[转帖] Linux命令拾遗-剖析工具
https://www.cnblogs.com/codelogs/p/16060472.html
简介#
这是Linux命令拾遗系列的第五篇,本篇主要介绍Linux中常用的线程与内存剖析工具,以及更高级的perf性能分析工具等。
本系列文章索引
Linux命令拾遗-入门篇
Linux命令拾遗-文本处理篇
Linux命令拾遗-软件资源观测
Linux命令拾遗-硬件资源观测
像vmstat,top等资源观测命令,只能观测到资源整体使用情况,以及在各进程/线程上的使用情况,但没法了解到进程/线程为什么会使用这么多资源?
这种情况下,可以通过剖析(profile)工具做进一步分析,如jstack,jmap,pstack,gcore,perf等。
jstack#
jstack是JVM下的线程剖析工具,可以打印出当前时刻各线程的调用栈,这样就可以了解到jvm中各线程都在干什么了,如下:
$ jstack 3051
2021-11-07 21:55:06
Full thread dump OpenJDK 64-Bit Server VM (11.0.12+7 mixed mode):
Threads class SMR info:
_java_thread_list=0x00007f3380001f00, length=10, elements={
0x00007f33cc027800, 0x00007f33cc22f800, 0x00007f33cc233800, 0x00007f33cc24b800,
0x00007f33cc24d800, 0x00007f33cc24f800, 0x00007f33cc251800, 0x00007f33cc253800,
0x00007f33cc303000, 0x00007f3380001000
}
"main" 1 prio=5 os_prio=0 cpu=2188.06ms elapsed=1240974.04s tid=0x00007f33cc027800 nid=0xbec runnable [0x00007f33d1b68000]
java.lang.Thread.State: RUNNABLE
at java.io.FileInputStream.readBytes(java.base@11.0.12/Native Method)
at java.io.FileInputStream.read(java.base@11.0.12/FileInputStream.java:279)
at java.io.BufferedInputStream.read1(java.base@11.0.12/BufferedInputStream.java:290)
at java.io.BufferedInputStream.read(java.base@11.0.12/BufferedInputStream.java:351)
- locked <0x00000007423a5ba8> (a java.io.BufferedInputStream)
at sun.nio.cs.StreamDecoder.readBytes(java.base@11.0.12/StreamDecoder.java:284)
at sun.nio.cs.StreamDecoder.implRead(java.base@11.0.12/StreamDecoder.java:326)
at sun.nio.cs.StreamDecoder.read(java.base@11.0.12/StreamDecoder.java:178)
- locked <0x0000000745ad1cf0> (a java.io.InputStreamReader)
at java.io.InputStreamReader.read(java.base@11.0.12/InputStreamReader.java:181)
at java.io.Reader.read(java.base@11.0.12/Reader.java:189)
at java.util.Scanner.readInput(java.base@11.0.12/Scanner.java:882)
at java.util.Scanner.findWithinHorizon(java.base@11.0.12/Scanner.java:1796)
at java.util.Scanner.nextLine(java.base@11.0.12/Scanner.java:1649)
at com.example.clientserver.ClientServerApplication.getDemo(ClientServerApplication.java:57)
at com.example.clientserver.ClientServerApplication.run(ClientServerApplication.java:40)
at org.springframework.boot.SpringApplication.callRunner(SpringApplication.java:804)
at org.springframework.boot.SpringApplication.callRunners(SpringApplication.java:788)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:333)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1309)
at org.springframework.boot.SpringApplication.run(SpringApplication.java:1298)
at com.example.clientserver.ClientServerApplication.main(ClientServerApplication.java:27)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke0(java.base@11.0.12/Native Method)
at jdk.internal.reflect.NativeMethodAccessorImpl.invoke(java.base@11.0.12/NativeMethodAccessorImpl.java:62)
at jdk.internal.reflect.DelegatingMethodAccessorImpl.invoke(java.base@11.0.12/DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(java.base@11.0.12/Method.java:566)
at org.springframework.boot.loader.MainMethodRunner.run(MainMethodRunner.java:49)
at org.springframework.boot.loader.Launcher.launch(Launcher.java:107)
at org.springframework.boot.loader.Launcher.launch(Launcher.java:58)
at org.springframework.boot.loader.JarLauncher.main(JarLauncher.java:88)
"Reference Handler" 2 daemon prio=10 os_prio=0 cpu=2.76ms elapsed=1240973.97s tid=0x00007f33cc22f800 nid=0xbf3 waiting on condition [0x00007f33a820a000]
java.lang.Thread.State: RUNNABLE
at java.lang.ref.Reference.waitForReferencePendingList(java.base@11.0.12/Native Method)
at java.lang.ref.Reference.processPendingReferences(java.base@11.0.12/Reference.java:241)
at java.lang.ref.Reference$ReferenceHandler.run(java.base@11.0.12/Reference.java:213)
实例:找占用CPU较高问题代码#
如果你发现你的java进程CPU占用一直都很高,可以用如下方法找到问题代码:
1,找出占用cpu的线程号pid
# -H表示看线程,其中312是java进程的pid
$ top -H -p 312
2,转换线程号为16进制
# 其中62是从top中获取的高cpu的线程pid
$ printf "%x" 314
13a
3,获取进程中所有线程栈,提取对应高cpu线程栈
$ jstack 312 | awk -v RS= '/0x13a/'
通过这种方法,可以很容易找到类似大循环或死循环之类性能极差的代码。
实例:查看各线程数量#
$ jstack 10235|grep -oP '"[^"]+"'|sed -E 's/[0-9]+/n/g'|sort|uniq -c|sort -nr
8 "GC Thread#n"
2 "Gn Conc#n"
2 "Cn CompilerThreadn"
1 "main"
1 "VM Thread"
1 "VM Periodic Task Thread"
1 "Sweeper thread"
1 "Signal Dispatcher"
1 "Service Thread"
1 "Reference Handler"
1 "Gn Young RemSet Sampling"
1 "Gn Refine#n"
1 "Gn Main Marker"
1 "Finalizer"
1 "Common-Cleaner"
1 "Attach Listener"
如上,通过uniq等统计jvm各线程数量,可用于快速确认业务线程池中线程数量是否正常。
jmap#
jmap是JVM下的内存剖析工具,用来分析或导出JVM堆数据,如下:
# 查看对象分布直方图,其中3051是java进程的pid
$ jmap -histo:live 3051 | head -n20
num instances bytes class name (module)
-------------------------------------------------------
1: 19462 1184576 [B (java.base@11.0.12)
2: 3955 469920 java.lang.Class (java.base@11.0.12)
3: 18032 432768 java.lang.String (java.base@11.0.12)
4: 11672 373504 java.util.concurrent.ConcurrentHashMap$Node (java.base@11.0.12)
5: 3131 198592 [Ljava.lang.Object; (java.base@11.0.12)
6: 5708 182656 java.util.HashMap$Node (java.base@11.0.12)
7: 1606 155728 [I (java.base@11.0.12)
8: 160 133376 [Ljava.util.concurrent.ConcurrentHashMap$Node; (java.base@11.0.12)
9: 1041 106328 [Ljava.util.HashMap$Node; (java.base@11.0.12)
10: 6216 99456 java.lang.Object (java.base@11.0.12)
11: 1477 70896 sun.util.locale.LocaleObjectCache$CacheEntry (java.base@11.0.12)
12: 1403 56120 java.util.LinkedHashMap$Entry (java.base@11.0.12)
13: 1322 52880 java.lang.ref.SoftReference (java.base@11.0.12)
14: 583 51304 java.lang.reflect.Method (java.base@11.0.12)
15: 999 47952 java.lang.invoke.MemberName (java.base@11.0.12)
16: 29 42624 [C (java.base@11.0.12)
17: 743 41608 java.util.LinkedHashMap (java.base@11.0.12)
18: 877 35080 java.lang.invoke.MethodType (java.base@11.0.12)
也可以直接将整个堆内存转储为文件,如下:
$ jmap -dump:format=b,file=heap.hprof 3051
Heap dump file created
$ ls *.hprof
heap.hprof
堆转储文件是二进制文件,没法直接查看,一般是配合mat(Memory Analysis Tool)等堆可视化工具来进行分析,如下:
mat打开hprof文件后,会看下如下一个概要界面。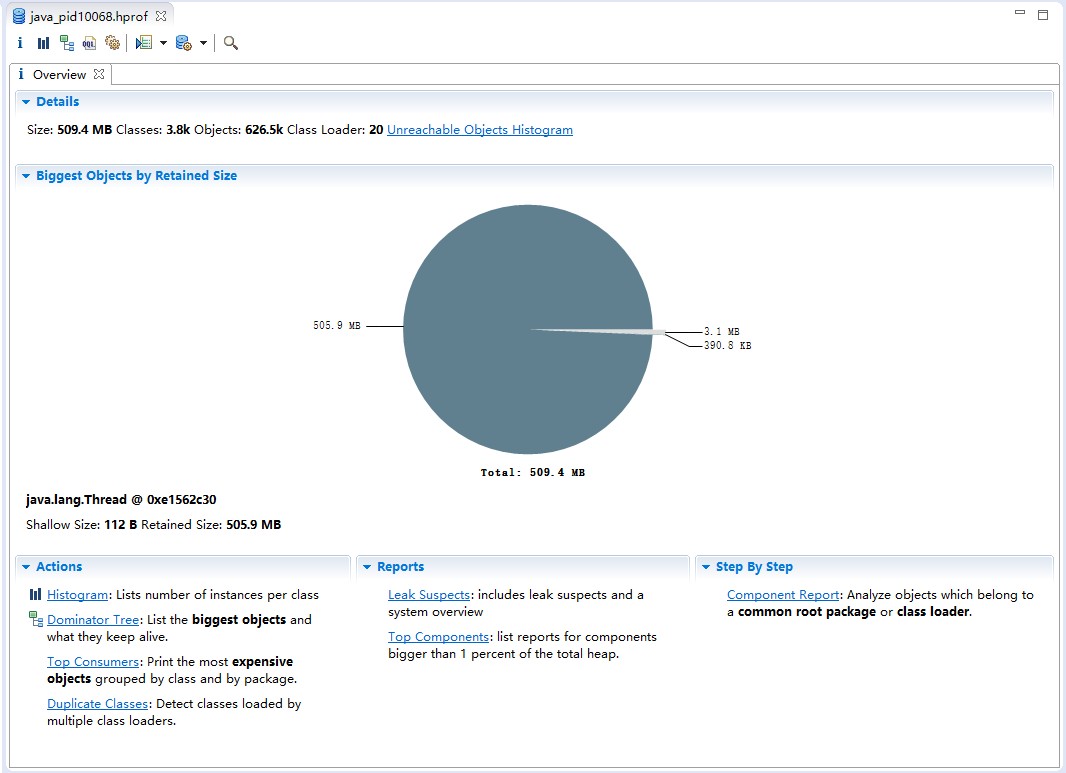
点击Histogram可以按类维度查询内存占用大小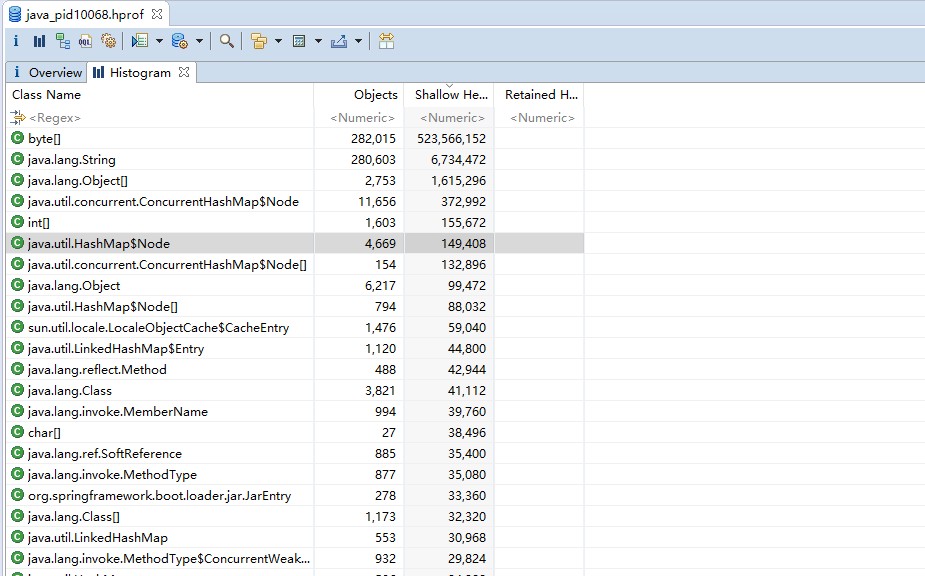
点击Dominator Tree可以看到各对象总大小(Retained Heap,包含引用的子对象),以及所占内存比例,可以看到一个ArrayList对象占用99.31%,看来是个bug,找到创建ArrayList的代码,修改即可。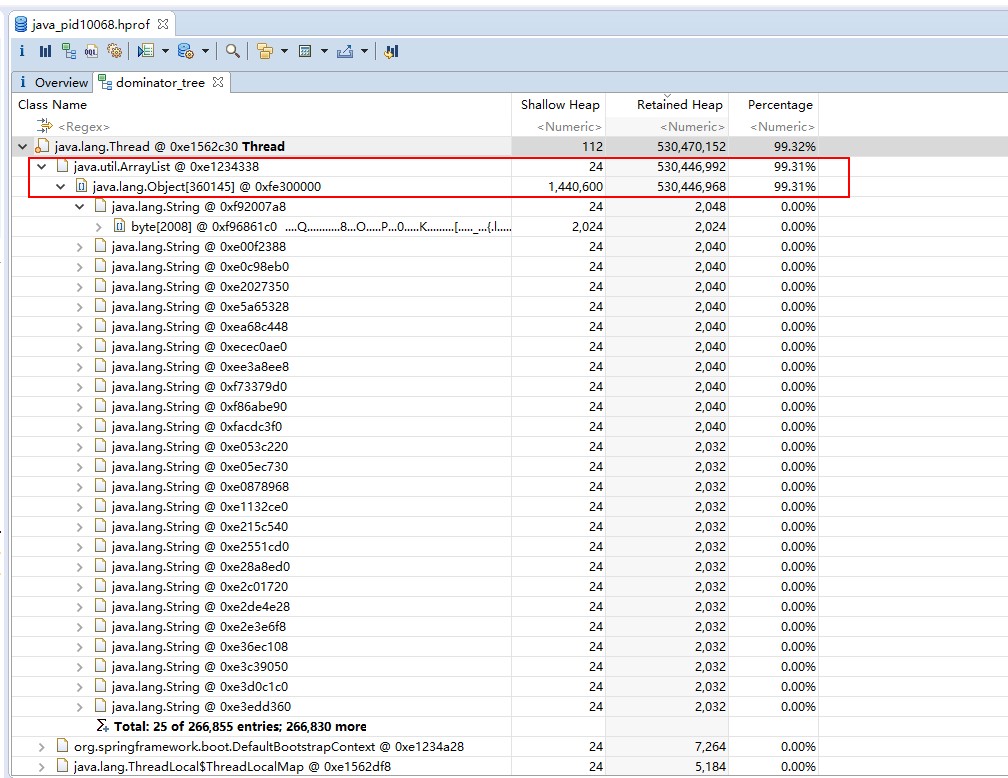
可以看到,使用jmap+mat很容易分析内存泄露bug,但需要注意的是,jmap执行时会让jvm暂停,对于高并发的服务,最好先将问题节点摘除流量后再操作。
另外,可以在jvm上添加参数-XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=./dump/,使得在发生内存溢出时,自动生成堆转储文件到dump目录。
mat下载地址:http://www.eclipse.org/mat/
pstack#
pstack是c/c++等原生程序的线程剖析工具,类似jstack,不过是面向原生程序的,用法如下:
$ pstack $pid
例如,mysql是用c/c++写的,当mysql运行hang住时,可以通过pstack来查看线程栈。
如下,执行一个update SQL卡住了,我们来分析分析为啥?
1,使用processlist找出问题SQL的线程id
mysql> select t.thread_id,t.thread_os_id,pl.* from information_schema.processlist pl
join performance_schema.threads t on pl.id = t.processlist_id;
+-----------+--------------+----+------+---------------------+------+---------+------+-----------+---------------------------------------------------------------------------------------------------------->
| thread_id | thread_os_id | ID | USER | HOST | DB | COMMAND | TIME | STATE | INFO >
+-----------+--------------+----+------+---------------------+------+---------+------+-----------+---------------------------------------------------------------------------------------------------------->
| 32 | 4850 | 7 | root | 10.142.72.126:34934 | NULL | Query | 0 | executing | select t.thread_id,t.thread_os_id,pl.* from information_schema.processlist pl join performance_schema.thr>
| 33 | 5771 | 8 | root | 10.142.112.35:54795 | NULL | Sleep | 488 | | NULL >
| 34 | 4849 | 9 | root | 10.142.112.35:54796 | demo | Sleep | 442 | | NULL >
| 35 | 5185 | 10 | root | 10.142.112.35:54797 | demo | Query | 403 | updating | update order set status=1 where oid=1 >
| 37 | 28904 | 12 | root | 10.142.72.126:34936 | demo | Sleep | 411 | | NULL >
+-----------+--------------+----+------+---------------------+------+---------+------+-----------+---------------------------------------------------------------------------------------------------------->
5 rows in set (0.00 sec)
可以看到,处理update SQL的线程的thread_os_id是5185
2,使用pstack获取线程栈
# 其中3287是mysqld进程的pid
$ pstack 3287 > mysqld_stack.log
3,在线程栈中找到卡住线程
$ cat mysqld_stack.log | awk -v RS= '$1 ~ /5185/'
Thread 33 (Thread 0x7fe3c05ea700 (LWP 5185)):
0 futex_wait_cancelable (private=<optimized out>, expected=0, futex_word=0x7fe358025474) at ../sysdeps/nptl/futex-internal.h:183
1 __pthread_cond_wait_common (abstime=0x0, clockid=0, mutex=0x7fe358025420, cond=0x7fe358025448) at pthread_cond_wait.c:508
2 __pthread_cond_wait (cond=0x7fe358025448, mutex=0x7fe358025420) at pthread_cond_wait.c:638
3 0x000055c1b85b55f8 in os_event::wait (this=0x7fe358025408) at /home/work/softwares/mysql-5.7.30/storage/innobase/os/os0event.cc:179
4 0x000055c1b85b4a24 in os_event::wait_low (this=0x7fe358025408, reset_sig_count=6) at /home/work/softwares/mysql-5.7.30/storage/innobase/os/os0event.cc:366
5 0x000055c1b85b51bc in os_event_wait_low (event=0x7fe358025408, reset_sig_count=0) at /home/work/softwares/mysql-5.7.30/storage/innobase/os/os0event.cc:611
6 0x000055c1b8579097 in lock_wait_suspend_thread (thr=0x7fe35800ab60) at /home/work/softwares/mysql-5.7.30/storage/innobase/lock/lock0wait.cc:315
7 0x000055c1b863f860 in row_mysql_handle_errors (new_err=0x7fe3c05e6cf4, trx=0x7fe41c3c18d0, thr=0x7fe35800ab60, savept=0x0) at /home/work/softwares/mysql-5.7.30/storage/innobase/row/row0mysql.cc:783
8 0x000055c1b868514b in row_search_mvcc (buf=0x7fe35801eab0 "\377", mode=PAGE_CUR_GE, prebuilt=0x7fe35800a3a0, match_mode=1, direction=0) at /home/work/softwares/mysql-5.7.30/storage/innobase/row/row0sel.cc:6170
9 0x000055c1b84d83e1 in ha_innobase::index_read (this=0x7fe35801e7c0, buf=0x7fe35801eab0 "\377", key_ptr=0x7fe35800c400 "\001", key_len=8, find_flag=HA_READ_KEY_EXACT) at /home/work/softwares/mysql-5.7.30/storage/innobase/handler/ha_innodb.cc:8755
10 0x000055c1b7a7c4fc in handler::index_read_map (this=0x7fe35801e7c0, buf=0x7fe35801eab0 "\377", key=0x7fe35800c400 "\001", keypart_map=1, find_flag=HA_READ_KEY_EXACT) at /home/work/softwares/mysql-5.7.30/sql/handler.h:2818
11 0x000055c1b7a6ca36 in handler::ha_index_read_map (this=0x7fe35801e7c0, buf=0x7fe35801eab0 "\377", key=0x7fe35800c400 "\001", keypart_map=1, find_flag=HA_READ_KEY_EXACT) at /home/work/softwares/mysql-5.7.30/sql/handler.cc:3046
12 0x000055c1b7a7774a in handler::read_range_first (this=0x7fe35801e7c0, start_key=0x7fe35801e8a8, end_key=0x7fe35801e8c8, eq_range_arg=true, sorted=true) at /home/work/softwares/mysql-5.7.30/sql/handler.cc:7411
13 0x000055c1b7a7556e in handler::multi_range_read_next (this=0x7fe35801e7c0, range_info=0x7fe3c05e7af8) at /home/work/softwares/mysql-5.7.30/sql/handler.cc:6476
14 0x000055c1b7a764c7 in DsMrr_impl::dsmrr_next (this=0x7fe35801ea20, range_info=0x7fe3c05e7af8) at /home/work/softwares/mysql-5.7.30/sql/handler.cc:6868
15 0x000055c1b84ebb84 in ha_innobase::multi_range_read_next (this=0x7fe35801e7c0, range_info=0x7fe3c05e7af8) at /home/work/softwares/mysql-5.7.30/storage/innobase/handler/ha_innodb.cc:20574
16 0x000055c1b830debe in QUICK_RANGE_SELECT::get_next (this=0x7fe358026ed0) at /home/work/softwares/mysql-5.7.30/sql/opt_range.cc:11247
17 0x000055c1b801a01c in rr_quick (info=0x7fe3c05e7d90) at /home/work/softwares/mysql-5.7.30/sql/records.cc:405
18 0x000055c1b81cbb1d in mysql_update (thd=0x7fe358000e10, fields=..., values=..., limit=18446744073709551615, handle_duplicates=DUP_ERROR, found_return=0x7fe3c05e8338, updated_return=0x7fe3c05e8340) at /home/work/softwares/mysql-5.7.30/sql/sql_update.cc:819
19 0x000055c1b81d262d in Sql_cmd_update::try_single_table_update (this=0x7fe3580090e0, thd=0x7fe358000e10, switch_to_multitable=0x7fe3c05e83d7) at /home/work/softwares/mysql-5.7.30/sql/sql_update.cc:2906
20 0x000055c1b81d2b9a in Sql_cmd_update::execute (this=0x7fe3580090e0, thd=0x7fe358000e10) at /home/work/softwares/mysql-5.7.30/sql/sql_update.cc:3037
21 0x000055c1b8108f4e in mysql_execute_command (thd=0x7fe358000e10, first_level=true) at /home/work/softwares/mysql-5.7.30/sql/sql_parse.cc:3616
22 0x000055c1b810ed9b in mysql_parse (thd=0x7fe358000e10, parser_state=0x7fe3c05e9530) at /home/work/softwares/mysql-5.7.30/sql/sql_parse.cc:5584
23 0x000055c1b8103afe in dispatch_command (thd=0x7fe358000e10, com_data=0x7fe3c05e9de0, command=COM_QUERY) at /home/work/softwares/mysql-5.7.30/sql/sql_parse.cc:1491
24 0x000055c1b81028b2 in do_command (thd=0x7fe358000e10) at /home/work/softwares/mysql-5.7.30/sql/sql_parse.cc:1032
25 0x000055c1b824a4bc in handle_connection (arg=0x55c1bdca11f0) at /home/work/softwares/mysql-5.7.30/sql/conn_handler/connection_handler_per_thread.cc:313
26 0x000055c1b8955119 in pfs_spawn_thread (arg=0x55c1bdb3fc20) at /home/work/softwares/mysql-5.7.30/storage/perfschema/pfs.cc:2197
27 0x00007fe4253f8609 in start_thread (arg=<optimized out>) at pthread_create.c:477
28 0x00007fe424fd3103 in clone () at ../sysdeps/unix/sysv/linux/x86_64/clone.S:95
从调用栈不难了解到,ha_innobase::index_read应该是读取索引数据的函数,调用row_search_mvcc时,走到一个lock_wait_suspend_thread函数中去了,看起来SQL执行过程中好像由于等待什么锁,被阻塞住了。
接下来,通过如下语句获取一下锁等待信息:
mysql> SELECT r.trx_mysql_thread_id waiting_thread,r.trx_query waiting_query,
-> concat(timestampdiff(SECOND,r.trx_wait_started,CURRENT_TIMESTAMP()),'s') AS duration,
-> b.trx_mysql_thread_id blocking_thread,t.processlist_command state,b.trx_query blocking_current_query,e.sql_text blocking_last_query
-> FROM information_schema.innodb_lock_waits w
-> JOIN information_schema.innodb_trx b ON b.trx_id = w.blocking_trx_id
-> JOIN information_schema.innodb_trx r ON r.trx_id = w.requesting_trx_id
-> JOIN performance_schema.threads t on t.processlist_id = b.trx_mysql_thread_id
-> JOIN performance_schema.events_statements_current e USING(thread_id);
+----------------+------------------------------------------+----------+-----------------+-------+------------------------+----------------------------------------------------+
| waiting_thread | waiting_query | duration | blocking_thread | state | blocking_current_query | blocking_last_query |
+----------------+------------------------------------------+----------+-----------------+-------+------------------------+----------------------------------------------------+
| 10 | update order set status=1 where oid=1 | 48s | 12 | Sleep | NULL | select * from order where oid=1 for update |
+----------------+------------------------------------------+----------+-----------------+-------+------------------------+----------------------------------------------------+
1 row in set, 1 warning (0.00 sec)
喔,原来有个for update查询语句,对这条数据加了锁,导致这个update SQL阻塞了。
注:ubuntu中pstack包年久失修,基本无法使用,想在ubuntu中使用,可以将centos中的pstack命令复制过来
gcore#
gcore是原生程序的内存转储工具,类似jmap,可以将程序的整个内存空间转储为文件,如下:
# 其中10235是进程的pid
$ gcore -o coredump 10235
$ ll coredump*
-rw-r--r-- 1 work work 3.7G 2021-11-07 23:05:46 coredump.10235
转储出来的dump文件,可以直接使用gdb进行调试,如下:
$ gdb java coredump.10235
For help, type "help".
Type "apropos word" to search for commands related to "word"...
Reading symbols from java...
(No debugging symbols found in java)
[New LWP 10235]
...
[Thread debugging using libthread_db enabled]
Using host libthread_db library "/lib/x86_64-linux-gnu/libthread_db.so.1".
Core was generated by `java'.
#0 __pthread_clockjoin_ex (threadid=139794527459072, thread_return=0x7ffd83e54538, clockid=<optimized out>, abstime=<optimized out>, block=<optimized out>) at pthread_join_common.c:145
145 pthread_join_common.c: No such file or directory.
[Current thread is 1 (Thread 0x7f2474987040 (LWP 10235))]
(gdb)
另外,可以如下配置内核参数,使得程序发生内存访问越界/段错误时,自动生成coredump文件。
# 开启coredump
$ ulimit -c unlimited
# 持久化方式
$ echo "ulimit -c unlimited" >> /etc/profile
# 设置coredump的命名规则
$ vi /etc/sysctl.conf
kernel.core_pattern=%e.core.%s_%t
# core_pattern占位变量解释
%p pid
%u uid
%g gid
%s signal number
%t UNIX time of dump
%h hostname
%e executable filename
# 查看coredump命名规则配置
$ cat /proc/sys/kernel/core_pattern
有时,在java进程上执行jmap时,会无法执行成功,这时可以使用gcore替代生成coredump,然后使用jmap转换为mat可以分析的hprof文件。
$ jmap -dump:format=b,file=heap.hprof `which java` coredump.10235
线程栈分析方法#
一般来说,jstack配合top只能定位类似死循环这种非常严重的性能问题,由于cpu速度太快了,对于性能稍差但又不非常差的代码,单次jstack很难从线程栈中捕捉到问题代码。
因为性能稍差的代码可能只会比好代码多耗1ms的cpu时间,但这1ms就比我们的手速快多了,当执行jstack时线程早已执行到非问题代码了。
既然手动执行jstack不行,那就让脚本来,快速执行jstack多次,虽然问题代码对于人来说执行太快,但对于正常代码来说,它还是慢一些的,因此当我快速捕捉多次线程栈时,问题代码出现的次数肯定比正常代码出现的次数要多。
# 每0.2s执行一次jstack,并将线程栈数据保存到jstacklog.log
$ while sleep 0.2;do \
pid=$(pgrep -n java); \
[[ $pid ]] && jstack $pid; \
done > jstacklog.log
$ wc -l jstacklog.log
291121 jstacklog.log
抓了这么多线程栈,如何分析呢?我们可以使用linux中的文本命令来处理,按线程栈分组计数即可,如下:
$ cat jstacklog.log \
|sed -E -e 's/0x[0-9a-z]+/0x00/g' -e '/^"/ s/[0-9]+/n/g' \
|awk -v RS="" 'gsub(/\n/,"\\n",$0)||1' \
|sort|uniq -c|sort -nr \
|sed 's/$/\n/;s/\\n/\n/g' \
|less
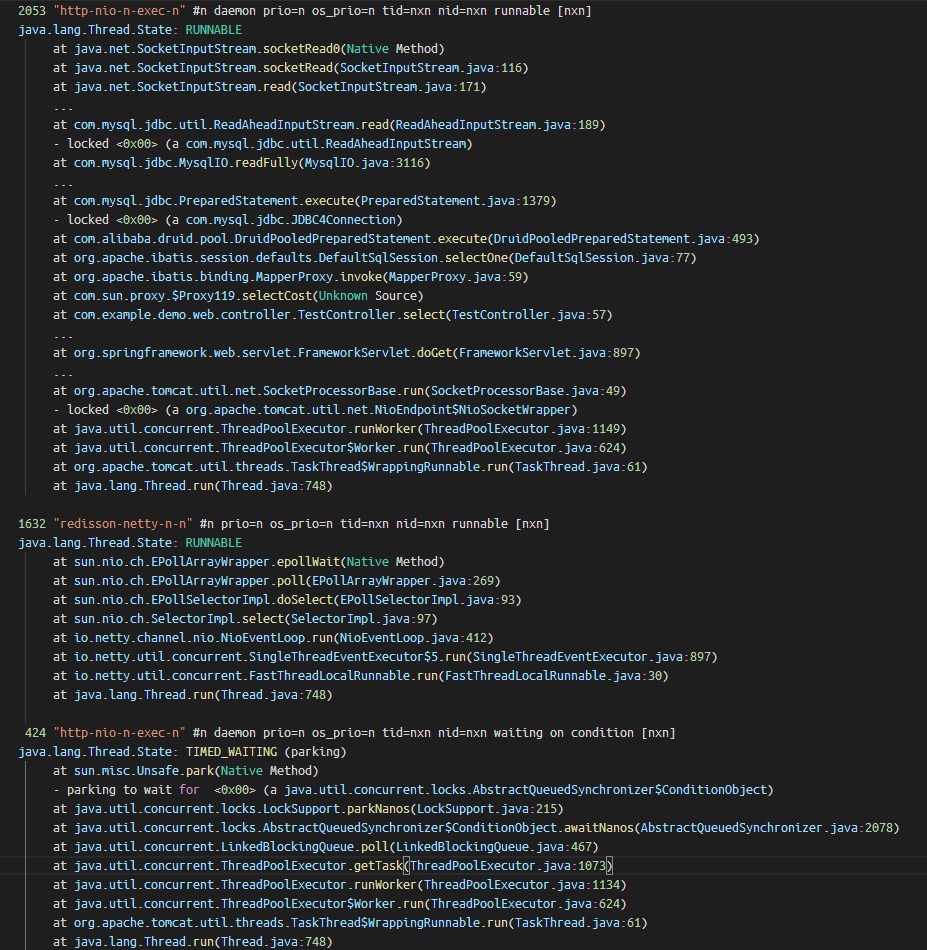
出现次数最多的线程栈,大概率就是性能不佳或阻塞住的代码,上图中com.example.demo.web.controller.TestController.select方法栈抓取到2053次,是因为我一直在压测这一个接口,所以它被抓出来最多。
火焰图#
可以发现,用文本命令分析线程栈并不直观,好在性能优化大师Brendan Gregg发明了火焰图,并开发了一套火焰图生成工具。
工具下载地址:https://github.com/brendangregg/FlameGraph
将jstack抓取的一批线程栈,生成一个火焰图,如下:
$ cat jstacklog.log \
| ./FlameGraph/stackcollapse-jstack.pl --no-include-tname \
| ./FlameGraph/flamegraph.pl --cp > jstacklog.svg
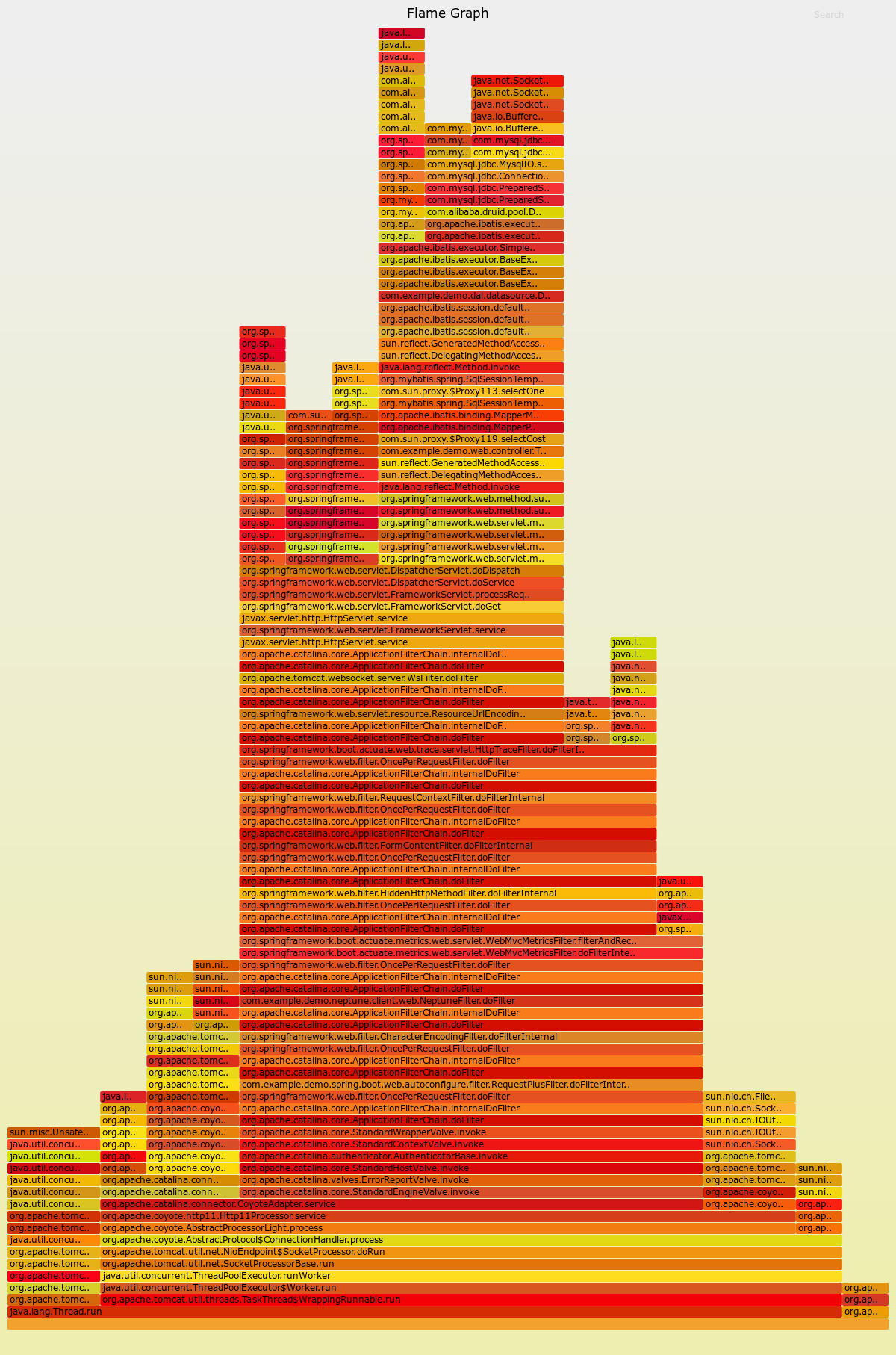
如上,生成的火焰图是svg文件,使用浏览器打开即可,在火焰图中,颜色并没有实际含义,它将相同的线程栈聚合在一起显示,因此,图中越宽的栈表示此栈在运行过程中,被抓取到的次数越多,也是我们需要重点优化的地方。
perf#
perf是Linux官方维护的性能分析工具,它可以观测很多非常细非常硬核的指标,如IPC,cpu缓存命中率等,如下:
# ubuntu安装perf,包名和内核版本相关,可以直接输入perf命令会给出安装提示
sudo apt install linux-tools-5.4.0-74-generic linux-cloud-tools-5.4.0-74-generic
# cpu的上下文切换、cpu迁移、IPC、分支预测
sudo perf stat -a sleep 5
# cpu的IPC与缓存命中率
sudo perf stat -e cycles,instructions,cache-references,cache-misses,bus-cycles -a sleep 10
# cpu的1级数据缓存命中率
sudo perf stat -e L1-dcache-loads,L1-dcache-load-misses,L1-dcache-stores -a sleep 10
# 页表缓存TLB命中率
sudo perf stat -e dTLB-loads,dTLB-load-misses,dTLB-prefetch-misses -a sleep 10
# cpu的最后一级缓存命中率
sudo perf stat -e LLC-loads,LLC-load-misses,LLC-stores,LLC-prefetches -a sleep 10
# Count system calls by type for the specified PID, until Ctrl-C:
sudo perf stat -e 'syscalls:sys_enter_*' -p PID -I1000 2>&1 | awk '$2 != 0'
# Count system calls by type for the entire system, for 5 seconds:
sudo perf stat -e 'syscalls:sys_enter_*' -a sleep 5 2>&1| awk '$1 != 0'
# Count syscalls per-second system-wide:
sudo perf stat -e raw_syscalls:sys_enter -I 1000 -a
当然,它也可以用来抓取线程栈,并生成火焰图,如下:
# 抓取60s的线程栈,其中1892是mysql的进程pid
$ sudo perf record -F 99 -p 1892 -g sleep 60
[ perf record: Woken up 5 times to write data ]
[ perf record: Captured and wrote 1.509 MB perf.data (6938 samples) ]
# 生成火焰图
$ sudo perf script \
| ./FlameGraph/stackcollapse-perf.pl \
| ./FlameGraph/flamegraph.pl > mysqld_flamegraph.svg
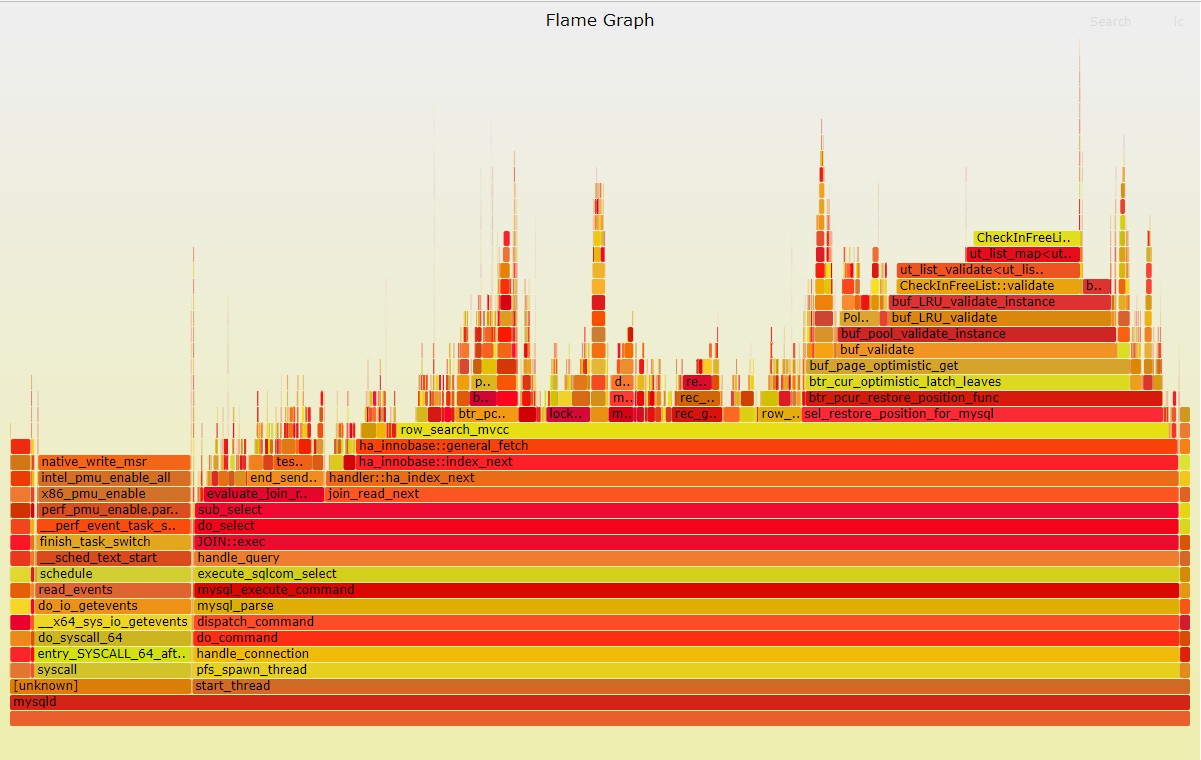
如上所示,使用perf生成的mysql的火焰图,perf抓取线程栈相比jstack的优点是,抓取精度比jstack更高,运行开销比jstack更小,并且还可以抓到Linux内核调用栈!
当然,如此强大的它,也需要像root这样至高无上的权限才能使用。
注:perf抓取线程栈,是顺着cpu上的栈寄存器找到当前线程的调用栈的,因此它只能抓到当前正在cpu上运行线程的线程栈,因此通过perf可以非常容易做oncpu分析,分析high cpu问题。
注意:某些情况下,perf获取到的mysql线程栈是破碎的,类似_Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command这种,非常难读,这种情况下,可以先使用sudo perf script | c++filt命令处理下c++函数命名问题,再将输出给到stackcollapse-perf.pl脚本,c++filt使用效果如下:
# 破碎的函数名
$ objdump -tT `which mysqld` | grep dispatch_command
00000000014efdf3 g F .text 000000000000252e _Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command
00000000014efdf3 g DF .text 000000000000252e Base _Z16dispatch_commandP3THDPK8COM_DATA19enum_server_command
# 使用c++filt处理过后的函数名
$ objdump -tT `which mysqld` | grep dispatch_command | c++filt
00000000014efdf3 g F .text 000000000000252e dispatch_command(THD*, COM_DATA const*, enum_server_command)
00000000014efdf3 g DF .text 000000000000252e Base dispatch_command(THD*, COM_DATA const*, enum_server_command)
offcpu火焰图#
线程在运行的过程中,要么在CPU上执行,要么被锁或io操作阻塞,从而离开CPU进去睡眠状态,待被解锁或io操作完成,线程会被唤醒而变成运行态。
如下: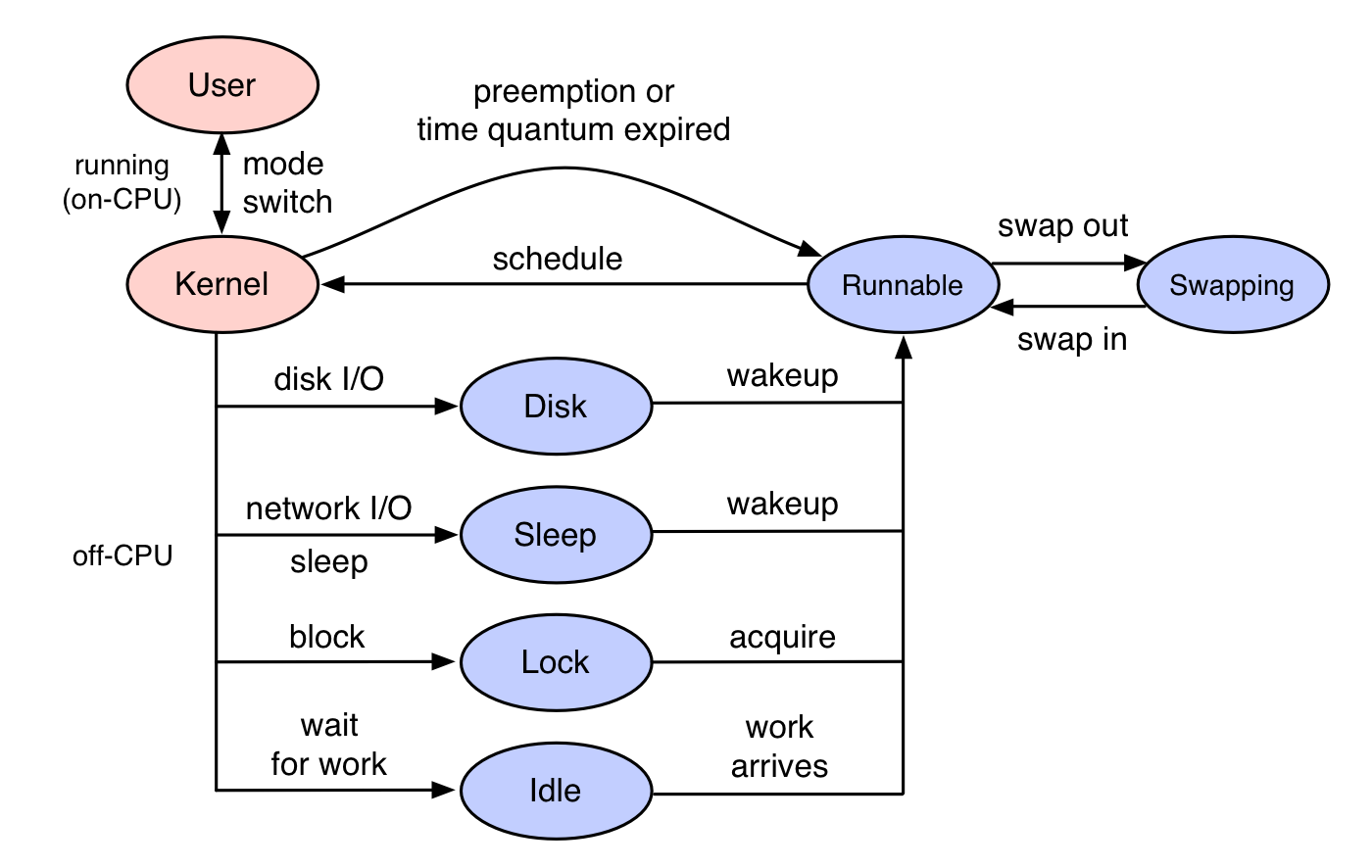
当线程在cpu上运行时,我们称其为oncpu,当线程阻塞而离开cpu后,称其为offcpu。
而线程离开CPU和之后被唤醒,就是我们常说的线程上下文切换,如果线程是因为io或锁等待而主动让出cpu,称为自愿上下文切换,如果是时间片用尽而让出cpu,称为非自愿上下文切换。
如果当线程在睡眠之前记录一下当前时间,然后被唤醒时记录当前线程栈与阻塞时间,再使用FlameGraph工具将线程栈绘制成一张火焰图,这样我们就得到了一张offcpu火焰图,火焰图宽的部分就是线程阻塞较多的点了,这就需要再介绍一下bcc工具了。
bcc#
bcc是使用Linux ebpf机制实现的一套工具集,包含非常多的底层分析工具,如查看文件缓存命中率,tcp重传情况,mysql慢查询等等,如下: 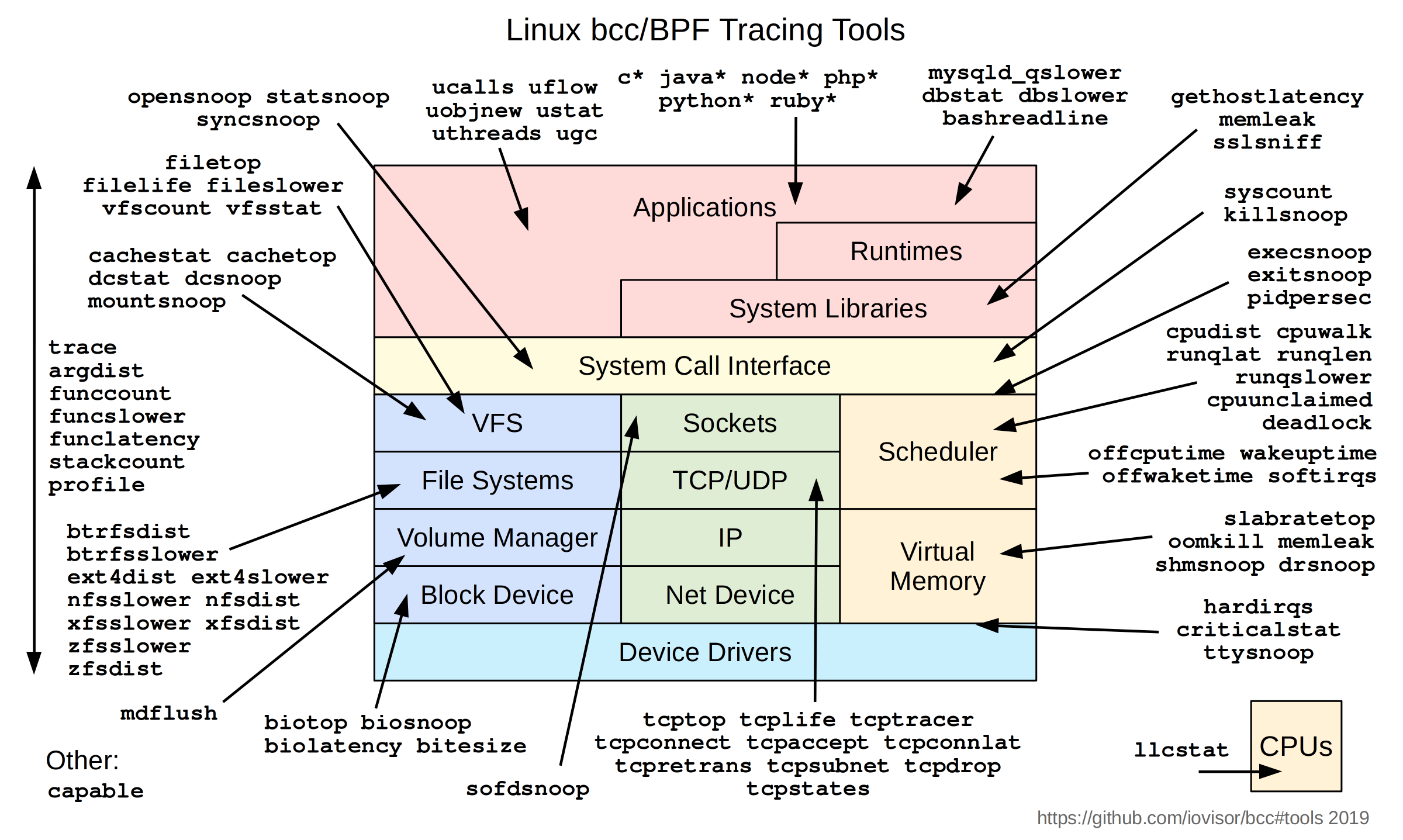
另外,它还可以做offcpu分析,生成offcpu火焰图,如下:
# ubuntu安装bcc工具集
$ sudo apt install bpfcc-tools
# 使用root身份进入bash
$ sudo bash
# 获取jvm函数符号信息
$ ./FlameGraph/jmaps
# 抓取offcpu线程栈30s,83101是mysqld的进程pid
$ offcputime-bpfcc -df -p 83101 30 > offcpu_stack.out
# 生成offcpu火焰图
$ cat offcpu_stack.out \
| sed 's/;::/:::/g' \
| ./FlameGraph/flamegraph.pl --color=io --title="Off-CPU Time Flame Graph" --countname=us > offcpu_stack.svg

如上图,我绘制了一张mysql的offcpu火焰图,可以发现大多数线程的offcpu都是由锁引起的,另外,offcpu火焰图与oncpu火焰图稍有不同,oncpu火焰图宽度代表线程栈出现次数,而offcpu火焰图宽度代表线程栈阻塞时间。
在我分析此图的过程中,发现JOIN::make_join_plan()函数最终竟然去调用了btr_estimate_n_rows_in_range_low这个函数,显然JOIN::make_join_plan()应该是用于制定SQL执行计划的,为啥好像去读磁盘数据了?经过在网上尝试搜索btr_estimate_n_rows_in_range_low,发现mysql有个机制,当使用非唯一索引查询数据时,mysql为了执行计划的准确性,会实际去访问一些索引数据,来辅助评估当前索引是否应该使用,避免索引统计信息不准导致的SQL执行计划不优。
我看了看相关表与SQL,发现当前使用的索引,由于之前研究分区表而弄成了非唯一索引了,实际上它可以设置为唯一索引的,于是我把索引调整成唯一索引,再次压测SQL,发现QPS从2300增加到了2700左右。
这里,也可以看出,对于一些没读过源码的中间件(如mysql),也是可以尝试使用perf或bcc生成火焰图来分析的,不知道各函数是干啥用的,可以直接把函数名拿到baidu、google去搜索,瞄一瞄别人源码解析的文章了解其作用。
bcc项目地址:https://github.com/iovisor/bcc
往期内容#
作者:打码日记
出处:https://www.cnblogs.com/codelogs/p/16060472.html
版权:本作品采用「署名-非商业性使用-相同方式共享 4.0 国际」许可协议进行许可。
[转帖] Linux命令拾遗-剖析工具的更多相关文章
- [转]12款最佳Linux命令行终端工具
摘要 “工欲善其事必先利其器”,作为菜鸟,也是从别人那里偷学来的一些东东.今天看到同事用到一个终端命令行工具,觉得自己弱爆了.然后在网上搜了下该工具.发现类似的工具还是挺多的,只是自己不知道罢了. 原 ...
- 12款最佳Linux命令行终端工具, 20款优秀的 Linux 终端仿真器
12款最佳Linux命令行终端工具 如果你跟我一样,整天要花大量的时间使用Linux命令行,而且正在寻找一些可替代系统自带的老旧且乏味的终端软件,那你真是找对了文章.我这里搜集了一些非常有趣的 ...
- 12款最佳Linux命令行终端工具
12款最佳Linux命令行终端工具 如果你跟我一样,整天要花大量的时间使用Linux命令行,而且正在寻找一些可替代系统自带的老旧且乏味的终端软件,那你真是找对了文章.我这里搜集了一些非常有趣的终端软件 ...
- 利用java实现可远程执行linux命令的小工具
在linux的脚本中,如果不对机器做其他的处理,不能实现在linux的机器上执行命令.为了解决这个问题,写了个小工具来解决这个问题. 后面的代码是利用java实现的可远程执行linux命令的小工具,代 ...
- linux命令-diff对比文件工具
diff 命令是 linux上非常重要的工具,用于比较文件的内容,特别是比较两个版本不同的文件以找到改动的地方.diff在命令行中打印每一个行的改动.最新版本的diff还支持二进制文件.diff程序的 ...
- Linux命令行文本工具
浏览文件 cat 查看文件内容 more 以翻页形式查看文件内容(只能向下翻页) less 以翻页形式查看文件内容(可以上下翻页) head 查看文件的头几行(默认10行) tail 查看文件的尾几行 ...
- Linux 命令行作弊工具安利
本文转自 微信公众号<Linux爱好者>的一篇文章,觉得工具非常好使,且极具使用价值,所以在此安利一下 Linux 用户的福音,记忆力解放!快速调用复杂命令 刚学的一句新命令,才用完就忘了 ...
- [转帖]linux命令dd
linux命令dd dd 是diskdump 的含义 之前学习过 总是记不住 用的还是少. http://embeddedlinux.org.cn/emb-linux/entry-level/20 ...
- OS第1次实验报告:熟悉使用Linux命令和剖析ps命令
零.个人信息 姓名:陈韵 学号:201821121053 班级:计算1812 一.实验目的 熟悉Linux命令行操作 二.实验内容 使用man查询命令使用手册 基本命令使用 三.实验报告 1. 实验环 ...
- [转帖]Linux命令中特殊符号
Linux命令中特殊符号 转自:http://blog.chinaunix.net/uid-16946891-id-5088144.html 在shell中常用的特殊符号罗列如下:# ; ;; . ...
随机推荐
- 教你搭建一个Telegraf+Influxdb+Grafana 监控系统
摘要:本文利用华为HECS云服务器进行监控系统部署. 本文分享自华为云社区<使用华为HECS云服务器打造Telegraf+Influxdb+Grafana 监控系统[华为云至简致远]>,作 ...
- 第三方测评:GaussDB(for Redis)稳定性与扩容表现
摘要:本文将通过采用Redis Labs推出的多线程压测工具memtier_benchmark对比测试下GaussDB(for Redis) 和原生Redis的特性差异 本文分享自华为云社区<墨 ...
- 如何在上架App之前设置证书并上传应用
App上架教程 在上架App之前想要进行真机测试的同学,请查看<iOS- 最全的真机测试教程>,里面包含如何让多台电脑同时上架App和真机调试. P12文件的使用详解 注意: 同样可以 ...
- 如何注册appuploader账号
如何注册appuploader账号 我们上一篇讲到appuploader的下载安装,要想使用此软件呢,需要注册账号才能使用,今 天我们来讲下如何注册appuploader账号来使用软件. 1.A ...
- Kubernetes(K8S) 监控 Prometheus + Grafana
监控指标 集群监控 节点资源利用率 节点数 运行Pods Pod 监控 容器指标 应用程序 Prometheus 开源的 监控.报警.数据库 以HTTP协议周期性抓取被监控组件状态 不需要复杂的集成过 ...
- C#写日志工具类(新版)
源码:https://gitee.com/s0611163/LogUtil 昨天打算把我以前写的一个C#写日志工具类放到GitHub上,却发现了一个BUG,当然,已经修复了. 然后写Demo对比了NL ...
- 十五、跨主机通信overlay网络
系列导航 一.docker入门(概念) 二.docker的安装和镜像管理 三.docker容器的常用命令 四.容器的网络访问 五.容器端口转发 六.docker数据卷 七.手动制作docker镜像 八 ...
- vue-element-admin完整开源项目介绍、本地部署和初步探索
1 说明: 1.1 从一个广受好评的开源项目:vue-element-admin的本地化,来初步分析vue的相关知识. 2 github地址和下载本地部署: https://github.com/Pa ...
- echarts 饼图 点击事件
https://www.cnblogs.com/wcnwcn/p/11170279.html
- B3637-DP【橙】
这题我用sort的时候大意了,从1开始使用的下标但是用sort时没加1导致排序错误,排了半天错才发现. 另外,这道题我似乎用了一种与网络上搜到了做法截然不同的自己的瞎想出来的做法,我的这个做法需要n^ ...