【论文笔记】 Denoising Implicit Feedback for Recommendation
Denoising Implicit Feedback for Recommendation
Authors: 王文杰,冯福利,何向南,聂礼强,蔡达成
WSDM‘21 新加坡国立大学,中国科学技术大学,山东大学
论文链接:http://staff.ustc.edu.cn/~hexn/papers/WSDM_2021_ADT.pdf,https://arxiv.org/pdf/2006.04153.pdf
本文链接:https://www.cnblogs.com/zihaojun/p/15704005.html
0. 总结
本文主要研究并解决推荐系统的隐式反馈数据中正样本存在噪声,会损害推荐系统性能的问题。
“伪正样本”在推荐系统训练的初始阶段Loss普遍较高,利用这个规律,可以对“伪正样本”和真正的正样本进行区分。
本文提出了适应性去噪训练(Adaptive Denoising Training,ADT)策略来解决上述问题,提出了截断损失函数和加权损失函数两种Loss函数,并基于交叉熵损失,在三个数据集上,基于三种推荐模型进行了实验,实验结果表明,ADT可以有效去除“伪正样本”对模型性能的干扰。
1.问题背景
由于隐式反馈数据量比较大,容易获得,因此隐式反馈数据已经是在线推荐系统的默认训练数据。
但是隐式反馈数据是存在噪声的。隐式反馈的正样本只能反映用户和物品之间存在交互,但是不能反映用户对此次交互的满意度。例如在电商中,用户可能点击了一个物品,但是并没有购买;即使用户购买了,对这个物品可能也是不满意的。
在推荐系统训练过程中,噪声数据可能会损害推荐系统的性能,使得推荐系统捕捉用户兴趣的能力下降。
2.研究目标
在没有用户停留时间、物品特征、用户反馈等额外信息的情况下(这些信息很稀疏,难以获得),识别并去除交互数据中的“伪正样本”,提高推荐系统训练的效率和推荐系统的精度。
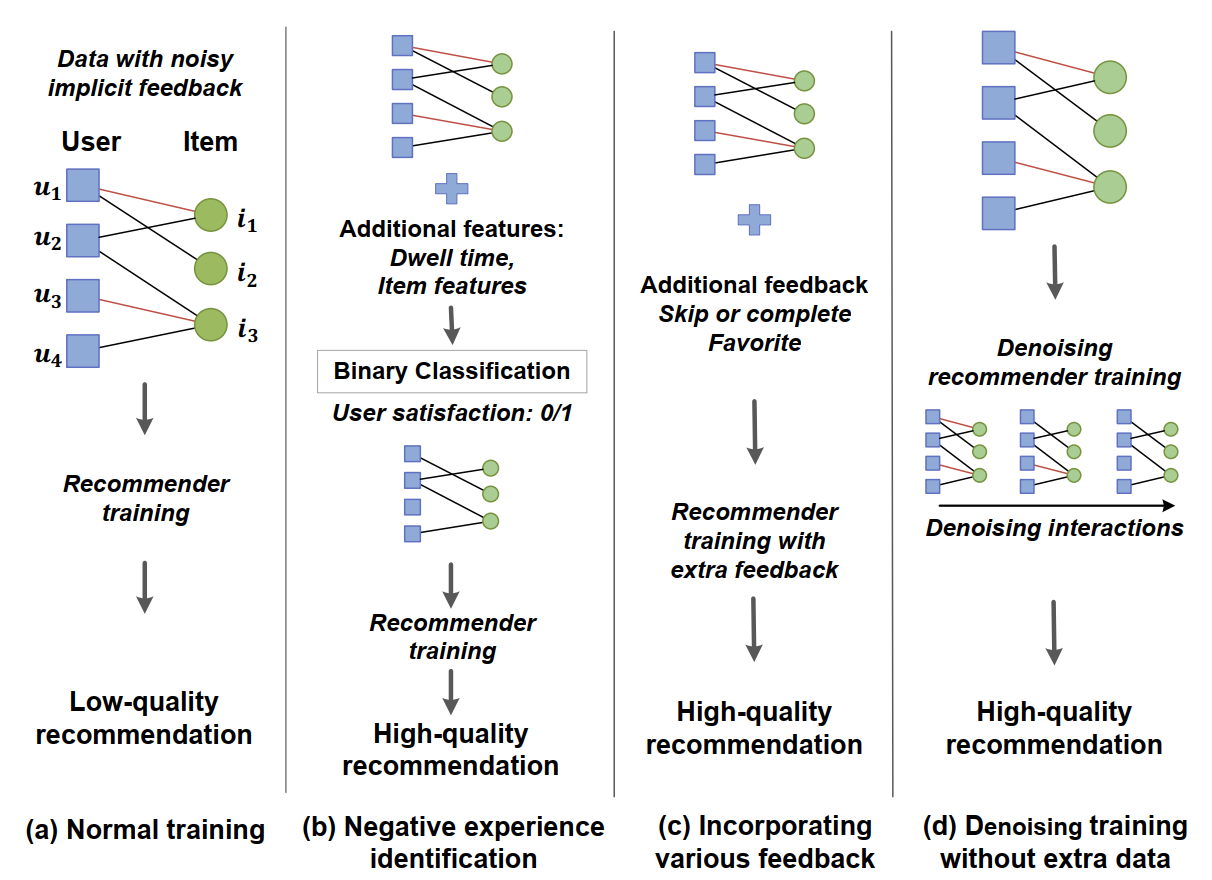
如下图,图中红色的交互代表“伪正样本”,黑色的交互代表“真正样本”。
第一列表示通常的推荐模型,会受到“伪正样本”的干扰,推荐质量差。
第二列和第三列表示利用额外信息来识别“伪正样本”,从而提高推荐质量。
最后一列表示本文提出的框架,在不利用额外信息的条件下,去除“伪正样本”的影响,生成高质量的推荐结果。
3. “伪正样本”研究
为了验证“伪正样本”对推荐性能的影响,基于NeuMF模型,设计如下实验:
- 训练阶段
- 使用所有交互数据(1-5分)的设置称为Normal training
- 只使用3-5分的交互数据(去除“伪正样本”)的设置成为Clean training
- 验证阶段
- 验证集和测试集同样去除1-2分的交互数据,只保留3-5分的交互数据
实验结果表明,Clean training明显优于Normal training,说明“伪正样本”确实会损害推荐系统的性能。
\hline \text { Dataset } & {\text { Adressa }} && {\text { Amazon-book }} \\
\text { Metric } & \text { Recall@20 } & \text { NDCG@20 } & \text { Recall@20 } & \text { NDCG@20 } \\
\hline \hline \text { Clean training } & 0.4040 & 0.1963 & 0.0293 & 0.0159 \\
\text { Normal training } & 0.3081 & 0.1732 & 0.0265 & 0.0145 \\
\hline \text { \#Drop } & 23.74 \% & 11.77 \% & 9.56 \% & 8.81 \% \\
\hline
\end{array}
\]
4. 方法
4.1 Obervations 观察
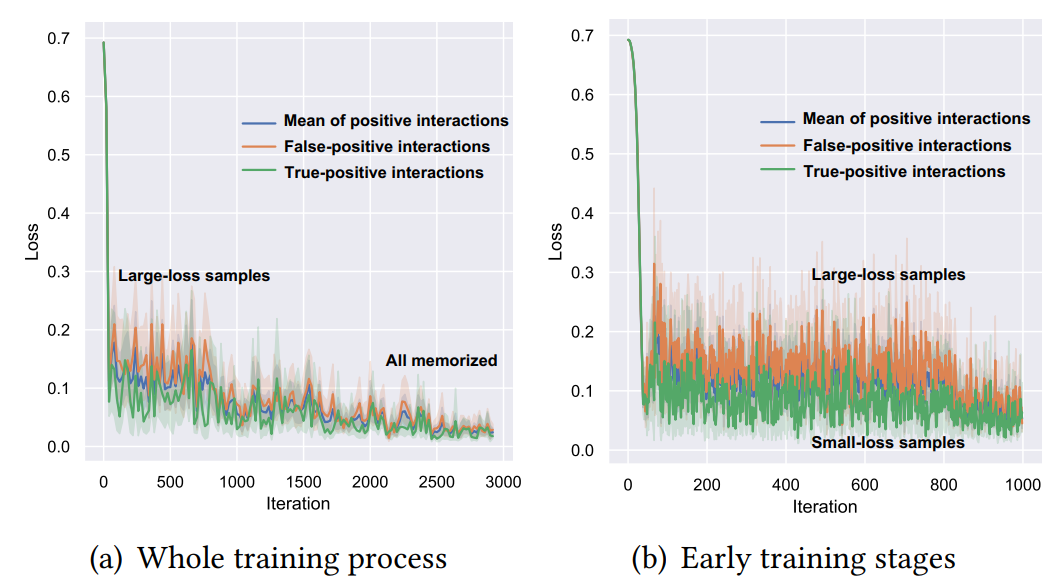
在Adressa数据集上,使用所有交互数据(1-5分)训练NeuMF,分别观察True-positive Interactions和False-positive Interactions的平均loss值。
从下图所示的实验结果中可以看出:
- 在左图所示的完整训练过程中,所有样本的loss最终都收敛到很小的值,说明所有的样本都被模型记住了。
- 在右图表示的训练初始阶段(0-1000 Iteraions),False-positive样本的loss值(橙色)明显高于True-positive的loss值(绿色),这说明在False-positive样本的训练难度明显更高。
这个规律可以用来区分“伪正样本”和“真正样本”。
4.2 Adaptive Denoising Training(ADT) 适应性去噪训练
基于上节中的观察,本文提出ADT模型,根据loss函数来区分“真正样本”和“伪正样本”。
ADT有两种思路:
- 截断loss(Truncated Loss):基于一个动态调整的阈值,将loss比较高的样本loss直接置0,使得这些样本在当前训练轮不参与模型更新。
- 加权loss(Reweighted Loss):给难样本(Loss大的样本)更低的权重。
这两种方法与Loss函数的设计无关,可以被应用到BCE和BPR等多种loss函数上。本文基于BCEloss进行实验。
4.2.1 截断交叉熵损失 Truncated Cross-Entropy Loss(T-CE)
\mathcal{L}_{T-C E}(u, i)= \begin{cases}0, & \mathcal{L}_{C E}(u, i)>\tau \wedge \bar{y}_{u i}=1 \\ \mathcal{L}_{C E}(u, i), & \text { otherwise }\end{cases} \\ \\
\mathcal{L}_{C E}\left(\mathcal{D}^{*}\right)=-\sum_{\left(u, i, y_{u i}^{*}\right) \in \mathcal{D}^{*}} y_{u i}^{*} \log \left(\hat{y}_{u i}\right)+\left(1-y_{u i}^{*}\right) \log \left(1-\hat{y}_{u i}\right)
\end{align}
\]
T-CE Loss将Loss值大于\(\tau\)的正样本损失函数置0,其中\(\tau\)是预定义的值,可以随着训练轮数变化而变化。
为了建模\(\tau\),定义样本淘汰率(drop rate),也就是在第T轮训练中,淘汰loss最高的比例为\(\epsilon(T)\)的样本:
\epsilon(T)=\min \left(\alpha T, \epsilon_{\max }\right)
\end{align}
\]
其中\(\alpha\)和\(\epsilon_{max}\)是超参数。
这样的设计可以保证:
- 样本淘汰率有上限,避免将样本全部舍弃。
- 训练开始时,使用全部样本
- 样本淘汰率从0逐渐增加到上限,使模型逐渐能分清真正样本和假正样本。
4.2.2 加权交叉熵损失函数 Reweighted Cross-Entropy Loss(R-CE)
\mathcal{L}_{R-C E}(u, i)=\omega(u, i) \mathcal{L}_{C E}(u, i)
\end{align}
\]
其中\(\omega(u, i)\)是调整不同样本损失在总损失函数中占比的权重。
\(\omega(u, i)\)应该有以下性质:
- 在训练过程中动态变化
- 使得Loss高的正样本权重更低
- 权重可以通过超参调整,以适用于不同模型和数据集
输出预测值\(\hat{y}_{u i}\)与Loss函数是一一对应的,\(\hat{y}_{u i}\)越低,对应的Loss就越高,则权重应该越低;可以利用\(\hat{y}_{u i}\)来定义\(\omega(u, i)\):
\omega(u, i) = f({\hat{y}_{ui}}) = \hat{y}_{u i}^{\beta}
\end{align}
\]
其中\(\beta\in[0,+\infin]\)是超参数,\(\hat{y}_{ui}\)表示预测值,\(\bar{y}_{ui}\)表示标签值。
Figure 5(a)展示\(\beta\)取不同的值时,Loss函数与预测值\(\hat{y}_{ui}\)的关系,即\(\beta\)越大,难样本(\(\hat{y}_{ui}\)较小)的Loss被压缩的效果越明显;当\(\beta = 0\)时,R-CE退化到普通的CE。
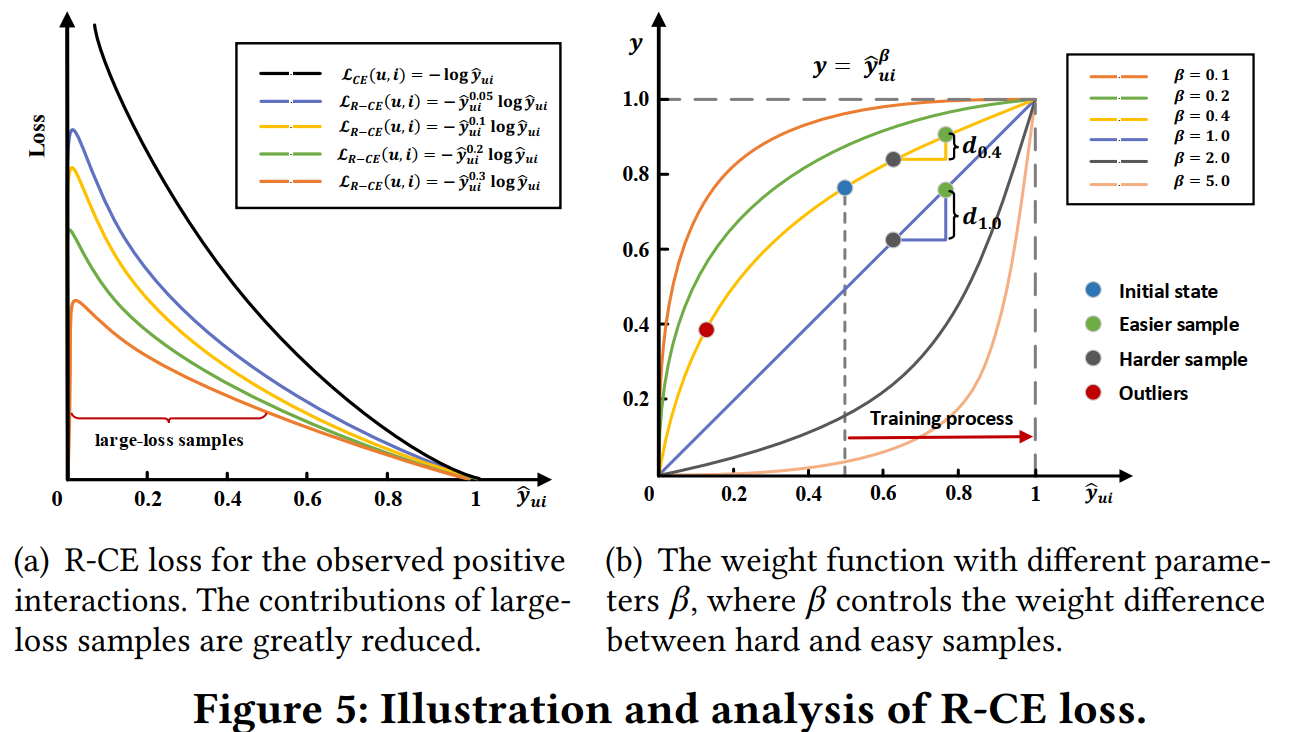
为了保证正负样本Loss值的一致性,给负样本也做了同样的处理:
\omega(u, i)= \begin{cases}\hat{y}_{u i}^{\beta}, & \bar{y}_{u i}=1 \\ \left(1-\hat{y}_{u i}\right)^{\beta}, & \text { otherwise }\end{cases}
\end{align}
\]
5. 实验
5.1 数据集
- Adressa:新闻阅读数据集,包含用户的点击数据和在页面的停留时间;停留少于10s的点击视为“伪正样本”
- Amazon-book:亚马逊评论数据集,包含用户对物品的评分数据;评分低于3分的交互视为“伪正样本”
- Yelp:餐厅评分数据集;评分低于3分的交互视为“伪正样本”
训练集和验证集包含所有交互,测试集只包含“真正样本”。
5.2 实验结果
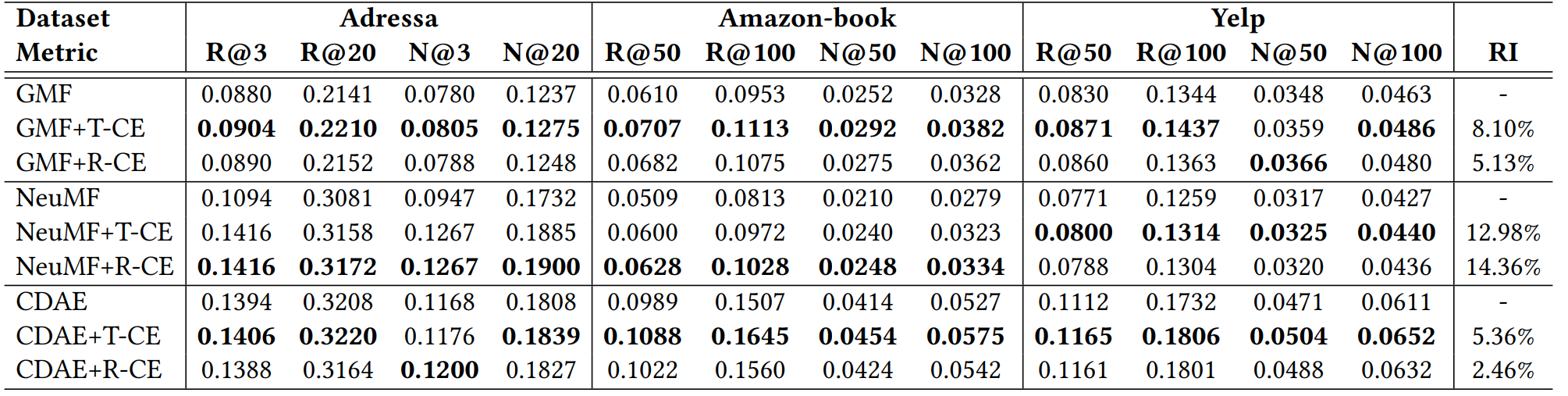
- 在三种推荐模型上,T-CE和R-CE Loss都提升了推荐性能,证明了方法的有效性
- 比较T-CE和R-CE两种方法,T-CE的性能一般会更好。这是因为T-CE直接去除了难样本的影响,并多了一个超参数。
- NeuMF的性能比GMF还低,这是因为训练数据中有“伪正样本”,NeuMF的拟合能力更强,学到了这些噪声信息。
- T-CE和R-CE都在NeuMF上取得了最大的性能提升,这与上一条结论一致——NMF受到“伪正样本”的影响更大。T-CE和R-CE在CDAE上面仍然有性能提升,证明了本文的方法的合理性。
为了验证本文的方法是否会损害不活跃用户的推荐精度,本文将用户按照交互数量分为四组。实验结果表明,即便是交互数量很少的用户组,推荐精度也得到了提升。
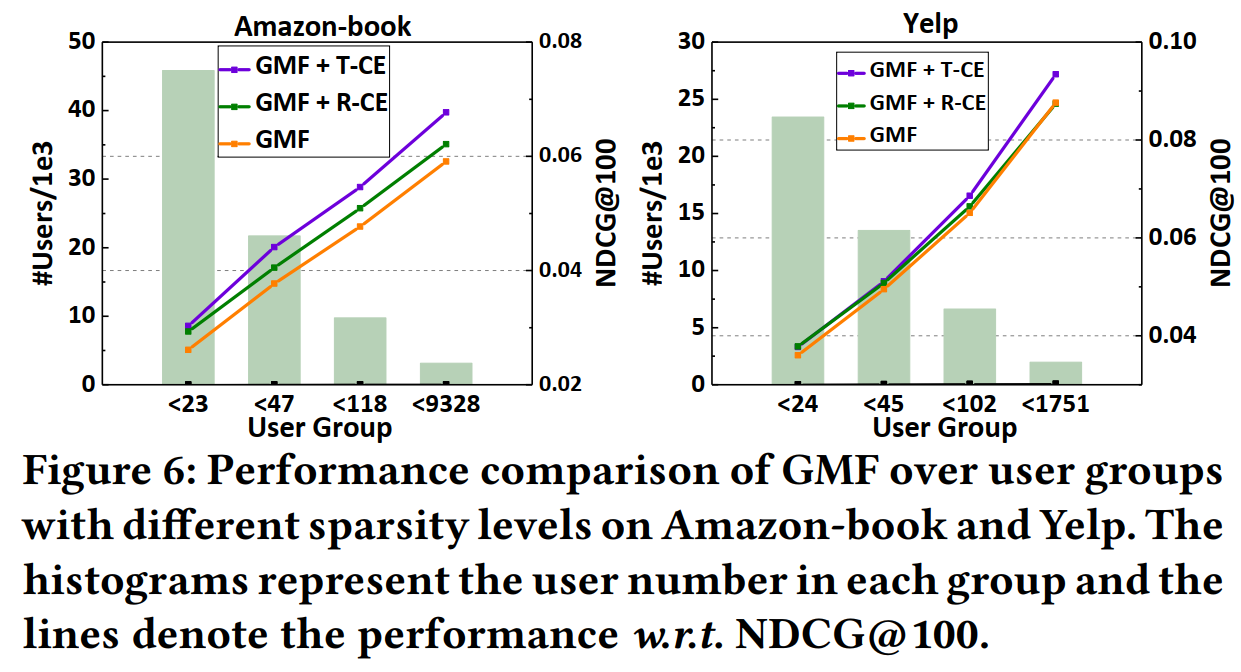
5.3 深入分析
5.3.1 “伪正样本”的Loss情况
第三部分已经分析过,“伪正样本”被模型记住之后,会使得模型性能降低。
本文用实验验证,提出的方法能否使得“伪正样本”不被模型记住,也就是“伪正样本”Loss是否能更高。
- 如Figure 7(a)所示,正常训练时,“伪正样本”的Loss会学到跟其他正样本一个水平
- 而使用T-CE时,“伪正样本”的Loss随着训练,先几乎不变,后迅速升高,说明模型准确识别到了这些“伪正样本”,并把他们从训练的正样本集排除出去。
- 而使用R-CE时,“伪正样本”的Loss随着训练过程仍然是下降的,但还是比其他样本高一些。
这一部分验证的是文章的核心论点,也是本文提出的模型起作用的核心机制——通过Loss函数识别并排除“伪正样本”的影响。
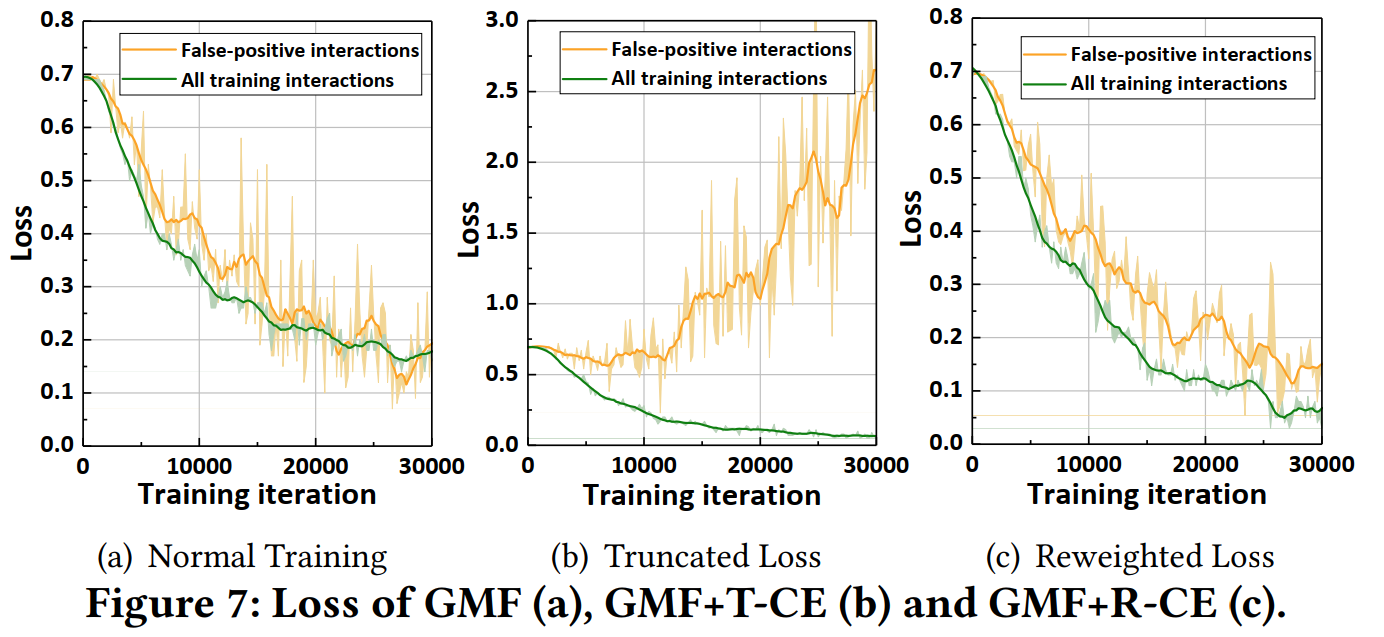
5.3.2 T-CE的性能研究
由于截断交叉熵损失函数(T-CE)使得“伪正样本”的Loss函数很高,作者又从T-CE过滤掉的交互与真正的“伪正样本”之间的召回率和准确率的角度来研究T-CE。
实验表明,T-CE选取“伪正样本”的准确率大约是随机选取的两倍,但准确率(precision)仍然只有10%左右。
- 一方面,这说明,为了过滤掉“伪正样本”,抛弃一些真正样本是值得的
- 但另一方面,这也说明本文章提出的方法准确率仍然很低
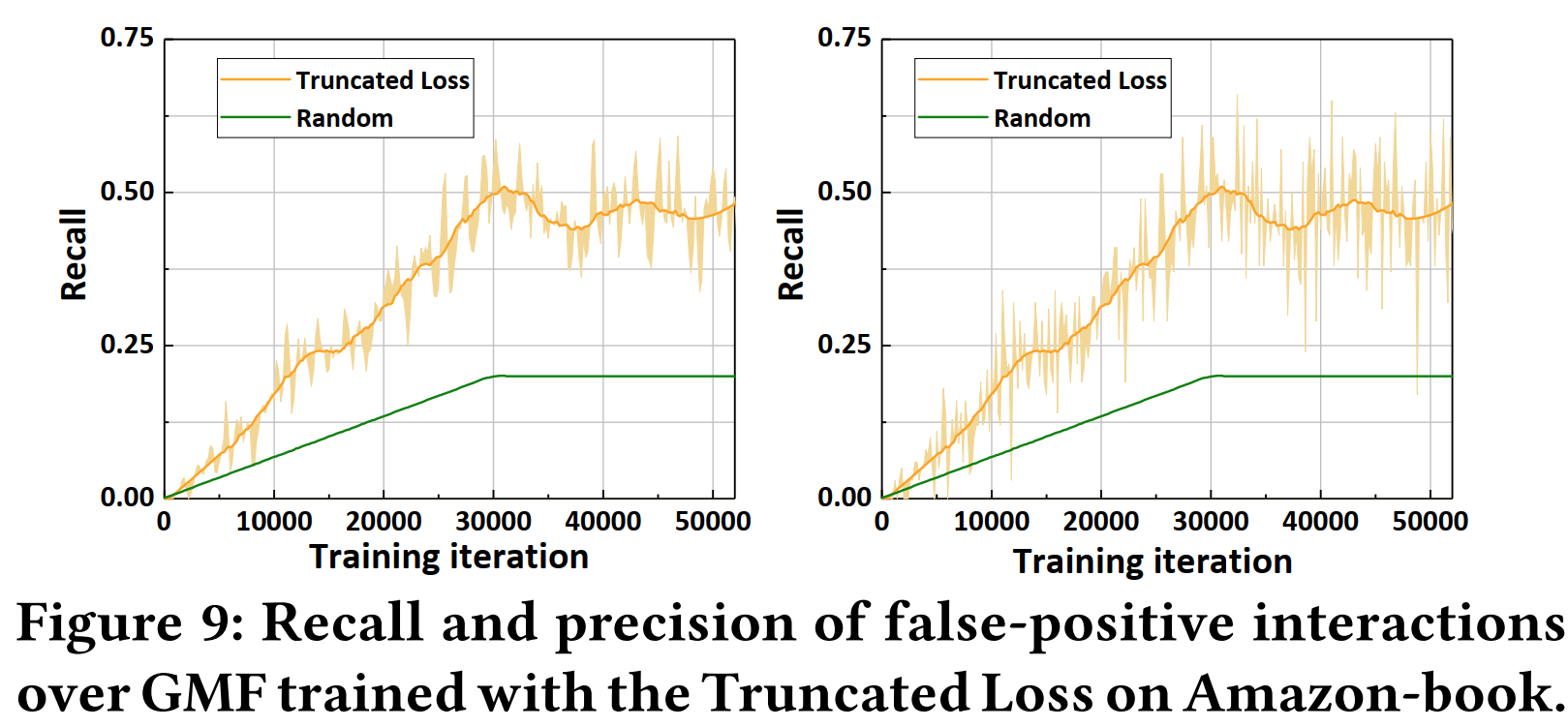
Weakness
- R-CE中给负样本也加了权重,而T-CE中没有对负样本做处理,实验中也没有对此做出说明。
- 识别“伪正样本”的准确率只有10%。
进一步阅读
[5] Yihong Chen, Bei Chen, Xiangnan He, Chen Gao, Yong Li, Jian-Guang Lou, and Yue Wang. 2019. lambdaOpt: Learn to Regularize Recommender Models in Finer Levels. In Proceedings of the 25th SIGKDD International Conference on Knowledge Discovery and Data Mining. ACM, 978–986.
[6] Jingtao Ding, Guanghui Yu, Xiangnan He, Fuli Feng, Yong Li, and Depeng Jin. 2019. Sampler design for bayesian personalized ranking by leveraging view data. Transactions on Knowledge and Data Engineering (2019).
[16] Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. 2017. Neural Collaborative Filtering. In Proceedings of the 26th International Conference on World Wide Web. IW3C2, 173–182.
[18] Y. Hu, Y. Koren, and C. Volinsky. 2008. Collaborative Filtering for Implicit Feedback Datasets. In Proceedings of the 8th International Conference on Data Mining. TEEE, 263–272.
[19] Rolf Jagerman, Harrie Oosterhuis, and Maarten de Rijke. 2019. To Model or to Intervene: A Comparison of Counterfactual and Online Learning to Rank from User Interactions. In Proceedings of the 42nd International SIGIR Conference on Research and Development in Information Retrieval. ACM, 15–24.
[39] Hongyi Wen, Longqi Yang, and Deborah Estrin. 2019. Leveraging Post-click Feedback for Content Recommendations. In Proceedings of the 13th Conference on Recommender Systems. ACM, 278–286.
[40] Yao Wu, Christopher DuBois, Alice X Zheng, and Martin Ester. 2016. Collaborative denoising auto-encoders for top-n Recommender Systems. In Proceedings of the 9th International Conference on Web Search and Data Mining. ACM, 153–162.
[41] Byoungju Yang, Sangkeun Lee, Sungchan Park, and Sang goo Lee. 2012. Exploiting Various Implicit Feedback for Collaborative Filtering. In Proceedings of the 21st International Conference on World Wide Web. IW3C2, 639–640.
【论文笔记】 Denoising Implicit Feedback for Recommendation的更多相关文章
- 【论文笔记】SamWalker: Social Recommendation with Informative Sampling Strategy
SamWalker: Social Recommendation with Informative Sampling Strategy Authors: Jiawei Chen, Can Wang, ...
- 【论文笔记】用反事实推断方法缓解标题党内容对推荐系统的影响 Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue
Click can be Cheating: Counterfactual Recommendation for Mitigating Clickbait Issue Authors: 王文杰,冯福利 ...
- 【论文笔记】Leveraging Post-click Feedback for Content Recommendations
Leveraging Post-click Feedback for Content Recommendations Authors: Hongyi Wen, Longqi Yang, Deborah ...
- 【RS】Using graded implicit feedback for bayesian personalized ranking - 使用分级隐式反馈来进行贝叶斯个性化排序
[论文标题]Using graded implicit feedback for bayesian personalized ranking (RecSys '14 recsys.ACM ) [论文 ...
- 【RS】BPR:Bayesian Personalized Ranking from Implicit Feedback - BPR:利用隐反馈的贝叶斯个性化排序
[论文标题]BPR:Bayesian Personalized Ranking from Implicit Feedback (2012,Published by ACM Press) [论文作者]S ...
- Alternating Least Squares(ASL) for Implicit Feedback Datasets的数学推导以及用Python实现
近期在看CF的相关论文,<Collaborative Filtering for Implicit Feedback Datasets>思想非常好,非常easy理解.可是从目标函数 是怎样 ...
- Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现(转)
Deep Learning论文笔记之(四)CNN卷积神经网络推导和实现 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文, ...
- 论文笔记之:Visual Tracking with Fully Convolutional Networks
论文笔记之:Visual Tracking with Fully Convolutional Networks ICCV 2015 CUHK 本文利用 FCN 来做跟踪问题,但开篇就提到并非将其看做 ...
- Deep Learning论文笔记之(八)Deep Learning最新综述
Deep Learning论文笔记之(八)Deep Learning最新综述 zouxy09@qq.com http://blog.csdn.net/zouxy09 自己平时看了一些论文,但老感觉看完 ...
随机推荐
- [loj3346]交换城市
观察可得,$(x,y)$能相互到达当且仅当:1.$x$和$y$联通:2.$x$和$y$所在的连通块不为链 根据这个结论,可以二分枚举答案+暴力判定,复杂度$o(qm\log_{2}1e9)$,可以通过 ...
- 【Mysql】三大日志 redo log、bin log、undo log
@ 目录 redo log(物理日志\重做日志) binlog(逻辑日志/归档日志) update语句执行流程 Uodolog(回滚日志/重做日志) undo log+redo log保证持久性 re ...
- web渗透工程师学习
职位描述: 对公司网站.业务系统进行安全评估测试(黑盒.白盒测试): 对公司各类系统进行安全加固: 对公司安全事件进行响应,清理后门,根据日志分析攻击途径: 安全技术研究,包括安全防范技术,黑客技术等 ...
- [Noip 2018][标题统计 龙湖斗 摆渡车 对称二叉树]普及组题解
啊喂,都已经9102年了,你还在想去年? 这里是一个Noip2018年PJ第二题打爆的OIer,错失省一 但经过了一年,我学到了很多,也有了很多朋友,水平也提高了很多,现在回看当时: 今年的Noip ...
- 洛谷 P4135 作诗(分块)
题目链接 题意:\(n\) 个数,每个数都在 \([1,c]\) 中,\(m\) 次询问,每次问在 \([l,r]\) 中有多少个数出现偶数次.强制在线. \(1 \leq n,m,c \leq 10 ...
- 2021.9.30 Codeforces 中档题四道
Codeforces 1528D It's a bird! No, it's a plane! No, it's AaParsa!(*2500) 考虑以每个点为源点跑一遍最短路,每次取出当前距离最小的 ...
- RSA,DSA,ECDSA,EdDSA和Ed25519的区别
RSA,DSA,ECDSA,EdDSA和Ed25519的区别 用过ssh的朋友都知道,ssh key的类型有很多种,比如dsa.rsa. ecdsa.ed25519等,那这么多种类型,我们要如何选择呢 ...
- R包开发过程记录
目的 走一遍R包开发过程,并发布到Github上使用. 步骤 1. 创建R包框架 Rsutdio --> File--> New Project--> New Directory - ...
- A Child's History of England.4
Still, the Britons would not yield. They rose again and again, and died by thousands, sword in hand. ...
- A Child's History of England.13
Then came the boy-king, Edgar, called the Peaceful, fifteen years old. Dunstan, being still the real ...