☕【Java技术指南】「编译器专题」重塑认识Java编译器的执行过程(常量优化机制)!
问题概括
静态常量可以再编译器确定字面量,但常量并不一定在编译期就确定了, 也可以在运行时确定,所以Java针对某些情况制定了常量优化机制。
常量优化机制
- 给一个变量赋值,如果等于号的右边是常量的表达式并且没有一个变量,那么就会在编译阶段计算该表达式的结果。
- 然后判断该表达式的结果是否在左边类型所表示范围内。
- 如果在,那么就赋值成功,如果不在,那么就赋值失败。
注意如果一旦有变量参与表达式,那么就不会有编译期间的常量优化机制。
结合问题,我们就可以大致猜出,如果常量能在编译期确定就会有优化,不能的话就不存在。
下面我们来详细讲解一下这个机制,Java中的常量池常量优化机制主要是两方面
就是对于byte/short/char三种类型的常量优化机制
先贴出一张Java八大数据类型大小范围表以供参考:

以下面这个程序为例
byte b1 = 1 + 2;
System.out.println(b1);
// 输出结果 3
运行结果解释:
1和2都是常量,Java有常量优化机制,就是可以编译时可以明显确定常量结果,所以直接把1和2的结果赋值给b1了。(和直接赋值3是一个意思)
换一种情况看看,把右边常量改成变量
byte b1 = 3;
byte b2 = 4;
byte b3 = b1 + b2;
System.out.println(b3); // 程序报错
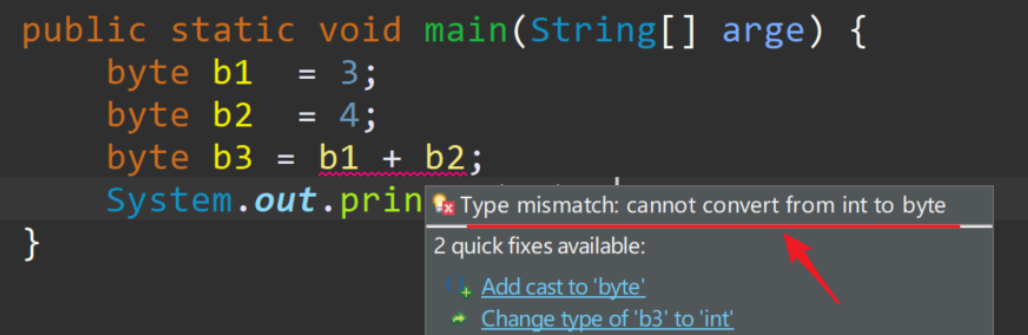
程序报错了,意思说类型不匹配:无法从int转换为byte
解释原因,从两个方面:
byte 与 byte (或者 short char ) 进行运算的时候会提升int 两个int 类型相加的结果也是int 类型
b1 和 b2 是两个变量,变量存储的是变化,在编译的时候无法判断里面的值,相加有可能会超出byte的取值这就是为什么一旦有变量参与表达式,那么就不会有编译期间的常量优化机制。
在这里我们试着把变量添加final改回常量,看看又有什么结果
final byte b1 = 1;
final byte b2 = 2;
byte b3 = b1 + b2;
System.out.println(b3);
发现程序可以正常运行,输出结果为3,所以可知常量优化机制一定是针对常量的。
接下来我们再看另外一个程序
byte b1 = 127 + 2;
System.out.println(b4);
程序再次报错,同样也是类型不匹配:无法从int转换为byte,这里解释一下,byte取值范围为-128~127;很明显右边表达式的结果是否在左边类型所表示范围,这个就是导致此错误出现的原因。
某些场景下,取值范围大的数据类型(int)可以直接赋值给取值范围小的(byte、shor、char),而且只能特定int赋值给byte/short/char,其他基本数据类型不行,如下图。
int num1 = 10;
final int num2 = 10;
byte var1 = num1 + 20; // 存在变量,编译报错
byte var2 = num2 + 20; // 编译通过
这个也是常量优化机制的一部分
所以我们这里总结一下byte/short/char三种类型的常量优化机制
- 先判断值是否是常量, 然后再看值是否在该数据类型的取值范围内
- 只有byte, short, char 可以使用常量优化机制,转换成int类型(这个你换成其他基本数据类型就不适应了)来个程序测试一下,下面这个就是单纯把之前的byte改成了int型,发现并不像之前报错,反而正常运行,输出结果3,所以就说明了只有byte, short, char 可以使用常量优化机制
int a = 1;
int b = 2;
int c = a + b;
System.out.println(c);
拓展一下(易错点):
byte var = 10;
var = var + 20; // 编译报错,运算中存在变量
var += 20; // 等效于: var = (short) (var + 20); 没有走常量优化机制,而是进行了类型转换
就是对于编译器对String类型优化(这个是重点难点)
String s1 = "abc";
String s2 = "a"+"b"+"c";
System.out.println(s1 == s2);
这个输出的结果是多少呢?有人就会认为 “a” + “b”+“c"会生成新的对象"abc”,但是这个对象和String s2 = "abc"不同,(a == b)是比较对象引用,因此不相等,结果为false。
如果你是这样想的话,那恭喜你对java的String有一定了解,但是你不清楚Java的常量池常量优化机制。
这个代码正确输出结果为true!!!
那么到底为什么呢,下面就来解释一下原因:
String s2 = “a” + “b”+“c”;编译器将这个"a" + “b”+“c"作为常量表达式,在编译时进行优化,直接取表达式结果"abc”,这里没有创建新的对象,而是从JVM字符串常量池中获取之前已经存在的"abc"对象。因此a,b具有对同一个string对象的引用,两个引用相等,结果true。
意思是说先通过优化,代码简化为
String s1 = "abc";
String s2 = "abc";
System.out.println(s1 == s2);
再基于jvm对String的处理机制的基础上,得出true的结论。
下面进一步探讨,什么样的String + 表达式会被编译器当成常量表达式?
String b = "a" + "b";
这个String + String被正式是ok的,那么string + 基本类型呢?
String a = "a1";
String b = "a" + 1;
System.out.println((a == b)); //result = true
String a = "atrue";
String b = "a" + true;
System.out.println((a == b)); //result = true
String a = "a3.4";
String b = "a" + 3.4;
System.out.println((a == b)); //result = true
可见编译器对String + 基本类型是当成常量表达式直接求值来优化的。
既然常量弄完了,我们换成变量来试试
String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c";
System.out.println(s3 == s2);
输出的结果是false
这里我们就可以看到常量优化只是针对常量,如果有变量的话就不能被优化
运行原理
String s3 = s1+“c”;这一句话,是在StringBuffer缓冲区中进行创建一个StringBuffer对象,将两者相加。
但是对s3进行赋值时不能够直接将缓冲区的对象地址取来而是用toString方法变成另外的堆内存,然后赋值给s3,所以,s3和s2的地址值已经不同了,所以输出false。
这里我们还可以拓展一下,把s1前面加final修饰符修改为常量看看
final String s1 = "ab";
String s2 = "abc";
String s3 = s1 + "c";
System.out.println(s2 == s3);
输出的结果居然变成了true,看来只要是进入常量池的常量,就有可能存在常量优化机制
再往里走一点,观察下面程序
private static String getS() {
return "b";
}
String s1 = "abc";
String s2 = "a"+getS();
System.out.println((s1 == s2));
结果又是出人意料,竟然是false
运行原理
编译器发现s2值是要调用函数才能计算出来的,是要在运行时才能确定结果的,所以编译器就设置为运行时执行到String s3=“a” + getS();时 要重新分配内存空间,导致s2和s1是指向两个不同的内存地址,所以==比较结果为false;
看来String这个所谓的"对象",完全不可以看成一般的对象,Java对String的处理近乎于基本类型,最大限度的优化了几乎能优化的地方。
我们来举个例子总结一下上面所有内容
public static void main(String[] arge) {
//1
String str1 = new String("1234");
String str2 = new String("1234");
System.out.println("new String()==:" + (str1 == str2));
//2
String str3 = "1234";
String str4 = "1234";
System.out.println("常量字符串==:" + (str3 == str4));
//3
String str5 = "1234";
String str6 = "12" + "34";
System.out.println("常量表达式==:" + (str5 == str6));
//4
String str7 = "1234";
String str8 = "12";
String str9 = str8 + "34";
System.out.println("字符串和变量相加的表达式==:" + (str7 == str9));
//5
final String val = "34";
String str10 = "1234";
String str11 = "12" + val;
System.out.println("字符串和常量相加的表达式==:" + (str10 == str11));
//6
String str12 = "1234";
String str13 = "12" + 34;
System.out.println("字符串和数字相加的表达式==:" + (str12 == str13));
//7
String str14 = "12true";
String str15 = "12" + true;
System.out.println("字符串和Boolen相加表达式==:" + (str14 == str15));
//8
String str16 = "1234";
String str17 = "12" + getVal();
System.out.println("字符串和函数得来的常量相加表达式==:" + (str16 == str17));
}
private static String getVal()
{
return "34";
}
运行输出:
new String()==:false
常量字符串==:true
常量表达式==:true
字符串和变量相加的表达式==:false
字符串和常量相加的表达式==:true
字符串和数字相加的表达式==:true
字符串和Boolen相加表达式==:true
字符串和函数得来的常量相加表达式==:false
代码分析:
Java中,String是引用类型;是关系运算符,比较两个引用类型时,判断的依据是:双方是否是指向了同一个内存地址。
(1)String为引用类型,str1和str2为新实例化出来的对象,分别指向不同的内存地址。而==对于引用类型判断,是判断的是引用地址,所以例子1结果为false。
(2)对于第二个例子,编译器编译代码时,会将”1234”当做一个常量,并保存在JVM的常量池中,然后编译String str3=”1234”;时,将常量的指针赋值给str3,在编译String str4=”1234”;时,编译器查找常量池里有没有值相同的常量,如果有就将存在的常量赋给str4,这样结果就是str3和str4都指向了常量池中的常量的地址,所以==比较结果为true;
(3)第三个例子,编译时编译器发现能够计算出”12”+”34”的值,它是个常量,就按照第二个例子一样处理,最终str5和str6都指向了同一个内存地址。所以==比较结果为true;
(4)第四个例子,常量优化只针对常量,String str9 = str8 + “34”;这一句话,str9的值在运行时才能确定结果,是在StringBuffer缓冲区中进行创建一个StringBuffer对象,将两者相加。但是对s3进行赋值时不能够直接将缓冲区的对象地址取来而是用toString方法变成另外的堆内存,然后赋值给s3,所以,s3和s2的地址值已经不同了,所以输出false。
(5)第五个例子、第六个例子和第七个例子,类似第三个例子,编译时编译器发现能够计算出值,就尽量计算出来,所以==比较结果为true;
(6)第八个例子中,编译器发现str17值是要调用函数才能计算出来的,是要在运行时才能确定结果的,所以编译器就设置为运行时执行到String str17=“12” + getVal();时 要重新分配内存空间,导致str13和str1是指向两个不同的内存地址,所以==比较结果为false;
总结一下
Java语言为字符串连接运算符(+)提供特殊支持,并为其他对象转换为字符串。 字符串连接是通过StringBuilder (或StringBuffer )类及其append方法实现的。 字符串转换是通过方法来实现toString(JDK1.8 api文档) 。(toString方法返回值是String,所以会返回一个String对象)。由于String的不可变性,对其进行操作的效率会大大降低,但对 “+”操作符,编译器对其进行了优化,往通俗来讲,如果编译时能直接得到最终字符串的结果就尽量获得最后的字符串,这样就免于中间创建对象的浪费了。
String str = "a" + "b" + "c"; // 直接等价于 str = "abc";
// 这个就解释了上面为true的所有情况
如果不能直接计算得到最终的字符串,就像上面的例子4一样,str17明显要调用函数才能计算出来的,是要在运行时才能确定结果,那肯定必须的开辟内存创建新的对象。具体就是通过黄色字体所描述的方法
☕【Java技术指南】「编译器专题」重塑认识Java编译器的执行过程(常量优化机制)!的更多相关文章
- 🏆【Java技术专区】「编译器专题」重塑认识Java编译器的执行过程(消除数组边界检查+公共子表达式)!
前提概要 Java的class字节码并不是机器语言,要想让机器能够执行,还需要把字节码翻译成机器指令.这个过程是Java虚拟机做的,这个过程也叫编译.是更深层次的编译. 在编译原理中,把源代码翻译成机 ...
- ☕【Java技术指南】「编译器专题」深入分析探究“静态编译器”(JAVA\IDEA\ECJ编译器)是否可以实现代码优化?
技术分析 大家都知道Eclipse已经实现了自己的编译器,命名为 Eclipse编译器for Java (ECJ). ECJ 是 Eclipse Compiler for Java 的缩写,是 Jav ...
- ☕【Java技术指南】「TestNG专题」单元测试框架之TestNG使用教程指南(上)
TestNG介绍 TestNG是Java中的一个测试框架, 类似于JUnit 和NUnit, 功能都差不多, 只是功能更加强大,使用也更方便. 详细使用说明请参考官方链接:https://testng ...
- ☕【Java技术指南】「JPA编程专题」让你不再对JPA技术中的“持久化型注解”感到陌生了!
JPA的介绍分析 Java持久化API (JPA) 显著简化了Java Bean的持久性并提供了一个对象关系映射方法,该方法使您可以采用声明方式定义如何通过一种标准的可移植方式,将Java 对象映射到 ...
- ☕【Java技术指南】「Guava Collections」实战使用相关Guava不一般的集合框架
Google Guava Collections 使用介绍 简介 Google Guava Collections 是一个对 Java Collections Framework 增强和扩展的一个开源 ...
- SpringBoot图文教程17—上手就会 RestTemplate 使用指南「Get Post」「设置请求头」
有天上飞的概念,就要有落地的实现 概念十遍不如代码一遍,朋友,希望你把文中所有的代码案例都敲一遍 先赞后看,养成习惯 SpringBoot 图文教程系列文章目录 SpringBoot图文教程1-Spr ...
- Java已五年1—二本物理到前端实习生到Java程序员「回忆贴」
关键词:郑州 二本 物理专业 先前端实习生 后Java程序员 更多文章收录在码云仓库:https://gitee.com/bingqilinpeishenme/Java-Tutorials 前言 没有 ...
- Java程序执行过程及内存机制
本讲将介绍Java代码是如何一步步运行起来的,其中涉及的编译器,类加载器,字节码校验器,解释器和JIT编译器在整个过程中是发挥着怎样的作用.此外还会介绍Java程序所占用的内存是被如何管理的:堆.栈和 ...
- ☕【Java技术指南】「并发原理专题」AQS的技术体系之CLH、MCS锁的原理及实现
背景 SMP(Symmetric Multi-Processor) 对称多处理器结构,它是相对非对称多处理技术而言的.应用十分广泛的并行技术. 在这种架构中,一台计算机由多个CPU组成,并共享内存和其 ...
随机推荐
- XCTF easyGo
拖入ida,发现符号表需要还原一下,载入一个还原符号表的脚本. go这个语言就有点恶心,字符串后面没有反斜杆零,ida识别出来,字符串就会挤在一堆,就很难看,看了某位师傅的wp,觉得这方法不错,就记录 ...
- SQL 查询并不是从 SELECT 开始的
原文地址:SQL queries don't start with SELECT 原文作者:Julia Evans(已授权) 译者 & 校正:HelloGitHub-小熊熊 & 卤蛋 ...
- 交换机卡在CPU task进程处理方法
故障现象: 笔记本通过console线连接H3C交换机的console口,无法登陆,敲任何东西都无效.因为没有备份,不敢重启.显示以下报错: <test-sw> wrong input! ...
- [转载]API网关
1. 使用API网关统一应用入口 API网关的核心设计理念是使用一个轻量级的消息网关作为所有客户端的应用入口,并且在 API 网关层面上实现通用的非功能性需求.如下图所示:所有的服务通过 API 网关 ...
- CF1539A Contest Start[题解]
Contest Start 题目大意 有 \(n\) 个人报名参加一个比赛,从 \(0\) 时刻开始每隔 \(x\) 分钟有一个人开始比赛,每个人参赛时间相同,均为 \(t\) .定义一个选手的不满意 ...
- 用EXCEL打开CSV文件
1.打开EXCEL 2.数据--自文本--选择对应的CSV文件 3.设置表头所在的行(例如17行为表头)则输入17 4.确定分隔符 5.单击"确定"即可
- 1.在配置XML文件时出现reference file contains errors (http://www.springframework.org/schema/beans/...解决方案
解决方案: 第一步:将 Preferences > XML > XML Files > Validation中"Honour all XML schema location ...
- fork、父进程和子进程
进程 什么是进程?进程是一个运行中的程序实体,拥有独立的堆栈.内存空间和逻辑控制流. 这是标准的进程概念.让我们通过操作系统的fork函数看看这个抽象的概念是怎么在进程的实现中体现出来的. 构成要素 ...
- PAT乙级:1094 谷歌的招聘 (20分)
PAT乙级:1094 谷歌的招聘 (20分) 题干 2004 年 7 月,谷歌在硅谷的 101 号公路边竖立了一块巨大的广告牌(如下图)用于招聘.内容超级简单,就是一个以 .com 结尾的网址,而前面 ...
- js里的发布订阅模式及vue里的事件订阅实现
发布订阅模式(观察者模式) 发布订阅模式的定义:它定义对象间的一种一对多的依赖关系,当一个对象的状态发生改变时,所有依赖于它的对象都将得到通知. 发布订阅模式在JS中最常见的就是DOM的事件绑定与触发 ...