图数据库实操:用 Nebula Graph 破解成语版 Wordle 谜底
{kind=link}

春节期间如果有小伙伴玩过 Wordle 这个火爆社交媒体的猜词游戏,可能对成语版本的汉兜有所耳闻。在玩汉兜过程中,我发现用 Nebula Graph 的图查询来解 Antfu 的汉兜(中文成语版 Wordle handle.antfu.me)会是件特别有意思的事情,很适合当作图数据库语句的实操。在本文中,你将了解我是如何用知识图谱“作弊”解汉兜。
什么是汉兜?
汉兜(https://handle.antfu.me )是由 Vue/Vite 核心团队成员的 Antfu 的又一个非常酷的作品,一个非常精致的汉字版的 Wordle,它是一个每日挑战的填字游戏的中文成语版。
每天,汉兜会发起一个猜成语挑战,人们要在十次内猜对对应成语才能获胜,每一步之后都会收到相应的文字、声母、韵母、声调的匹配情况的提示,其中:绿色表示这个因素存在并且位置匹配、橘色表示这个元素存在但是位置不对,详细的规则可见如下的网页截图:

汉兜的乐趣在于在有限的尝试次数中,在大脑中搜寻可能的答案,不断地去逼近真理,任何试图作弊、讨巧去泄漏结果的行为都是很无趣、倒胃口的(比如从开源的汉兜代码里窃取信息),这个过程就像大脑做了个体操。
说到大脑的成语词汇量体操,我突然想到,为什么我们不能在大脑之外造一个汉语成语知识图谱,然后基于这个图谱实操一把图数据库,做个图查询体操呢?
构造解决汉兜的成语知识图谱
什么是知识图谱?
简单来说,知识图谱是一个连接实体之间关联关系的网络,它最初由 Google 提出并用来满足搜索引擎中基于知识推理才可获得(而不是网页倒排索引)的搜索问题,比如:”姚明妻子的年龄?“、”火箭队得过几次总冠军?“
这些问题里边,我们关注问题中的条件。到 2022 年的现在,知识图谱已经被广泛应用在推荐系统、问答系统、安全风控等等更多搜索之外的领域。
为什么需要用知识图谱解决汉兜?
原因就是:because I can
实际上,我们在大脑中解决字谜游戏的过程像极了图谱网络中的信息搜寻的过程,汉兜的解谜反馈提示条件天然适合被用图谱的语义来进行表达。在本文后边,你们会发现解谜条件翻译成图语义是非常自然的,这个问题就像是一个天然的为图谱而存在的练习一样,我相信这和知识图谱的结构和人脑中的知识结构接近有很大的关系。
如何构建面向汉兜解谜的知识图谱?
知识图谱是由实体(顶点)和关系(边)组成的,用图数据库管理系统(Graph Database MS)可以很方便地进行知识的入库、更改、查询、甚至可视化探索。
在本文里,我将利用开源的分布式图数据库 Nebula Graph 开实践这个过程,具体图谱系统的搭建我都会放在文末。
在本章,我们只讨论图谱的建模:如何面向汉兜的解谜去设计“实体”与“关系”。
图建模
最初的想法
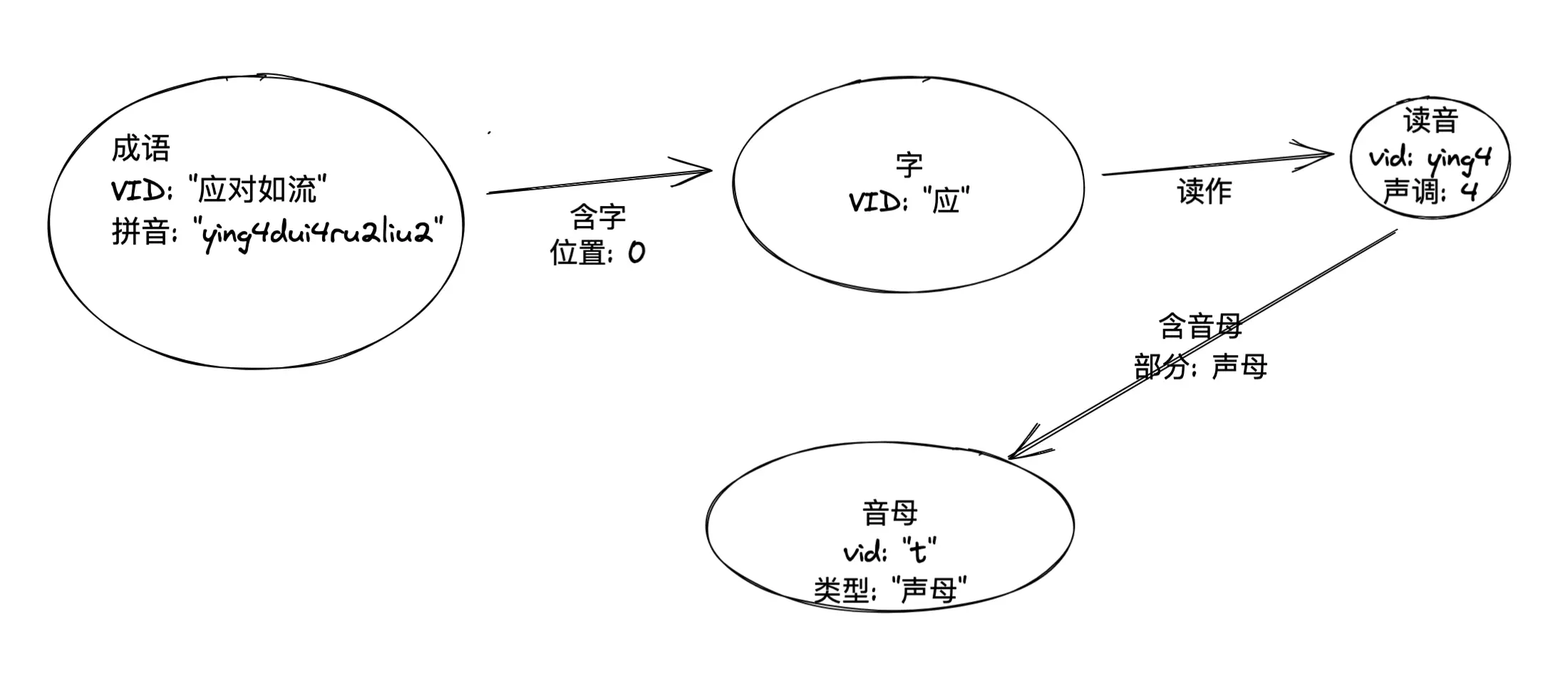
首先,一定存在的实体是:
- 成语
- 汉字
- 成语-[包含]->汉字,每个汉字-[读作]->读音。
其次,因为解谜过程中涉及到了声母、韵母以及声调的条件,考虑到图谱本身的量级非常小(千级别),而且字的读音是一对多的关系,我把读音和声母(包涵声母-initial和韵母-final)也作为实体,他们之间的关系则是顺理成章了:
最终的版本
然而,我在后边基于图谱进行查询的时候发现最初的建模会使得 (成语)–>(字)–>(读音) 查询过程中丢失了这个字特定的读法的条件,所以我最终的建模是:
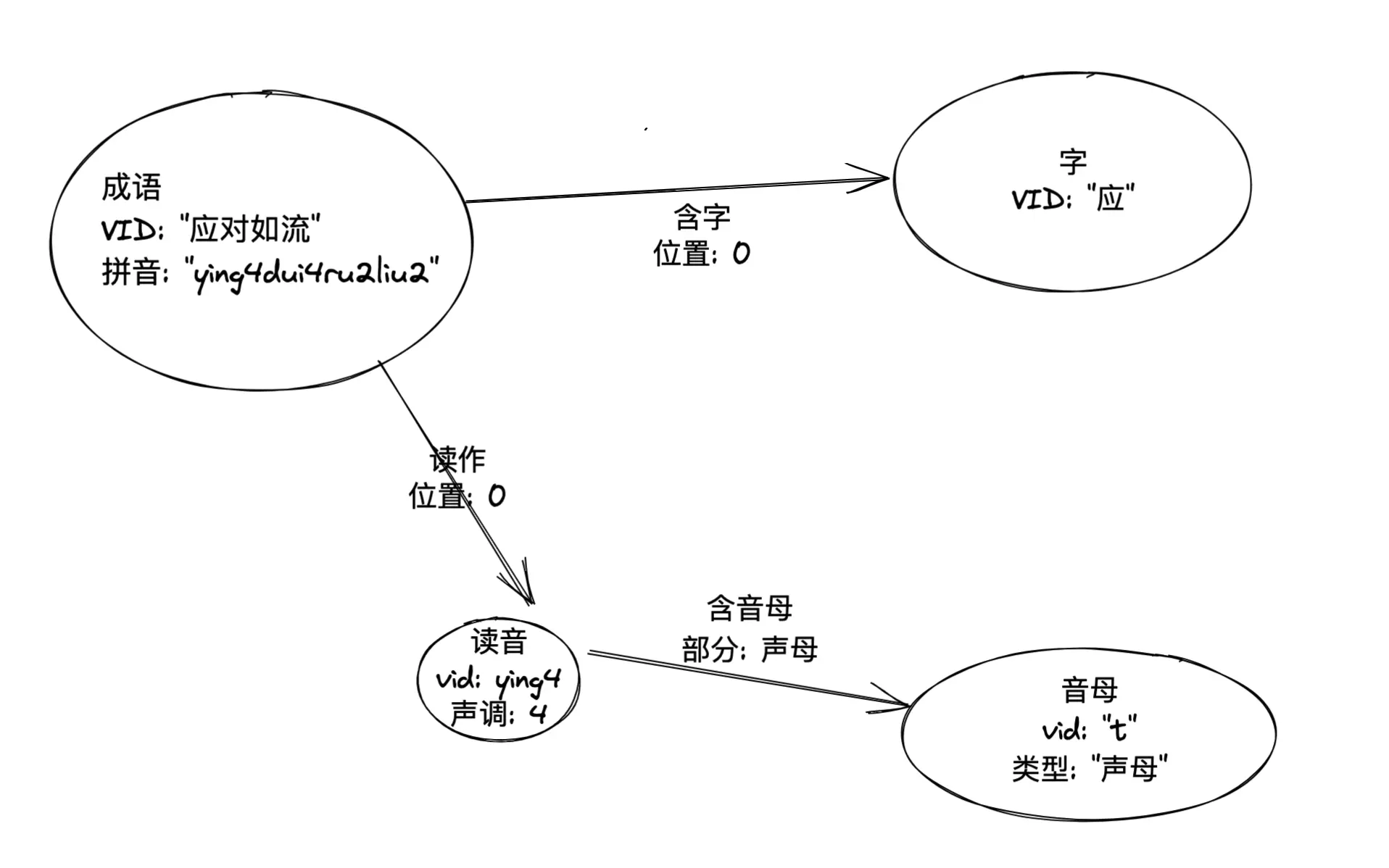
这样,纯文字的条件只涉及了 (成语)-->(字) 这一跳,而读音、声母、声调的条件则是另一条关系路径,既没有最初版本条件的冗余,又可以在一个路径模式匹配里带上两种条件(后边的例子里会涉及这样的表达)。
构建成语知识图谱
有了建模、这么简单的图谱的构建就剩下了数据的收集、清洗和入库。
对于所有成语数据和他们的读音,我一方面直接抽取了汉兜代码内部的数据,另一方面利用 PyPinyin 这个开源的 Python 库将汉兜数据中没有读音的数据获得读音,同时,我也用到了 PyPinyin 里的很多方便的函数,比如:获取一个拼音的声母、韵母。
构建工具的代码在这里:https://github.com/wey-gu/chinese-graph
更多信息我也放在文末的附录之中。
开始知识图谱查询体操
至此,我假设咱们都已经有了我帮大家搭建的成语作弊知识图谱了,开始我们的图谱查询体操吧!
首先,打开汉兜 https://handle.antfu.me/
假设我们想从一个成语开始,如果你没有想法的话可以试试这个:
# 匹配成语中的一个结果
MATCH (x:idiom) "爱憎分明" RETURN x LIMIT 1
# 返回结果
("爱憎分明" :idiom{pinyin: "['ai4', 'zeng1', 'fen1', 'ming2']"})
然后我们把它填到汉兜之中,获得第一次尝试的提示条件:
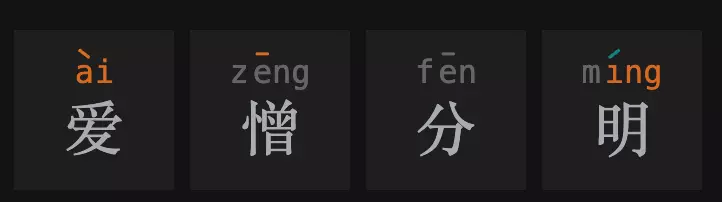
我们运气不错,得到了三个位置上的条件!
- 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱(爱)
- 有一个一声的字,不在第二个位置(憎)
- 有一个字韵母是 ing,不在第四个位置(明)
- 第四个字是二声(明)
下面,我们开始图数据库语句体操!
# 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "爱"
# 有一个一声的字,不在第二个位置
MATCH (x:idiom) -[with_pinyin_1:with_pinyin]->(pinyin_1:character_pinyin)
WHERE pinyin_1.character_pinyin.tone == 1 AND with_pinyin_1.position != 1
# 有一个字韵母是 ing,不在第四个位置
MATCH (x:idiom) -[with_pinyin_2:with_pinyin]->(:character_pinyin)-[:with_pinyin_part]->(final_part_2:pinyin_part{part_type: "final"})
WHERE id(final_part_2) == "ing" AND with_pinyin_2.position != 3
# 第四个字是二声
MATCH (x:idiom) -[with_pinyin_3:with_pinyin]->(pinyin_3:character_pinyin)
WHERE pinyin_3.character_pinyin.tone == 2 AND with_pinyin_3.position == 3
RETURN x, count(x) as c ORDER BY c DESC
在图数据库之中运行,得到了 7 个答案:
("惊愚骇俗" :idiom{pinyin: "['jing1', 'yu2', 'hai4', 'su2']"})
("惊世骇俗" :idiom{pinyin: "['jing1', 'shi4', 'hai4', 'su2']"})
("惊见骇闻" :idiom{pinyin: "['jing1', 'jian4', 'hai4', 'wen2']"})
("沽名卖直" :idiom{pinyin: "['gu1', 'ming2', 'mai4', 'zhi2']"})
("惊心骇神" :idiom{pinyin: "['jing1', 'xin1', 'hai4', 'shen2']"})
("荆棘载途" :idiom{pinyin: "['jing1', 'ji2', 'zai4', 'tu2']"})
("出卖灵魂" :idiom{pinyin: "['chu1', 'mai4', 'ling2', 'hun2']"})
看起来“惊世骇俗“比较主流,试试!

我们很幸运,借助于成语作弊知识图谱,居然一次就找到了答案,当然这实际上得益于第一次随机选取的词带来的限制条件的个数,不过在大部分情况下,两次尝试获得最终答案的可能性还是非常大的!
注,这中间很长的 253 分钟是因为我在查询中发现之前代码里构造的图谱有点 bug,是“披枷带锁”这个词引起的读音图谱的错误数据,还好后来被修复了。
大家知道“披枷带锁”的正确读音么?
回题,我给大家详细解释一下这个成语破解的过程。
语句的含义
我们从第一个字的条件开始,这是一个既有声音、又有字形信息的条件。
- 声音信息:存在一个韵母为 ai4 的发音,位置不在第一个字
- 文字信息:这个韵母为 ai4 的字,不是爱字
对于声音信息条件,转换为图模式匹配为:(成语)-一个字发音-(拼音)-包含声母-(韵母) WHERE 拼音韵母为 ai4 AND 位置不是第一个。
因为建模的时候,属性名称我用的是英文(其实中文也是支持的),实际上的语句为:
# 有一个非第一个位置的字,拼音是 4 声,韵母是 ai
MATCH (x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0
# ...
RETURN x
类似的,表示非第一个位置的字,不是爱的表达是:
# 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)
WHERE with_char_0.position != 0 AND id(char0) != "爱"
# ...
RETURN x, count(x) as c ORDER BY c DESC
而因为这两个条件最终描述的是同一个字,所以它们是可以被写在一个路径下的:
# 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱
MATCH (char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "爱"
# ...
RETURN x
更多的 MATCH 语法和例子细节,请大家参考文档:
- MATCH:https://docs.nebula-graph.com.cn/3.0.1/3.ngql-guide/7.general-query-statements/2.match/
- 图模式:https://docs.nebula-graph.com.cn/3.0.1/3.ngql-guide/1.nGQL-overview/3.graph-patterns/
- nGQL 命令:cheatsheet
可视化展示线索
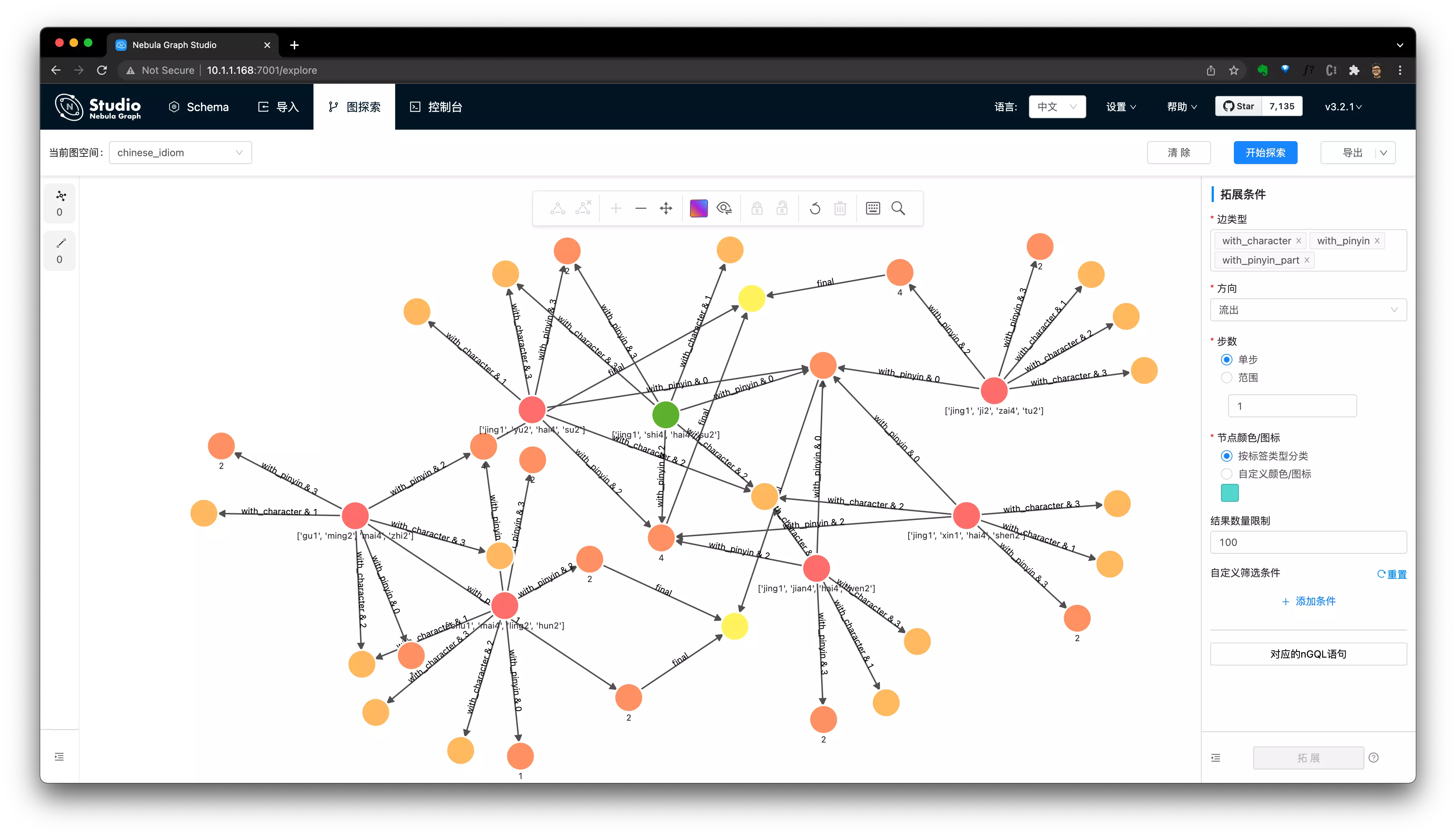
我们把每一个条件的匹配路径作为输出,利用 Nebula Graph 的可视化能力,可以得到:
# 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱 # 有一个非第一个位置的字,拼音是 4 声,韵母是 ai,但不是爱
MATCH p0=(char0:character)<-[with_char_0:with_character]-(x:idiom)-[with_pinyin_0:with_pinyin]->(pinyin_0:character_pinyin)-[:with_pinyin_part]->(final_part_0:pinyin_part{part_type: "final"})
WHERE id(final_part_0) == "ai" AND pinyin_0.character_pinyin.tone == 4 AND with_pinyin_0.position != 0 AND with_char_0.position != 0 AND id(char0) != "爱"
# 有一个一声的字,不在第二个位置
MATCH p1=(x:idiom) -[with_pinyin_1:with_pinyin]->(pinyin_1:character_pinyin)
WHERE pinyin_1.character_pinyin.tone == 1 AND with_pinyin_1.position != 1
# 有一个字韵母是 ing,不在第四个位置
MATCH p2=(x:idiom) -[with_pinyin_2:with_pinyin]->(:character_pinyin)-[:with_pinyin_part]->(final_part_2:pinyin_part{part_type: "final"})
WHERE id(final_part_2) == "ing" AND with_pinyin_2.position != 3
# 第四个字是二声
MATCH p3=(x:idiom) -[with_pinyin_3:with_pinyin]->(pinyin_3:character_pinyin)
WHERE pinyin_3.character_pinyin.tone == 2 AND with_pinyin_3.position == 3
RETURN p0,p1,p2,p3
在可视化工具的 Console 控制台里执行上边的语句之后,选择导入图探索,就可以看到:
下一步
如果大家是从本文第一次了解到 Nebula Graph 图数据库,那么大家可以下一步从 Nebula Graph 项目和 Nebula Graph 社区的官方 Bilibili 站点 https://space.bilibili.com/472621355 了解更多有意思的入门知识。
另外,这里是 Nebula Graph 的官方线上试玩环境,大家可以照着文档,利用试玩环境尝鲜。
后边,Nebula Graph 会开展每天的汉兜 nGQL 体操活动,敬请关注哈!
Happy Graphing!
附录:搭建成语知识图谱
收集、生成图谱数据
$ python3 graph_data_generator.py
导入数据到 Nebula Graph 图数据库
部署图数据库
借助于 Nebula-Up:https://github.com/wey-gu/nebula-up/,一行就可以了。
$ curl -fsSL nebula-up.siwei.io/install.sh | bash -s -- v3.0.0
部署成功的话,会看到这样的结果:
┌────────────────────────────────────────┐
│ Nebula-Graph Playground is Up now! │
├────────────────────────────────────────┤
│ │
│ Congrats! Your Nebula is Up now! │
│ $ cd ~/.nebula-up │
│ │
│ You can access it from browser: │
│ http://127.0.0.1:7001 │
│ http://<other_interface>:7001 │
│ │
│ Or access via Nebula Console: │
│ $ ~/.nebula-up/console.sh │
│ │
│ To remove the playground: │
│ $ ~/.nebula-up/uninstall.sh │
│ │
│ Have Fun! │
│ │
└────────────────────────────────────────┘
图谱入库
借助于 Nebula-Importer https://github.com/vesoft-inc/nebula-importer/ ,一行就可以了。
$ docker run --rm -ti \
--network=nebula-docker-compose_nebula-net \
-v ${PWD}/importer_conf.yaml:/root/importer_conf.yaml \
-v ${PWD}/output:/root \
vesoft/nebula-importer:v3.0.0 \
--config /root/importer_conf.yaml
大概一两分钟数据就导入成功了,命令也会正常退出。
连到图数据库的 Console
获得本机第一个网卡的地址,这里是 10.1.1.168
$ ip address
2: enp4s0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 1000
link/ether 2a:32:4c:06:04:c4 brd ff:ff:ff:ff:ff:ff
inet 10.1.1.168/24 brd 10.1.1.255 scope global dynamic enp4s0
进入 Console 的容器执行下边的命令:
$ ~/.nebula-up/console.sh
# nebula-console -addr 10.1.1.168 -port 9669 -user root -p nebula
检查一下导入的数据:
(root@nebula) [(none)]> show spaces
+--------------------+
| Name |
+--------------------+
| "chinese_idiom" |
+--------------------+
(root@nebula) [(none)]> use chinese_idiom
Execution succeeded (time spent 1510/2329 us)
Fri, 25 Feb 2022 08:53:11 UTC
(root@nebula) [chinese_idiom]> match p=(成语:idiom) return p limit 2
+------------------------------------------------------------------+
| p |
+------------------------------------------------------------------+
| <("一丁不识" :idiom{pinyin: "['yi1', 'ding1', 'bu4', 'shi2']"})> |
| <("一丝不挂" :idiom{pinyin: "['yi1', 'si1', 'bu4', 'gua4']"})> |
+------------------------------------------------------------------+
(root@nebula) [chinese_idiom]> SUBMIT JOB STATS
+------------+
| New Job Id |
+------------+
| 11 |
+------------+
(root@nebula) [chinese_idiom]> SHOW STATS
+---------+--------------------+--------+
| Type | Name | Count |
+---------+--------------------+--------+
| "Tag" | "character" | 4847 |
| "Tag" | "character_pinyin" | 1336 |
| "Tag" | "idiom" | 29503 |
| "Tag" | "pinyin_part" | 57 |
| "Edge" | "with_character" | 116090 |
| "Edge" | "with_pinyin" | 5943 |
| "Edge" | "with_pinyin_part" | 3290 |
| "Space" | "vertices" | 35739 |
| "Space" | "edges" | 125323 |
+---------+--------------------+--------+
附录:图建模的 Schema nGQL
CREATE SPACE IF NOT EXISTS chinese_idiom(partition_num=5, replica_factor=1, vid_type=FIXED_STRING(24));
USE chinese_idiom;
# 创建点的类型
CREATE TAG idiom(pinyin string); #成语
CREATE TAG character(); #汉字
CREATE TAG character_pinyin(tone int); #单字的拼音
CREATE TAG pinyin_part(part_type string); #拼音的声部
# 创建边的类型
CREATE EDGE with_character(position int); #包含汉字
CREATE EDGE with_pinyin(position int); #读作
CREATE EDGE with_pinyin_part(part_type string); #包含声部
参考文献
交流图数据库技术?加入 Nebula 交流群请先填写下你的 Nebula 名片,Nebula 小助手会拉你进群~~
{kind=link}
图数据库实操:用 Nebula Graph 破解成语版 Wordle 谜底的更多相关文章
- mysql数据库实操笔记20170418
一.建立商品分类表和价格表: 1.分类表`sankeq``sankeq`CREATE TABLE cs_mysql11(id INT(11) NOT NULL AUTO_INCREMENT,categ ...
- Python3安装cx_Oracle连接oracle数据库实操总结
弄清版本,最重要!!! 首先安装配置时,必须把握一个点,就是版本一致!包括:系统版本,python版本,oracle客户端的版本,cx_Oracle的版本,然后安装配置就容易了! 如果已经安装Pyth ...
- mysql数据库实操笔记20170419
一.insert与replace区别: insert:当表里有字段设置了主键或者唯一时,插入重复的唯一或主键字段值是不能执行的: replase:当表里有字段设置了主键或者唯一时,插入重复的唯一或主键 ...
- 实操一下<python cookbook>第三版1
这几天没写代码, 练一下代码. 找的书是<python cookbook>第三版的电子书. *这个操作符,运用得好,确实少很多代码,且清晰易懂. p = (4, 5) x, y = p p ...
- COSCon'19 | 如何设计新一代的图数据库 Nebula
11 月 2 号 - 11 月 3 号,以"大爱无疆,开源无界"为主题的 2019 中国开源年会(COSCon'19)正式启动,大会以开源治理.国际接轨.社区发展和开源项目为切入点 ...
- 图数据库 Nebula Graph 的数据模型和系统架构设计
Nebula Graph:一个开源的分布式图数据库.作为唯一能够存储万亿个带属性的节点和边的在线图数据库,Nebula Graph 不仅能够在高并发场景下满足毫秒级的低时延查询要求,而且能够提供极高的 ...
- 全方位讲解 Nebula Graph 索引原理和使用
本文首发于 Nebula Graph Community 公众号 index not found?找不到索引?为什么我要创建 Nebula Graph 索引?什么时候要用到 Nebula Graph ...
- 分布式图数据库 Nebula Graph 的 Index 实践
导读 索引是数据库系统中不可或缺的一个功能,数据库索引好比是书的目录,能加快数据库的查询速度,其实质是数据库管理系统中一个排序的数据结构.不同的数据库系统有不同的排序结构,目前常见的索引实现类型如 B ...
- Nebula Graph 技术总监陈恒:图数据库怎么和深度学习框架进行结合?
引子 Nebula Graph 的技术总监在 09.24 - 09.30 期间同开源中国·高手问答的小伙伴们以「图数据库的设计和实践」为切入点展开讨论,包括:「图数据库的存储设计」.「图数据库的计算设 ...
- 分布式图数据库 Nebula Graph 中的集群快照实践
1 概述 1.1 需求背景 图数据库 Nebula Graph 在生产环境中将拥有庞大的数据量和高频率的业务处理,在实际的运行中将不可避免的发生人为的.硬件或业务处理错误的问题,某些严重错误将导致集群 ...
随机推荐
- .NET MAUI 简介
欢迎使用.NET 多平台应用程序 UI.此版本标志着我们在统一 .NET 平台的多年旅程中的新里程碑.现在,您和超过 500 万其他 .NET 开发人员拥有面向 Android.iOS.macOS 和 ...
- LyScriptTools 反汇编类API接口手册
LyScriptTools模块实在LyScript模块反汇编基础上封装而成,其提供了更多的反汇编方法,可以更好的控制x64dbg完成自动化反汇编任务,API参考手册如下. 插件地址:https://g ...
- C/C++ Qt 基本文件读写方法
Qt文件操作有两种方式,第一种使用QFile类的IODevice读写功能直接读写,第二种是利用 QFile和QTextStream结合起来,用流的方式进行文件读写. 第一种,利用QFile中的相关函数 ...
- Redis中的key的生存时间和过期时间
目录 1.说明 2.指令 2.1.删除和更新 3.过期时间的保存 4.计算剩余生存时间 5.过期键的删除策略 5.1.定时删除 5.2.惰性删除 5.3.定期删除 1.说明 生存时间: (Time T ...
- libuv计时器
目录 1.uv_timer_t - 计时器句柄 2.API 2.1.uv_timer_init 2.2.uv_timer_start 2.3.uv_timer_stop 2.4.uv_timer_ag ...
- Python 元组详细使用
1. 元组 元组和列表类似,但属于不可变序列,元组一旦创建,用任何方法都不可修改其元素. 元组的定义方式和列表相同,但定义时所有元素是放在一对圆括号"()"中,而不是方括号中. 1 ...
- Python内置小工具(非常实用!)
一.1秒钟启动一个下载服务器在工作中时不时会有这样的一个需求:将服务器(或者自己电脑)上的文件传给其他同事.将文件传给同事本身并不是一个很繁琐的工作,现在的聊天工具一般都支持文件传输.但是,如果需要传 ...
- NC51222 Strategic game
题目链接 题目 题目描述 Bob enjoys playing computer games, especially strategic games, but sometimes he cannot ...
- Wireguard笔记(一) 节点安装配置和参数说明
目录 Wireguard笔记(一) 节点安装配置和参数说明 Wireguard笔记(二) 命令行操作 Wireguard笔记(三) lan-to-lan子网穿透和多网段并存 简介 虚拟子网软件,类似于 ...
- Android上的日志
Android的日志机制和普通的Java项目有一些不一样, 这里记录一下 安卓内建的Log 安卓应用类型(在build.gradle里定义 android {...})的模块, 可以直接引用内建的an ...