【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!
一、爬虫对象-豆瓣音乐TOP250
今天我们分享一期python爬虫案例讲解。爬取对象是,豆瓣音乐TOP250排行榜数据:https://music.douban.com/top250
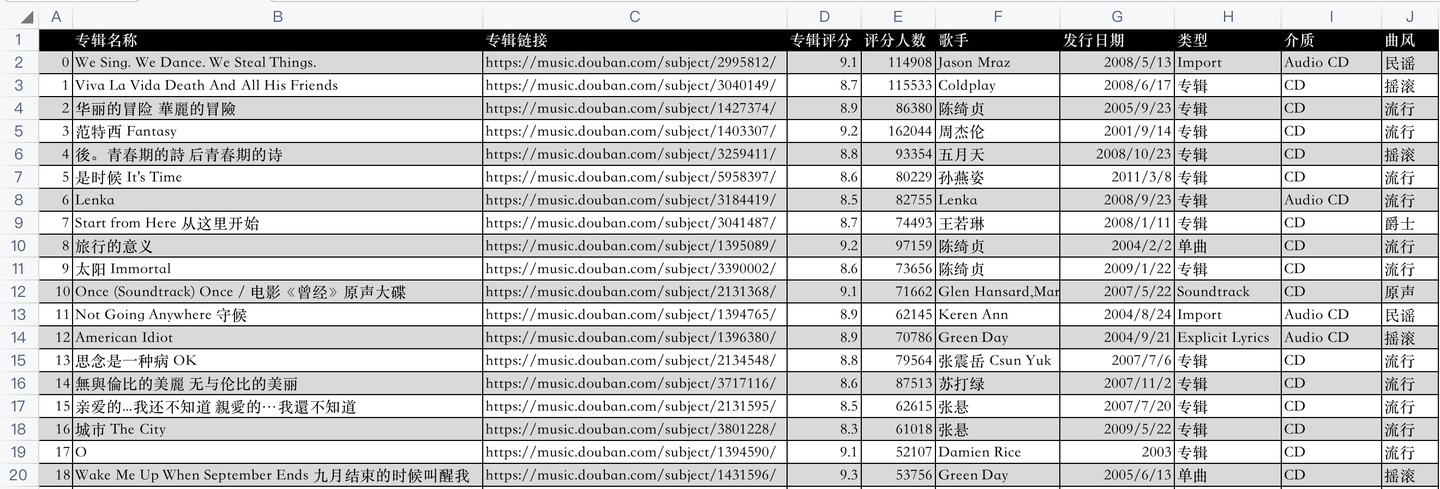
开发好python爬虫代码后,爬取成功后的csv数据,如下:
代码是怎样实现的爬取呢?下面逐一讲解python实现。
二、python爬虫代码讲解
首先,导入需要用到的库:
import requests # 发送请求
from bs4 import BeautifulSoup # 解析网页
import pandas as pd # 存取csv
from time import sleep # 等待时间
然后,向豆瓣音乐网页发送请求:
res = requests.get(url, headers=headers)
利用BeautifulSoup库解析响应页面:
soup = BeautifulSoup(res.text, 'html.parser')
用BeautifulSoup的select函数,(css解析的方法)编写代码逻辑,部分核心代码:
name = music.select('.pl2 a')[0].text.replace('\n', '').replace(' ', ' ').strip() # 专辑名称
music_name.append(name)
url = music.select('.pl2 a')[0]['href'] # 专辑链接
music_url.append(url)
star = music.select('.rating_nums')[0].text # 音乐评分
music_star.append(star)
star_people = music.select('.pl')[1].text # 评分人数
star_people = star_people.strip().replace(' ', '').replace('人评价', '').replace('(\n', '').replace('\n)',
'') # 数据清洗
music_star_people.append(star_people)
music_infos = music.select('.pl')[0].text.strip() # 歌手、发行日期、类型、介质、曲风
最后,将爬取到的数据保存到csv文件中:
def save_to_csv(csv_name):
"""
数据保存到csv
:return: None
"""
df = pd.DataFrame() # 初始化一个DataFrame对象
df['专辑名称'] = music_name
df['专辑链接'] = music_url
df['专辑评分'] = music_star
df['评分人数'] = music_star_people
df['歌手'] = music_singer
df['发行日期'] = music_pub_date
df['类型'] = music_type
df['介质'] = music_media
df['曲风'] = music_style
df.to_csv(csv_name, encoding='utf_8_sig') # 将数据保存到csv文件
其中,把各个list赋值为DataFrame的各个列,就把list数据转换为了DataFrame数据,然后直接to_csv保存。
这样,爬取的数据就持久化保存下来了。
需要说明的是,豆瓣页面上第4、5、6页只有24首(不是25首),所以总数量是247,不是250。
不是爬虫代码有问题,是豆瓣页面上就只有247条数据。
三、同步视频
同步讲解视频:【python爬虫】利用python爬虫爬取豆瓣音乐TOP250的数据!
四、获取完整源码
附完整源码:【python爬虫案例】利用python爬虫爬取豆瓣音乐TOP250的数据!
我是 @马哥python说 ,持续分享python源码干货中!
【python爬虫案例】用python爬豆瓣音乐TOP250排行榜!的更多相关文章
- python爬虫1——获取网站源代码(豆瓣图书top250信息)
# -*- coding: utf-8 -*- import requests import re import sys reload(sys) sys.setdefaultencoding('utf ...
- Python爬虫小白入门(七)爬取豆瓣音乐top250
抓取目标: 豆瓣音乐top250的歌名.作者(专辑).评分和歌曲链接 使用工具: requests + lxml + xpath. 我认为这种工具组合是最适合初学者的,requests比pytho ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
随机推荐
- 基于ARM联合ZYNQ的设计小结
基于ARM联合ZYNQ的设计小结 1.硬件设计 硬件设计就是使用PS的自带硬核,外接其他可以连接AXI的IP核,构成一个自定义的硬件平台.如果简单理解,可以把这些操作统称为底层.这部分的设计还是比较方 ...
- KingbaseES 优化之sql优化方法
金仓数据库在sql层面提供了多种优化手段,但是这些的前提时需要保证我们的统计信息准确,优化器已经在正确信息下选择了它认为的最优的执行计划, 优化手段包括 •使用索引 索引解决的问题用于在进行表的扫描时 ...
- KingbaseES数据库适配Activiti7 didn't put process definition问题处理过程
一.Activiti介绍 Activiti是一个轻量级的java开源BPMN 2工作流引擎.目前以升级至7.x,支持与springboot2.x集成. 二.项目环境 Spring Boot版本2.2. ...
- #分块,可撤销并查集#洛谷 3247 [HNOI2016]最小公倍数
题目 分析 考虑将询问和边权按 \(a\) 分别从小到大排序,考虑最暴力的做法就是将不超过 \(a'\) 且 不超过 \(b'\) 的边抽取出来 放进并查集判断 \(a,b\) 的最大值都能达到 \( ...
- #矩阵树定理,高斯消元,容斥定理#洛谷 4336 [SHOI2016]黑暗前的幻想乡
题目 分析 这很明显是矩阵树定理,但是每个建筑公司都恰好修建一条边非常难做, 考虑如果一个建筑公司在某个方案中并没有恰好修建一条边, 那么这种方案一定能在不选其它任意一个公司的方案中被减掉, 那就可以 ...
- IDEA Tab键设置为4个空格
在不同的编辑器里 Tab 的长度可能会不一致,这会导致有 Tab 的代码,用不同的编辑器打开时,格式可能会乱. 而且代码压缩时,空格会有更好的压缩率. 所以建议将 IDEA 的 Tab 键设置为 4 ...
- VS2019 开发 MFC ACtivex (OCX)控件
需求: js调用ocx方法,传递字符串到ocx控件中显示 操作步骤: 一.新建 ocx 项目 二.填写项目信息 三.完成项目创建 四.修改项目属性 打开 项目属性 -> 链接器 -> ...
- 比nestjs更优雅的ioc:跨模块访问资源
使用ts的最佳境界:化类型于无形 在项目中使用ts可以带来类型智能提示与校验的诸多好处.同时,为了减少类型标注,达到化类型于无形的效果,CabloyJS引入了ioc和依赖查找的机制.在上一篇文章中,我 ...
- HarmonyOS Connect FAQ第四期
原文:https://mp.weixin.qq.com/s/bvaV086QTnpnDFyYAVxQwQ,点击链接查看更多技术内容.在HarmonyOS Connect生态产品的认证测试环节,你是否存 ...
- Vue 项目 invalid host header 问题 配置 disableHostCheck:true报错
项目场景:解决 Vue 项目 invalid host header 问题disableHostCheck:true报错 问题描述使用内网穿透时出现 invalid host header找了好多都是 ...