爬虫再探实战(四)———爬取动态加载页面——请求json
还是上次的那个网站,就是它.现在尝试用另一种办法——直接请求json文件,来获取要抓取的信息。
第一步,检查元素,看图如下:
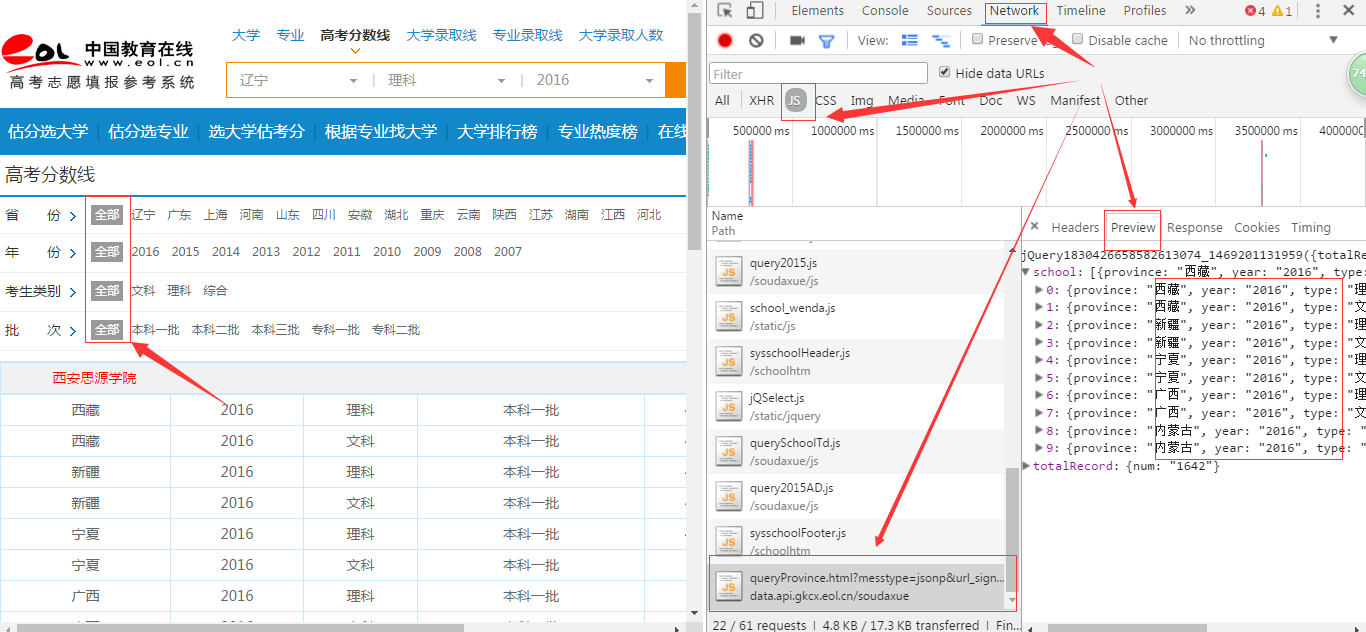
过滤出JS文件,并找出包含要抓取信息的js文件,之后就是构造requests请求对象,然后解析json文件啦。源码如下:
import requests def save(school_datas):
for data in school_datas:
# print(data)
year = data['year']
province = data['province']
type = data['type']
bath = data['bath']
score = data['score']
print(province, year, type, bath,score ) for i in range(1, 34):
print("第%s页====================="%str(i))
# url = "http://data.api.gkcx.eol.cn/soudaxue/queryProvince.html?messtype=jsonp&url_sign=queryprovince&province3=&year3=&page=1&size=100&luqutype3=&luqupici3=&schoolsort=&suiji=&callback=jQuery1830426658582613074_1469201131959&_=1469201133189"
data = requests.get("http://data.api.gkcx.eol.cn/soudaxue/queryProvince.html", params={"messtype":"json","url_sign":"queryprovince","page":str(i),"size":"50","callback":"jQuery1830426658582613074_1469201131959","_":"1469201133189"}).json()
print("每一页信息条数——>", len(data['school']))
print("全部信息条数——>", data["totalRecord"]['num'])
school_datas = data["school"]
save(school_datas)
简单说明一下params部分,大部分是从json文件网址中截取信息构造,其中size参数是一个页面返回的信息数量,可调节大小,网站一般有限制,这里是50(就算size超出50的话也是返回50条);page,就是字面意思啦,这里从1请求到33为止,33由int(1640/50) + 1)得到,1640是信息总条数。此外,params还可以设置其他参数来具体指定省份时间等。
最重要的,在同样的网速下,这个程序不仅简单,而且,3s左右就可以输出全部结果(这里只是输出,没有保存),效率高出模拟登陆不是一点啊。。。
关于动态加载网页的抓取先到这里告一段落,之后打算简单学习一下JS相关的知识再来总结一下。
最后感谢群里面两位大牛的指点,@南京-天台@四川-Irony。
爬虫再探实战(四)———爬取动态加载页面——请求json的更多相关文章
- Python+Selenium爬取动态加载页面(2)
注: 上一篇<Python+Selenium爬取动态加载页面(1)>讲了基本地如何获取动态页面的数据,这里再讲一个稍微复杂一点的数据获取全国水雨情网.数据的获取过程跟人手动获取过程类似,所 ...
- Python+Selenium爬取动态加载页面(1)
注: 最近有一小任务,需要收集水质和水雨信息,找了两个网站:国家地表水水质自动监测实时数据发布系统和全国水雨情网.由于这两个网站的数据都是动态加载出来的,所以我用了Selenium来完成我的数据获取. ...
- 爬虫再探实战(三)———爬取动态加载页面——selenium
自学python爬虫也快半年了,在目前看来,我面临着三个待解决的爬虫技术方面的问题:动态加载,多线程并发抓取,模拟登陆.目前正在不断学习相关知识.下面简单写一下用selenium处理动态加载页面相关的 ...
- Scrapy 框架 使用 selenium 爬取动态加载内容
使用 selenium 爬取动态加载内容 开启中间件 DOWNLOADER_MIDDLEWARES = { 'wangyiPro.middlewares.WangyiproDownloaderMidd ...
- C#使用phantomjs,爬取AJAX加载完成之后的页面
1.开发思路:入参根据apiSetting配置文件,分配静态文件存储地址,可实现不同站点的静态页生成功能.静态页生成功能使用无头浏览器生成,生成之后的字符串进行正则替换为固定地址,实现本地正常访问. ...
- ExtJS 4.1 TabPanel动态加载页面并执行脚本【转】
ExtJS 4.1 TabPanel动态加载页面并执行脚本 按照官方示例,可以动态加载页面,可是脚本不执行,于是查SDK.google,发现scripts需要设置为true,于是设置该属性,整个代码如 ...
- 记录Js动态加载页面.append、html、appendChild、repend添加元素节点不生效以及解决办法
今天再优化blog页面的时候添加了个关注按钮和图片,但是页面上这个按钮和图片时有时无,本来是搞后端的,被这个前端的小问题搞得抓耳挠腮的! 网上各种查询解决方案,把我解决问题的艰辛历程分享出来,希望大家 ...
- div动态加载页面
div动态加载页面 /* /// method 1 var url="<%=basePath%>/qne.do?p=pessegerCountSet"; $.post( ...
- Python 爬虫实例(8)—— 爬取 动态页面
今天使用python 和selenium爬取动态数据,主要是通过不停的更新页面,实现数据的爬取,要爬取的数据如下图 源代码: #-*-coding:utf-8-*- import time from ...
随机推荐
- 11 个用来创建图形和图表的 JavaScript 工具包
11个用来创建图形和图表的JavaScript工具包,方便开发者使用,喜欢的各位收藏一下吧! Aristochart DEMO|| Download Aristochart 是一个用来创建图形和图表的 ...
- hduoj-----(1068)Girls and Boys(二分匹配)
Girls and Boys Time Limit: 20000/10000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) ...
- 5. Longest Palindromic Substring -- 最长回文字串
Given a string S, find the longest palindromic substring in S. You may assume that the maximum lengt ...
- SAP 质检使用非物料基本单位
今天也是奇葩了,物料A基本单位平方米,转化单位卷,销售和采购是按照平方米来采购,但是质检的需要按照平方米来做抽样检验.... 程序开发的: 修改该物料的工序基本单位为卷,再修改检验计划基本单位为卷 程 ...
- SQL Server数据库(SQL Sever语言 存储过程及触发器)
存储过程:就像函数一样的会保存在数据库中-->可编程性-->存储过程 创建存储过程: 保存在数据库表,可编程性,存储过程create proc jiafa --需要的参数@a int,@b ...
- 【转载】FLUNT温度场模拟
1. Gambit 绘制几何计算域,划分网格,定义边界类型 2. fluent设置以及计算 注意: define->models->energy 打开能量方程 de ...
- Javascript 严格模式详解(转)
一.概述 除了正常运行模式,ECMAscript 5添加了第二种运行模式:"严格模式"(strict mode).顾名思义,这种模式使得Javascript在更严格的条件下运行. ...
- DOM系列---基础篇[转]
DOM (Document Object Model) 即文档对象模型, 针对 HTML 和 XML 文档的 API (应用程序接口) .DOM 描绘了一个层次化的节点树,运行开发人员添加.移除和修改 ...
- tds 安装找不到已安装的DB2
应该是没有安装ksh的问题,yum install ksh
- eclipse隐藏菜单栏实现全部酷黑主题
将eclipse升级到了最新版的neon,将主题颜色设置为了dark,瞬间高大上了很多,唯独菜单栏还是白色的,很刺眼.况且菜单栏不是很常用,所以我们可以将菜单栏隐藏起来,以达到全部黑色的效果. 步骤: ...