深度学习(五)——DatadLoader的使用
一、DataLoader简介
官网地址:
1. DataLoder类
class torch.utils.data.DataLoader(dataset, batch_size=1, shuffle=None, sampler=None, batch_sampler=None, num_workers=0, collate_fn=None, pin_memory=False, drop_last=False, timeout=0, worker_init_fn=None, multiprocessing_context=None, generator=None, *, prefetch_factor=None, persistent_workers=False, pin_memory_device='')
由此可见,DataLoder必须需要输入的参数只有\(dataset\)。
2. 参数说明
dataset(Dataset): 数据集的储存的路径位置等信息
batch_size(int): 每次取数据的数量,比如batchi_size=2,那么每次取2条数据
shuffle(bool): True: 打乱数据(可以理解为打牌中洗牌的过程); False: 不打乱。默认为False
num_workers(int): 加载数据的进程,多进程会更快。默认为0,即用主进程进行加载。但在windows系统下,num_workers如果非0,可能会出现 BrokenPipeError[Error 32] 错误
drop_last(bool): 比如我们从100条数据中每次取3条,到最后会余下1条,如果drop_last=True,那么这条数据会被舍弃(即只要前面99条数据);如果为False,则保留这条数据
二、DataLoader实操
- 数据集仍然采用上一篇的CIFAR10数据集
1. DataLoader取数据的逻辑
首先import dataset,dataset会返回一个数据的img和target
然后import dataloder,并设置\(batch\_size\),比如\(batch\_size=4\),那么dataloder会获取这些数据:dataset[0]=img0, target0; dataset[1]=img1, target1; dataset[2]=img2, target2; dataset[3]=img3, target3. 并分别将其中的4个img和4个target进行打包,并返回打包好的imgs和targets
比如下面这串代码:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
这里的test_loader会取出test_data[0]、test_data[1]、test_data[2]、test_data[3]的img和target,并分别打包。返回两个参数:打包好的imgs,打包好的taregts
2. 如何取出DataLoader中打包好的img、target数据
(1)输出打包好的img、target
代码示例如下:
import torchvision
from torch.utils.data import DataLoader
#测试集,并将PIL数据转化为tensor类型
test_data=torchvision.datasets.CIFAR10("./dataset",train=False,transform=torchvision.transforms.ToTensor())
#batch_size=4:每次从test_data中取4个数据集并打包
test_loader=DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
#测试数据集中第一章图片及target
img, target=test_data[0]
print(img.shape)
print(target)
#取出test_loader中的图片
for data in test_loader:
imgs,targets = data
print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
在11行处debug一下可以发现,test_loader中有个叫sampler的采样器,采取的是随机采样的方式,也就是说这batch_size=4时,每次抓取的4张图片都是随机抓取的。
(2)展示图片
用tensorboard就可以可视化了,具体操作改一下上面代码最后的for循环就好了
from torch.utils.tensorboard import SummaryWriter
writer=SummaryWriter("dataloder")
step=0 #tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("test_data",imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
(3)关于shuffle的理解
- 可以理解为一个for循环就是打一次牌,打完一轮牌后,若shuffle=False,那么下一轮每一步抓到的牌都会跟上一轮相同;如果shuffle=True,那么就会进行洗牌,打乱牌的顺序后,下一轮每一步跟上一轮的会有不同。
首先将shuffle设置为False:
test_loader=DataLoader(dataset=test_data, batch_size=64, shuffle=True, num_workers=0, drop_last=False)
然后对(2)的代码进行修改,运行代码:
for epoch in range(2): #假设打两次牌,我们来观察两次牌中间的洗牌情况
step = 0 # tensorboard步长参数
for data in test_loader:
imgs,targets = data
# print(imgs.shape) #[Run] torch.Size([4, 3, 32, 32]) 4张图片打包,3通道,32×32
# print(targets) #[Run] tensor([3, 5, 2, 7]) 4张图,每张图片对应的标签分别是3,5,2,7(某一次print的举例,每次print结果不太一样)
writer.add_images("Epoch: {}".format(epoch),imgs,step) #注意这里是add_images,不是add_image。因为这里是加入了64张图
step=step+1
writer.close()
结果显示,未洗牌时运行的结果是一样的:
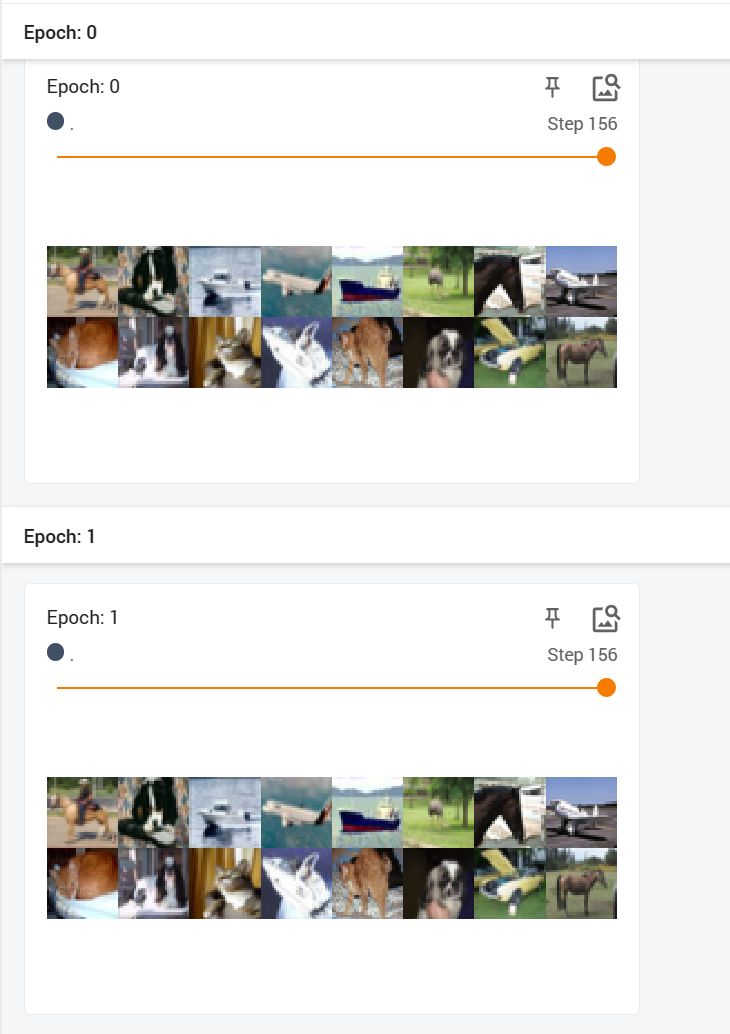
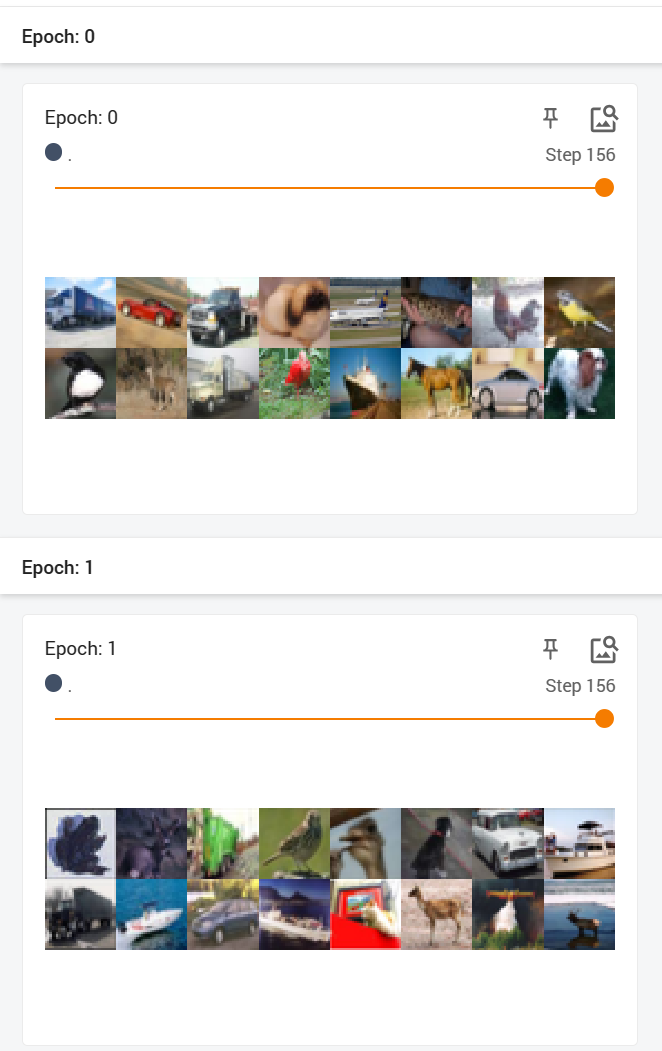
- 将shuffle设置为True,再次运行,可以发现两次结果还是不一样的:
深度学习(五)——DatadLoader的使用的更多相关文章
- go微服务框架go-micro深度学习(五) stream 调用过程详解
上一篇写了一下rpc调用过程的实现方式,简单来说就是服务端把实现了接口的结构体对象进行反射,抽取方法,签名,保存,客户端调用的时候go-micro封请求数据,服务端接收到请求时,找到需要调用调 ...
- 深度学习菜鸟的信仰地︱Supervessel超能云服务器、深度学习环境全配置
并非广告~实在是太良心了,所以费时间给他们点赞一下~ SuperVessel云平台是IBM中国研究院和中国系统与技术中心基于POWER架构和OpenStack技术共同构建的, 支持开发者远程开发的免费 ...
- go微服务框架go-micro深度学习-目录
go微服务框架go-micro深度学习(一) 整体架构介绍 go微服务框架go-micro深度学习(二) 入门例子 go微服务框架go-micro深度学习(三) Registry服务的注册和发现 go ...
- 推荐系统遇上深度学习(十)--GBDT+LR融合方案实战
推荐系统遇上深度学习(十)--GBDT+LR融合方案实战 0.8012018.05.19 16:17:18字数 2068阅读 22568 推荐系统遇上深度学习系列:推荐系统遇上深度学习(一)--FM模 ...
- Deep Learning(深度学习)学习笔记整理系列之(五)
Deep Learning(深度学习)学习笔记整理系列 zouxy09@qq.com http://blog.csdn.net/zouxy09 作者:Zouxy version 1.0 2013-04 ...
- 深度学习课程笔记(十五)Recurrent Neural Network
深度学习课程笔记(十五)Recurrent Neural Network 2018-08-07 18:55:12 This video tutorial can be found from: Yout ...
- 深度学习课程笔记(五)Ensemble
深度学习课程笔记(五)Ensemble 2017.10.06 材料来自: 首先提到的是 Bagging 的方法: 我们可以利用这里的 Bagging 的方法,结合多个强分类器,来提升总的结果.例如: ...
- 深度学习(五)基于tensorflow实现简单卷积神经网络Lenet5
原文作者:aircraft 原文地址:https://www.cnblogs.com/DOMLX/p/8954892.html 参考博客:https://blog.csdn.net/u01287127 ...
- UFLDL深度学习笔记 (五)自编码线性解码器
UFLDL深度学习笔记 (五)自编码线性解码器 1. 基本问题 在第一篇 UFLDL深度学习笔记 (一)基本知识与稀疏自编码中讨论了激活函数为\(sigmoid\)函数的系数自编码网络,本文要讨论&q ...
- 深度学习论文翻译解析(五):Siamese Neural Networks for One-shot Image Recognition
论文标题:Siamese Neural Networks for One-shot Image Recognition 论文作者: Gregory Koch Richard Zemel Rusla ...
随机推荐
- 【Spring】SpringSecurity的使用
4 SpringSecurity 只需要协助SpringSecurity创建好用户对应的角色和权限组,同时把各个资源所要求的权限信息设定好,剩下的像 "登录验证"."权限 ...
- CSS6大种选择器
一.常用的css基本选择器(4种) 1.标签选择器 结构: 标签名{css属性名:属性值}作用:通过标签名,找到页面中所有的这类标签,设置样式 注意:1.标签选择器选择的是一类标签,而不是单独的一个2 ...
- 2020-08-13:Hadoop生态圈的了解?
福哥答案2020-08-13: 该项目包括以下模块:1.Common(公共工具)支持其他Hadoop模块的公共工具. 2.HDFS(Hadoop分布式文件系统)提供对应用程序数据的高吞吐量访问的分布式 ...
- 2022-08-03:以下go语言代码输出什么?A:2;B:3;C:1;D:0。 package main import “fmt“ func main() { slice := []i
2022-08-03:以下go语言代码输出什么?A:2:B:3:C:1:D:0. package main import "fmt" func main() { slice := ...
- 2022-02-21:不含连续1的非负整数。 给定一个正整数 n ,返回范围在 [0, n] 都非负整数中,其二进制表示不包含 连续的 1 的个数。 输入: n = 5 输出: 5 解释: 下面是带
2022-02-21:不含连续1的非负整数. 给定一个正整数 n ,返回范围在 [0, n] 都非负整数中,其二进制表示不包含 连续的 1 的个数. 输入: n = 5 输出: 5 解释: 下面是带有 ...
- 2021-11-13:至少有 K 个重复字符的最长子串。给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k 。返回这一子串的长度。提示:1
2021-11-13:至少有 K 个重复字符的最长子串.给你一个字符串 s 和一个整数 k ,请你找出 s 中的最长子串, 要求该子串中的每一字符出现次数都不少于 k .返回这一子串的长度.提示:1 ...
- ModuleNotFoundError: No module named 'flask_mail'
ModuleNotFoundError: No module named 'flask_mail' 解决: pip install flask_mail
- ES6迭代器(Iterator)和生成器(Generator)
平时我们迭代数据用得最多的应该就是for循环了 来看个简单的例子 var colors = ["red", "green", "blue"] ...
- 用go封装一下封禁功能
用go封装一下封禁功能 本篇为用go设计开发一个自己的轻量级登录库/框架吧 - 秋玻 - 博客园 (cnblogs.com)的封禁业务篇,会讲讲封禁业务的实现,给库/框架增加新的功能. 源码:http ...
- web自动化07-元素等待
元素等待 1.什么是元素等待? 在定位页面元素时如果没找到,会在指定时间内一直等待的过程 2.为什么需要元素等待 网络速度慢 电脑配置低 服务器处理请求慢 3.三种元素等 ...