Netty数据如何在 pipeline 中流动
前言
在之前文章中,我们已经了解了pipeline在netty中所处的角色,像是一条流水线,控制着字节流的读写,本文,我们在这个基础上继续深挖pipeline在事件传播
Unsafe对象
顾名思义,unsafe是不安全的意思,就是告诉你不要在应用程序里面直接使用Unsafe以及他的衍生类对象。
netty官方的解释如下
❝
Unsafe operations that should never be called from user-code. These methods are only provided to implement the actual transport, and must be invoked from an I/O thread
❞
Unsafe 在Channel定义,属于Channel的内部类,表明Unsafe和Channel密切相关
下面是unsafe接口的所有方法
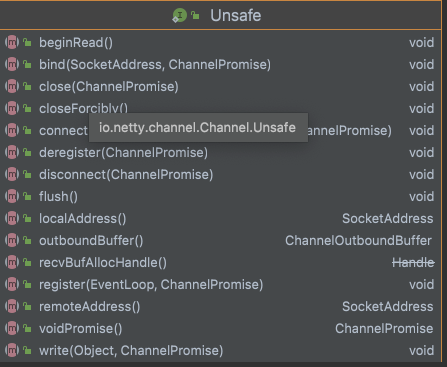
按功能可以分为分配内存,Socket四元组信息,注册事件循环,绑定网卡端口,Socket的连接和关闭,Socket的读写,看的出来,这些操作都是和jdk底层相关
Unsafe 继承结构
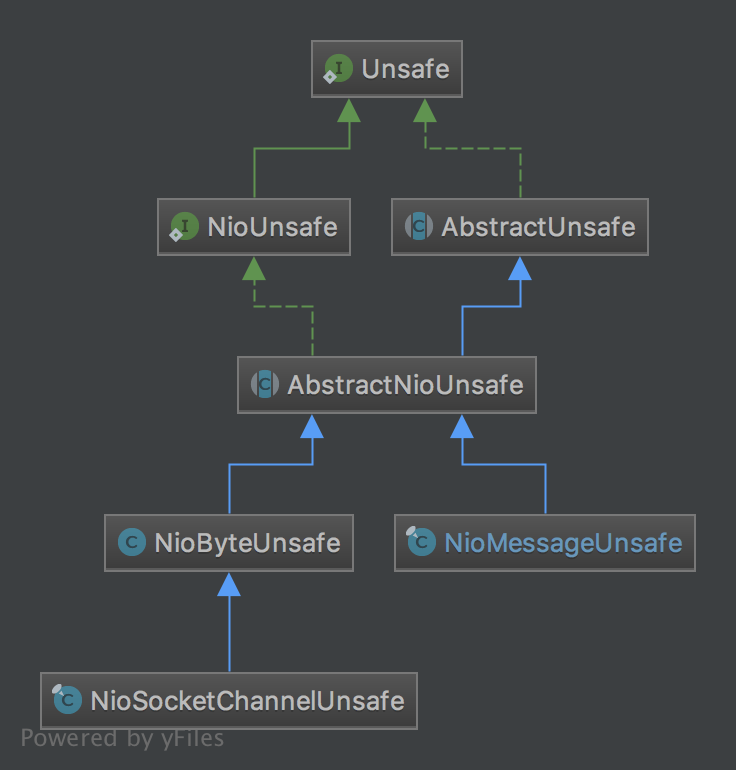
NioUnsafe 在 Unsafe基础上增加了以下几个接口
public interface NioUnsafe extends Unsafe {
SelectableChannel ch();
void finishConnect();
void read();
void forceFlush();
}
从增加的接口以及类名上来看,NioUnsafe 增加了可以访问底层jdk的SelectableChannel的功能,定义了从SelectableChannel读取数据的read方法
Unsafe的分类:
从以上继承结构来看,我们可以总结出两种类型的Unsafe分类,一个是与连接的字节数据读写相关的NioByteUnsafe(后面讲解),一个是与新连接建立操作相关的NioMessageUnsafe(之前文章讲过)
「NioByteUnsafe中的读:委托到外部类NioSocketChannel」
protected int doReadBytes(ByteBuf byteBuf) throws Exception {
final RecvByteBufAllocator.Handle allocHandle = unsafe().recvBufAllocHandle();
allocHandle.attemptedBytesRead(byteBuf.writableBytes());
return byteBuf.writeBytes(javaChannel(), allocHandle.attemptedBytesRead());
}
最后一行已经与jdk底层以及netty中的ByteBuf相关,将jdk的 SelectableChannel的字节数据读取到netty的ByteBuf中
「NioMessageUnsafe中的读:委托到外部类NioSocketChannel」
protected int doReadMessages(List<Object> buf) throws Exception {
SocketChannel ch = javaChannel().accept();
if (ch != null) {
buf.add(new NioSocketChannel(this, ch));
return 1;
}
return 0;
}
用于处理链接事件,之前分析过。
「NioByteUnsafe中的写:委托到外部类NioSocketChannel」
@Override
protected int doWriteBytes(ByteBuf buf) throws Exception {
final int expectedWrittenBytes = buf.readableBytes();
return buf.readBytes(javaChannel(), expectedWrittenBytes);
}
最后一行已经与jdk底层以及netty中的ByteBuf相关,将netty的ByteBuf中的字节数据写到jdk的 SelectableChannel中
pipeline中的head
「NioEventLoop」
private void processSelectedKey(SelectionKey k, AbstractNioChannel ch) {
final AbstractNioChannel.NioUnsafe unsafe = ch.unsafe();
//新连接的已准备接入或者已存在的连接有数据可读
if ((readyOps & (SelectionKey.OP_READ | SelectionKey.OP_ACCEPT)) != 0 || readyOps == 0) {
unsafe.read();
}
}
「NioByteUnsafe」
@Override
public final void read() {
final ChannelConfig config = config();
final ChannelPipeline pipeline = pipeline();
// 创建ByteBuf分配器
final ByteBufAllocator allocator = config.getAllocator();
final RecvByteBufAllocator.Handle allocHandle = recvBufAllocHandle();
allocHandle.reset(config);
ByteBuf byteBuf = null;
do {
// 分配一个ByteBuf
byteBuf = allocHandle.allocate(allocator);
// 将数据读取到分配的ByteBuf中去
allocHandle.lastBytesRead(doReadBytes(byteBuf));
if (allocHandle.lastBytesRead() <= 0) {
byteBuf.release();
byteBuf = null;
close = allocHandle.lastBytesRead() < 0;
break;
}
// 触发事件,将会引发pipeline的读事件传播
pipeline.fireChannelRead(byteBuf);
byteBuf = null;
} while (allocHandle.continueReading());
pipeline.fireChannelReadComplete();
}
同样,我抽出了核心代码,细枝末节先剪去,NioByteUnsafe 要做的事情可以简单地分为以下几个步骤
拿到Channel的config之后拿到ByteBuf分配器,用分配器来分配一个ByteBuf,ByteBuf是netty里面的字节数据载体,后面读取的数据都读到这个对象里面 将Channel中的数据读取到ByteBuf 数据读完之后,调用 pipeline.fireChannelRead(byteBuf); 从head节点开始传播至整个pipeline 最后调用fireChannelReadComplete();
这里,我们的重点其实就是 pipeline.fireChannelRead(byteBuf);
「DefaultChannelPipeline」
final AbstractChannelHandlerContext head;
//...
head = new HeadContext(this);
public final ChannelPipeline fireChannelRead(Object msg) {
AbstractChannelHandlerContext.invokeChannelRead(head, msg);
return this;
}
结合这幅图
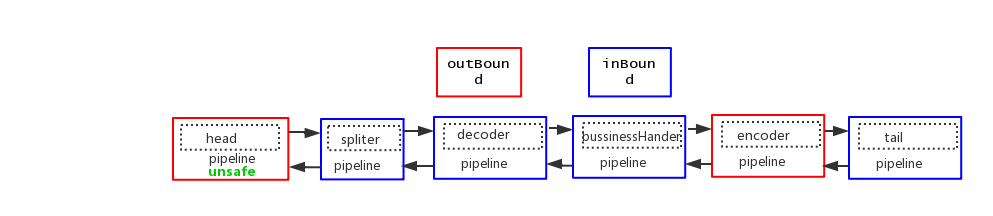
可以看到,数据从head节点开始流入,在进行下一步之前,我们先把head节点的功能过一遍
「HeadContext」
final class HeadContext extends AbstractChannelHandlerContext
implements ChannelOutboundHandler, ChannelInboundHandler {
private final Unsafe unsafe;
HeadContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, HEAD_NAME, false, true);
unsafe = pipeline.channel().unsafe();
setAddComplete();
}
@Override
public ChannelHandler handler() {
return this;
}
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception {
// NOOP
}
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception {
// NOOP
}
@Override
public void bind(
ChannelHandlerContext ctx, SocketAddress localAddress, ChannelPromise promise)
throws Exception {
unsafe.bind(localAddress, promise);
}
@Override
public void connect(
ChannelHandlerContext ctx,
SocketAddress remoteAddress, SocketAddress localAddress,
ChannelPromise promise) throws Exception {
unsafe.connect(remoteAddress, localAddress, promise);
}
@Override
public void disconnect(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.disconnect(promise);
}
@Override
public void close(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.close(promise);
}
@Override
public void deregister(ChannelHandlerContext ctx, ChannelPromise promise) throws Exception {
unsafe.deregister(promise);
}
@Override
public void read(ChannelHandlerContext ctx) {
unsafe.beginRead();
}
@Override
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
@Override
public void flush(ChannelHandlerContext ctx) throws Exception {
unsafe.flush();
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
ctx.fireExceptionCaught(cause);
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception {
invokeHandlerAddedIfNeeded();
ctx.fireChannelRegistered();
}
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelUnregistered();
// Remove all handlers sequentially if channel is closed and unregistered.
if (!channel.isOpen()) {
destroy();
}
}
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelActive();
readIfIsAutoRead();
}
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelInactive();
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelReadComplete();
readIfIsAutoRead();
}
private void readIfIsAutoRead() {
if (channel.config().isAutoRead()) {
channel.read();
}
}
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
ctx.fireUserEventTriggered(evt);
}
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception {
ctx.fireChannelWritabilityChanged();
}
}
从head节点继承的两个接口看,TA既是一个ChannelHandlerContext,同时又属于inBound和outBound Handler
在传播读写事件的时候,head的功能只是简单地将事件传播下去,如ctx.fireChannelRead(msg);
在真正执行读写操作的时候,例如在调用writeAndFlush()等方法的时候,最终都会委托到unsafe执行,而当一次数据读完,channelReadComplete方法会被调用
pipeline中的inBound事件传播
我们接着上面的 AbstractChannelHandlerContext.invokeChannelRead(head, msg); 这个静态方法看,参数传入了 head,我们知道入站数据都是从 head 开始的,以保证后面所有的 handler 都由机会处理数据流。
我们看看这个静态方法内部是怎么样的:
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
public void run() {
next.invokeChannelRead(m);
}
});
}
}
调用这个 Context (也就是 head) 的 invokeChannelRead 方法,并传入数据。我们再看看head中 invokeChannelRead 方法的实现,实际上是在headContext的父类AbstractChannelHandlerContext中:
「AbstractChannelHandlerContext」
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}
public ChannelHandler handler() {
return this;
}
上面 handler()就是headContext中的handler,也就是headContext自身,也就是调用 head 的 channelRead 方法。那么这个方法是怎么实现的呢?
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
ctx.fireChannelRead(msg);
}
什么都没做,调用 Context 的 fire 系列方法,将请求转发给下一个节点。我们这里是 fireChannelRead 方法,注意,这里方法名字都挺像的。需要细心区分。下面我们看看 Context 的成员方法 fireChannelRead:
「AbstractChannelHandlerContext」
@Override
public ChannelHandlerContext fireChannelRead(final Object msg) {
invokeChannelRead(findContextInbound(), msg);
return this;
}
这个是 head 的抽象父类 AbstractChannelHandlerContext 的实现,该方法再次调用了静态 fire 系列方法,但和上次不同的是,不再放入 head 参数了,而是使用 findContextInbound 方法的返回值。从这个方法的名字可以看出,是找到入站类型的 handler。我们看看方法实现:
private AbstractChannelHandlerContext findContextInbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.next;
} while (!ctx.inbound);
return ctx;
}
该方法很简单,找到当前 Context 的 next 节点(inbound 类型的)并返回。这样就能将请求传递给后面的 inbound handler 了。我们来看看 invokeChannelRead(findContextInbound(), msg);
static void invokeChannelRead(final AbstractChannelHandlerContext next, Object msg) {
final Object m = next.pipeline.touch(ObjectUtil.checkNotNull(msg, "msg"), next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
next.invokeChannelRead(m);
} else {
executor.execute(new Runnable() {
public void run() {
next.invokeChannelRead(m);
}
});
}
}
上面我们找到了next节点(inbound类型的),然后直接调用 next.invokeChannelRead(m);如果这个next是我们自定义的handler,此时我们自定义的handler的父类是AbstractChannelHandlerContext,则又回到了AbstractChannelHandlerContext中实现的invokeChannelRead,代码如下:
「AbstractChannelHandlerContext」
private void invokeChannelRead(Object msg) {
if (invokeHandler()) {
try {
((ChannelInboundHandler) handler()).channelRead(this, msg);
} catch (Throwable t) {
notifyHandlerException(t);
}
} else {
fireChannelRead(msg);
}
}
public ChannelHandler handler() {
return this;
}
此时的handler()就是我们自定义的handler了,然后调用我们自定义handler中的 channelRead(this, msg);
请求进来时,pipeline 会从 head 节点开始输送,通过配合 invoker 接口的 fire 系列方法,实现 Context 链在 pipeline 中的完美传递。最终到达我们自定义的 handler。
❝
此时如果我们想继续向后传递该怎么办呢?我们前面说过,可以调用 Context 的 fire 系列方法,就像 head 的 channelRead 方法一样,调用 fire 系列方法,直接向后传递就 ok 了。
❞
如果所有的handler都调用了fire系列方法,则会传递到最后一个inbound类型的handler,也就是——tail节点,那我们就来看看tail节点
pipeline中的tail
final class TailContext extends AbstractChannelHandlerContext implements ChannelInboundHandler {
TailContext(DefaultChannelPipeline pipeline) {
super(pipeline, null, TAIL_NAME, true, false);
setAddComplete();
}
@Override
public ChannelHandler handler() {
return this;
}
@Override
public void channelRegistered(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelUnregistered(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelActive(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelInactive(ChannelHandlerContext ctx) throws Exception { }
@Override
public void channelWritabilityChanged(ChannelHandlerContext ctx) throws Exception { }
@Override
public void handlerAdded(ChannelHandlerContext ctx) throws Exception { }
@Override
public void handlerRemoved(ChannelHandlerContext ctx) throws Exception { }
@Override
public void userEventTriggered(ChannelHandlerContext ctx, Object evt) throws Exception {
// This may not be a configuration error and so don't log anything.
// The event may be superfluous for the current pipeline configuration.
ReferenceCountUtil.release(evt);
}
@Override
public void exceptionCaught(ChannelHandlerContext ctx, Throwable cause) throws Exception {
onUnhandledInboundException(cause);
}
@Override
public void channelRead(ChannelHandlerContext ctx, Object msg) throws Exception {
onUnhandledInboundMessage(msg);
}
@Override
public void channelReadComplete(ChannelHandlerContext ctx) throws Exception { }
}
正如我们前面所提到的,tail节点的大部分作用即终止事件的传播(方法体为空)
「channelRead」
protected void onUnhandledInboundMessage(Object msg) {
try {
logger.debug(
"Discarded inbound message {} that reached at the tail of the pipeline. " +
"Please check your pipeline configuration.", msg);
} finally {
ReferenceCountUtil.release(msg);
}
}
tail节点在发现字节数据(ByteBuf)或者decoder之后的业务对象在pipeline流转过程中没有被消费,落到tail节点,tail节点就会给你发出一个警告,告诉你,我已经将你未处理的数据给丢掉了
总结一下,tail节点的作用就是结束事件传播,并且对一些重要的事件做一些善意提醒.
pipeline中的outBound事件传播
上一节中,我们在阐述tail节点的功能时,忽略了其父类AbstractChannelHandlerContext所具有的功能,这一节中,我们以最常见的writeAndFlush操作来看下pipeline中的outBound事件是如何向外传播的
典型的消息推送系统中,会有类似下面的一段代码
Channel channel = getChannel(userInfo);
channel.writeAndFlush(pushInfo);
这段代码的含义就是根据用户信息拿到对应的Channel,然后给用户推送消息,跟进 channel.writeAndFlush
public ChannelFuture writeAndFlush(Object msg) {
return pipeline.writeAndFlush(msg);
}
从pipeline开始往外传播
public final ChannelFuture writeAndFlush(Object msg) {
return tail.writeAndFlush(msg);
}
Channel 中大部分outBound事件都是从tail开始往外传播, writeAndFlush()方法是tail继承而来的方法,我们跟进去
「AbstractChannelHandlerContext」
public ChannelFuture writeAndFlush(Object msg) {
return writeAndFlush(msg, newPromise());
}
public ChannelFuture writeAndFlush(Object msg, ChannelPromise promise) {
write(msg, true, promise);
return promise;
}
「AbstractChannelHandlerContext」
private void write(Object msg, boolean flush, ChannelPromise promise) {
AbstractChannelHandlerContext next = findContextOutbound();
final Object m = pipeline.touch(msg, next);
EventExecutor executor = next.executor();
if (executor.inEventLoop()) {
if (flush) {
next.invokeWriteAndFlush(m, promise);
} else {
next.invokeWrite(m, promise);
}
} else {
AbstractWriteTask task;
if (flush) {
task = WriteAndFlushTask.newInstance(next, m, promise);
} else {
task = WriteTask.newInstance(next, m, promise);
}
safeExecute(executor, task, promise, m);
}
}
先调用findContextOutbound()方法找到下一个outBound()节点
「AbstractChannelHandlerContext」
private AbstractChannelHandlerContext findContextOutbound() {
AbstractChannelHandlerContext ctx = this;
do {
ctx = ctx.prev;
} while (!ctx.outbound);
return ctx;
}
找outBound节点的过程和找inBound节点类似,反方向遍历pipeline中的双向链表,直到第一个outBound节点next,然后调用next.invokeWriteAndFlush(m, promise)
「AbstractChannelHandlerContext」
private void invokeWriteAndFlush(Object msg, ChannelPromise promise) {
if (invokeHandler()) {
invokeWrite0(msg, promise);
invokeFlush0();
} else {
writeAndFlush(msg, promise);
}
}
调用该节点的ChannelHandler的write方法,flush方法我们暂且忽略,后面会专门讲writeAndFlush的完整流程
「AbstractChannelHandlerContext」
private void invokeWrite0(Object msg, ChannelPromise promise) {
try {
((ChannelOutboundHandler) handler()).write(this, msg, promise);
} catch (Throwable t) {
notifyOutboundHandlerException(t, promise);
}
}
可以看到,数据开始出站,从后向前开始流动,和入站的方向是反的。那么最后会走到哪里呢,当然是走到 head 节点,因为 head 节点就是 outbound 类型的 handler。
「HeadContext」
public void write(ChannelHandlerContext ctx, Object msg, ChannelPromise promise) throws Exception {
unsafe.write(msg, promise);
}
调用了 底层的 unsafe 操作数据,这里,加深了我们对head节点的理解,即所有的数据写出都会经过head节点
当执行完这个 write 方法后,方法开始退栈。逐步退到 unsafe 的 read 方法,回到最初开始的地方,然后继续调用 pipeline.fireChannelReadComplete() 方法。
总结
调用 pipeline 的 fire 系列方法,这些方法是接口 invoker 设计的,pipeline 实现了 invoker 的所有方法,inbound 事件从 head 开始流入,outbound 事件从 tail 开始流出。 pipeline 会将请求交给 Context,然后 Context 通过抽象父类 AbstractChannelHandlerContext 的 invoke 系列方法(静态和非静态的)配合 AbstractChannelHandlerContext 的 fire 系列方法再配合 findContextInbound 和 findContextOutbound 方法完成各个 Context 的数据流转。 当入站过程中,调用 了出站的方法,那么请求就不会向后走了。后面的处理器将不会有任何作用。想继续相会传递就调用 Context 的 fire 系列方法,让 Netty 在内部帮你传递数据到下一个节点。如果你想在整个通道传递,就在 handler 中调用 channel 或者 pipeline 的对应方法,这两个方法会将数据从头到尾或者从尾到头的流转一遍。
结束
❝
识别下方二维码!回复: 「
入群」 ,扫码加入我们交流群!
❞


Netty数据如何在 pipeline 中流动的更多相关文章
- Netty源码分析 (五)----- 数据如何在 pipeline 中流动
在上一篇文章中,我们已经了解了pipeline在netty中所处的角色,像是一条流水线,控制着字节流的读写,本文,我们在这个基础上继续深挖pipeline在事件传播 Unsafe 顾名思义,unsaf ...
- MVC如何在Pipeline中接管请求的?
MVC如何在Pipeline中接管请求的? 文章内容 上个章节我们讲到了,可以在HttpModules初始化之前动态添加Route的方式来自定义自己的HttpHandler,最终接管请求的,那MVC是 ...
- MVC之前的那点事儿系列(9):MVC如何在Pipeline中接管请求的?
文章内容 上个章节我们讲到了,可以在HttpModules初始化之前动态添加Route的方式来自定义自己的HttpHandler,最终接管请求的,那MVC是这么实现的么?本章节我们就来分析一下相关的M ...
- 关于Netty Pipeline中Handler的执行顺序问题
原文地址:http://blog.csdn.net/wgyvip/article/details/25637651 最近在学习Netty框架,根据官网的教程学着做了几个小测试,都成功了,后面开始试着写 ...
- 如何在MyEclipse中通过hibernate使用jtds驱动连接数据库,并向数据库添加数据的方法
最近学习了下如何在MyEclipse中通过hibernate使用jtds驱动连接数据库,并向数据库添加数据的方法,虽然MyEclipse中自带了连接数据库的方法,我也尝试了下其他方法,如有不当之处请指 ...
- 160803、如何在ES6中管理类的私有数据
如何在ES6中管理类的私有数据?本文为你介绍四种方法: 在类的构造函数作用域中处理私有数据成员 遵照命名约定(例如前置下划线)标记私有属性 将私有数据保存在WeakMap中 使用Symbol作为私有属 ...
- Electron-vue实战(三)— 如何在Vuex中管理Mock数据
Electron-vue实战(三)— 如何在Vuex中管理Mock数据 作者:狐狸家的鱼 本文链接:Vuex管理Mock数据 GitHub:sueRimn 在vuex中管理mock数据 关于vuex的 ...
- 关于如何在mysql中插入一条数据后,返回这条数据的id
简单的总结一下如何在mysql中出入一条数据后,返回该条数据的id ,假如之后代码需要这个id,这样做起来就变得非常方便,内容如下: <insert id="insertAndGetI ...
- 如何在FineReport中解析数据库内XML文件
在数据库表中,其中字段XML所存的为xml格式数据在表xmltest中.那么在使用该表进行报表制作时,需要将存于xml字段中的值读取出来作为报表数据源. XML每条记录数据格式如下: <Fiel ...
随机推荐
- linux mint 18.1 安装备忘录
本次全新安装mint18.1,遇到一些问题,全部解决,怕日后忘记,再捣鼓琢磨,浪费时间,特记录在此: 一.楷体字体问题 安装完后的mint18.1,显示都是楷体,经请教薄荷论坛高手,可用以下办法解决: ...
- AT3950-[AGC022E]Median Replace【贪心,dp】
正题 题目链接:https://www.luogu.com.cn/problem/AT3950 题目大意 一个包含\(?,0,1\)的长度为奇数的序列,把\(?\)替换为\(0/1\).每次可以选择三 ...
- 位运算符的用法 ----非(!),与(&),或(|),异或(^)
位运算符的用法 ----非(!),与(&),或(|),异或(^) 三种运算符均针对二进制 非!:是一元运算符.对一个二进制的整数按位取反,输入0则输出1,输入1则输出0. 例: 0100 -( ...
- CF911G Mass Change Queries(线段树+暴力)
cf机子真的快. 其实这个题的维护的信息还是很巧妙的. 首先,观察到题目中涉及到,区间修改这个操作,然后最后只查询一次,我们不妨用线段树来维护这个过程. 但是貌似直接维护每个位置的值可能不太好维护. ...
- CF49E Common ancestor(dp+dp+dp)
纪念卡常把自己卡死的一次自闭模拟赛 QWQ 一开始看这个题,以为是个图论,仔细一想,貌似可以直接dp啊. 首先,因为规则只有从两个变为1个,貌似可以用类似区间\(dp\)的方式来\(check\)一段 ...
- 洛谷4630APIO2018铁人两项(圆方树+dp)
QWQ神仙题啊(据说是今年第一次出现圆方树的地方) 首先根据题目,我们就是求对于每一个路径\((s,t)\)他的贡献就是两个点之间的点数,但是图上问题我并没有办法很好的解决... 这时候考虑圆方树,我 ...
- bzoj2064分裂(dp)
题目大意: 给定一个初始集合和目标集合,有两种操作:1.合并集合中的两个元素,新元素为两个元素之和 2.分裂集合中的一个元素,得到的两个新元素之和等于原先的元素.要求用最小步数使初始集合变为目标集合, ...
- Flink Sql 之 Calcite Volcano优化器(源码解析)
Calcite作为大数据领域最常用的SQL解析引擎,支持Flink , hive, kylin , druid等大型项目的sql解析 同时想要深入研究Flink sql源码的话calcite也是必备 ...
- python的参数传递是值传递还是引用传递?都不是!
[写在前面] 参考文章: https://www.cnblogs.com/spring-haru/p/9320493.html[偏理论,对值传递和引用传递作了总结] https://www.cnblo ...
- 原生js-返回顶部
html部分: <body style="height:2000px"> <div id="div1"> 返回顶部 </div&g ...