【论文阅读】End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances
文章名:CVPR2020: End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances
Column: December 14, 2021 11:15 AM
Last edited time: December 31, 2021 6:46 PM
Sensor: 1 RGB
Status: Finished
Summary: RL; carla leaderboard
Type: CVPR
Year: 2020
引用量: 44
参考与前言 resource
代码:https://github.com/valeoai/LearningByCheating;虽然代码是lbc的名字 但是其实是作者fork过来的,然后基于lbc基础上进行自添加删除等 hhhh (原来fork过来的是没有issue栏了 emmm)
视频:
1. Motivation
IL DRL 对比
首先主要是指出模仿学习的缺点:因为专家的数据都是great,也就是你承认他开车开得对,没有开错的,这也就造成了一个distribution mismatch,只有好的数据;当然也有文章[1,32] 指出:那我就填开错的数据进去,但是呢 这种数据一般都是车保持在本车道/lateral control
- 我没搞懂这个lateral control是指横向控制偏失吗?
所以呢,DRL不会有distribution mismatch的问题,因为他的数据都是在提供reward signal下通过RL来学的,而这种情况下呢,不是说车开的对错,而是你车开的好坏 how good action taken
但是呢DRL也面临着一些问题:
- 依赖于replay buffer,而这个buffer又会限制input size比较小
- black box → 所以有些方法是先提取信息,比如得到分割图片后在传到controller,以此检验是否关注到信息点了
Contribution
根据前面的对比,引出自己的contribution:
我们是第一个成功使得RL在复杂驾驶环境上用的,环路相遇和交通灯识别等
引入了一种新的技术:implicit affordance 使得RL可以在 大网络下 和 大input size 使用replay remory的训练
主要就是两个阶段,这样RL这边接收的就不是raw image,memory剩下20倍左右。→ 好像之前想的降维操作哎
- 用resnet18框架去输出 feature
- 然后 RL 接收 这个降维后的feature
做了 implicit affordance 和 reward shaping 的消融实验

总的来看 contribution除了第二点,emm 其他贡献其他文章也基本有的;
第二点最好再仔细看一下method部分
不过我感觉这个introduction写的不错哎,比较全和明了去介绍并提出了贡献点二,可以借鉴一下
2. Method
- 输入是1个相机(4张连续时间的图片),加RGB是3个通道,一共下来12个通道,那应该是batch_size x 12 x 288 x 288
- 输出是方向盘转角和油门
整个框架
RL 设置
首先选的是value-based method,当然这样的设置就导致我们看的动作都是离散的,文中并没有做policy-based的对比(挖坑 后面做),借鉴开源的Rainbow-IQN Ape-X 但是去掉了dueling network
温馨链接:RL policy-based method和value-based method区别
Reward Shaping
原来这个shaping是指... reward setting
计算的方法主要是 Carla提供了waypoint的API来进行判断,当遇到路口的时候,随机选择(左、右、直走),reward主要由以下三个决定
desired speed:reward range [0,1]
如果在期望速度给最大1,然后线性打分当速度高了或者是低了,本文中期望速度为40km/h
展开可见图片示意
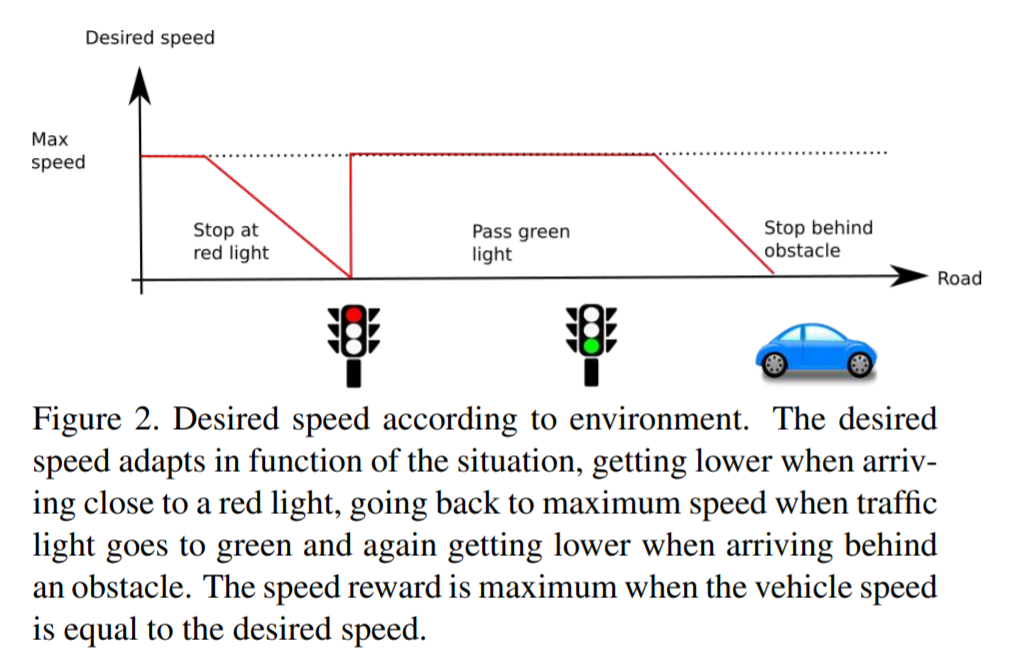
desired position:reward range [-1,0]
如果刚好在道路中心的路径点给0,然后和相距距离成反比的给负reward,以下两种情况episode直接停止,并设reward为-1,本文设置\(D_{max}=2\text{m}\) 也正是中心线到路边缘的距离
- 与中心路径点相距超过\(D_{max}\)
- 与其他东西相撞,闯红绿灯,前无障碍物/红灯时 车辆停下来
desired rotation
这一个设置的是因为 作者发现只有前两个的时候,车子会在有障碍物的时候直接停下,而不是绕行,因为绕行会让他的第二个reward下降,直行的话又会使他撞上去 → 有做消融实验证明
reward 和 optimal trajectory的angle差距值成反比
但是看到这点的时候,我本来打算看看rotation的reward范围,然后发现这个作者... 是假开源,他并没有开源RL expert的代码 emmm,也没有给出RL跑的数据集 → 按道理不给代码 给数据集应该不难?代码里只有load他的model,连Dataloader都没有 emmm
还有一点是在换道的时候 reward还是会偏离原路径点的angle呀,如果是optimal trajectory的角度的话,并没有定义清楚optimal trajectory是由谁给出的
噢 是不是 他在开头嫌弃的那个carla的expert?→ 不对啊 他不会换道呀
Network
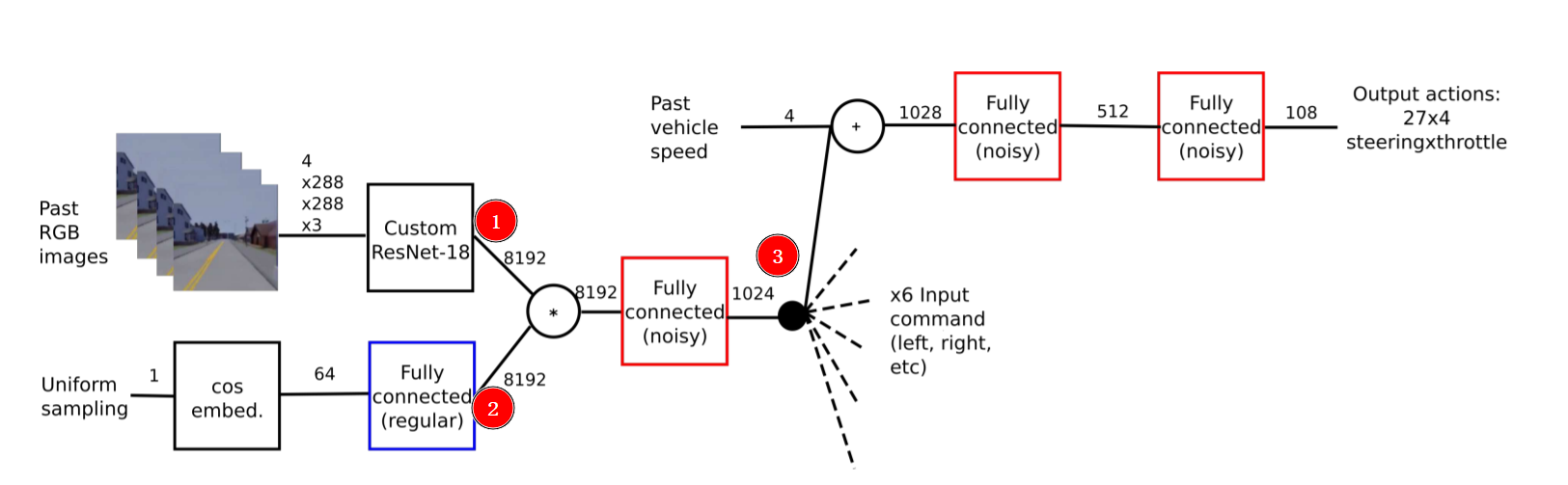
整体图
① RGB → resnet那层,在classif_state_net这层输出,把他展开成一维的长度:8192
classif_state_net = encoding.view(-1, self.size_state_RL)
② 这层有点奇怪,主要是这个框图奇怪,首先对着代码仅有的model看,输入不是什么uniform sampling 而是直接上面的image那里encoder的值,只是经过过的不是view(-1) 而是几层sampled_block → 也就是代码中没有体现②和③ → 破案了,没体现② 但是③后面的有了 在DQN model里面,直接是每个noisyLayer下的两个linear+relu搞定到output输出
只看①对应的直接下图的decoder部分:
下图下半部:展开一维长度8192,再经过一层Linear&relu 到1024长度
return classif_output, state_output, dist_to_tl_output, delta_position_yaw_output下图上半部:在展成一维前,输入到另一个四层的sampled_block形式 [Upsample,Conv2d,BatchNorm2d,ReLU,Conv2d,BatchNorm2d],直接输出
return out_seg但是这里有个问题是,实际操作代码输出的尺寸应该是24x73x128,而且代码里也是直接按照这个输入到DQN那边的rl_state_net的
喔 原来这步是decoder的输出,看这幅图:(第一幅画的什么呀 emmm)
①:经过完resnet18后还走了一层 [Conv2d,BatchNorm2d],然后展成一维:8192
decoder:在①展成一维前,输入到另一个四层的sampled_block形式 [Upsample,Conv2d,BatchNorm2d,ReLU,Conv2d,BatchNorm2d],然后输出是out_seg
# Segmentation branchupsample0 = self.up_sampled_block_0(encoding) # 512*8*8 or 512*6*8 (crop sky)upsample1 = self.up_sampled_block_1(upsample0) # 256*16*16 or 256*12*16 (crop sky)upsample2 = self.up_sampled_block_2(upsample1) # 128*32*32 or 128*24*32 (crop sky)upsample3 = self.up_sampled_block_3(upsample2) # 64*64*64 or 64*48*64 (crop sky)upsample4 = self.up_sampled_block_4(upsample3) # 32*128*128 or 32*74*128 (crop sky)out_seg = self.last_bn(self.last_conv_segmentation(upsample4)) # nb_class_segmentation*128*128# ===================================================# We will upsample image with nearest neightboord interpolation between each umsample block# https://distill.pub/2016/deconv-checkerboard/self.up_sampled_block_0 = create_resnet_basic_block(6, 8, 512, 512)self.up_sampled_block_1 = create_resnet_basic_block(12, 16, 512, 256)self.up_sampled_block_2 = create_resnet_basic_block(24, 32, 256, 128)self.up_sampled_block_3 = create_resnet_basic_block(48, 64, 128, 64)self.up_sampled_block_4 = create_resnet_basic_block(74, 128, 64, 32)# ===================================================def create_resnet_basic_block(width_output_feature_map, height_output_feature_map, nb_channel_in, nb_channel_out):basic_block = nn.Sequential(nn.Upsample(size=(width_output_feature_map, height_output_feature_map), mode="nearest"),nn.Conv2d(nb_channel_in,nb_channel_out,kernel_size=(3, 3),stride=(1, 1),padding=(1, 1),bias=False,),nn.BatchNorm2d(nb_channel_out, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),nn.ReLU(inplace=True),nn.Conv2d(nb_channel_out,nb_channel_out,kernel_size=(3, 3),stride=(1, 1),padding=(1, 1),bias=False,),nn.BatchNorm2d(nb_channel_out, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True),)return basic_block
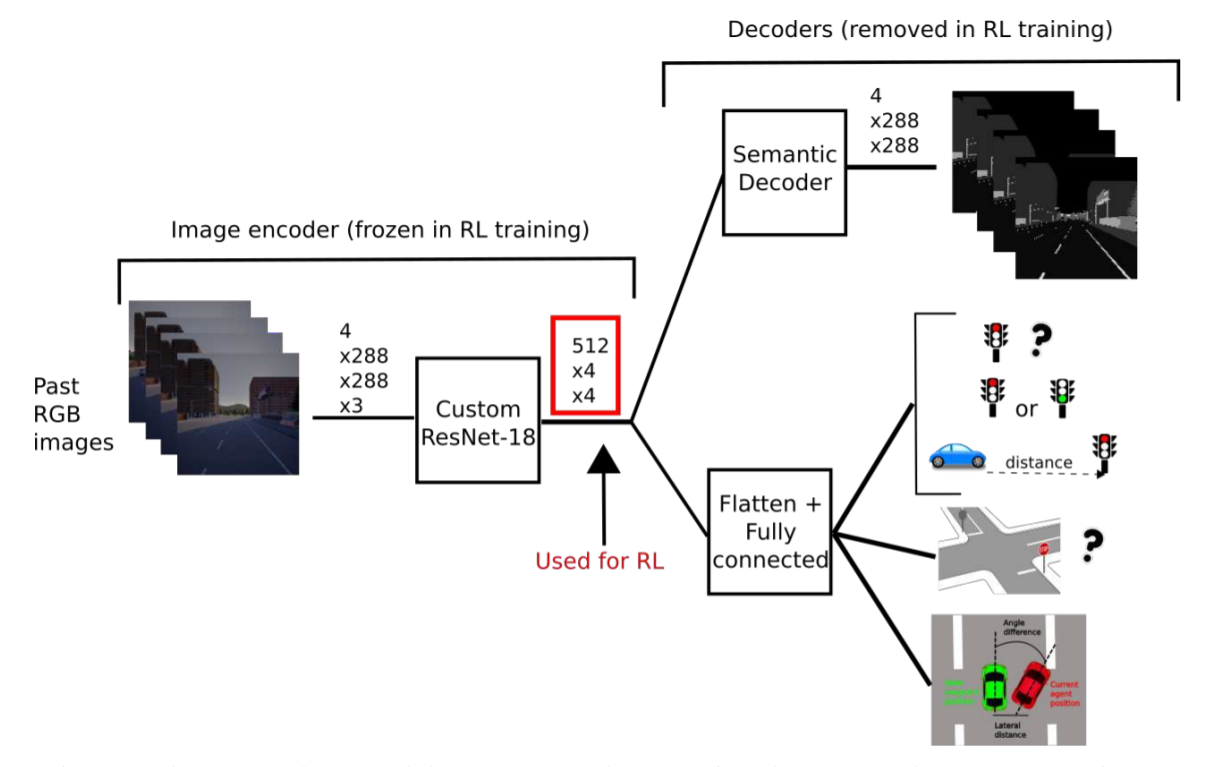
image输入框架
总结一下:
- 作者没有公布自己的数据集,也没有公开怎样拿到的expert数据以训练出这样一个model的,而是直接给了一个稍微训练好的model权重文件
- 实际有了model后,整个流程就是收到图片,输出resnet18后的数据,分两道:
- 走到semantic decoder,输出
out_seg - 走到flatten展开一维,然后再经过不同的Linear配置,各自输出:
state_output, dist_to_tl_output, delta_position_yaw_output
- 走到semantic decoder,输出
- 最后第二点的a+b.一起展成一维的,再输出到DQN那边进行一层Linear+relu,同收到的speed和steering一起 再走到三层Linear 最后输出的action
- 因为第一点的原因,纯看代码 真的看不出用来RL,即使是DQN也只是cat数据一起,经过几层的NoiseLayer which is nn.Linear;所以emmm 一言难尽 → 审稿人竟然没有就这点提出质疑
3. Conclusion

看完全文+代码,再看这个结论部分,多少有点code lie → 因为第二点 using a value-based Rainbow-IQN-Apex training with an adapted reward!没有在代码中进行体现
- large conditional netwrok:估计是指自己先通过resnet18 铺平后送入DQN的意思吧
- implicit affordance:分开输出out_seg和图二所示的下部分(红绿灯、速度、偏航角偏移) 但其实DQN那里基本也是一起一维到DQN的,只是说中途有个好展示的东西?但是论文里也没给出这一个中间小输出是长什么样的
- future work 可以对比一下value-based, policy-based and actor-critic,所以这就是不给出value-based 的 code原因?怕太卷了 大家直接看到就卷出来了
碎碎念
emmm 但是不得不说这个作者在leaderboard提交的 还是比较厉害的:人家可是只用了一个相机!看看在他前面的传感器使用量都是直接拉满到四个。
但是感觉这个应该是训练了很久的,不然不至于一年过后的今天还是不在repo中给出自己hard task的结果 hhhh
【论文阅读】End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances的更多相关文章
- 论文笔记系列-Neural Architecture Search With Reinforcement Learning
摘要 神经网络在多个领域都取得了不错的成绩,但是神经网络的合理设计却是比较困难的.在本篇论文中,作者使用 递归网络去省城神经网络的模型描述,并且使用 增强学习训练RNN,以使得生成得到的模型在验证集上 ...
- 论文阅读:Deep Attentive Tracking via Reciprocative Learning
Deep Attentive Tracking via Reciprocative Learning 2018-11-14 13:30:36 Paper: https://arxiv.org/abs/ ...
- 【论文阅读】3DMM-A Morphable Model for The Synthesis of 3D Faces
前言 参考 1. 2. 完
- 论文阅读 | BadNets: Identifying Vulnerabilities in the Machine Learning Model Supply Chain
BadNets: 识别机器学习模型供应链中的漏洞 摘要 基于深度学习的技术已经在各种各样的识别和分类任务上取得了最先进的性能.然而,这些网络通常训练起来非常昂贵,需要在许多gpu上进行数周的计算;因此 ...
- 【论文阅读】MEAL: Multi-Model Ensemble via Adversarial Learning
转载请注明出处:https://www.cnblogs.com/White-xzx/ 原文地址:https://arxiv.org/abs/1812.02425 Github: https://git ...
- 【CV论文阅读】An elegant solution for subspace learning
Pre: It is MY first time to see quite elegant a solution to seek a subspace for a group of local fea ...
- [置顶]
人工智能(深度学习)加速芯片论文阅读笔记 (已添加ISSCC17,FPGA17...ISCA17...)
这是一个导读,可以快速找到我记录的关于人工智能(深度学习)加速芯片论文阅读笔记. ISSCC 2017 Session14 Deep Learning Processors: ISSCC 2017关于 ...
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- Open source packages on Deep Reinforcement Learning
智能车 self driving car + 强化学习 reinforcement learning + 神经网络 模拟 https://github.com/MorvanZhou/my_resear ...
- (zhuan) Paper Collection of Multi-Agent Reinforcement Learning (MARL)
this blog from: https://github.com/LantaoYu/MARL-Papers Paper Collection of Multi-Agent Reinforcemen ...
随机推荐
- Solution Set - SAM
讲解一些 SAM 经典的应用.可以结合 字 符 串 全 家 桶 中 SAM 的部分食用. 洛谷P2408 求不同子串个数.在 SAM 中,所有结点是一个等价类,包含的字符串互不相同.结点 \(u\) ...
- Could not find mimemagic-0.3.2 in any of the sources
rails s报如下错误 Could not find mimemagic-0.3.2 in any of the sources Run `bundle install` to install mi ...
- ansible(6)--ansible的copy和fetch模块
1. copy模块 功能:从 ansible 服务端主控端复制文件到远程主机: copy模块的主要参数如下: 参数 说明 src 复制的源文件路径,若源文件为目录,默认进行递归复制,如果路劲以&quo ...
- Java简单实现MQ架构和思路02
Java MQ的100个功能清单 有重复的 一个消息队列(MQ)可以有以下功能: 批量发送消息:允许将多个消息打包成一个批次发送,可以减少网络传输开销和提高系统吞吐量. 消息过期时间:消息可以设置一个 ...
- JDK源码阅读-------自学笔记(八)(数组演示冒泡排序和二分查找)
冒泡排序 算法 比较相邻的元素.如果第一个比第二个大,就交换他们两个 对每一对相邻元素作同样的工作,从开始第一对到结尾的最后一对.在这一点,最后的元素应该会是最大的数 针对所有的元素重复以上的步骤,除 ...
- c++ RTTI Runtime Type Identification 运行阶段类型识别
NoVirtualBase* NvirBase = new NovirtualDerivd(); NvirBase->print(); // auto nd1 = dynamic_cast< ...
- CentOS搭建Jellyfin影音服务器
一. 安装Jellyfin 之前介绍过Docker安装jellyfin,但Docker安装方式存在一些限制,于是一起学习一下用RPM包在CentOS 7下安装方法. 先安装需要的依赖: yum ins ...
- Django项目目录结构
- Android 13 - Media框架(23)- ACodecBufferChannel
关注公众号免费阅读全文,进入音视频开发技术分享群! 这一节我们将了解 ACodecBufferChannel 上一节我们了解到input buffer 和 output buffer 是如何分配的了, ...
- 使用Docker安装Odoo 17(非Docker Compose)
使用Docker安装Odoo 17(非Docker Compose) 前言 最近在学习Odoo,先是windows 安装企业版,多年不用windows的服务器操作系统,一看windows的ECS那么贵 ...