Machine Learning for hackers读书笔记(二)数据分析
#均值:总和/长度
mean()
#中位数:将数列排序,若个数为奇数,取排好序数列中间的值.若个数为偶数,取排好序数列中间两个数的平均值
median()
#R语言中没有众数函数
#分位数
quantile(data):列出0%,25%,50%,75%,100%位置处的数据
#可自己设置百分比
quantile(data,probs=0.975)
#方差:衡量数据集里面任意数值与均值的平均偏离程度
var()
#标准差:
sd()
#直方图,binwidth表示区间宽度为1
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 1)

#发现上图是对称的,使用直方图时记住:区间宽度是强加给数据的一个外部结构,但是它却同时揭示了数据的内部结构
#把宽度改成5
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 5)
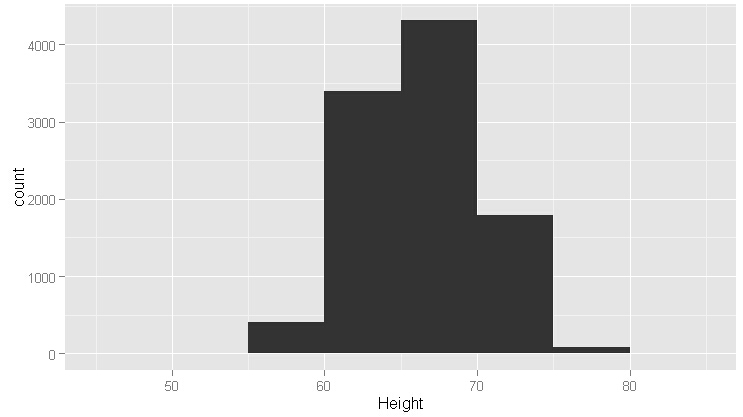
#从上图看,对称性不存在了,这叫过平滑,相反的情况叫欠平滑,如下图
ggplot(heights.weights, aes(x = Height)) +geom_histogram(binwidth = 0.01)

#因此合适的直方图需要调整宽度值.可以选择其他方式进行可视化,即密度曲线图
ggplot(heights.weights, aes(x = Height)) +geom_density()

#如上图,峰值平坦,尝试按性别划分数据
ggplot(heights.weights, aes(x = Height, fill = Gender)) +geom_density()

#混合模型,由两个标准分布混合而形成的一个非标准分布
#正态分布,钟形曲线或高斯分布
#按性别分片
ggplot(heights.weights, aes(x = Weight, fill = Gender)) +geom_density() +facet_grid(Gender ~ .)

#以下代码指定分布的均值和方差,m和s可以调整,只是移动中心或伸缩宽度
m <- 0
s <- 1
ggplot(data.frame(X = rnorm(100000, m, s)), aes(x = X)) +geom_density()
#构建出了密度曲线,众数在钟形的峰值处
#正态分布的众数同时也是均值和中位数
#只有一个众数叫单峰,两个叫双峰,两个以上叫多峰
#从一个定性划分分布有对称(symmetric)分布和偏态(skewed)分布
#对称(symmetric)分布:众数左右两边形状一样,比如正态分布
#这说明观察到小于众数的数据和大于众数的数据可能性是一样的.
#偏态(skewed)分布:说明在众数右侧观察到极值的可能性要大于其左侧,称为伽玛分布
#从另一个定性区别划分两类数据:窄尾分布(thin-tailed)和重尾分布(heavy-tailed)
#窄尾分布(thin-tailed)所产生的值通常都在均值附近,可能性有99%
#柯西分布(Cauchy distribution)大约只有90%的值落在三个标准差内,距离均值越远,分布特点越不同
#正态分布几乎不可能产生出距离均值有6个标准差的值,柯西分布有5%的可能性
#产生正态分布及柯西分布随机数
set.seed(1)
normal.values <- rnorm(250, 0, 1)
cauchy.values <- rcauchy(250, 0, 1)
range(normal.values)
range(cauchy.values)
#画图
ggplot(data.frame(X = normal.values), aes(x = X)) +geom_density()
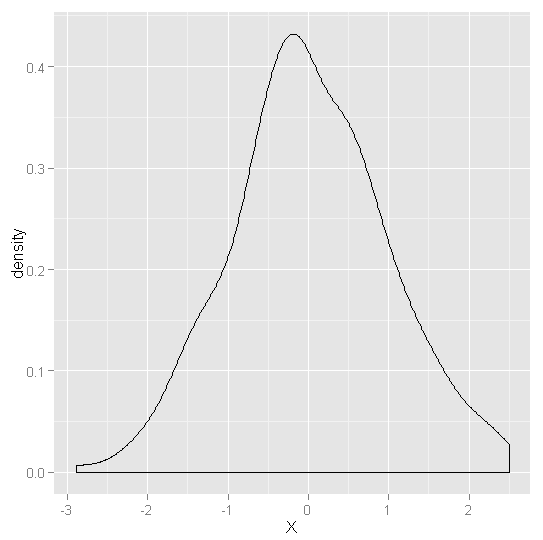
ggplot(data.frame(X = cauchy.values), aes(x = X)) +geom_density()
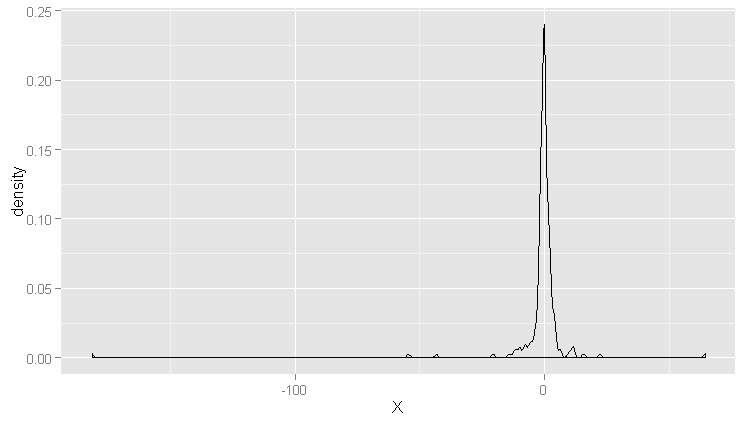
#正态分布:单峰,对称,钟形窄尾
#柯西分布:单峰,对称,钟形重尾
#产生gamma分布随机数
gamma.values <- rgamma(100000, 1, 0.001)
ggplot(data.frame(X = gamma.values), aes(x = X)) +geom_density()

#游戏数据很多都符合伽玛分布
#伽玛分布只有正值
#指数分布:数据集中频数最高是0,并且只有非负值出现
#例如,企业呼叫中心常发现两次收到呼叫请求的间隔时间看上去符合指数分布
#散点图
ggplot(heights.weights, aes(x = Height, y = Weight)) +geom_point()
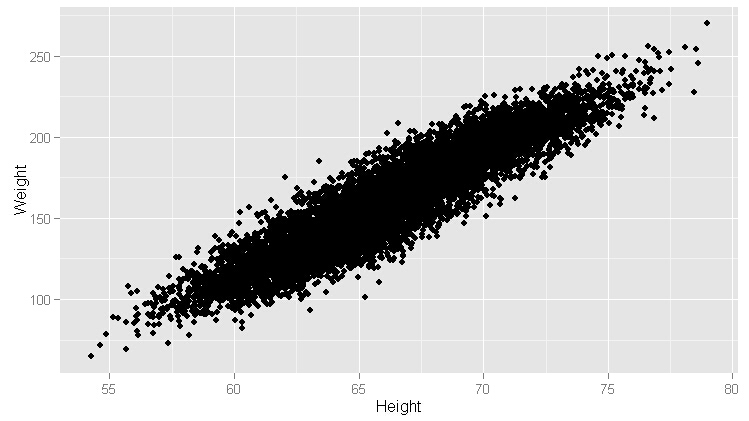
#加平滑模式
ggplot(heights.weights, aes(x = Height, y = Weight)) +geom_point() +geom_smooth()
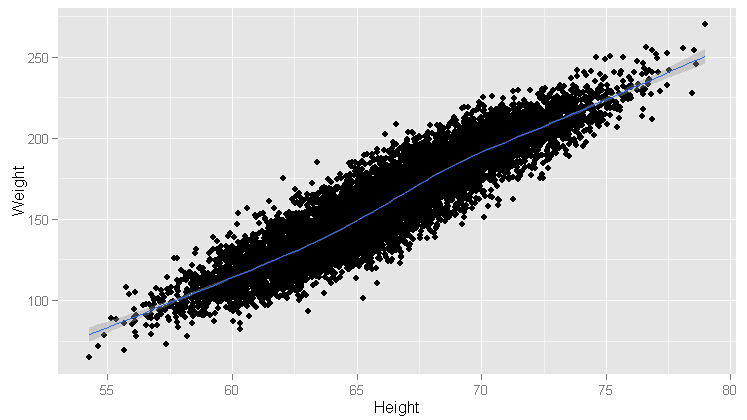
ggplot(heights.weights[1:20, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()
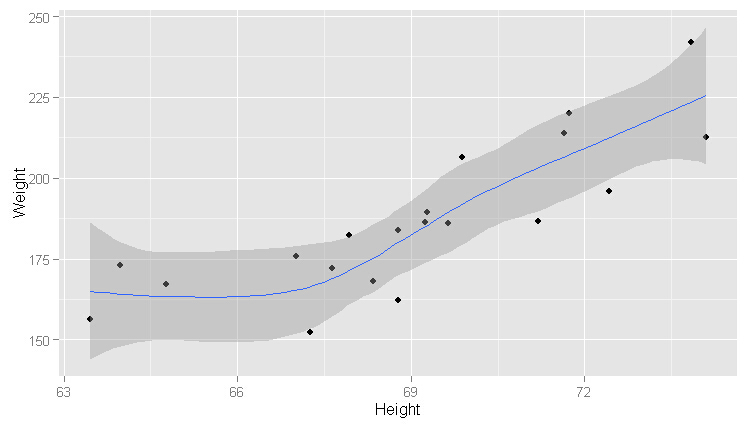
ggplot(heights.weights[1:200, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()

ggplot(heights.weights[1:2000, ], aes(x = Height, y = Weight)) +geom_point() +geom_smooth()

ggplot(heights.weights, aes(x = Height, y = Weight)) +
geom_point(aes(color = Gender, alpha = 0.25)) +
scale_alpha(guide = "none") +
scale_color_manual(values = c("Male" = "black", "Female" = "gray")) +
theme_bw()
# An alternative using bright colors.
ggplot(heights.weights, aes(x = Height, y = Weight, color = Gender)) +
geom_point()
#
# Snippet 35
#
heights.weights <- transform(heights.weights,
Male = ifelse(Gender == 'Male', 1, 0))
logit.model <- glm(Male ~ Weight + Height,
data = heights.weights,
family = binomial(link = 'logit'))
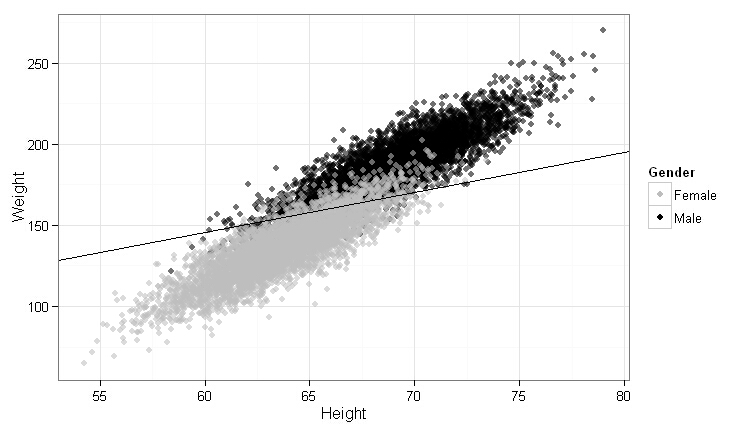
ggplot(heights.weights, aes(x = Height, y = Weight)) +
geom_point(aes(color = Gender, alpha = 0.25)) +
scale_alpha(guide = "none") +
scale_color_manual(values = c("Male" = "black", "Female" = "gray")) +
theme_bw() +
stat_abline(intercept = -coef(logit.model)[1] / coef(logit.model)[2],
slope = - coef(logit.model)[3] / coef(logit.model)[2],
geom = 'abline',
color = 'black')
Machine Learning for hackers读书笔记(二)数据分析的更多相关文章
- Machine Learning for hackers读书笔记(十二)模型比较
library('ggplot2')df <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\12-Model_C ...
- Machine Learning for hackers读书笔记(十)KNN:推荐系统
#一,自己写KNN df<-read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\10-Recommendations\\ ...
- Machine Learning for hackers读书笔记(七)优化:密码破译
#凯撒密码:将每一个字母替换为字母表中下一位字母,比如a变成b. english.letters <- c('a', 'b', 'c', 'd', 'e', 'f', 'g', 'h', 'i' ...
- Machine Learning for hackers读书笔记(六)正则化:文本回归
data<-'F:\\learning\\ML_for_Hackers\\ML_for_Hackers-master\\06-Regularization\\data\\' ranks < ...
- Machine Learning for hackers读书笔记(三)分类:垃圾邮件过滤
#定义函数,打开每一个文件,找到空行,将空行后的文本返回为一个字符串向量,该向量只有一个元素,就是空行之后的所有文本拼接之后的字符串 #很多邮件都包含了非ASCII字符,因此设为latin1就可以读取 ...
- Machine Learning for hackers读书笔记_一句很重要的话
为了培养一个机器学习领域专家那样的直觉,最好的办法就是,对你遇到的每一个机器学习问题,把所有的算法试个遍,直到有一天,你凭直觉就知道某些算法行不通.
- Machine Learning for hackers读书笔记(九)MDS:可视化地研究参议员相似性
library('foreign') library('ggplot2') data.dir <- file.path('G:\\dataguru\\ML_for_Hackers\\ML_for ...
- Machine Learning for hackers读书笔记(八)PCA:构建股票市场指数
library('ggplot2') prices <- read.csv('G:\\dataguru\\ML_for_Hackers\\ML_for_Hackers-master\\08-PC ...
- Machine Learning for hackers读书笔记(五)回归模型:预测网页访问量
线性回归函数 model<-lm(Weight~Height,data=?) coef(model):得到回归直线的截距 predict(model):预测 residuals(model):残 ...
随机推荐
- nodejs快速入门
目录: 编写第一个Node.js程序: 异步式I/O和事件循环: 模块和包: 调试. 1. 编写第一个Node.js程序: Node.js 具有深厚的开源血统,它诞生于托管了许多优秀开源项目的网站—— ...
- sql server 批量删除数据表
SET ANSI_NULLS ONGOSET QUOTED_IDENTIFIER ONGO-- =============================================-- Auth ...
- delphi 网络函数
Delphi网络函数 unit net; interfaceusessysutils,windows,dialogs,winsock,classes,comobj,wininet; //得到本机的局域 ...
- Android的事件处理机制详解(二)-----基于监听的事件处理机制
基于监听的事件处理机制 前言: 我们开发的app更多的时候是需要与用户的交互----即对用户的操作进行响应 这就涉及到了android的事件处理机制; android给我们提供了两套功能强大的处理机制 ...
- $("#id a") - $("#id .c a") = ?
前沿 这是之前淘宝的一道面试题,题目借用了 jQuery 选择器的语法.大概的意思是,从 #id 元素内选出所有不是 .c 后代的 a 元素,即父元素 #id 内的所有后代元素中,选出不是 .c 后代 ...
- 通过HTTP头控制浏览器的缓存
通过HTTP头控制浏览器的缓存 浏览器缓存是提高用户体验和提升程序性能的一个很重要的途径,通过浏览器的缓存控制,可以对实时性要求不高的数据进行缓存,可以减少甚至不需要再次对服务器的请求就可以显示数据. ...
- node操作mysql数据库
1.建立数据库连接:createConnection(Object)方法 该方法接受一个对象作为参数,该对象有四个常用的属性host,user,password,database.与php ...
- ffmpeg转码时对编码率和固定码率的处理
http://www.rosoo.net/a/201107/14663.html 一般fps在代码里这样表示 Fps = den/num 如果den = 15,num=1,则fps = 15. 如果帧 ...
- Spring框架学习之第6节
bean的生命周期 为什么总是一个生命当做一个重点? Servlet –> servlet生命周期 Java对象生命周期 往往笔试,面试总喜欢问生命周期的问题? ① 实例化(当我们的程序加载 ...
- IIS7 ASP.NET 未被授权访问所请求的资源
IIS7 ASP.NET 未被授权访问所请求的资源 ASP.NET 未被授权访问所请求的资源.请考虑授予 ASP.NET 请求标识访问此资源的权限. ASP.NET 有一个在应用程序没有模拟时使用的基 ...