[DB] Spark Core (2)
RDD
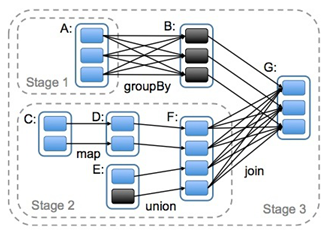
WordCount处理流程
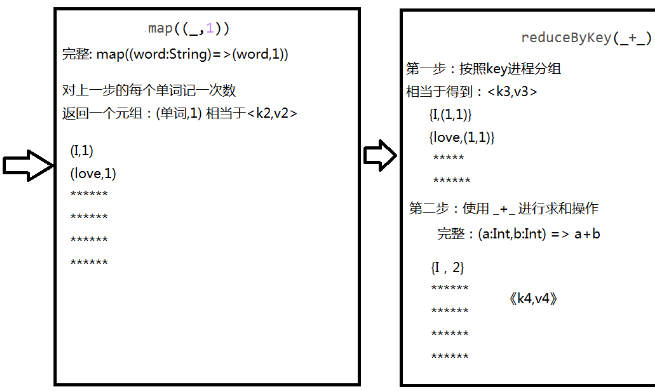
- sc.textFile("/root/temp/data.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect

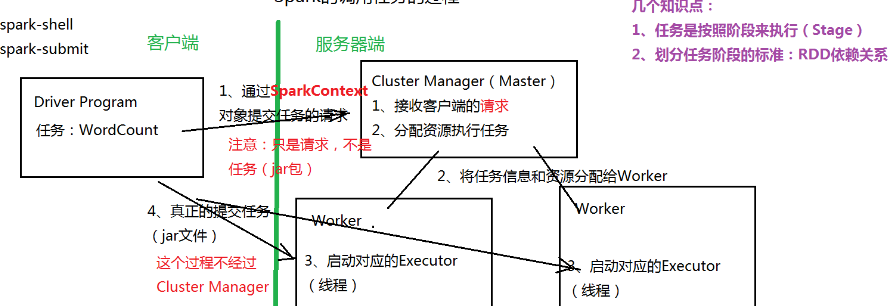
调用任务过程
- 客户端将任务通过SparkContext对象提交给Manager
- Manager将任务分配给Worker
- 客户端将任务提交给Worker
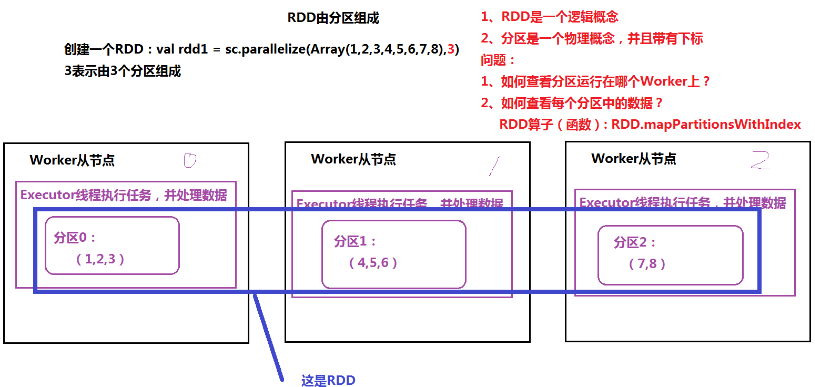
特性
- 由分区组成,每个分区运行在不同的worker上
- 通过算子(函数)处理每个分区中的数据
- RDD之间存在依赖关系(宽依赖、窄依赖),根据依赖关系,划分任务的Stage(阶段)
创建
- 通过集合创建:SparkContext.parallelize
- 通过读取外部数据源:HDFS,本地目录
算子(函数)
- Transformation:由一个RDD生成一个新的RDD。延时加载(计算)
- map(func):对原来的RDD进行某种操作,返回一个新的RDD
- filter(func):过滤
- flatMap(func):压平,类似Map
- mapPartitions(func):对RDD中的每个分区进行操作
- sample(withReplacement, fraction, seed)
- union(otherDataset):集合操作
- distinct([numTasks]):去重
- groupByKey([numTasks]):聚合操作(分组)
- sortByKey([ascending],[numTasks]):排序(针对<key,value>)
- sortBy()
- Action:对RDD计算出一个结果
- reduce(func)
- collect():
- foreach(func):类似map,但没有返回值
缓存
- 默认将RDD的数据缓存在内存中
- 提高性能
- 表示RDD可以被缓存,函数:persist 或 cache
容错
- 检查点(Checkpoint)
- 复习:HDFS中,由SecondaryNameNode进行日志的合并
- 一种容错机制,Lineage(血统)表示任务执行的声明周期(整个任务的执行过程)
- 血统越长,出错概率越大,出错时不需要从头计算,从最近检查点的位置往后计算即可
- 命令(本地模式和集群模式操作一样):
- sc.setCheckpointDir("/root/temp/spark"):指定检查点文件保存目录
- rdd1.checkpoint:标识RDD可以生成检查点
依赖
- 单步WordCount程序:
- val rdd1 = sc.textFile("/root/temp/input/data.txt")
- val rdd2 = rdd1.flatMap(_.split(" "))
- val rdd3 = rdd2.map((_,1)) 完整: val rdd3 = rdd2.map((word:String)=>(word,1) )
- val rdd4 = rdd3.reduceByKey(_+_)
- rdd4.collect
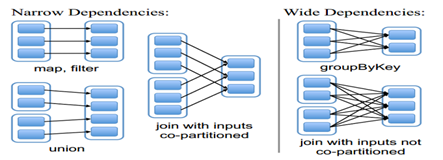
- 根据依赖关系划分任务执行的Stage(阶段)
- 宽依赖(类似“超生”):多个RDD的分区依赖了同一个父RDD分区(左父右子),如groupBy
- 窄依赖(类似“独生子女”):每个父RDD分区,最多被一个RDD的分区使用,如map
- 宽依赖是划分stage的依据
参考
官方API
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package
[DB] Spark Core (2)的更多相关文章
- [DB] Spark Core (1)
生态 Spark Core:最重要,其中最重要的是RDD(弹性分布式数据集) Spark SQL Spark Streaming Spark MLLib:机器学习算法 Spark Graphx:图计算 ...
- [DB] Spark Core (3)
高级算子 mapPartitionWithIndex:对RDD中每个分区(有下标)进行操作,通过自己定义的一个函数来处理 def mapPartitionsWithIndex[U](f: (Int, ...
- Spark Streaming揭秘 Day35 Spark core思考
Spark Streaming揭秘 Day35 Spark core思考 Spark上的子框架,都是后来加上去的.都是在Spark core上完成的,所有框架一切的实现最终还是由Spark core来 ...
- 【Spark Core】任务运行机制和Task源代码浅析1
引言 上一小节<TaskScheduler源代码与任务提交原理浅析2>介绍了Driver側将Stage进行划分.依据Executor闲置情况分发任务,终于通过DriverActor向exe ...
- TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9a7c0a1 转换为 spark.core.IViewport。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 mx.controls::DataGrid@9aa90a1 转换为 spark.core.IViewport. ...
- Spark Core
Spark Core DAG概念 有向无环图 Spark会根据用户提交的计算逻辑中的RDD的转换(变换方法)和动作(action方法)来生成RDD之间的依赖关系,同时 ...
- spark core (二)
一.Spark-Shell交互式工具 1.Spark-Shell交互式工具 Spark-Shell提供了一种学习API的简单方式, 以及一个能够交互式分析数据的强大工具. 在Scala语言环境下或Py ...
- Spark Core 资源调度与任务调度(standalone client 流程描述)
Spark Core 资源调度与任务调度(standalone client 流程描述) Spark集群启动: 集群启动后,Worker会向Master汇报资源情况(实际上将Worker的资 ...
- 大数据技术之_27_电商平台数据分析项目_02_预备知识 + Scala + Spark Core + Spark SQL + Spark Streaming + Java 对象池
第0章 预备知识0.1 Scala0.1.1 Scala 操作符0.1.2 拉链操作0.2 Spark Core0.2.1 Spark RDD 持久化0.2.2 Spark 共享变量0.3 Spark ...
随机推荐
- jenkins构建go及java项目
jenkins构建go及java项目 转载请注明出处https://www.cnblogs.com/funnyzpc/p/14554017.html 写在前面 jenkins作为java的好基友,经历 ...
- 「HTML+CSS」--自定义加载动画【008】
前言 Hello!小伙伴! 首先非常感谢您阅读海轰的文章,倘若文中有错误的地方,欢迎您指出- 哈哈 自我介绍一下 昵称:海轰 标签:程序猿一只|C++选手|学生 简介:因C语言结识编程,随后转入计算机 ...
- DAOS 分布式异步对象存储|相关组件
DAOS 的安装涉及多个组件,这些组件可以是集中式的,也可以是分布式的. DAOS 软件定义存储 (software-defined storage, SDS) 框架依赖于两种不同的通信通道: 用于带 ...
- 第17 章 : 深入理解 etcd:etcd 性能优化实践
深入理解 etcd:etcd 性能优化实践 本文将主要分享以下五方面的内容: etcd 前节课程回顾复习: 理解 etcd 性能: etcd 性能优化 -server 端: etcd 性能优化 -cl ...
- 201871030122-牛建疆 实验三 结对项目——《D{0-1}KP 实例数据集算法实验平台》项目报告
项目 内容 课程班级博客链接 班级博客链接 作业要求链接 作业要求链接 我的课程学习目标 (1)体验软件项目开发中的两人合作,练习结对编程(Pair programming).(2)掌握Github协 ...
- 比较运算规则 == 、 ===、Object.is 和 ToPrimitive 方法 [[DefaultValue]] (hint)
1.== 相等运算符 如果 x 与 y 类型一致时规则如下: 1. 如果 x 类型为 Undefined,返回 true. 2. 如果 x 类型为 Null,返回 true. 3. 如果 x 类型为 ...
- 数据库MySQL五
测试题复习 子查询案例 DML语句(很重要) 自增长列 为某一个字段设置自增长 修改语句 truncate实际上是DDL语句删除表再新建一个表 DCL事务 ACID 回滚:没发生 提交才更新数据 /* ...
- Idea使用指南--实用版
idea使用指南--基础配置: 视频链接:https://www.bilibili.com/video/av21735428/?p=1 idea安装: 快捷方式create destop shortc ...
- 如何识别自己基因组数据是哪个全基因组参考版本(Genome Reference Versions/ Genome Build)
首先在这里先感谢我们[Bio生信学习交流群]的群友和创建此群的群主[陈博士后]. 今天解决的问题是怎么查看自己的基因组数据是哪个Genome Reference Versions. 步骤: 第一步,打 ...
- 【秒懂音视频开发】21_显示BMP图片
文本的主要内容是:使用SDL显示一张BMP图片,算是为后面的<播放YUV>做准备. 为什么是显示BMP图片?而不是显示JPG或PNG图片? 因为SDL内置了加载BMP的API,使用起来会更 ...