math.toIntExact(this.numStoredFields[index]); final BytesRef bytes;
if (merging) {
bytes = this.bytes;
} else {
bytes = new BytesRef();
} final DataInput documentInput;
if (length == 0) {
// empty
documentInput = new ByteArrayDataInput();
} else if (merging) {
// already decompressed
documentInput = new ByteArrayDataInput(bytes.bytes, bytes.offset + offset, length);
} else if (sliced) {
fieldsStream.seek(startPointer);
decompressor.decompress(fieldsStream, chunkSize, offset, Math.min(length, chunkSize - offset), bytes);
documentInput = new DataInput() { int decompressed = bytes.length; void fillBuffer() throws IOException {
assert decompressed <= length;
if (decompressed == length) {
throw new EOFException();
}
final int toDecompress = Math.min(length - decompressed, chunkSize);
decompressor.decompress(fieldsStream, toDecompress, 0, toDecompress, bytes);
decompressed += toDecompress;
} @Override
public byte readByte() throws IOException {
if (bytes.length == 0) {
fillBuffer();
}
--bytes.length;
return bytes.bytes[bytes.offset++];
} @Override
public void readBytes(byte[] b, int offset, int len) throws IOException {
while (len > bytes.length) {
System.arraycopy(bytes.bytes, bytes.offset, b, offset, bytes.length);
len -= bytes.length;
offset += bytes.length;
fillBuffer();
}
System.arraycopy(bytes.bytes, bytes.offset, b, offset, len);
bytes.offset += len;
bytes.length -= len;
} };
} else {
fieldsStream.seek(startPointer);
decompressor.decompress(fieldsStream, totalLength, offset, length, bytes);
assert bytes.length == length;
documentInput = new ByteArrayDataInput(bytes.bytes, bytes.offset, bytes.length);
} return new SerializedDocument(documentInput, length, numStoredFields);
}
5. 几个数据结构
核心的几个get的外观数据结构主要有,请求时GetRequest, 查找时DocIdAndVersion, 真正的结果GetResult, 以及响应时的出参GetResponse. 其实前面已经可以查看,不过在此处做个归集,有意者阅之。
0. get的请求数据结构
// org.elasticsearch.action.get.GetRequest
public class GetRequest extends SingleShardRequest<GetRequest> implements RealtimeRequest { private String type;
private String id;
private String routing;
private String preference; private String[] storedFields; private FetchSourceContext fetchSourceContext; private boolean refresh = false; boolean realtime = true; private VersionType versionType = VersionType.INTERNAL;
private long version = Versions.MATCH_ANY; public GetRequest() {
type = MapperService.SINGLE_MAPPING_NAME;
} GetRequest(StreamInput in) throws IOException {
super(in);
type = in.readString();
id = in.readString();
routing = in.readOptionalString();
if (in.getVersion().before(Version.V_7_0_0)) {
in.readOptionalString();
}
preference = in.readOptionalString();
refresh = in.readBoolean();
storedFields = in.readOptionalStringArray();
realtime = in.readBoolean(); this.versionType = VersionType.fromValue(in.readByte());
this.version = in.readLong();
fetchSourceContext = in.readOptionalWriteable(FetchSourceContext::new);
}
...
}
1. docId 和 version 包含数据结构
// org.elasticsearch.common.lucene.uid.VersionsAndSeqNoResolver.DocIdAndVersion
/** Wraps an {@link LeafReaderContext}, a doc ID <b>relative to the context doc base</b> and a version. */
public static class DocIdAndVersion {
public final int docId;
public final long version;
public final long seqNo;
public final long primaryTerm;
public final LeafReader reader;
public final int docBase; public DocIdAndVersion(int docId, long version, long seqNo, long primaryTerm, LeafReader reader, int docBase) {
this.docId = docId;
this.version = version;
this.seqNo = seqNo;
this.primaryTerm = primaryTerm;
this.reader = reader;
this.docBase = docBase;
}
}
2. GetResult 数据结构
// org.elasticsearch.index.get.GetResult
public class GetResult implements Writeable, Iterable<DocumentField>, ToXContentObject { public static final String _INDEX = "_index";
public static final String _TYPE = "_type";
public static final String _ID = "_id";
private static final String _VERSION = "_version";
private static final String _SEQ_NO = "_seq_no";
private static final String _PRIMARY_TERM = "_primary_term";
private static final String FOUND = "found";
private static final String FIELDS = "fields"; private String index;
private String type;
private String id;
private long version;
private long seqNo;
private long primaryTerm;
private boolean exists;
private final Map<String, DocumentField> documentFields;
private final Map<String, DocumentField> metaFields;
private Map<String, Object> sourceAsMap;
private BytesReference source;
private byte[] sourceAsBytes; public GetResult(StreamInput in) throws IOException {
index = in.readString();
type = in.readOptionalString();
id = in.readString();
if (in.getVersion().onOrAfter(Version.V_6_6_0)) {
seqNo = in.readZLong();
primaryTerm = in.readVLong();
} else {
seqNo = UNASSIGNED_SEQ_NO;
primaryTerm = UNASSIGNED_PRIMARY_TERM;
}
version = in.readLong();
exists = in.readBoolean();
if (exists) {
source = in.readBytesReference();
if (source.length() == 0) {
source = null;
}
if (in.getVersion().onOrAfter(Version.V_7_3_0)) {
documentFields = readFields(in);
metaFields = readFields(in);
} else {
Map<String, DocumentField> fields = readFields(in);
documentFields = new HashMap<>();
metaFields = new HashMap<>();
fields.forEach((fieldName, docField) ->
(MapperService.META_FIELDS_BEFORE_7DOT8.contains(fieldName) ? metaFields : documentFields).put(fieldName, docField));
}
} else {
metaFields = Collections.emptyMap();
documentFields = Collections.emptyMap();
}
} public GetResult(String index, String type, String id, long seqNo, long primaryTerm, long version, boolean exists,
BytesReference source, Map<String, DocumentField> documentFields, Map<String, DocumentField> metaFields) {
this.index = index;
this.type = type;
this.id = id;
this.seqNo = seqNo;
this.primaryTerm = primaryTerm;
assert (seqNo == UNASSIGNED_SEQ_NO && primaryTerm == UNASSIGNED_PRIMARY_TERM) || (seqNo >= 0 && primaryTerm >= 1) :
"seqNo: " + seqNo + " primaryTerm: " + primaryTerm;
assert exists || (seqNo == UNASSIGNED_SEQ_NO && primaryTerm == UNASSIGNED_PRIMARY_TERM) :
"doc not found but seqNo/primaryTerm are set";
this.version = version;
this.exists = exists;
this.source = source;
this.documentFields = documentFields == null ? emptyMap() : documentFields;
this.metaFields = metaFields == null ? emptyMap() : metaFields;
}
...
}
3. get响应结果 GetResponse
// org.elasticsearch.action.get.GetResponse
public class GetResponse extends ActionResponse implements Iterable<DocumentField>, ToXContentObject { GetResult getResult; GetResponse(StreamInput in) throws IOException {
super(in);
getResult = new GetResult(in);
} public GetResponse(GetResult getResult) {
this.getResult = getResult;
}
...
}
ES系列(五):获取单条数据get处理过程实现的更多相关文章
- Golang 网络爬虫框架gocolly/colly 五 获取动态数据
Golang 网络爬虫框架gocolly/colly 五 获取动态数据 gcocolly+goquery可以非常好地抓取HTML页面中的数据,但碰到页面是由Javascript动态生成时,用goque ...
- ES系列五、ES6.3常用api之搜索类api
1.搜索api 1.1.routing:路由 执行搜索时,它将广播到所有索引/索引分片(副本之间的循环).可以通过提供routing参数来控制将搜索哪些分片.例如,在索引book时,路由值可以是nam ...
- 【CSS系列】获取实时数据做进度
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- Storm系列(五)架构分析之Nimbus启动过程
启动流程图 mk-assignments 功能:对当前集群中所有Topology进行新一轮的任务调度. 实现源码路径: \apache-storm-0.9.4\storm-core\src\clj ...
- Nimbus<一>Storm系列(五)架构分析之Nimbus启动过程
启动流程图 mk-assignments 功能:对当前集群中所有Topology进行新一轮的任务调度. 实现源码路径: \apache-storm-0.9.4\storm-core\src\clj\b ...
- ES系列目录
ES系列一.CentOS7安装ES 6.3.1 ES系列二.CentOS7安装ES head6.3.1 ES系列三.基本知识准备 ES系列四.ES6.3常用api之文档类api ES系列五.ES6.3 ...
- Django的restframework的序列化组件之对单条数据的处理
之前我们学习的都是处理书籍或者出版社的所有的数据的方法,下面我们来看下处理单个书籍,或者单个出版社的方法 这个时候我们就需要重新写一个类,这个类的方法,就需要有3个参数,参数1是self,参数2是re ...
- solr与.net系列课程(四)solr查询参数的讲解与.net如何获取solr数据
solr与.net系列课程(四)solr查询参数的讲解与.net如何获取solr数据 上一节我们完成了solr连接数据库,细心的朋友会发现一个问题,就是solr其实和语言没有任何关系,配置完成后任何语 ...
- 室内定位系列(二)——仿真获取RSS数据
很多情况下大家都采用实际测量的数据进行定位算法的性能分析和验证,但是实际测量的工作量太大.数据不全面.灵活性较小,采用仿真的方法获取RSS数据是另一种可供选择的方式.本文介绍射线跟踪技术的基本原理,以 ...
随机推荐
- 【java框架】SpringBoot(3) -- SpringBoot集成Swagger2
1.SpringBoot web项目集成Swagger2 1.1.认识Swagger2 Swagger 是一个规范和完整的框架,用于生成.描述.调用和可视化 RESTful 风格的 Web 服务.总体 ...
- java位运算求一个整数的绝对值
1 import java.util.Scanner; 2 3 public class Question1 { 4 public static void main(String[] args) { ...
- HarmonyOS三方件开发指南(16)-VideoCache 视频缓存
目录: 1.引言 2.功能介绍 3.VideoCache使用指南 4.VideoCache开发指南 5.<HarmonyOS三方件开发指南>系列文章合集 引言 对于视频播放器这个app大家 ...
- Python fire库使用
1.前要fire是python中用于生成命令行界面(Command Line Interfaces, CLIs)的工具 不需要做任何额外的工作,只需要从主模块中调用fire.Fire() 它会自动将你 ...
- Etcd常用运维命令
目录 常用命令 常见操作 如何缩容? 如何扩容? 数据目录丢失或被误删除,节点启动失败或者加入集群报错? 操作步骤 操作步骤不正确的各种常见错误日志 常用命令 #查看集群member情况 etcdct ...
- zk都有哪些使用场景?
(1)分布式协调:这个其实是zk很经典的一个用法,简单来说,就好比,你A系统发送个请求到mq,然后B消息消费之后处理了.那A系统如何知道B系统的处理结果?用zk就可以实现分布式系统之间的协调工作.A系 ...
- 如何建立一个足够安全的SSH连接?
1 概述 使用SSH连接服务器是一件很平常的事,但是,连接是否足够安全是一个令人担忧的问题.本文从如下几个方面介绍了如何建立一个足够安全的SSH连接: 端口 协议 用户 密码 密钥对 ssh-agen ...
- NumPy之:数据类型
目录 简介 数组中的数据类型 类型转换 查看类型 数据溢出 简介 我们知道Python中有4种数字类型,分别是int,float,bool和complex.作为科学计算的NumPy,其数据类型更加的丰 ...
- python进阶(16)深入了解GIL锁(最详细)
前言 python的使用者都知道Cpython解释器有一个弊端,真正执行时同一时间只会有一个线程执行,这是由于设计者当初设计的一个缺陷,里面有个叫GIL锁的,但他到底是什么?我们只知道因为他导致pyt ...
- UI自动化测试框架:PO模式+数据驱动
1. PO 设计模式简介 2. 工程结构说明 3. 工程代码实现 page 包 action 包 business_process 包 util 包 conf 包 test_data 目录 log 目 ...