【Python爬虫案例】用python爬1000条哔哩哔哩搜索结果
一、爬取目标
大家好,我是 @马哥python说 ,一名10年程序猿。
今天分享一期爬虫的案例,用python爬哔哩哔哩的搜索结果,也就是这个页面: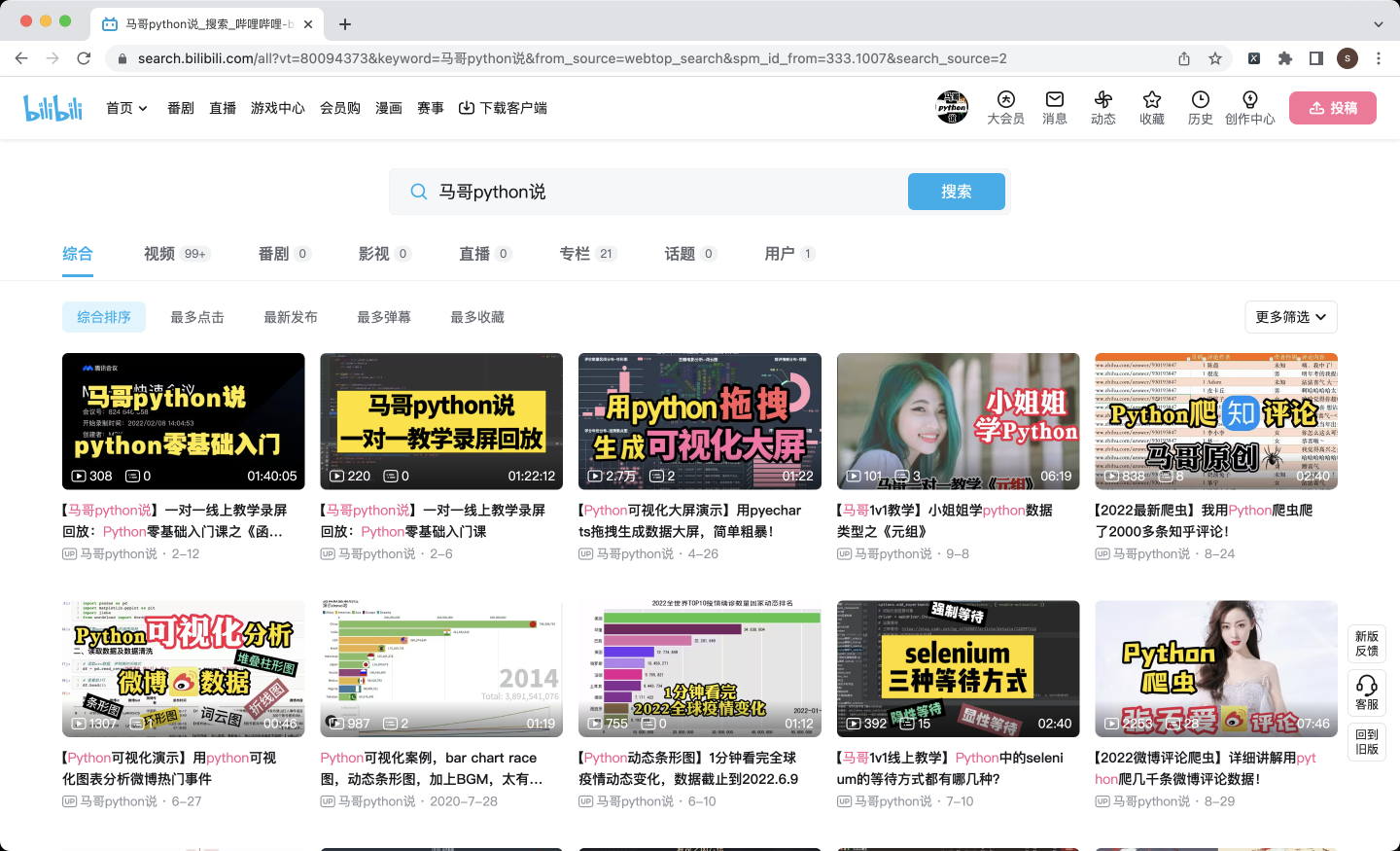
爬取字段,包含:
页码, 视频标题, 视频作者, 视频编号, 创建时间, 视频时长, 弹幕数, 点赞数, 播放数, 收藏数, 分区类型, 标签, 视频描述
部分爬取结果: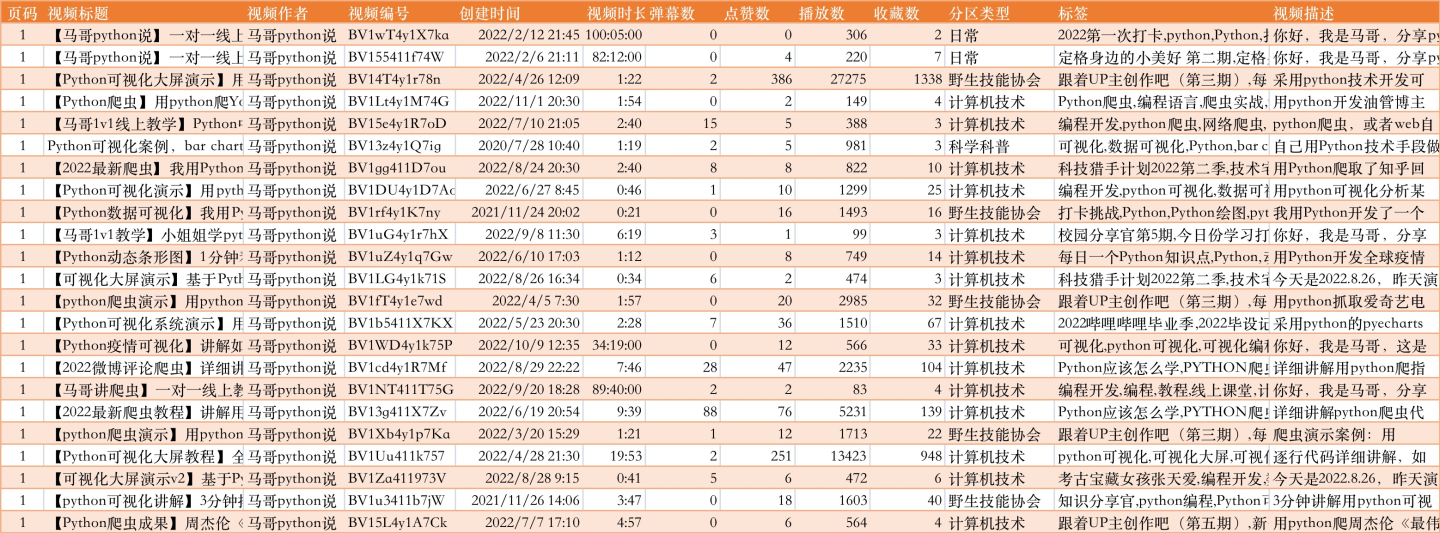
这里,我一共爬了30页,每页30条,共30*30=900条数据(当然,最大爬取页数可自定义放大)
下面,开始分析网页。
打开开发者模式,在页面搜索关键词,并进行翻页一次,如下: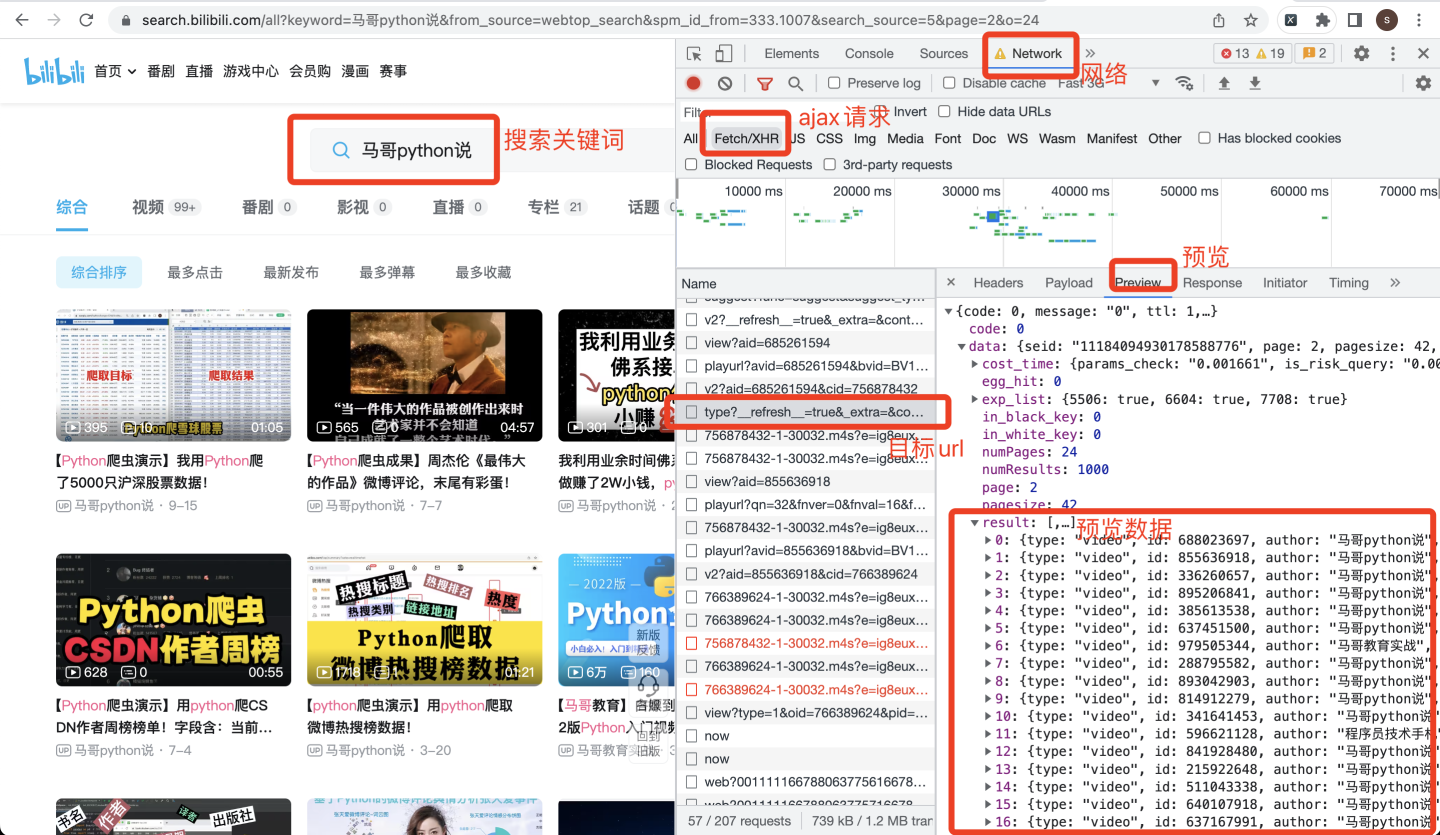
看到了result节点中的列表数据,就是我们要找到的视频数据,依次查看每个具体数据: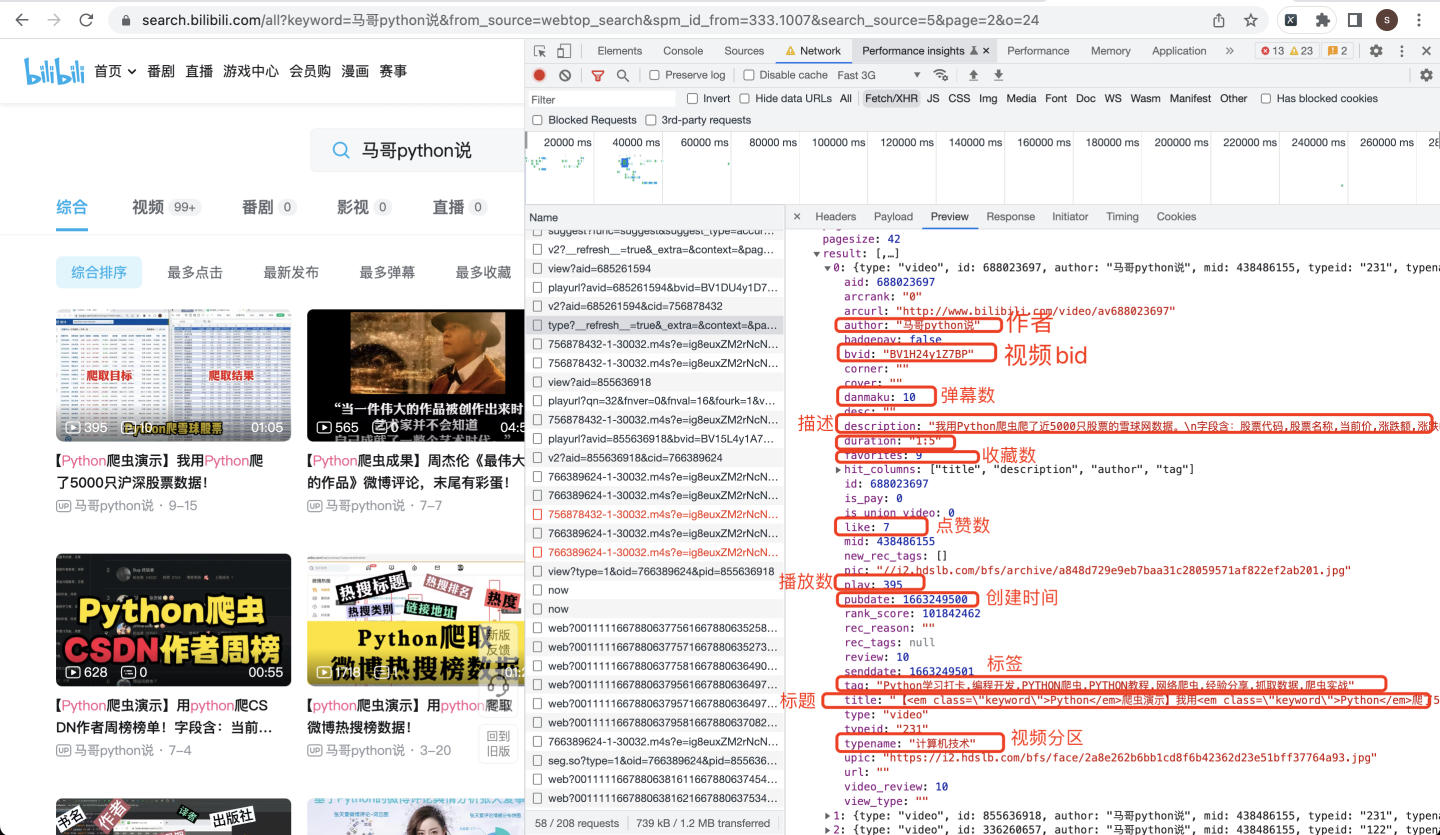
json数据
分析到这里,就可以开发爬虫了。
二、讲解代码
首先,导入用到的库:
import requests # 发送请求
import time # 获取时间
import os
import pandas as pd # 保存csv数据
import re # 数据清洗
下面,开始发送请求。
请求地址在哪获取呢?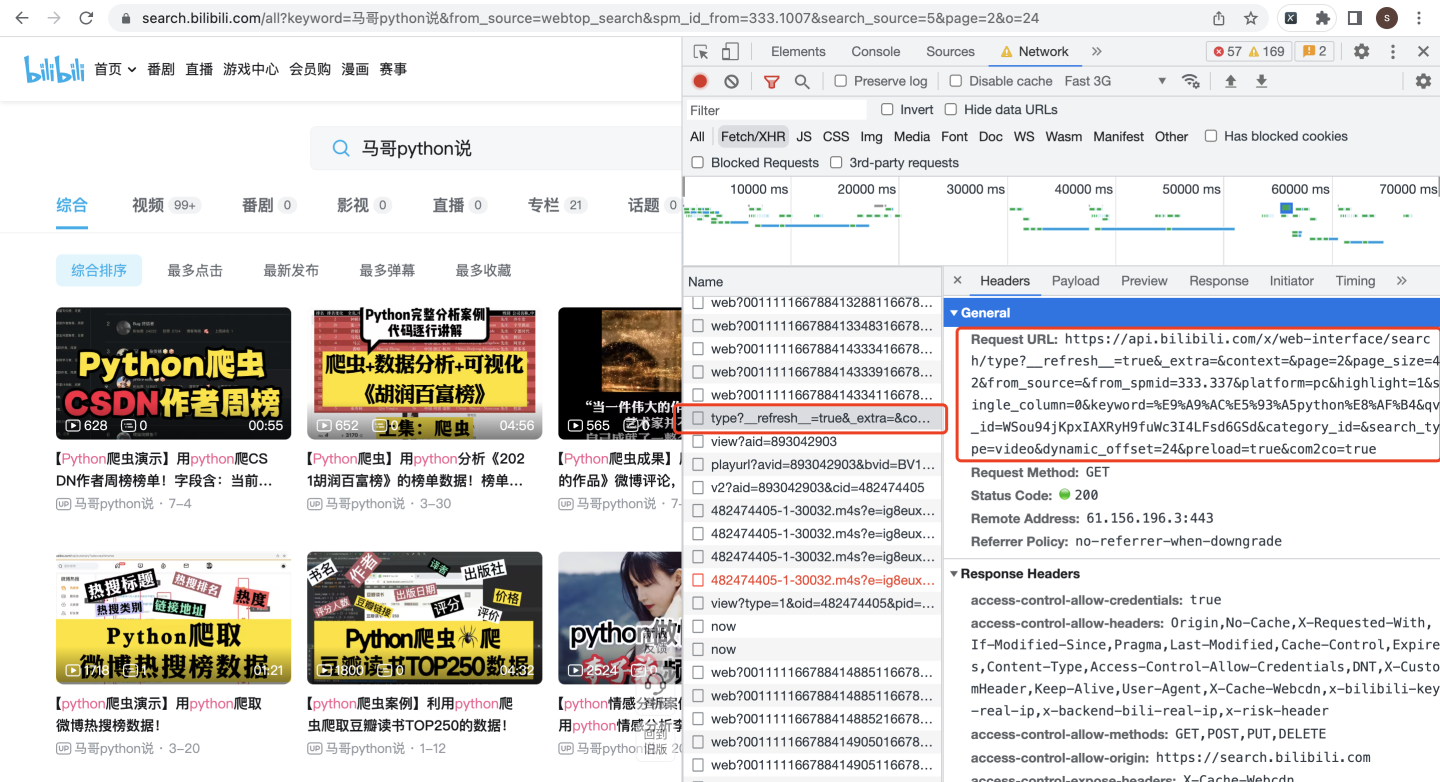
请求参数在Payload里面: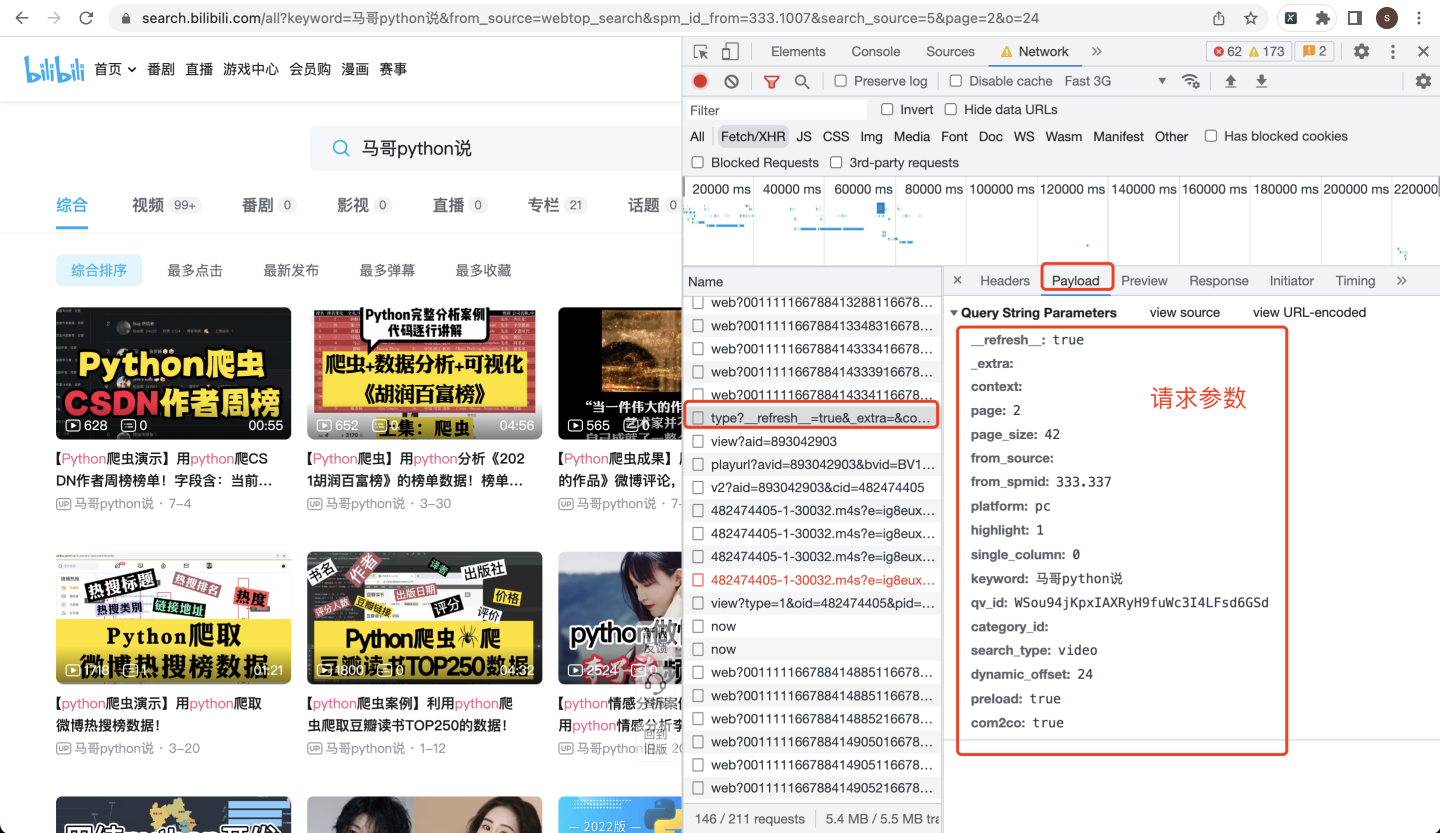
请求参数代码:
# 请求参数
params = {
'__refresh__': 'true',
'_extra': '',
'context': '',
'page': page,
'page_size': 30,
'from_source': '',
'from_spmid': '333.337',
'platform': 'pc',
'highlight': '1',
'single_column': '0',
'keyword': v_keyword,
'qv_id': 'dHavr2spEK3TphPa54klZ6svdhBYOlyP',
'category_id': '',
'search_type': 'video',
'dynamic_offset': 24,
'preload': 'true',
'com2co': 'true',
}
请求头,在Request Headers里面: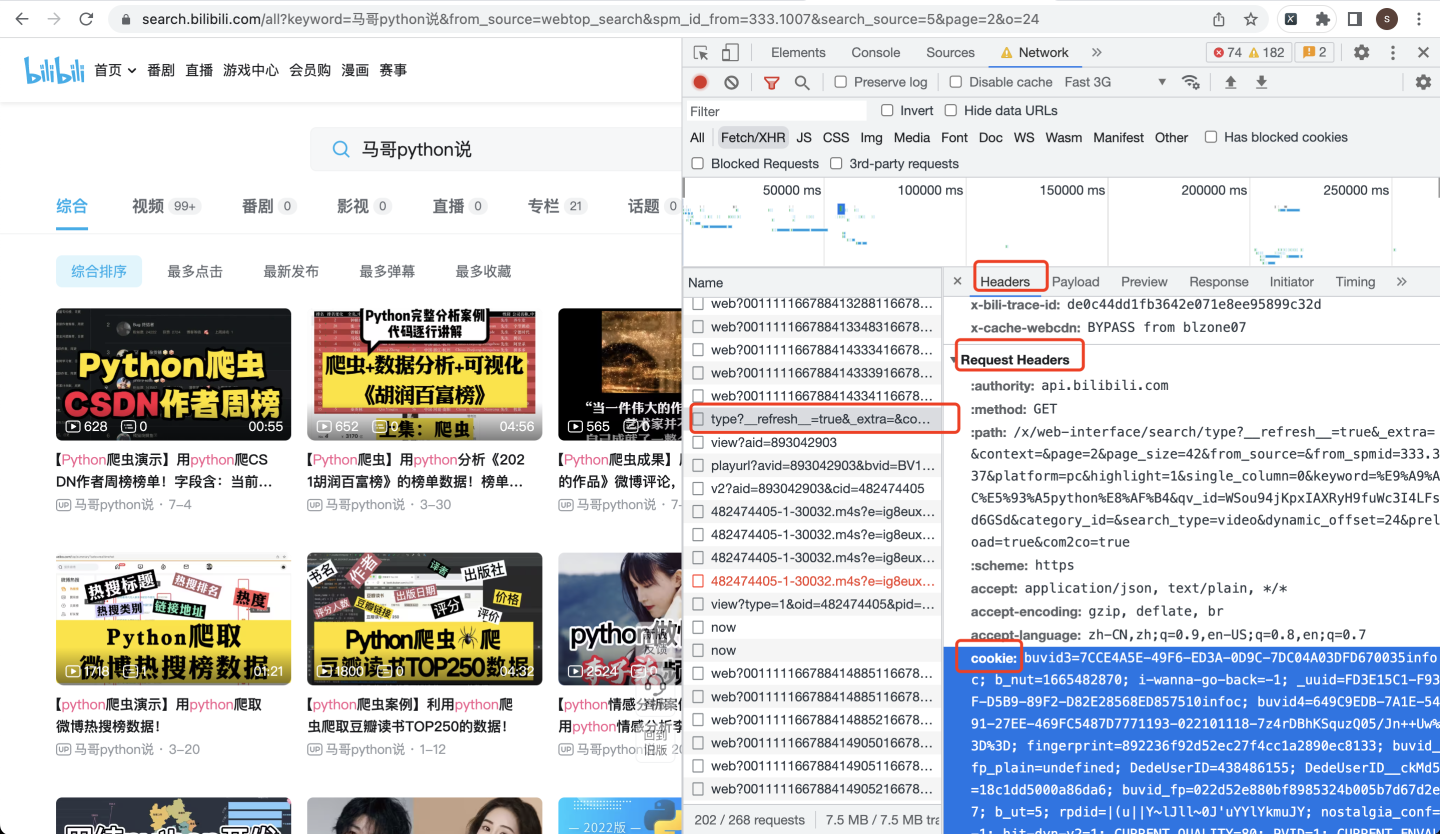
注意!cookie很重要,如果不传入cookie这个参数,会返回412错误码!
请求头代码:
# 请求头
headers = {'accept': 'application/json, text/plain, */*',
'accept-encoding': 'gzip, deflate, br',
'accept-language': 'zh-CN,zh;q=0.9,en-US;q=0.8,en;q=0.7',
# cookie必需,否则返回412
'cookie': "换成自己的cookie",
'origin': 'https://search.bilibili.com',
'referer': 'https://search.bilibili.com/all?keyword={}&from_source=webtop_search&spm_id_from=333.1007&search_source=5&page=2&o=24'.format(
v_keyword),
'sec-ch-ua': '"Google Chrome";v="107", "Chromium";v="107", "Not=A?Brand";v="24"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform ': '"macOS"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
发送请求:
# 向页面发送请求
r = requests.get(url, headers=headers, params=params)
print(r.status_code) # 查看响应码
解析出result列表数据:
data_list = j_data['data']['result']
print('数据长度:', len(data_list))
定义空列表,并for循环追加数据,以视频标题title为例:
for data in data_list:
title = re.compile(r'<[^>]+>', re.S).sub('', data['title']) # 正则表达式清洗文本
print('视频标题: ' + title)
title_list.append(title)
其他字段同理,不再赘述。
最后通过pandas的to_csv,保存最终数据。
# 数据保存到csv文件
df.to_csv(v_out_file, encoding='utf_8_sig', mode='a+', index=False, header=header)
to_csv的时候需加上选项(encoding='utf_8_sig'),否则存入数据会产生乱码,尤其是windows用户!
三、同步讲解视频
讲解视频:https://www.bilibili.com/video/BV1MG4y1f7Sx
四、完整源码
附完整源码:公众号"老男孩的平凡之路"后台回复"爬B站搜索"即可获取。
原创作者: 马哥python说 持续分享python干货中!
【Python爬虫案例】用python爬1000条哔哩哔哩搜索结果的更多相关文章
- python爬虫Scrapy(一)-我爬了boss数据
一.概述 学习python有一段时间了,最近了解了下Python的入门爬虫框架Scrapy,参考了文章Python爬虫框架Scrapy入门.本篇文章属于初学经验记录,比较简单,适合刚学习爬虫的小伙伴. ...
- 转 Python爬虫实战一之爬取糗事百科段子
静觅 » Python爬虫实战一之爬取糗事百科段子 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把,这次我们尝试一下用爬虫把他们抓取下来. 友情提示 糗事百科在前一段时间进行了改版,导致 ...
- Python爬虫实战二之爬取百度贴吧帖子
大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 前言 亲爱的们,教程比较旧了,百度贴吧页面可能改版,可能代码不 ...
- Python爬虫实战一之爬取糗事百科段子
大家好,前面入门已经说了那么多基础知识了,下面我们做几个实战项目来挑战一下吧.那么这次为大家带来,Python爬取糗事百科的小段子的例子. 首先,糗事百科大家都听说过吧?糗友们发的搞笑的段子一抓一大把 ...
- 转 Python爬虫实战二之爬取百度贴吧帖子
静觅 » Python爬虫实战二之爬取百度贴吧帖子 大家好,上次我们实验了爬取了糗事百科的段子,那么这次我们来尝试一下爬取百度贴吧的帖子.与上一篇不同的是,这次我们需要用到文件的相关操作. 本篇目标 ...
- python爬虫学习01--电子书爬取
python爬虫学习01--电子书爬取 1.获取网页信息 import requests #导入requests库 ''' 获取网页信息 ''' if __name__ == '__main__': ...
- python爬虫:了解JS加密爬取网易云音乐
python爬虫:了解JS加密爬取网易云音乐 前言 大家好,我是"持之以恒_liu",之所以起这个名字,就是希望我自己无论做什么事,只要一开始选择了,那么就要坚持到底,不管结果如何 ...
- Python爬虫:为什么你爬取不到网页数据
前言: 之前小编写了一篇关于爬虫为什么爬取不到数据文章(文章链接为:Python爬虫经常爬不到数据,或许你可以看一下小编的这篇文章), 但是当时小编也是胡乱编写的,其实里面有很多问题的,现在小编重新发 ...
- python爬虫27 | 当Python遇到MongoDB的时候,存储av女优的数据变得如此顺滑爽~
上次 我们知道了怎么操作 MySQL 数据库 python爬虫26 | 把数据爬取下来之后就存储到你的MySQL数据库. MySQL 有些年头了 开源又成熟又牛逼 所以现在很多企业都在使用 MySQL ...
- python爬虫-基础入门-python爬虫突破封锁
python爬虫-基础入门-python爬虫突破封锁 >> 相关概念 >> request概念:是从客户端向服务器发出请求,包括用户提交的信息及客户端的一些信息.客户端可通过H ...
随机推荐
- Linux开启SSH连接
1. 查看是否安装 openssh-server:yum list installed | grep openssh-server 已安装成功,如下图 2.如果没有任何输出显示表示没有安装openss ...
- Spring Cloud 服务的注册与发现之eureka客户端注册
1.在客户端maven项目中添加eureka客户端依赖 <dependency> <groupId>org.springframework.cloud</groupId& ...
- KingbaseES V8R3 备份恢复案例 -- sys_rman物理备份异机恢复
案例说明: 在生产环境通过sys_rman执行了物理备份后,需要在异机构建测试环境,本案例描述了通过物理备份异机恢复的详细过程及操作. 适用版本: KingbaseES V8R3 节点信息: [kin ...
- KingabseES执行计划-分区剪枝(partition pruning)
概述 分区修剪(Partition Pruning)是分区表性能的查询优化技术 .在分区修剪中,优化器分析SQL语句中的FROM和WHERE子句,以在构建分区访问列表时消除不需要的分区.此功能使数据库 ...
- Lab1:Xv6 and Unix utilities
Sleep功能 通过接受时间参数,调用system_call 指令 sleep实现该功能 #include "kernel/types.h" #include "kern ...
- archlinux开机出现错误Dependency failed for /home. Dependency failed for Local File System Time outwaiting for device /dev/disk/...
错误如下 Dependency failed for /home. Dependency failed for Local File System Time outwaiting for device ...
- #KMP,dp#洛谷 3426 [POI2005]SZA-Template
题目 给定一个字符串\(S\),字符串可以理解成一条每个字母代表一种颜色的线段, 找到一个长度最小的串\(T\),使得在若干位置放置\(T\)后使得字符串被完全覆盖 分析 显然它要么取\(i\),要么 ...
- OpenHarmony创新赛人气投票活动,最佳人气作品由你来定!
12月1日至12月15日 十大入围作品线上投票激战正酣 最佳人气作品,由你来定! 投票链接:https://forums.openharmony.cn/forum.php?mod=viewth ...
- 三步就能在OpenHarmony中实现车牌识别
介绍 本车牌识别项目是基于开源项目 EasyPR(Easy to do Plate Recognition)实现.EasyPR 是一个开源的中文车牌识别系统,基于 OpenCV 开源库开发. 本项目使 ...
- C# 字符串操作指南:长度、连接、插值、特殊字符和实用方法
字符串用于存储文本.一个字符串变量包含由双引号括起的字符集合 示例: // 创建一个string类型的变量并赋予一个值 string greeting = "Hello"; 如果需 ...