墨天轮访谈 | OceanBase 白超:海量数据管理,为什么选择OceanBase?
分享嘉宾:白超(大窑) OceanBase解决方案架构师、前蚂蚁集团数据库团队DBA专家
整理:墨天轮社区
导 读
大家好,我是白超(花名:大窑),在过去的几年中,作为蚂蚁集团数据库SRE团队成员,经历了历年的双11大促,深度参与了交易支付、数字金融、国际站点等多个业务的数据库存储架构升级工作。今天分享的内容包含两个方面,一是介绍OceanBase的技术架构特点,另一方面也想从蚂蚁集团自身业务演进发展的角度来谈谈,为什么OceanBase是互联网行业海量数据并发业务需求的必然选择。
互联网行业数据库面临的挑战
当前互联网行业对于数据库提出了很多挑战,随着业务形态的发展演进,数据增长速度越来越快。不管是私有部署,还是云数据库,也都同样面临着规模越来越大,实例数越来越多的情况。
首先从效率上,因为DBA需要运维的实例数更多了。不同的业务线,不同的应用,面临不同问题的时候,DBA 的幸福感是很低的,时间是碎片化的。对于业务来说,感知就是数据库本身的容量防御能力不足,应急时效也难以保证,比如电商大促、直播、秒杀等场景上,很多时候支撑能力是不够的。
其次在成本上,数据增长的速度是非常快的。尤其从疫情发生以来,很多场景线上化的趋势更加明显。包括线上支付,线上购物等场景越来越多。从而引发的订单数量,以及用于实时分析的场景数据增速明显加快。在此场景下,体现到数据库资源上会发现机器需求增多,与之对应的存储需求增大,但CPU利用并不充分。尤其遇到节日促销或类似双11,618等并发场景备战时,是需要提前做扩容,往往需要提前很长时间就开始准备机器资源。
第三,传统的单机数据库,比如Oracle或者互联网行业常用的MySQL都有一些痛点,是不得不面对的。比如数据量太大时,很多时候就要选择拆库,在这个过程中又要引入中间件,本身增加了一定的复杂度会侵入业务,对于DBA又添加了一些新的挑战。比如随业务发展表变得很大,需要做一些DDL表结构的变更。在传统数据库的场景下,这些变更都会存在较大的风险,甚至有阻塞业务的可能。
再比如说缓存穿透,高连接数达到数据库极限;主备切换看似成功了,其实只是集群层面成功,DNS或者虚拟IP等并没有切换成功;容灾场景下的脑裂,丢数据问题等这些都是在过去使用传统数据库时面临的常见问题。
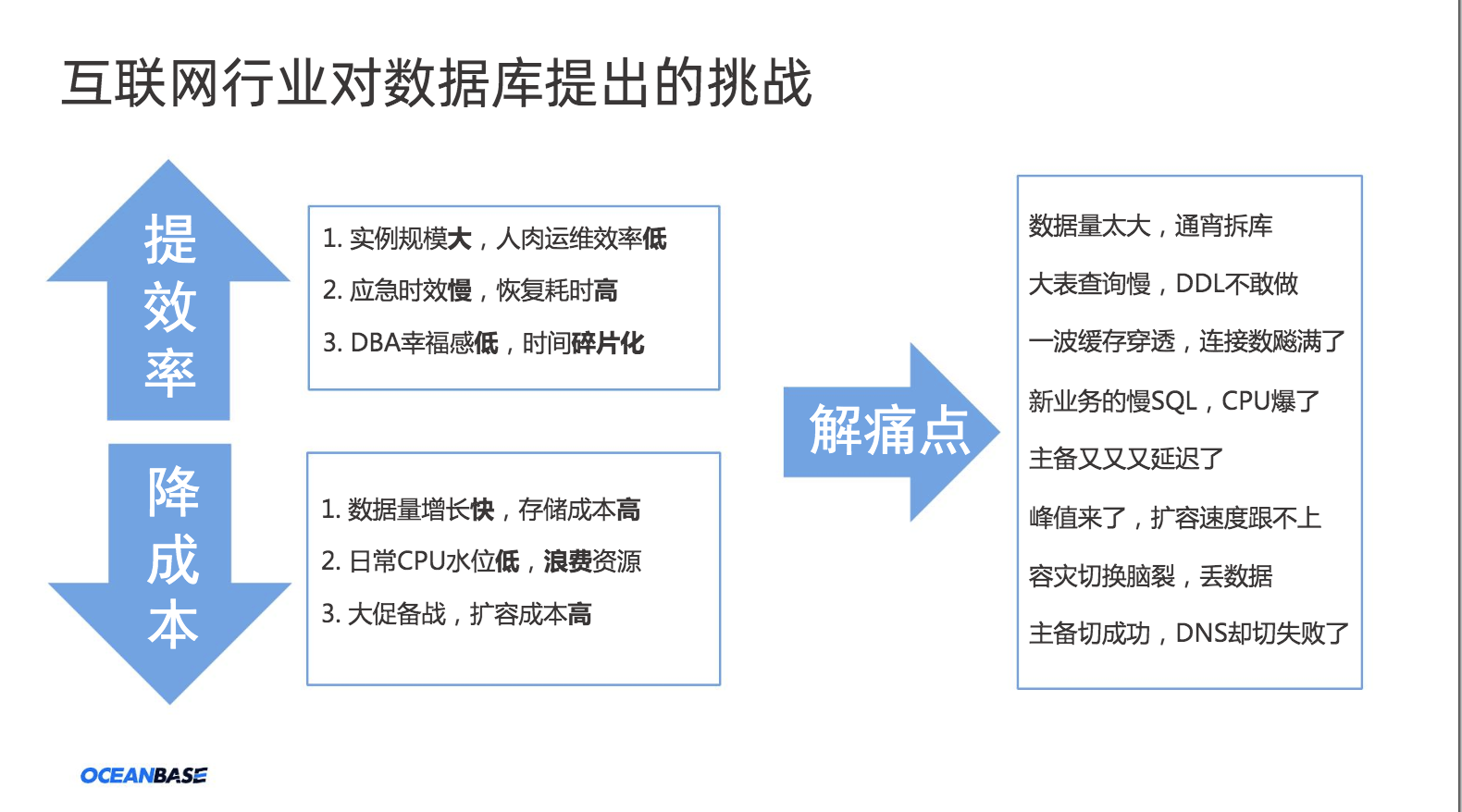
图1 互联网行业下数据库的挑战
蚂蚁数据库架构的三代升级史
随着互联网行业的发展,对数据库提出了越来越高的要求——除了“提效率”与“降成本”,还有“解痛点”。 传统数据库在处理业务需求时遇到了很多的问题,这些问题在蚂蚁也都经历过,首先我来简单讲讲蚂蚁集团数据库的演进过程。
第一代数据架构是构建在IOE的基础之上——IBM的小型机、Oracle的商业数据库,还有EMC的共享存储。随之带来的运维成本非常高,同时稳定性的挑战也非常大的。随着业务的快速发展,这套架构已经完全没有办法适应业务发展的增速。
以当时的支付宝为例,因为它本身金融交易的属性,拥有非常大规模的Oracle RAC集群,然而这种架构本身的扩容是有上限的,当扩容一定规模的情况时,数据库性能的边际效应已经非常明显了,无法再提升数据库的容量,这些都是业务增长情况下必须要面对的问题。
因此从支付宝业务发展的角度出发,为了解决这些问题,蚂蚁数据库整体架构演进到第二阶段:中间件+拆分+单元化。
随之诞生的是第二代架构,第二代架构的主体仍然是传统单机数据库——也就是Oracle和部分MySQL,加上蚂蚁自研的分布式中间件,某种程度上解决了业务的水平和垂直的扩展能力。但即便如此仍然有不少难题亟待解决,例如:机房级故障的快速恢复和强一致性保障、跨库跨分片事务、全局一致性、自动负载均衡以及复杂SQL的执行能力。
业务井喷式的发展对底层的数据库提出了更高的要求,这些要求包括更高的稳定性,快速恢复能力和极致的弹性能力等,为了解决这些问题,我们需要的是一套全新的方案和架构,也就最终演进到了以OceanBase为核心的第三代数据存储底盘。
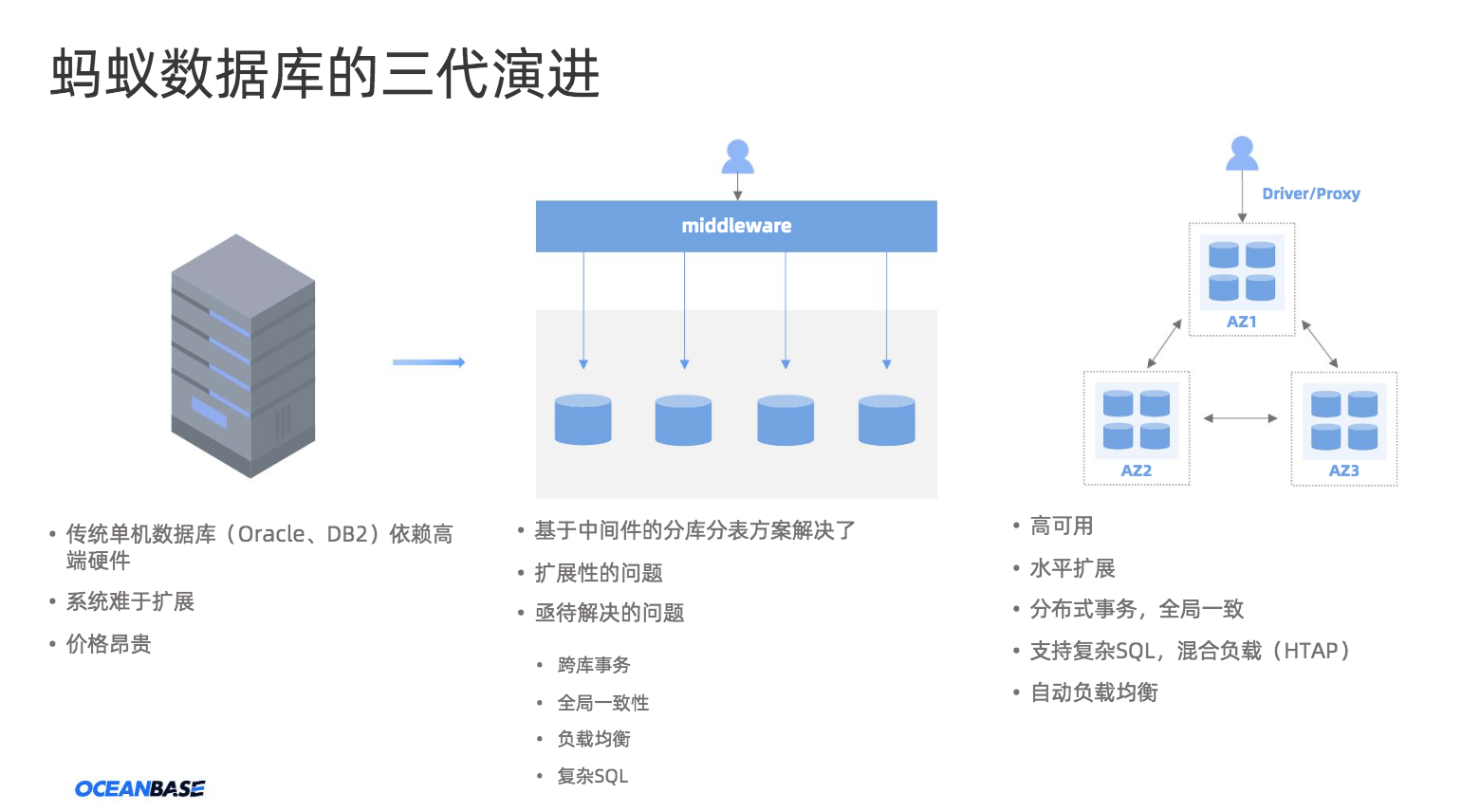
图2 蚂蚁数据库的三代演进
OceanBase 集群架构
ceanBase 是不基于任何开源产品,完全自研的原生分布式关系数据库。下面我将进一步介绍OceanBase是如何在高速增长业务中,在一个个真实的业务需求下不断创新和打磨的,首先我们来看OceanBas的集群架构。
OceanBase是一个存储无共享的架构,如下图例子所示,这个OceanBase集群中有6台OBServer被分成了3个Zone,在实际部署中可能这三个Zone会存在于三个机房,其中Zone1、Zone2、Zone3的数据是完全对等的,这样设计的能够实现当任意一个机房不可用时,出现断电或者网络“孤岛”现象时,也不会影响OB整体对业务应用的服务。因此第一个特点是OceanBase集群架构中所有的节点都是对等的,每个节点有独立的管控、SQL、事务以及存储引擎,整个系统没有任何单点。
OceanBase中的数据以分布式的方式进行存储,这样为数据库的线性扩展性提供了理论基础,自动实现访问路由、策略驱动负载均衡。同时OceanBase的集群架构还具有高可用和强一致的特性,通过multi-Paxos分布式协议的工程实现,确保数据(日志)持久化在多数派节点成功,少数派故障时能够做到数据不丢失,故障转移自动完成。
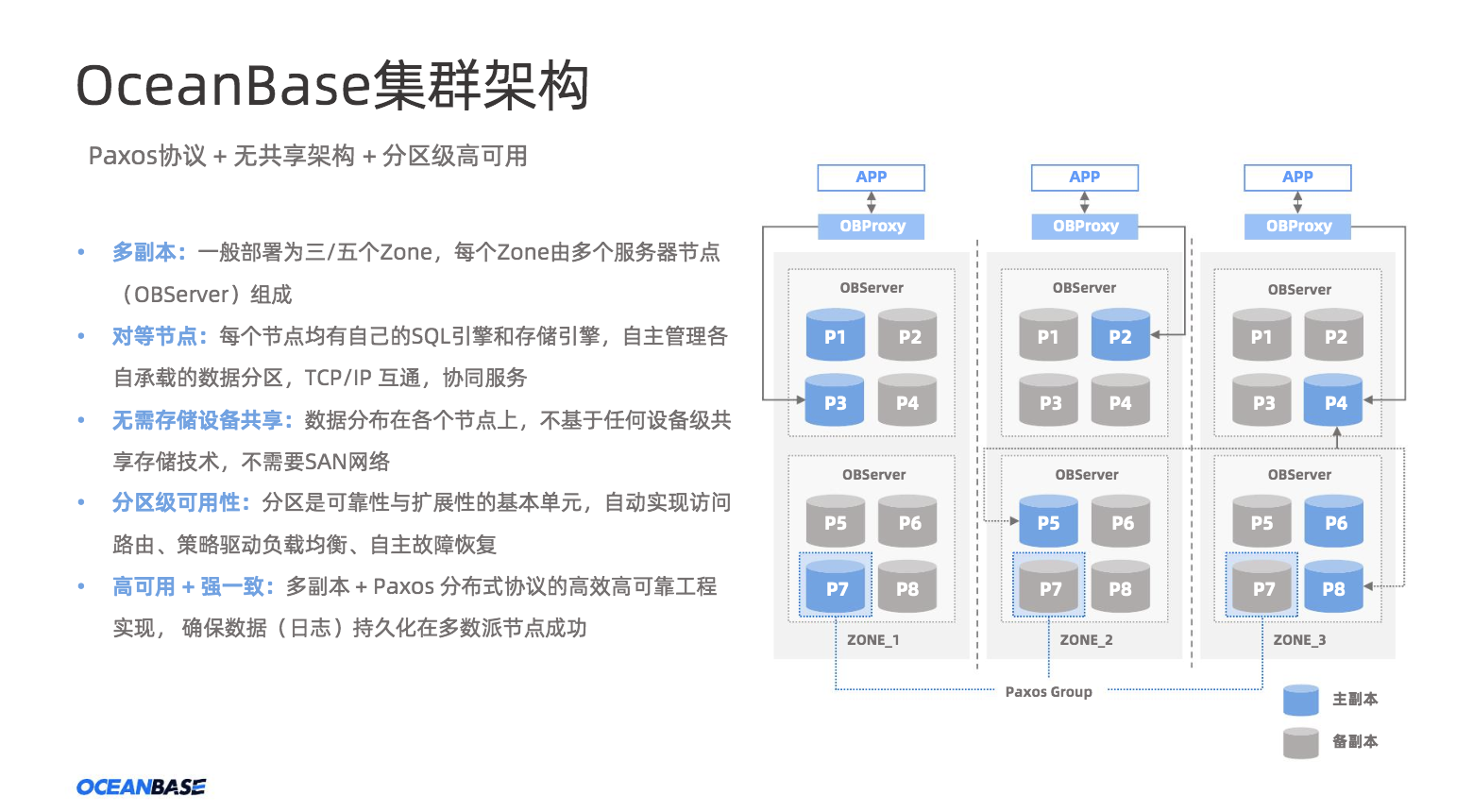
图3 OceanBase 集群架构
OceanBase 如何支撑海量并发的互联网业务?
1、OceanBase 的特性与优势
OceanBase的第一个特性是多租户+存储压缩,能够大幅提高资源利用率,降低成本。
大集群将长尾应用的多实例MySQL/Oracle统一进行管理,有效提高资源密度,消除存储碎片。同时多租户的特性实现数据库内核级虚拟化,满足数据安全隔离的同时,提供基于业务画像的可伸缩计算资源、同时通过Leader打散实现混部。
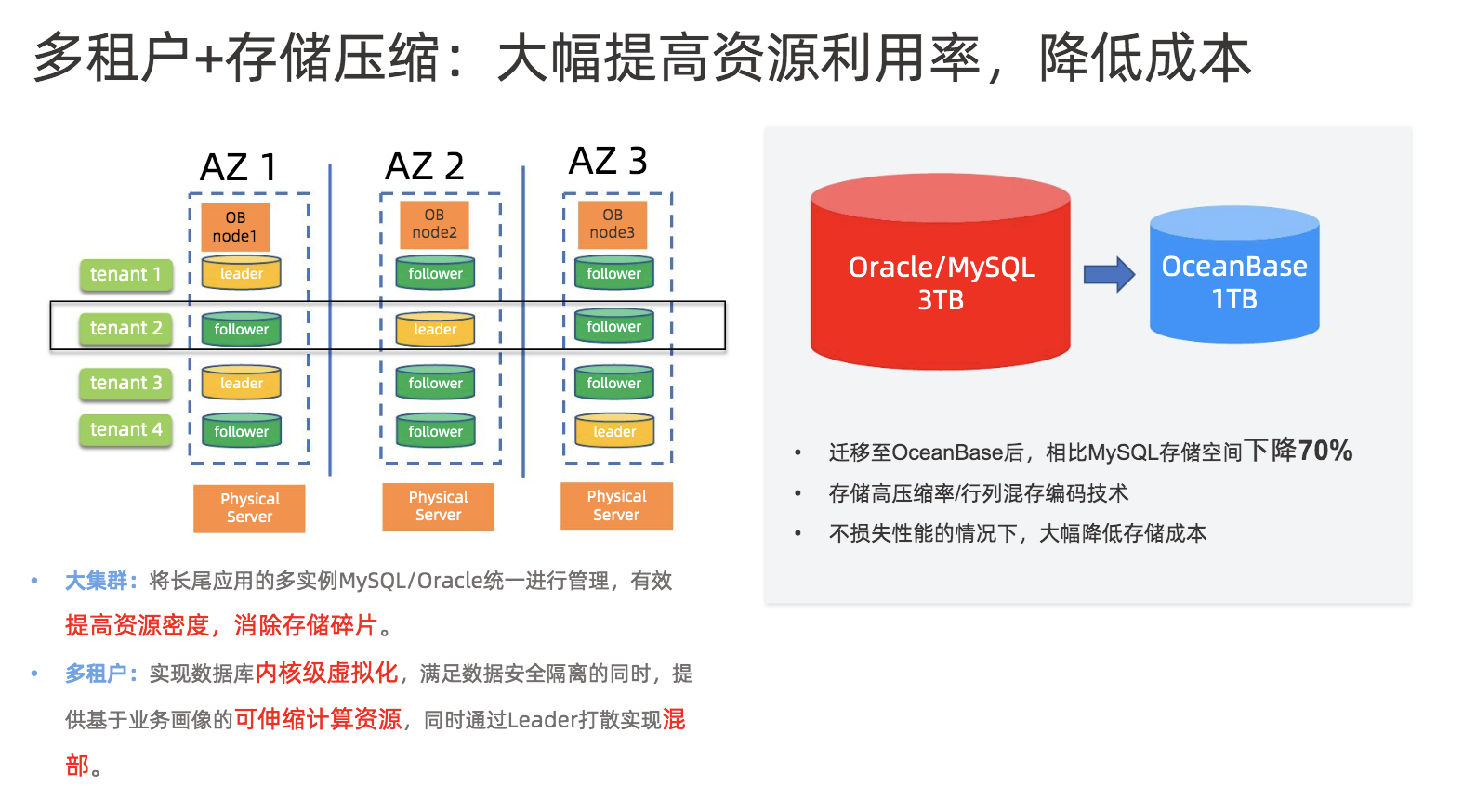
图4 OceanBase 特性:多租户+存储压缩
OceanBase 数据库使用基于 LSM-Tree 的存储引擎,能够有效地对数据进行压缩,并且不影响性能,可以降低用户的存储成本。
在支撑支付宝某业务从Oracle迁移到OceanBase中,实现了数据库占用存储区空间由100TB减少到33TB。
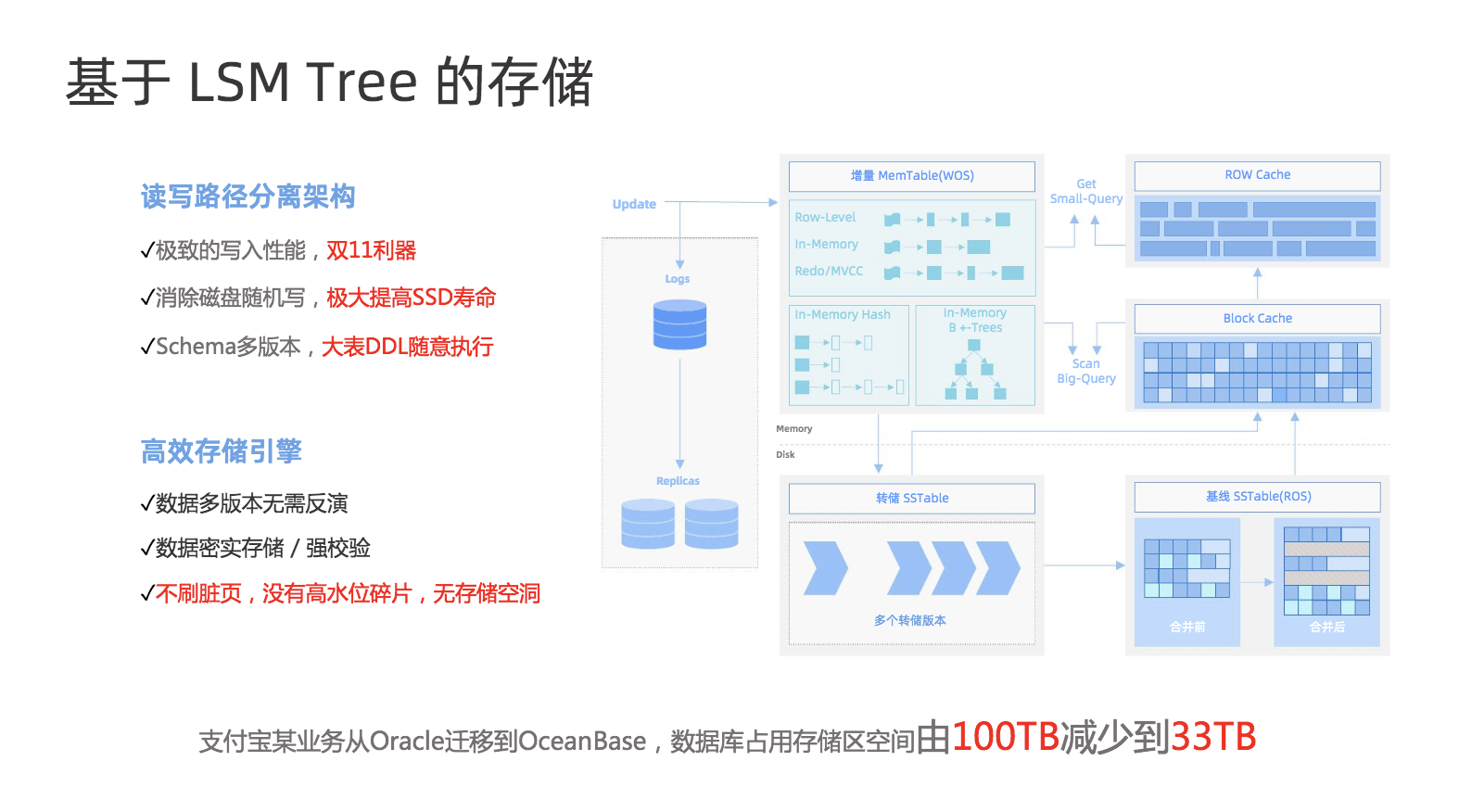
图5 OceanBase 基于LSM Tree的存储
此外,OceanBase能够原生的实现水平无限扩展与迁移均衡流控。
在水平扩展过程中仅需OCP发起操作,内核负责数据迁移和内部强校验,当均衡完成后新的节点自动开始提供服务。同时OceanBase的数据均衡迁移速度远高于传统数据库逻辑迁移的速度。

图6 OceanBase 特性:水平无限扩展+迁移均衡流控
在上面的内核特性支撑下,OceanBase得以实现快速的弹性扩缩容。如下图所示,当需要扩容时,能够快速地将数据水平负载均衡至下方的新添加三个节点,由此实现集群翻倍的读写能量,过程中对应用透明,区别于传统数据库单点写的架构,OceanBase可以实现全副本的leader 打散,这也为超高并发写入的业务提供了基础。
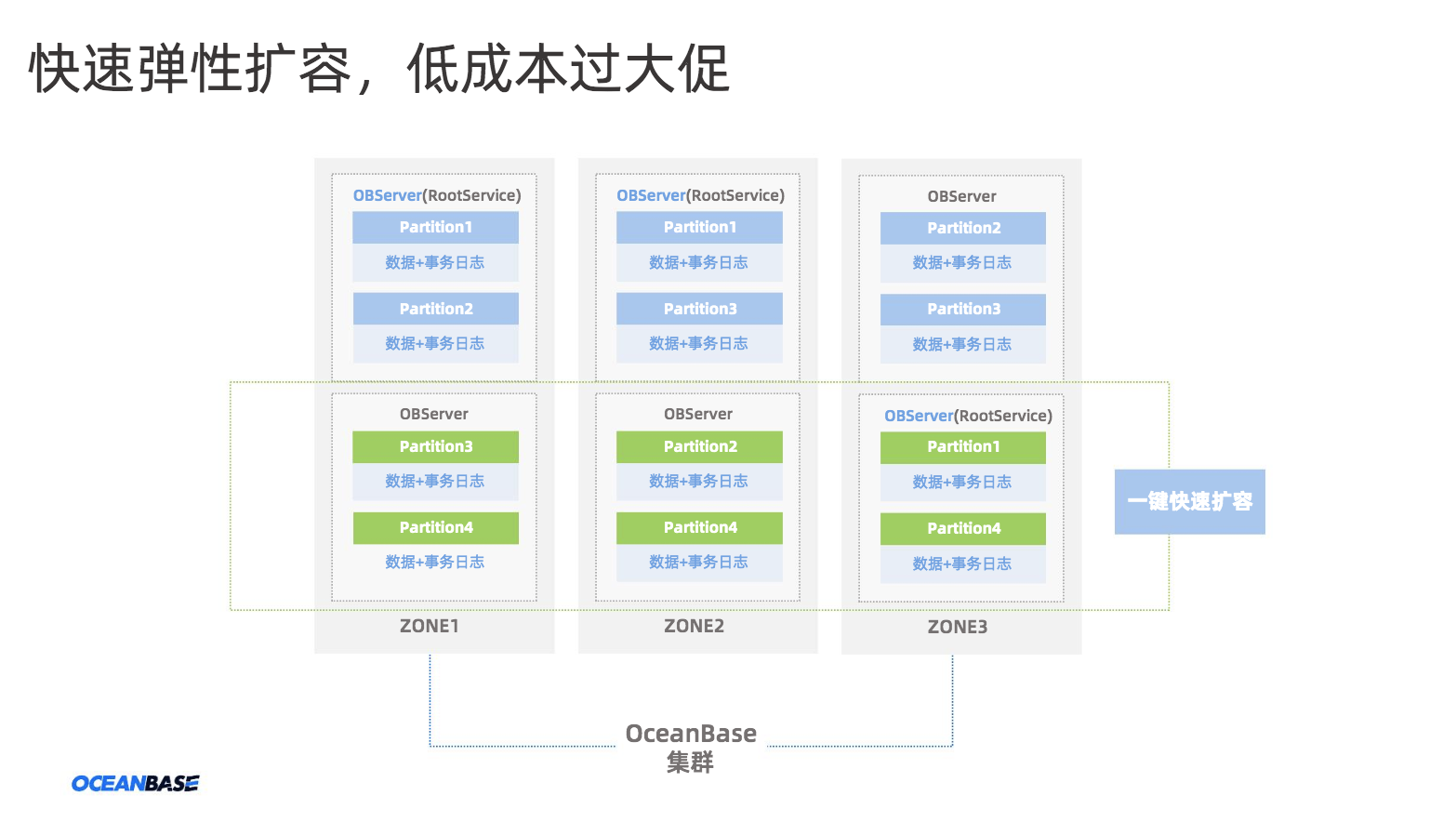
图7 OceanBase 特性:快速弹性扩容
不仅如此,OceanBase在多副本上实现的读写分离的能力,大大提升了数据库读扩展能力的同时,AP类的报表分析不影响在线业务。
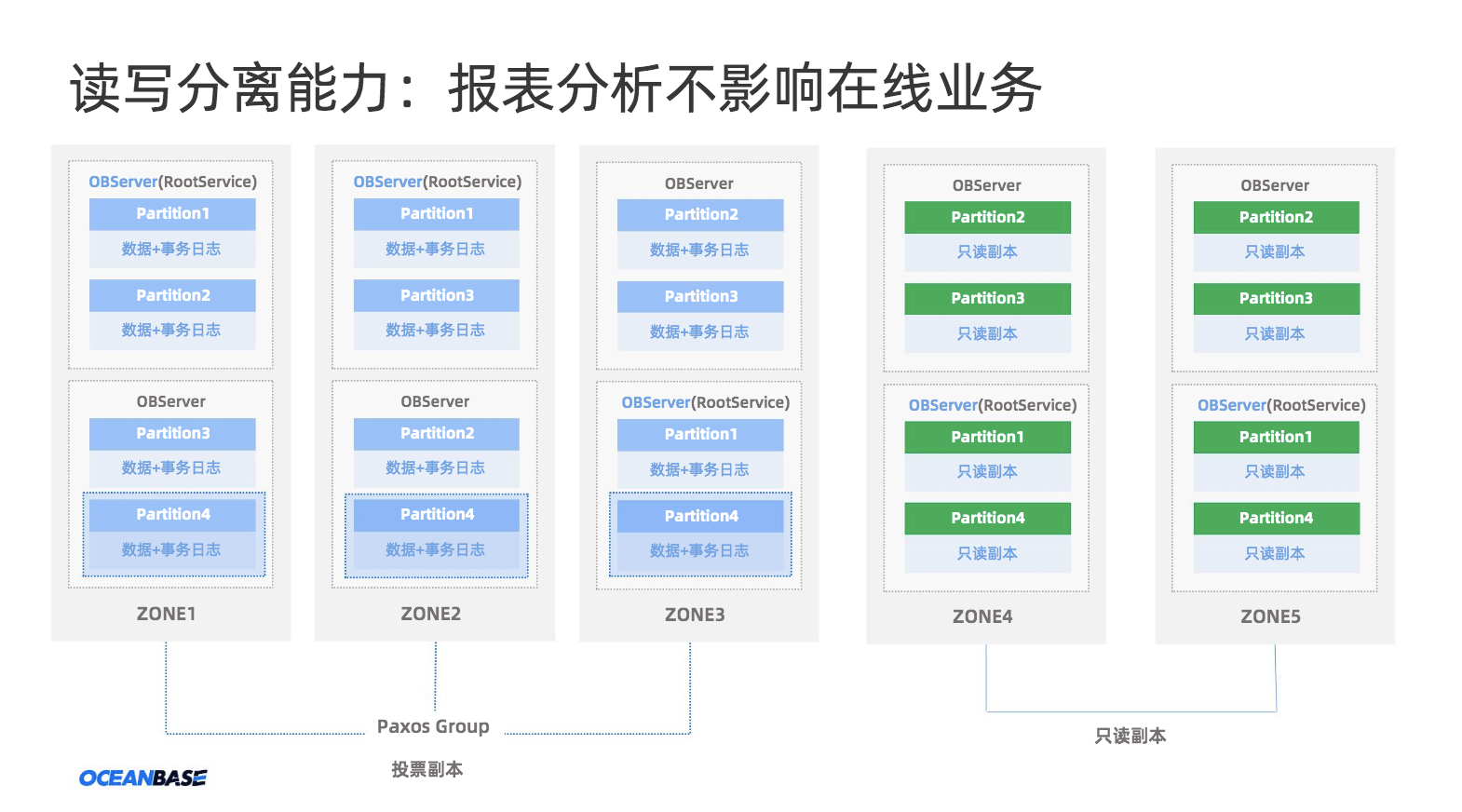
图8 OceanBase 实现读写分离
OceanBase 的稳定性高可用特性,帮助业务实现强一致自动容灾、宕机自动恢复。当业务从传统数据库迁移至OceanBase后,数据库相关故障频率平均下降80%,同时遇到异常抖动和基础设施故障,真正实现“先恢复、后诊断”。
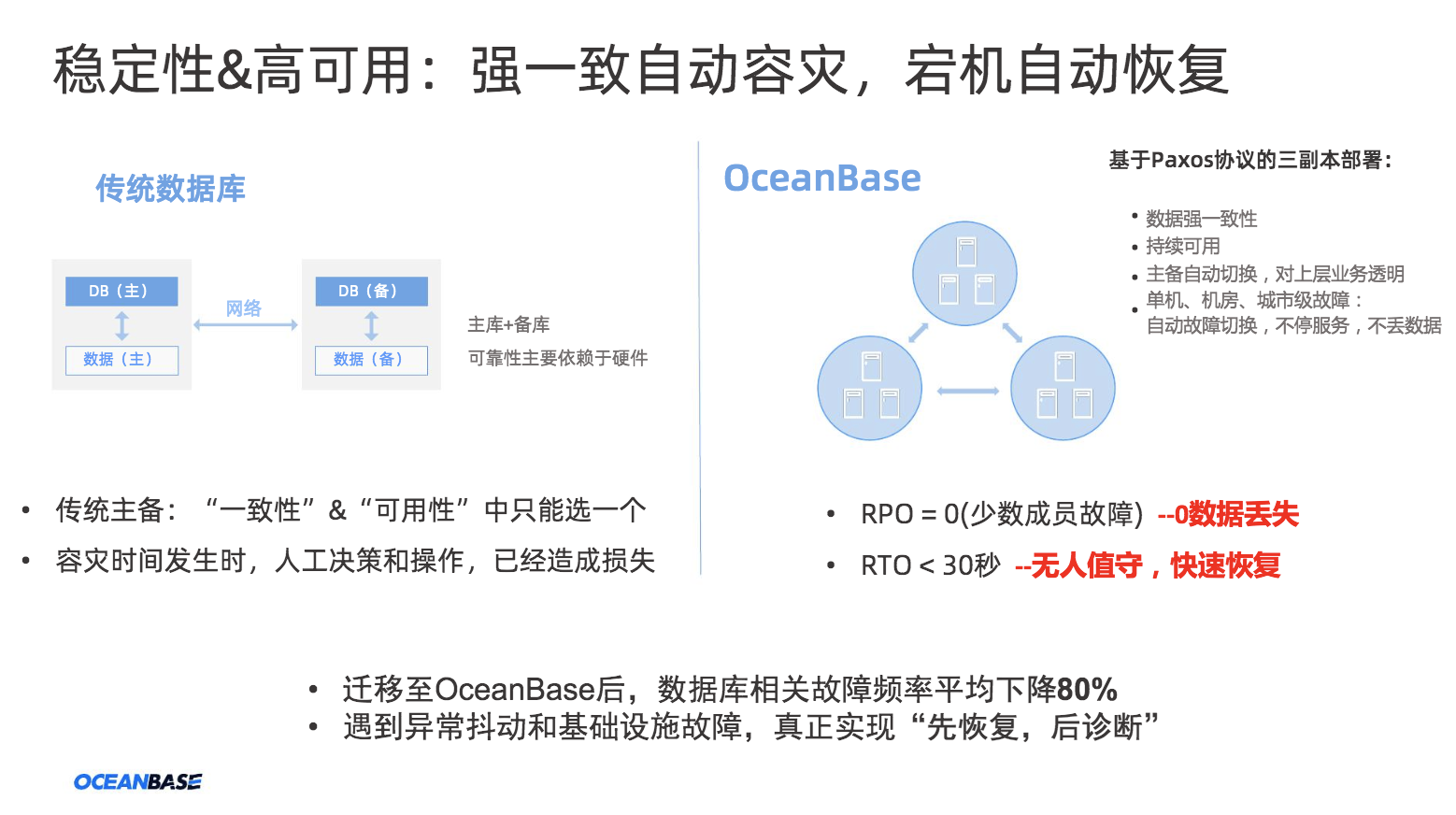
图9 OceanBase 特性:稳定性&高可用
2、一站式管理平台OCP 实现智能化运维
接下来想谈一谈ob在智能化运维的一些能力。OCP是OceanBase提供的面向DBA的一站式管理平台,让分布式的数据库管理变轻松,实现健康巡检、全集群日志在线分析、监控下钻分析以及智能运维体系 SQL诊断。
其中重点值得强调的是基于OB内核对在线SQL的管控能力,结合OCP的智能诊断功能,DBA可以在问题发生期间快速定位问题SQL,并执行一系列并发限流、熔断、执行计划绑定等操作,大大提高数据库应急的效率。

图10 OCP 助力效力提升
OceanBase 互联网行业应用案例
1、案例一:Gcash电子钱包全站迁移
Gcash电子钱包全站迁移到OceanBase,实现存储空间下降70%,故障业务不中断、成本降低30%的可观效果,同时在云控制台的加持下,DBA运维效率大幅提升。
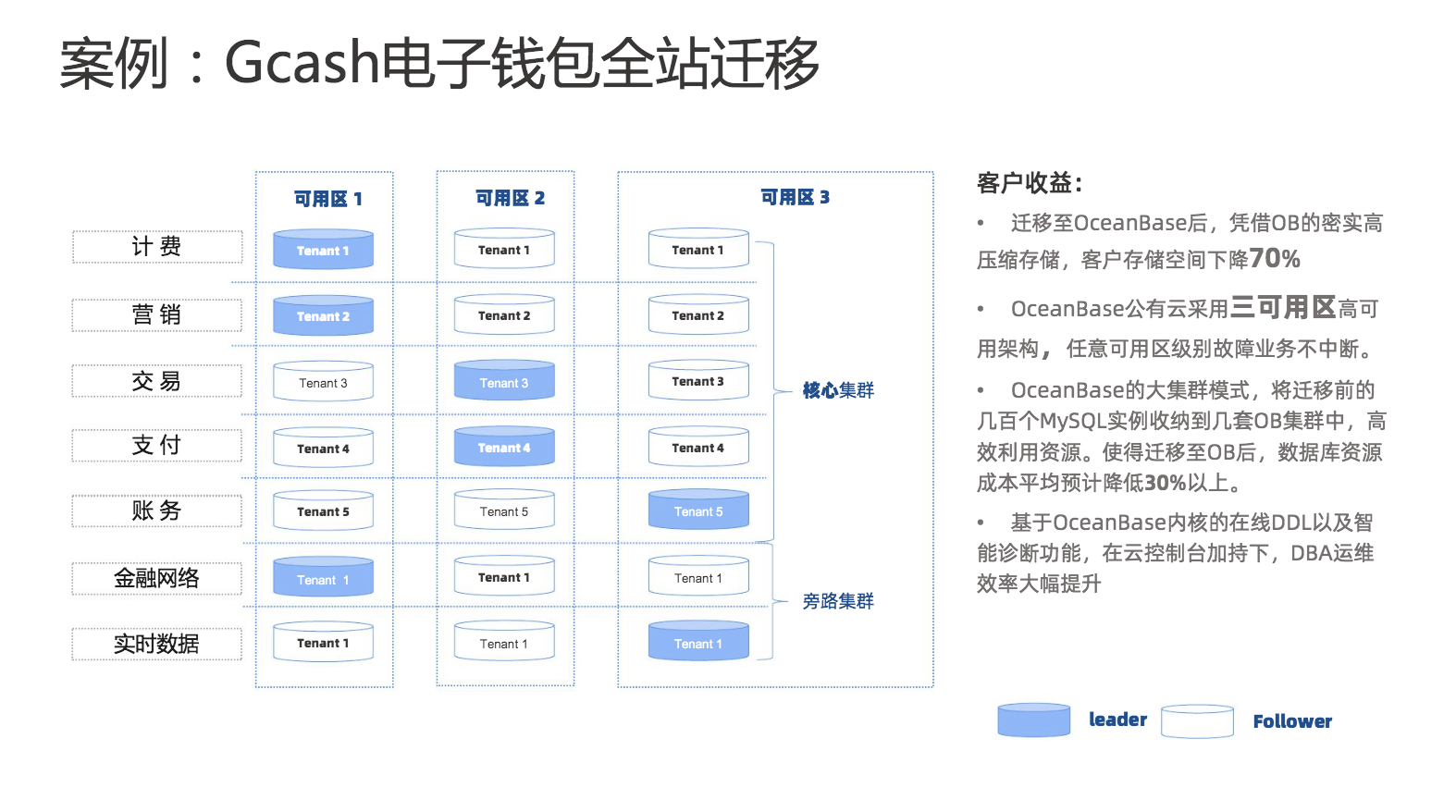
图11 案例:Gcash电子钱包全站迁移
2、案例二:某交通出行行业HTAP架构
在某交通出行行业HTAP架构的案例中,迁移至OceanBase帮助性能容量提升3倍,帮助客户解决了随着业务发展着断拆库的苦恼,大幅提升存储可扩展性等痛点。
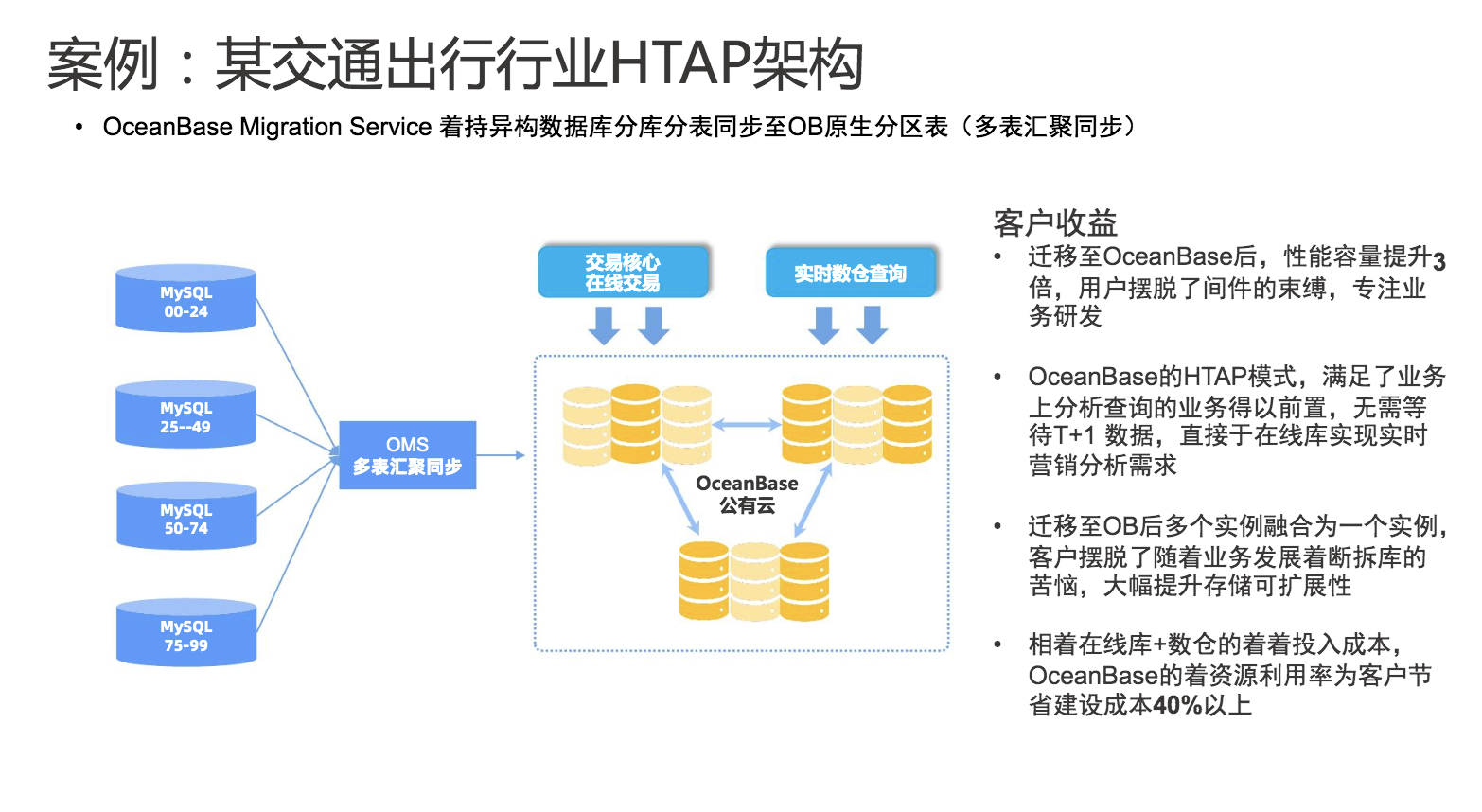
图12 案例:某交通出行行业HTAP架构
3、案例三:菜鸟发货工作台复杂业务实时查询
在菜鸟发货工作台的应用案例中,依托OceanBase的HTAP特性,助力客户提升海量存储下的写入和更新性能;同时依托OceanBase分布式并行执行引擎,通过简单的扩容操作即可近似线性提升复杂分析查询的性能。
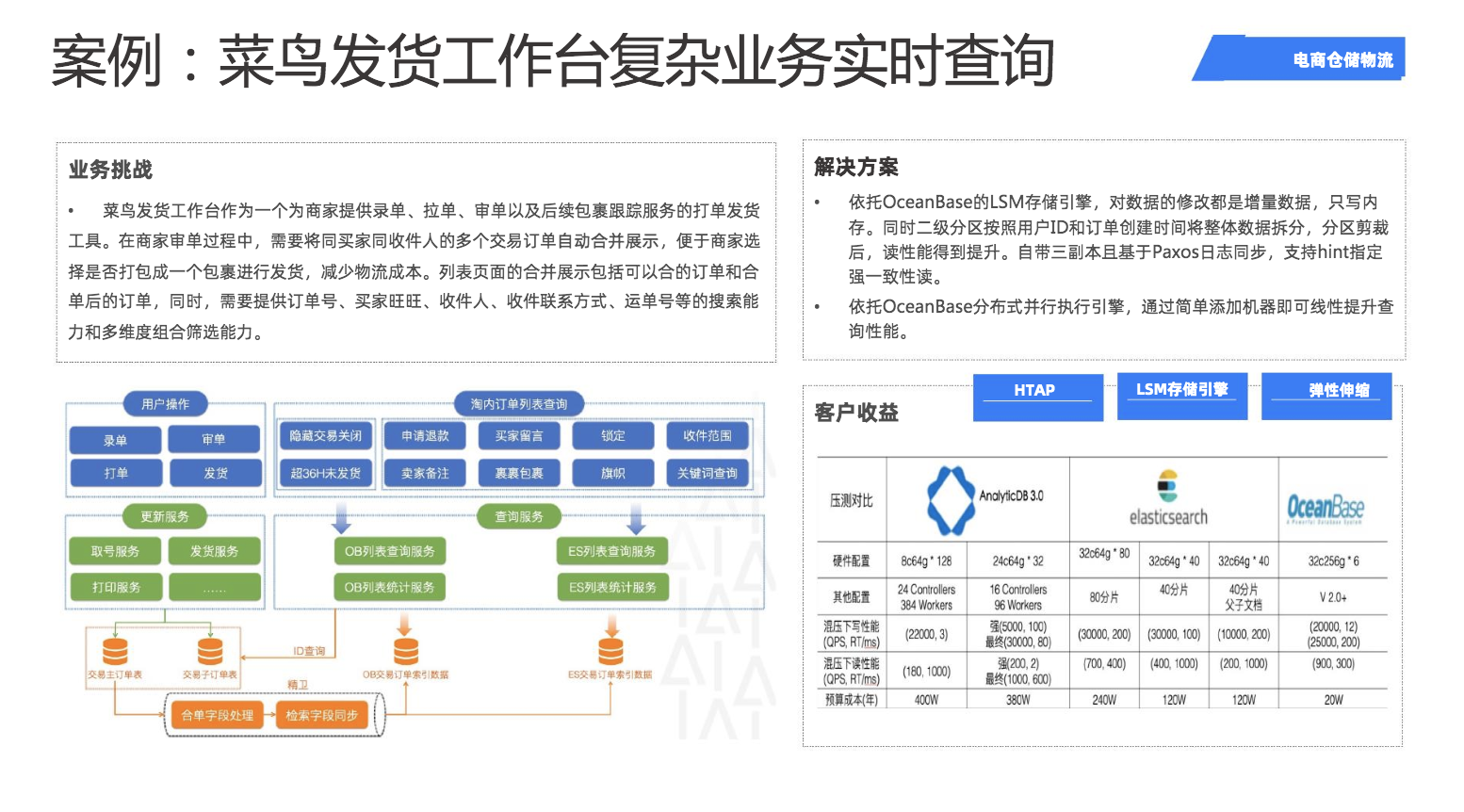
图13 案例:菜鸟发货工作台复杂业务实时查询
作为原生分布式数据库的开拓者,OceanBase 致力于从根本上解决海量数据管理的核心问题。未来,OceanBase 将不断突破关键技术瓶颈,不断创造数据管理技术的新未来。
下图是OceanBase在泛互行业的最佳实践汇总。很多面向实际业务的优秀特性例如自适应限流、大查询队列、快速自愈等等,由于时间关系,不在今天一一展开,大家有兴趣欢迎在我们的官网社区展开讨论。

图14 案例:OceanBase在泛互行业的最佳实践汇总
我今天的分享就到这里,谢谢大家!
更多精彩内容,欢迎大家观看现场视频回放与会议资料
视频回放:https://www.modb.pro/video/6329
会议资料:https://www.modb.pro/doc/60566
- 查看原文:https://www.modb.pro/db/400424
- 查看【国产数据库沙龙】互联网行业应用专场文章、视频回放资源:https://www.modb.pro/topic/399271
欲了解更多可以进入墨天轮,围绕数据人的学习成长提供一站式的全面服务,打造集新闻资讯、在线问答、活动直播、在线课程、文档阅览、资源下载、知识分享及在线运维为一体的统一平台,持续促进数据领域的知识传播和技术创新。
关注官方公众号: 墨天轮、 墨天轮平台、墨天轮成长营、数据库国产化 、数据库资讯
墨天轮访谈 | OceanBase 白超:海量数据管理,为什么选择OceanBase?的更多相关文章
- OceanBase数据库实践入门——手动搭建OceanBase集群
前言 目前有关OceanBase功能.案例.故事的文章已经很多,对OceanBase感兴趣的朋友都想安装一个数据库试试.本文就是分享初学者如何手动搭建一个OceanBase集群.这也是学习理解Ocea ...
- OceanBase
OceanBase 编辑 本词条缺少名片图,补充相关内容使词条更完整,还能快速升级,赶紧来编辑吧! OceanBase是一个支持海量数据的高性能分布式数据库系统,实现了 数千亿条记录.数百TB数据上的 ...
- 一款基于 Web 的通用数据管理工具(转载)
一款基于 WEB 的通用数据管控工具 - CloudQuery 前言 前段时间,公司因为业务发展,数据量攀升,老板迫切需要一个工具对数据进行精细化管理,一是确实需要精细化管理:二是因为我们公司小,数据 ...
- DBA_Oracle海量数据处理分析(方法论)
2014-12-18 Created By BaoXinjian
- 巨杉Talk | 拒绝数据碎片化,原生分布式数据库灵活应对数据管理需求
2019年7月19-20日,以“运筹帷幄,数揽未来”为主题的DAMS中国数据智能管理峰会在上海青浦区成功举办.在DAMS峰会上,巨杉数据库为大家带来了题为“云架构下的分布式数据库设计与实践”的主题分享 ...
- 淘宝数据库OceanBase SQL编译器部分 源代码阅读--Schema模式
淘宝数据库OceanBase SQL编译器部分 源代码阅读--Schema模式 什么是Database,什么是Schema,什么是Table,什么是列,什么是行,什么是User?我们能够能够把Data ...
- OceanBase安装
背景: OceanBase是阿里巴巴.蚂蚁金服自主研发的可扩展的分布式关系数据库,实现了数千亿条记录.数百 TB 数据上的跨行跨表事务,主要支持支付宝核心的交易.支付.会员和账务系统等 OLTP 和 ...
- 脱离OBDeploy工具,手工部署OceanBase方法
[简介] OBDeploy是OceanBase集群部署的工具,可以通过简单的几行命令,就能快速的进行OceanBase部署.但对于初学者来讲,可能会比较困惑,Deploy到底做了哪些事情?里面的具体步 ...
- Oceanbase读写分离方案探索与优化
[作者] 许金柱,携程资深DBA,专注于分布式数据库研究及运维. 台枫,携程高级DBA,主要负责MySQL和OceanBase的运维. [前言] 读写分离,是一种将数据库的查询操作和写入操作分离 ...
- oceanbase 社区版安装
# 一.环境准备|节点类别|主机名|IP||-|-|-||OBSERVER|observer1|192.168.3.41||OBSERVER|observer2|192.168.3.42||OBSER ...
随机推荐
- RHCA rh442 006 中断号 缓存命中率 内存概念 大页
IRQ均衡 硬中断 IRQ是中断号 2003 电脑 拨号 56K Modem USB 打印机 拨号成功,打印机会是乱码,他们会不兼容 因为终端号一样 (类似ip地址冲突) 在bios里面调整设备的中断 ...
- linux中whereis、which、find、locate的区别
linux中whereis.which.find.locate的区别 1. find fan路名含 find是最常见和最强大的查找命令,你可以用它找到任何你想找的文件. find的使用实例 ...
- tmux开启鼠标模式
在tmux的配置文件中进行配置: vim ~/.tmux.conf set -g mouse on
- 【转载】 PID算法的解析
原文来自DF创客社区地址:http://www.dfrobot.com.cn/community/thread-14783-1-1.html ----------------------------- ...
- 使用UltraISO克隆clone树莓派SD卡(注意不是复制、备份,是克隆)
搞了好长时间做了一个树莓派的SD卡,包括了一些自己安装的配置,为了防止哪天把这个SD卡搞坏掉(比如写数据时候断电,比如apt upgrade时掉电),于是考虑把这个SD卡进行克隆clone. 因为手上 ...
- AMiner的数据质量和完善问题
最近参加到了一个国家科技项目中,这里就不吐槽这种高校承接国家科技项目是一件多么不靠谱的事情了,这里就说说我们的对标产品"AMiner".补充一下,虽然个人对AMiner的评价不是很 ...
- 常用的php方法
/* * http 封装网络请求方法 */ /* * get method */ function get($url, $param=array()){ if(!is_array($param)){ ...
- kubernetes负载感知调度
背景 kubernetes 的原生调度器只能通过资源请求来调度 pod,这很容易造成一系列负载不均的问题, 并且很多情况下业务方都是超额申请资源,因此在原生调度器时代我们针对业务的特性以及评估等级来设 ...
- 用whl文件安装Anaconda中的GDAL
本文介绍在Anaconda环境下,基于.whl文件安装Python中高级地理数据处理库GDAL的方法. 在之前的文章中,我们介绍了基于conda install命令直接联网安装GDAL库的方法 ...
- Node.js 使用
创建 Node 项目 npm init -y # 初始化 Node 项目 package.json 文件 这个文件记录了项目的相关信息. { "name": "hello ...