【合合TextIn】智能文档处理系列—电子文档解析技术全格式解析

|
类型名称
|
介绍说明
|
|---|---|
|
TXT
|
纯文本格式,不支持文本格式化(如加粗、斜体)、嵌入对象或其他文档元素,兼容性极强,适用于简单的文本数据存储和交换。
|
|
PDF
|
便携式文档格式(Portable Document Format),能够精确保留文档的格式和布局,支持文本、图像、矢量图形等多种内容类型,是跨平台文件共享的常用格式。
|
|
DOC
|
Microsoft Word文档的格式(97-2003),支持丰富的格式化文本、图表、图像等元素,主要用于办公自动化和文档编辑。
|
|
DOCX
|
Microsoft Word的开放XML文档格式,从Word 2007开始使用,比DOC更加高效和具有兼容性,支持文档的结构化和数据的重新利用。
|
|
XLSX
|
Microsoft Excel的开放XML电子表格格式,支持复杂的工作簿、工作表、公式、图表等功能,是处理和分析业务数据的标准工具。
|
|
Markdown
|
轻量级标记语言,使用简单的标记语法来格式化文档,易于阅读和写作,广泛用于撰写网页内容、技术文档等。
|
|
RTF
|
富文本格式(Rich Text Format),允许文本格式化和包含图像等对象,确保文档可以在不同的文本处理软件之间传输而保持格式不变。
|
|
CSV
|
逗号分隔值(Comma-Separated Values),一种常用的文本格式,用以存储表格数据,包括数字和文本,每行一个数据记录,字段由逗号分隔,简单且被广泛支持。
|
|
HTML
|
超文本标记语言(HyperText Markup Language),用于创建网页和网页应用的标准标记语言,能够嵌入文本、链接、图像、视频等多媒体内容。
|
|
XML
|
可扩展标记语言(eXtensible Markup Language),一种标记语言,用于存储和传输数据,设计宗旨是传输数据而非显示数据,支持自定义标签。
|
|
PPT
|
PowerPoint演示文档格式,支持文本、图表、图像、动画等多媒体内容的演示文档创建,广泛用于教育、商务演示等场合。
|

- io和codecs:Python的标准库io提供了基础的文件操作接口,而codecs模块则用于处理不同的字符编码。它们可以处理文件读写操作,并支持多种字符编码。
- chardet:是一个Python库,用于自动检测文本文件的字符编码。它支持多种编码,可以帮助解决编码识别的问题,尤其是在处理来源不明的TXT文件时非常有用。
- open():Python的open()函数在universal newline mode模式下能自动处理不同操作系统的换行符问题,使得跨平台的文本处理更加方便。
- Pandas:虽然Pandas主要用于数据分析,但它也提供了强大的文本文件处理能力。对于包含表格数据的TXT文件,Pandas可以轻松地读取和处理,支持大文件的高效处理。
- NLTK (Natural Language Toolkit) 和 spaCy:这两个库虽然主要用于自然语言处理,但它们也支持对TXT文件中的文本内容进行高级处理,如分词、词性标注等。这对于需要对TXT文件内容进行深入分析的应用场景非常有用。
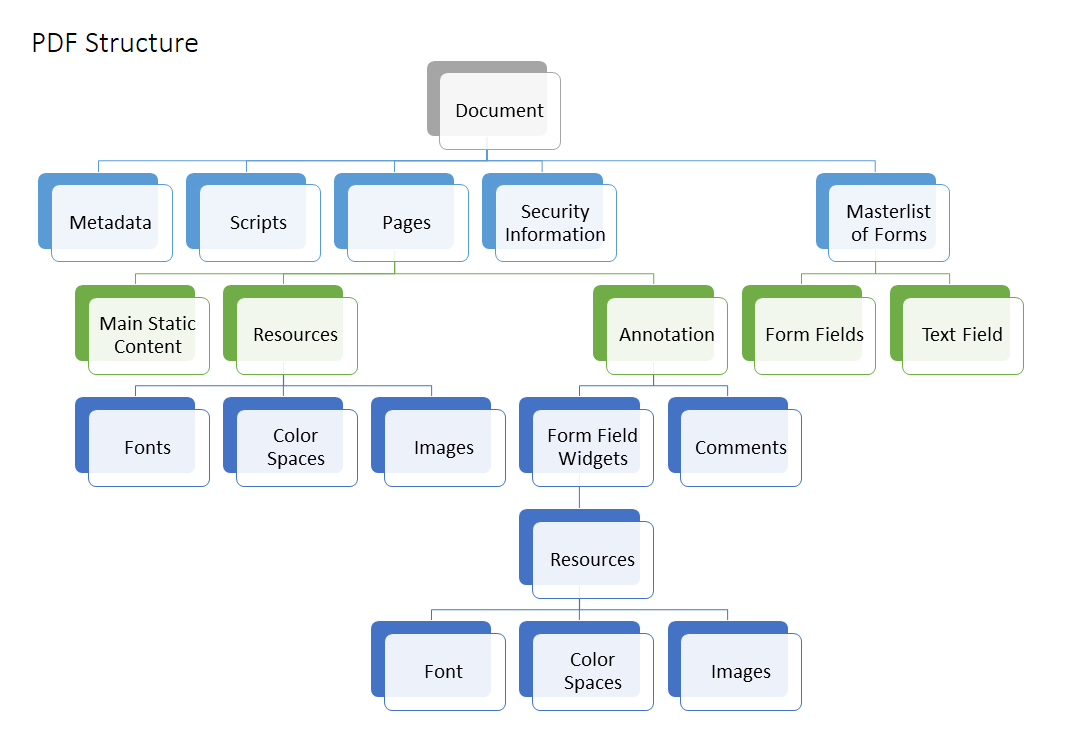
- 对象:PDF文件中的基本数据单位,包括数字、字符串、数组、字典等。
- 页面树:组织文档页面的结构,定义了页面之间的关系。
- 内容流:定义了页面内容的绘制方式,包括文本和图形。
- 资源字典:包含了绘制内容所需的字体、图像等资源。
- 交叉引用表:提供了文件中各对象位置的索引,便于快速定位。
- 文件尾部:包含了文件的交叉引用表和文件目录的位置。
- 文本流:存储实际的文本内容。
- 格式化信息:定义文本的样式和排版,如字体大小、颜色、段落对齐方式等。
- OLE(对象链接与嵌入):用于嵌入或链接到其他文件和信息,如图表和图片。

- word/document.xml:存储文档的主体文本。
- word/styles.xml:定义文档的样式信息,如字体、大小、颜色等。
- word/rels:包含文档中对象(如图片、表格、链接)的关系定义。
- docProps:存储文档的元数据,如作者、标题和主题。
- python-docx:是一个Python库,提供了读取、修改以及创建DOCX文件的能力。它可以访问文档中的文本、表格、图片等元素,并允许修改文档样式。
- Apache POI的XWPF(XML Word Processor Format)组件提供了Java语言下处理DOCX文件的能力。它支持读取、创建和修改文档中的内容和样式。
- Open XML SDK:由Microsoft提供,是一个针对.NET平台的开发工具包,专门用于处理基于Open XML标准的文档格式,包括DOCX。它提供了丰富的API来操作文档的各个方面。
- docx4j:是一个Java库,用于处理OpenXML格式的文档,如DOCX、PPTX和XLSX。它提供了广泛的功能,包括从DOCX文件中提取文本、转换文档格式等。
- xl/worksheets/:存储各个工作表的数据。
- xl/styles.xml:定义了电子表格的样式信息,如字体、颜色、边框等。
- xl/workbook.xml:描述了工作簿的结构,包括工作表的名称和顺序。
- [Content_Types].xml:定义了文件中所包含的不同类型的文件和XML标记语言。
- Apache POI:一个强大的Java库,提供了广泛的Microsoft Office文件格式支持,包括XLSX。它允许开发者读取、修改和写入XLSX文件,以及处理复杂的电子表格数据和样式。
- OpenPyXL:一个专门用于读写Excel 2010 xlsx/xlsm/xltx/xltm文件的Python库。它支持读取电子表格数据、修改样式、以及创建新的XLSX文件。
- EPPlus:一个针对.NET平台的库,提供了对XLSX文件的读写支持。它使得.NET开发者可以在不需要安装Microsoft Excel的情况下处理电子表格数据。
- libxlsxwriter:一个C库,用于创建兼容Excel 2007+的XLSX文件。它支持电子表格的各种特性,包括公式、格式和图表。
- SheetJS js-xlsx:是一个强大的JavaScript工具库,支持解析和编写各种电子表格格式,包括XLSX。它可以在浏览器和Node.js环境下运行,非常适合Web应用。
- # 表示标题。
- - 或 * 表示无序列表。
- [链接文本](URL) 表示链接。
- Markdown-it:一个快速的JavaScript Markdown解析器,支持多种Markdown扩展和配置选项。它可用于Web浏览器和Node.js环境。
- CommonMark:旨在建立一个Markdown标准化语法规范,并提供跨多个编程语言的解析器和渲染器。CommonMark工作组提供了C、JavaScript、Python、Ruby等语言的实现。
- Pandoc:不仅是一个Markdown解析器,更是一个文档转换工具,支持Markdown与多种格式(如HTML、LaTeX、DOCX等)之间的互转。Pandoc提供了广泛的语法支持和灵活的转换选项。
- Remarkable:一个高度可配置的JavaScript Markdown解析器,提供了高速解析和灵活的插件系统,支持自定义Markdown扩展。
- Marked:是一个快速、轻量级的Markdown解析器和编译器,用于Node.js和浏览器。它易于使用,并提供了可扩展的选项和接口。

- Pyth:是一个Python库,专注于读取和写入RTF文档。它支持文本样式和格式化,适合需要处理RTF文档基本内容的应用。
- RTF Parser Kit:提供了一套Java工具,用于解析RTF文件。它能够解析RTF文档的结构和内容,适用于需要在Java应用中处理RTF格式的场景。
- librtf:是一个C语言库,用于从RTF文件中提取文本内容。虽然它的功能相对简单,但对于需要解析RTF文件文本的应用来说足够使用。
- unRTF:是一个命令行程序,可以将RTF文件转换为HTML、纯文本和其他格式。虽然它主要用于转换而不是库,但可以在后端应用中作为工具使用,以实现RTF文件的快速处理。
- pandas:一个强大的数据分析和操作库,提供了read_csv函数来读取CSV文件,支持复杂的解析规则,如自定义分隔符、处理缺失值和类型转换等。
- csv模块:Python标准库中的模块,提供了读取和写入CSV文件的功能。它支持自定义分隔符、引号处理规则等基本功能。
- Apache Commons CSV:提供了一套简单但强大的接口来读写CSV文件,支持自定义分隔符、多种CSV格式的预设(如Excel、RFC4180)等。
- Papa Parse:一个强大、快速的JavaScript库,用于解析CSV文件。它能够自动处理大文件、读取本地文件、远程文件和文本流,支持浏览器和Node.js。
- CsvHelper:一个用于.NET的库,提供了简单易用的接口来读写CSV文件。它支持自定义映射、类型转换和LINQ查询等高级功能。
- Beautiful Soup:一个Python库,用于解析HTML和XML文档,从中提取数据。它提供了简单的方法来导航、搜索和修改DOM树。
- jsoup:一个用于Java的HTML解析器,其API设计用于提取和操作数据,使用DOM和CSS选择器查询。jsoup也提供了强大的错误容忍性。
- Cheerio:适用于Node.js环境,使用类似于jQuery的语法来操作HTML文档。Cheerio实现了核心jQuery库的子集,专注于HTML解析和数据提取。
- HTML Agility Pack:一个.NET库,用于解析HTML文档,支持XPath和XSLT,允许开发者对DOM进行读取、修改和搜索操作。
- Puppeteer 和 Playwright:这两个Node库提供了一个高级API来控制Chrome或其他浏览器。虽然主要用于自动化和测试,但它们也可以用于动态HTML内容的解析和渲染。

- lxml:是一个高性能的Python XML处理库,支持XPath和XSLT等功能,非常适合于复杂的XML文档处理。
- ElementTree:Python标准库中的一个XML解析模块,提供了直观的API来读取、修改和创建XML文件。
- SAX (Simple API for XML) 和 DOM (Document Object Model):这两个API在许多语言中都有实现,如Java、C#和JavaScript。SAX提供了一个基于事件的解析方式,适合于大文件或流式处理;DOM则通过构建整个文档的树状结构来允许更复杂的文档处理。
- TinyXML-2:是一个简单、小巧、高效的C++ XML解析库,适用于需要嵌入XML解析功能的应用程序。
- libxml2:是一个用于C语言的XML处理库,提供了全面的XML和HTML解析功能。它是许多高级语言库的底层依赖,包括lxml。
- Apache POI:提供了对Microsoft Office文件格式的广泛支持,包括PPT和PPTX。POI的HSLF和XSLF组件分别用于处理PPT和PPTX格式,支持读取、编辑和创建幻灯片。
- python-pptx:是一个Python库,专门用于创建和更新PPTX文件。它提供了对幻灯片内容、布局、样式和属性的高级接口,支持文本、图表、图片等元素的处理。
- Aspose.Slides:虽然不是完全开源,但提供了一个免费社区版。它是一个跨平台的幻灯片处理库,支持.NET、Java、C++和其他语言,提供了丰富的功能,包括幻灯片的创建、编辑、转换和渲染。
- Open XML SDK:由Microsoft提供,专门用于处理基于Open XML标准的Office文档,包括PPTX。该SDK提供了底层的文件操作接口,适用于需要深入处理文档结构和内容的应用。
【合合TextIn】智能文档处理系列—电子文档解析技术全格式解析的更多相关文章
- iStylePDF安全电子文档解决方案之电子合同在线订立
交易是商业世界不可或缺的一部分,而签名是交易的凭证.可是,尽管互联网和IT技术已经很发达,但每逢遇到签名,还是得用最原始的方法——握笔写字.与如今走到哪都能听到“互联网+”相比有点不合潮流,通过电子签 ...
- 采用WPF技术,开发OFD电子文档阅读器
前言 OFD是国家标准版式文档格式,于2016年生效.OFD文档国家标准参见<电子文件存储与交换格式版式文档>.既然是国家标准,OFD随后肯定会首先在政务系统使用,并逐步推向社会各个方面. ...
- ofd电子文档内容分析工具(分析文档、签章和证书)
前言 ofd是国家文档标准,其对标的文档格式是pdf.ofd文档是容器格式文件,ofd其实就是压缩包.将ofd文件后缀改为.zip,解压后可看到文件包含的内容. ofd文件分析工具下载:点我下载.获取 ...
- 采用QT技术,开发OFD电子文档阅读器
前言 ofd作为板式文档规范,相当于国产化的pdf.由于pdf标准制定的较早,相关生态也比较完备,市面上的pdf阅读器种类繁多.国内ofd阅读器寥寥无几,作者此前采用wpf开发了一款阅读器,但该阅读器 ...
- C语言最重要的知识点(电子文档)
总体上必须清楚的: 1)程序结构是三种: 顺序结构 .选择结构(分支结构).循环结构. 2)读程序都要从main()入口, 然后从最上面顺序往下读(碰到循环做循环,碰到选择做选择),有且只有一个m ...
- Oracle EBS R12 电子技术参考手册 - eTRM (电子文档)
http://etrm.oracle.com/pls/etrm/etrm_search.search
- JS电子文档链接
http://www.oschina.net/translate/learning-javascript-design-patterns 学用 JavaScript 设计模式 http://es6 ...
- OFD电子文档阅读器功能说明(采用WPF开发,永久免费)
特别说明 ofd阅读器开发语言为c#,具有完全自主产权,没有使用第三方ofd开发包.可以根据你的需求快速定制开发.本阅读器还在开发完善阶段,如有任何问题,可以联系我QQ:13712486.博客:htt ...
- 福昕PDF电子文档处理套装软件中文企业版9.01
下载地址:http://zbh.ustc.edu.cn/msiso/FoxitPDFEditor901_ZH_Setup.msi 激活码:A7000-010S0-RC900-XVF4R-9J5OM-W ...
- 一文读懂四种常见的XML解析技术
之前的文章我们讲解了<XML系列教程之Schema技术_上海尚学堂java培训技术干货><XML的概念.特点与作用.XML申明_上海Java培训技术干货>,大家可以点击回顾一下 ...
随机推荐
- P1387
#include<iostream> #include<utility> using namespace std; typedef long long ll; #define ...
- 一套基于 Ant Design 和 Blazor 的开源企业级组件库
前言 今天大姚给大家分享一套基于Ant Design和Blazor的开源(MIT License).免费的企业级组件库(喜欢Ant Design风格的同学推荐使用):Ant Design Blazor ...
- Unity 2023/Unity 6编辑器文字模糊的解决方案
这是从2023.1开始就有的问题了.本质原因是Unity不知道哪个天才决定的在编辑器文字上使用了SDF渲染. 2023.1因为缺乏选项导致几乎不可用:2023.2加了一个锐度选项:后来在论坛里被众人喷 ...
- Swift开发基础07-内存布局
了解Swift的内存布局和底层原理对于编写高性能和内存高效的应用非常重要.接下来,我将更详细地介绍Swift的内存管理机制和一些底层实现细节,包括内存布局.ARC(自动引用计数).引用类型和值类型的区 ...
- 调试 Node.js
调试 Node.js 调试器 调试器是一种软件工具,用于通过分析方法观察和控制程序的执行流 设计目标:帮助找出 bug 的根本原因,并帮助你解决它 工作方式:将程序托管在自己的执行进程中或者作为附加到 ...
- LeetCode102.二叉树的层序遍历
LeetCode题目链接:https://leetcode.cn/problems/binary-tree-level-order-traversal/submissions/548489149/ 题 ...
- ThinkPHP一对一关联模型的运用(ORM)
一.序言 最近在写ThinkPHP关联模型的时候一些用法总忘,我就想通过写博客的方式复习和整理下一些用法. 具体版本: topthink/framework:6.1.4 topthink/think- ...
- 使用with 还是 join
用分解关联查询的方式查询具有以下优势:多次单表查询,让缓存的效率更高:许多应用程序可以方便地缓存单表查询对应的结果对象.对 MYSQL 的查询缓存来说,如果关联中的某个表发生了变化,那么就无法使用查询 ...
- STM32开发环境配置记录——关于PlatformIO + VSCode + CubeMX的集成环境配置
前言 为什么配置这样的一个环境呢?鄙人受够了Keil5那个简陋的工作环境了,实在是用不下去,调试上很容易跟CubeMX的代码产生不协调导致调试--发布代码不一致造成的一系列问题.CubeIDE虽说 ...
- 【Scala】05 对象特性Part2
特质重复继承关系 父类特质 A 子类特质B 继承 A 子类特质C 继承A 类D 继承了 B 又实现了 C class D extends B with C 继承顺序是 D 继承 C 继承 B 继承 A ...