火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
近日,《火山引擎云原生数据仓库 ByteHouse 技术白皮书》正式发布。白皮书简述了 ByteHouse 基于 ClickHouse 引擎的发展历程,首次详细展现 ByteHouse 的整体架构设计及自研核心技术,为云原生数据仓库发展,及企业数字化转型实战运用提供最新的参考和启迪。
以下为 ByteHouse 技术白皮书整体架构设计版块摘录。
ByteHouse 整体架构设计
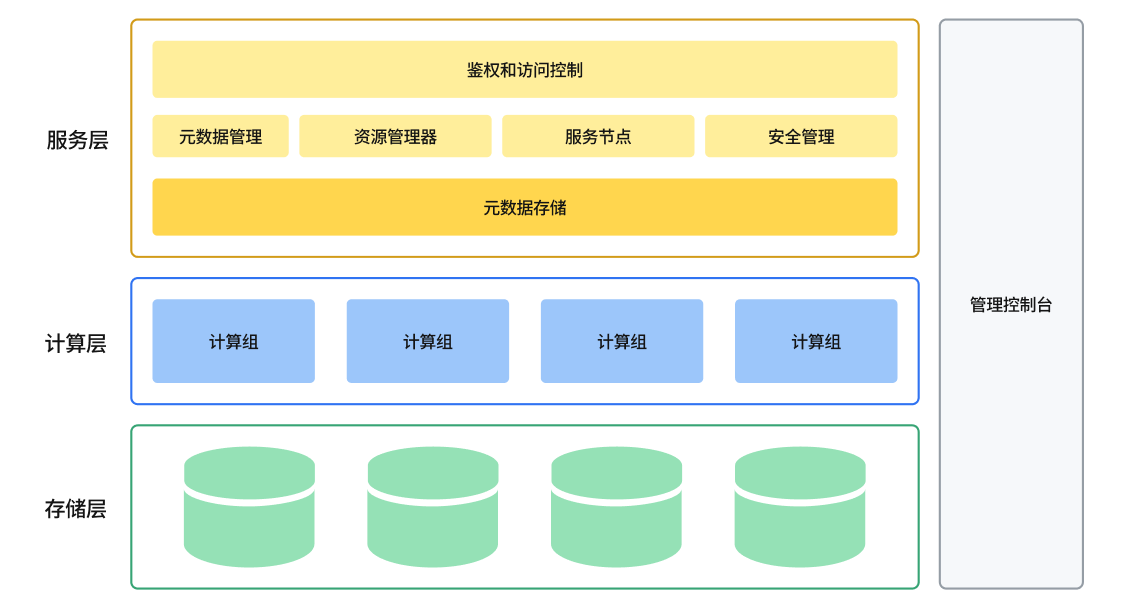
ByteHouse 整体架构图
云原生数据仓库 ByteHouse 总体架构图如上图所示,设计目标是实现高扩展性、高性能、高可靠性、高易用性。从下往上,总体上分服务层、计算层和存储层。
服务层
服务层包括了所有与用户交互的内容,包括用户管理、身份验证、查询优化器,事务管理、安全管理、元数据管理,以及运维监控、数据查询等可视化操作功能。
服务层主要包括如下组件:
资源管理器
资源管理器(Resource Manager)负责对计算资源进行统一的管理和调度,能够收集各个计算组的性能数据,为查询、写入和后台任务动态分配资源。同时支持计算资源隔离和共享,资源池化和弹性扩缩等功能。资源管理器是提高集群整体利用率的核心组件。
服务节点
服务节点(CNCH Server)可以看成是 Query 执行的 master 或者是 coordinator。每一个计算组有 1 个或者多个 CNCH Server,负责接受用户的 query 请求,解析 query,生成逻辑执行计划,优化执行计划,调度和执行 query,并将最终结果返回给用户。
服务节点是无状态的,意味着用户可以接入任意一个服务节点(当然如果有需要,也可以隔离开),并且可以水平扩展,意味着平台具备支持高并发查询的能力。
元数据服务
元数据服务(Catalog Service)提供对查询相关元数据信息的读写。Metadata 主要包括 2 部分:Table 的元数据和 Part 的元数据。表的元数据信息主要包括表的 Schema,partitioning schema,primary key,ordering key。Part 的元数据信息记录表所对应的所有 data file 的元数据,主要包括文件名,文件路径,partition, schema,statistics,数据的索引等信息。
元数据信息会持久化保存在状态存储池里面,为了降低对元数据库的访问压力,对于访问频度高的元数据会进行缓存。
元数据服务自身只负责处理对元数据的请求,自身是无状态的,可以水平扩展。
安全管理
权限控制和安全管理,包括入侵检测、用户角色管理、授权管理、访问白名单管理、安全审计等功能。
计算层
通过容器编排平台(如 Kubernetes)来实现计算资源管理,所有计算资源都放在容器中。
计算组是计算资源的组织单位,可以将计算资源按需划分为多个虚拟集群。每个虚拟集群里包含 0 到多台计算节点,可按照实际资源需求量动态的扩缩容。
一个租户内可以创建 1 个或多个计算组,计算资源扩缩容的方式有两种,一种是调整计算组的 CPU 核数和内存大小实现快速的纵向扩缩容,另一种方式是增减计算组的数量实现水平扩容,在存储计算分离的架构下,计算资源与存储资源是解耦的且无状态的,扩缩容过程不需要迁移和平衡数据,因而可以实现快速弹性扩缩容。
计算节点主要承担的是计算任务,这些任务可以是数据写入、用户查询,也可以是一些后台任务。用户查询和后台任务,可以共享相同的计算节点以提高利用率,也可以使用独立的计算节点以保证严格的资源隔离。用户可以根据计算任务的特性、优先级和业务类别不同,构建多个计算组,并设置不同的资源弹性策略,提高计算效率降低成本。
存储层
采用 HDFS 或 S3 等云存储服务作为数据存储层,用来存储实际数据、索引等内容。
数据表的数据文件存储在远端的统一分布式存储系统中,与计算节点分离开来。底层存储系统可能会对应不同类型的分布式系统。例如 HDFS,Amazon S3, Google cloud storage,Azure blob storage,阿里云对象存储等等。
不同的分布式存储系统,例如 S3 和 HDFS 有很多不同的功能和不一样的性能,会影响到功能的设计和实现。例如 hdfs 不支持文件的 update, S3 object move 操作时重操作需要复制数据等。
通过存储的服务化,对计算层提供统一的抽象文件系统接口,存储层采用 S3 还是 HDFS 对计算层透明;计算层可以支持 ByteHouse 自身的计算引擎之外,将来还可以便捷地对接其他计算引擎,例如 Presto、Spark 等。
采用块存储或对象存储作为共享的存储层,带来的好处是多方面的:
首先底层存储是天然支持高可用
存储容量可以无限扩缩
扩容时无需做数据均衡
作业执行流程
ByteHouse 中的作业按照响应优先级分为 3 大类:Read query、Write query 和 Background 的作业。不同类型的作业,按照前面所述,可以运行同一个工作节点上,也可以分离开来。
数据查询流程
服务节点负责响应和接受用户查询请求,并调度到相应的计算组中去执行,并回传结果给服务节点。各个计算节点执行完子查询之后, 很多时候会有相应计算结果要集中处理,如果希望这一层有计算组的隔离,务节点的部分功能例如聚合最终结果需要下放到计算组中的计算节点中去。
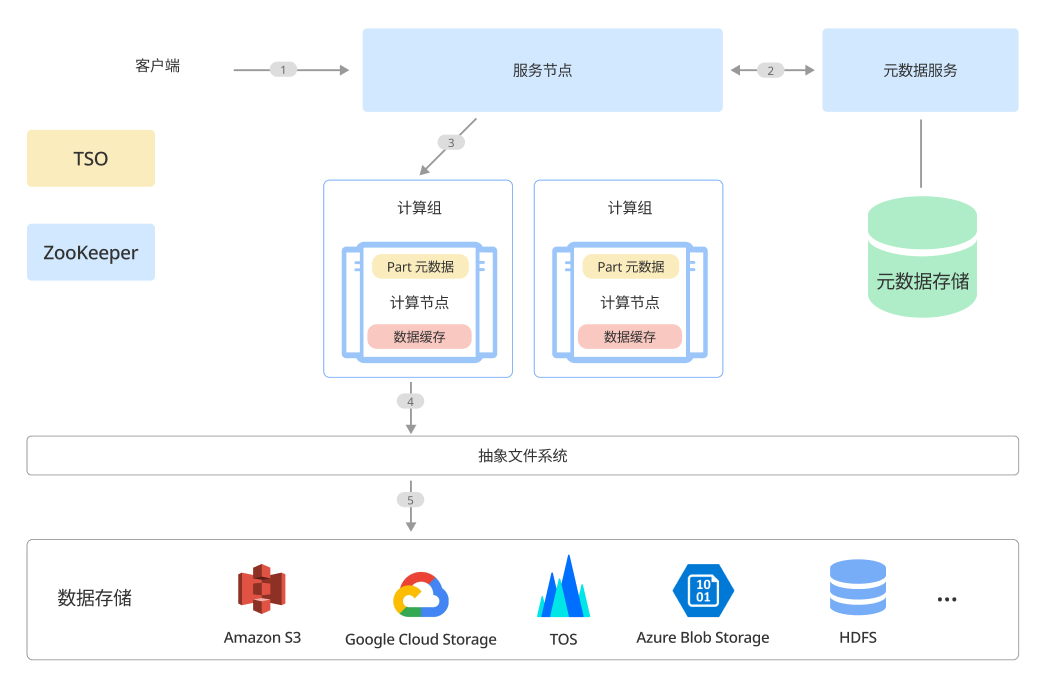
Read Query 模块交互图
Query 的执行过程:
用户提交 Query 到服务节点
从元数据服务获取需要的元数据信息,对 Query 进行 Parse,Planning,Optimize,生成执行计划
服务节点对 Query 进行调度
计算节点接收到 Query 子查询
Query 从远程文件系统获取原始数据,并根据 Query 的执行计划在计算节点上执行,并发回计算结果给服务节点汇总。
数据写入流程
ByteHouse 实现了读写分离,有单独写入节点来执行写入请求,写入请求分为几类:insert values, insert infile, insert select,insert values 可能包含大量数据集,为避免网络传输开销直接由服务节点本地执行 insert 而无需转发给写入节点来执行。
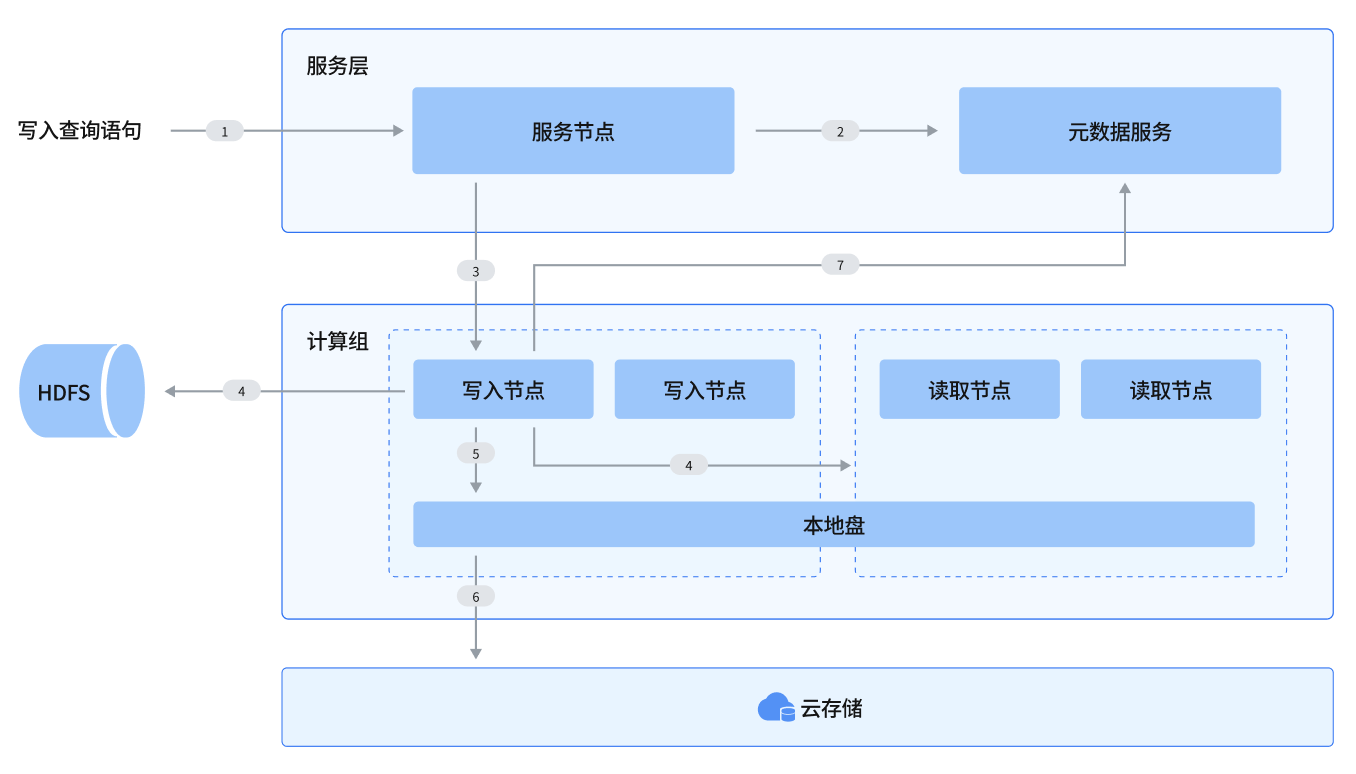
Write Query 模块交互图
Query 的执行过程:
用户提交 Write Query 到服务节点
服务节点从元数据服务获取需要的元数据信息,对 Query 进行 parse,planning,optimize,生成执行计划,根据写入类型分为以下两种模式来执行:
Local 模式:insert values 操作直接由服务节点跳转到步骤四直接执行
分布式模式:对于 insert infile/select 模式直接将执行计划信息分发给一个写入节点执行
服务节点对写入请求根据调度策略选择合适的写入节点执行
写入节点从读取节点(insert select)或者外部存储(insert infile hdfs)读取数据流
写入节点写入数据到本地盘
写入节点 导出 本地盘到云存储
写入节点 更新元数据
后台任务
为了更好的查询性能,会有一些作业在后台对写入的数据进行更进一步的处理。ByteHouse 中主要包括如下 3 种后台任务。
Merge:将不同的 parts 文件按 Primary Key 做排序合并成一个大的 part 文件。
Checkpoint: 对表的任意更新,例如元数据的改变,数据字典等异步构建操作会产生新的增量数据文件,这部分新产生的增量和原有的数据文件会在后台合并成一个新的数据文件。
GC:空间回收,当数据文件中的垃圾空间超过一定阈值后,会触发后台作业回收空间.
数据导入导出
ByteHouse 包括一个数据导入导出(Data Express)模块,负责数据的导入导出工作。
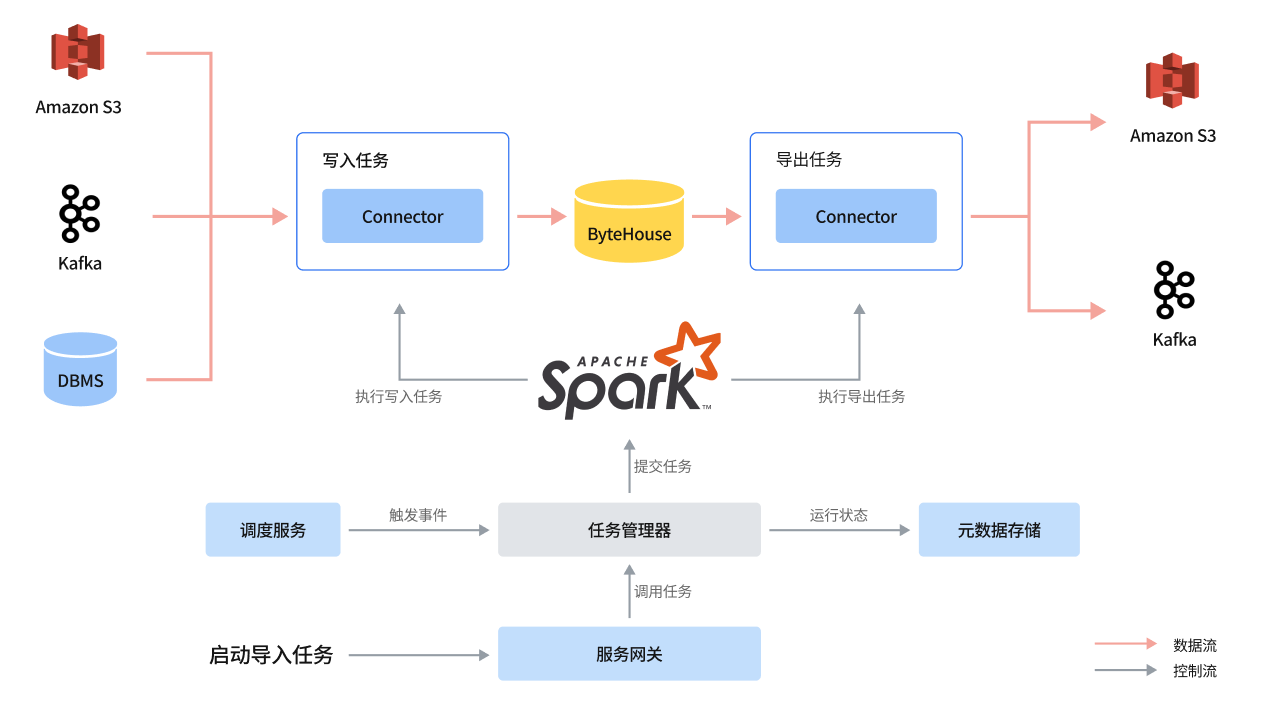
Data Express 模块架构图
Data Express 为数据导入/导出作业提供工作流服务和快速配置模板,用户可以从提供的快速模板创建数据加载作业。
DataExpress 利用 Spark 来执行数据迁移任务。
主要模块:
- JobServer
- 导入模板
- 导出模板
JobServer 管理所有用户创建的数据迁移作业,同时运行外部事件触发数据迁移任务。
启动任务时,JobServer 将相应的作业提交给 Spark 集群,并监控其执行情况。作业执行状态将保存在我们的元存储中,以供 Bytehouse 进一步分析。
ByteHouse 支持离线数据导入和实时数据导入。
离线导入
离线导入数据源:
Object Storage:S3、OSS、Minio
Hive (1.0+)
Apache Kafka /Confluent Cloud/AWS Kinesis
本地文件
RDS
离线导入适用于希望将已准备好的数据一次性加载到 ByteHouse 的场景,根据是否对目标数据表进行分区,ByteHouse 提供了不同的加载模式:
全量加载:全量将用最新的数据替换全表数据。
增量加载:增量加载将根据其分区将新的数据添加到现有的目标数据表。ByteHouse 将替换现有分区,而非进行合并。
支持的文件类型
ByteHouse 的离线导入支持以下文件格式:
Delimited files (CSV, TSV, etc.)
Json (multiline)
Avro
Parquet
Excel (xls)
实时导入
ByteHouse 能够连接到 Kafka,并将数据持续传输到目标数据表中。与离线导入不同,Kafka 任务一旦启动将持续运行。ByteHouse 的 Kafka 导入任务能够提供 exactly-once 语义。您可以停止/恢复消费任务,ByteHouse 将记录 offset 信息,确保数据不会丢失。
支持的消息格式
ByteHouse 在流式导入中支持以下消息格式:
Protobuf
JSON
更多的导入数据源以及导出功能正在不断完善中。
多租户管理
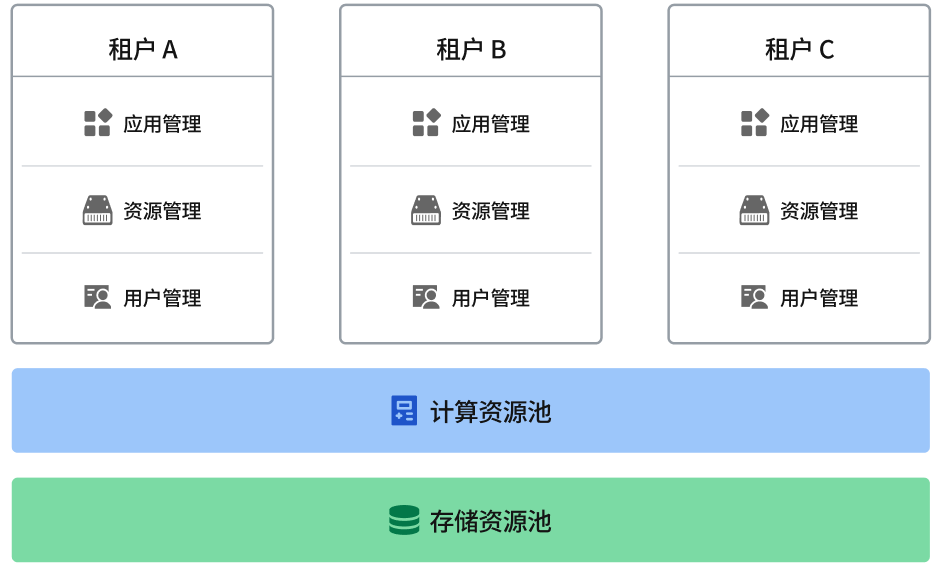
多租户管理架构图
ByteHouse 的计算资源、数据资源、作业任务和用户权限都用租户进行隔离,所有的数据对象和资源都在一个租户内部进行管理。
不同的业务团队可以建立各自的租户,按额度申请所需的计算资源,便于进行资源管理和结算。计算资源隔离在租户内部,屏蔽租户之间的资源争抢。
数据库、数据表、视图等对象都在租户内部进行管理和授权,数据安全限制在租户内部。数据查询、数据导入任务也在各自租户中,增加了任务代码安全性。
多租户管理功能适应了整个企业资源集中统一管理、按需按份额使用、兼顾资源共享和数据安全要求,同时可以为 SaaS 应用提供支撑,能按需为新用户申请资源,做到即开即用,又能满足不同用户资源和数据隔离性需求,实现一套系统服务所有用户。
运维监控管理
ByteHouse 的私有化部署版本包含一个可视化的资源监控和管理平台,提供资源、负载监控仪表盘,直观地展现集群整体状况,同时提供租户管理、报警监控、审计日志、扩缩容、系统升级、故障节点替换等核心功能,让运维人员通过白屏化操作,降低运维成本和操作风险。
集群管理维护模块包括对物理资源的配置、节点重启、故障节点一键替换、滚动升级、滚动重启等功能,实现可视化运维管理。
通过仪表板对集群健康度进行宏观监控,集群资源饱和度监控能实时查看存储计算的当前应用情况和增长趋势,方便进行扩缩容;节点健康度监控能实时监控节点实时的响应情况;集群负载监控能实时反应集群总体负载水位;提供 Grafana 对各个组件运行状态进行细粒度监控。

运维监控模块示意图
监控报警模块提供与第三方报警平台对接能力,支持对 CPU、内存、存储资源使用量指标、技术组件健康度指标、计算任务状态指标、集群负载和性能指标进行监控,并通过短信、电话等方式通知值班员。
点击链接,立即下载完整版白皮书
https://www.wjx.cn/vm/Ot0YJFq.aspx#
点击跳转 火山引擎云原生数据仓库ByteHouse了解更多
火山引擎云原生数据仓库 ByteHouse 技术白皮书 V1.0(中)的更多相关文章
- OpenFlow技术白皮书-V1.0
1. 概述 OpenFlow是由斯坦福大学的Nick McKeown教授在2008年4月ACM Communications Review上发表的一篇论文OpenFlow: enabling inn ...
- 灵雀云CTO陈恺:从“鸿沟理论”看云原生,哪些技术能够跨越鸿沟?
灵雀云CTO陈恺:从“鸿沟理论”看云原生,哪些技术能够跨越鸿沟? 历史进入2019年,放眼望去,今天的整个技术大环境和生态都发生了很大的变化.在己亥猪年春节刚刚过去的早春时节,我们来梳理和展望一下整个 ...
- 混部之殇-论云原生资源隔离技术之CPU隔离(一)
作者 蒋彪,腾讯云高级工程师,10+年专注于操作系统相关技术,Linux内核资深发烧友.目前负责腾讯云原生OS的研发,以及OS/虚拟化的性能优化工作. 导语 混部,通常指在离线混部(也有离在线混部之说 ...
- [华三] IPv6技术白皮书(V1.00)
IPv6技术白皮书(V1.00) http://www.h3c.com/cn/d_200802/605649_30003_0.htm H3C S7500E IPv6技术白皮书 关键词:IPv6,隧道 ...
- waf 引擎 云原生平台tproxy 实现调研
了解了基本 云原生架构,不清楚的查看之前的文章:https://www.cnblogs.com/codestack/p/13914134.html 现在来看看云原生平台tproxy waf引擎串联实现 ...
- waf 引擎云原生调研---扫盲
概念: lstio Istio是一个用于服务治理的开放平台 Istio是一个Service Mesh形态的用于服务治理的开放平台 Istio是一个与Kubernetes紧密结合的适用于云原生场景的Se ...
- NodeJS 基于 Dapr 构建云原生微服务应用,从 0 到 1 快速上手指南
Dapr 是一个可移植的.事件驱动的运行时,它使任何开发人员能够轻松构建出弹性的.无状态和有状态的应用程序,并可运行在云平台或边缘计算中,它同时也支持多种编程语言和开发框架.Dapr 确保开发人员专注 ...
- 接口性能测试方案 白皮书 V1.0
一. 性能测试术语解释 1. 响应时间 响应时间即从应用系统发出请求开始,到客户端接收到最后一个字节数据为止所消耗的时间.响应时间按软件的特点再可以细分,如对于一个 C/S 软件的响应时间可以细分为网 ...
- 高性能、快响应!火山引擎 ByteHouse 物化视图功能及入门介绍
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流群 物化视图是指将视图的计算结果存储在数据库中的一种技术.当用户执行查询时,数据库会直接从已经预计算好的结果中获取数据 ...
- 技术分享 | 云原生多模型 NoSQL 概述
作者 朱建平,TEG/云架构平台部/块与表格存储中心副总监.08年加入腾讯后,承担过对象存储.键值存储,先后负责过KV存储-TSSD.对象存储-TFS等多个存储平台. NoSQL 技术和行业背景 No ...
随机推荐
- CSS必学:你需要知道的盒子模型的秘密
作者:WangMin 格言:努力做好自己喜欢的每一件事 作为前端开发来说,要掌握的CSS基础一定很多,那么CSS中盒子模型肯定是必考必问必掌握的前端知识点,因为它是CSS基础中非常重要的内容,接下来我 ...
- 题解 AGC054D
前言 因为本人尚菜,所以本篇文章没有什么数学符号,请大家放心食用. 题目分析 先吐槽一嘴,这个 o 表示 (),这个 x 表示 )(,十分形象. 好,我们先观察原序列,容易得出第一条性质: ox 的加 ...
- inget
万能密码考点 payload ?id=1' or 1=1--+
- Johnson 最短路算法
Johnson 算法 全源最短路径求解其实是单源最短路径的推广,求解单源最短路径的两种算法时间复杂度分别为: Dijkstra 单源最短路径算法:时间复杂度为 \(O(E + VlogV)\),要求权 ...
- 给大家介绍一款强大的抓包代理工具--mitmproxy
最近工作中涉及到和app相关的测试工作,需要用到mock,特意网上查了些资料,发现有很多工具可以实现app的mock,但是经过我反复试用后,发现mitmproxy这个工具非常的强大 我认为mitmpr ...
- AutoCAD ObjectARX 二次开发(2020版)--4,使用ARX向导创建CAD二次开发项目(编程框架)--
手动创建ObjectARX应用程序非常麻烦,在此步骤中,将介绍ObjectARX向导. 在这里,我们将使用ObjectARX向导创建我们的ObjectARX应用程序. 本节的程序的需求是,接收CAD用 ...
- Win10操作系统安装Python
1 Python解释器下载 1.1 安装环境 Windows 10 专业工作站版22H2 python-3.9.6-amd64.exe 1.2 下载地址 Python官网:https://www.py ...
- 生成模型的两大代表:VAE和GAN
生成模型 给定数据集,希望生成模型产生与训练集同分布的新样本.对于训练数据服从\(p_{data}(x)\):对于产生样本服从\(p_{model}(x)\).希望学到一个模型\(p_{model}( ...
- 【JMeter】使用nmon进行性能资源监控
使用nmon进行性能资源监控 目录 使用nmon进行性能资源监控 一.前言 二.nmon的下载安装 1.查看系统信息 2.查看CPU信息 2.下载 3.解压 4.一个小问题 三.在性能测试时使用命令行 ...
- Docker命令之export|import、save|load
1.export|import export docker export -o /ly/myexport-redis 49c26f7431d1 -o : 指定一个不存在的文件夹,存放导出的镜像 imp ...