强化学习 —— reinforce算法中更新一次策略网络时episodes个数的设置对算法性能的影响 —— reinforce算法中迭代训练一次神经网络时batch_size大小的不同设置对算法性能的影响
本文相关的博客:(预先知识)
强化学习中经典算法 —— reinforce算法 —— (进一步理解, 理论推导出的计算模型和实际应用中的计算模型的区别)
本文代码地址:
https://gitee.com/devilmaycry812839668/cart-pole_-policy-network_-reinforce
=============================================
由前面的博客分析可知,本文代码如果以模式mode=0,或mode=1的情况运行的话算法直接从随机策略进入衰退中,无法达到要求的结果,因此本文中我们使用本文代码中模式mode=2,和mode=3,这两种情况。
其中mode=2为最常用的reinforce算法模式,也就是对折扣奖励进行高斯化的规整后进行计算,更新策略网络,而mode=3的reinforce算法模式则是对折扣奖励乘以状态出现的折扣概率而得到折扣概率下的折扣奖励,然后再进行计算更新策略网络。
由于实际中reinforce算法我们可以认为是本文代码中的mode=2的形式,因此mode=3在这里没有太多意义,只为补充扩展之用。
===================================
运行mode2文件夹下的 anaylisis.py 文件,可以得到以下结果:
ssh://devilmaycry@192.168.1.111:22/home/devilmaycry/anaconda3/envs/tf-14.0/bin/python -u /tmp/mode2/analysis.py
batch_size 为: 1 mean: 945.9293 std: 192.9449 共解决任务数: 99
batch_size 为: 5 mean: 3111.8041 std: 377.6134 共解决任务数: 97
batch_size 为: 10 mean: 5247.8571 std: 619.4505 共解决任务数: 98
batch_size 为: 25 mean: 11210.2500 std: 1125.7558 共解决任务数: 100
batch_size 为: 50 mean: 20717.1717 std: 2423.9770 共解决任务数: 99
batch_size 为: 100 mean: 40154.5455 std: 6498.1625 共解决任务数: 99
batch_size 为: 300 mean: 113667.0000 std: 16274.0472 共解决任务数: 100
batch_size 为: 500 mean: 187413.2653 std: 20496.8919 共解决任务数: 98
batch_size 为: 1000 mean: 380818.1818 std: 51131.5127 共解决任务数: 99
[1.52 1.186 1.17 1.082 1.032 1.06 1.011 0.984]
[1.52 1.803 2.11 2.283 2.356 2.497 2.524 2.484] Process finished with exit code 0
不同的batch_size 在reinforce算法中是指每次更新策略网络时所采用的episodes数据的个数。
不同batch_size的设置下分别进行100次试验。
可以看到不同batch_size设置下在100次试验中均有可能有一定概率到不到要求,也就是说都会有一定的概率在训练过程中使策略网络衰退,而衰退后的策略网络对一个episode内所有的状态均给出同样的action。
不同batch_size的设置下mean值和std值为取得要求结果时所用episodes数的均值及标准差。(没有达到要求的试验不参与计算)
主要分析的数据为这两行数据:
[1.52 1.186 1.17 1.082 1.032 1.06 1.011 0.984]
[1.52 1.803 2.11 2.283 2.356 2.497 2.524 2.484]
其中,我们的batch_size的设置分别为: [1, 5, 10, 25, 50, 100, 300, 500, 1000]
因此上面的第一行数据为不同batch_size设置下后一种设置对前一种batch_size设置下运算效率的提升。
我们这里对运算效率提升的定义为:后一种运算效率 除以 前一种运算效率。
运算效率则定义为:(后一种batch_size对前一种batch_size的比值) 除以 (后一种到达要求所需的episodes个数对前一种到达要求所需的episodes个数的比值)
为什么我们这里这样定义运算效率呢???
其中一个原因就是在向量化计算中如果计算要求在计算设备的最高计算能力之下(比如在CPU或GPU上使用TensorFlow等计算神经网络,利用率在100%之内),我们单纯的增加同一计算中部分算子内某矩阵的维度值(如:矩阵A,维度为[1000, 1000],乘以矩阵B,维度为[1000, 10]所用时间 和 矩阵A,维度为[1000, 1000],乘以矩阵C,维度为[1000, 100] 所用计算时间的差距一般小于维度增加的线性比,这里是指A*B计算时间不大于10倍的A*C时间,实际中往往A*B的时间稍稍大于A*C的时间,甚至可以近似相等)。
而我们如果增加了batch_size的大小,我们更新策略网络的次数也需要总的次数除以batch_size大小。比如batch_size为1的情况下需要10000次迭代计算,这里我们就是更新了10000次策略网络,然而如果batch_size=10的情况下,我们也进行了10000次迭代计算,那么我们实际上只进行了10000/10=1000次策略网络的更新。也就是说在相同的总episodes数下,batch_size越大,我们进行网络更新所需的计算时间越短(而在算法模型中往往策略更新所需时间往往为算法整体过程的大部分时间)。
根据上面的第二行数据可知,batch_size为[5, 10, 25, 50, 100, 300, 500, 1000]时,运算效率的提升(网络更新步骤操作的性能的提升)为第二行数据:
[1.52 1.803 2.11 2.283 2.356 2.497 2.524 2.484]
根据第二行数据可知,当batch_size逐渐增大时网络更新操作的运算效率逐渐提高然后再下降,也就是说在一定范围内提高batch_size的大小可以很好的提高算法进行网络更新(策略更新)时的运算效率。
上面说的就是batch_size适当的提高可以减少训练时所需的迭代次数(这里主要指进行网络更新时所需的迭代次数),由于强化学习算法中可以大致分为训练数据生成+网络训练两个部分,可以有效的提高网络训练部分可以在一定程度上提高强化学习算法的运算效率。
同样,我们可以看了不同batch_size下的mode=3下的结果:
batch_size 为: 1 mean: 998.3838 std: 173.8887 共解决任务数: 99
batch_size 为: 5 mean: 3479.4444 std: 542.2390 共解决任务数: 99
batch_size 为: 10 mean: 6036.0000 std: 729.5830 共解决任务数: 95
batch_size 为: 25 mean: 13198.7245 std: 1374.2269 共解决任务数: 98
batch_size 为: 50 mean: 24829.7980 std: 3268.8994 共解决任务数: 99
batch_size 为: 100 mean: 48707.0707 std: 9821.3255 共解决任务数: 99
batch_size 为: 300 mean: 146567.0103 std: 27464.4577 共解决任务数: 97
batch_size 为: 500 mean: 236831.6327 std: 40591.4151 共解决任务数: 98
batch_size 为: 1000 mean: 494072.1649 std: 83719.9858 共解决任务数: 97
后一种batch_size设置对前一种设置的运算效率(特指网络更新步骤)提升:
[1.435 1.153 1.143 1.063 1.02 0.997 1.031 0.959]
后一种batch_size设置对第一种设置的运算效率(特指网络更新步骤)提升:
[1.435 1.654 1.891 2.01 2.05 2.044 2.108 2.021]
同样从最后一行的数据我们可以发现如果适当的增加batch_size的大小可以提高策略网络的运算效率。
这时候问题来了,增加一定的batch_size真的能够提高算法的运算效率吗???
因为强化学习算法一般可以写成下面的计算模式:
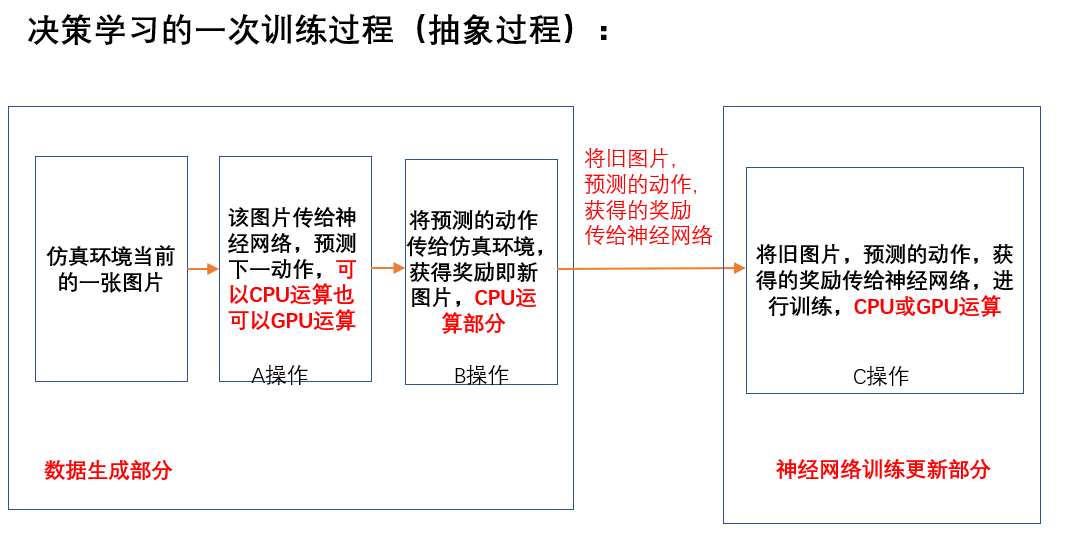
相关内容参见:https://www.cnblogs.com/devilmaycry812839668/p/14165876.html
我们可以看到强化学习的计算过程主要分为训练数据的生成部分和策略的训练部分,上面的分析我们发现适当的增加batch_size的大小可以一定程度上提高策略训练部分运算效率,但是对于数据生成部分呢???
无疑,增加batch_size的大小就需要加大数据生成部分的计算量,那么比如说在reinforce中的mode=2时,这时我们把batch_size设置为10,那么策略网络更新部分提速为2.11,也就是说此时网络更新部分的用时为batch_size=1时的 1/2.11=0.4739,但是由于batch_size变为了10,那么数据生成部分其实变为了batch_size=1时,10*0.4799=4.799。假设当batch_size=1时,数据生成部分需要时间为X,网络训练部分时间为Y,那么batch_size=10时数据生成部分所需时间为4.799X, 网络训练部分的时间为0.4799Y,那么batch_size=1时总的训练时间为X+Y, 而batch_size=10时总的训练时间为4.799X+0.4799Y,那么如果我们不考虑并行或分布式下的reinforce而是纯单线程下的reinforce算法,那么batch_size从1变为10后运算时间是否能缩小就要看X+Y与4.799X+0.4799Y之间哪个大了,只有4.799X+0.4799Y<X+Y时才能说batch_size提高了算法性能,而此时X/Y<(1-0.4799)/3.799=0.1369,也就是说只有在batch_size=1时数据成本部分的时间X与网络训练部分的时间Y的比值小于0.1369这样batch_size=10才能提高算法的运算效率。
**** 个人观点:现在很多的并行强化学习算法其实也是基于这个理论进行的,只不过一直没有相关的主要的工作来说明这个问题,这也是A3C算法提高算法性能的一个很重要的一点。大家可以想象一下在A3C中我们是怎么并行化数据生成部分的,比如在A3C中我们使用10个进程来并行化数据生成部分,那么每个数据生成的进程虽然还是处理batch_size=1的数据生成,但是由于有10个数据生成的进程并行,那么此时做网络更新时的batch_size=10,就如前面reinforce算法的分析一样,如果10个进程并行化数据生成部分那么此时的数据生成部分时间为4.799X/10=0.4799X,而网络更新部分依然为0.4799Y,那么数据生成并行化(10个进程进行数据生成)后的batch_size=10的reinforce算法整体的算法运算时间为0.4799(X+Y),而此时我们就可以轻松实现算法运算性能的提升,总体的运算时间再batch_size=10时是batch_size=1时的0.4799。
***另外要说明一点的是:我们不能无限的增加batch_size, 从上面的简单实验中看到增加一定的batch_size可以提高策略更新部分的性能,但是这同时有两个限制:
1. 做网络策略更新时的硬件设备的计算性能,因为当batch_size大到一定程度后网络策略更新部分的单次更新的运算时间也会随之增加(甚至是线性增加),而我们刚才的最初假设就是batch_size在设备计算能力负荷下可以不额外提高运算时间(或者稍微增加一定的运算时间,远小于线性增加),而batch_size增加到一定程度后这个假设条件自然也是不存在的。也就是说batch_size增加一定程度后,单次更新网络的时间也会随之大幅增加,也就不满足前面的条件了。
2.batch_size增加一定程度后,所需的网络更新的总次数也会逐渐增加。从前面简单的实验我们可以看到reinforce算法的batch_size增加为1000后所需要的网络更新次数甚至会高于batch_size=500时的网络更新次数。因此batch_size一直增加,总的更新次数不仅不会一直提升甚至还会在一定数值后出现下降,这里简单实验中mode=2时batch_size=500后总的更新次数开始增加。
====================================================
经过上面的分析,我们可以具体看下不同batch_size下,mode=2的reinforce运行时间大致多少:
运行analysis_2.py 代码,得到下面结果:
batch_size 为: 1 mean: 20.7283 std: 3.8936 共解决任务数: 99
batch_size 为: 5 mean: 93.0511 std: 9.2488 共解决任务数: 97
batch_size 为: 10 mean: 175.7676 std: 16.9390 共解决任务数: 98
batch_size 为: 25 mean: 374.1988 std: 41.3579 共解决任务数: 100
batch_size 为: 50 mean: 699.6893 std: 94.7146 共解决任务数: 99
batch_size 为: 100 mean: 1432.9880 std: 341.8591 共解决任务数: 99
batch_size 为: 300 mean: 4215.9689 std: 656.8553 共解决任务数: 100
batch_size 为: 500 mean: 7483.7373 std: 889.7766 共解决任务数: 98
batch_size 为: 1000 mean: 14214.7104 std: 2023.5635 共解决任务数: 99
batch_size: [1, 5, 10, 25, 50, 100, 300, 500, 1000]
batch_size增加的倍数: [5. 2. 2.5 2. 2. 3. 1.667 2. ]
运算时间增加的倍数: [4.489 1.889 2.129 1.87 2.048 2.942 1.775 1.899]
可以看到reinforce算法在单线程进行数据生成时总的运行时间增加的比例与batch_size大小增加的比例大致相等,比如batch_size=5时总的运算时间为4.489,我们可以大致的将其近似的等价于batch_size增加的比例5, 而这个结果并不与前面的分析相互矛盾,之所以这样是因为一个episodes的数据生成的时间要远大于一次网络更新的时间,要是仍然用X表示数据生成的时间,Y表示网络更新的时间,这里其实在侧面验证了这么一个事实,那就是X>>Y,X远大于Y,这在另一方面说明了这样一个事实,那就是在强化学习中往往训练数据生成的时间要远大于网络训练的时间,因此单纯的提高batch_size虽然可以提高网络更新的效率但是会提高数据生成所花费的时间,因此不能单纯的增加batch_size,而现在比较常用的A3C等算法一个主要的思想就是将数据生成部分并行化,这样就保证了数据生成部分不会有较大的时间花费的增加。在保证数据生成的时间不会过多增加或者几乎报错不变,这时提高网络更新的效率,就能提高算法整体的效率。
而本文上面的分析也说明了数据生成部分的时间往往大于网络训练的时间,这也在某种程度上说明了为什么现在很大一部分的强化学习算法都是使用CPU来进行网络更新而不是使用GPU来进行网络更新,因为如果网络训练的计算不是很大的情况下CPU的计算速度会超过GPU的,再加上数据切换等问题就更加促使很多的强化学习算法在CPU上进行网络更新要速度快于在GPU上做网络更新的这个问题。而这方面的相关讨论已经在前面的博客讨论过:
深度学习中使用TensorFlow或Pytorch框架时到底是应该使用CPU还是GPU来进行运算???
===============================
特别说明:
本文代码经过检查发现存在问题,经过修改后已经进行更新。
错误在于每次进行reinforce算法计算时所使用的状态(观测值均为next_observation, 还不是正确的情况下使用observation),因此导致在进行reinforce算法时使用的当前状态其实均为当前状态的下一状态。所以mode=0, 和 mode=1 情况下均不能收敛, 修改后发现,mode=0, mode=1, mode=2, mode=3 均是可以正常收敛的。
十分有意思的一点是,即使传入reinforce算法中的observation是后一时刻的也没有使mode=2, mode=3 这两种算法获得收敛取得最终结果,而mode=0, 和 mode=1 这两种模式的设置下将一时刻的next_observation当做当前时刻的observation传入到reinforce算法中导致算法无法收敛。
那么这是不是说明mode=2, mode=3这两种设置更具鲁棒性,或者说收敛性更强呢。我想这主要还是说明mode=2, 和 mode=3 这两种设置对获得的状态中存在噪音的情况有一定的抗干扰性,可以快速的从有干扰噪音的状态中学习到所希望的模式。
修改后的代码分别进行了batch_size=5 和 batch_size=20 这两种情况下的测试,所得结论和未修改代码之前所得到的结论相似,因此不影响本文之前所得结论。计算结果如下:
mode=0 情况:


mode=1 情况:


mode=2 情况:


mode=3 情况:


--------------------------------------------------
强化学习 —— reinforce算法中更新一次策略网络时episodes个数的设置对算法性能的影响 —— reinforce算法中迭代训练一次神经网络时batch_size大小的不同设置对算法性能的影响的更多相关文章
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习-学习笔记14 | 策略梯度中的 Baseline
本篇笔记记录学习在 策略学习 中使用 Baseline,这样可以降低方差,让收敛更快. 14. 策略学习中的 Baseline 14.1 Baseline 推导 在策略学习中,我们使用策略网络 \(\ ...
- Flink + 强化学习 搭建实时推荐系统
如今的推荐系统,对于实时性的要求越来越高,实时推荐的流程大致可以概括为这样: 推荐系统对于用户的请求产生推荐,用户对推荐结果作出反馈 (购买/点击/离开等等),推荐系统再根据用户反馈作出新的推荐.这个 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 强化学习论文(Scalable agent alignment via reward modeling: a research direction)
原文地址: https://arxiv.org/pdf/1811.07871.pdf ======================================================== ...
- ICML论文|阿尔法狗CTO讲座: AI如何用新型强化学习玩转围棋扑克游戏
今年8月,Demis Hassabis等人工智能技术先驱们将来到雷锋网“人工智能与机器人创新大会”.在此,我们为大家分享David Silver的论文<不完美信息游戏中的深度强化学习自我对战&g ...
- 强化学习一:Introduction Of Reinforcement Learning
引言: 最近和实验室的老师做项目要用到强化学习的有关内容,就开始学习强化学习的相关内容了.也不想让自己学习的内容荒废掉,所以想在博客里面记载下来,方便后面复习,也方便和大家交流. 一.强化学习是什么? ...
- 强化学习之 免模型学习(model-free based learning)
强化学习之 免模型学习(model-free based learning) ------ 蒙特卡罗强化学习 与 时序查分学习 ------ 部分节选自周志华老师的教材<机器学习> 由于现 ...
- 强化学习(四)用蒙特卡罗法(MC)求解
在强化学习(三)用动态规划(DP)求解中,我们讨论了用动态规划来求解强化学习预测问题和控制问题的方法.但是由于动态规划法需要在每一次回溯更新某一个状态的价值时,回溯到该状态的所有可能的后续状态.导致对 ...
- 【转载】 强化学习(四)用蒙特卡罗法(MC)求解
原文地址: https://www.cnblogs.com/pinard/p/9492980.html ------------------------------------------------ ...
随机推荐
- linux系统下,配置多个tomcat服务
安装jdk时配置的环境变量 export JAVA_HOME=/usr/local/jdk1.8.0_311 export JRE_HOME=$JAVA_HOME/jre export PATH=$P ...
- OpenWrt安装配置Tailscale
什么是tailscale? Tailscale就是基于Wireguard的一个联网工具,无需公网地址,通过去中心化,实现各个节点之间点对点的连接.配置简单友好,支持的各类平台和客户端. 相比较其他组网 ...
- echarts柱状图横(x)轴文字显示不全,一招解决
柱状图底部X轴文字过长时,将会出现文字显示不全的问题,这是echarts为了美观默认的设置 现在我们把文章倾斜旋转点角度即可全部显示 以下是代码 scale() { var chartDom = do ...
- mysql ON DUPLICATE KEY UPDATE 演示
<e>查询:INSERT INTO member_test(mem_no,flag)VALUE('111','1') 错误代码: 1062Duplicate entry '111' for ...
- 开源云同步的markdown写作软件——Yosoro
文章目录 前言 简便的项目管理 舒服的写作体验 支持one driver 存在缺点 前言 Yosoro是一款支持在Win.Linux.macOS上使用的写作软件.它的界面设计以及交互上表达出的极简主义 ...
- C++之printf函数
背景 C++中可以使用cout来输出. 但是cout输出一些格式化的数据非常麻烦. 比如: hour,min和sec代表当前时间,需求:按12:00:00格式输出当前时间. //使用cout输出 co ...
- 实验9.单臂路由实现Vlan互通实验
# 单臂路由实现Vlan互通实验 本实验用于测试单臂路由方式实现Vlan路由. 实验组 实验过程 SW int g0/0/1 port link-type access port default vl ...
- CF1523D Love-Hate
抽象化题意: 一共有 \(m\) 个元素,给定 \(n\) 个集合,每个集合的元素不超过 \(15\) 个,求出一个元素个数最多的集合 \(S\) 是至少 \(\lceil \dfrac{n}{2} ...
- Css实现浏览滚动条效果
Css实现浏览滚动条效果 前言 也是有大半个月没有更新文章了,大部分时间都在玩,然后就是入职的事.今天就更新一个小知识,刷抖音的时候看到的,感觉还不错. 属性介绍 关键属性animation-time ...
- python基础-元组tuple( )
元组的定义和操作 元组的特性: 元素数量 支持多个 元素类型 任意 下标索引 支持 重复元素 支持 可修改性 不支持 数据有序 是 使用场景 不可修改.可重复的 一批数据记录场景 # 定义元组 ...