【ElasticSearch】ES 读数据,写数据与搜索数据的过程
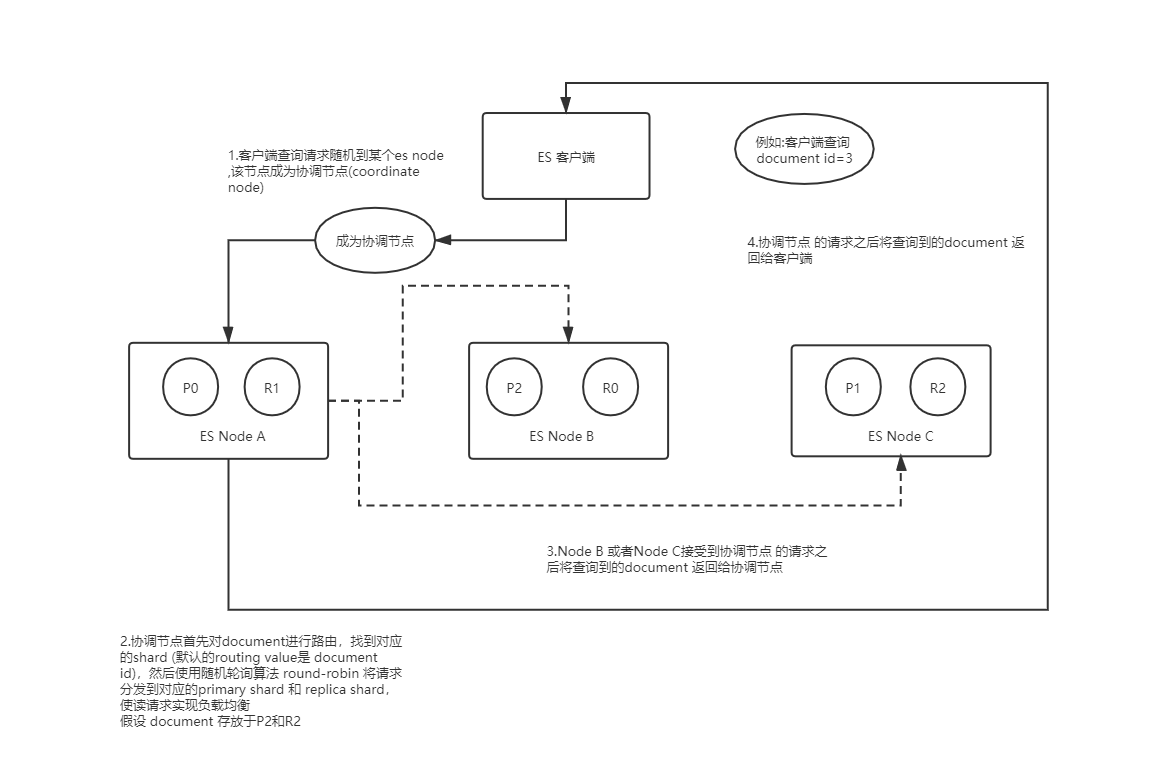
ES读数据的过程:
1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2.corrdinating node 对 doc id 对哈希,找出该文档对应所在的shards,将请求转发到对应的node,
此时会使用round-robin 随机轮询算法,在primary shard 和 replica shard 之中选择一个 ,实现读请求的负载均衡;
3.接受请求的node 返回给document 给coordinate node;
4.coordinate node 返回document 给客户端;
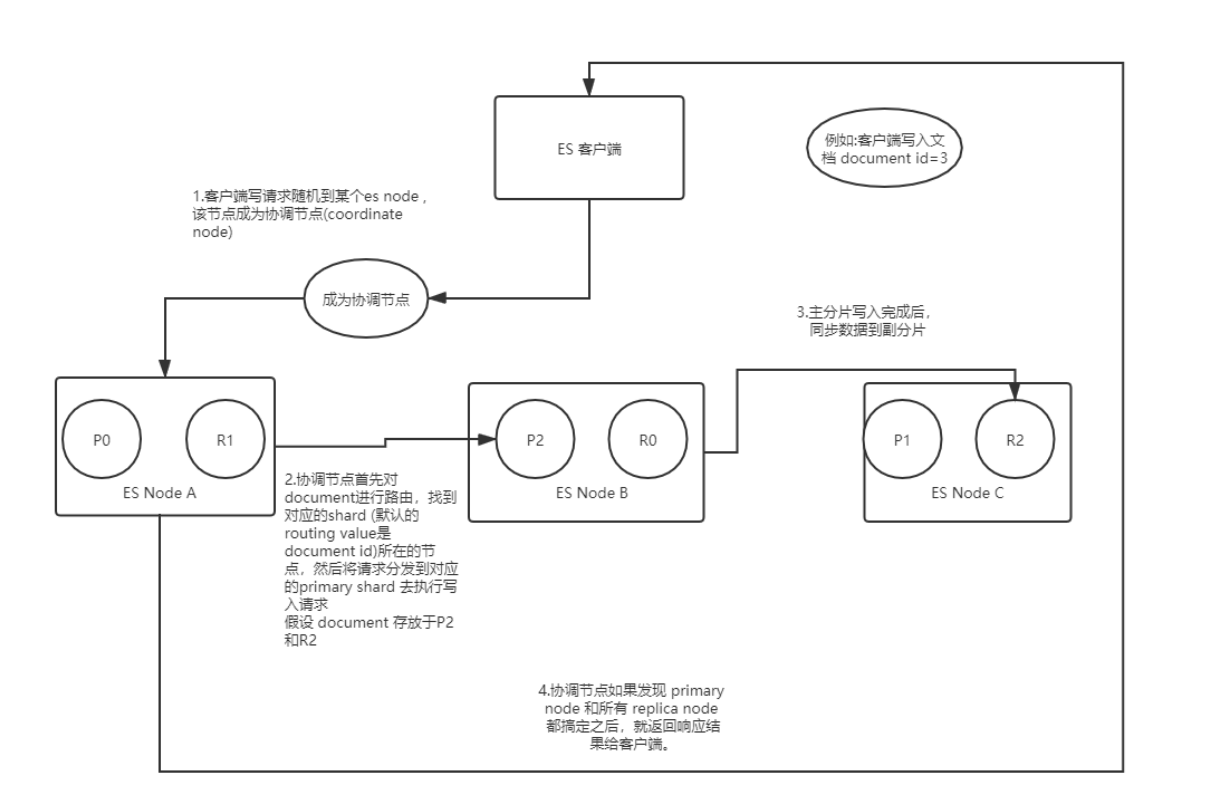
ES写数据的过程:
1.ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2.协调节点 对 doc id 对哈希,找出该文档存放的primary shard,将请求转发到该shard对应的节点;
3.节点收到请求,primary shard处理写入,然后将数据同步到对应的replica shard 所在的节点;
4.协调节点 发现 主分片和副分片都写入完成后 返回响应结果给 ES 客户端;
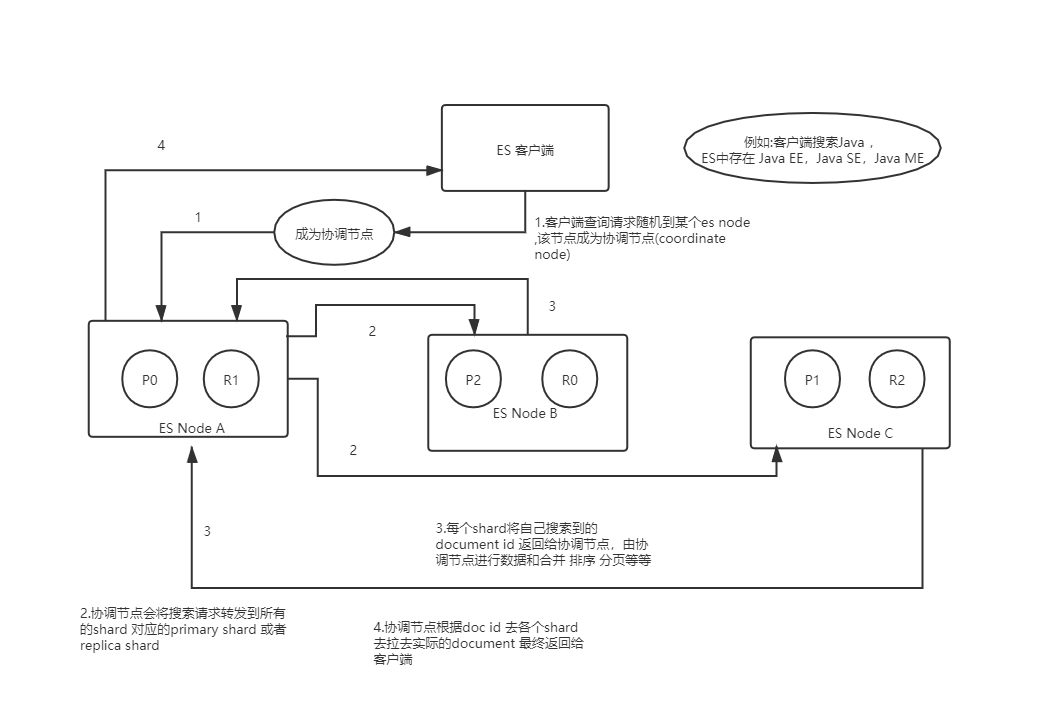
ES搜索数据的过程:
1..ES客户端选择一个node发送请求,该请求作为协调节点(coordinating node);
2. 协调节点将请求发送到所有的shard ,包括primary shard 或者是 replica shard
3. shard 将搜索到的数据 也就是doc id 返回给协调节点
4. 协调节点根据doc id ,将请求分发到doc id 对应的shard 去获取完整的document ,然后将数据返回给ES 客户端
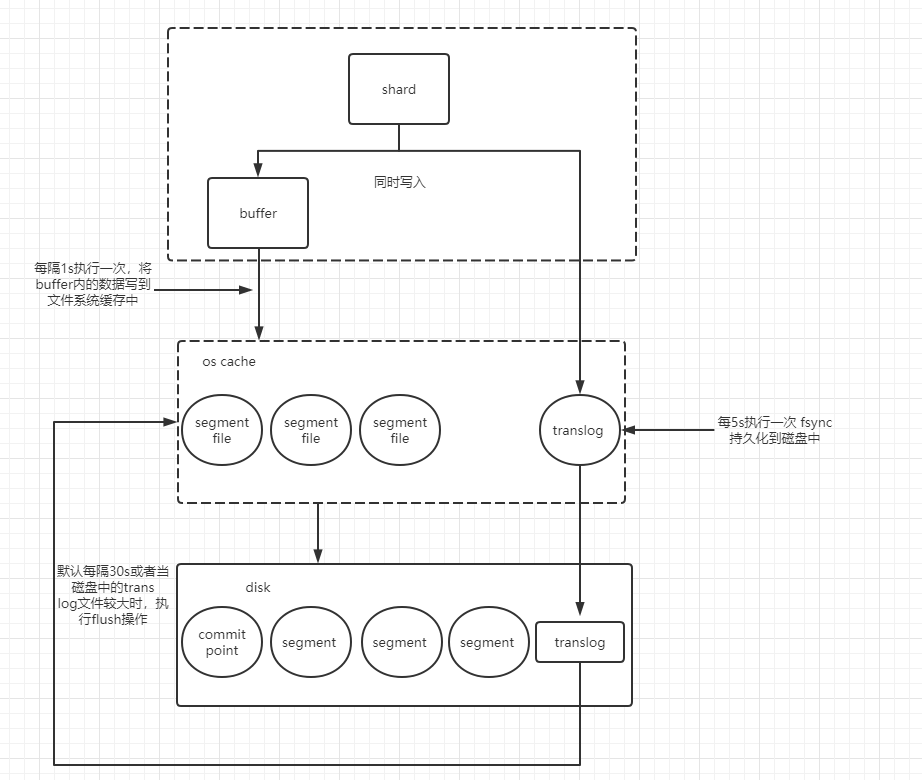
ES写数据的底层原理:
1.shard 收到写入请求后,写到内存buffer,同时写入到translog((每个shard都对应一个translog文件),注意内存buffer里面的数据是搜索不到的
2.shard 会每隔1秒执行refresh操作,将buffer内的数据刷到os cache级别的缓存中去(这里是文件系统缓存),生成新的segement,buffer内的数据被刷到os cache中,
buffer被清空,此时,这个数据也能被搜索到了
3.重复1,2两个步骤,数据会被写入到一个一个的os cache 的 segment file 中去,并刷到磁盘中去,但是每次写入,translog 会越来越大,到达一定长度将会触发 commit 操作
commit 操作
将buffer内的现有数据refresh 到os cache中,清空buffer,然后将一个commit point 写入到磁盘中,里面标识这个commit point对应的所有segment file
同时强行将os cache 里面的数据fsync到磁盘文件中去,最后清空现有的translog文件,重启一个新的translog文件;
fsync+清空translog, 操作就是 flush,默认30分钟执行一次flush,如果translog 文件过大(默认512M)也会触发flush操作,flush
注意:os 文件系统中的translog的数据写到磁盘中 translog文件中 fsync的操作默认每5s 执行一次;
参考:
https://blog.csdn.net/wang7075202/article/details/111308905
https://blog.csdn.net/lsgqjh/article/details/83022206
https://www.jianshu.com/p/15837be98ffd
https://blog.csdn.net/wx1528159409/article/details/105973336/
https://blog.csdn.net/u013129944/article/details/93720081
https://developer.51cto.com/art/202009/625293.htm
【ElasticSearch】ES 读数据,写数据与搜索数据的过程的更多相关文章
- Java NIO中的读和写
一.概述 读和写是I/O的基本过程.从一个通道中读取只需创建一个缓冲区,然后让通道将数据读到这个缓冲区.写入的过程是创建一个缓冲区,用数据填充它,然后让通道用这些数据来执行写入操作. 二.从文件中读取 ...
- NIO 中的读和写
概述 读和写是I/O的基本过程.从一个通道中读取很简单:只需创建一个缓冲区,然后让通道将数据读到这个缓冲区中.写入也相当简单:创建一个缓冲区,用数据填充它,然后让通道用这些数据来执行写入操作. 从文件 ...
- (转)通过HTTP RESTful API 操作elasticsearch搜索数据
样例数据集 这是编造的JSON格式银行客户账号信息文档,文档schema如下: { “account_number”: 0, “balance”: 16623, “firstname”: “Brads ...
- zookeeper集群,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的。
zookeeper集群,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的.
- selenium实现excel文件数据的读、写
在进行软件测试或设计自动化测试框架时,一个不可避免的过程就是: 参数 化,在利用 python 进行自动化测试开发时,通常会使用 excel 来做数据管 理,利用 xlrd.xlwt 开源包来读写 e ...
- Elasticsearch 搜索数据
章节 Elasticsearch 基本概念 Elasticsearch 安装 Elasticsearch 使用集群 Elasticsearch 健康检查 Elasticsearch 列出索引 Elas ...
- [Elasticsearch] ES聚合场景下部分结果数据未返回问题分析
背景 在对ES某个筛选字段聚合查询,类似groupBy操作后,发现该字段新增的数据,聚合结果没有展示出来,但是用户在全文检索新增的筛选数据后,又可以查询出来, 针对该问题进行了相关排查. 排查思路 首 ...
- elasticsearch与mongodb分布式集群环境下数据同步
1.ElasticSearch是什么 ElasticSearch 是一个基于Lucene构建的开源.分布式,RESTful搜索引擎.它的服务是为具有数据库和Web前端的应用程序提供附加的组件(即可搜索 ...
- SQL数据同步到ElasticSearch(三)- 使用Logstash+LastModifyTime同步数据
在系列开篇,我提到了四种将SQL SERVER数据同步到ES中的方案,本文将采用最简单的一种方案,即使用LastModifyTime来追踪DB中在最近一段时间发生了变更的数据. 安装Java 安装部分 ...
随机推荐
- [源码解析] 消息队列 Kombu 之 基本架构
[源码解析] 消息队列 Kombu 之 基本架构 目录 [源码解析] 消息队列 Kombu 之 基本架构 0x00 摘要 0x01 AMQP 1.1 基本概念 1.2 工作过程 0x02 Poll系列 ...
- 面试系列二:精选大数据面试真题JVM专项-附答案详细解析
公众号(五分钟学大数据)已推出大数据面试系列文章-五分钟小面试,此系列文章将会深入研究各大厂笔面试真题,并根据笔面试题扩展相关的知识点,助力大家都能够成功入职大厂! 大数据笔面试系列文章分为两种类型: ...
- 大括号之谜:C++的列表初始化语法解析
有朋友在使用std::array时发现一个奇怪的问题:当元素类型是复合类型时,编译通不过. struct S { int x; int y; }; int main() { int a1[3]{1, ...
- MySQL基础知识:创建MySQL数据库和表
虚构一个微型在线书店的数据库和数据,作为后续MySQL脚本的执行源,方便后续MySQL和SQL的练习. 在虚构这个库的过程中,主要涉及的是如何使用命令行管理 MySQL数据库对象:数据库.表.索引.外 ...
- BeetleX使用bootstrap5开发SPA应用
在早期版本BeetleX.WebFamily只提供了vuejs+element的集成,由于element只适合PC管理应用开发相对于移动应用适配则没这么方便.在新版本组件集成了bootstra ...
- yolo训练数据集
最近了解了下yolov3的训练数据集部分,总结了以下操作步骤:(基于pytorch框架,请预先装好pytorch的相关组件) 1.下载ImageLabel软件对图片进行兴趣区域标记,每张图片对应一个x ...
- PTE 准备之 Personal introduction
Task strategies Be prepared! This is your opportunity to give the admissions officers a first impres ...
- mysql最经典的语句
一.基础1.说明:创建数据库CREATE DATABASE database-name2.说明:删除数据库drop database dbname3.说明:备份sql server--- 创建 备份数 ...
- 《数据持久化与鸿蒙的分布式数据管理能力》直播课答疑和PPT分享
问:hi3861开发板支持分布式数据库吗? 目前,分布式数据库仅支持Java接口,因此Hi3861没有现成的API用于操作分布式数据库. 问:分布式数据管理包括搜索吗? 分布式数据管理包括融合搜索能力 ...
- P1200_你的飞碟在这儿(JAVA语言)
题目描述 众所周知,在每一个彗星后都有一只UFO.这些UFO时常来收集地球上的忠诚支持者. 不幸的是,他们的飞碟每次出行都只能带上一组支持者.因此,他们要用一种聪明的方案让这些小组提前知道谁会被彗星带 ...