HBase集群搭建
HBase集群搭建
搭建环境:假设我们的linux环境已经准备好,包括网络、JDK、防火墙、主机名、免密登录等都没有问题,而且一定要有zookeeper。下面我们用3台linux虚拟机来搭建Hbase集群,首先启动我们的3台linux虚拟机,主机名分别为hadoop01、hadoop02和hadoop03。
1.启动zookeeper集群
启动zookeeper的命令:
[root@hadoop01 zookeeper]# bin/zkServer.sh start
查看zookeeper启动状态:
[root@hadoop01 zookeeper]# bin/zkServer.sh status
2.启动HDFS集群
由于Hbase是基于Hadoop的HDFS的,所以我们还要启动HDFS集群。
HDFS的启动命令:
[root@hadoop01 hadoop]# sbin/start-dfs.sh
通过jps命令看到至少有如下5个进程是正常的:
[root@hadoop01 hadoop]# jps
2511 DataNode --HDFS的DataNode进程
2034 QuorumPeerMain --Zookeeper进程
2850 DFSZKFailoverController --ZKFC进程
2412 NameNode --HDFS的NameNode进程
2683 JournalNode --JournalNode进程
在浏览器中访问如下地址,检查NameNode的状态(若显示为“active”说明正常):

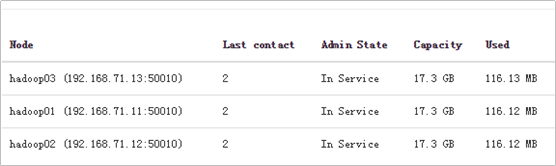
检查DataNode的状态是否正常:
3.上传Hbase安装包
我们使用的是Hbase的版本是:hbase-1.2.1-bin.tar.gz
4.解压Hbase的安装包
解压命令(其中参数-C表示解压的指定的目录):
[root@hadoop01 soft]# tar -zxvf hbase-1.2.1-bin.tar.gz -C /root/apps/
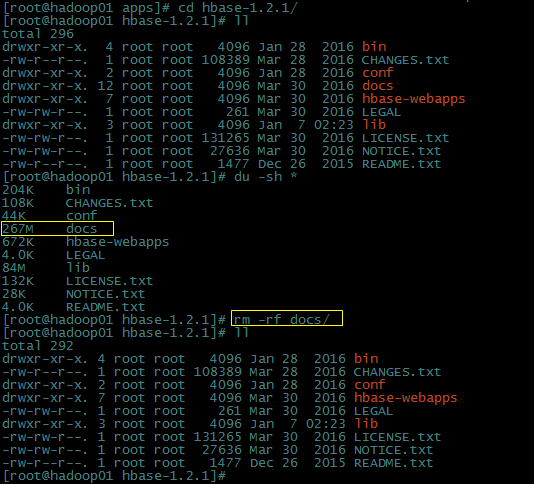
进入到解压后的Hbase目录,把docs目录删除(为了后面拷贝更快一点):
5.修改配置文件hbase-env.sh
主要修改2个地方:
//修改JAVA_HOME
export JAVA_HOME= /root/apps/jdk1.7.0_80/
//Hbase其实自己带了zookeeper的jar包,它可以自己启动zookeeper
//这样的话就会跟我们自己单独部署的那个多种服务共用的zookeeper集群会产生冲突
//所以这里一般设置为false
export HBASE_MANAGES_ZK=false
在hbase-env.sh配置文件还有一些其他的配置,从中选择一些做简单介绍:
//配置Hbase的classpath路径,这个我们不用配置,Hbase会自动加载它的lib目录
//如果你把hadoop的配置文件也放到Hbase的classpath下面,Hbase也会去加载
# export HBASE_CLASSPATH= //Hbase最大可用的堆内存大小,默认是1G
# export HBASE_HEAPSIZE=1G //该项配置可以将数据序列化到JVM自己的堆内存中
//而不是放到JVM分配给Hbase的堆内存
# export HBASE_OFFHEAPSIZE=1G //Hbase在启动的时候会给JVM传递该参数,这是一个种“使用并发标记的垃圾回收器”
//JVM有很多种垃圾回收器,每一种都有自己的特性,并非某一种垃圾回收比其他的好,这要看用在哪一种程序里面
//比如服务端和客户端的垃圾回收差别就很大,客户端只要能将垃圾清理干净(暂停用户线程然后清理垃圾,即StopTheWorld)就OK了,但是服务器端不能这样做,它讲究并发
export HBASE_OPTS="-XX:+UseConcMarkSweepGC" //传给HMaster的JVM参数,永久区大小和最大永久区大小
export HBASE_MASTER_OPTS="$HBASE_MASTER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" //传给RegionServer的JVM参数,这些JVM参数都可以根据我们的服务器的情况进行调整
export HBASE_REGIONSERVER_OPTS="$HBASE_REGIONSERVER_OPTS -XX:PermSize=128m -XX:MaxPermSize=128m" //打印JVM的GC详细信息,并打印GC的时间
export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps" //指定将GC的详细信息打印到哪个文件,便于后续分析
export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>" export SERVER_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" //下面3个是打印客户端的一些GC信息设置
export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps"
export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH>"
export CLIENT_GC_OPTS="-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps -Xloggc:<FILE-PATH> -XX:+UseGCLogFileRotation -XX:NumberOfGCLogFiles=1 -XX:GCLogFileSize=512M" //你可以把用来做备份Master的节点的主机名放到下面的backup-masters文件中,作为Hbase的备选Master主机
export HBASE_BACKUP_MASTERS=${HBASE_HOME}/conf/backup-masters
6.修改配置文件hbase-site.xml
<configuration>
<!-- 指定hbase在HDFS上存储的路径,路径是自定义的 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://ns1/hbase</value>
</property>
<!-- 指定hbase是分布式的,让Hbase运行在分布式模式下 -->
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!—既然在hbase-env.sh中设置了不使用自己的zookeeper,所以这里要指定zookeeper的地址,多个用“,”分割 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hadoop01:2181, hadoop02:2181, hadoop03:2181</value>
</property>
</configuration>
7.修改regionservers
告诉这个regionservers脚本我们哪些机器用作regionserver节点:
hadoop01
hadoop02
hadoop03
8.创建backup-masters文件
由于hbase-env.sh配置文件中关于Hbase备选Master设置如下:

所以我们需要参加一个“backup-masters文件”(这个名字要和hbase-env.sh配置文件中设置的保持一致),我们设置hadoop02作为备选Master节点:
hadoop02
9.拷贝hadoop的配置文件到HBase[重要]
将hadoop的/root/apps/hadoop/etc/hadoop/目录下面的hdfs-site.xml和core-site.xml这两个配置文件拷贝到HBase的/root/apps/hbase-1.2.1/conf目录下:
[root@hadoop01 hadoop]# cp hdfs-site.xml core-site.xml /root/apps/hbase-1.2.1/conf/
10.将配置后的hbase目录拷贝到其他节点
在hadoop01上分别执行如下命令,将hadoop01上的hbase-1.2.1目录分别拷贝到hadoop02和hadoop03的相同目录下:
scp -r hbase-1.2.1/ hadoop02:$PWD
scp -r hbase-1.2.1/ hadoop03:$PWD
11.同步3台机器的时间
我们在使用HDFS的时候经常会出现一些莫名奇妙的问题,通常可能是由于多台服务器的时间不同步造成的。因为它要经常去分析一些时间戳、版本或者超时时间等,如果多台服务器的时间差的太远,可能会导致一些误判。
有两种方式来同步多台服务器的时间:
(1)在每台服务器上开启时间同步的进程,通过网络时间服务器进行同步;
(2)如果你的电脑不能联网,可以将多台服务器的时间手动改成一致的;
我们下面使用第二种方式来设置,使用“date –s”命令来同步时间:

12.启动Hbase集群
在启动Hbase集群之前,确保hdfs集群和zookeeper集群都已经启动成功。
我们打算让hadoop01来做Hbase的Master节点,所以我们在hadoop01上执行启动Hbase的命令“bin/start-hbase.sh”,并使用jps来查看进程,可以看到HMaster进程和HRegionServer两个进程:

在Hadoop02机器上可以看到HMaster(备用Master)和HRegionServer进程:

在hadoop03机器上可以看到HRegionServer进程:

打开浏览器访问:http://hadoop01:16010/
可以看到hadoop01是Master节点:

在浏览器中访问:http://hadoop02:16010/
可以看到hadoop02是备用Master节点:

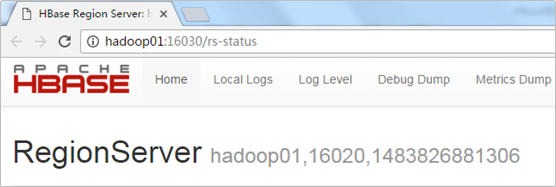
在浏览器中访问:http://hadoop01:16030
可以看到hadoop01也是RegionServer节点:
在浏览器中访问:http://hadoop02:16030/
可以看到hadoop02也是RegionServer节点:

在浏览器中访问:http://hadoop03:16030/
可以看到hadoop03也是RegionServer节点:

12.测试一下Hbase集群的高可用
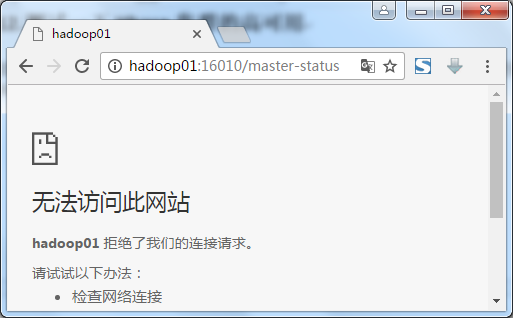
尝试将hadoop01上的HMaster进程kill掉,然后再通过浏览器观察,看hadoop02是否由原来的备用Master转成Master:

在浏览器中已经无法访问http://hadoop01:16010/:
在浏览器中访问http://hadoop02:16010/ 可以看到hadoop02从原来的BackupMaster变成了Master节点,接管了原来hadoop01的工作:
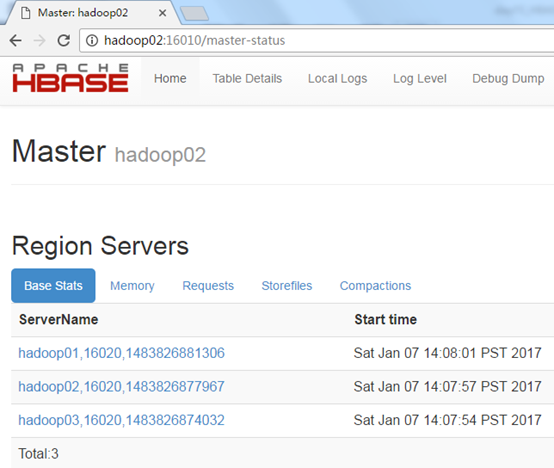
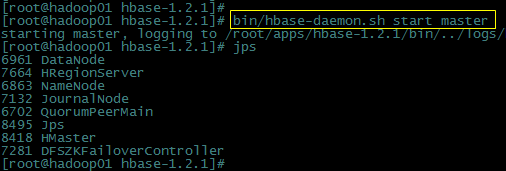
使用如下命令在hadoop01上重新启动一个Hbase的Master进程:
[root@hadoop01 hbase-1.2.1]# bin/hbase-daemon.sh start master
再在浏览器中访问:http://hadoop01:16010/ ,可以看到hadoop01自动成为备用Master节点:

HBase集群搭建的更多相关文章
- Hadoop+HBase 集群搭建
Hadoop+HBase 集群搭建 1. 环境准备 说明:本次集群搭建使用系统版本Centos 7.5 ,软件版本 V3.1.1. 1.1 配置说明 本次集群搭建共三台机器,具体说明下: 主机名 IP ...
- 高可用Hadoop平台-HBase集群搭建
1.概述 今天补充一篇HBase集群的搭建,这个是高可用系列遗漏的一篇博客,今天抽时间补上,今天给大家介绍的主要内容目录如下所示: 基础软件的准备 HBase介绍 HBase集群搭建 单点问题验证 截 ...
- Hbase集群搭建及所有配置调优参数整理及API代码运行
最近为了方便开发,在自己的虚拟机上搭建了三节点的Hadoop集群与Hbase集群,hadoop集群的搭建与zookeeper集群这里就不再详细说明,原来的笔记中记录过.这里将hbase配置参数进行相应 ...
- hbase集群搭建参考资料
hadoop分布式集群搭建 http://www.ityouknow.com/hadoop/2017/07/24/hadoop-cluster-setup.html hbase分布式集群搭建: htt ...
- 基于centos6.5 hbase 集群搭建
注意本章内容是在上一篇文章“基于centos6.5 hadoop 集群搭建”基础上创建的 1.上传hbase安装包 hbase-0.96.2-hadoop2 我的目录存放在/usr/hadoop/hb ...
- 大数据中HBase集群搭建与配置
hbase是分布式列式存储数据库,前提条件是需要搭建hadoop集群,需要Zookeeper集群提供znode锁机制,hadoop集群已经搭建,参考 Hadoop集群搭建 ,该文主要介绍Zookeep ...
- spark学习5(hbase集群搭建)
第一步:Hbase安装 hadoop,zookeeper前面都安装好了 将hbase-1.1.3-bin.tar.gz上传到/usr/HBase目录下 [root@spark1 HBase]# chm ...
- 五、Zookeeper、Hbase集群搭建
一.前提 1.安装JDK 2.安装Hadoop 3.安装zoookeeper 1.加入zookeeper包,并解压tar -zxvf zookeeper-3.4.9.tar.gz 2.去/etc/pr ...
- 虚拟机zookeeper和hbase集群搭建
集群zookeeper dataDir=/usr/local/zookeeper/dataDir dataLogDir=/usr/local/zookeeper/dataLogDir # the po ...
随机推荐
- C#微信开发文档
C#微信开发文档 开发前准备 微信公众平台链接: https://mp.weixin.qq.com/cgi-bin/home?t=home/index&lang=zh_CN 开发初期我们使用测 ...
- 制作动画平滑过渡效果:《CSS3 Transition》
W3C标准中对css3的transition这是样描述的:“css的transition允许css的属性值在一定的时间区间内平滑地过渡.这种效果可以在鼠标单击.获得焦点.被点击或对元素任何改变中触发, ...
- java配置自动任务,定期执行代码
任务调用类: package business.tools.service; import java.util.ArrayList; import java.util.Calendar; import ...
- WebForm 发送邮箱
首先在设置发件邮箱的SMTP服务,以新浪邮箱为例:设置区----客户端pop/imap/smtp----"POP3/SMTP服务"和"IMAP4服务/SMTP服务&quo ...
- Eclipse启动提示Failed to load the JNI shared library JVM.dll
一.出现了上述问题解决办法 1.查看eclipse.ini文件 看看eclipse环境架构需要的是什么. plugins/org.eclipse.equinox.launcher.win32.win3 ...
- P2312 解方程
题目描述 已知多项式方程: a0+a1x+a2x^2+..+anx^n=0 求这个方程在[1, m ] 内的整数解(n 和m 均为正整数) 输入输出格式 输入格式: 输入文件名为equation .i ...
- easyui表单插件-包括日期时控件-列表
← jQuery EasyUI 表单插件 – Numberspinner 数值微调器 jQuery EasyUI 表单插件 - Timespinner 时间微调器 jQuery EasyUI 插件 ...
- Shell脚本编程初体验
原文:http://linoxide.com/linux-shell-script/guide-start-learning-shell-scripting-scratch/ 作者: Petras L ...
- [HDOJ5938]Four Operations(暴力,DFS)
题目链接:http://acm.hdu.edu.cn/showproblem.php?pid=5938 题意:给出一个长度最大是2020的数字串, 你要把数字串划分成55段, 依次填入'+', '-' ...
- [HDOJ1231]最大连续子序列
混了好几个地方的博客,还是觉得博客园比较靠谱,于是决定在这里安家落户了.本人本科生一个,希望各位巨巨多多指教~ Hello World! 单独一个象征性的问候实在是太low了,还是决定来点实质性的.. ...