FBNet/FBNetV2/FBNetV3:Facebook在NAS领域的轻量级网络探索 | 轻量级网络
FBNet系列是完全基于NAS方法的轻量级网络系列,分析当前搜索方法的缺点,逐步增加创新性改进,FBNet结合了DNAS和资源约束,FBNetV2加入了channel和输入分辨率的搜索,FBNetV3则是使用准确率预测来进行快速的网络结构搜索
来源:晓飞的算法工程笔记 公众号
FBNet
论文: FBNet: Hardware-Aware Efficient ConvNet Design via Differentiable Neural Architecture Search | CVPR 2019

Introduction
近期卷积网络的设计除了注重准确率之外,还需要兼顾运行性能,特别是在移动设备上的运行性能,这使得卷积神经网络的设计变得更加难,主要有以下难点:
- Intractable design space,由于卷积网络参数很多,导致设计空间十分复杂,目前很多方法提出自动化搜索,能够简化人工设计的流程,但这种方法一般需要大量的算力。
- Nontransferable optimality,卷积网络的性能取决于很多因素,比如输入分辨率和目标设备,不同的分辨率需要调整不同的网络参数,而相同block在不同的设备上的效率也可能大不相同,所以需要对网络在特定的条件下进行特定的调优。
- Inconsistent efficiency metrics,大多数效率指标不仅与网络结构相关,也和目标设备上的软硬件设置有关。为了简化,很多研究都采用硬件无关的指标来表示卷积的效率,比如FLOPs,但FLOPs并不能总等同于性能,还跟block的实现方式相关,这使得网络的设计更加困难。
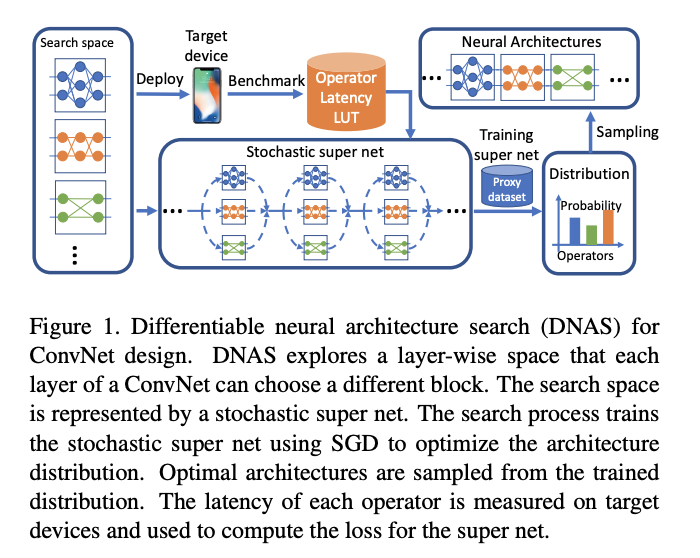
为了解决以上问题,论文提出FBNet,使用可微神经网络搜索(DNAS)来发现硬件相关的轻量级卷积网络,流程如图1所示。DNAS方法将整体的搜索空间表示为超网,将寻找最优网络结构问题转换为寻找最优的候选block分布,通过梯度下降来训练block的分布,而且可以为网络每层选择不同的block。为了更好的估计网络的时延,预先测量并记录了每个候选block的实际时延,在估算时直接根据网络结构和对应的时延累计即可。
Method
DNAS将网络结构搜索问题公式化为:
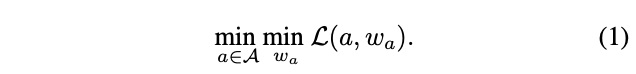
给定结构空间\(\mathcal{A}\),寻找最优的结构\(a\in \mathcal{A}\),在训练好权值\(w_a\)后,可以满足最小化损失\(\mathcal{L}(a, w_a)\),论文主要集中于3个因素:搜索空间\(\mathcal{A}\)、考虑实际时延的损失函数\(\mathcal{L}(a, w_a)\)以及高效的搜索算法。
The Search Space
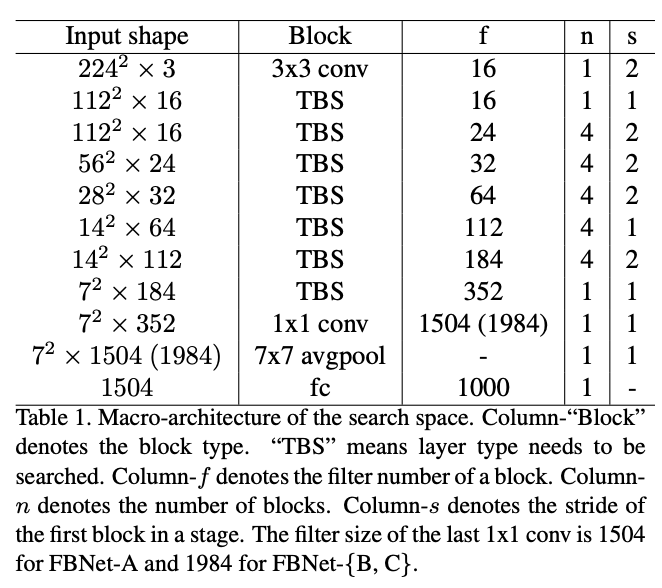
之前的方法大都搜索单元结构,然后堆叠成完整的网络,但实际上,相同的单元结构在不同的层对网络的准确率和时延的影响是大不相同的。为此,论文构造了整体网络结构(macro-architecture)固定的layer-wise搜索空间,每层可以选择不同结构的block,整体网络结构如表1所示,前一层和后三层的结构是固定的,其余层的结构需要进行搜索。前面的层由于特征分辨率较大,人工设定了较小的核数量以保证网络的轻量性。
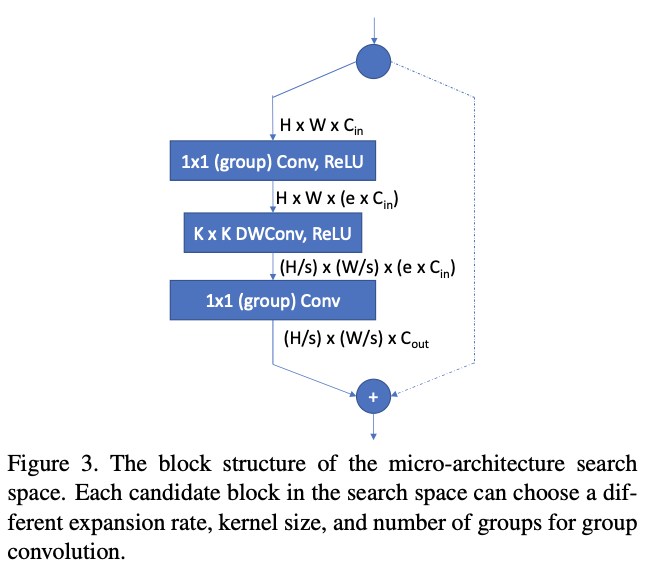
layer-wise搜索空间如图3所示,基于MobileNetV2和ShuffleNet的经典结构设计,通过设定不同的卷积核大小\(K\)(3或5)、扩展率\(e\)以及分组数来构造成不同的候选block。若block的输入和输出分辨率一致,则添加element-wise的shortcut,而若使用了分组卷积,则需要对卷积输出进行channel shuffle。
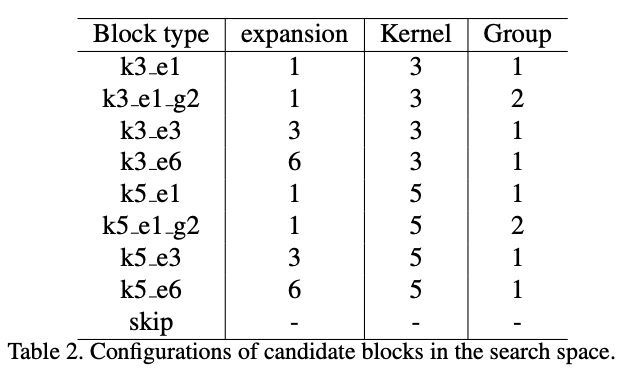
论文的实验包含9种候选block,每种block的超参数如表2所示。另外,还有skip结构,直接映射输入到输出,用来缩短整体网络的深度。总体而言,整体网络包含22个需要搜索的层,每层从9个候选block中选择,共有\(9^{22}\)种可能的结构。
Latency-Aware Loss Function
公式1中的损失函数不仅要反映准确率,也要反应目标硬件上的时延。因此,定义以下损失函数:
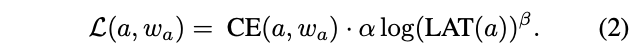
\(CE(a, w_a)\)表示交叉熵损失,\(LAT(a)\)表示当前结构在目标硬件上的时延,\(\alpha\)控制整体损失函数的幅值,\(\beta\)调整时延项的幅值。时延的计算可能比较耗时,论文使用block的时延lookup表格来估计网络的的整体:
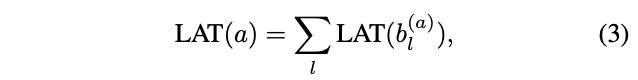
\(b^{(a)}_l\)为结构\(a\)中\(l\)层的block,这种估计方法假设block间的计算相互独立,对CPUs和DSPs等串行计算设备有效,通过这种方法,能够快速估计\(10^{21}\)种网络的实际时延。
The Search Algorithm
论文将搜索空间表示为随机超网,超网为表1整体结构,每层包含9个表2的并行block。在推理的时候,候选block被执行的概率为:
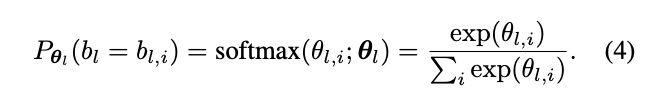
\(\theta_l\)包含决定\(l\)层每个候选block采样概率的参数,\(l\)层的输出可表示为:
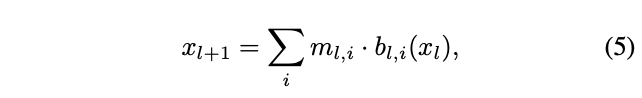
\(m_{l,i}\)是\(\{0, 1\}\)随机变量,根据采样概率随机赋值,层输出为所有block的输出之和。因此,网络结构\(a\)的采样概率可表示为:
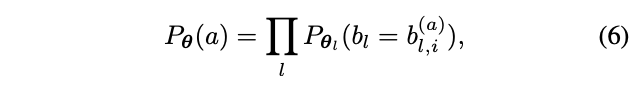
\(\theta\)包含所有block的\(\theta_{l,i}\),基于上面的定义,可以将公式1的离散优化问题转换为:
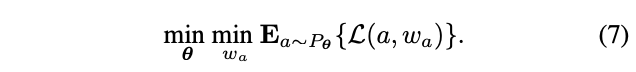
这样,权值\(w_a\)是可导的,但\(\theta\)仍然不可导,因为\(m_{l,i}\)的定义是离散的,为此将\(m_{l,i}\)的生成方法转换为Gumbel Softmax:
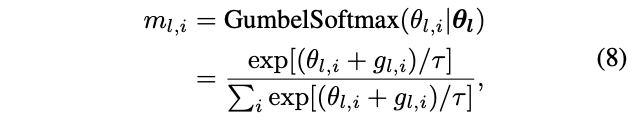
\(g_{l,i} \sim Gumbel(0,1)\)为Gumbel分布的随机噪声,\(\tau\)为温度参数。当\(\tau\)接近0时,\(m_{l,i}\)类似于one-shot,当\(\tau\)越大时,\(m_{l,i}\)类似于连续随机变量。这样,公式2的交叉熵损失就可以对\(w_a\)和\(\theta\)求导,而时延项\(LAT\)也可以改写为:
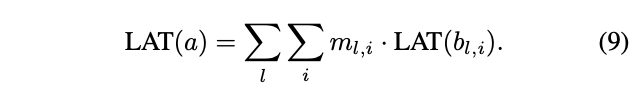
由于使用lookup表格,所以\(LAT(b_{l,i})\)是个常量因子,网络\(a\)的整体时延对\(m_{l,i}\)和\(\theta_{l,i}\)也是可导的。至此,损失函数对权值\(w_a\)和结构变量\(\theta\)都是可导的,可以使用SGD来高效优化损失函数。
搜索过程等同于随机超网的训练过程,在训练时,计算\(\partial\mathcal{L}/\partial w_a\)更新超网每个block的权值,在block训练后,每个block对准确率和时延的贡献不同,计算\(\partial\mathcal{L}/\partial \theta\)来更新每个block的采样概率\(P_{\theta}\)。在超网训练完后,通过采样网络分布\(P_{\theta}\)得到最优的网络结构。
Experiments
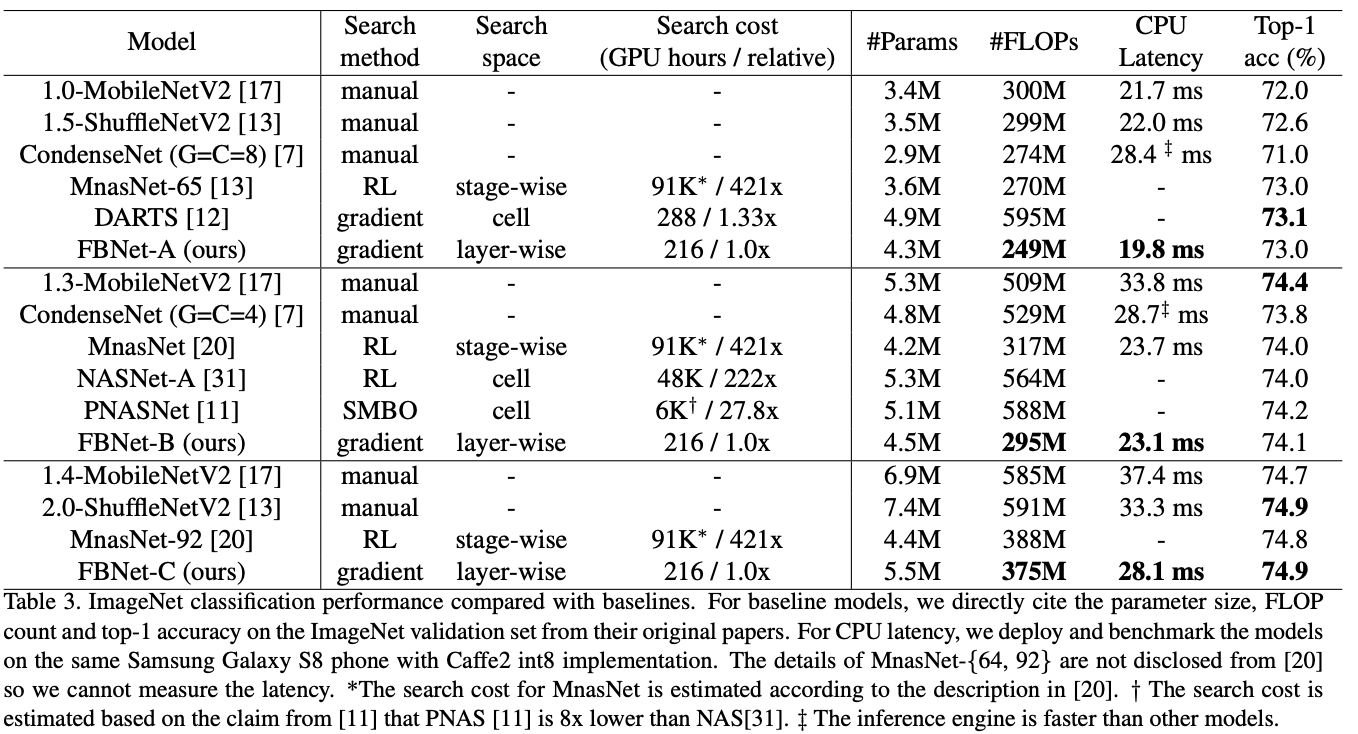
与各轻量级网络对比在ImageNet上的性能对比。
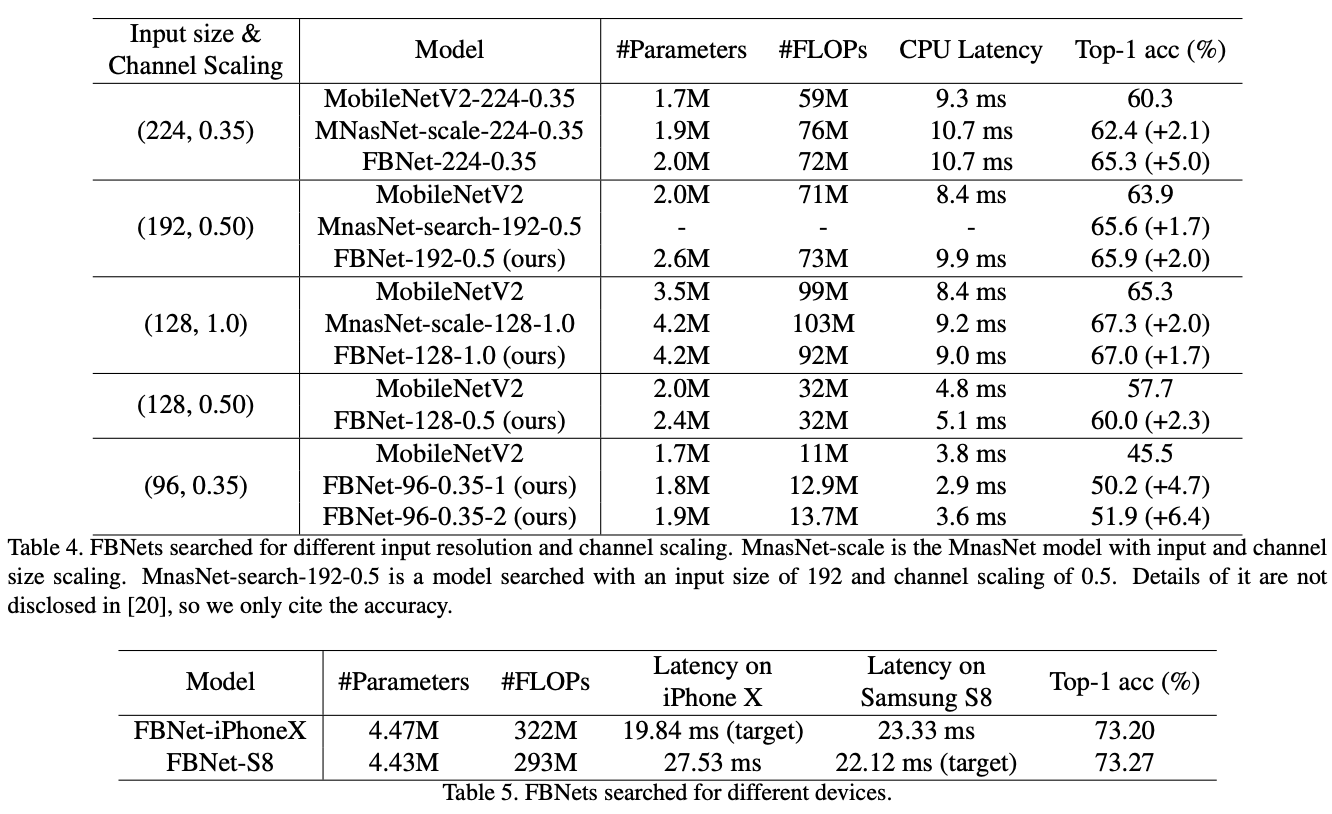
特定资源和设备条件下的性能对比。
Conclustion
论文提出一种可微的神经网络搜索方法,将离散的单元结构选择转换为连续的单元结构概率分布,另外将目标设备时延加入到优化过程中,结合超网的权值共享,能够快速地端到端地生成特定条件下的高性能轻量化网络。不过论文的block框架基于目前主流MobileNetV2和ShuffleNet设计,更多地是对其结构参数进行搜索,所以在网络结构有一定的束缚。
FBNetV2
论文: FBNetV2: Differentiable Neural Architecture Search for Spatial and Channel Dimensions | CVPR 2020

Introduction
DNAS通过训练包含所有候选网络的超网来采样最优的子网,虽然搜索速度快,但需要耗费大量的内存,所以搜索空间一般比其它方法要小,且内存消耗和计算量消耗随搜索维度线性增加。
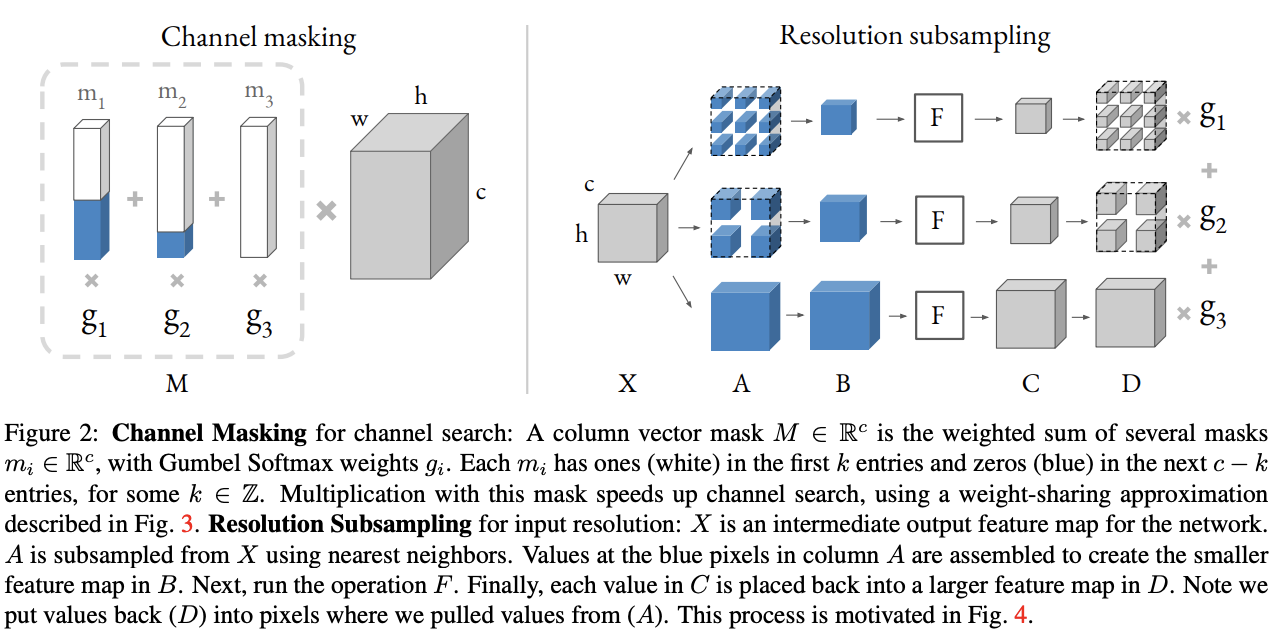
为了解决这个问题,论文提出DMaskingNAS,将channel数和输入分辨率分别以mask和采样的方式加入到超网中,在带来少量内存和计算量的情况下,大幅增加\(10^{14}\)倍搜索空间。
Channel Search
DNAS一般将候选block都实例化在超网中,在训练过程中对候选block进行选择,直接将channel维度加入到搜索空间会增加会增加大量的内存以及计算量。
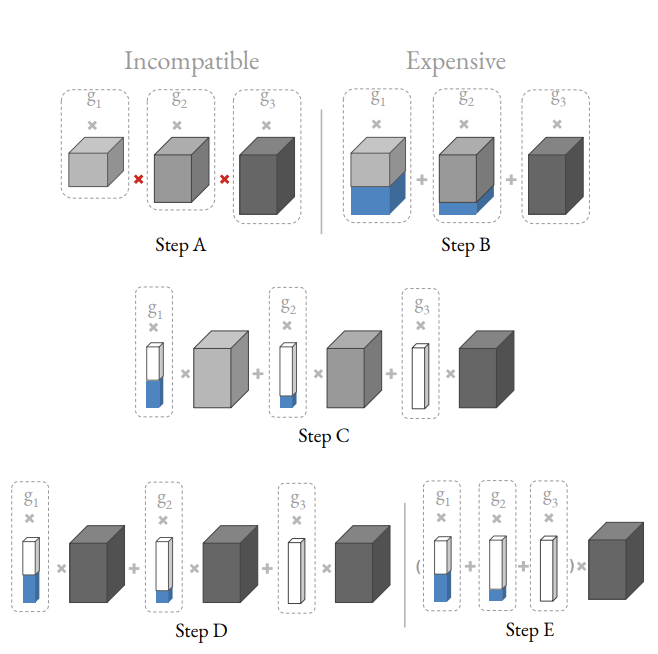
常规的实现方法如Step A,将不同大小的卷积都实例化,为了使得不同维度卷积的输出可以融合,对维度较小的特征进行Step B的zero padding。Step B可转换成如Step C,3个卷积输出一样大小的特征,再用3个不同的mask对输出进行mask(蓝色为0,白色为1)。由于Step C的3个卷积大小和输入都一样,可以用一个权值共享卷积进行实现,即Step D。将Step D的mask先合并,再与卷积输出相乘,这样可以省计算量和内存,最终得到Step E,仅需要1次卷积和1份特征图即可。
Input Resolution Search
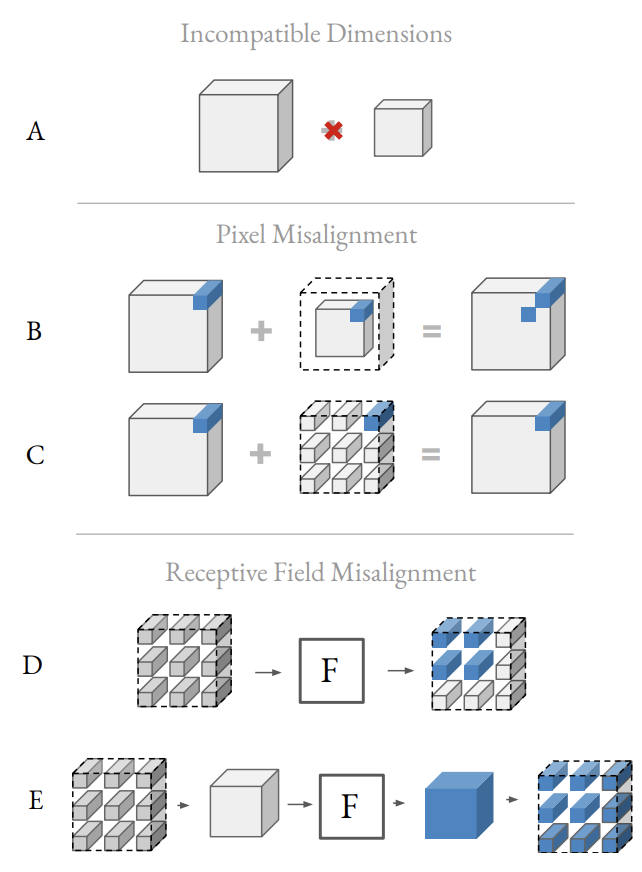
跟channel加入搜索空间类似,输入分辨率,DNAS的实现方式也是为每个不同输入分辨率实例化所有的层,这样会增加成倍的计算量和内存,还有一些难以避免的问题:
- 特征输出无法融合。输入分辨率不同的block的输出大小不同,如图A,不能进行直接的融合。一般可进行如图B的zero padding解决大小一致问题,但这会造成像素不对齐的问题,所以采用图C的Interspersing zero-padding采样方法(最近邻+zero-padding)来避免像素不对齐以及像素污染。
- 采样的特征图导致感受域减小。如图D,假设F为\(3\times 3\)卷积,采样后的特征图导致单次卷积只覆盖了\(2\times 2\)的有效输入,所以在进行卷积操作前需对采样后的特征图进行压缩,卷积操作完后再扩展恢复,如图E。实际上图E可通过空洞卷积进行实现,即避免了额外的内存申请,也避免了卷积核的修改。
论文在实验部分没有对输入分辨率的配置和搜索过程进行描述,只是展示了实验结果,而作者只开源了搜索得到的网络,没有开源搜索代码。这里猜测应该搜索时使用同一个超网对不同的分辨率输入进行特征提取,然后合并最终输出进行训练,最后取权重最大的分辨率,如图2所示,\(F\)为共用的超网,如果有了解的朋友麻烦告知下。
Experiments
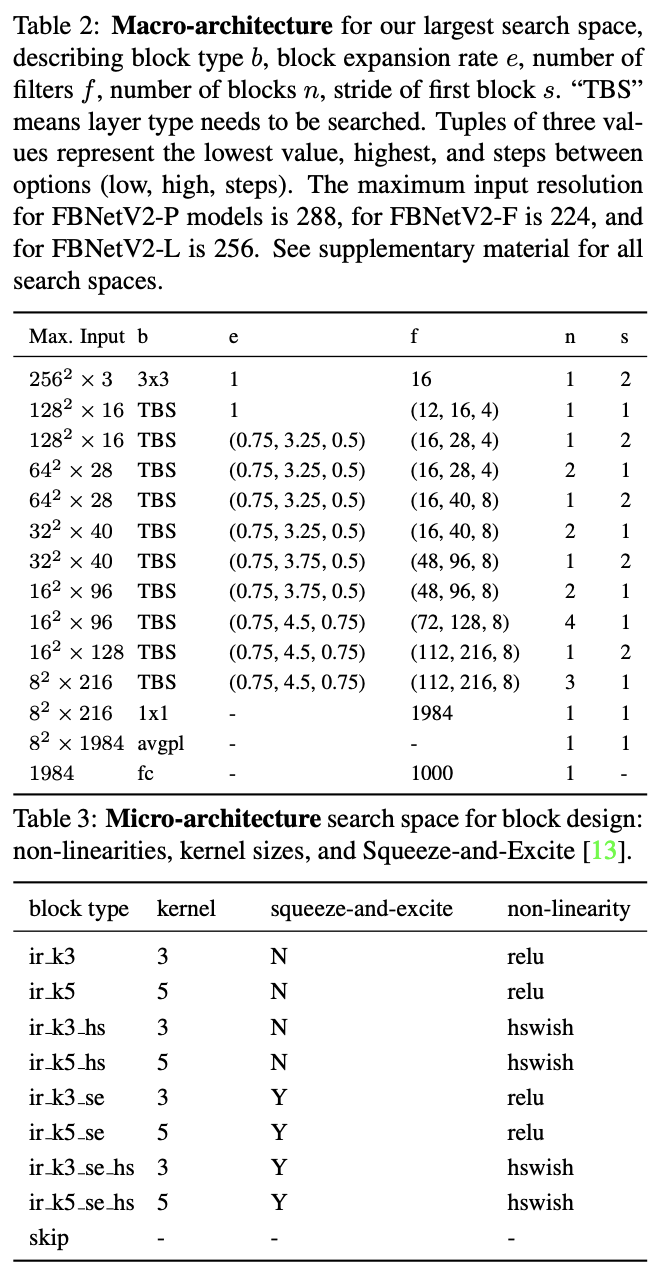
搜索时设定的整体网络结构以及每个候选block,共包含\(10^{35}\)个候选网络。
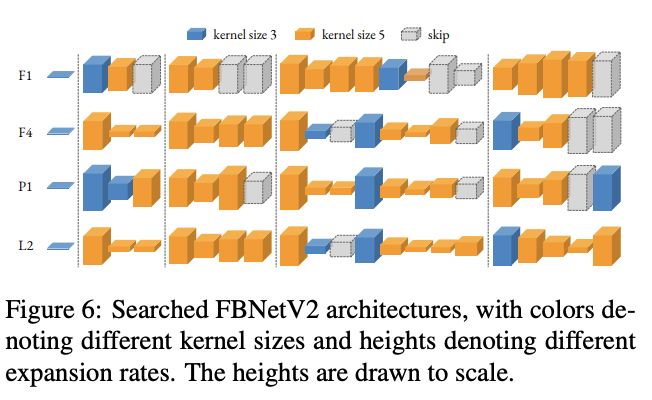
搜索得到的多个FBNetV2网络,每个网络都对应不同的资源需求。
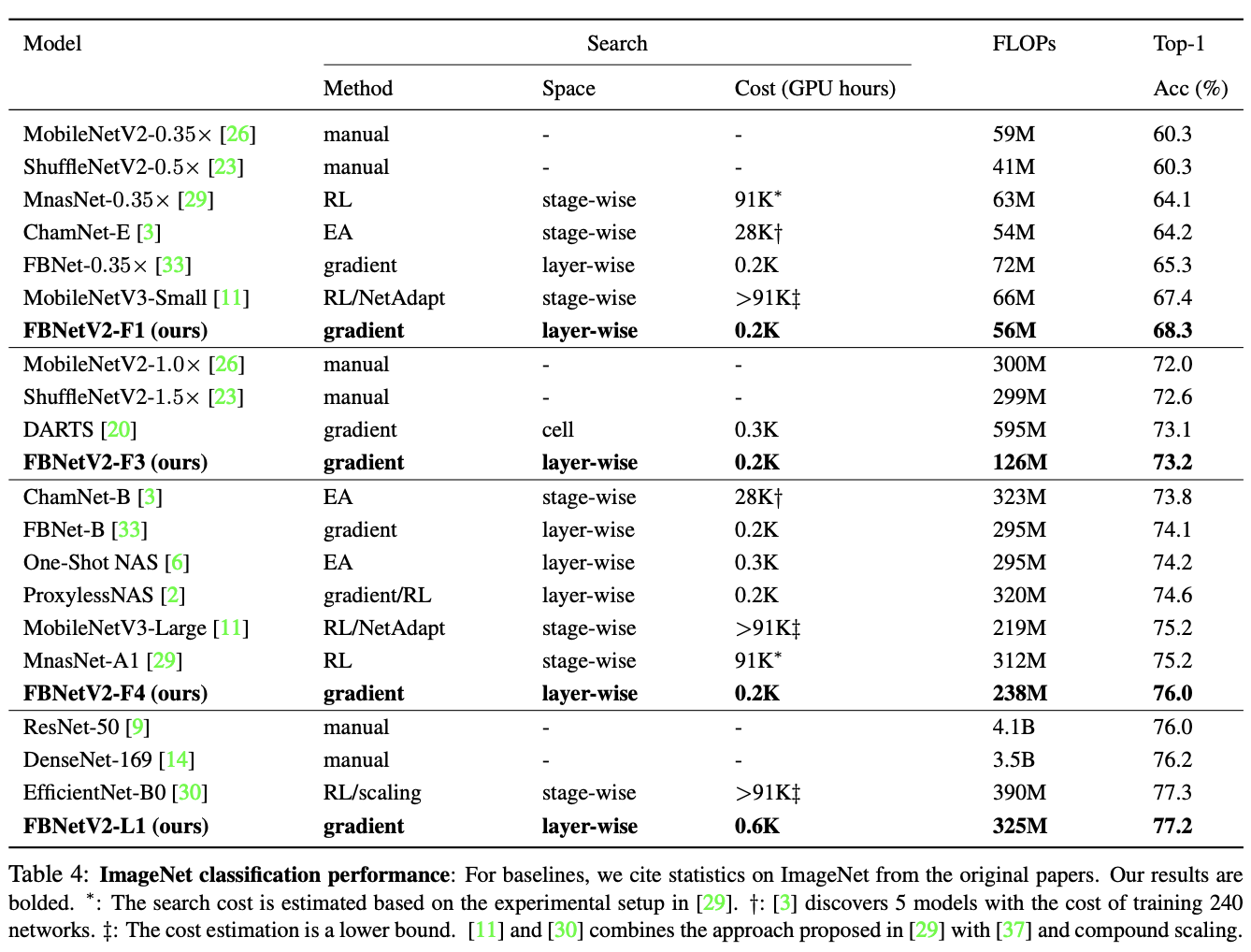
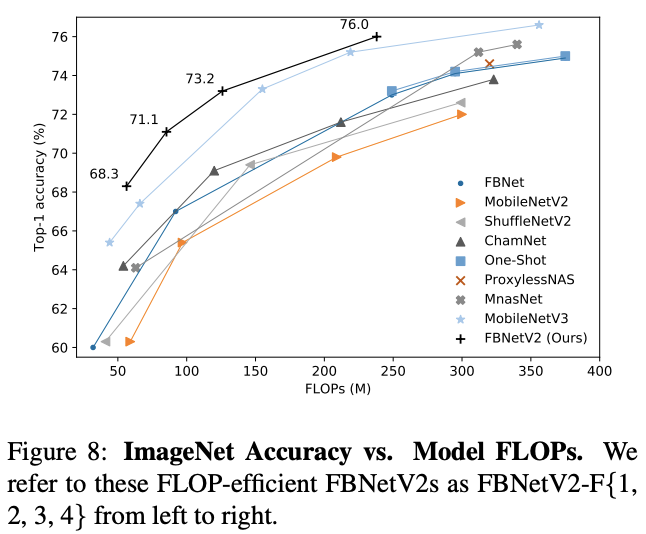
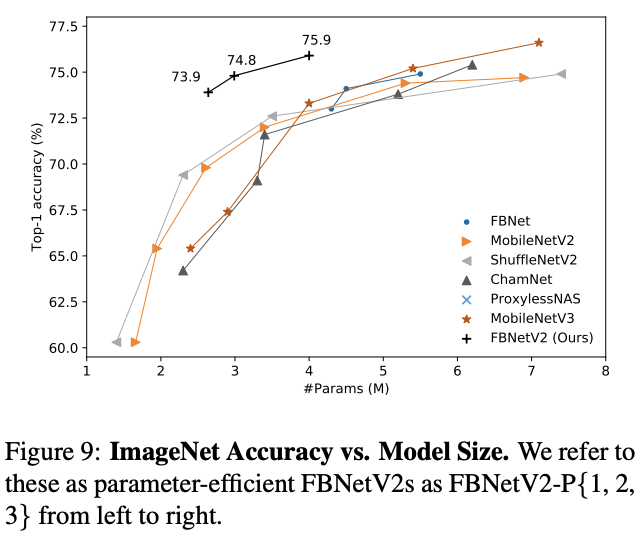
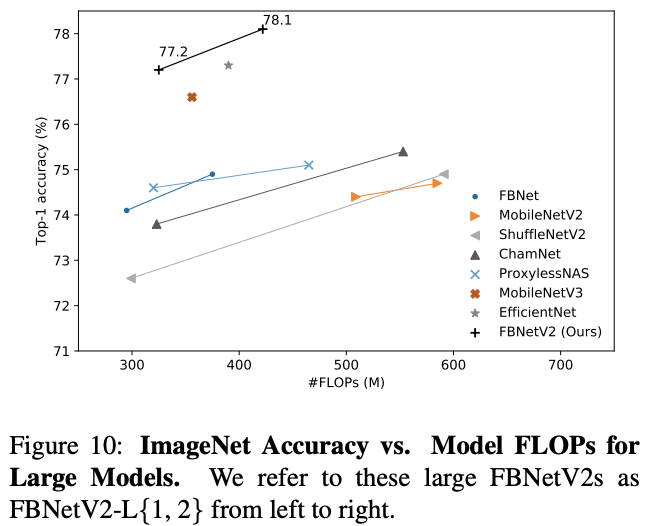
与其它网络的性能对比。
Conclustion
之前提到FBNet的block框架基于目前主流MobileNetV2和ShuffleNet设计,更多地是对其结构参数进行搜索,所以在网络结构有一定的束缚。FBNetV2马上来了个\(10^{14}\)倍的提升,各方面效果也比目前大多数的网络要好,但整体看下来,论文更像一个量化方法,因为基底还是固定为现有网络的结构设计。
FBNetV3
论文: FBNetV3: Joint Architecture-Recipe Search using Neural Acquisition Function

Introduction
FBNetV3目前只放在了arxiv上,论文认为目前的NAS方法大都只满足网络结构的搜索,而没有在意网络性能验证时的训练参数的设置是否合适,这可能导致模型性能下降。为此,论文提出JointNAS,在资源约束的情况下,搜索最准确的训练参数以及网络结构。
JointNAS
JointNAS优化目标可公式化为:
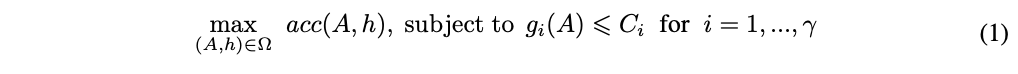
\(A\)、\(h\)和\(\Omega\)分别代表网络结构embedding、训练参数embedding和搜索空间,\(acc\)计算当前结构和训练参数下的准确率,\(g_i\)和\(\gamma\)分别为资源消耗计算和资源数量。

JointNAS的搜索过程如Alg. 1所示,将搜索分为两个阶段:
- 粗粒度阶段(coarse-grained),该阶段主要迭代式地寻找高性能的候选网络结构-超参数对以及训练准确率预测器。
- 细粒度阶段(fine-grained stages),借助粗粒度阶段训练的准确率预测器,对候选网络进行快速的进化算法搜索,该搜索集成了论文提出的超参数优化器AutoTrain。
Coarse-grained search: Constrained iterative optimization
粗粒度搜索生成准确率预测器和一个高性能候选网络集。
Neural Acquisition Function
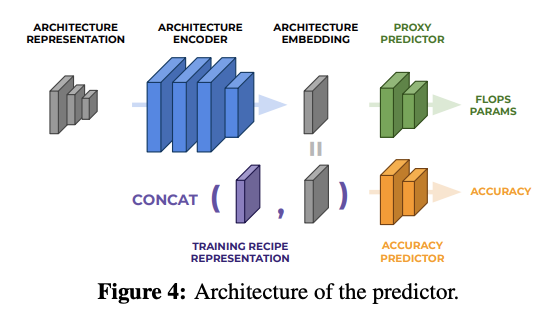
预测器的结构如图4所示,包含一个结构编码器以及两个head,分别为辅助的代理head以及准确率head。代理head预测网络的属性(FLOPs或参数量等),主要在编码器预训练时使用,准确率head根据训练参数以及网络结构预测准确率,使用代理head预训练的编码器在迭代优化过程中进行fine-tuned。
Step 1. Pre-train embedding layer
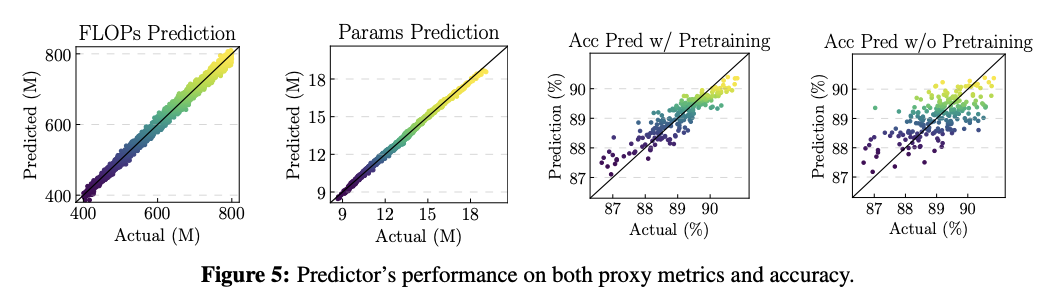
预测器包含一个预训练过程,首先训练模型以网络结构作为输入,预测网络的属性(FLOPs或参数量等),这样的训练数据是很容易获取的,随机生成大量网络并计算其属性即可,然后将编码器共享给准确率head,再正式展开后续的网络搜索中。编码器的预训练能够显著提高预测器的准确率和稳定性,效果如图5所示。
Step 2. Constrained iterative optimization
首先使用拟蒙特卡罗从搜索空间采样网络结构-超参数对,然后迭代地训练预测器:
- 基于预测器结果选择一个batch符合条件的网络结构-超参数对
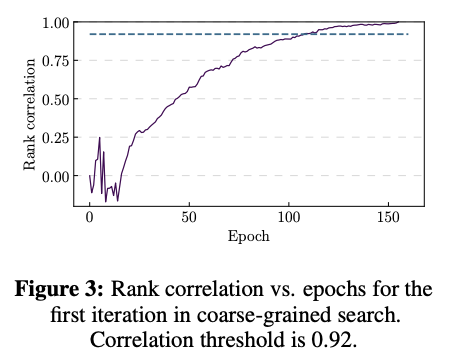
- 训练和测试网络结构-超参数对的准确率,训练采用了早停策略。取第一次迭代的网络的最终准确率以及每个epoch的准确率,绘制每个epoch的网络排名与最终排名相关性曲线,如图3所示,取相关性为0.92的周期作为训练周期。
- 更新预测器,预测器的前50个epoch固定编码器参数,后续采用学习率逐步下降的学习测量。准确率预测head使用Huber loss进行训练,能扛住异常点对模型训练的影响。
这个迭代过程能够减少候选者的数量,避免了不必要的验证,提高探索效率。
Fine-grained search: Predictor-based evolutionary search
第二阶段使用自适应的基因算法,选择第一阶段的最优网络结构-训练参数对作为第一代种群。在每轮迭代中,对种群进行突变产生满足约束的新子群,使用粗粒度阶段训练的预测器来快速预测个体的得分,选择最优的\(K\)个网络结构-训练参数对作为下一代种群。计算当前迭代相对于上一轮迭代的最高得分增长,当增长不够时退出,得到最终的高准确率网络结构以及相应的训练参数。
需要注意,当资源约束改变时,预测器依然可以重复使用,能够快速地使用细粒度阶段搜索到合适的网络结构和训练参数。
Search space
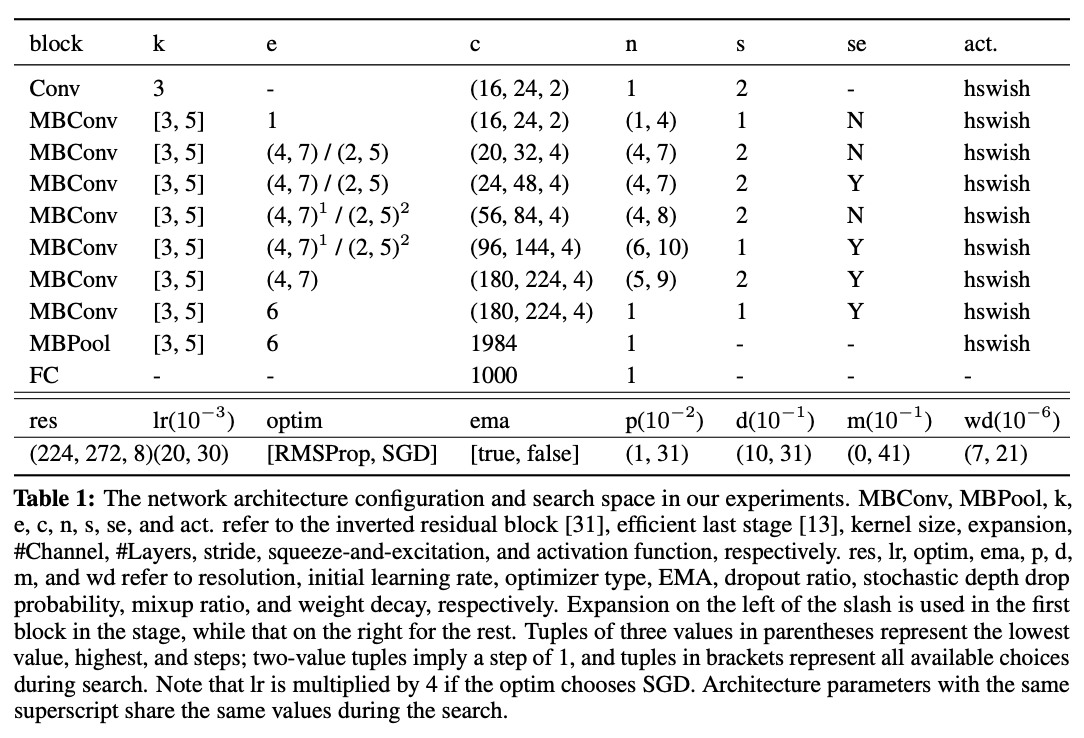
搜索空间如表1所示,共包含\(10^{17}\)种网络结构以及\(10^{7}\)种训练超参数。
Experiments
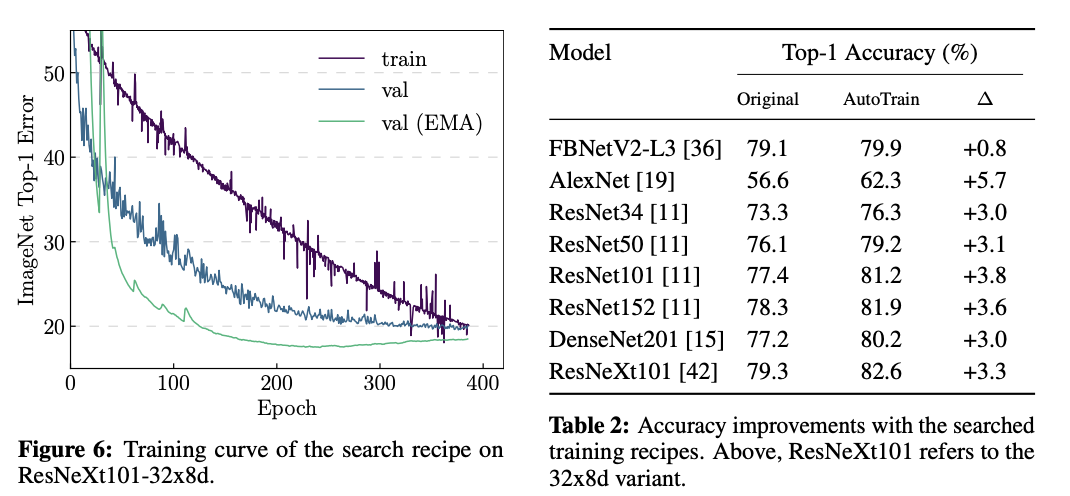
固定网络结构,测试训练参数搜索的有效性。
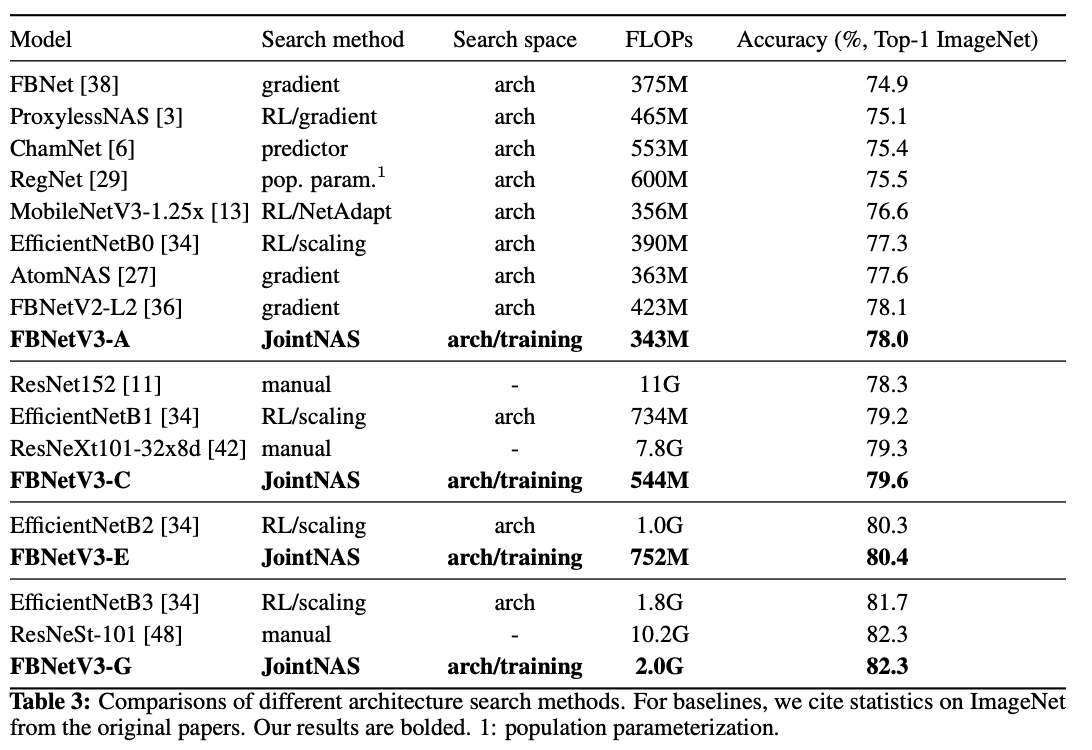
与其它网络进行ImageNet性能对比。
Conclustion
FBNetV3完全脱离了FBNetV2和FBNet的设计,使用的准确率预测器以及基因算法都已经在NAS领域有很多应用,主要亮点在于将训练参数加入到了搜索过程中,这对性能的提升十分重要。
Conclustion
FBNet系列是完全基于NAS方法的轻量级网络系列,分析当前搜索方法的缺点,逐步增加创新性改进,FBNet结合了DNAS和资源约束,FBNetV2加入了channel和输入分辨率的搜索,FBNetV3则是使用准确率预测来进行快速的网络结构搜索,期待完整的代码开源。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

FBNet/FBNetV2/FBNetV3:Facebook在NAS领域的轻量级网络探索 | 轻量级网络的更多相关文章
- NASNet : Google Brain经典作,改造搜索空间,性能全面超越人工网络,继续领跑NAS领域 | CVPR 2018
论文将搜索空间从整体网络转化为卷积单元(cell),再按照设定堆叠成新的网络家族NASNet.不仅降低了搜索的复杂度,从原来的28天缩小到4天,而且搜索出来的结构具有扩展性,在小模型和大模型场景下都能 ...
- 怎样设计最优的卷积神经网络架构?| NAS原理剖析
虽然,深度学习在近几年发展迅速.但是,关于如何才能设计出最优的卷积神经网络架构这个问题仍在处于探索阶段. 其中一大部分原因是因为当前那些取得成功的神经网络的架构设计原理仍然是一个黑盒.虽然我们有着关于 ...
- 自己家里搭建NAS服务器有什么好方案?
转自:https://www.zhihu.com/question/21359049 作者:陈二发链接:https://www.zhihu.com/question/21359049/answer/6 ...
- [ZZ] 多领域视觉数据的转换、关联与自适应学习
哈工大左旺孟教授:多领域视觉数据的转换.关联与自适应学习 http://blog.sciencenet.cn/home.php?mod=space&uid=3291369&do=blo ...
- 转- 集群NAS技术架构
集群NAS技术架构 标签: 集群存储负载均衡扩展服务器网络 原贴:http://blog.csdn.net/liuaigui/article/details/6422700 作者刘爱贵 1 什么是集群 ...
- Facebook巴特尔与谷歌移动广告 急于打开中国市场
随着Facebook(62.5, -0.69, -1.09%)即将设立了销售办事处在北京发酵消息.谷歌(556.33, 2.43, 0.44%)似还差点自觉保护国内市场. 6月5日,谷歌在深圳举行了面 ...
- 基于开源软件构建高性能集群NAS系统,包括负载均衡(刘爱贵)
大数据时代的到来已经不可阻挡,面对数据的爆炸式增长,尤其是半结构化数据和非结构化数据,NoSQL存储系统和分布式文件系统成为了技术浪潮,得到了长足的发展.非结构化数据目前呈现更加快速的增长趋势,IDC ...
- 敏捷史话(十三):我被 Facebook 解雇了——Kent Beck
2011年,Kent Beck 加入了 Facebook .那时候的他已年过半百,几十年的经验让他自认为非常了解软件行业.在 Facebook 的新手训练营期间,Kent 开始意识到,Facebook ...
- 用普通计算机假设基于liunx系统的NAS部署FineReport决策系统
何为NAS? 简单说就是连接在网络上,具备资料存储功能的装置因此也称为“网络存储器”.它是一种专用数据存储服务器.他以数据为中心,将存储设备与服务器彻底分离,集中管理数据,从而释放带宽.提高性能.降低 ...
- Facebook 网络模拟工具 ATC部署及使用
废话引用: Facebook此前开源了增强网络流量控制工具 ATC,能利用WiFi网络模拟各种移动网络,测试智能手机和APP在不同国家地区和应用环境下的性能表现.ATC能够模拟2G.2.5G(Edge ...
随机推荐
- Swoole从入门到入土(19)——WebSocket服务器[文件传输]
要利用WebSocket进行文件传输,我们需要讨论两种情况,分别是:发送方可以是客户端,和 发送方是服务端. 1.发送方是客户端 1)服务端接收 $server->on('message', ...
- Python之猜数字游戏
说明: 本例改编自<Python编程快速上手>.例子很简单我就不多说了 直接上代码,给初学python练手用. 给你6次机会猜对一个预先生成好的1-20之间的整数.覆盖一下知识点: 条件语 ...
- C++ sentry 如何压缩日志文件
项目中在使用 sentry 上传事件的 attachment 函数过程中发现,附带的 log 文件是未压缩的,于是有了需求,即需要在 sentry 内部将未压缩的文件流压缩后再上传给服务器 这个需求看 ...
- Puppeteer介绍
Puppeteer是什么 Puppeteer是一个Node库,它提供了一个高级API来通过DevTools协议控制Chromium或Chrome. 可以使用Puppeteer来自动化完成浏览器的操作, ...
- channel管道
channel 如果说goroutine是并发体的话,那么channels则是他们之间的通信机制.一个channel是一个通信机制,它可以让一个goroutine通过它给另一个goroutine发生值 ...
- java数组实现的超市管理系统(控制台)
说明:使用数组存储数据,针对用户功能1:增加用户2:删除用户3:修改用户:针对商品功能:1.显示所有商品2.修改商品信息3.添加商品信息4.删除商品信息5.查询商品信息 效果展示 ========== ...
- 第126篇: 异步函数(async和await)
好家伙,本篇为<JS高级程序设计>第十章"期约与异步函数"学习笔记 ES8 的 async/await 旨在解决利用异步结构组织代码的问题. 为为此增加了两个新关键 ...
- 【Azure 应用服务】Azure Function 部署槽交换时,一不小心把预生产槽上的配置参数交换到生产槽上,引发生产错误
问题描述 部署Function代码先到预生产槽中,进行测试后通过交换方式,把预生产槽中的代码交换到生产槽上,因为在预生产槽中的设置参数值与生产槽有不同,但是在交换的时候,没有仔细检查.导致在交换的时候 ...
- C/C++、C#、JAVA(三):字符串操作
C/C++.C#.JAVA(三):字符串操作 目录 C/C++.C#.JAVA(三):字符串操作 定义字符串 C C++ C# JAVA 捕捉输入和输出 等值比较 C/C++ C# JAVA 字符串操 ...
- Mutillidae品台上使用sqlmap注入测试
Mutillidae是一个开放源码的提供安全渗透测试的Web应用程序, Mutillidae可以安装在Linux.windows xp.windows 7等平台上.下载及安装说明文档详见:mutill ...