以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路
更多技术交流、求职机会,欢迎关注字节跳动数据平台微信公众号,回复【1】进入官方交流群
I. 传统数仓的演进:云数仓
近年来,随着数据“爆炸式”的增长,越来越多的数据被产生、收集和存储。而挖掘海量数据中的真实价值,从其中提取商机并洞见未来,则成了现代企业和组织不可忽视的命题。
随着数据量级和复杂度的增大,数据分析处理的技术架构也在不断演进。在面对海量数据分析时,传统 OLAP 技术架构中的痛点变得越来越明显,如扩容缩容耗时长,导致资源利用率偏低,成本居高不下;以及运维配置复杂,需要专业的技术人员介入等。
为了解决这类问题,云数仓的概念应运而生。和传统数仓架构不同的是,云原生数仓借助于云平台的基础资源,实现了资源的动态扩缩容,并最大化利用资源,从而达到 Pay as you go 按实际用量付费的模式。
ByteHouse 作为云原生的数据平台,从架构层面入手,通过存储和计算分离的云原生架构完美适配云上基础设施。在字节跳动内部,ByteHouse 已经支持 80% 的分析应用场景,包括用户增长业务、广告、A/B 测试等。除了极致的分析性能之外,ByteHouse 开箱即用,按实际使用付费的特性也极大地降低了企业和个人的上手门槛,能够在短短数分钟内体验到数据分析的魅力。
Talk is cheap, 接下来就让我们通过一个实战案例来体验下 ByteHouse 云数仓的强大功能。
II. 快速上手 ByteHouse——轻量级云数仓
本章节通过使用 ByteHouse 云数仓进行 SSB 基准测试,在带领读者了解产品性能的同时,也一并熟悉产品中各个模块的功能,开启你的数据分析之路,通过分析海量数据,加速数据洞察。ByteHouse 的架构总览如下。
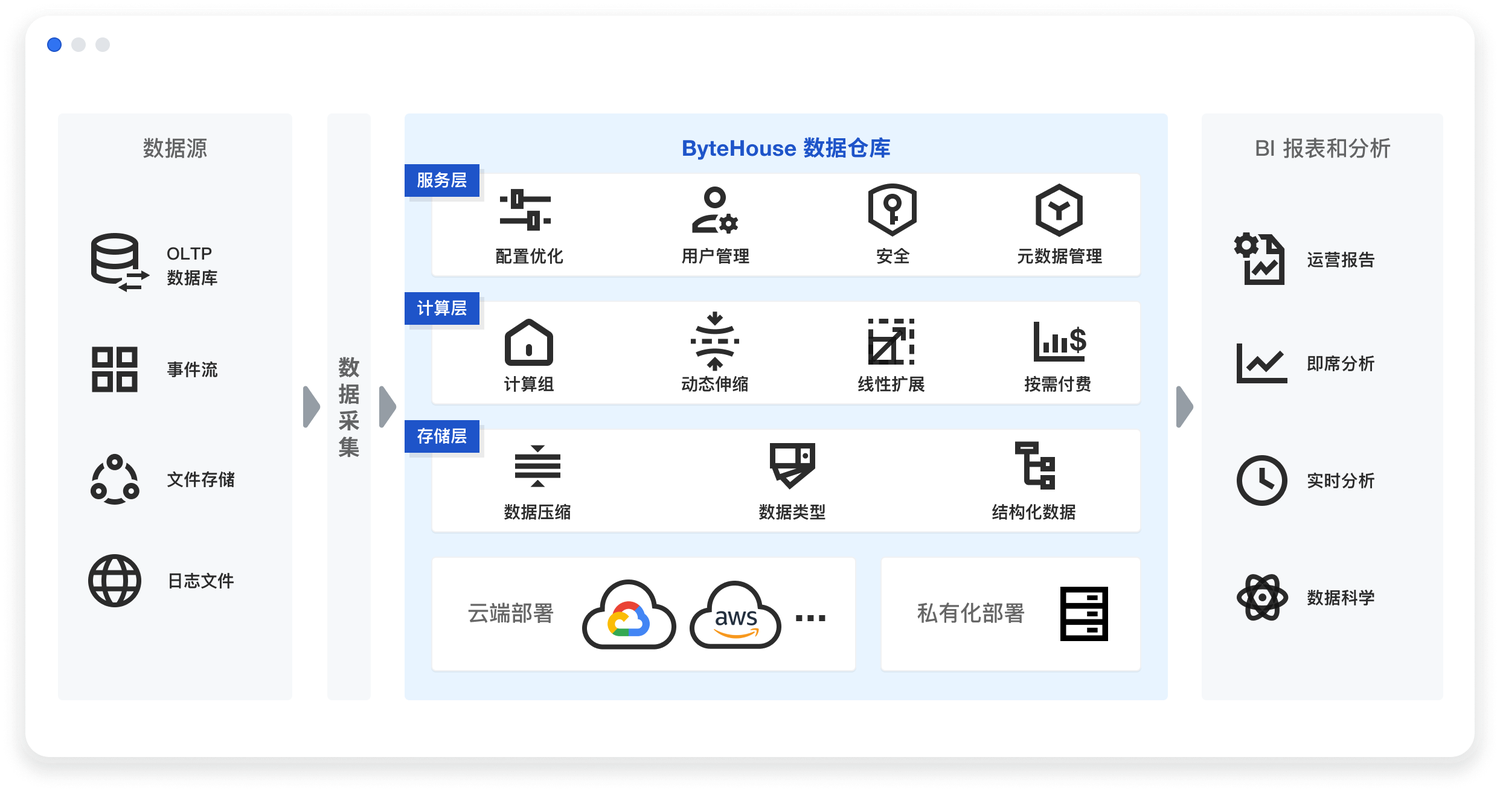
SSB 基准测试
SSB(Star Schema Benchmark)是由麻省州立大学波士顿校区的研究员定义的基于现实商业应用的数据模型。SSB 是在 TPC-H 标准的基础上改进而成,主要将 TPC-H 中的雪花模型改成了更为通用的的星型模型,将基准查询从复杂的 Ad-hoc 查询改成了结构更加固定的 OLAP 查询,从而主要用于模拟测试 OLAP 引擎和轻量数仓场景下的查询性能。由于 SSB 基准测试较为中立,并贴近现实的商业场景,因此在学界及工业界有广泛的应用。
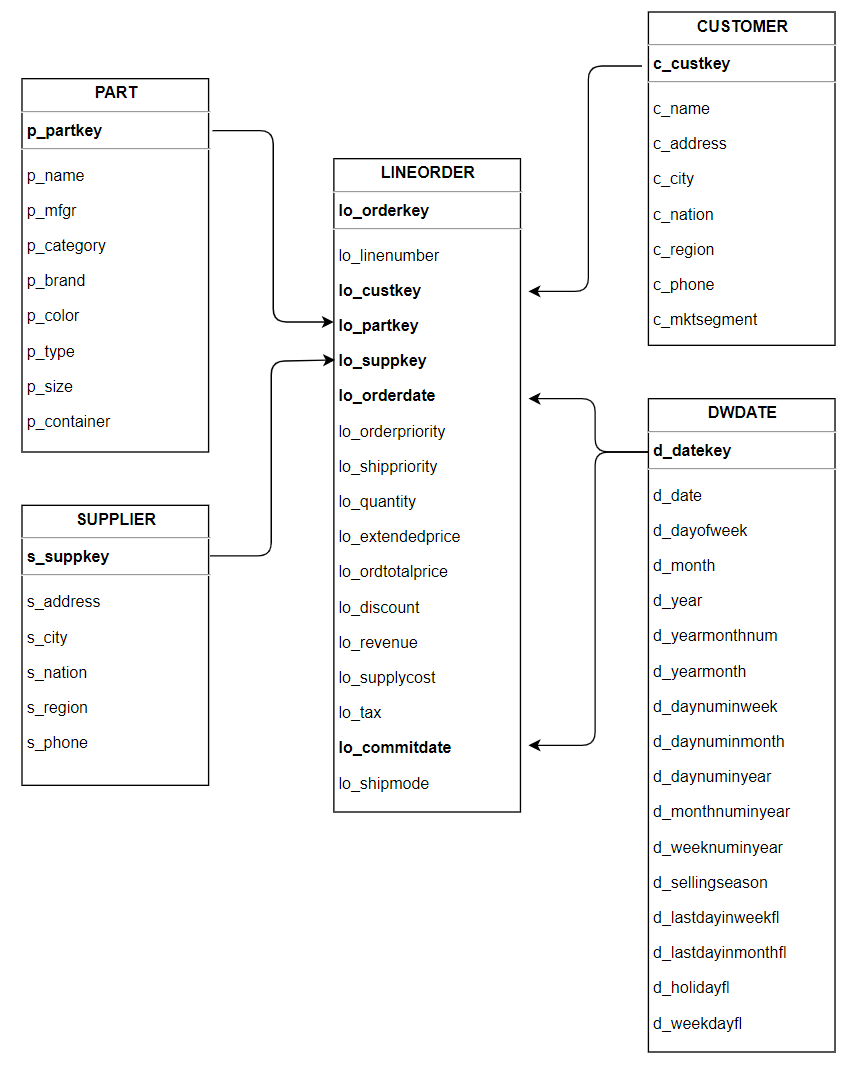
SSB 基准测试中对应的表结构如下所示,可以看到 SSB 主要采用星型模型,其中包含了 1 个事实表 lineorder 和 4 个维度表 customer, part, dwdate 以及 supplier,每张维度表通过 Primary Key 和事实表进行关联。测试通过执行 13 条 SQL 进行查询,包含了多表关联,group by,复杂条件等多种组合。更多详细信息请参考 SSB 文献。
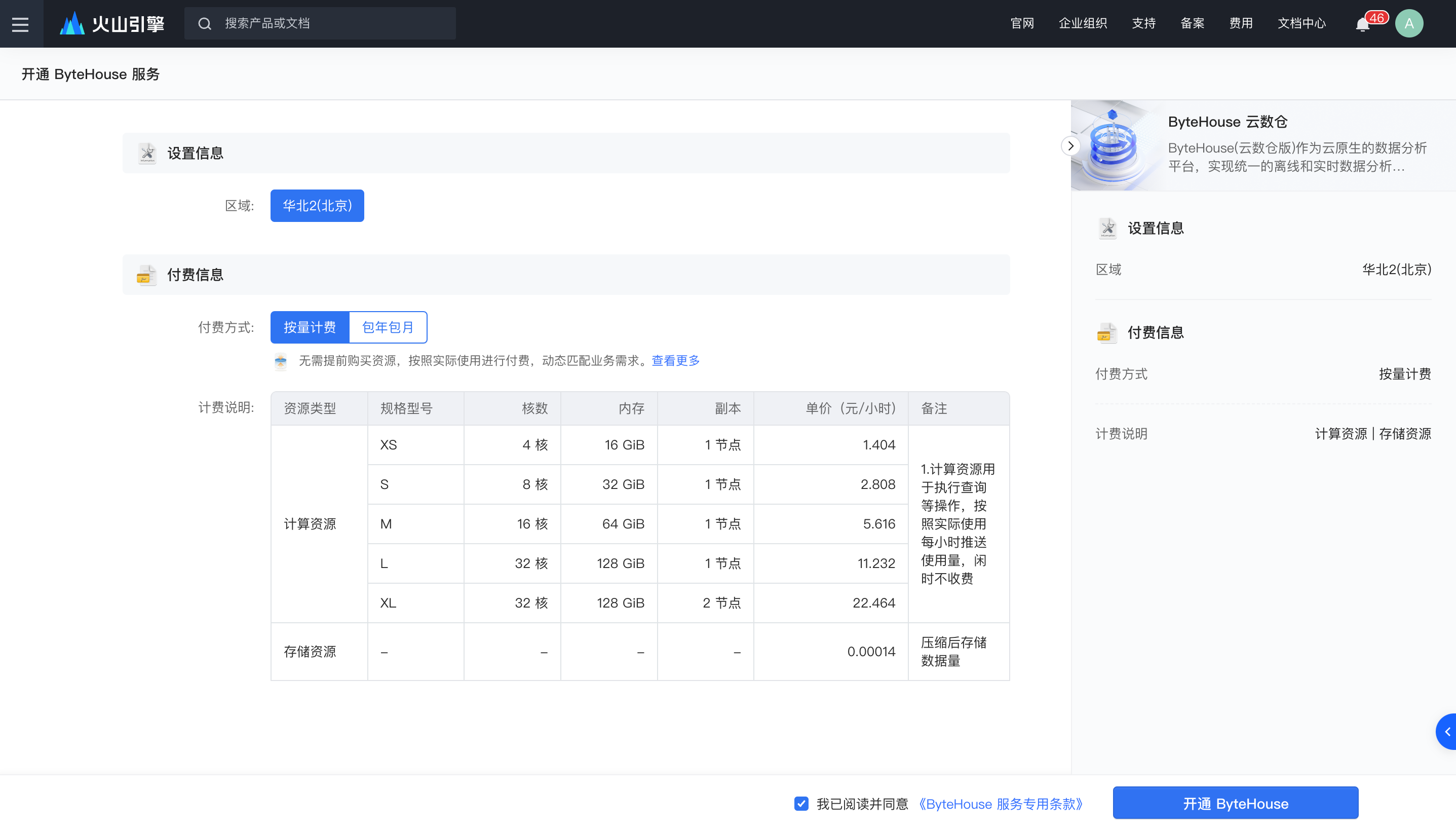
步骤一:官网注册并开通 ByteHouse
访问ByteHouse 云数仓火山引擎官网,注册火山引擎账户,完成实名认证后,即可登录到产品控制台。开通产品进行测试,目前 ByteHouse 支持包年包月和按量付费两种模式的实例,便于您根据业务需求进行选择。
步骤二:创建计算组
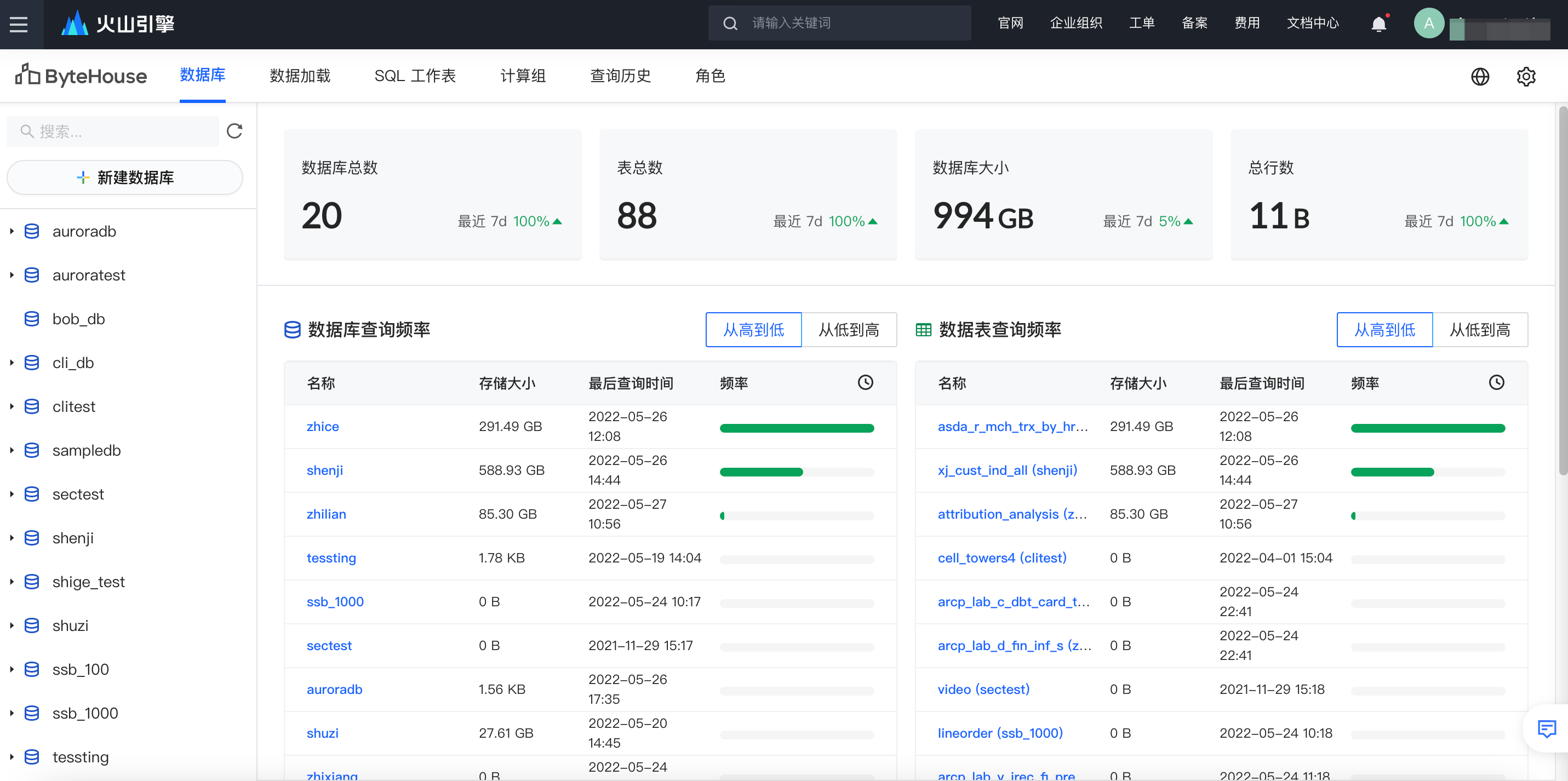
登录到控制台后,可以看到数据库表管理、数据加载、SQL 工作表、计算组、查询历史和角色管理等几大模块。分别具有如下作用:
数据库表管理:用于创建和管理数据库、数据表以及视图等数据对象
数据加载:用于从不同的离线和实时数据源如对象存储、Kafka 等地写入数据
SQL 工作表:在界面上编辑、管理并运行 SQL 查询
计算组:创建和管理虚拟的计算资源,用于执行数据查询等操作
查询历史:用于查看 SQL 的历史执行记录、状态和查询详情等
为了方便进行后续的建库建表和查询等操作,首先在 ByteHouse 控制台创建型号为 L 的计算组,如下图所示
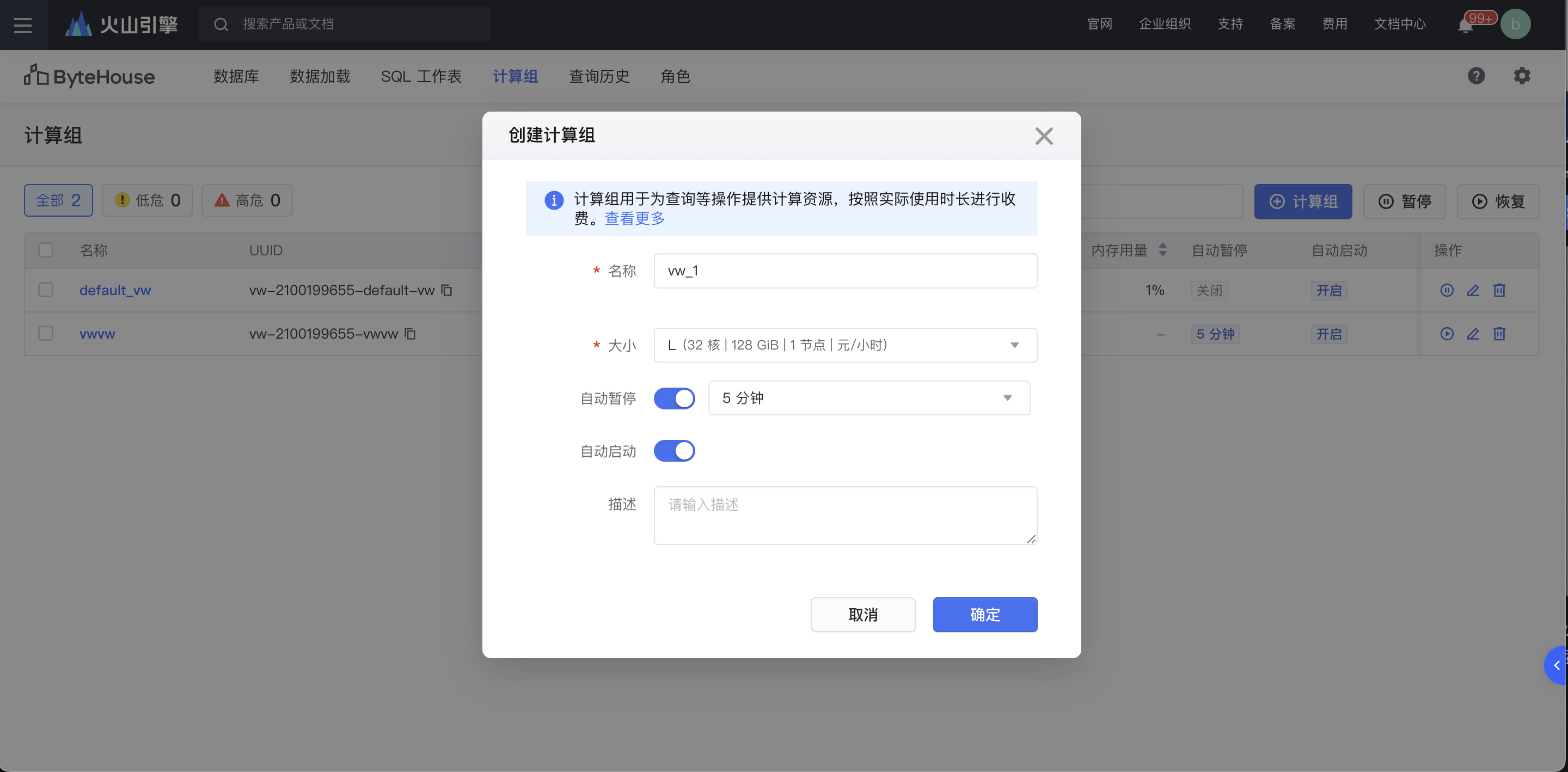
计算组是 Bytehouse 中的计算资源集群,可按需进行横向扩展。计算组提供所需的资源如 CPU、内存及临时存储等,用于执行数据查询 DQL、DML 等操作。ByteHouse 计算组能够实现弹性扩缩容,读写分离、存算分离等,并且能对资源进行细粒度的权限控制。
步骤三:创建数据库表
在控制台页面中创建名为 ssb_100 的数据库

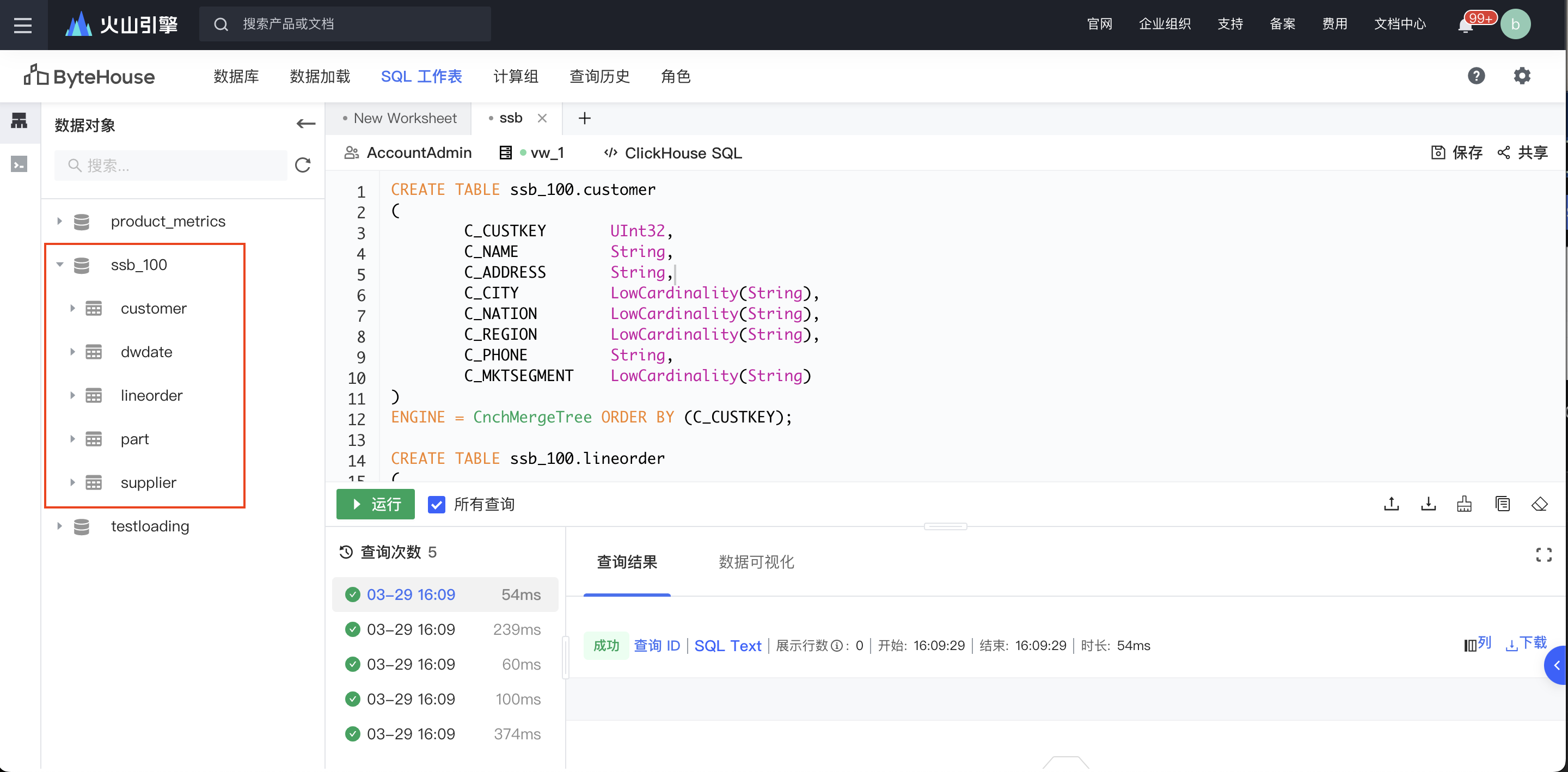
创建完毕后,进入到 SQL 工作表模块,通过如下建表语句建立四个数据表(事实表),并保存对应的 SQL 语句。
CREATE TABLE ssb_100.customer
(
C_CUSTKEY UInt32,
C_NAME String,
C_ADDRESS String,
C_CITY LowCardinality(String),
C_NATION LowCardinality(String),
C_REGION LowCardinality(String),
C_PHONE String,
C_MKTSEGMENT LowCardinality(String),
C_PLACEHOLDER Nullable(String)
)
ENGINE = CnchMergeTree ORDER BY (C_CUSTKEY); CREATE TABLE ssb_100.lineorder
(
LO_ORDERKEY UInt32,
LO_LINENUMBER UInt8,
LO_CUSTKEY UInt32,
LO_PARTKEY UInt32,
LO_SUPPKEY UInt32,
LO_ORDERDATE Date,
LO_ORDERPRIORITY LowCardinality(String),
LO_SHIPPRIORITY UInt8,
LO_QUANTITY UInt8,
LO_EXTENDEDPRICE UInt32,
LO_ORDTOTALPRICE UInt32,
LO_DISCOUNT UInt8,
LO_REVENUE UInt32,
LO_SUPPLYCOST UInt32,
LO_TAX UInt8,
LO_COMMITDATE Date,
LO_SHIPMODE LowCardinality(String),
LO_PLACEHOLDER Nullable(String)
)
ENGINE = CnchMergeTree PARTITION BY toYear(LO_ORDERDATE) ORDER BY (LO_ORDERDATE, LO_ORDERKEY); CREATE TABLE ssb_100.part
(
P_PARTKEY UInt32,
P_NAME String,
P_MFGR LowCardinality(String),
P_CATEGORY LowCardinality(String),
P_BRAND LowCardinality(String),
P_COLOR LowCardinality(String),
P_TYPE LowCardinality(String),
P_SIZE UInt8,
P_CONTAINER LowCardinality(String),
P_PLACEHOLDER Nullable(String)
)
ENGINE = CnchMergeTree ORDER BY P_PARTKEY; CREATE TABLE ssb_100.supplier
(
S_SUPPKEY UInt32,
S_NAME String,
S_ADDRESS String,
S_CITY LowCardinality(String),
S_NATION LowCardinality(String),
S_REGION LowCardinality(String),
S_PHONE String,
S_PLACEHOLDER Nullable(String)
)
ENGINE = CnchMergeTree ORDER BY S_SUPPKEY; CREATE TABLE ssb_100.dwdate
(
D_DATEKEY UInt32,
D_DATE String,
D_DAYOFWEEK String, -- defined in Section 2.6 as Size 8, but Wednesday is 9 letters
D_MONTH String,
D_YEAR UInt32,
D_YEARMONTHNUM UInt32,
D_YEARMONTH String,
D_DAYNUMINWEEK UInt32,
D_DAYNUMINMONTH UInt32,
D_DAYNUMINYEAR UInt32,
D_MONTHNUMINYEAR UInt32,
D_WEEKNUMINYEAR UInt32,
D_SELLINGSEASON String,
D_LASTDAYINWEEKFL UInt32,
D_LASTDAYINMONTHFL UInt32,
D_HOLIDAYFL UInt32,
D_WEEKDAYFL UInt32,
S_PLACEHOLDER Nullable(String)
)
ENGINE=CnchMergeTree() ORDER BY (D_DATEKEY);
SQL 执行完毕后,在控制台左侧对应的数据对象页面会展示出创建完成的五个工作表,分别为 customer,dwdate,lineorder以及part 和 supplier
步骤四:从对象存储中导入 SSB 数据
通过预先生成 SSB_100 GB 的数据集并存储在对象存储(如 AWS S3 或者 火山引擎 TOS),我们可以方便且快速的将数据导入到 ByteHouse 中进行分析。本次实践中通过配置 火山引擎 TOS 的数据源对数据进行导入。
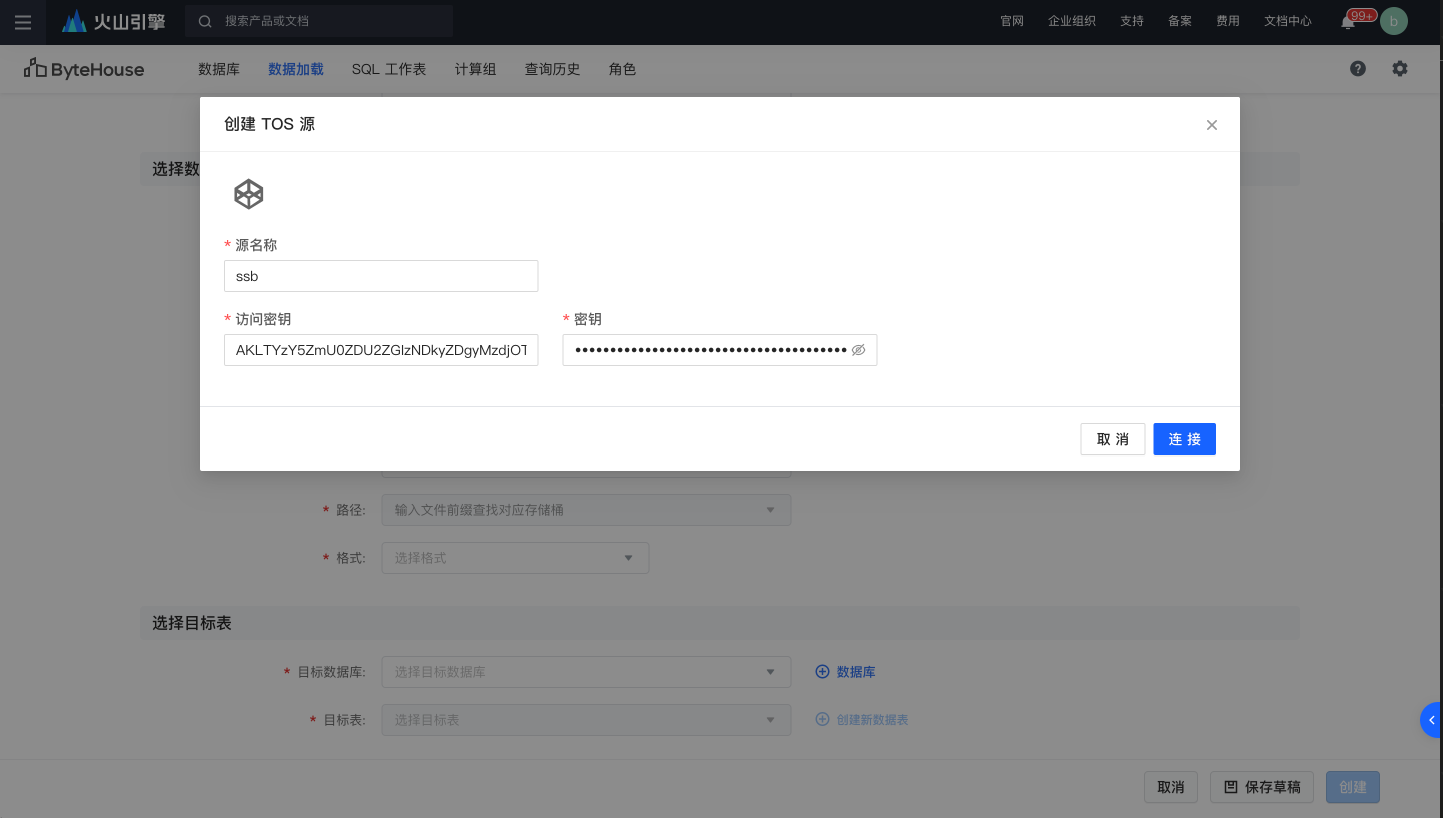
首先在数据加载模块,新建对象存储数据源,并配置对应的秘钥连接火山引擎对象存储
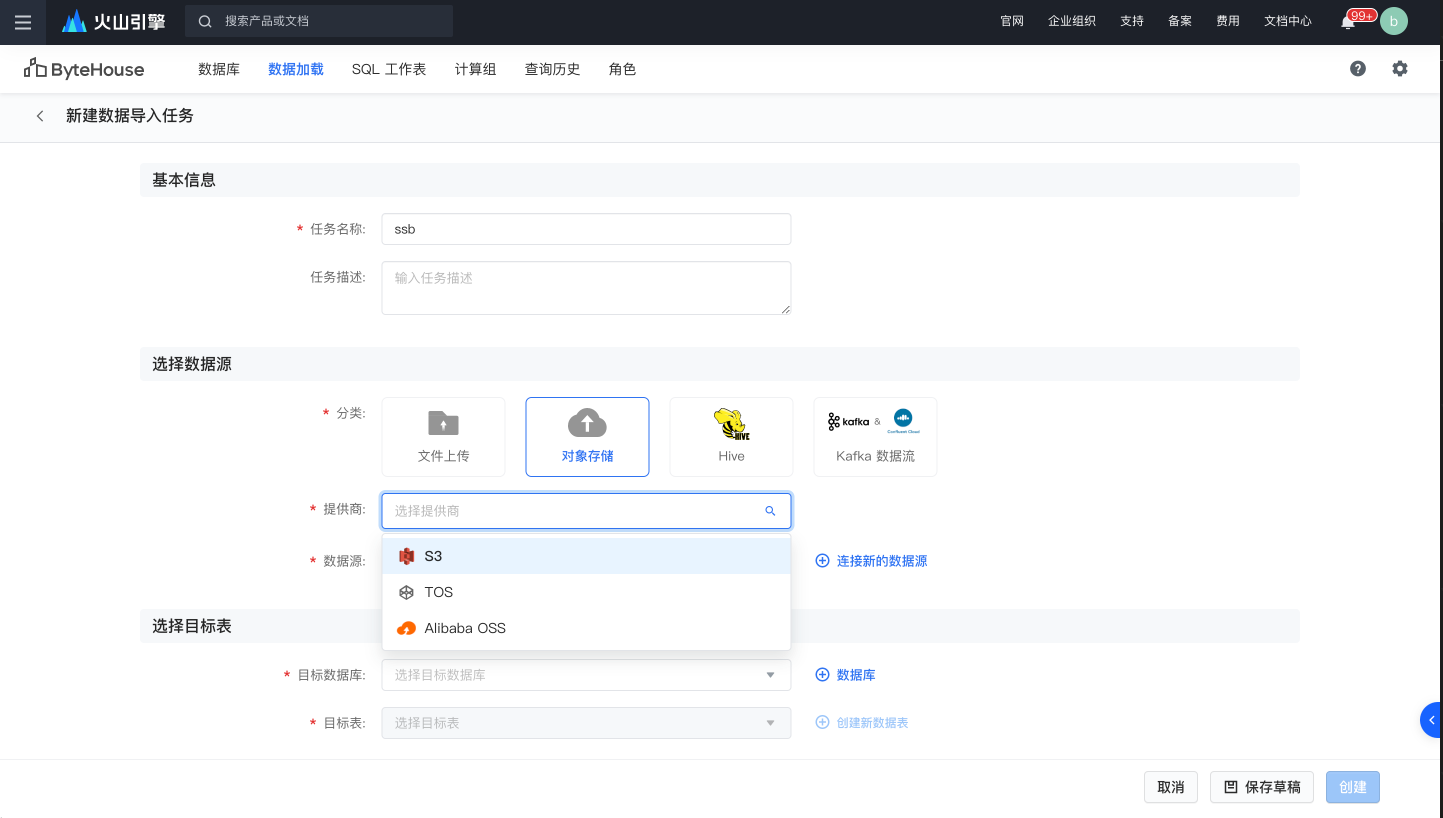
连接新的数据源后,选择 bytehouse-shared-dataset 的储存桶和ssb_100/lineorder.csv 相应的路径
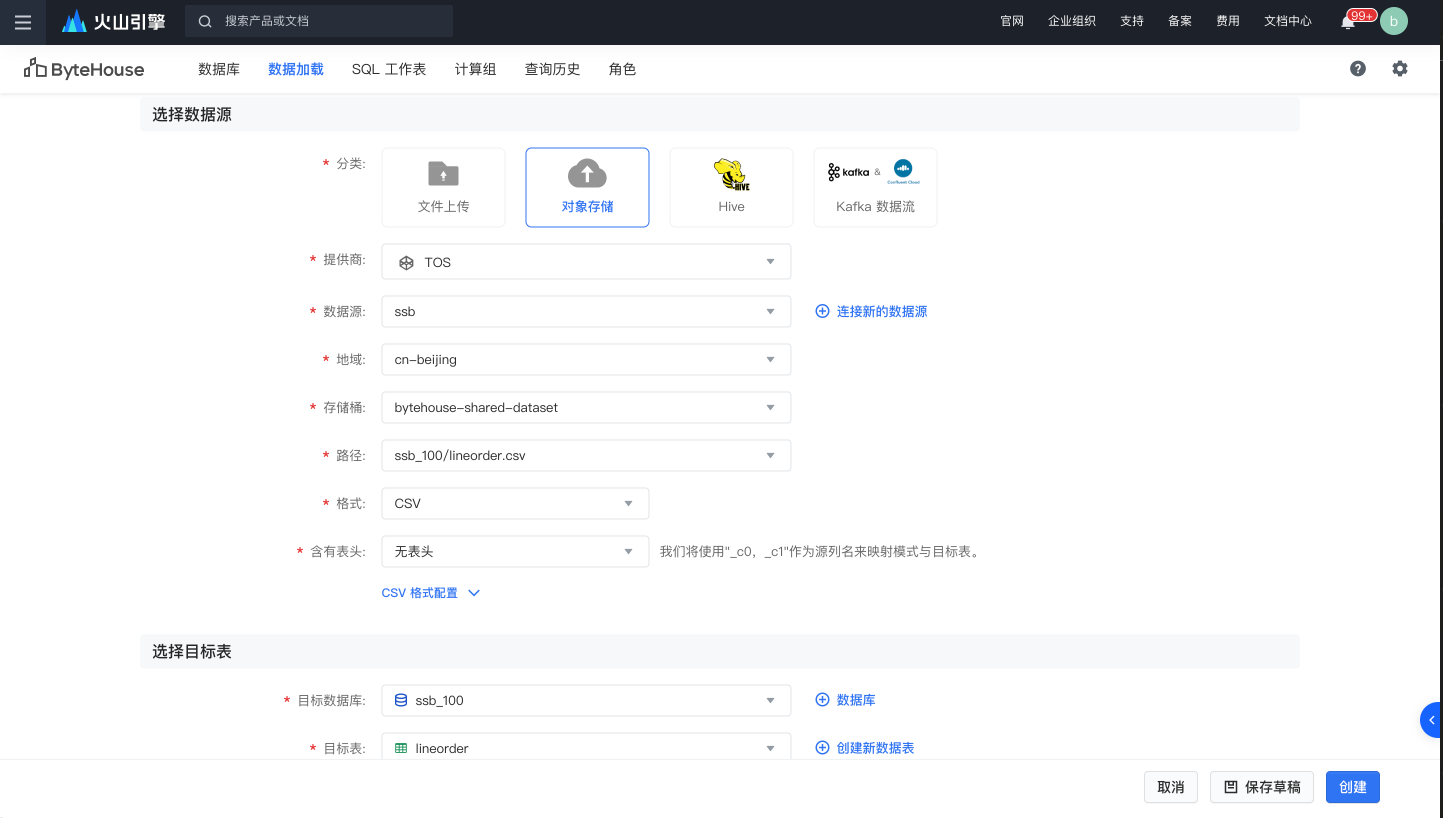
选择之前建的数据库ssb_100和对应标表lineorder,然后按创建。重复步骤为其他四个工作表数据加载。
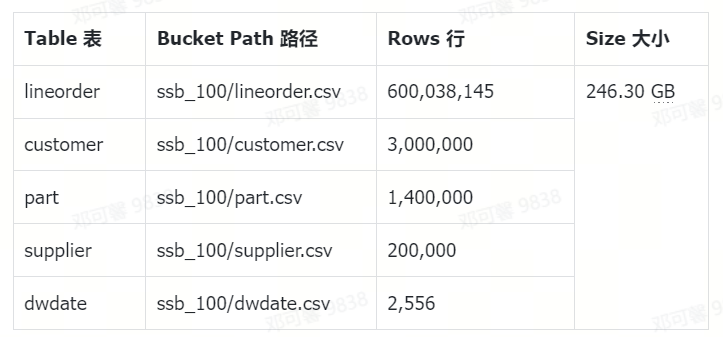
数据源中存储的数据条数如下所示。用于导入完成后,对数据表的行数进行统计,进行准确性校验。
创建导入任务完成后,点击“开始”启动导入任务,任务启动后会在几秒钟内分配资源并初始化导入任务,并在导入过程中展示预估的时间和导入进度。在导入任务的执行详情中,可以查看导入状态、导入详细日志、配置信息等。
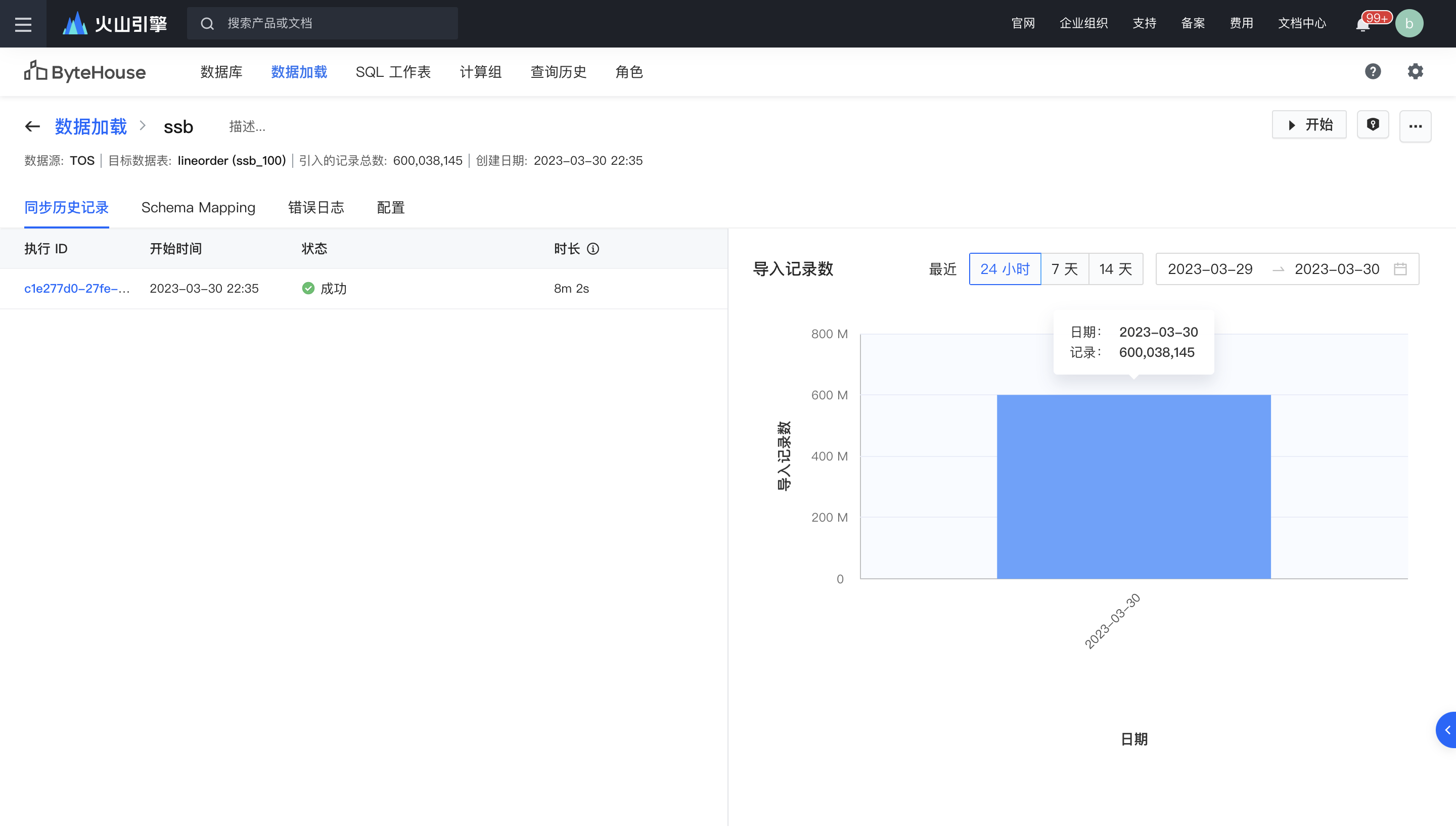
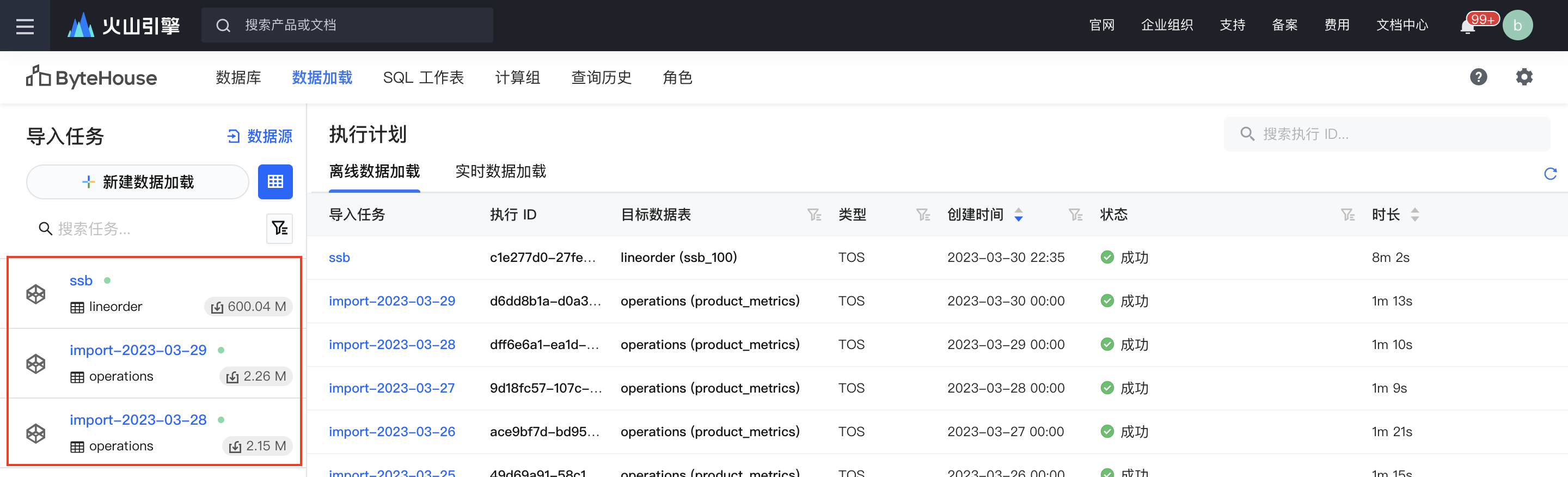
步骤五:数据处理及分析
原始查询测试
通过执行 SSB 的 13 条查询语句,对于多表关联和排序等场景进行性能测试。查询语句如下所示:

为了方便对 SSB 数据集进行测试,我们可以通过改写 SSB,将星型模型打平转换为大宽表进行分析
注:为了确保打平表的执行,需要配置参数 SET max_memory_usage = 20000000000; 此外需要在 ByteHouse 控制台中配置查询超时为 3600s,避免执行超时导致的失败。
SET max_memory_usage = 20000000000; create table ssb_100.lineorder_flat
engine = CnchMergeTree
partition by toYear(lo_orderdate)
order by (lo_orderdate, lo_orderkey) as
select
l.lo_orderkey as lo_orderkey,
l.lo_linenumber as lo_linenumber,
l.lo_custkey as lo_custkey,
l.lo_partkey as lo_partkey,
l.lo_suppkey as lo_suppkey,
l.lo_orderdate as lo_orderdate,
l.lo_orderpriority as lo_orderpriority,
l.lo_shippriority as lo_shippriority,
l.lo_quantity as lo_quantity,
l.lo_extendedprice as lo_extendedprice,
l.lo_ordtotalprice as lo_ordtotalprice,
l.lo_discount as lo_discount,
l.lo_revenue as lo_revenue,
l.lo_supplycost as lo_supplycost,
l.lo_tax as lo_tax,
l.lo_commitdate as lo_commitdate,
l.lo_shipmode as lo_shipmode,
c.c_name as c_name,
c.c_address as c_address,
c.c_city as c_city,
c.c_nation as c_nation,
c.c_region as c_region,
c.c_phone as c_phone,
c.c_mktsegment as c_mktsegment,
s.s_name as s_name,
s.s_address as s_address,
s.s_city as s_city,
s.s_nation as s_nation,
s.s_region as s_region,
s.s_phone as s_phone,
p.p_name as p_name,
p.p_mfgr as p_mfgr,
p.p_category as p_category,
p.p_brand as p_brand,
p.p_color as p_color,
p.p_type as p_type,
p.p_size as p_size,
p.p_container as p_container
from ssb_100.lineorder as l
inner join ssb_100.customer as c on c.c_custkey = l.lo_custkey
inner join ssb_100.supplier as s on s.s_suppkey = l.lo_suppkey
inner join ssb_100.part as p on p.p_partkey = l.lo_partkey;
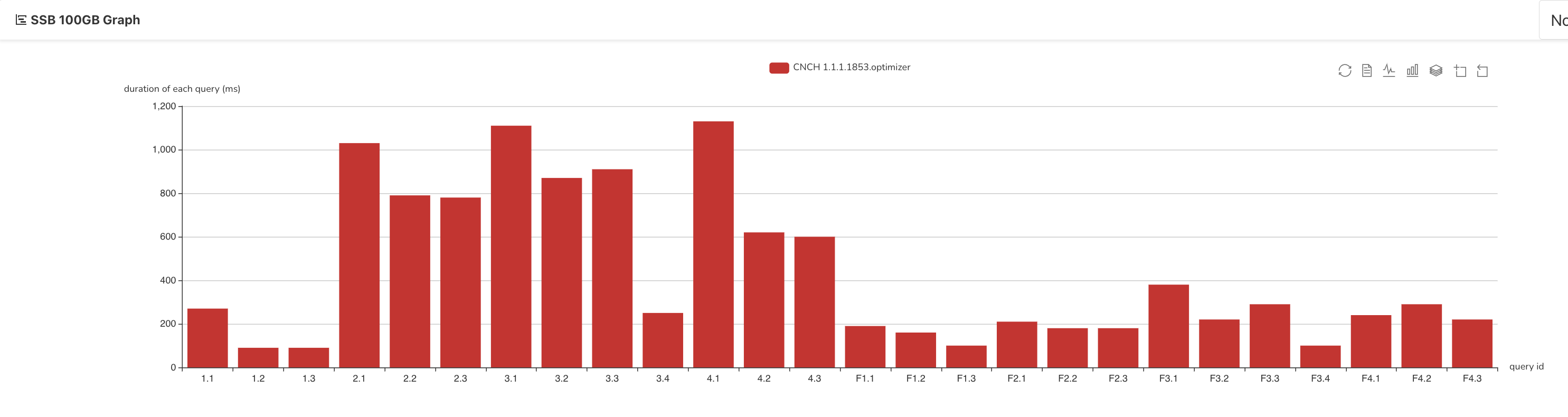
建表完成后,通过执行查询语句进行 SSB 性能测试,如下所示:

III. 查询结果和成本分析
执行完毕后,统计查询结果如下所示:
注:查询结果因配置参数和资源配置的不同,耗时也有差异,欢迎联系 ByteHouse 进行查询优化。

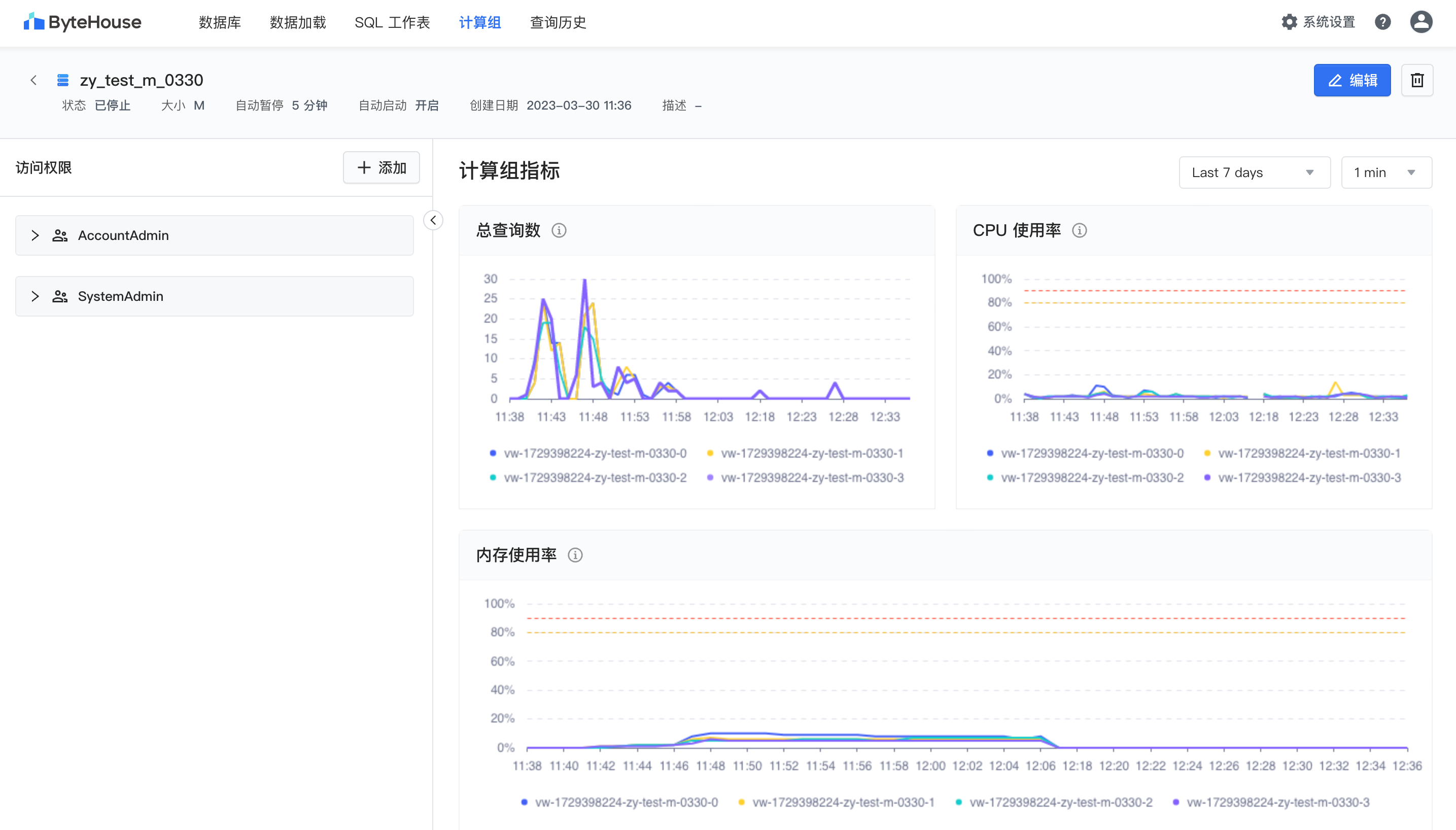
查询完成后,在 ByteHouse 计算组详情页面可以查看工作负载,包括总查询条数和 CPU/Mem 利用率等,从而确认计算资源的使用情况。
根据本次压测进行预估,消耗计算和存储资源如下表所示,由于 ByteHouse 云数仓版本按使用量计费的能力,在空闲时支持自动关闭计算组并不收取闲置费用,从而能够极大的节省资源。测试完成后,预估的总体消耗约为 31.23 元。

点击跳转 ByteHouse云原生数据仓库 了解更多
以 100GB SSB 性能测试为例,通过 ByteHouse 云数仓开启你的数据分析之路的更多相关文章
- ByteHouse云数仓版查询性能优化和MySQL生态完善
ByteHouse云数仓版是字节跳动数据平台团队在复用开源 ClickHouse runtime 的基础上,基于云原生架构重构设计,并新增和优化了大量功能.在字节内部,ByteHouse被广泛用于各类 ...
- MatrixOne从入门到实践08——SSB性能测试
MatrixOne从入门到实践--SSB性能测试 SSB 星型模式基准测试是 OLAP 数据库性能测试的常用场景,通过本篇教程,您可以了解到如何在 MatrixOne 中实现 SSB 测试. 测试环境 ...
- 一本通1587【例 3】Windy 数
1587: [例 3]Windy 数 时间限制: 1000 ms 内存限制: 524288 KB 题目描述 原题来自:SCOI 2009 Windy 定义了一种 Windy 数:不含前 ...
- 【CDH数仓】Day02:业务数仓搭建、Kerberos安全认证+Sentry权限管理、集群性能测试及资源管理、邮件报警、数据备份、节点添加删除、CDH的卸载
五.业务数仓搭建 1.业务数据生成 建库建表gmall 需求:生成日期2019年2月10日数据.订单1000个.用户200个.商品sku300个.删除原始数据. CALL init_data('201 ...
- LoadRunner性能测试样例分析
LR性能测试结果样例分析 测试结果分析 LoadRunner性能测试结果分析是个复杂的过程,通常可以从结果摘要.并发数.平均事务响应时间.每秒点击数.业务成功率.系统资源.网页细分图.Web服务器资源 ...
- web应用性能测试-Tomcat 7 连接数和线程数配置
转自:http://www.jianshu.com/p/8445645b3aff 引言 这段时间折腾了哈java web应用的压力测试,部署容器是tomcat 7.期间学到了蛮多散碎的知识点,及时梳理 ...
- UniqueMergeTree:支持实时更新删除的 ClickHouse 表引擎
UniqueMergeTree 开发的业务背景 首先,我们看一下哪些场景需要用到实时更新. 我们总结了三类场景: 第一类是业务需要对它的交易类数据进行实时分析,需要把数据流同步到 ClickHouse ...
- 2023云数据库技术沙龙MySQL x ClickHouse专场成功举办
4月22日,2023首届云数据库技术沙龙 MySQL x ClickHouse 专场,在杭州市海智中心成功举办.本次沙龙由玖章算术.菜根发展.良仓太炎共创联合主办.围绕"技术进化,让数据更智 ...
- MaxCompute/DataWorks权限问题排查建议
MaxCompute/DataWorks权限问题排查建议 __前提:__MaxCompute与DataWorks为两个产品,在权限体系上既有交集又要一定的差别.在权限问题之前需了解两个产品独特的权限体 ...
- 异构数据库迁移——DATAX
背景 在最近接触到的一个case里面,需要把db2的数据迁移至oracle,客户可接收的停机时间为3小时. 同步方式的比较 一说到停机时间,大家第一时间想到Oracle公司的GoldenGate实时同 ...
随机推荐
- HarmonyOS UI 开发
引言 HarmonyOS 提供了强大的 UI 开发工具和组件,使开发者能够创建吸引人的用户界面.本章将详细介绍在 HarmonyOS 中应用 JS.CSS.HTML,HarmonyOS 的 UI 组件 ...
- 手撕Vuex-实现actions方法
经过上一篇章介绍,完成了实现 mutations 的功能,那么接下来本篇将会实现 actions 的功能. 本篇我先介绍一下 actions 的作用,然后再介绍一下实现的思路,最后再实现代码. act ...
- go中的内存逃逸
内存逃逸(memory escape)是指在编写 Go 代码时,某些变量或数据的生命周期超出了其原始作用域的情况.当变量逃逸到函数外部或持续存在于堆上时,会导致内存分配的开销,从而对程序的性能产生负面 ...
- Spring及UML
深入浅出UML:http://blog.csdn.net/lovelion/article/details/7843437 //Component 1 package umltest.ticketma ...
- Asp.Net Core webapi+net6 使用资源筛选器(过滤器) 做缓存
写一个特性类,用来做标记 [AttributeUsage(AttributeTargets.Method)] //只对方法有效 public class ResourceFilterAttribute ...
- Python 潮流周刊#26:requests3 的现状
你好,我是猫哥.这里每周分享优质的 Python.AI 及通用技术内容,大部分为英文.本周刊开源,欢迎投稿.另有电报频道作为副刊,补充发布更加丰富的资讯. 品牌赞助 本周刊由"Python猫 ...
- String 的 indexOf 与 search 方便的区别
String 这个对象里面包含许多方法 今天只要讲 indexOf 与 search 1.indexOf stringObject.indexOf(searchvalue,fromindex) 2.s ...
- 浅谈斜率优化DP
前言 考试 T2 出题人放了个树上斜率优化 DP,直接被同校 OIER 吊起来锤. 离 NOIP 还有不到一周,赶紧学一点. 引入 斜率 斜率,数学.几何学名词,是表示一条直线(或曲线的切线)关于(横 ...
- 大立科技DM63红外相机SDK开发Ⅰ-连接仪器
1.开发准备 为了方便发开,需要下载Visual Studio,本开发基于Visual Studio 2022,使用C++. 通过Visual Studio创建好项目后,将DMSDK V1.16.3内 ...
- Android app兼容低版本Java环境
原文地址: Android app兼容低版本Java环境 - Stars-One的杂货小窝 起因是修复一个Bug遇到的问题,找到了一个可以让app兼容低版本java的方法 众所周知,Android版本 ...