第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记
Flink介绍-《Fink原理、实战与性能优化》读书笔记
1.1 Apache Flink是什么?
在当代数据量激增的时代,各种业务场景都有大量的业务数据产生,对于这些不断产生的数据应该如何进行有效的处理,成为当下大多数公司所面临的问题。随着雅虎对hadoop的开源,越来越多的大数据处理技术开始涌入人们的视线,例如目前比较流行的大数据处理引擎Apache Spark,基本上已经取代了MapReduce成为当前大数据处理的标准。但是随着数据的不断增长,新技术的不断发展,人们逐渐意识到对实时数据处理的重要性。相对于传统的数据处理模式,流式数据处理有着更高的处理效率和成本控制能力。Flink 就是近年来在开源社区不断发展的技术中的能够同时支持高吞吐、低延迟、高性能的分布式处理框架
1.2数据架构的演变
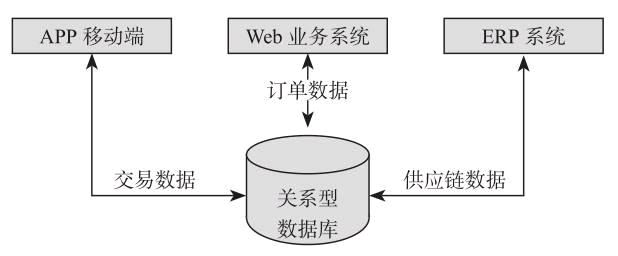 图1-1 传统的数据结构
图1-1 传统的数据结构
如图1-1所示,传统的单体数据架构最大的特点便是 集中式数据存储,大多数将架构分为计算层和存储层。
单体架构的初期效率很高,但是随着时间的推移,业务越来越多,系统逐渐变得很大,越来越难以维护和升级,数据库是唯一的准确数据源,每个应用都需要访问数据库来获取对应的数据,如果数据库发生改变或者出现问题,则将对整个业务系统产生影响。
后来随着微服务架构的出现,企业开始采用微服务作为企业业务系统的架构体系。微服务架构的核心思想是:一个应用是由多个小的、相互独立的微服务组成,这些服务运行在自己的进程中,开发和发布都没有依赖。不同的服务能依据不同的业务需求,构建的不同的技术架构之上,能够聚焦在有限的业务功能。 如图1-2
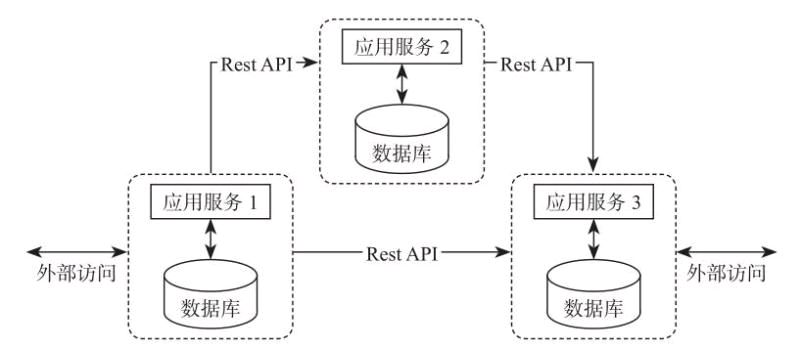 图1-2 微服务架构
图1-2 微服务架构
起初数据仓库主要还是构建在关系型数据库之上。例如Oracle、Mysql等数据库,但是随着企业数据量的增长,关系型数据库已经无法支撑大规模数据集的存储和分析,因为越来越多的企业开始选择基于Hadoop构建企业级大数据平台。同时众多的Sql_on_hadhoop上构建不同类型的数据应用变得简单而高效。
在构建企业数据仓库的过程中,数据往往都是周期性的从业务系统中同步到大数据平台,完成一系列的ETL转换动作之后,最终形成了数据集市等应用。但是对于一些时间要求比较高的应用,例如实时报表统计,则必须有非常低的延时展示统计结果,为此业界提出了一套Lambda架构方案来处理不同类型的数据。
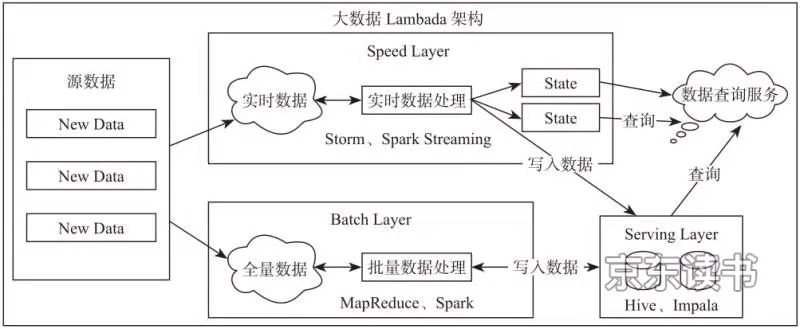 图1-3 大数据lambada架构
图1-3 大数据lambada架构
图1-3解释:大数据平台中包含批量计算的Batch Layer和实时计算的Speed Layer,通过在一套平台中将批计算和流计算整合在一起,例如使用Hadoop MapReduce进行批量数据的处理,使用Apache Storm进行实时数据的处理。这种架构在一定程度上解决了不同计算类型的问题,但是带来的问题是框架太多会导致平台复杂度过高、运维成本高等。在一套资源管理平台中管理不同类型的计算框架使用也是非常困难的事情。
后来随着Apache Spark的分布式内存处理框架的出现,提出了将数据切分成微批的处理模式进行流式数据处理,从而能够在一套计算框架内完成批量计算和流式计算。但因为Spark本身是基于批处理模式的原因,并不能完美且高效的处理原生的数据流,因此对流式计算支持的相对较弱,可以说Spark的出现本质上是在一定程度上对Hadoop架构进行了一定的升级和优化。
1.2.3有状态流计算架构
数据产生的本质,其实是一条条真实存在的事件,前面提到的不同的架构其实都是在一定程度违背了这种本质,需要通过在一定时延的情况下对业务数据进行处理,然后得到基于业务数据统计的准确结果。实际上,基于流式计算技术局限性,我们很难再数据产生的过程中进行计算并直接产生统计结果,因为这不仅对系统有非常高的要求,还必须要满足高性能、高吞吐、低延时等众多目标。
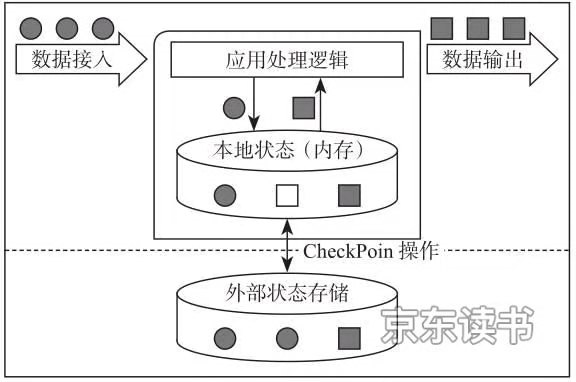 图1-4 有状态计算架构
图1-4 有状态计算架构
基于有状态计算的方式最大的优势是不需要将原始数据重新从外部存储中拿出来,从而进行全量计算,因为这种计算方式的代价可能是非常高的。
1.2.4为什么会是Flink
Flink通过实现Google Dataflow流式计算模型实现了高吞吐、低延迟、高性能兼具实时流式计算框架。同时Flink支持高度容错的状态管理,防止状态在计算过程中因为系统异常而出现丢失,Flink周期性地通过分布式快照技术Checkpoints实现状态的持久化维护,使得即使在系统停机或者异常的情况下都能计算出正确的结果。
Flink的具体优势有以下几点:
同时支持高吞吐、低延迟、高性能
Flink是目前开源社区中唯一一套集高吞吐、低延迟、高性能三者于一身的分布式流式数据处理框架。像Apache Spark也只能兼顾高吞吐和高性能特性,主要因为在Spark Streaming流式计算中无法做到低延迟保障;而流式计算框架Apache Storm只能支持低延迟和高性能特性,但是无法满足高吞吐的要求。而满足高吞吐、低延迟、高性能这三个目标对分布式流式计算框架来说是非常重要的。支持事件时间(Event Time)概念
在流式计算领域中,窗口计算的地位举足轻重,但目前大多数框架窗口计算采用的都是系统时间(Process Time),也是事件传输到计算框架处理时,系统主机的当前时间。Flink能够支持基于事件时间(Event Time)语义进行窗口计算,也就是使用事件产生的时间,这种基于事件驱动的机制使得事件即使乱序到达,流系统也能够计算出精确的结果,保持了事件原本产生时的时序性,尽可能避免网络传输或硬件系统的影响。支持有状态计算
Flink在1.4版本中实现了状态管理,所谓状态就是在流式计算过程中将算子的中间结果数据保存在内存或者文件系统中,等下一个事件进入算子后可以从之前的状态中获取中间结果中计算当前的结果,从而无须每次都基于全部的原始数据来统计结果,这种方式极大地提升了系统的性能,并降低了数据计算过程的资源消耗。对于数据量大且运算逻辑非常复杂的流式计算场景,有状态计算发挥了非常重要的作用。支持高度灵活的窗口(windows)操作
在流处理应用中,数据是连续不断的,需要通过窗口的方式对流数据进行一定范围的聚合计算,例如统计在过去的1分钟内有多少用户点击某一网页,在这种情况下,我们必须定义一个窗口,用来收集最近一分钟内的数据,并对这个窗口内的数据进行再计算。Flink将窗口划分为基于Time、Count、Session,以及Data-driven等类型的窗口操作,窗口可以用灵活的触发条件定制化来达到对复杂的流传输模式的支持,用户可以定义不同的窗口触发机制来满足不同的需求。
基于轻量级分布式快照(Snapshot)实现的容错
Flink能够分布式运行在上千个节点上,将一个大型计算任务的流程拆解成小的计算过程,然后将tesk分布到并行节点上进行处理。在任务执行过程中,能够自动发现事件处理过程中的错误而导致数据不一致的问题,比如:节点宕机、网路传输问题,或是由于用户因为升级或修复问题而导致计算服务重启等。在这些情况下,通过基于分布式快照技术的Checkpoints,将执行过程中的状态信息进行持久化存储,一旦任务出现异常停止,Flink就能够从Checkpoints中进行任务的自动恢复,以确保数据在处理过程中的一致性。基于JVM实现独立的内存管理
内存管理是所有计算框架需要重点考虑的部分,尤其对于计算量比较大的计算场景,数据在内存中该如何进行管理显得至关重要。针对内存管理,Flink实现了自身管理内存的机制,尽可能减少JVM GC对系统的影响。另外,Flink通过序列化/反序列化方法将所有的数据对象转换成二进制在内存中存储,降低数据存储的大小的同时,能够更加有效地对内存空间进行利用,降低GC带来的性能下降或任务异常的风险,因此Flink较其他分布式处理的框架会显得更加稳定,不会因为JVM GC等问题而影响整个应用的运行。Save Points(保存点)
对于7*24小时运行的流式应用,数据源源不断地接入,在一段时间内应用的终止有可能导致数据的丢失或者计算结果的不准确,例如进行集群版本的升级、停机运维操作等操作。值得一提的是,Flink通过Save Points技术将任务执行的快照保存在存储介质上,当任务重启的时候可以直接从事先保存的Save Points恢复原有的计算状态,使得任务继续按照停机之前的状态运行,Save Points技术可以让用户更好地管理和运维实时流式应用。
1.3 Flink应用场景
- 实时智能推荐
- 复杂事件处理
- 实时欺诈检测
- 实时数仓与ETL
- 流数据分析
- 实时报表分析
1.4 Flink基本架构
1.4.1 基本组件栈
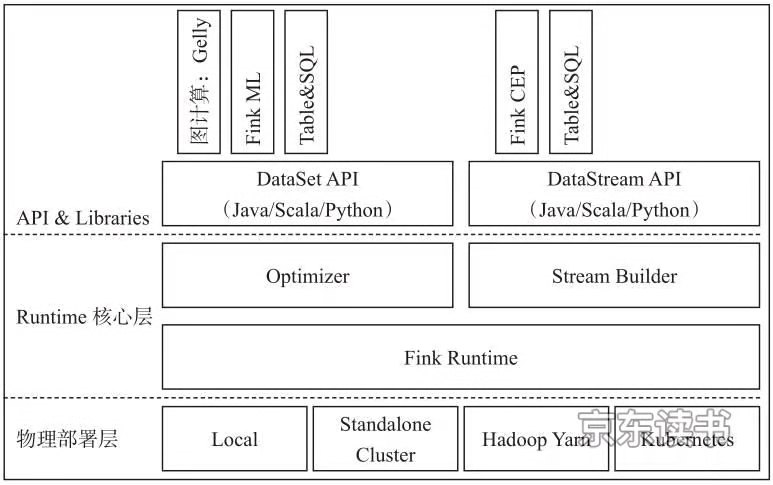 图1-5 Flink基本组件栈
图1-5 Flink基本组件栈
flink分为架构分为三层,由上往下依次是API&Libraries层、Runtime核心层以及物理部署层
API&Libraries层
作为分布式数据处理框架,Flink同时提供了支撑计算和批计算的接口,同时在此基础上抽象出不同的应用类型的组件库,如基于流处理的CEP(复杂事件处理库)、SQL&Table库和基于批处理的FlinkML(机器学习库)等、Gelly(图处理库)等。API层包括构建流计算应用的DataStream API和批计算应用的DataSet API,两者都提供给用户丰富的数据处理高级API,例如Map、FlatMap操作等,同时也提供比较低级的Process Function API,用户可以直接操作状态和时间等底层数据。
Runtime核心层
该层主要负责对上层不同接口提供基础服务,也是Flink分布式计算框架的核心实现层,支持分布式Stream作业的执行、JobGraph到ExecutionGraph的映射转换、任务调度等。将DataSteam和DataSet转成统一的可执行的Task Operator,达到在流式引擎下同时处理批量计算和流式计算的目的。
物理部署层
该层主要涉及Flink的部署模式,目前Flink支持多种部署模式:本地、集群(Standalone、YARN)、云(GCE/EC2)、Kubenetes。Flink能够通过该层能够支持不同平台的部署,用户可以根据需要选择使用对应的部署模式。
1.4.2基本架构图
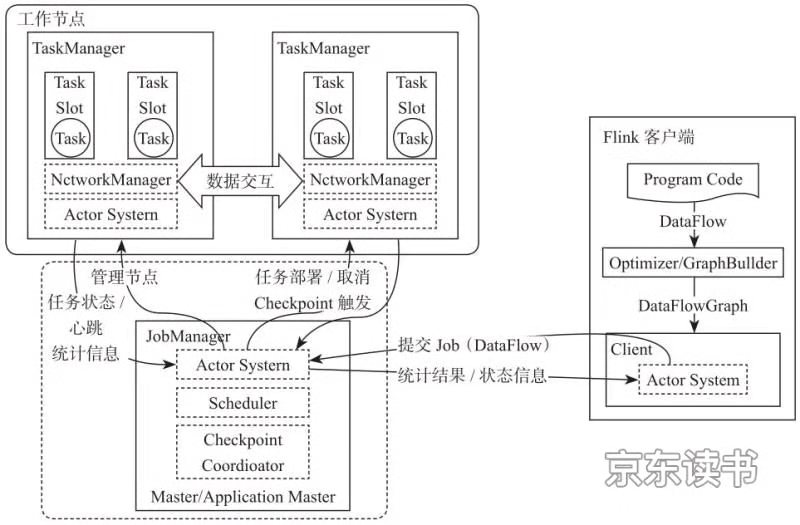 图1-6 Flink基本架构图
图1-6 Flink基本架构图
Flink系统主要由两个组件组成,分别为JobManager和TaskManager,Flink架构也遵循Master-Slave架构设计原则,JobManager为Master节点,TaskManager为Worker(Slave)节点。所有组件之间的通信都是借助于Akka Framework,包括任务的状态以及Checkpoint触发等信息。
1.Client客户端
客户端负责将任务提交到集群,与JobManager构建Akka连接,然后将任务提交到JobManager,通过和JobManager之间进行交互获取任务执行状态。客户端提交任务可以采用CLI方式或者通过使用Flink WebUI提交,也可以在应用程序中指定JobManager的RPC网络端口构建ExecutionEnvironment提交Flink应用。
2.JobManager
JobManager负责整个Flink集群任务的调度以及资源的管理,从客户端中获取提交的应用,然后根据集群中TaskManager上TaskSlot的使用情况,为提交的应用分配相应的TaskSlots资源并命令TaskManager启动从客户端中获取的应用。JobManager相当于整个集群的Master节点,且整个集群中有且仅有一个活跃的JobManager,负责整个集群的任务管理和资源管理。JobManager和TaskManager之间通过Actor System进行通信,获取任务执行的情况并通过Actor System将应用的任务执行情况发送给客户端。同时在任务执行过程中,Flink JobManager会触发Checkpoints操作,每个TaskManager节点收到Checkpoint触发指令后,完成Checkpoint操作,所有的Checkpoint协调过程都是在Flink JobManager中完成。当任务完成后,Flink会将任务执行的信息反馈给客户端,并且释放掉TaskManager中的资源以供下一次提交任务使用。
3.TaskManager
TaskManager相当于整个集群的Slave节点,负责具体的任务执行和对应任务在每个节点上的资源申请与管理。客户端通过将编写好的Flink应用编译打包,提交到JobManager,然后JobManager会根据已经注册在JobManager中TaskManager的资源情况,将任务分配给有资源的TaskManager节点,然后启动并运行任务。TaskManager从JobManager接收需要部署的任务,然后使用Slot资源启动Task,建立数据接入的网络连接,接收数据并开始数据处理。同时TaskManager之间的数据交互都是通过数据流的方式进行的。
可以看出,Flink的任务运行其实是采用多线程的方式,这和MapReduce多JVM进程的方式有很大的区别Flink能够极大提高CPU使用效率,在多个任务和Task之间通过TaskSlot方式共享系统资源,每个TaskManager中管理多个TaskSlot资源池进行对资源进行有效管理。
总结:
本章主要是对Flink有个初步的认识和了解。
第一章-Flink介绍-《Fink原理、实战与性能优化》读书笔记的更多相关文章
- Flink原理、实战与性能优化读书笔记
第一章 ApacheFlink介绍 一.Flink优势 1. 目前唯一同时支持高吞吐.低延迟.高性能的分布式流式数据处理框架 2. 支持事件事件概念 3. 支持有状态计算,保持了事件原本产生的时序性, ...
- 《Getting Started with WebRTC》第一章 WebRTC介绍
<Getting Started with WebRTC>第一章 WebRTC介绍 本章是对WebRTC做概念性的介绍. 阅读完本章后.你将对下面方面有一个清晰的理解: . 什么 ...
- 秋色园QBlog技术原理解析:性能优化篇:缓存总有失效时,构造持续的缓存方案(十四)
转载自:http://www.cyqdata.com/qblog/article-detail-38993 文章回顾: 1: 秋色园QBlog技术原理解析:开篇:整体认识(一) --介绍整体文件夹和文 ...
- Mariadb第一章:介绍及安装--小白博客
mariadb(第一章) 数据库介绍 1.什么是数据库? 简单的说,数据库就是一个存放数据的仓库,这个仓库是按照一定的数据结构(数据结构是指数据的组织形式或数据之间的联系)来组织,存储的,我们可以 ...
- Java 螺纹第三版 第一章Thread介绍、 第二章Thread创建和管理学习笔记
第一章 Thread导论 为何要用Thread ? 非堵塞I/O I/O多路技术 轮询(polling) 信号 警告(Alarm)和定时器(Timer) 独立的任务(Ta ...
- 《大数据实时计算引擎 Flink 实战与性能优化》新专栏
基于 Flink 1.9 讲解的专栏,涉及入门.概念.原理.实战.性能调优.系统案例的讲解. 专栏介绍 扫码下面专栏二维码可以订阅该专栏 首发地址:http://www.54tianzhisheng. ...
- Android群英传》读书笔记 (4) 第八章 Activity和Activity调用栈分析 + 第九章 系统信息与安全机制 + 第十章 性能优化
第八章 Activity和Activity调用栈分析 1.Activity生命周期理解生命周期就是两张图:第一张图是回字型的生命周期图第二张图是金字塔型的生命周期图 注意点(1)从stopped状态重 ...
- Spring 实战 第4版 读书笔记
第一部分:Spring的核心 1.第一章:Spring之旅 1.1.简化Java开发 创建Spring的主要目的是用来替代更加重量级的企业级Java技术,尤其是EJB.相对EJB来说,Spring提供 ...
- 第17 章 : 深入理解 etcd:etcd 性能优化实践
深入理解 etcd:etcd 性能优化实践 本文将主要分享以下五方面的内容: etcd 前节课程回顾复习: 理解 etcd 性能: etcd 性能优化 -server 端: etcd 性能优化 -cl ...
随机推荐
- 详解calc()函数功能
calc()对大家来说,或许很陌生,不太会相信calc()是css中的部分.因为看其外表像个函数,既然是函数为何又出现在CSS中呢?这一点也让我百思不得其解,今天有一同事告诉我,说CSS3中有一个属性 ...
- 解决tomcat的404问题
遇到的问题 点击startup.bat启动tomcat启动成功,但在网页上输入local:8080却显示Access Error: 404 -- Not Found Cannot locate doc ...
- Linux基础三:用户和组
三.用户和组 1.概念 (1).用户概念: 用户是用来运行某一些进程.拥有某一些文件或目录. 在Linux里面,用户分成三大类:root用户.系统用户.普通用户. 用户是用UID来唯一标识身份的,且r ...
- Python 爬取妹子图(技术是无罪的)
... import requests from bs4 import BeautifulSoup import os import sys class mzitu(): def html(self, ...
- php 图像和水印
生成图像 $img = imagecreate(400,400); imagecolorallocate($img,255,255,255); imageellipse($img,200,200,50 ...
- Spark-StructuredStreaming 下的checkpointLocation分析以及对接 Grafana 监控和提交Kafka Lag 监控
一.Spark-StructuredStreaming checkpointLocation 介绍 Structured Streaming 在 Spark 2.0 版本于 2016 年引入, 是基于 ...
- [hdu6995]Travel on Tree
问题即查询将其按照dfs序排序后,相邻两点(包括首尾)的距离和 考虑使用莫队+set维护,时间复杂度为$o(n\sqrt{n}\log n)$,无法通过 进一步的,注意到删除是可以用链表实现的,因此考 ...
- mabatis的sql标签
定义:mapper.xml映射文件中定义了操作数据库的sql,并且提供了各种标签方法实现动态拼接sql.每个sql是一个statement,映射文件是mybatis的核心. 一,内容标签 1.Name ...
- C#使用Thrift作为RPC框架入门(三)之三层架构
前言 这是我们讲解Thrift框架的第三篇文章,前两篇我们讲了Thrift作为RPC框架的基本用法以及架构的设计.为了我们更好的使用和理解Thrift框架,接下来,我们将来学习一下Thrift框架提供 ...
- pytest-rerunfailures/pytest-repeat重跑插件
在测试中,我们会经常遇到这种情况,由于环境等一些原因,一条case运行5次,只有两次成功 其它三次失败,针对这种概率性成功或失败,若是我们每次都运行一次就比较耗时间,这个时候 就需要pytest提供的 ...