A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2021)
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2021)
- 本篇博客是对A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation的一些重要idea的解读,原文连接为:A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation (acm.org)
- 该文重点介绍了同时从data和query中学习联合数据分布的方法。
- 特点:
- 不做任何独立性假设
- 同时利用data和query训练模型
- 增量更新,更好的时间和空间消耗
基数估计及联合分布相关信息
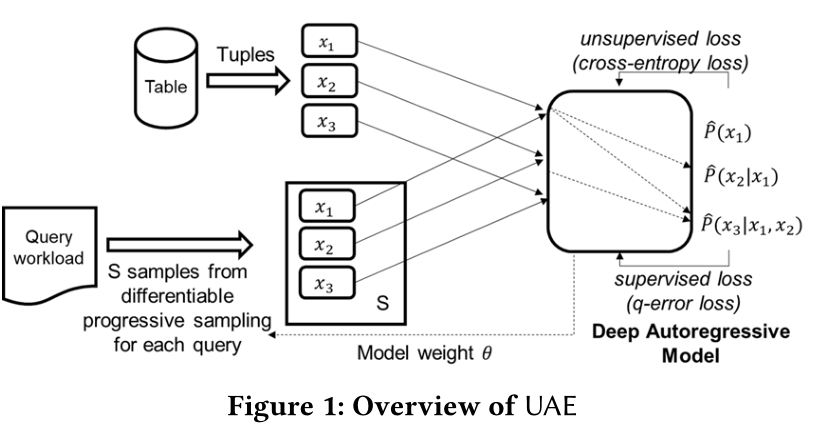
- 该部分在笔者另一篇介绍Naru的博客中已经讲述Deep Upsupervised Cardinality Estimation 解读(2019 VLDB) - 茶柒每天要学习 - 博客园 (cnblogs.com) 这里不做过多赘述,本文所用到的模型在data-driven方面的思想与Naru基本一致(包括使用自回归模型,encoding,decoding,progressive sampling)下文的重点是介绍如何用query(监督数据)训练data-driven(无监督模型)。
在自回归模型中加入query信息训练的challenge
现有的自回归模型无法实现从query中学习,这是因为在做反向传播时,梯度无法流经采样的一些离散随机变量(在本文中代表进行范围查询时渐进采样出的一系列点),因此采样过程是不可微的。本文介绍了使用gumbel-softmax方法对采样的点进行重参数化,使之可微的方法。
Gumbel-Softmax Trick
- gumbel-softmax是一种重参数化技巧,假设我们知道数据表中某一个属性列的概率分布P,范围查询需要我们在目标范围按照该概率分布采样出一些点{x...},利用这些采样点对范围选择度进行估计。但是这样采样出来的点有一个问题:x只是按照某种概率分布P直接选择出来的值,并没有一个明确定义公式,这就导致了x虽然与概率P存在某种关联,但是并没有办法对其进行求导,也就不能利用反向传播调整概率分布。
- 既然问题的原因是没有一个明确的公式,那么我们构造出一个公式,使之得到的结果就是这些采样不就可以解决不可微的问题了吗?我们想要构造的就是下式,即gumbel-max技巧:
\]
其中\(g_i=-log(-log(u_i)),u_i\sim Uniform(0,1)\).被称为Gumbel噪声,这个噪声的作用是使得每次公式产生的结果都不一致因为如果每次都一致就不叫采样了。根据该式我们最终会得到一个one-hot向量,用该向量与待采样的值域空间相乘即可得到采样点。我们注意到上式存在argmax操作,该操作也是不可微的,此时我们用softmax操作代替argmax即可解决问题,而最终方案被称为gumbel-softmax技巧。
损失函数
- data-driven 使用交叉熵损失函数
- query-driven使用q-error 损失函数*
- 本文通过一个超参数将两者相结合如下图:
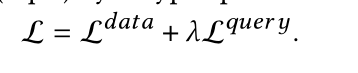
workflow
A Unified Deep Model of Learning from both Data and Queries for Cardinality Estimation 论文解读(SIGMOD 2021)的更多相关文章
- Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021)
Fauce:Fast and Accurate Deep Ensembles with Uncertainty for Cardinality Estimation 论文解读(VLDB 2021) 本 ...
- Deep Upsupervised Cardinality Estimation 解读(2019 VLDB)
Deep Upsupervised Cardinality Estimation 本篇博客是对Deep Upsupervised Cardinality Estimation的解读,原文连接为:htt ...
- 论文解读(GraphDA)《Data Augmentation for Deep Graph Learning: A Survey》
论文信息 论文标题:Data Augmentation for Deep Graph Learning: A Survey论文作者:Kaize Ding, Zhe Xu, Hanghang Tong, ...
- Unified shader model
https://en.wikipedia.org/wiki/Unified_shader_model In the field of 3D computer graphics, the Unified ...
- Deep High-Resolution Representation Learning for Human Pose Estimation
Deep High-Resolution Representation Learning for Human Pose Estimation 2019-08-30 22:05:59 Paper: CV ...
- 论文笔记:(NIPS2017)PointNet++: Deep Hierarchical Feature Learning on Point Sets in a Metric Space
目录 一. 存在的问题 1.提取局部特征的能力 2.点云密度不均问题 二.解决方案 1.改进特征提取方法: (1)采样层(sampling) (2)分组层(grouping) (3)特征提取层(fea ...
- 论文解读(SUBLIME)《Towards Unsupervised Deep Graph Structure Learning》
论文信息 论文标题:Towards Unsupervised Deep Graph Structure Learning论文作者:Yixin Liu, Yu Zheng, Daokun Zhang, ...
- 论文解读(DCN)《Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering》
论文信息 论文标题:Towards K-means-friendly Spaces: Simultaneous Deep Learning and Clustering论文作者:Bo Yang, Xi ...
- 论文解读(IDEC)《Improved Deep Embedded Clustering with Local Structure Preservation》
Paper Information Title:<Improved Deep Embedded Clustering with Local Structure Preservation>A ...
随机推荐
- 人口信息普查系统-JavaWeb-四
今天给大家分享前端人口登记页面,人口查询页面 人口登记 <%@ page language="java" contentType="text/html; chars ...
- Python初学笔记之字符串
一.字符串的定义 字符串是就一堆字符,可以使用""(双引号).''(单引号)来创建. 1 one_str = "定义字符串" 字符串内容中包含引号时,可以使用转 ...
- 深入理解F1-score
本博客的截图均来自zeya的post:Essential Things You Need to Know About F1-Score | by Zeya | Towards Data Science ...
- Xml的一些基本概念(摘抄自w3school.com.cn)
一个Xml的文档示例: 点击查看代码 <?xml version="1.0" encoding="ISO-8859-1"?> <note> ...
- 「CTSC 2011」幸福路径
[「CTSC 2011」幸福路径 蚂蚁是可以无限走下去的,但是题目对于精度是有限定的,只要满足精度就行了. \({(1-1e-6)}^{2^{25}}=2.6e-15\) 考虑使用倍增的思想. 定义\ ...
- Jmeter平均响应时间和TPS的计算方法
转自:https://www.cnblogs.com/xianlai-huang/p/7795215.html Jmeter的Throughput和平均RT的计算 1.TPS:每秒处理的事务数,jme ...
- memcache启动多个服务
windows 7 64bit 环境下安装memcached 1.下载后解压到D:\memcached(下载地址:memcached-win64下载地址) 2.安装到windows服务,打开cmd命令 ...
- push自定义动画
// // ViewController.m // ViewControllerAnimation // // Created by mac on 15/5/26. // Copyright ...
- 帆软报表(finereport) 饼图联动
饼图联动:点击饼图1,饼图2和饼图3显示饼图1的关联数据,接着点击饼图2,饼图3显示饼图2的关联数据,点击上方清除级联,饼图则恢复默认展示状态 下面以上图示例效果为例,说明制作过程. 1.为每个饼图准 ...
- C#字符串Base64编解码
C#字符串Base64编解码 首先讲一下什么是Base64编码所谓Base64就是一种基于64个可打印字符来表示二进制数据的方法.Base64编码是从二进制到字符的过程,常用于在网络上传输不可见字符( ...