pandas 取 groupby 后每个分组的前 N 行
原始数据如下:
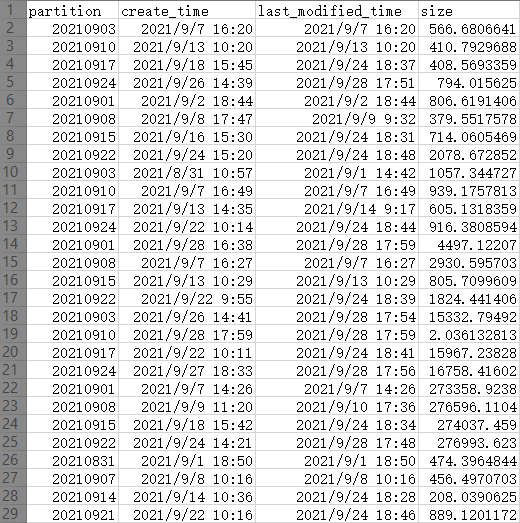
(图是从 excel 截的,最左1行不是数据,是 excel 自带的行号,为了方便说明截进来的)
除去首行是标题外,有效数据为 28行 x 4列
目前的需求是根据 partition 分组,然后取每组的前 2 行,如果不考虑排序,代码如下:
(把head()里面的数字改成 n 就可以取 n 行)
import pandas as pd
esp_df = pd.read_excel('excel文件路径', sheet_name='Sheet名')
esp_df.groupby(['partition', 'create_time', 'last_modified_time']).mean().reset_index(drop=False).groupby('partition').head(2)
结果如下:
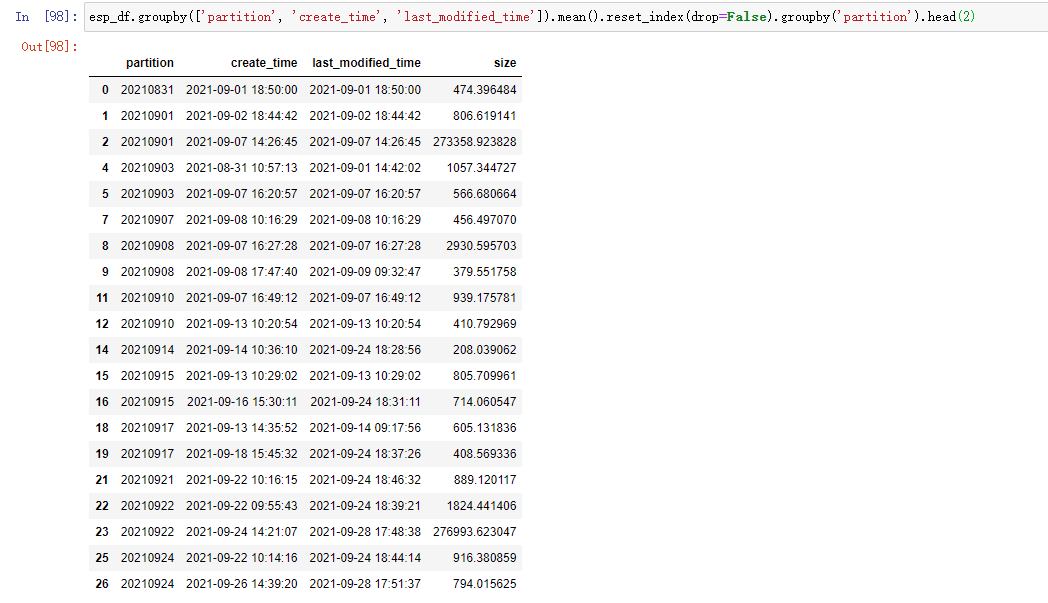
分别说明如下:
- groupby:分组,这里是根据数据中的 3 列来一起分组,因为我们并不需要做聚合运算,所以这么取可以保留原始数据不变。原始数据只有 4 列,这里 groupby 了 3 列,只剩下 size(其实把 size 放进去一起 groupby 也没问题)
- mean:求平均值,但是在这里没用,因为上一步的 groupby 取了前面的 3 列,在本例中,前 3 列并在一起就能得到一个唯一的一行,所以这里其实也只是每一行数据自己求平均数,结果等于它本身。同理,这里替代成求和函数
sum()也是一样的。但是不能省略,因为**省略后它就是一个DataFrameGroupBy类型的变量,不是DataFrame,而DataFrameGroupBy是没有后面的reset_index方法的 - reset_index:重置索引,groupby 之后,结果集的索引就变成了 groupby 里面的 key,这个
reset_index把这个索引重新退回为数据。
举例说明,在应用reset_index之前,即使用mean()之后的数据是这样的:

可以看到左边的 3 列,也就是 groupby key 的 partition、create_time、last_modified_time 是加粗了的,说明此时这 3 列都是索引;而且 partition 因为有相同的行,还被合并了。显然这不是我们想要的。reset_index 把它们重新放回到数据列里

参数中的 drop 作用是是否保留(重置前)的索引
数据就又回来了,索引变成了原来默认的(0123...)
- groupby:再次根据 partition 分组
- head: 取每个分组的前 n 行
如果要排序
本例中,如果要先根据 partition 分组,然后再根据 size 倒序(从大到小)再取前 2 行,则代码如下:
esp_df.groupby(['partition']).apply(lambda x: x.sort_values(["size"], ascending = False)).reset_index(drop=True).groupby('partition').head(2)
结果如下:

pandas 取 groupby 后每个分组的前 N 行的更多相关文章
- 第十三节:pandas之groupby()分组
1.Series()对象分组 1.1.单级索引 1.2.多级索引 2.DataFrame()对象分组 3.获取一个分组,遍历分组,filter过滤.
- pandas之groupby分组与pivot_table透视
一.groupby 类似excel的数据透视表,一般是按照行进行分组,使用方法如下. df.groupby(by=None, axis=0, level=None, as_index=True, so ...
- sql-实现select取行号、分组后在分组内排序、每个分组中的前n条数据
表结构设计: 实现select取行号 sql局部变量的2种方式 set @name='cm3333f'; select @id:=1; 区别:set 可以用=号赋值,而select 不行,必须使用:= ...
- pandas获取groupby分组里最大值所在的行,获取第一个等操作
pandas获取groupby分组里最大值所在的行 10/May 2016 python pandas pandas获取groupby分组里最大值所在的行 如下面这个DataFrame,按照Mt分组, ...
- Pandas之groupby分组
释义 groupby用来分组,调用groupby 之后返回pandas.core.groupby.generic.DataFrameGroupBy,其实就是由一个个格式为(key, 分组后的dataf ...
- sql server 分组,取每组的前几行数据
sql中group by后,获取每组中的前N行数据,目前我知道的有2种方法 比如有个成绩表: 里面有字段学生ID,科目,成绩.我现在想取每个科目的头三名. 1. 子查询 select * from ...
- mysql分组取最大(最小、最新、前N条)条记录
在数据库开发过程中,我们要为每种类型的数据取出前几条记录,或者是取最新.最小.最大等等,这个该如何实现呢,本文章向大家介绍如何实现mysql分组取最大(最小.最新.前N条)条记录.需要的可以参考一下. ...
- pandas之groupby分组与pivot_table透视表
zhuanzi: https://blog.csdn.net/qq_33689414/article/details/78973267 pandas之groupby分组与pivot_table透视表 ...
- Pandas系列(九)-分组聚合详解
目录 1. 将对象分割成组 1.1 关闭排序 1.2 选择列 1.3 遍历分组 1.4 选择一个组 2. 聚合 2.1 一次应用多个聚合操作 2.2 对DataFrame列应用不同的聚合操作 3. t ...
随机推荐
- 证明:(a,[b,c]) = [(a,b),(a,c)]
这题是潘承洞.潘承彪所著<初等数论>(第三版)第一章第5节里一个例题,书中采用算术基本定理证明,并指出要直接用第4节的方法来证是较困难的. 现采用第4节的方法(即最大公约数理论里的几个常用 ...
- Linux 单实例oracle安装步骤
一.查看逻辑盘大小,执行 lsblk 二.查看硬盘及分区信息 ,执行 fdisk -l 三.将物理硬盘分区初始化为物理卷,以便LVM使用 ,创建pv pvcreate /dev/sdb 四.查看物理卷 ...
- 对于MySQL远程连接中出现的一个问题总结
2021年9月3日更新补充 (真的心累,本来是个小问题,但是网上帖子都基本差不多,基本都是相同的操作,导致搜了半个多小时才解决) 一.首先为什么要重新发一次呢,因为我发现上次写的这个记录是不完善甚至是 ...
- Spring笔记(2)
一.AOP简介 1.概念: 面向切面编程(Aspect-Oriented Programming),可以说是OOP(Object-Oriented Programing,面向对象编程)的补充和完善. ...
- vue之 分页封装
npm 下载 npm i element-ui -S components 创建 Page 文件夹 创建 Page.vue 文件 vue 文件 <template> <div c ...
- 学习Linux tar 命令:最简单也最困难
摘要:在本文中,您将学习与tar 命令一起使用的最常用标志.如何创建和提取 tar 存档以及如何创建和提取 gzip 压缩的 tar 存档. 本文分享自华为云社区<Linux 中的 Tar 命令 ...
- Vue 2.0 与 Vue 3.0 响应式原理比较
Vue 2.0 的响应式是基于Object.defineProperty实现的 当你把一个普通的 JavaScript 对象传入 Vue 实例作为 data 选项,Vue 将遍历此对象所有的 prop ...
- 微信支付 V3 开发教程(一):初识 Senparc.Weixin.TenPayV3
前言 我在 9 年前发布了 Senparc.Weixin SDK 第一个开源版本,一直维护至今,如今 Stras 已经破 7K,这一路上得到了 .NET 社区的积极响应和支持,也受到了非常多的宝贵建议 ...
- Python - 面向对象编程 - 小实战(1)
题目 设计一个类Person,生成若干实例,在终端输出如下信息 小明,10岁,男,上山去砍柴 小明,10岁,男,开车去东北 小明,10岁,男,最爱大保健 老李,90岁,男,上山去砍柴 老李,90岁,男 ...
- Identity用户管理入门三(注册用户)
用户注册主要有2个方法,1.密码加密 2.用户注册 3.ASP.NET Core Identity 使用密码策略.锁定和 cookie 配置等设置的默认值. 可以在类中重写这些设置 Startup(官 ...