【Flink入门修炼】2-2 Flink State 状态
- 什么是状态?状态有什么作用?
- 如果你来设计,对于一个流式服务,如何根据不断输入的数据计算呢?
- 又如何做故障恢复呢?
一、为什么要管理状态
流计算不像批计算,数据是持续流入的,而不是一个确定的数据集。在进行计算的时候,不可能把之前已经输入的数据全都保存下来,然后再和新数据合并计算。效率低下不说,内存也扛不住。
另外,如果程序出现故障重启,没有之前计算过的状态保存,那么也就无法再继续计算了。
因此,就需要一个东西来记录各个算子之前已经计算过值的结果,当有新数据来的时候,直接在这个结果上计算更新。这个就是状态。
常见的流处理状态功能如下:
- 数据流中的数据有重复,我们想对重复数据去重,需要记录哪些数据已经流入过应用,当新数据流入时,根据已流入过的数据来判断去重。
- 检查输入流是否符合某个特定的模式,需要将之前流入的元素以状态的形式缓存下来。比如,判断一个温度传感器数据流中的温度是否在持续上升。
- 对一个时间窗口内的数据进行聚合分析,分析一个小时内某项指标的75分位或99分位的数值。
- 在线机器学习场景下,需要根据新流入数据不断更新机器学习的模型参数。
二、state 简介
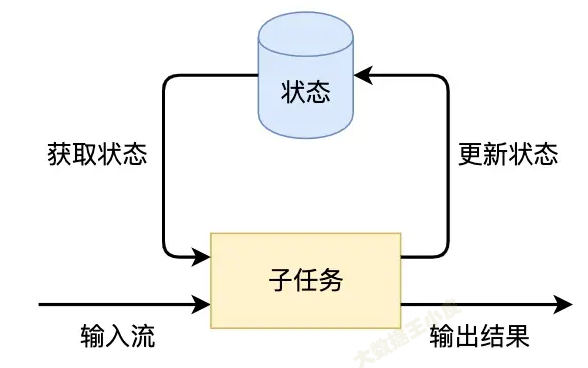
Flink的状态是由算子的子任务来创建和管理的。一个状态更新和获取的流程如下图所示,一个算子子任务接收输入流,获取对应的状态,根据新的计算结果更新状态。
状态的保存:
需要考虑的问题:
- container 异常后,状态不丢
- 状态可能越来越大
因此,状态不能直接放在内存中,以上两点问题都无法保证。
需要有一个外部持久化存储方式,常见的如放到 HDFS 中。(此部分读者感兴趣可自行搜索资料探索)
三、Flink 状态类型
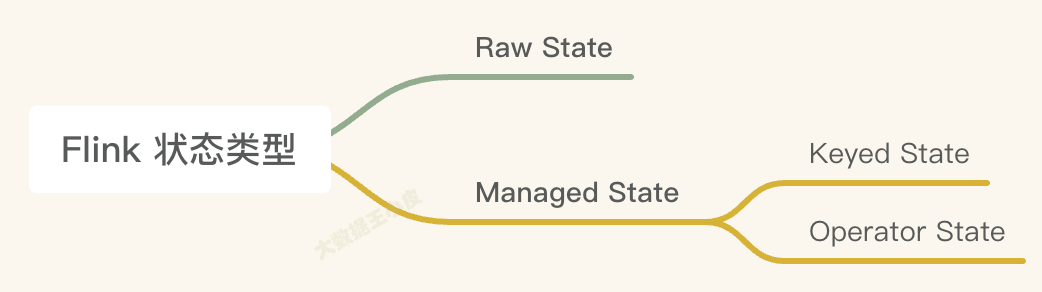
一)Managed State 和 Raw State
- Managed State 是由 Flink 管理的。Flink帮忙存储、恢复和优化。
- Raw State 是开发者自己管理的,需要自己序列化(较少用到)。
在 Flink 中推荐用户使用Managed State管理状态数据 ,主要原因是 Managed State 能够更好地支持状态数据的重平衡以及更加完善的内存管理。
| Managed State | Raw State | |
|---|---|---|
| 状态管理方式 | Flink Runtime 管理,自动存储,自动恢复,内存管理方式上优化明显 | 用户自己管理,需要用户自己序列化 |
| 状态数据结构 | 已知的数据结构 value , list ,map | flink不知道你存的是什么结构,都转换为二进制字节数据 |
| 使用场景 | 大多数场景适用 | 需要满足特殊业务,自定义operator时使用,flink满足不了你的需求时候,使用复杂 |
下文将重点介绍Managed State。
二)Keyed State 和 Operator State
Managed State 又有两种类型:Keyed State 和 Operator State。
| keyed state | operator state | |
|---|---|---|
| 适用场景 | 只能应用在 KeyedSteam 上 | 可以用于所有的算子 |
| State 处理方式 | 每个 key 对应一个 state,一个 operator 处理多个 key ,会访问相应的多个 state | 一个 operator 对应一个 state |
| 并发改变 | 并发改变时,state随着key在实例间迁移 | 并发改变时需要你选择分配方式,内置:1.均匀分配 2.所有state合并后再分发给每个实例 |
| 访问方式 | 通过RuntimeContext访问,需要operator是一个richFunction | 需要你实现CheckPointedFunction或ListCheckPointed接口 |
| 支持数据结构 | ValuedState, ListState, Reducing State, Aggregating State, MapState, FoldingState(1.4弃用) |
只支持 listState |
Keyed State
简单来说,通过 keyBy 分组的就会用到 Keyed State。就是按照分组来的状态。(Keyed State 是Operator State的特例,区别在于 Keyed State 事先按照 key 对数据集进行了分区,每个 Key State 仅对应ー个Operator和 Key 的组合。)
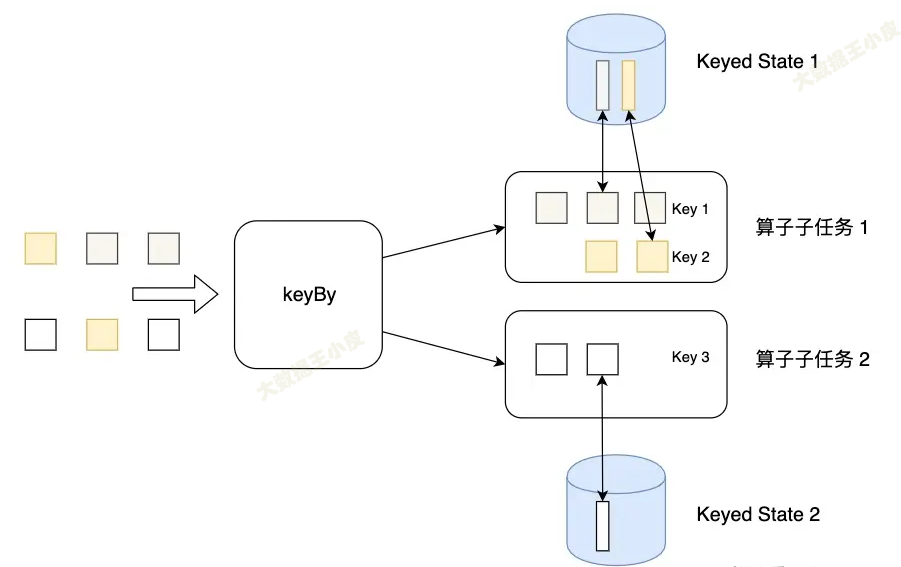
Keyed State可以通过 Key Groups 进行管理,主要用于当算子并行度发生变化时,自动重新分布Keyed State数据 。分配代码如下:
// KeyGroupRangeAssignment.java
public static int computeKeyGroupForKeyHash(int keyHash, int maxParallelism) {
return MathUtils.murmurHash(keyHash) % maxParallelism;
}
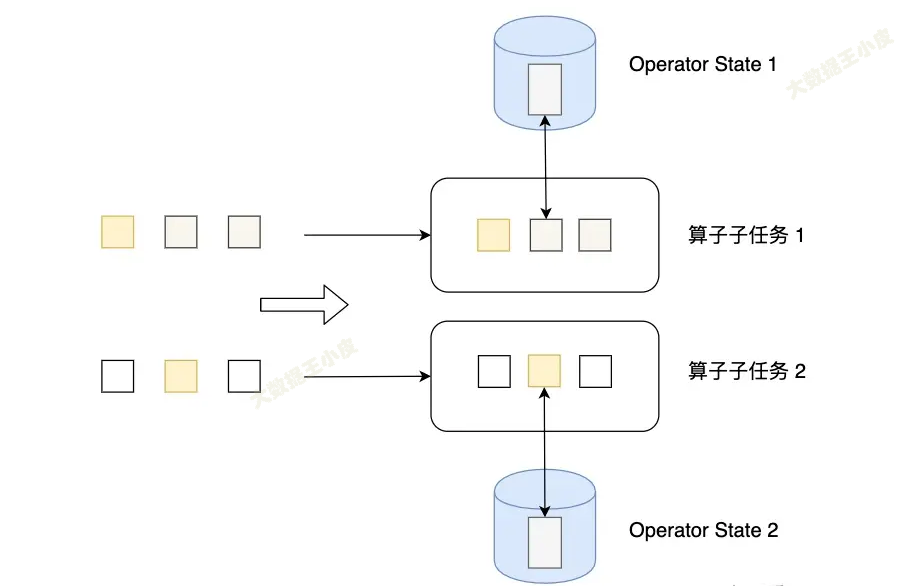
Operator State
Operator State 可以用在所有算子上,每个算子子任务或者说每个算子实例共享一个状态,流入这个算子子任务的数据可以访问和更新这个状态。
例如 Kafka Connector 中,每一个并行的 Kafka Consumer 都在 Operator State 中维护当前 Consumer 订阅的 partiton 和 offset。
三)Flink 实现类
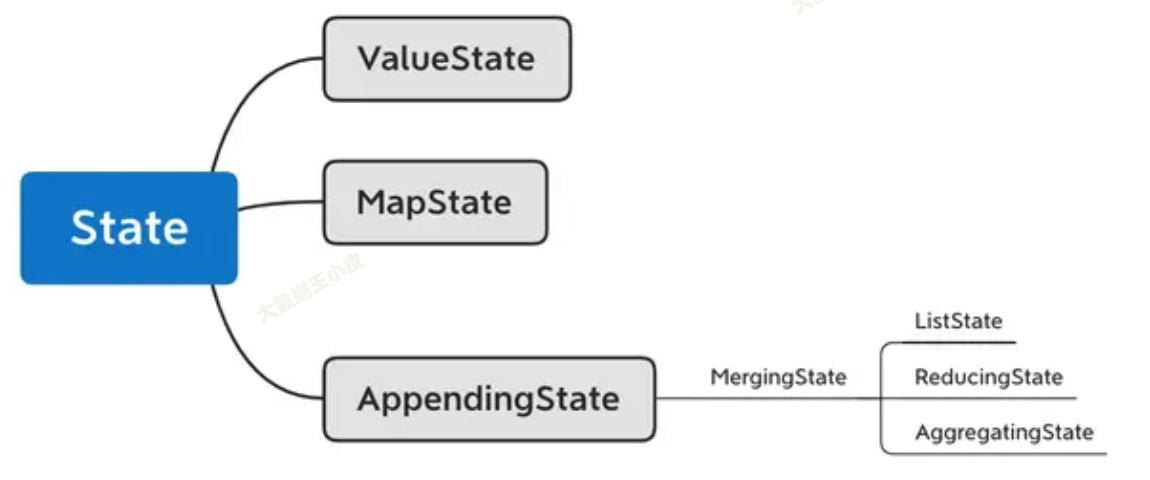
在开发中,需要保存的状态也有不同的数据结构,那么 Flink 也提供了相应的类。
如上图所示:
ValueState[T]保存单一变量状态MapState[K, V]同 java map,保存 kv 型状态ListState[T]数组类型状态ReducingState[T]单一状态,将原状态和新状态合并后再更新AggregatingState[IN, OUT]同样是合并更新,只不过前后数据类型可以不一样
四、实践
实现一个简单的计数窗口。
输入数据是一个元组 Tuple2.of(1L, 3L),把元组的第一个元素当作 key(在示例中都 key 都是 “1”),第二个元素当 value。
该函数将出现的次数以及总和存储在 ValueState 中。 一旦出现次数达到 2,则将平均值发送到下游,并清除状态重新开始。 请注意,我们会为每个不同的 key(元组中第一个元素)保存一个单独的值。
public class CountWindowAverage extends RichFlatMapFunction<Tuple2<Long, Long>, Tuple2<Long, Long>> {
/**
* The ValueState handle. The first field is the count, the second field a running sum.
*/
private transient ValueState<Tuple2<Long, Long>> sum;
@Override
public void flatMap(Tuple2<Long, Long> input, Collector<Tuple2<Long, Long>> out) throws Exception {
// access the state value
Tuple2<Long, Long> currentSum = sum.value();
// update the count
currentSum.f0 += 1;
// add the second field of the input value
currentSum.f1 += input.f1;
// update the state
sum.update(currentSum);
// if the count reaches 2, emit the average and clear the state
if (currentSum.f0 >= 2) {
out.collect(new Tuple2<>(input.f0, currentSum.f1 / currentSum.f0));
sum.clear();
}
}
@Override
public void open(Configuration config) {
ValueStateDescriptor<Tuple2<Long, Long>> descriptor =
new ValueStateDescriptor<>(
"average", // the state name
TypeInformation.of(new TypeHint<Tuple2<Long, Long>>() {}), // type information
Tuple2.of(0L, 0L)); // default value of the state, if nothing was set
sum = getRuntimeContext().getState(descriptor);
}
}
// this can be used in a streaming program like this (assuming we have a StreamExecutionEnvironment env)
env.fromElements(Tuple2.of(1L, 3L), Tuple2.of(1L, 5L), Tuple2.of(1L, 7L), Tuple2.of(1L, 4L), Tuple2.of(1L, 2L))
.keyBy(value -> value.f0)
.flatMap(new CountWindowAverage())
.print();
// the printed output will be (1,4) and (1,5)
四、小结
本节我们介绍了 Flink 状态,是用于流式计算中中间数据存储和故障恢复的。
Flink 状态分为 Raw State 和 Manage State,其中 Manage State 中又包含 Keyed State 和 Operator State。最重要的是 Keyed State 要重点理解和掌握。
在编程开发过程中,针对不同的数据结构,Flink 提供了对应的 State 类。并提供了一个 state demo 代码供学习。
参考文章:
七、Flink入门--状态管理_flink流式任务如何保证7*24小时运行-CSDN博客
Flink状态管理详解:Keyed State和Operator List State深度解析
爆肝 3 月,3w 字、15 章节详解 Flink 状态管理!(建议收藏)-腾讯云开发者社区-腾讯云(较详细)
Flink 笔记二 Flink的State--状态原理及原理剖析_flink key state是每个key对应一个state还是每个分区对应一个state-CSDN博客(源码剖析)
Flink 状态管理详解(State TTL、Operator state、Keyed state)-腾讯云开发者社区-腾讯云
Flink 源码阅读笔记(10)- State 管理
【Flink入门修炼】2-2 Flink State 状态的更多相关文章
- Flink入门-第一篇:Flink基础概念以及竞品对比
Flink入门-第一篇:Flink基础概念以及竞品对比 Flink介绍 截止2021年10月Flink最新的稳定版本已经发展到1.14.0 Flink起源于一个名为Stratosphere的研究项目主 ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink入门(四)——编程模型
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink的编程模型. 数据集类型: 无穷数据集:无穷的持续集成的数据集合 有界数据集:有 ...
- Flink入门(三)——环境与部署
flink是一款开源的大数据流式处理框架,他可以同时批处理和流处理,具有容错性.高吞吐.低延迟等优势,本文简述flink在windows和linux中安装步骤,和示例程序的运行,包括本地调试环境,集群 ...
- Flink入门(五)——DataSet Api编程指南
Apache Flink Apache Flink 是一个兼顾高吞吐.低延迟.高性能的分布式处理框架.在实时计算崛起的今天,Flink正在飞速发展.由于性能的优势和兼顾批处理,流处理的特性,Flink ...
- 记一次flink入门学习笔记
团队有几个系统数据量偏大,且每天以几万条的数量累增.有一个系统每天需要定时读取数据库,并进行相关的业务逻辑计算,从而获取最新的用户信息,定时任务的整个耗时需要4小时左右.由于定时任务是夜晚执行,目前看 ...
- flink 入门
http://ifeve.com/flink-quick-start/ http://vinoyang.com/2016/05/02/flink-concepts/ http://wuchong.me ...
- Flink入门宝典(详细截图版)
本文基于java构建Flink1.9版本入门程序,需要Maven 3.0.4 和 Java 8 以上版本.需要安装Netcat进行简单调试. 这里简述安装过程,并使用IDEA进行开发一个简单流处理程序 ...
- 不一样的Flink入门教程
前言 微信搜[Java3y]关注这个朴实无华的男人,点赞关注是对我最大的支持! 文本已收录至我的GitHub:https://github.com/ZhongFuCheng3y/3y,有300多篇原创 ...
- 新一代分布式实时流处理引擎Flink入门实战之先导理论篇-上
@ 目录 概述 定义 为什么使用Flink 应用行业和场景 应用行业 应用场景 实时数仓演变 Flink VS Spark 架构 系统架构 术语 无界和有界数据 流式分析基础 分层API 运行模式 作 ...
随机推荐
- NLP文本匹配任务Text Matching 有监督训练:PointWise(单塔)、DSSM(双塔)、Sentence BERT(双塔)项目实践
NLP文本匹配任务Text Matching [有监督训练]:PointWise(单塔).DSSM(双塔).Sentence BERT(双塔)项目实践 0 背景介绍以及相关概念 本项目对3种常用的文本 ...
- NLP领域任务如何选择合适预训练模型以及选择合适的方案【规范建议】【ERNIE模型首选】
1.常见NLP任务 信息抽取:从给定文本中抽取重要的信息,比如时间.地点.人物.事件.原因.结果.数字.日期.货币.专有名词等等.通俗说来,就是要了解谁在什么时候.什么原因.对谁.做了什么事.有什么结 ...
- python:spacy、gensim库的安装遇到问题及bug处理
1.spacy SpaCy最新版V3.0.6版,在CMD 模式下可以通过 pip install spacy -U 进行安装 注意这个过程进行前可以先卸载之前的旧版本 pip uninstall sp ...
- npm sill idealTree buildDeps安装卡住问题
1.解决方式1 1.1设置淘宝镜像 npm config set registry http://registry.npm.taobao.org/ npm config get registry 参考 ...
- 架构设计脱胎换骨!英特尔酷睿Ultra深度解析
英特尔正式发布了第一代酷睿Ultra处理器平台,也就是首个基于Intel 4制程工艺(7nm)打造的移动级处理器平台,其核心代号为Meteor Lake,产品系列贴标设计也采用了全新方案. 同时在命名 ...
- 【奶奶看了都会】ChatGPT3.5接入企业微信,可连续对话
1.连续对话效果 小伙伴们,这周ChatGPT放出大招,开放了GPT3.5的API.说简单点,就是提供了和ChatGPT页面对话一样模型的接口.而之前接的ChatGPT接口都是3.0,并不是真正的Ch ...
- Cpu是如何选择线程的?
Cpu是如何选择线程的? linux中线程存放格式 linux中线程与进程对应的结构体都是task_struct 唯一不同的点在于线程存放的东西少了点(由于一个进程中的线程们是共享一定数据的那些东西就 ...
- 小知识:在Exadata平台上使用ExaWatcher收集信息
在非Exadata平台上,我们通常会使用DBA已经很熟悉的OSW,如果有不熟悉的朋友可以参考我之前的随笔初步了解OSW: OSW 快速安装部署 OSW Analyzer分析oswbb日志发生异常 而在 ...
- Flink CDC写入数据到kafka几种格式
Flink CDC写入kafka几种常见的数据格式,其中包括upsert-kafka写入后正常的json格式,debezium-json格式以及changelog-json格式. upsert-kaf ...
- TCP和UDP面试题提问
@ 目录 TCP UDP 总结 应用 TCP(传输控制协议)和UDP(用户数据报协议)是两种计算机网络通信协议,它们在网络通信中起着不同的作用. TCP TCP 是面向连接的协议,它在数据传输之前需要 ...