redis为什么那么快?
数据库有很多,为什么Redis能有如此突出的表现呢?一方面,因为它是内存数据库,所有操作都在内存上完成。另外一方面就要归功于他的数据结构。高效的数据结构是Redis快速处理的基础。今天我们就来聊聊了Redis的数据类型以及对应的数据结构。
首先Redis有5大基本类型:
1.String(字符串)
2.List(列表)
3.Hash(哈希)
4.Set(集合)
5.Zset(Sorted Set 有序集合)
他们的底层实现简单来说一共有6种,分别是简单的动态字符串、双向链表、压缩列表、哈希表、跳表以及整数数组。他们和数据类型的对应关系如下所示:
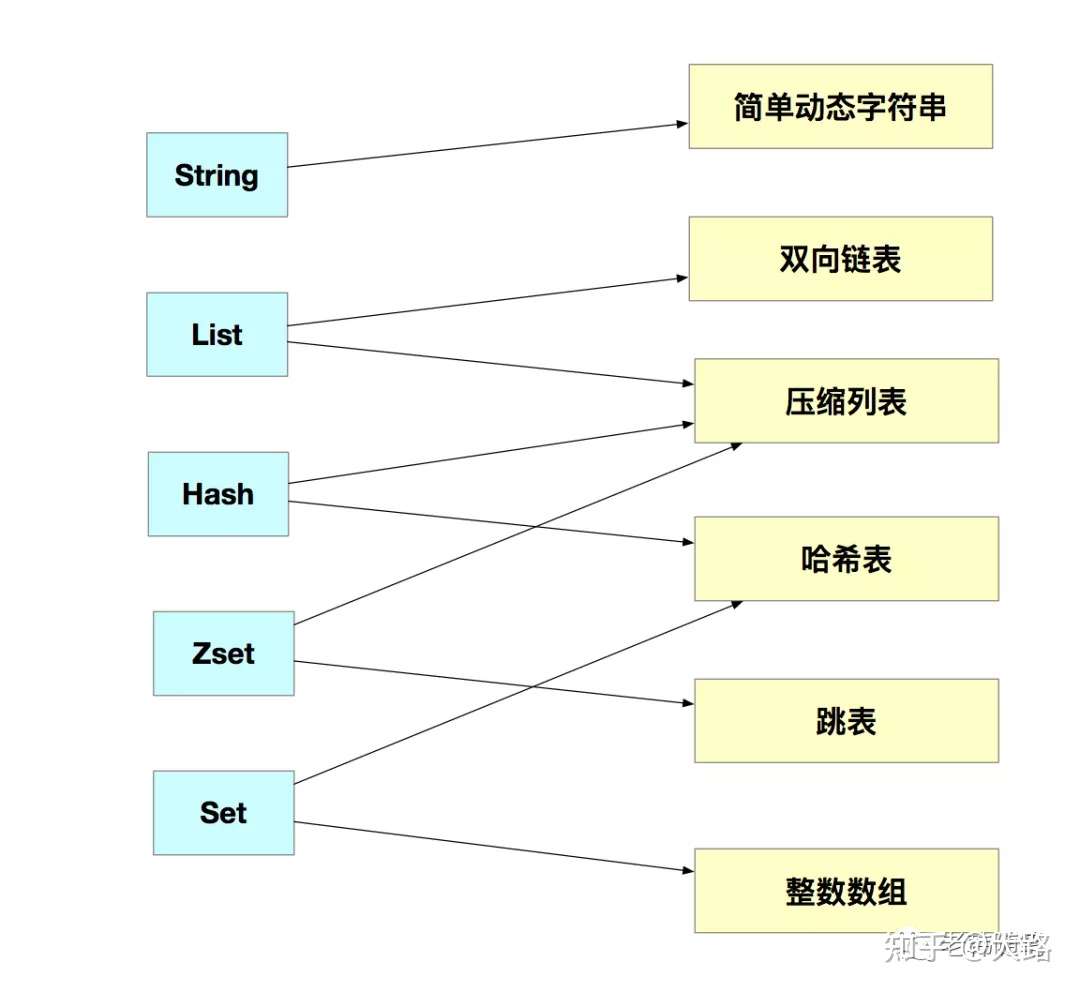
可以看到这些数据结构都是值的底层实现,那键和值之间是用什么数据结构来进行组织的呢?为了实现从键到值的快速访问,Redis使用了一个哈希表来保存所有的键值对。
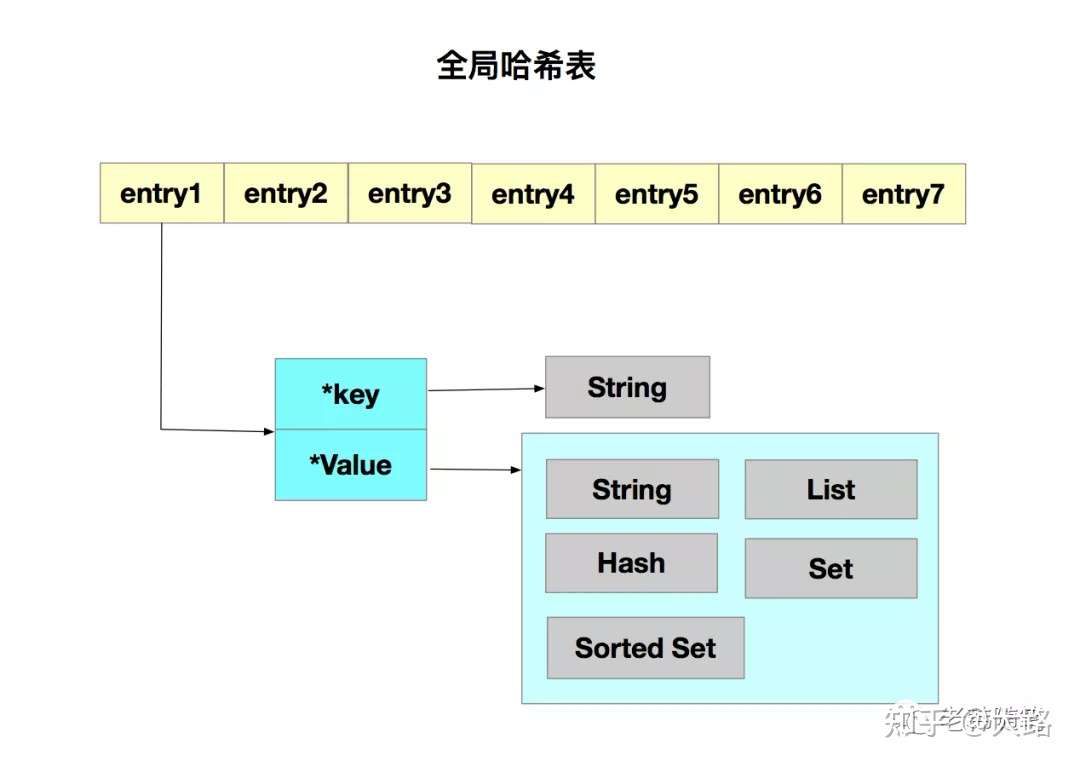
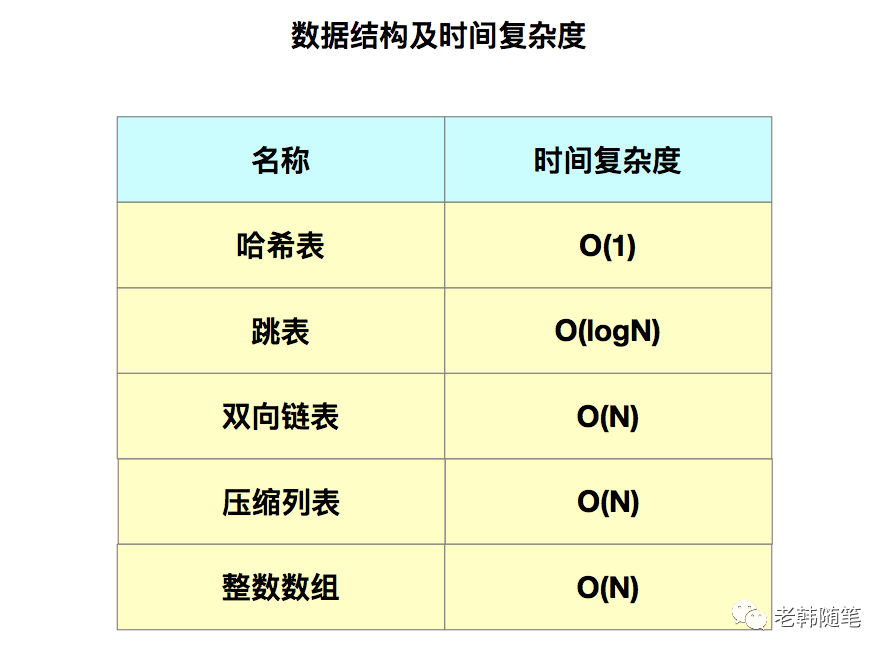
哈希表的最大好处很明显,就是可以以O(1)的时间复杂度来快速查找到键值对。但他有一个潜在的风险点,当你往Redis里写入大量的数据就会出现哈希表的冲突问题以及rehash带来的操作阻塞问题。
Redis解决哈希冲突的方式,就是链式哈希。链式哈希很容易理解,就是指同一个hash桶中的多个元素用一个链表来保存。如下图所示:
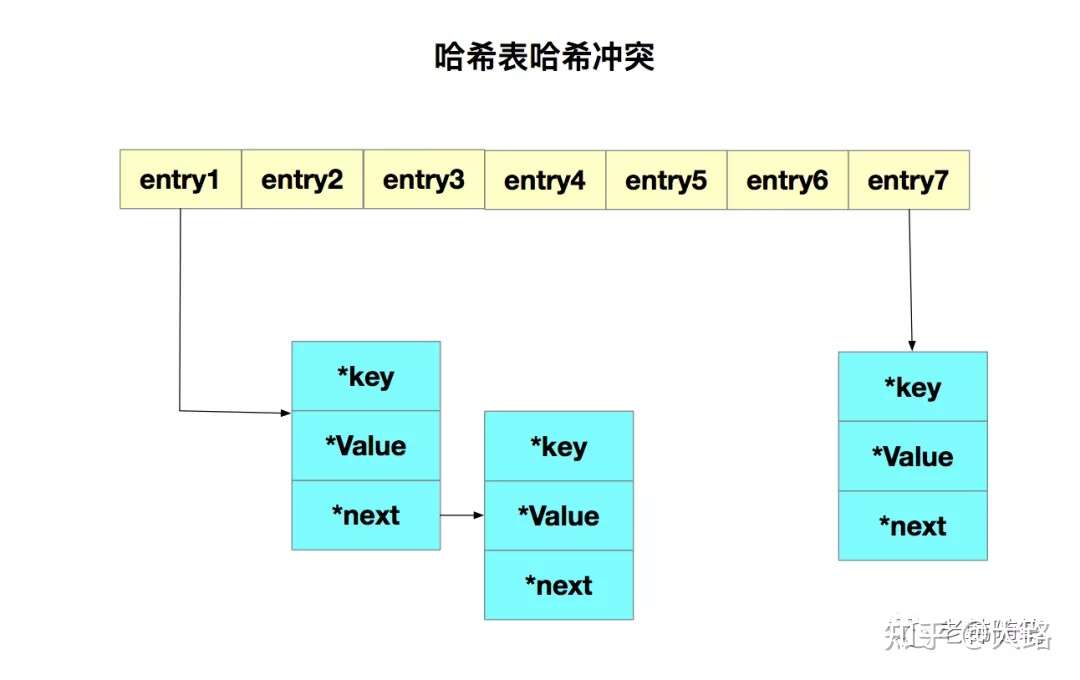
这就出现一个问题,哈希冲突链表上的元素只能通过指针逐一查找再操作。如果哈希表里写入的数据越来越多,哈希冲突也会越来越多,这就会导致某些哈希冲突链过长,进而导致链上的元素查找耗时长,效率低。这对求快的redis来说是不能接受的。
所以Redis会对哈希表做rehash操作。rehash也就是增加现有的哈希桶的数量,让逐渐增多的entry元素能在更多的桶之间分散保存,减少单个桶中的元素个数,从而减少冲突。
为了使rehash更高效,Redis默认使用2个全局哈希表:哈希表1和哈希表2。一开始,当你刚插入数据时,默认使用哈希表1,此时哈希表2并没有分配空间。随着数据的增多,Redis开始执行Rehash。主要分为以下3步:
- 给哈希表2分配更大的空间。
- 把哈希表1的数据重新映射并拷贝到哈希表2。
- 释放哈希表1的空间。
到此我们可以从哈希表1切换到哈希表2,用容量更大的哈希表2来保存更多的数据,而原来的哈希表1留做下一次rehash扩容备用。
可以看到第二步会涉及到大量的数据拷贝,如果一次性把哈希表1全部都迁移完,会造成Redis线程阻塞,无法服务其他请求。为了避免这个问题,Redis采用了渐进式的Rehash。简单来说就是在第二步拷贝数据时,仍然正常处理客户端的请求,每处理一个请求,从哈希表1的第一个索引位置开始,顺带着将这个索引位置上的所有entries拷贝到哈希表2中;等处理下一个请求时,再顺带拷贝哈希表1的下一个索引位置的entries。这样就避免了一次性大量的数据拷贝,保证了数据的快速访问。
目前为止,你已经了解了Redis的键和值是怎么通过哈希表来组织的了,对于String类型来说,找到哈希桶就能直接增删改查了,所以哈希表O(1)的时间复杂度就是它的复杂度,但是对于集合类型来说,即使找到哈希桶了,还需要在集合中进一步操作。接下来我们就分别聊聊集合类型的底层数据结构和操作复杂度。
我们在上面已经了解到集合类型的底层结构主要有5种:整数数组、双向链表、哈希表、压缩列表和跳表。
其中,哈希表的操作特点我们已经学过;整数数组和双向链表也很常见,主要是通过数组下标和链表指针逐个访问元素,操作复杂度是O(N),操作效率比较低。压缩列表实际上类似于一个数组,和数组不同的是,压缩列表在表头有三个字段zlbytes、zltail和zllen,分别表示列表的长度、列表尾的偏移量和列表中元素的个数;压缩列表在表尾还有一个zlend表示列表结束。在压缩列表中,如果我们要查找定位第一个元素和最后一个元素,可以通过表头直接定位,时间复杂度为O(1)。而查找其它元素时,就没有那么高效了,只能逐个查询,时间复杂度为O(N)。


下面我们来重点看一下跳表。有序链表只能逐一查找元素,导致操作起来非常缓慢,于是就出现了跳表。跳表是在链表的基础上增加了多级索引,通过索引位置的几个跳转,实现数据的快速定位。如图所示:
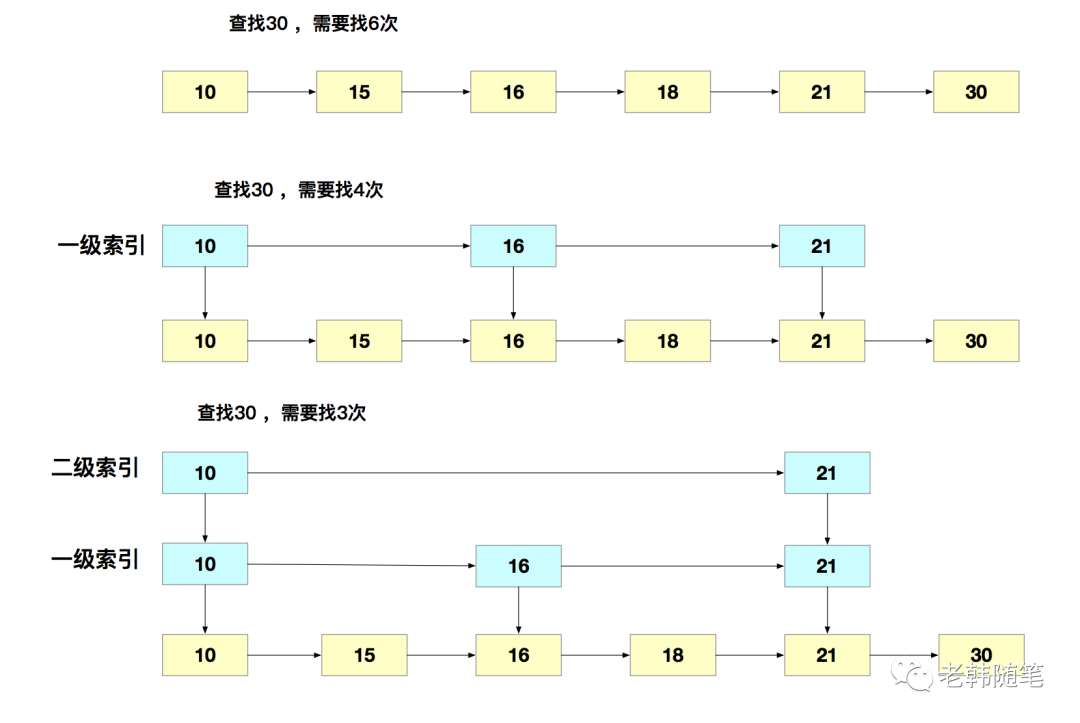
可以看到,这个查找过程就是在多级索引上跳来跳去,最后定位到元素。当数据量很大时,跳表的查找复杂度是O(logN)。
好了,今天就分享到这里,如果有什么问题,可以在留言区留言。

redis为什么那么快?的更多相关文章
- 为什么说Redis是单线程的以及Redis为什么这么快!
参考文章:https://blog.csdn.net/xlgen157387/article/details/79470556 redis简介 Redis是一个开源的内存中的数据结构存储系统,它可以用 ...
- 为什么说Redis是单线程的以及Redis为什么这么快!(转)
文章转自https://blog.csdn.net/chenyao1994/article/details/79491337 一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到 ...
- Redis为什么这么快
Redis为什么这么快 1.完全基于内存,绝大部分请求是纯粹的内存操作,非常快速.数据存在内存中,类似于HashMap,HashMap的优势就是查找和操作的时间复杂度都是O(1): 2.数据结构简单, ...
- Redis性能解析--Redis为什么那么快?
echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加echo微信(微信号:t2421499075)交流学习. 百战不败,依不自称常胜,百败不颓,依能奋力前行.--这才是真正的堪称强大!!! Red ...
- 《为什么说Redis是单线程的以及Redis为什么这么快!》
为什么说Redis是单线程的以及Redis为什么这么快! 一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到什么是“二八定律”.什么是“热数据和冷数据”,复杂一点的会问到缓 ...
- [转帖]Redis性能解析--Redis为什么那么快?
Redis性能解析--Redis为什么那么快? https://www.cnblogs.com/xlecho/p/11832118.html echo编辑整理,欢迎转载,转载请声明文章来源.欢迎添加e ...
- 为什么说Redis是单线程的以及Redis为什么这么快!(转)
一.前言 近乎所有与Java相关的面试都会问到缓存的问题,基础一点的会问到什么是“二八定律”.什么是“热数据和冷数据”,复杂一点的会问到缓存雪崩.缓存穿透.缓存预热.缓存更新.缓存降级等问题,这些看似 ...
- 性能测试 | 理解单线程的Redis为何那么快?
前言 Redis是一种基于键值对(Key-Value)的NoSQL数据库,Redis的Value可以由String,hash,list,set,zset,Bitmaps,HyperLogLog等多种数 ...
- Redis 为什么这么快?
1. 纯内存操作,肯定快 数据存储在内存中,读取的时候不需要进行磁盘的 IO 2. 单线程,无锁竞争损耗 单线程保证了系统没有线程的上下文切换 使用单线程,可以避免不必要的上下文切换和竞争条件,没有多 ...
- Redis为什么这么快?
Redis为什么这么快?
随机推荐
- rpm包名详解-rpm命令使用方法
linux软件包管理-rpm mount # 挂载 1.将光盘镜像插入光驱 2.创建挂载目录 mkdir /guangqu 3.挂载到/guangqu [root@gong ~]# mount /de ...
- nosql数据库之Redis持久化、备份和主从配置
一.持久化方式 Redis提供了两种数据备份的方式,一种是RDB,另外一种是AOF. RDB AOF 开启/关闭 开启:默认开启:关闭:把配置文件中所有的save注释就是关闭了 开启:在配置文件中 ...
- 常用数据库连接池配置及使用(Day_11)
世上没有从天而降的英雄,只有挺身而出的凡人. --致敬,那些在疫情中为我们挺身而出的人. 运行环境 JDK8 + IntelliJ IDEA 2018.3 优点: 使用连接池的最主要的优点是性能.创 ...
- .NET平台系列13 .NET5 统一平台
系列目录 [已更新最新开发文章,点击查看详细] 时机决定一切,对于 .NET5 也是如此.实际上微软.NET团队在开始开发 .NET Core 时,对 .NET Framework 的全面重写 ...
- OFRecord 数据集加载
OFRecord 数据集加载 在数据输入一文中知道了使用 DataLoader 及相关算子加载数据,往往效率更高,并且学习了如何使用 DataLoader 及相关算子. 在 OFrecord 数据格式 ...
- 地理围栏API服务开发
地理围栏API服务开发 要使用华为地理围栏服务API,需要确保设备已经下载并安装了HMS Core(APK),并将Location Kit的SDK集成到项目中. 指定应用权限 如果需要使用地理围栏服务 ...
- NVIDIA GPU卷积网络的自动调谐
NVIDIA GPU卷积网络的自动调谐 针对特定设备和工作负载的自动调整对于获得最佳性能至关重要.这是关于如何为NVIDIA GPU调整整个卷积网络. NVIDIA GPU在TVM中的操作实现是以模板 ...
- Spring Cloud02:Eureka Server注册中心
一.Eureka是什么 Eureka是Netflix开源的基于REST的服务治理方案,Spring Cloud集成了Eureka,提供服务治理和服务发现功能,可以和基于Spring Boot搭建的微服 ...
- ApplicationListener接口,在spring容器初始化后执行的方法
一.如果我们希望在Spring容器将所有的Bean都初始化完成之后,做一些操作,那么就可以使用ApplicationListener接口,实现ApplicationListener接口中的onAppl ...
- 这 7 个 Linux 命令,你是怎么来使用的?
使用 Linux 系统的开发者,很多人都有自己喜欢的系统命令,下面这个几个命令令是我平常用的比较多的,分享一下. 我不会教科书般的罗列每个指令的详细用法,只是把日常开发过程中的一些场景下,经常使用的命 ...