CPU乱序执行基础 —— Tomasulo算法及执行过程
朋友们可以关注下我的公众号,获得最及时的更新:

IBM 360/91浮点单元最先实现Tomasulo算法从而允许乱序执行。360体系只有4个双精度浮点寄存器,限制了编译器调度的有效性。而且,IBM 360/91的访存和浮点延迟都很长,如果顺序执行指令,虽然只有RAW hazard,但是后面无关的指令只能被stall。如果乱序执行,还会额外引入WAR和WAW hazard。Tomasulo算法通过Register renaming解决了这些问题。
Tomasulo算法1966年提出,设计目标是让编译器在360系列计算机中通用,不用为每台计算机专门做一个编译器。
因为乱序执行,基础的Tomasulo算法不能保证Precise Exception和Speculation,带有Reorder buffer的Tomasulo算法可以解决这个问题。
作用
- 指令顺序发射(issue/dispatch),乱序执行(execute),顺序提交(commit)。
- Register renaming : 通过reservation station和ROB实现。
- distributed RS : 如果多个指令同时等待一个寄存器的数据,那么可以在一个时钟周期内通过CDB传输到多个RS.
- 实现Bypassing/forwarding
- 通过CDB,数据直接从执行单元EU传输到等待该操作数的RS。
- 通过Reorder buffer(ROB),可以实现Precise exception和HW Speculation,同时由于ROB保证指令顺序提交,顺便也消除了WAR & WAW hazard.
不带ROB
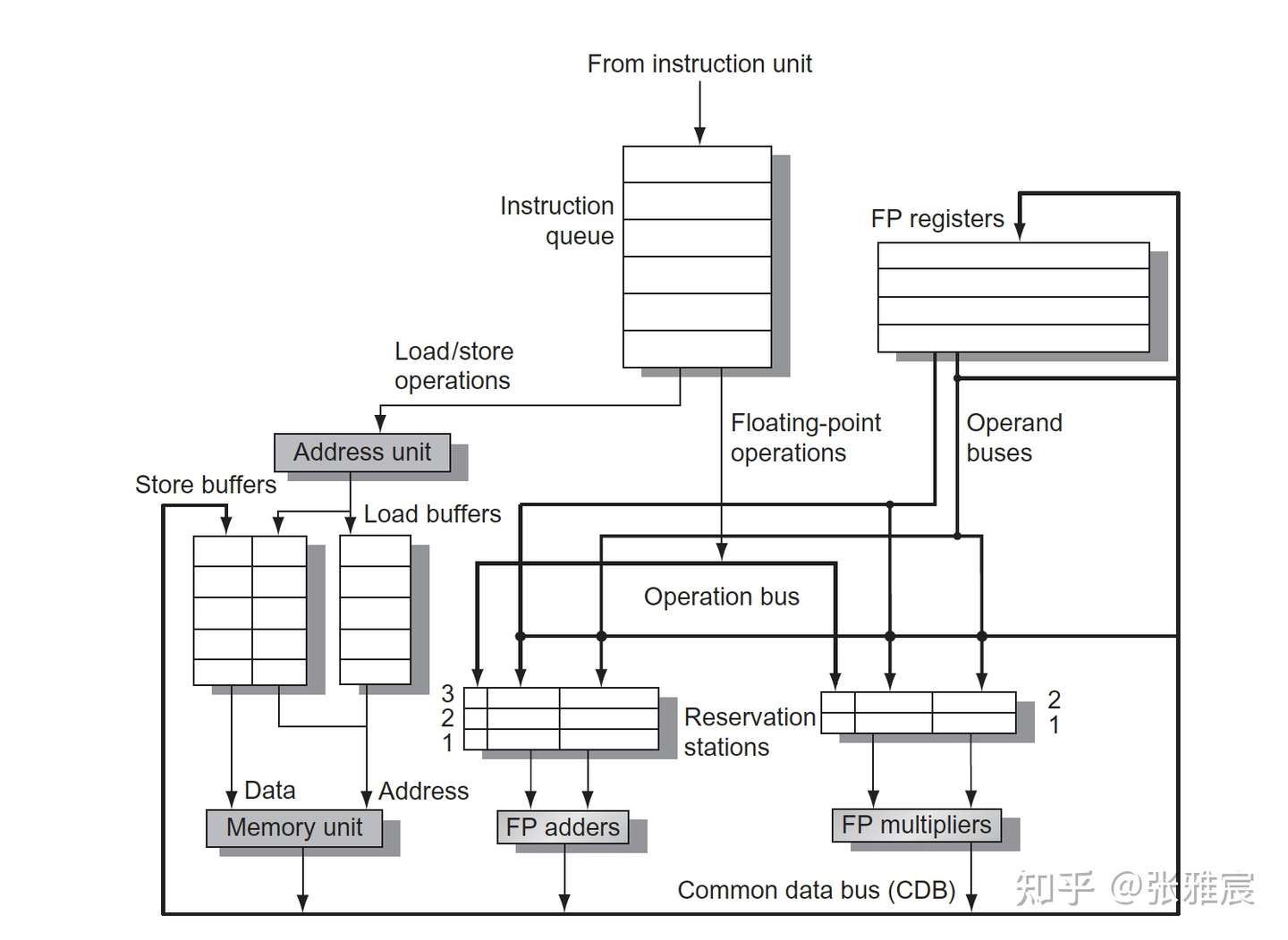 图来自computer architecture —— a quantitative approach 6th edition(英文版) P198
图来自computer architecture —— a quantitative approach 6th edition(英文版) P198
在不带ROB的版本里,执行单元(FP adders/FP mulitipliers)产出的数据会直接写入到对应的register file和等待这个数据的RS中,不能实现Precise exception和HW Speculation,所以这里关注带有ROB版本的Tomasulo 算法。
Precise exception(精确异常) 的意思是当指令出现异常时(除0、page fault,etc),前面的指令已经完成,后面的指令不能对寄存器、内存等进行修改,即跟顺序执行的效果一样,比如:
fdiv.d f0,f2,f4
fadd.d f10,f10,f8
fsub.d f12,f12,f143条指令之间没有hazard,后两条指令会比除法指令先结束。如果在结束后除法指令发生了exception,操作系统在进行exception处理时,只能假设之前的指令执行完成,后面指令没有执行,exception恢复后,加法和减法指令还得再执行一次,结果就不对了。
带ROB
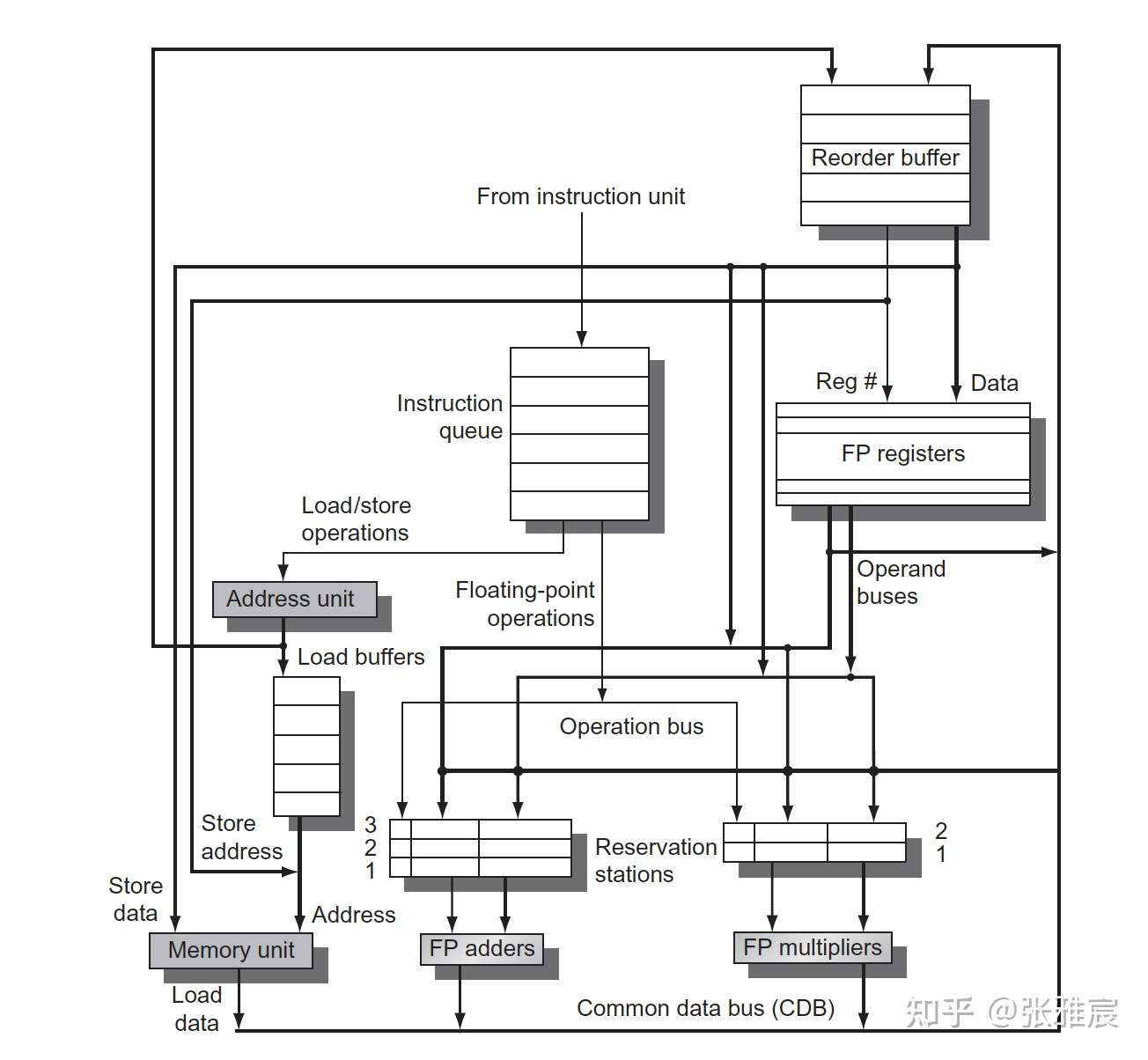 图来自computer architecture —— a quantitative approach 6th edition(英文版) P210
图来自computer architecture —— a quantitative approach 6th edition(英文版) P210
ROB的存在使得指令虽然乱序执行,但是必须顺序提交,防止不可撤销的更新操作发生(写寄存器,写内存)。
Instruction queue
FIFO queue,存取到的指令。
Reservation Station
当前面的指令由于hazard、cache miss被阻塞时,后面不相关的指令可以继续执行,被阻塞的指令临时放在RS中,不至于整个流水线被阻塞。当被阻塞指令需要的操作数通过CDB传输到对应的RS时,指令被送到EU中执行。RS包含的字段:
- Op —— 此保留站存放的指令需要执行的运算,fadd、fld、fds,etc.
- Qj,Qk —— 即将更新此源操作数的指令对应的ROB entry tag。 0意味着不存在RAW hazard,该源操作数当前可用。比如fadd f0,f1,f2; fsub f3,f0,f2; 这里针对f0存在RAW hazard,假如为fadd指令分配的ROB entry tag是#1,那么fsub的RS entry里Qj就是#1, 意思是等待ROB tag为#1的指令更新这个操作数。其实这里就是通过Register renaming减少RAW hazard。
- Vj, Vk —— 源操作数的值。对于每一个操作数,Q和V只有一个是有效的。
- A —— 在load/store指令中存放内存地址相关信息。比如fld f6, 32(x2), 32+x2是effective address,放在此字段中。
- Dest —— 此指令对应的ROB entry tag。用来更新对应ROB中的field.
- Busy —— 是否被占用。
Common data bus(CDB)
数据传输,EU -> RS、ROB -> Register File,etc。传输时还会带着更新此数据的指令对应的ROB entry tag,这样RS里就可以通过匹配tag来更新源操作数。
Reorder buffer(ROB)
FIFO queue,每一项ROB包含4个字段:
- Instruction type —— 指令类型。branch、store、load、ALU operation.
- Destination —— 对于load和ALU operation来说是目标寄存器,对于store是内存地址,branch此字段无意义。
- Value —— 指令结果值。
- Ready —— 指令是否已经完成执行。
Register File
由于Commit阶段存在,Register File只能由ROB通过CDB去更新,RS不能直接更新Register File. Register File存放着将要向此寄存器更新值的ROB entry tag。如果没有值或者为0,代表此寄存器的值可用,否则,意味着该寄存器的值会被前面的指令更新,用该寄存器作为源操作数的需要等待CDB将更新后的值传输过来。

Load Buffer/Store Buffer
Load Buffer存放effective address。Store Buffer的功能一般集成到了ROB中,因为Store Buffer需要的value和effective address在ROB中已经有了。
load/store指令对于相同的effective address也是存在hazard的,而且必须是effective address在execute阶段计算好后才知道是否有hazard存在。比如:
- fsd f5, 1000(f0), fld f0, 1000(f0)
- fsd f5, 1000(f0), fld f0, 1000(f1) —— 虽然base register不同,但是有可能f0和f1的值相同,计算后的effective address也相同,这就存在RAW hazard.

指令执行过程
发射(Issue)
从instruction queue取一条指令(单发射)。如果RS和ROB均有空位,则发射指令到RS,如果有一个没有空位,会stall指令发射。如果操作数对应的寄存器/ROB中的数据可用,。更新Busy字段表明此RS项被占用。为分配的ROB
执行(Execute)
如果操作数均准备好了,直接执行,可能占用多个时钟周期,如果在同一个时钟周期内有多个指令可以执行,一般策略是随机挑选。如果任一一个操作数没有准备好,监控CDB获取计算好的操作数,此步骤检查RAW hazard.
对于store指令,此步骤仅仅计算effective address.
对于load指令,除了计算effective address,还需要确保当前ROB中的Store指令没有相同的Destination时,才会去内存/cache中读数据,这里避免了针对同一effective address的RAW hazard.
写回(Write result)
计算结果和指令对应的ROB entry tag沿着CDB传输到ROB和等待此操作结果的RS项。对于store指令比较特殊,如果要存储的值已经准备好了,将其写到对应ROB entry的Value字段,否则,还需要等CDB将需要存储的值传输过来,更新Value.
注意和不带ROB的算法不同,为了之后可回退计算结果,此步骤不会直接将结果写入到Register File中。
提交(Commit)
当指令到达ROB头部且ready字段为1,根据指令类型不同,操作不同:
- normal commit —— 用Value更新Destination寄存器,并将对应的项目从ROB移除。
- store —— 和上面类似,只是根据Destination和Value更新对应的内存地址。
- branch with incorrect prediction —— 意味着branch预测错误(CPU分支预测器是另外一个很大的话题),需要flush ROB,也就是不要提交branch预测错误后执行指令,从应该执行的指令处重新开始执行。
如果一个指令抛出了异常/预测错误,会在ROB中记录。只有在Commit阶段且指令到达ROB头部时才会识别并flush ROB。
这个是整体流程的伪代码,来自computer architecture —— a quantitative approach 6th edition(英文版) P216

- rd —— 目标寄存器,rs/rt —— 源寄存器。
- RS —— Reservation Station,r和b —— 为指令分配的Reservation Station entry和ROB entry。
- h —— ROB头部entry。
- result —— RS通过CDB传输的EU计算结果。
- RegisterStat —— 寄存器结构,Regs —— 实际寄存器。
RS和ROB的项数
可以看出RS和ROB的总项数反映出一个处理器的乱序执行能力。项数越大表明in-flight(正在执行)的指令数目越多。Intel公司的Nehamel有128项ROB,IBM公司的Power 4/5有200项ROB.
Reservation Station组织形态一般有三种:
- 独立 —— 一个EU一个RS,设计简单,只要一个写入端口和读出端口。但是利用率低,容易忙的忙死,闲的闲死。
- 分组 —— 把EU分为几组,同组的共享一个RS,需要多个写入和读出端口。分组时通常考虑定点、浮点和访问3类。MIPS R1000是定点、浮点和访问3个RS,每个各16项。Alpha 21264是定点和访存共用一个20项的RS,浮点共用一个15项的RS。
- 全局 —— 所有EU共用一个RS,读出和写入端口很多,控制比较复杂。当然使用效率最高,而且CDB只要送到全局RS。Intel P6架构的Pentium Pro、Pentuim II、Pentuim III都是类似的结构,只有一个RS,共20项。
Onur Mutlu的这个Lecture讲的更加详细
朋友们可以关注下我的公众号,获得最及时的更新:
CPU乱序执行基础 —— Tomasulo算法及执行过程的更多相关文章
- [No0000167]CPU内部组成结构及指令执行过程
计算机的基本硬件系统由运算器.控制器.存储器和输入.输出设备五大部件组成.运算器和控制器等部件被集成在一起统称为中央处理单元(Central Processing Unit,CPU). CPU的功能 ...
- 关于Floyd-Warshall算法由前趋矩阵计算出的最短路径反映出了算法的执行过程特性的证明
引言:Floyd-Warshall算法作为经典的动态规划算法,能够在O(n3)复杂度之内计算出所有点对之间的最短路径,且由于其常数较小,对于中等规模数据运行效率依然可观.算法共使用n此迭代,n为顶点个 ...
- CPU结构与指令执行过程简介
CPU(Central Processing Unit)是计算机中进行算术和逻辑计算处理指令的主要部件. CPU结构 CPU由通用寄存器组,运算器,控制器和数据通路等部件组成. 寄存器包括 数据寄存器 ...
- 操作系统复习——如何查看一个进程的详细信息,如何追踪一个进程的执行过程 ,如何在 Linux 系统下查看 CPU、内存、磁盘、IO、网卡情况?epoll和select区别?
1. 如何查看一个进程的详细信息,如何追踪一个进程的执行过程 通过pstree命令(根据pid)进行查询进程内部当前运行了多少线程:# pstree -p 19135(进程号) 使用top命令查看(可 ...
- LINUX内核分析第八周学习总结:进程的切换和系统的一般执行过程
韩玉琪 + 原创作品转载请注明出处 + <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000 一.进程切换的关 ...
- 《数据结构与算法之美》 <01>复杂度分析(上):如何分析、统计算法的执行效率和资源消耗?
我们都知道,数据结构和算法本身解决的是“快”和“省”的问题,即如何让代码运行得更快,如何让代码更省存储空间.所以,执行效率是算法一个非常重要的考量指标. 那如何来衡量你编写的算法代码的执行效率呢?这里 ...
- 【体系结构】动态调度算法:记分牌算法和tomasulo算法
记分牌和tomasulo算法 动态调度: 通过硬件在程序执行时重新安排代码的执行序列来减少竞争引起的流水线停顿时间 动态调度流水线具备以下功能: (1)允许按序取多条指令和发射多条指令----取指(I ...
- 《Linux内核分析》第八周 进程的切换和系统的一般执行过程
[刘蔚然 原创作品转载请注明出处 <Linux内核分析>MOOC课程http://mooc.study.163.com/course/USTC-1000029000] WEEK EIGHT ...
- 小觑数据库(SqlServer)查询语句执行过程
近年来,越来越多的NoSql产品不断的以技术革命的者的身份跳出来:“你看哥是多么的快,你们关型型数据库真是战五渣阿”.是的,高性能的场景下NoSql真的很出彩.而我们关系型数据库只能在墙角哭泣&quo ...
随机推荐
- debian老版本下载地址
https://cdimage.debian.org/cdimage/archive/
- ApacheCN Java 译文集 20210921 更新
新增了五个教程: Java 设计模式最佳实践 零.前言 一.从面向对象到函数式编程 二.创建型模式 三.行为模式 四.结构模式 五.函数式模式 六.让我们开始反应式吧 七.反应式设计模式 八.应用架构 ...
- CentOS-7部署Docker容器
为了适应当前容器化的部署方式,故最近也在对docker进行学习.目前的理解是docker服务就像一艘货船,而你的各项服务可以封装在一个个集装箱里,而且在docker里服务的启动非常快,故有必要从基础的 ...
- NSString为何要用copy修饰,而不是strong?
NSString本身是无所谓的,但是如果一个 NSString 指针指向了一个 NSMutableString的内存空间的话,如果使用 strong 修饰的话,如果你在别处修改这个值的话,那么原来的值 ...
- CSS3自定义滚动条样式-webkit内核
自定义滚动条实现 此部分针对webkit内核的浏览器,使用伪类来改变滚动条的默认样式,详情如下: 滚动条组成部分 1. ::-webkit-scrollbar 滚动条整体部分 2. ::-webkit ...
- VUE项目部署到线上生产环境,Loading chunk xxx failed
项目部署到生产环境,路由点击无效,报错 Loading chunk chunk-xxxxx failed.(missing xxxx) 加载失败,错误的路径. 话不多说,直接贴代码: vue.conf ...
- WebGPU 中消失的 FBO 和 RBO
目录 1 WebGL 中的 FBO 与 RBO 1.1 帧缓冲对象(FramebufferObject) 1.2 颜色附件与深度模板附件的真正载体 1.3 FBO/RBO/WebGLTexture 相 ...
- [USACO4.2]工序安排Job Processing
两种想法: (样例是真的良心,卡掉了两种错误做法)洗完一件马上塞一件到最快的空闲烘干机去?X,因为最后一件洗完的衣服决定了第二问的答案,但它并不一定得到最优待遇--最快的烘干机. 给最后一件洗完的 ...
- 学习Spring5必知必会(1)~未使用spring前的麻烦
一.未使用spring前的麻烦 开闭原则:扩展是开放的,但是对于修改是"封闭的". 1.代码耦合度比较高[不符合开闭原则]: public class EmployeeServic ...
- 为什么大厂前端监控都在用GIF做埋点?
什么是前端监控? 它指的是通过一定的手段来获取用户行为以及跟踪产品在用户端的使用情况,并以监控数据为基础,为产品优化指明方向,为用户提供更加精确.完善的服务. 如果这篇文章有帮助到你,️关注+点赞️鼓 ...