Bike Sharing Analysis(二)- 假设检验方法
假设检验
假设检验是推论统计学(inferential statistics)的一个分支,也就是对一个较小的、有代表性的数据组(例如样本集合)进行分析与评估,并依此推断出一个大型的数据组(例如人口)的一般性结论。一个典型的例子如:估算一个国家中居民的平均身高(在这个场景下,也就是人口)。在估算时,可能会在1000个人(也就是样本)中进行分析以及评估,然后对整个国家里的居民平均身高进行估算。
假设检验尝试解决的问题:一个特定的假设值是否与直接分析(或评估)获取的值处于一致。
一般来说,假设检验的步骤如下:
1. 定义null 与 alternative hypotheses:
在第一步中,会定义一个null hypothesis(记为H0)。这里我们定义H0为:某国的人口平均身高为175cm。这个假设是需要之后通过统计测试进行测试的假设。Alternative hypothesis(记为Ha)由null hypothesis 的补全完整性声明组成,在这个例子中,alternative hypothesis Ha 为:平均身高不为175cm。null hypothesis 和 alternative hypothesis 永远都是相互补全的。
2. 确立合适的检验统计量:
检验统计量是基于样本计算出的一个量。它的值是决定接收或是拒绝null hypothesis 的基准。在大部分情况下,它可以由下面的公式计算得出:

这里sample statistic(样本统计值)是在样本上计算得出的统计值(在这个例子中,就是1000个样本居民的平均身高);
value under null hypothesis(null hypothesis 下的值),假设 null hypothesis成立时的值(在这个例子中,也就是175cm);
standard error of sample statistic(样本统计值的标准差),是样本的标准误差。
一旦test statistic 确定并计算得出后,我们需要决定它遵循什么样的概率分布。在大部分情况下,会使用如下概率分布:
- t-分布(Student’s t-distribution),对应t-检验(t-test)
- 标准正态分布(Standard normal)或z-分布(z-distribution),对应z-检验(z-test)
- 卡方分布(Chi-squared distribution),对应卡方检验(chi-squared test)
- F-分布(F-distribution),对应F-检验(F-tests)
在选择使用哪个分布时,取决于样本的大小以及检验的类别。根据经验,如果样本大小超过30,我们预期“中心极限定理的假设成立“,所以检验统计(test statistic)遵循一个标准分布(所以使用z-检验)。对于更保守的办法,或是对于小于30个样本,应使用t-检验(检验统计遵循Student’s t-分布)
3. 指定显著性水平(significance level):
在检验统计量(test statistic)计算得出后,我们需要决定是否能拒绝null hypothesis。在执行时,我们首先指定一个显著性水平(significance level),也就是拒绝一个正确的null hypothesis 的概率。一般的方法是指定5% 的显著性水平。这个意思是:null hypothesis 为正确的,但是我们有5% 的概率拒绝它(对于更保险的方法,我们可以使用1% 或甚至0.5%)。一旦一个显著性水平被指定后,我们需要计算拒绝点(rejection points),他们是用于与检验统计量进行对比的值。如果检验统计量(test statistic)大于指定的拒绝点,则我们可以拒绝 null hypothesis 并假设 alternative hypothesis 为真。这里我们就可以将两者区分开来
4. 双侧检验(two-sided tests):
这是在null hypothesis 假设value“等同于“一个预定义的值的时候做的检验。举个例子,全国人民的平均身高等同于175cm。在这个例子中,如果我们指定一个显著性水平为5%,则我们会有两个临界值(一正一负),它们两条尾巴的总体概率相加为5%。在计算临界值时,我们需要找到一个正态分布的两个百分比值,这两个百分比值之间的概率等同于1减去显著性水平。举个例子,如果我们假定样本的身高均值服从一个正态分布,指定检验的显著性水平为5%,则我们需要找到两个百分比数,落入它们区间之外的值的概率等于0.05。由于它的概率由两条尾巴进行分割,所以这2个百分数就是2.5 和 97.5。对于一个正态分布来说,对应的值就是-1.96 和 1.96,这就是两个临界值。所以,如果以下为真,则我们不会拒绝null hypothesis:
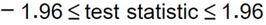
如果上面的公式不为真,那也就是说,检验统计值(test statistic)大于1.96或是小于-1.96,则我们拒绝null hypothesis
5. 单侧检验(One-sided tests):
这是在null hypothesis 假定value “大于“或是”小于“一个预定义值的时候做的检验。例如,全国人民的平均身高高于175cm。在这个例子中,如果我们指定一个显著性水平为5%,则我们将仅有一个临界值,它的尾巴的概率等同于5%。在找这个临界值时,我们需要找到一个正态分布的一个百分数,对应的是尾部概率等于0.05 的值。对于”大于“类型的检验,临界值对应于5-分位数,或是-1.645(若是检验遵从一个正态分布);对于”小于“类型的检验,临界值对应为95-分位数,或是1.645。所以,若是以下为真,则我们会拒绝null hypothesis(”大于“检验的情况):

反之,对于“小于“检验的类型,若是以下公式为真,则我们拒绝null hypothesis:

需要注意的是,通常情况下,相对于计算一个特定显著性水平的临界值,我们会使用检验的 p 值(p-value)。p值是在null hypothesis可以被拒绝时的最小显著性水平。p 值也提供了,在null hypothesis 为真的情况下,获取观测到的样本统计量的概率。如果获取的 p 值小于一个指定的显著性水平,则我们可以拒绝null hypothesis。所以p值的方法,在实际使用中,是另一个(大多数情况下也是更方便的一个)执行假设检验的方法。
下一章我们会使用 Python 来演示一个实际执行假设检验的例子。
Bike Sharing Analysis(二)- 假设检验方法的更多相关文章
- Kaggle Bike Sharing Demand Prediction – How I got in top 5 percentile of participants?
Kaggle Bike Sharing Demand Prediction – How I got in top 5 percentile of participants? Introduction ...
- PGM学习之二 PGM模型的分类与简介
废话:和上一次的文章确实隔了太久,希望趁暑期打酱油的时间,将之前学习的东西深入理解一下,同时尝试用Python写相关的机器学习代码. 一 PGM模型的分类 通过上一篇文章的介绍,相信大家对PGM的定义 ...
- linux杂记(十二?) 关于账号和密码的二三事
关于密码的二三事 关于账号和密码的二三事 久了不更linux的相关知识,实在是懒得想内容点(纯粹是懒).那么今天就来谈谈关于linux密码和账号的重要概念. 假如你的主机遭到入侵,那么对方的第一个侵入 ...
- 《MySQL面试小抄》索引考点二面总结
<MySQL面试小抄>索引考点二面总结 我是肥哥,一名不专业的面试官! 我是囧囧,一名积极找工作的小菜鸟! 囧囧表示:小白面试最怕的就是面试官问的知识点太笼统,自己无法快速定位到关键问题点 ...
- T检验与F检验的区别_f检验和t检验的关系
1,T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定. 通过把所得到的统计检定值,与统计学家建立了一 ...
- 通俗理解T检验和F检验
来源: http://blog.sina.com.cn/s/blog_4ee13c2c01016div.html 1,T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总 ...
- 通俗理解T检验与F检验的区别【转】
转自:http://blog.sina.com.cn/s/blog_4ee13c2c01016div.html1,T检验和F检验的由来一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错 ...
- 统计学常用概念:T检验、F检验、卡方检验、P值、自由度
1,T检验和F检验的由来 一般而言,为了确定从样本(sample)统计结果推论至总体时所犯错的概率,我们会利用统计学家所开发的一些统计方法,进行统计检定. 通过把所得到的统计检定值,与统计学家建立了一 ...
- SparkMLlib学习之线性回归
SparkMLlib学习之线性回归 (一)回归的概念 1,回归与分类的区别 分类模型处理表示类别的离散变量,而回归模型则处理可以取任意实数的目标变量.但是二者基本的原则类似,都是通过确定一个模型,将输 ...
- python数据统计分析
1. 常用函数库 scipy包中的stats模块和statsmodels包是python常用的数据分析工具,scipy.stats以前有一个models子模块,后来被移除了.这个模块被重写并成为了 ...
随机推荐
- HZ2023 远足游记
你说得对,但是我放假之前写的 P4689 代码没了 所以来摆 4.6(远足) 上午 走路,刚开始感觉没啥 走到园博园发现没预料中那么顺利 但是还感觉没啥 因为也没预料到 \(N·m\) 学校会让我们原 ...
- 【GUI开发】用python爬YouTube博主信息,并开发成exe软件!
目录 一.背景介绍 二.代码讲解 2.1 爬虫 2.2 tkinter界面 2.3 存日志 三.说明 一.背景介绍 你好,我是@马哥python说,一名10年程序猿. 最近我用python开发了一个G ...
- 深入学习和理解Django模板层:构建动态页面
title: 深入学习和理解Django模板层:构建动态页面 date: 2024/5/5 20:53:51 updated: 2024/5/5 20:53:51 categories: 后端开发 t ...
- gin 图片上传到本地或者oss
路由层 func registerCommonRouter(v1 *gin.RouterGroup) { up := v1.Group("upload") { up.POST(&q ...
- IceRPC之服务器地址与TLS的安全性->快乐的RPC
作者引言 很高兴啊,我们来到了IceRPC之服务器地址与TLS的安全性->快乐的RPC, 基础引导,让自已不在迷茫,快乐的畅游世界. 服务器地址 ServerAddress 了解服务器地址的概念 ...
- C语言:渔夫捕鱼算法问题
题目:渔夫捕鱼 A,B,C,D,E五个渔夫夜间合伙捕鱼,,第二天清A先醒来,他把鱼均分五份,把多余的一条扔回湖中,便拿了自己的一份回家了,B醒来后,也把鱼均分五份,把多余的一条扔回湖中,便拿了自己的一 ...
- ASP.NET Core的全局拦截器(在页面回发时,如果判断当前请求不合法,不执行OnPost处理器)
ASP.NET Core RazorPages中,我们可以在页面模型基类中重载OnPageHandlerExecuting方法. 下面的例子中,BaseModel继承自 PageModel,是所有页面 ...
- Kmesh进入CNCF云原生全景图,实现网格治理sidecarless化
本文分享自华为云社区<Kmesh进入CNCF 云原生全景图> ,作者:云容器大未来. 近日,Kmesh 正式进入 CNCF 云原生全景图,位于 Service Mesh 类别下. CNCF ...
- NumPy 随机数据分布与 Seaborn 可视化详解
随机数据分布 什么是数据分布? 数据分布是指数据集中所有可能值出现的频率,并用概率来表示.它描述了数据取值的可能性. 在统计学和数据科学中,数据分布是分析数据的重要基础. NumPy 中的随机分布 N ...
- 高分辨率食道测压(HRM)
高分辨率测压(High resolution Manometry) HRM的优势 高分辨率食管测压不但实现了从咽部到胃部的全程功能监测,而且插管无需牵拉,操作十分方便.更为重要的是,临床医生经过简单的 ...