Redis高并发快的3大原因详解
1. Redis的高并发和快速的原因
1.redis是基于内存的,内存的读写速度非常快;
2.redis是单线程的,省去了很多上下文切换线程的时间;
3.redis使用多路复用技术,可以处理并发的连接。非阻塞IO 内部实现采用epoll,采用了epoll+自己实现的简单的事件框架。epoll中的读、写、关闭、连接都转化成了事件,然后利用epoll的多路复用特性,绝不在io上浪费一点时间。
下面重点介绍单线程设计和IO多路复用核心设计快的原因。
2. 为什么Redis是单线程的
- 官方答案
因为Redis是基于内存的操作,CPU不是Redis的瓶颈,Redis的瓶颈最有可能是机器内存的大小或者网络带宽。既然单线程容易实现,而且CPU不会成为瓶颈,那就顺理成章地采用单线程的方案了。
- 性能指标
关于redis的性能,官方网站也有,普通笔记本轻松处理每秒几十万的请求。
- 详细原因
1. 不需要各种锁的性能消耗
Redis的数据结构并不全是简单的Key-Value,还有list,hash等复杂的结构,这些结构有可能会进行很细粒度的操作,比如在很长的列表后面添加一个元素,在hash当中添加或者删除一个对象。这些操作可能就需要加非常多的锁,导致的结果是同步开销大大增加。
总之,在单线程的情况下,就不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗。
2. 单线程多进程集群方案
单线程的威力实际上非常强大,每核心效率也非常高,多线程自然是可以比单线程有更高的性能上限,但是在今天的计算环境中,即使是单机多线程的上限也往往不能满足需要了,需要进一步摸索的是多服务器集群化的方案,这些方案中多线程的技术照样是用不上的。
所以单线程、多进程的集群不失为一个时髦的解决方案。
3. CPU消耗
采用单线程,避免了不必要的上下文切换和竞争条件,也不存在多进程或者多线程导致的切换而消耗 CPU。
但是如果CPU成为Redis瓶颈,或者不想让服务器其他CUP核闲置,那怎么办?
可以考虑多起几个Redis进程,Redis是key-value数据库,不是关系数据库,数据之间没有约束。只要客户端分清哪些key放在哪个Redis进程上就可以了。
3. Redis单线程的优劣势
- 单进程单线程优势
1.代码更清晰,处理逻辑更简单
2.不用去考虑各种锁的问题,不存在加锁释放锁操作,没有因为可能出现死锁而导致的性能消耗
3.不存在多进程或者多线程导致的切换而消耗CPU
- 单进程单线程弊端
1.无法发挥多核CPU性能,不过可以通过在单机开多个Redis实例来完善;
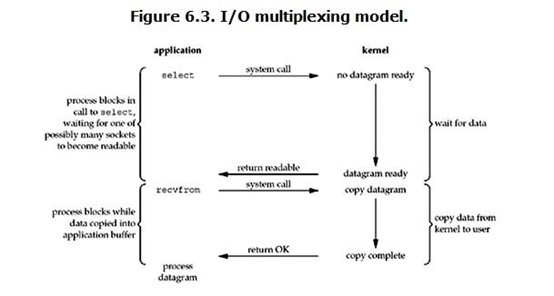
4. IO多路复用技术
redis 采用网络IO多路复用技术来保证在多连接的时候, 系统的高吞吐量。
多路-指的是多个socket连接,复用-指的是复用一个线程。多路复用主要有三种技术:select,poll,epoll。epoll是最新的也是目前最好的多路复用技术。
这里“多路”指的是多个网络连接,“复用”指的是复用同一个线程。采用多路 I/O 复用技术可以让单个线程高效的处理多个连接请求(尽量减少网络IO的时间消耗),且Redis在内存中操作数据的速度非常快(内存内的操作不会成为这里的性能瓶颈),主要以上两点造就了Redis具有很高的吞吐量。
5. Redis高并发快总结
1.Redis是纯内存数据库,一般都是简单的存取操作,线程占用的时间很多,时间的花费主要集中在IO上,所以读取速度快。
2.再说一下IO,Redis使用的是非阻塞IO,IO多路复用,使用了单线程来轮询描述符,将数据库的开、关、读、写都转换成了事件,减少了线程切换时上下文的切换和竞争。
3.Redis采用了单线程的模型,保证了每个操作的原子性,也减少了线程的上下文切换和竞争。
4.另外,数据结构也帮了不少忙,Redis全程使用hash结构,读取速度快,还有一些特殊的数据结构,对数据存储进行了优化,如压缩表,对短数据进行压缩存储,再如,跳表,使用有序的数据结构加快读取的速度。
5.还有一点,Redis采用自己实现的事件分离器,效率比较高,内部采用非阻塞的执行方式,吞吐能力比较大。
Redis高并发快的3大原因详解的更多相关文章
- 高并发架构系列:Redis为什么是单线程、及高并发快的3大原因详解
Redis的高并发和快速原因 1.redis是基于内存的,内存的读写速度非常快: 2.redis是单线程的,省去了很多上下文切换线程的时间: 3.redis使用多路复用技术,可以处理并发的连接.非阻塞 ...
- Redis为什么是单线程、及高并发快的3大原因详解
Redis的高并发和快速原因 1.redis是基于内存的,内存的读写速度非常快: 2.redis是单线程的,省去了很多上下文切换线程的时间: 3.redis使用多路复用技术,可以处理并发的连接.非阻塞 ...
- Redis为什么是单线程,高并发快的3大原因详解
出处知乎:https://zhuanlan.zhihu.com/p/58038188 Redis的高并发和快速原因 1.redis是基于内存的,内存的读写速度非常快: 2.redis是单线程的,省去了 ...
- 千万级高并发负载均衡软件haproxy配置文件详解
balance roundrobin #轮询方式 balance source #将用户IP经过hash计算后,使同一IP地址的所有请求都发送到同一固定的后 ...
- Redis高并发和快速的原因
一.Redis的高并发和快速原因 1.redis是基于内存的,内存的读写速度非常快: 2.redis是单线程的,省去了很多上下文切换线程的时间: 3.redis使用多路复用技术,可以处理并发的连接 ...
- Redis 高并发解决方案
针对大流量瞬间冲击,比如秒杀场景 redis前面可以加一层限流 sentinel / Hystrix redis高并发(读多写少)下缓存数据库双写误差: 1. 修改操作使用分布式锁(就是修改的时候加锁 ...
- 《Netty Zookeeper Redis 高并发实战》 图书简介
<Netty Zookeeper Redis 高并发实战> 图书简介 本书为 高并发社群 -- 疯狂创客圈 倾力编著, 高度剖析底层原理,深度解读面试难题 疯狂创客圈 Java 高并发[ ...
- linux中高并发socket最大连接数的优化详解
linux中高并发socket最大连接数的优化详解 https://m.jb51.net/article/106546.htm?from=singlemessage
- Kafka为什么性能这么快?4大核心原因详解
Kafka的性能快这是大厂Java面试经常问的一个话题,下面我就重点讲解Kafka为什么性能这么快的4大核心原因@mikechen 1.页缓存技术 Kafka 是基于操作系统 的页缓存(page ca ...
随机推荐
- ElasticSearch实战系列十一: ElasticSearch错误问题解决方案
前言 本文主要介绍ElasticSearch在使用过程中出现的各种问题解决思路和办法. ElasticSearch环境安装问题 1,max virtual memory areas vm.max_ma ...
- Ubuntu编译安装TrinityCore3.3.5
系统:Ubuntu 14.04.4 LTS (GNU/Linux 3.13.0-32-generic x86_64) 1核2G Notice:内存不可过小,否则会编译失败 #安装一堆东西 4 apt- ...
- Sqoop 安装部署
1. 上传并解压 Sqoop 安装文件 将 sqoop-1.4.7.bin__hadoop-2.6.0.tar.gz 安装包上传到 node-01 的 /root/ 目录下并将其解压 [root@no ...
- 015.Python函数名的使用以及函数变量的操作
一 函数名的使用 python中的函数可以像变量一样,动态创建,销毁,当参数传递,作为值返回,叫第一类对象.其他语言功能有限 1.1 函数名是个特殊的变量,可以当做变量赋值 def func(): p ...
- python基础之pip、.pyc、三元运算、进制、一切皆对象、可变与不可变类型
一.pip(下载工具==yum) 1.重点(必须掌握的) 列出已安装的包 pip list 安装要安装的包 pip install xxx 安装特定版本 pip install django==1.1 ...
- mysql基础之帮助信息
在mysql中获取帮助 1.当连接到mysql数据库以后,使用help命令或者\?表示获取帮助信息: MariaDB [ren]> help General information about ...
- spring mvc下实现通过邮箱找回密码功能
1功能分析 通过spring mvc框架实现通过邮箱找回密码. 2 实现分析 主要是借助某个邮箱的pop3/smtp服务实现的邮件代发功能. 3 源码分析 3.1首先在用户表对应的javabean中加 ...
- lvresize 调整LVM逻辑卷的空间大小,可以增大空间和缩小空间
lvresize 相关命令:lvreduce,lvextend,lvdisplay,lvcreate,lvremove,lvscan lvresize指令:调整逻辑卷空间大小[语 法]lvr ...
- python的数组
- 【Azure 环境】Azure Key Vault (密钥保管库)中所保管的Keys, Secrets,Certificates是否可以实现数据粒度的权限控制呢?
问题描述 Key Vault (密钥保管库) 能不能针对用户授权实现指定用户只能访问某个或某些特定的key? 如当前有两个用户(User1, User2),在Key Vault中有10个Key,Use ...