基于 MaxCompute 的实时数据处理实践
简介: MaxCompute 通过流式数据高性能写入和秒级别查询能力(查询加速),提供EB级云原生数仓近实时分析能力;高效的实现对变化中的数据进行快速分析及决策辅助。当前Demo基于近实时交互式BI分析/决策辅助场景,实现指标卡近实时BI分析、近实时市场监测、近实时趋势分析、近实时销量拆分功能。
本文作者 隆志强 阿里云智能 高级产品专家
一、产品功能介绍
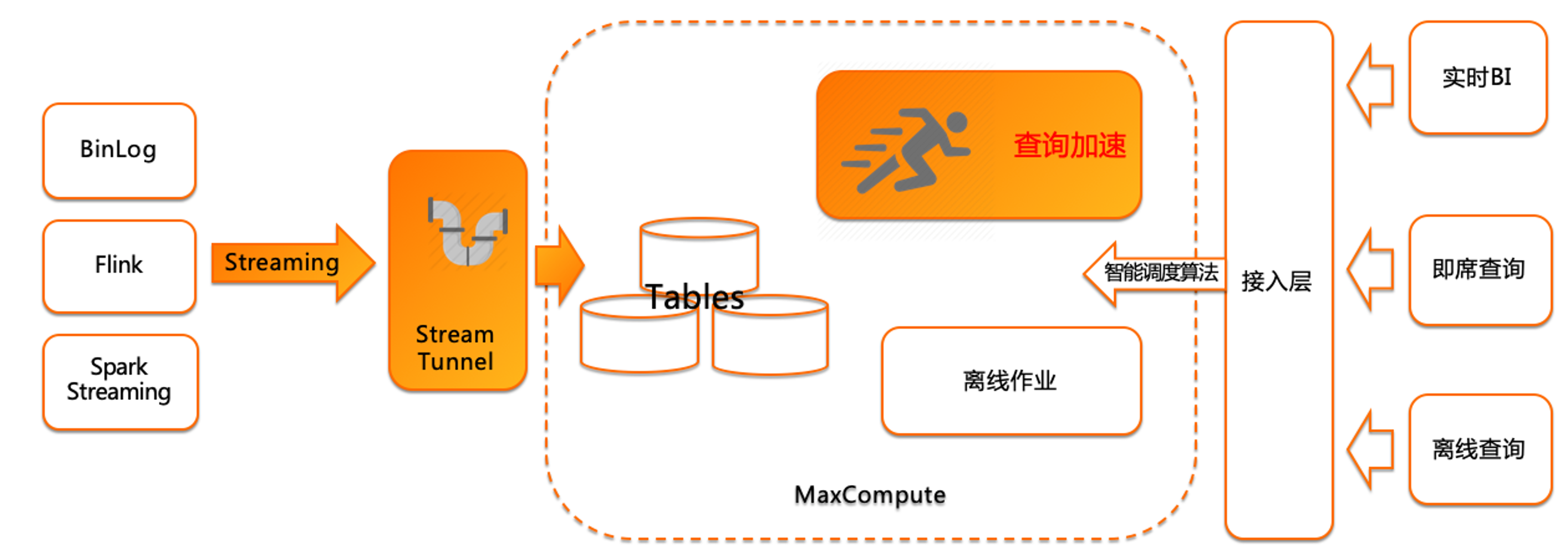
基于查询加速的数仓架构
当前比较盛行的实时数仓,基本都是基于Flink来做的。今天分享的内容不是把 MaxCompute定义为一个实时数仓,我们讲的是基于当前数据的实时处理流程,在MaxCompute中是怎么去做支持的,怎么在 MaxCompute 中做实时数据的接入、查询、应用。开源的实时数仓是基于Flink来做的,Flink本质是实时计算,支持流批一体,所以比较实时的场景都是基于Flink+Kafka+存储来做的。本次分享主要不是讲计算环节,本次主要讲解基于BinLog、Flink、Spark Streaming的实时流数据是怎么写入到 MaxCompute 中的。
通过实时流通道,实时写入MaxCompute,写入即可见,这是 MaxCompute 的产品特点。目前市场的数仓产品写入查询绝大多数都有延时存在, MaxCompute 是做到了高QPS的实时写入,写入即可查。可以通过查询加速(MCQA)实时查询写入进 MaxCompute 的数据。对接到BI工具,即席查询可以实时访问到实时写入的数据。
Binlog写到到MaxCompute,是通过DataX,支持增删改查的合并,后续在产品功能迭代中,MaxCompute会支持upsert,支持业务数据库数据的新增、修改、删除。Flink数据计算完之后写入到 MaxCompute 时,直接使用Streaming Tunnel插件写入MaxCompute中,这个过程不需要做代码开发,Kafka也支持了插件。
实时写入目前没有做写入数据的计算处理环节,只是快速的把现在流式数据包括消息服务的数据,直接通过Streaming Tunnel服务写入到MaxCompute中。当前Streaming Tunnel支持了主流消息服务,如Kafka、Flink,做了插件支持。以及Streaming Tunnel SDK,当前只支持Java SDK。可以通过Streaming Tunnel SDK做一些应用读取之后的逻辑处理,再调取Streaming Tunnel SDK写入到MaxCompute中。写入MaxCompute之后,目前主要的处理环节是针对写入的数据,进行直读查询,也可以把写入的数据关联到MaxCompute中的离线数据,做联合查询分析。在查的过程中,如果是通过SDK或者JDBC接入时,可以打开查询加速(MCQA)功能。如果是通过web console或DataWorks,是默认开启查询加速(MCQA)功能。当前主要是BI分析工具和第三方应用层分析工具,通过SDK或JDBC链接MaxCompute时,是可以打开查询加速(MCQA)功能,这样可以做到接近秒级查询实时写入的数据。
整体来看,现在的场景主要是数据的实时流式写入,写入之后可以结合离线数据,做联合分析查询,通过查询加速(MCQA)功能。在数据进入MaxCompute后,是没有做计算的,只是做查询服务。这是目前基于MaxCompute实时数据处理场景。
流式数据写入功能介绍
当前流式数据写入功能已经在中国区商业化发布。当前此功能是免费使用。
功能特定
- 支持高并发、高QPS(Queries-per-second)场景下流式数据写入,写入即可见。
- 提供流式语义API:通过流式服务的API可以方便的开发出分布式数据同步服务。
- 支持自动创建分区:解决数据同步服务并发创建分区导致的并发抢锁问题。
- 支持增量数据异步聚合(Merge):提升数据存储效率。
- 支持增量数据异步zorder by排序功能,zorder by详情请参见插入或覆写数据(INSERT INTO | INSERT OVERWRITE)。
性能优势
- 更优化的数据存储结构,解决高QPS写入导致的碎片文件问题。
- 数据链路与元数据访问完全隔离,解决高并发写入场景下元数据访问导致的抢锁延迟和报错问题。
- 提供了增量数据异步处理机制,可以在使用过程中无感知情况下对新写入的增量数据做进一步处理,已经支持的功能包括:
- 数据聚合(Merge): 提升存储效率。
- zorder by排序:提升存储、查询效率。
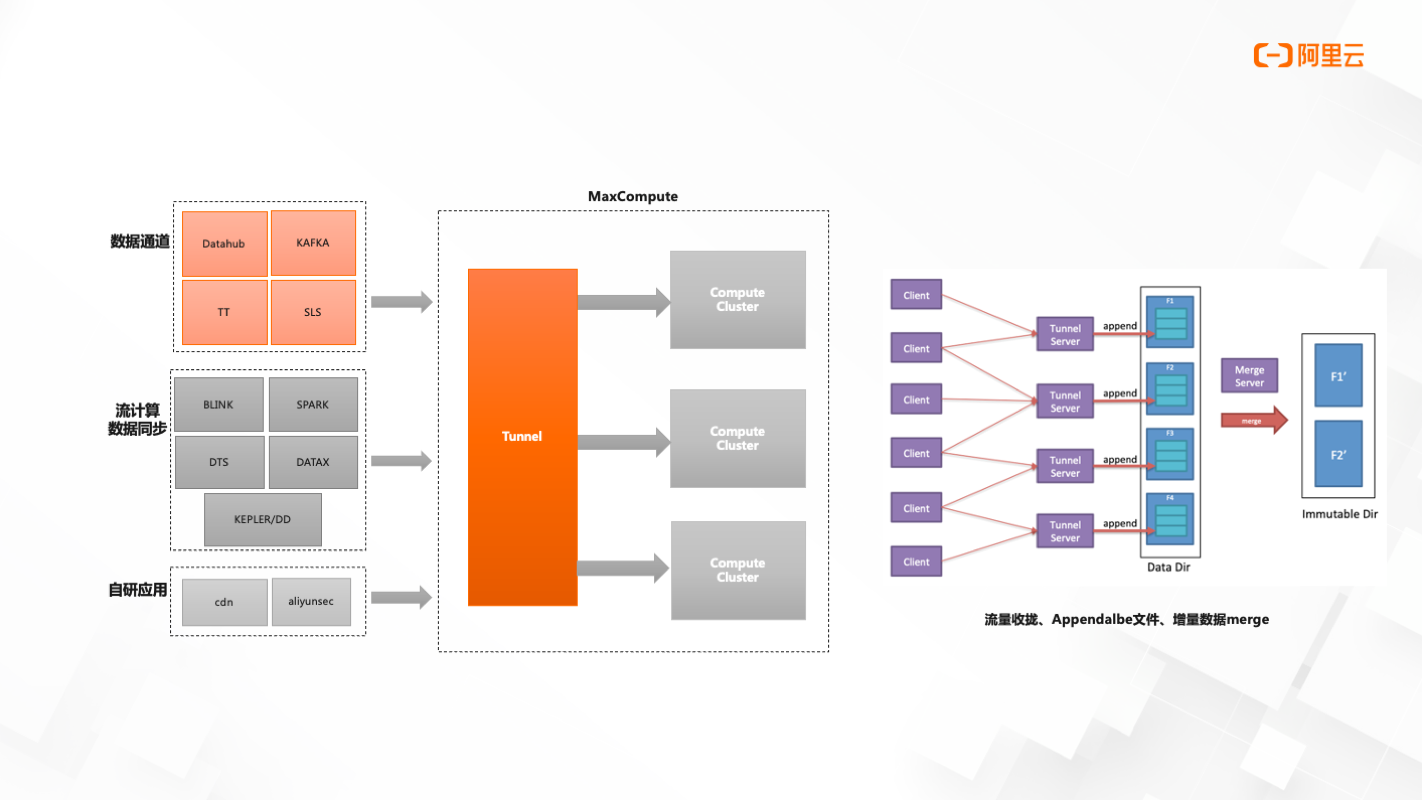
流式数据写入-技术架构
Stream API无状态并发数据实时可见
技术架构分为三个部分:数据通道、流计算数据同步、自研应用。
当前数据通道支持的有Datahub、Kafka、TT、SLS
流计算数据同步支持的有Blink、Spark、DTS、DataX、kepler/DD
数据写入MaxCompute中,在计算集群前会有Tunnel集群存在,提供Stream Tnnel服务来完成从客户端到Tunnel服务端数据的写入。写入过程是一个文件最佳的过程,最后会有一个文件的合并。这个过程是消耗了数据通道过程中的计算资源服务,但这一消耗是免费的。
查询加速功能介绍
实现数据实时写入与基于查询加速的交互式分析
目前查询加速功能可以支持日常查询80%-90%的场景。查询加速功能的语法与MaxCompute内置语法完全一致。
MaxCompute查询加速 – 针对实时性要求高的查询作业,全链路加快 MaxCompute 查询执行速度
- 使用MaxComputeSQL语法和引擎,针对近实时场景进行优化
- 系统自动进行查询优化选择,同时支持用户选择延时优先还是吞吐优先的执行方式
- 针对近实时场景使用不同的资源调度策略:latencybased
- 针对低延时要求的场景进行全链路优化:独立执行资源池;多层次的数据和metaCaching;交互协议优化
收益
- 简化架构,查询加速与海量分析自适应的一体化方案
- 对比普通离线模式快几倍甚至数十倍
- 结合MaxCompute流式上传能力,支持近实时分析
- 支持多种接入方式,易集成
- 支持自动识别离线任务中的短查询,后付费模式是默认开启。预付费当前支持为使用包年包月资源的实例下SQL扫描量在10 GB以内的查询作业提供免费查询加速服务。
- 低成本,免运维,高弹性
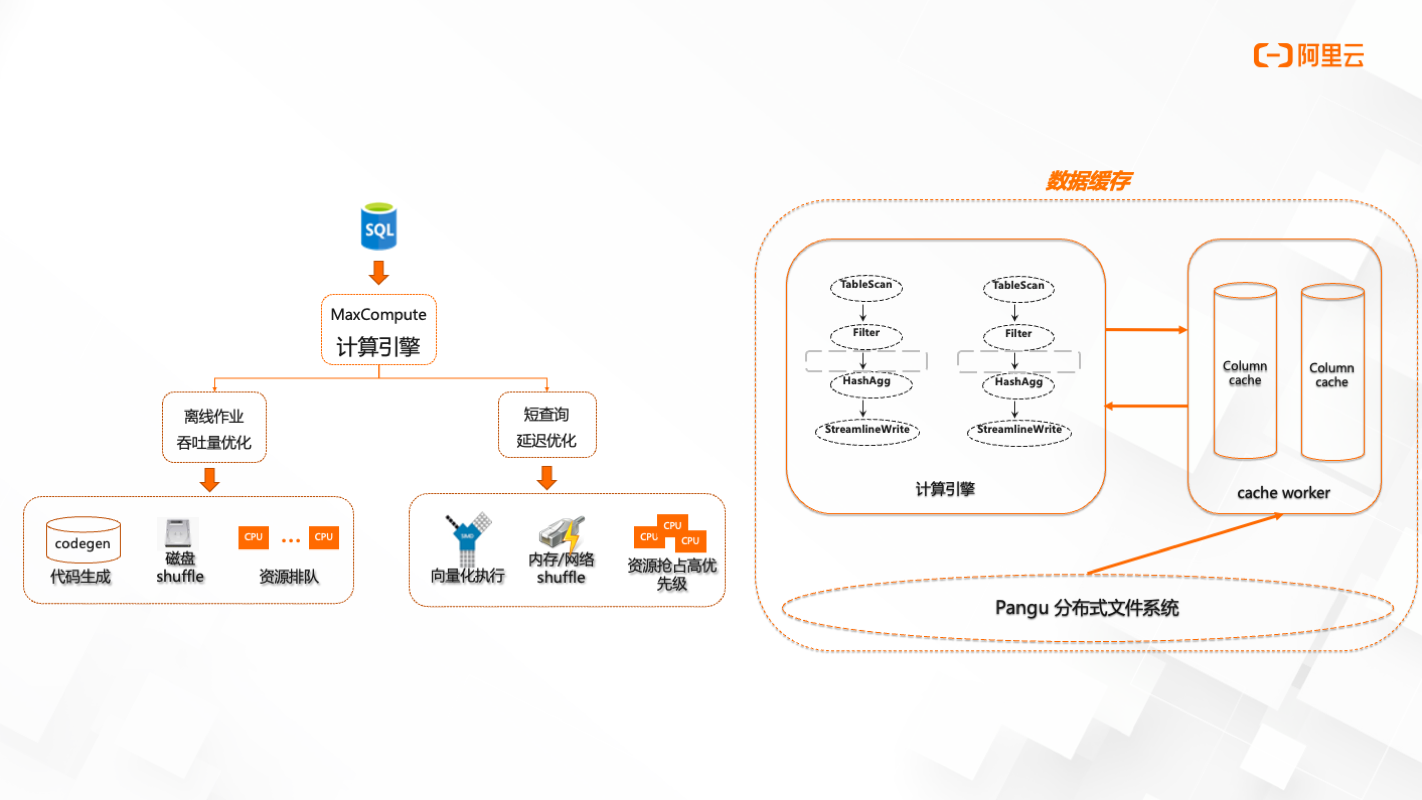
查询加速-技术架构
自适应执行引擎、多层次缓存机制
当SQL提交到MaxCompute计算引擎时,会分为两个模式,离线作业(吞吐量优化)和短查询(延迟优化)。两个模式从技术底层来说,查询加速作业做了执行计划的缩减和优化,计算资源是预拉起资源,是向量化执行,会基于内存/网络shuffle以及多层次的缓存机制。相比于离线作业的代码生产到磁盘shuffle,再进行资源排队申请。查询加速会进行识别作业,如果符合条件,则直接进入预拉起资源。在数据缓存部分,基于Pangu分布式文件系统,对表跟字段会有一个缓存机制。
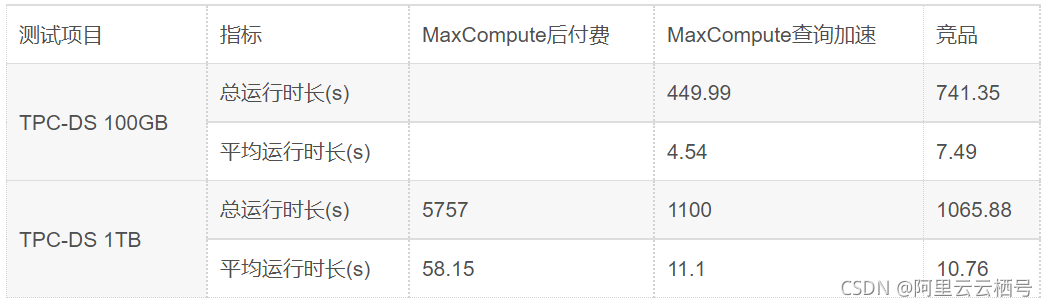
查询加速-性能比对
TPCDS测试集与某业界领先竞品的性能比较
- 100GB超越30%以上
- 1TB规模性能不相上下

二、应用场景
流式数据写入-应用场景
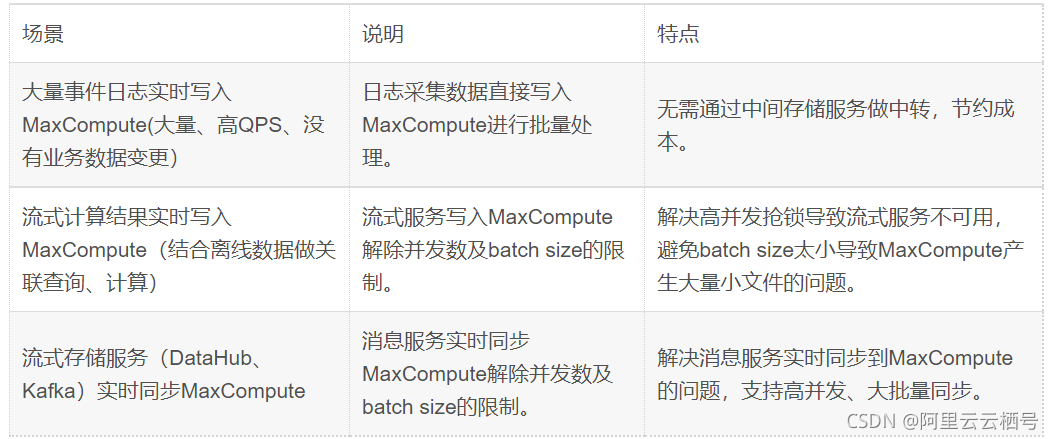
查询加速-应用场景
固定报表快速查询
- 数据ETL处理为面向消费的聚合数据
- 满足固定报表/在线数据服务需求,秒级查询
- 弹性并发/数据缓存/易集成
通过数据应用工具或者是BI分析工具通过JDBC/SDK接入到MaxCompute,可以直读到MaxCompute内的表数据。
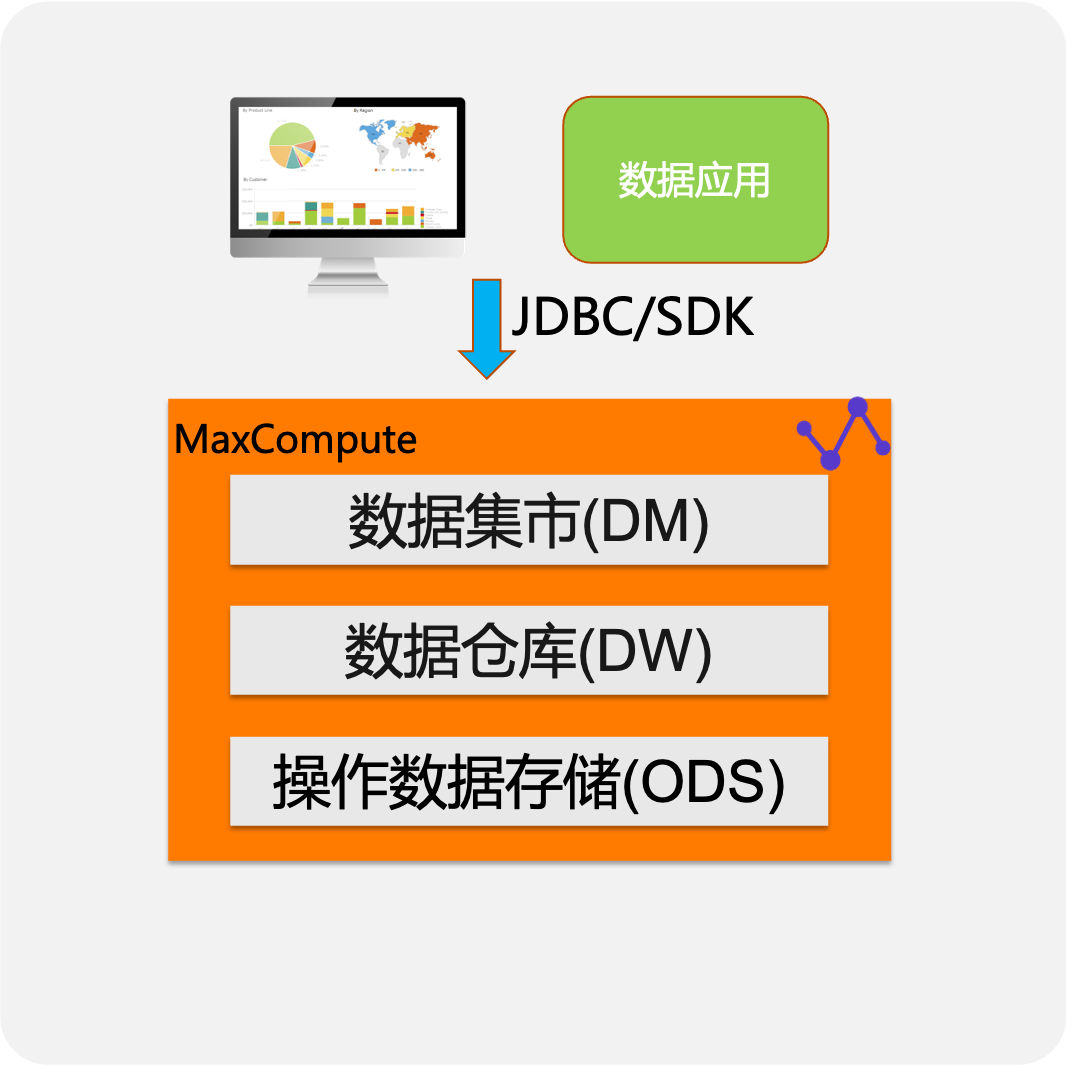
Ad-hoc数据探索分析
- 自动识别作业特征,根据数据规模、计算复杂度选择不同的执行模式,简单查询跑的快、复杂查询算得动
- 配合存储层建模优化,如分区、HashClustering等进一步优化查询性能
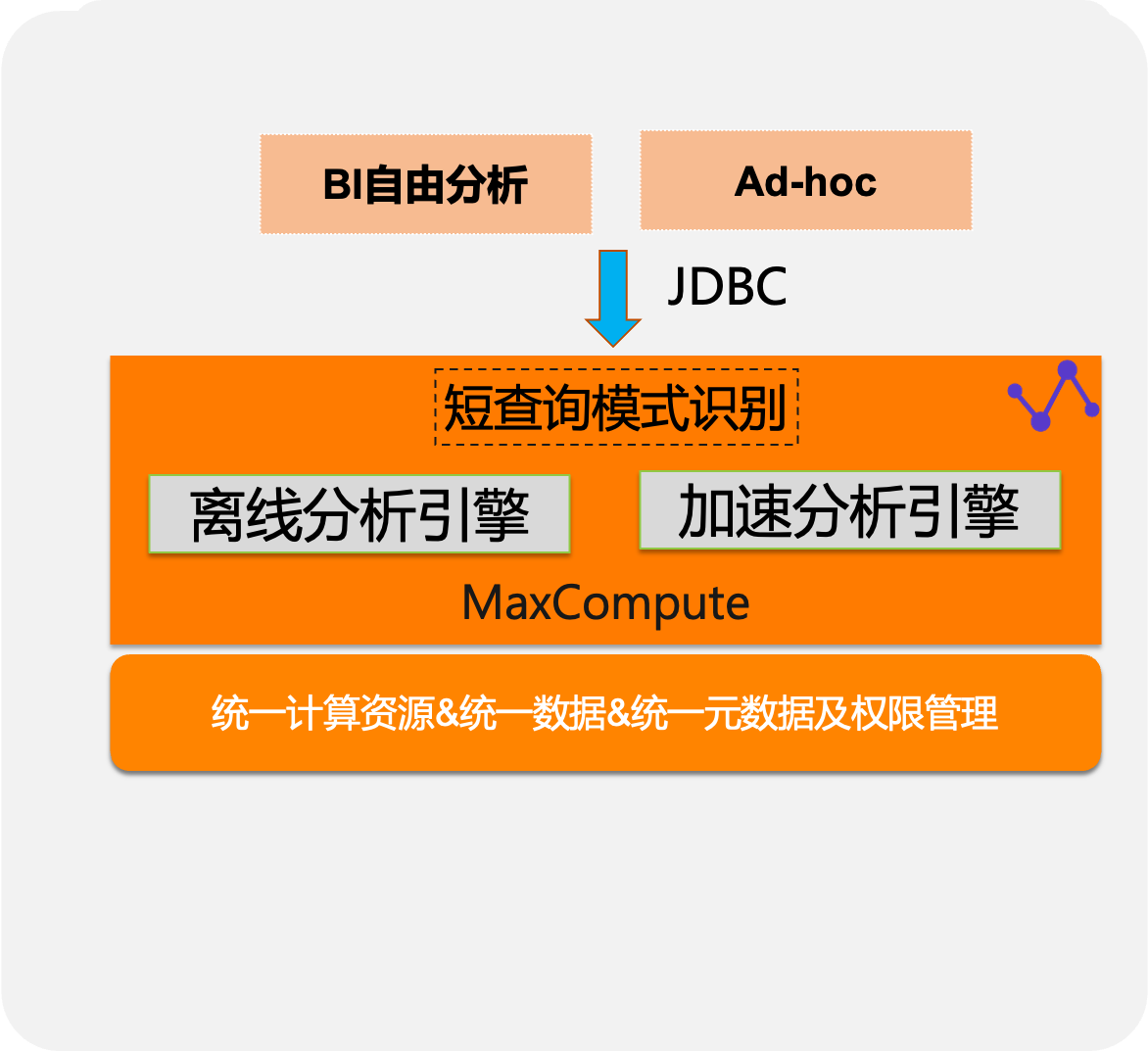
近实时运营分析
- 支持批量和流式数据接入
- 历史数据和近实时数据融合分析
- 产品级别集成消息服务:
- Datahub-日志/消息
- DTS-数据库日志
- SLS-行为日志
- Kafka-物联网/日志接入
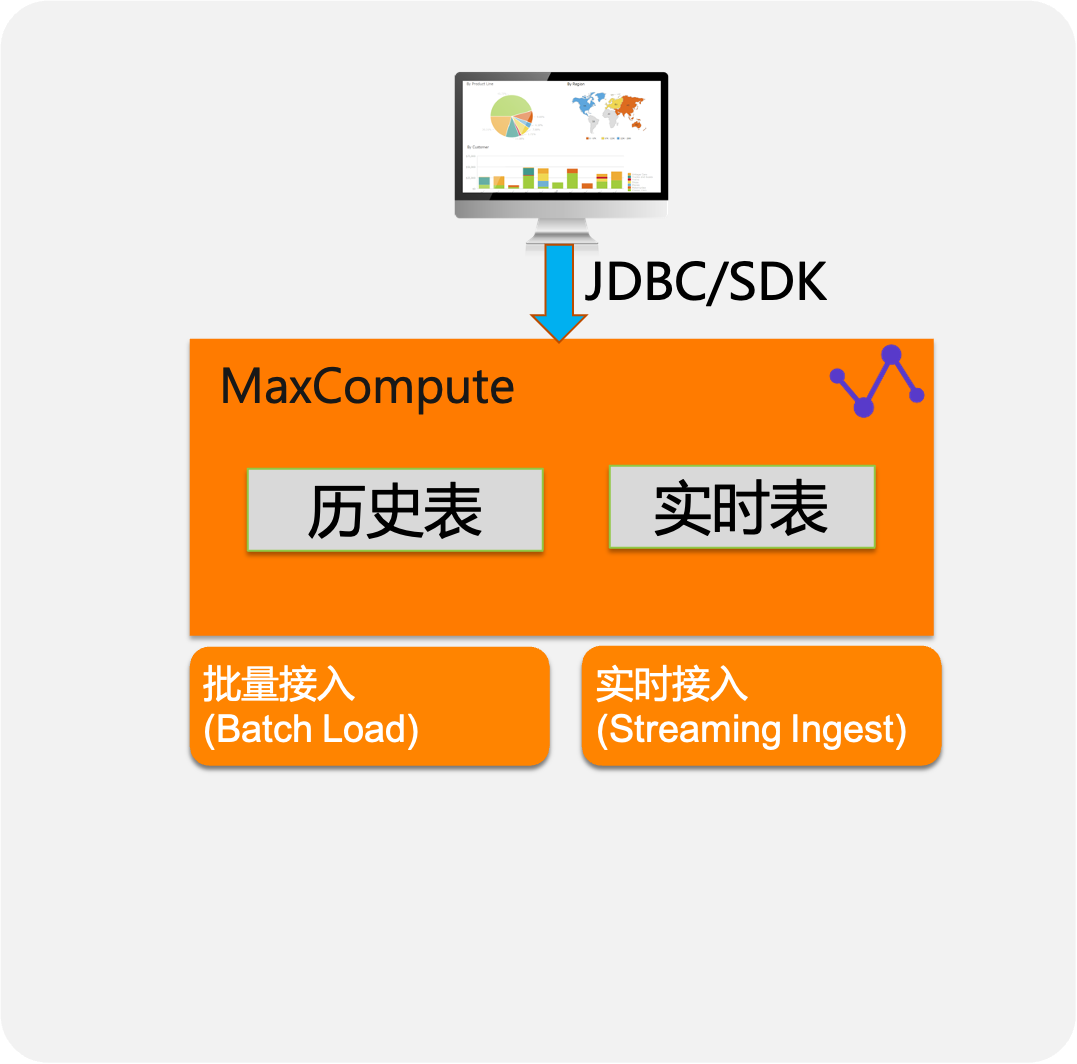
三、工具及接入
流式数据写入-接入
消息&服务
- 消息队列Kafka(插件支持)
- Logstash的输出插件(插件支持)
- Flink版内置插件
- DataHub实时数据通道(内部插件)
SDK类新接口-Java
参考上述示例可以自己封装相应的业务逻辑。
查询加速-接入
工具类
- DataWorks(默认开启)
- ODPS CMD(需要配置)
- MaxCompute Studio(需要配置)
SDK类接口
- ODPS JavaSDK
- ODPS PythonSDK
- JDBC
老接口兼容
- 自动识别模式
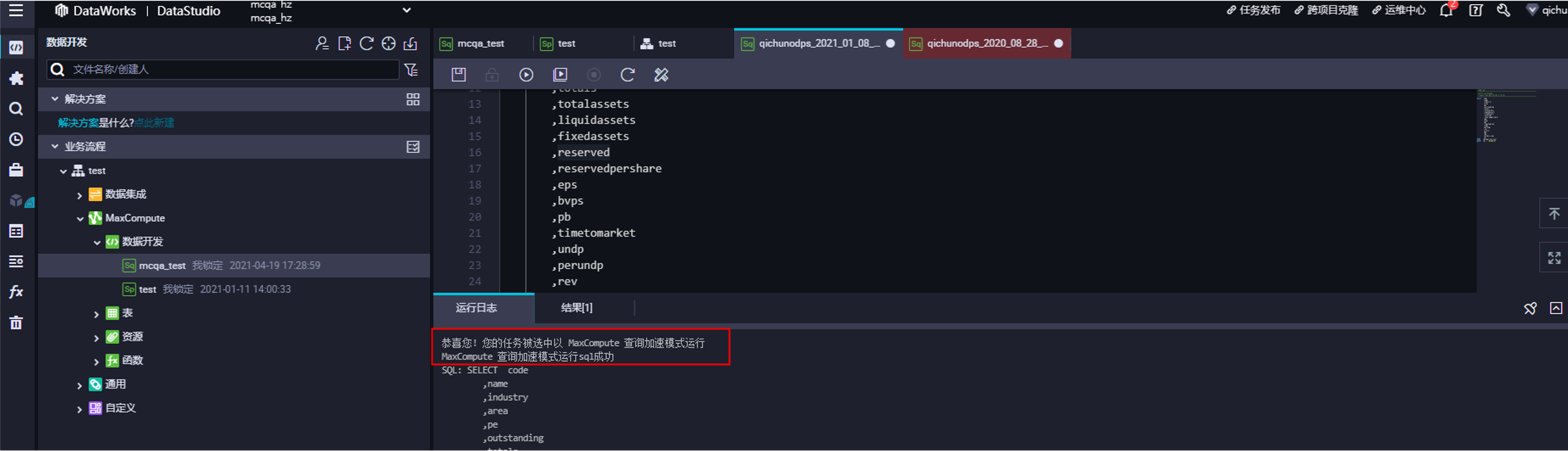
四、Demo&总结
基于MaxCompute的实时数据处理实践
实现对变化中的数据进行快速高性能分析及决策辅助,10亿条数据查询秒级获取。
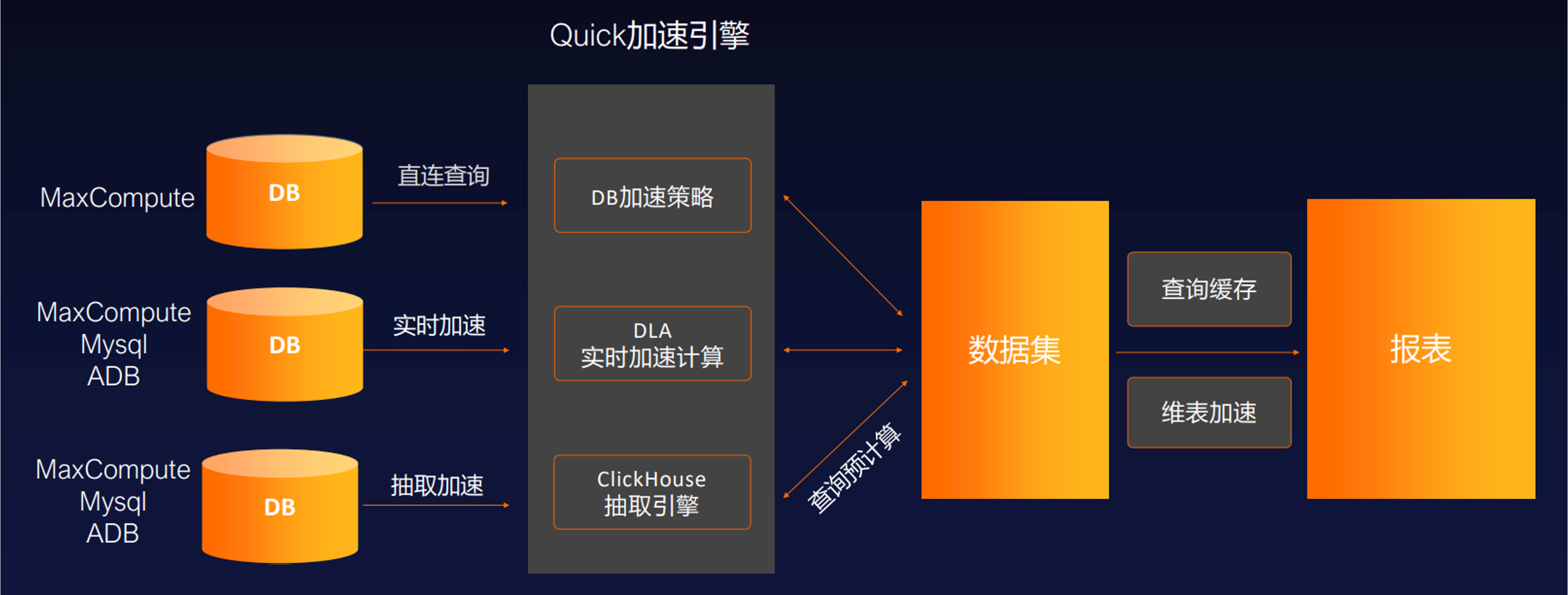
本次Demo实践是通过MaxCompute+QuickBI实现。QuickBI现在已支持直连的MaxCompute查询加速模式,QuickBI本身已有加速引擎,如DLA、CK等。当前最优的模式,直连MaxCompute走查询加速模式是最快的。
实践总结
优点
- Streaming Tunnel: 实时写入可见,解决了高QPS写入导致的碎片文件问题;
- 查询加速:低延迟-多级缓存&快速资源调度、易用-一套SQL语法、弹性-存储计算分离
提升
- 目前下游应用消费/汇总时每次只能全量查询,无法做进一步实时流计算处理;实时入库不支持修改、删除;
- 后续MC提供流式SQL引擎运行实时流作业,做到流批一体
原文链接
本文为阿里云原创内容,未经允许不得转载。
基于 MaxCompute 的实时数据处理实践的更多相关文章
- [转]基于Storm的实时数据处理方案
1 文档说明 该文档描述的是以storm为主体的实时处理架构,该架构包括了数据收集部分,实时处理部分,及数据落地部分. 关于不同部分的技术选型与业务需求及个人对相关技术的熟悉度有关,会一一进行分析. ...
- 基于Lua脚本解决实时数据处理流程中的关键问题
摘要 在处理实时数据的过程中需要缓存的参与,由于在更新实时数据时并发处理的特点,因此在更新实时数据时经常产生新老数据相互覆盖的情况,针对这个情况调查了Redis事务和Lua脚本后,发现Redis事务并 ...
- 基于MaxCompute打造轻盈的人人车移动端数据平台
摘要: 2019年1月18日,由阿里巴巴MaxCompute开发者社区和阿里云栖社区联合主办的“阿里云栖开发者沙龙大数据技术专场”走近北京联合大学,本次技术沙龙上,人人车大数据平台负责人吴水永从人人车 ...
- 基于MaxCompute的媒体大数据开放平台建设
摘要:随着自媒体的发展,传统媒体面临着巨大的压力和挑战,新华智云运用大数据和人工智能技术,致力于为媒体行业赋能.通过媒体大数据开放平台,将媒体行业全网数据汇总起来,借助平台数据处理能力和算法能力,将有 ...
- 基于MaxCompute的数仓数据质量管理
声明 本文中介绍的非功能性规范均为建议性规范,产品功能无强制,仅供指导. 参考文献 <大数据之路——阿里巴巴大数据实践>——阿里巴巴数据技术及产品部 著. 背景及目的 数据对一个企业来说已 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统
使用 Kafka 和 Spark Streaming 构建实时数据处理系统 来源:https://www.ibm.com/developerworks,这篇文章转载自微信里文章,正好解决了我项目中的技 ...
- 使用 Kafka 和 Spark Streaming 构建实时数据处理系统(转)
原文链接:http://www.ibm.com/developerworks/cn/opensource/os-cn-spark-practice2/index.html?ca=drs-&ut ...
- 基于Kafka的实时计算引擎如何选择?Flink or Spark?
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- 基于Kafka的实时计算引擎如何选择?(转载)
1.前言 目前实时计算的业务场景越来越多,实时计算引擎技术及生态也越来越成熟.以Flink和Spark为首的实时计算引擎,成为实时计算场景的重点考虑对象.那么,今天就来聊一聊基于Kafka的实时计算引 ...
- MaxCompute表设计最佳实践
MaxCompute表设计最佳实践 产生大量小文件的操作 MaxCompute表的小文件会影响存储和计算性能,因此我们先介绍下什么样的操作会产生大量小文件,从 而在做表设计的时候考虑避开此类操作. 使 ...
随机推荐
- Welcome to YARP - 3 负载均衡 (Load Balancing)
目录 Welcome to YARP - 1.认识YARP并搭建反向代理服务 Welcome to YARP - 2.配置功能 2.1 - 配置文件(Configuration Files) 2.2 ...
- FBEC大会 | 瑞云科技 CTO 赵志杰:元宇宙时代的基础设施——实时云渲染
FBEC未来商业生态链接大会于2023年2月24日在深圳福田大中华喜来登酒店盛大召开,本次大会由广东省游戏产业协会.深圳市互联网文化市场协会指导,陀螺科技主办. 大会以"勇毅前行·逐光而上& ...
- 企业家智能客服知识库重磅更新,发布`v0.1.5`
FastWiki加入AIDotNet (github.com),FastWiki不再属于个人项目,目前FastWiki捐赠给了AIDotNet组织,AIDotNet拥有一下优秀项目: 项目名称 链接 ...
- Prism框架的用法
今天,我向大家介绍一款WPF后台框架,以及,它的用法. 官网 https://prismlibrary.com/ Prism 框架是一个用于构建松耦合.可维护且可测试的 WPF 和 Xamarin.F ...
- 记录--Vue3 封装 ECharts 通用组件
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 按需导入的配置文件 配置文件这里就不再赘述,内容都是一样的,主打一个随用随取,按需导入. import * as echarts from ...
- centos7上单机安装fastdfs6.0.9
目录 1.背景 2.fastdfs的一些知识 2.1 fastdfs的特点 2.2 架构图 2.2.1 client 介绍 2.2.2 tracker-server 介绍 2.2.3 storage- ...
- Python 生成二维码的几种方式、生成条形码
一: # 生成地维码 import qrcode import matplotlib.pyplot as plt from barcode.writer import ImageWriter 创建QR ...
- 学习笔记-Kafka消息队列
官网地址:https://kafka.apache.org/ 一.认识kafka 1.认识kafka Apache Kafka是Apache软件基金会的开源的流处理平台,该平台提供了消息的订阅与发布的 ...
- Java 中文、unicode编码互转 ;汉字、二进制字符串互转
//中文转unicode编码 public static String gbEncoding(final String gbString) { char[] utfBytes = gbString.t ...
- java实战字符串1:给定两个字符串 s 和 t,判断他们的编辑距离是否为 1。
题目描述给定两个字符串 s 和 t,判断他们的间距是否为 1.(满足以下三个条件) 往 s 中插入一个字符得到 t从 s 中删除一个字符得到 t在 s 中替换一个字符得到 t 例1 输入: ab ac ...