Spark-寒假-实验2
1. 计算级数
代码:
import scala.io.StdIn
object jishu
{
def main(args:Array[String])
{
var Sum=0.0
println("请输入q的值")
var q:Int=StdIn.readInt()
var i=1.0
while(Sum<q)
{
Sum=Sum+(i+1)/i
i=i+1
}
println("-------------------")
printf("级数的前n项和为:%f \n",Sum)
}
}
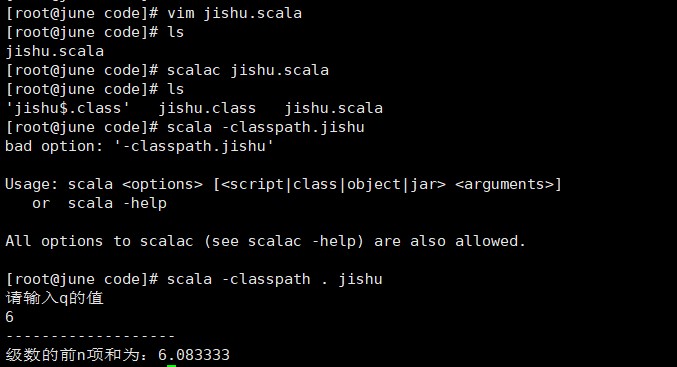
测试截图:
2. 模拟图形绘制
代码:
case class Point(var x:Double,var y:Double) extends Drawable
{
def shift(deltaX:Double,deltaY:Double)
{
x+=deltaX;
y+=deltaY;
}
}
trait Drawable
{
def draw()
{
println(this.toString)
}
}
abstract class Shape(var point :Point)
{
var r =4.0
def moveTo(point2:Point):Unit={
point=point2
}
def zoom(b:Double):Unit
def this(cpoint:Point,cr:Double)
{
this(cpoint:Point)
this.r=cr
}
def this(lpoint:Point,lpoint2:Point)
{
this(lpoint:Point)
}
}
//圆形
class Circle(point: Point,R:Double) extends Shape(point: Point) with Drawable{
r=R
//重写,对图形放大,半径放大
override def zoom(b:Double): Unit = {
r = r * b
}
//重写,打印
override def draw(): Unit ={
var toString="Circle center:("+point.x+","+point.y+")\t"+"R="+r
println(toString)
}
//重写,移动
override def moveTo(point2: Point): Unit ={
point.x=point2.x
point.y=point2.y
}
}
//直线
class Line(point: Point, point1: Point)extends Shape(point: Point) with Drawable{
//重写,对图形放大
override def zoom(b:Double): Unit = {
var xmid=(point1.x+point.x)/2 //寻找中点坐标
var ymid=(point1.y+point.y)/2
point.x=xmid-(xmid-point.x)*b
point.y=ymid-(ymid-point.y)*b
point1.x=xmid+(point1.x-xmid)*b
point1.y=ymid+(point1.y-ymid)*b
}
//重写,打印
override def draw(): Unit ={
var toString="Line:("+point.x+","+point.y+")--"+"("+point1.x+","+point1.y+")"
println(toString)
}
//重写,移动
override def moveTo(point2: Point): Unit ={
point1.x=point1.x+point2.x-point.x
point1.y=point1.y+point2.y-point.y
point.x=point2.x
point.y=point2.y
}
}
object moni {
def main(args: Array[String]) {
val p=new Point(10,30)
p.draw; val line1 = new Line(Point(0,0),Point(20,20))
line1.draw
line1.moveTo(Point(5,5)) //移动到一个新的点
line1.draw
line1.zoom(2) //放大两倍
line1.draw val cir= new Circle(Point(10,10),5)
cir.draw
cir.moveTo(Point(30,20))
cir.draw
cir.zoom(0.5)
cir.draw
}
}
测试结果:

3. 统计学生成绩
代码:
object scoreReport{
def main(args: Array[String]) {
// 假设数据文件在当前目录下,自行更改文件名
val inputFile = scala.io.Source.fromFile("ceshi1.txt")
//”\s+“是字符串正则表达式,将每行按空白字符(包括空格/制表符)分开
// 由于可能涉及多次遍历,同 toList 将 Iterator 装为 List
// originalData 的类型为 List[Array[String]]
val originalData =
inputFile.getLines.map{_.split("\s+")} .toList
val courseNames = originalData.head.drop(2) //获取第一行中的课程名
val allStudents = originalData.tail // 去除第一行剩下的数据
val courseNum = courseNames.length
// 统计函数,参数为需要常用统计的行
//用到了外部变量 courseNum,属于闭包函数
def statistc(lines:List[Array[String]])= {
// for 推导式,对每门课程生成一个三元组,分别表示总分,最低分和最高分
(for(i<- 2 to courseNum+1) yield {
// 取出需要统计的列
val temp = lines map {elem=>elem(i).toDouble}
(temp.sum,temp.min,temp.max)
}) map {case (total,min,max) => (total/lines.length,min,max)
} // 最后一个 map 对 for 的结果进行修改,将总分转为平均分
}
// 输出结果函数
def printResult(theresult:Seq[(Double,Double,Double)]){
// 遍历前调用 zip 方法将课程名容器和结果容器合并,合并结果为二元组容器
(courseNames zip theresult) foreach {
case (course,result)=>
println(f"${course+":"}%-10s${result._1}%5.2f${result._2}%8.2f${r
esult._3}%8.2f")
} }
// 分别调用两个函数统计全体学生并输出结果
val allResult = statistc(allStudents)
println("course average min max")
printResult(allResult)
//按性别划分为两个容器
val (maleLines,femaleLines) = allStudents partition
{_(1)=="male"}
// 分别调用两个函数统计男学生并输出结果
val maleResult = statistc(maleLines)
println("course average min max")
printResult(maleResult)
// 分别调用两个函数统计男学生并输出结果
val femaleResult = statistc(femaleLines)
println("course average min max")
printResult(femaleResult)
}
}
测试截图:


Spark-寒假-实验2的更多相关文章
- 沉淀,再出发——在Hadoop集群的基础上搭建Spark
在Hadoop集群的基础上搭建Spark 一.环境准备 在搭建Spark环境之前必须搭建Hadoop平台,尽管以前的一些博客上说在单机的环境下使用本地FS不用搭建Hadoop集群,可是在新版spark ...
- spark学习及环境配置
http://dblab.xmu.edu.cn/blog/spark/ 厦大数据库实验室博客 总结.分享.收获 实验室主页 首页 大数据 数据库 数据挖掘 其他 子雨大数据之Spark入门教程 林子 ...
- [DE] How to learn Big Data
打开一瞧:50G的文件! emptystacks jobstacks jobtickets stackrequests worker 大数据加数据分析,需要以python+scikit,sql作为基础 ...
- 通过案例对 spark streaming 透彻理解三板斧之一: spark streaming 另类实验
本期内容 : spark streaming另类在线实验 瞬间理解spark streaming本质 一. 我们最开始将从Spark Streaming入手 为何从Spark Streaming切入 ...
- Spark Streaming和Flume-NG对接实验
Spark Streaming是一个新的实时计算的利器,而且还在快速的发展.它将输入流切分成一个个的DStream转换为RDD,从而可以使用Spark来处理.它直接支持多种数据源:Kafka, Flu ...
- 在阿里云上搭建 Spark 实验平台
在阿里云上搭建 Spark 实验平台 Hadoop2.7.3+Spark2.1.0 完全分布式环境 搭建全过程 [传统文化热爱者] 阿里云服务器搭建spark特别坑的地方 阿里云实现Hadoop+Sp ...
- 实验5 Spark SQL编程初级实践
今天做实验[Spark SQL 编程初级实践],虽然网上有答案,但都是用scala语言写的,于是我用java语言重写实现一下. 1 .Spark SQL 基本操作将下列 JSON 格式数据复制到 Li ...
- 2019寒假训练营第三次作业part2 - 实验题
热身题 服务器正在运转着,也不知道这个技术可不可用,万一服务器被弄崩了,那损失可不小. 所以, 决定在虚拟机上试验一下,不小心弄坏了也没关系.需要在的电脑上装上虚拟机和linux系统 安装虚拟机(可参 ...
- 1.Spark Streaming另类实验与 Spark Streaming本质解析
1 Spark源码定制选择从Spark Streaming入手 我们从第一课就选择Spark子框架中的SparkStreaming. 那么,我们为什么要选择从SparkStreaming入手开始我们 ...
- 实验 5 Spark SQL 编程初级实践
实验 5 Spark SQL 编程初级实践 参考厦门大学林子雨 1. Spark SQL 基本操作 将下列 json 数据复制到你的 ubuntu 系统/usr/local/spark 下,并 ...
随机推荐
- WebRTC本地插入多个转发节点
网络延迟是一种比较常见的情况.在本地网页上,我们可以建立多个RTCPeerConnection,增加转发次数,来模拟出网络延迟的效果. 建立通话后,再往后面增加本地转发节点. 准备 页面准备,方便我们 ...
- python enumerate枚举用法总结
enumerate()说明 enumerate()是python的内置函数enumerate在字典上是枚举.列举的意思对于一个可迭代的(iterable)/可遍历的对象(如列表.字符串),enumer ...
- vue常用技巧-动态btn的封装
@1.要求: 1.点击某个按钮后激活active样式,其余按钮则为normal样式 2.要满足任意个数btn(btn个数不确定) @2.思路: 1.首先,btn个数不确定则意味着必须使用v-for循环 ...
- Linux C++获取磁盘剩余空间和可用空间
完整源码 #include <sys/statfs.h> #include <string> #include <iostream> #include <li ...
- c++11之字符串格式化
1.关于 我知道的,C++20中引入了相当方便的字符串格式化,有兴趣的朋友,可以看下fmt库,截至目前,它实现了c++20中引入的字符串格式化绝大部分功能. 2.format 既然c++11中没有方便 ...
- 【LeetCode】163. Missing Ranges 解题报告 (C++)
作者: 负雪明烛 id: fuxuemingzhu 个人博客:http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 遍历 日期 题目地址:https://leetcode ...
- 【LeetCode】682. Baseball Game 解题报告(Python)
作者: 负雪明烛 id: fuxuemingzhu 个人博客: http://fuxuemingzhu.cn/ 目录 题目描述 题目大意 解题方法 使用栈模拟 日期 题目地址:https://leet ...
- 一、SQL高级语句
摘抄别的博主的博客主要总去CSDN看不太方便自己整理一下加深记忆! 导入文件至数据库 #将脚本导入 source 加文件路径 mysql> source /backup/test.sql; se ...
- Netty源码分析之ByteBuf引用计数
引用计数是一种常用的内存管理机制,是指将资源的被引用次数保存起来,当被引用次数变为零时就将其释放的过程.Netty在4.x版本开始使用引用计数机制进行部分对象的管理,其实现思路并不是特别复杂,它主要涉 ...
- 【Azure 应用服务】探索在Azure上设置禁止任何人访问App Service的默认域名(Default URL)
问题描述 总所周知,Azure App Service服务会默认提供一个 ***.chinacloudsites.cn为后缀的域名,但是该域名由上海蓝云网络科技有限公司备案,仅用于向其客户提供 Azu ...