LeViT:Facebook提出推理优化的混合ViT主干网络 | ICCV 2021
论文提出了用于快速图像分类推理的混合神经网络
LeVIT,在不同的硬件平台上进行不同的效率衡量标准的测试。总体而言,LeViT在速度/准确性权衡方面明显优于现有的卷积神经网络和ViT,比如在80%的ImageNet top-1精度下,LeViT在CPU上比EfficientNet快5倍来源:晓飞的算法工程笔记 公众号
论文: LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference

Introduction
虽然许多研究旨在减少分类器和特征提取器的内存占用,但推理速度同样重要,高吞吐量对应于更好的能源效率。论文的目标是开发一个基于Vision Transformer的模型系列,在GPU、CPU和ARM等高度并行的架构上具有更快的推理速度。
在相同的计算复杂度下,Transformer的速度会比卷积架构更快。这是因为大多数硬件加速器(GPU、TPU)都经过优化以执行大型矩阵乘法,而在Transformer中的注意力块和MLP块主要依赖于矩阵乘法。相反,卷积需要复杂的数据访问模式,通常跟IO绑定的。
论文引入轻量的卷积组件来代替产生类似卷积特征的Transformer组件,同时将统一的Transformer结构替换为带池化的金字塔结构。由于整体结构类似于LeNet,论文称新网络为LeViT。
除提出LeViT外,论文还提供了以下缩小ViT模型体量的方法:
- 使用注意力作为下采样机制的多阶段
Transformer架构。 - 计算高效的图像块提取器,可减少第一层中特征数量。
- 可学习且平移不变的注意力偏置,取代位置编码。
- 重新设计的
Attention-MLP块,计算量更低。
Motivation
Convolutions in the ViT architecture

ViT的图像块提取器一般为步幅16的16x16卷积,然后将输出乘以可学习的权重来得到第一个自注意力层的\(q\), \(k\)和\(v\)特征。论文认为,这些操作也可以认为是对输入进行卷积函数处理。
如图2所示,论文可视化了DeiT第一层的注意力权值,发现权值空间都有与Gabor滤波器类似的模式。
卷积中权值空间的平滑度主要来自卷积区域的重叠,相邻的像素接收大致相同的梯度。对于没有区域重叠ViT,权值空间的平滑可能是由数据增强引起的。当图像训练多次且有平移时,相同的梯度也会平移通过下一个滤波器,因此学习到了这种平滑的权值空间。
因此,尽管Transformer架构中不存在归纳偏置,但训练确实会产生类似于传统卷积层的权值空间。
Preliminary experiment: grafting
ViT的作者尝试将Transformer层堆叠在传统的ResNet-50之上,将ResNet-50充当Transformer层的特征提取器,梯度可以在两个网络传播中。然而,在他们的实验中,Transformer层的数量是固定的。
与ViT的实验不同的是,论文主要在相近算力的情况下对比不同数量的卷积阶段和Transformer层数时之间的性能,进行Transformer与卷积网络的混合潜力的研究。
论文对具有相似的运行时间ResNet-50和DeiT-Small进行实验,由于裁剪后的ResNet产生的激活图比DeiT使用的\(14\times14\)激活图更大,需要在它们之间引入了一个平均池化层。同时,在卷积层和Transformer层的转换处引入了位置编码和分类标记。对于ResNet-50,论文使用ReLU激活层和BN层。
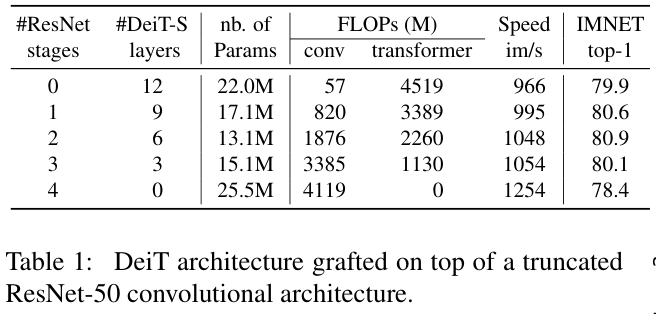
结果如表1所示,混合架构均比单独的DeiT和ResNet-50的性能要好,两个阶段的ResNet-50的参数数量最少且准确度最高。
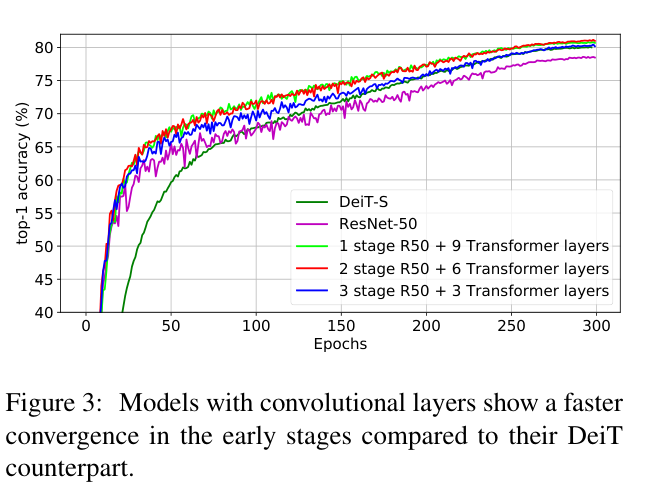
论文在图 3 中展示了一个有趣的观察结果:混合模型在训练期间的早期收敛类似于卷积网络,随后切换到类似于DeiT-S的收敛速度。由于卷积层具有很强的归纳偏差能力(尤其是平移不变性),能够更有效地学习早期层中的低级特征,而高质量的图像块编码使得训练初期能更快地收敛。
Model
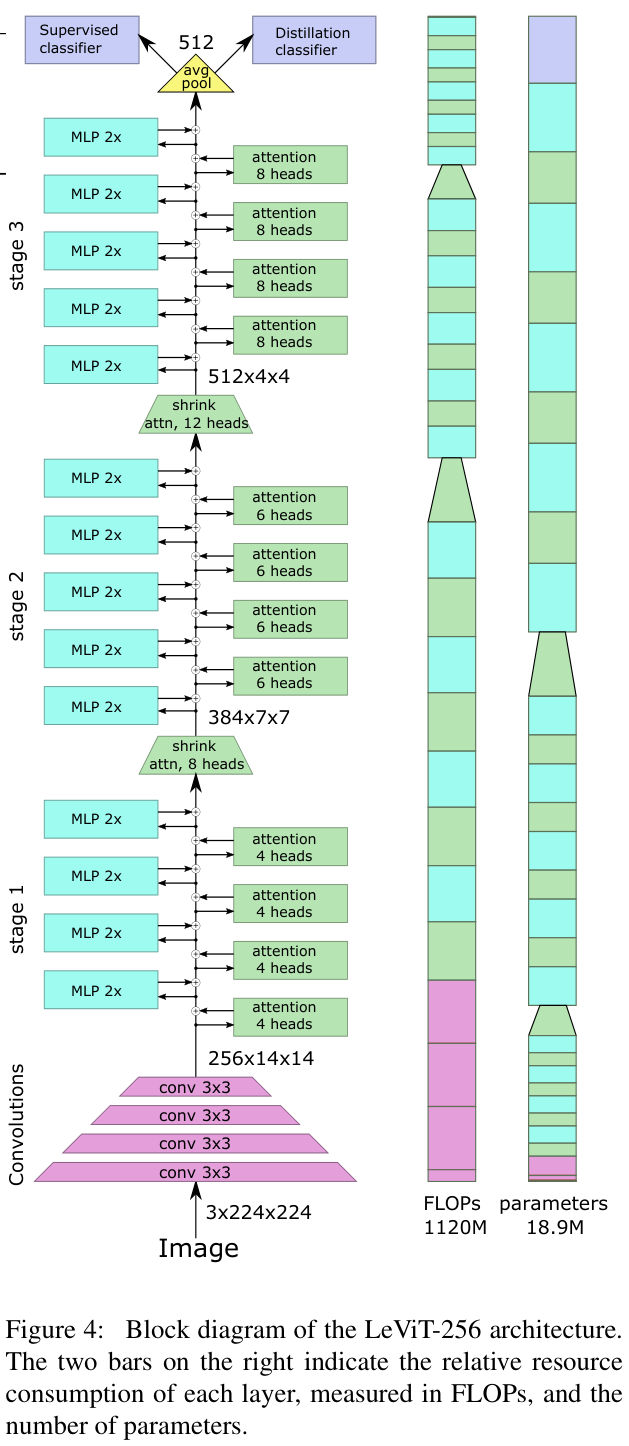
Design principles of LeViT
LeViT建立在ViT架构和DeiT训练方法之上,引入一些对卷积架构有用的组件。忽略分类标记的作用,ViT就是处理特征图的层堆叠,中间的特征编码可以看作是FCN架构中的传统\(C\times H\times W\) 特征图(\(B C H W\) 格式)。因此,适用于特征图的操作(池化、卷积)也可以应用于DeiT的中间特征。
需要注意的是,优化计算架构不一定要最小化参数数量。ResNet系列比VGG网络更高效的设计之一是在两个阶段以相对较小的额外计算消耗进行有效的分辨率降低,使得第三阶段的激活图的分辨率缩小到足够小(14x14),从而降低了计算成本。
LeViT components
Patch embedding
先前的分析表明,将小型卷积网络应用于Transformer的输入时可以提高准确性。在LeViT中,论文选择 4 层 \(3\times3\) 卷积(步幅为 2)来对输入进行处理,通道数分别为\(C\ =\ 32,64,128,256\),最终输出大小为\((256,14,14)\)的特征。这里的特征提取仅用了184 MFLOPs,而ResNet-18用了 1042 MFLOPs来执行相同的降维。
No classification token
为了使用 \(B C H W\) 的张量格式,论文去掉了分类标记,改为在最后一个特征图上用平均池化来产生用于分类器的编码。对于训练期间的蒸馏,论文为分类和蒸馏任务训练了不同的分类器。在测试时,将两个分类器输出进行平均。在实践中,LeViT可以使用\(B N C\) 或\(BCHW\)张量格式来实现,以实际效率为准。
Normalization layers and activations
ViT架构中的FC层相当于\(1 \times 1\) 卷积,每个注意力层和MLP层前都使用层归一化。对于LeViT,每个卷积之后都进行BN归一化,与残差连接相连的BN归一化层的权值都被初始化为零。BN归一化可以与前面的卷积合并推理,这是优于层归一化的运行时优势(在EfficientNet B0上,这种融合将GPU上的推理速度提高了 2 倍)。DeiT使用GELU激活函数,而LeViT使用Hardswish激活函数。
Multi-resolution pyramid
卷积架构一般构建为金字塔,特征分辨率随着处理过程中通道数量的增加而降低。LeViT将ResNet的阶段集成到Transformer架构中,阶段内部则是类似于ViT的残差结构。
Downsampling
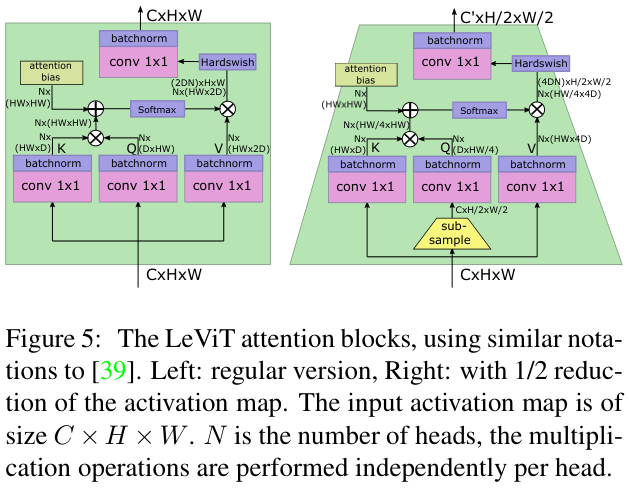
在LeViT的阶段之间,使用shrinking注意力块来减小激活图的大小。在Q映射前,先应用下采样再软激活得到输出。这可以将大小为\((C,H,W)\)的输入张量映射到大小为\((G^{\prime},H/2,W/2)\)的输出张量,其中\({C}^{\prime}\,>\,{C}\,\)。由于尺寸的变化,使用此注意力块时没有残差连接。另外,为了防止信息丢失,论文将注意力头的数量增加为\(C/D\)。
Attention bias instead of a positional embedding
Transformer架构中的位置编码是一个位置相关的可训练参数向量,将其与输入序列合并后再输入Transformer块进行后续计算。如果不使用位置编码,Transformer输出将独立于输入序列的排列关系,导致分类精度的急剧下降。
由于位置编码对于更高层特征提取也很重要,因此它很可能保留在中间特征中,导致不必要地占用特征容量。因此,论文尝试在每个注意力块内提供位置信息,并在注意力机制中显式注入相对位置信息(在注意力图计算中添加一个注意力偏差)。
对于头 \(h\in[N]\),两个像素 \((x,y)\ \in [H] × [W]\) 和 \((x^{\prime},y^{\prime})\in[H]\times[W]\) 之间的注意力值计算为
\]
第一项是经典注意力,第二个是平移不变的注意力偏置。每个头都有\(H\times W\)个参数,对应不同的像素偏移情况,距离取绝对值能鼓励模型训练翻转不变性。
Smaller keys
注意力偏置项减少了键映射矩阵编码位置信息的压力,因此论文减小了 \({\cal{Q}}\) 和 \({\cal{K}}\) 通道数,缩短相关矩阵的运算时间。假设 \({\cal{Q}}\) 和 \({\cal{K}}\) 的通道数为\(D\;\in\;\{16,32\}\),则 \({\cal{V}}\) 的通道数为 \(2D\)。
对于没有残差连接的下采样层,论文将 \({\cal{V}}\) 的维度设置为 \({\mathrm{4}}D\) 以防止信息丢失。
Attention activation
在使用线性映射组合不同头的输出之前,论文对 \(A^{h}V\) 乘积应用Hardswish激活。
Reducing the MLP blocks
ViT中的MLP残差块是一个线性层,先将输入通道数增加 4 倍,应用非线性映射后再通过另一个非线性映射将其降低回原始输入的通道数。由于MLP在运行时间和参数方面通常比注意力块更高,LeViT将MLP层替换为\(1\times 1\)卷积,然后通过BN层进行归一化。为了降低计算成本,论文将卷积的扩展因子从4减少到2,这使得注意块和MLP块的计算量大致相同。
The LeViT family of models
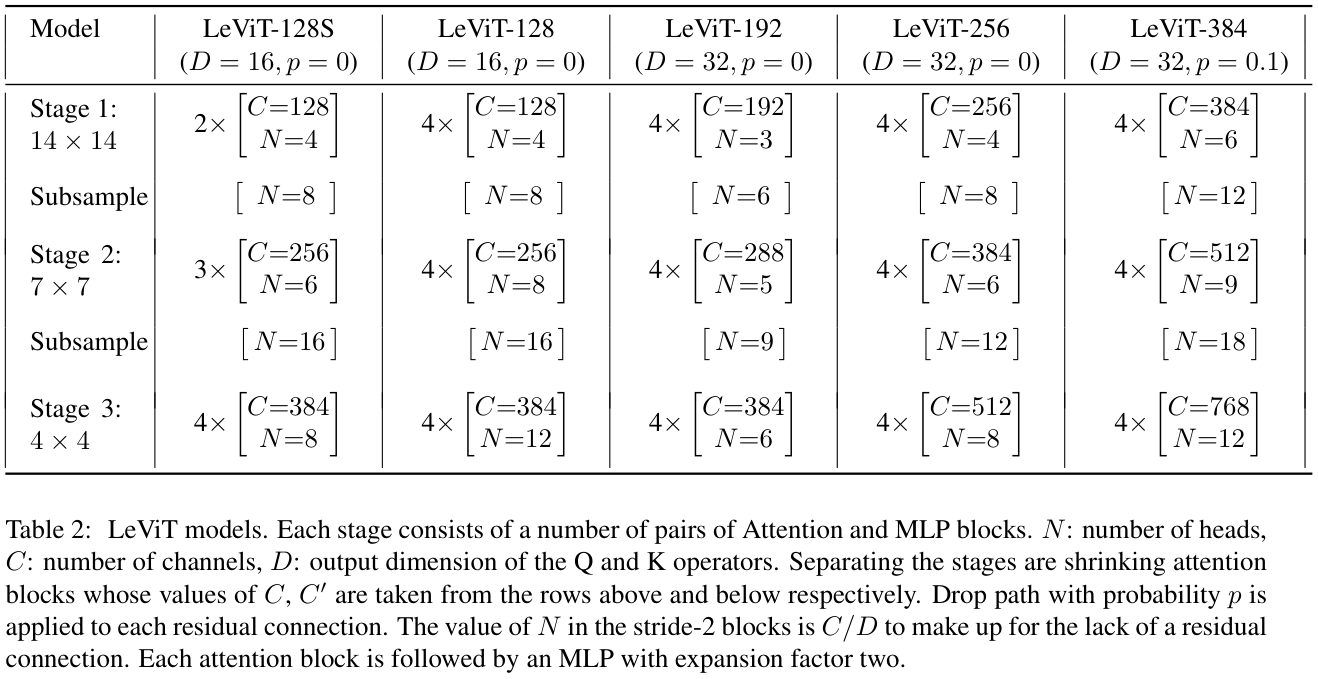
LeViT模型可以通过改变各阶段的大小来权衡速度和精度,表2展示了论文涉及的LeViT系列模型。
Experiments
Experimental context
论文在PyTorch中运行所有实验,因此论文依赖于该API中可用的优化。为了获得更客观的时序,论文在三个不同的硬件平台上对推理进行计时,每个平台对应一个用例:
- 一个
16GB NVIDIA Volta GPU(峰值性能为12 TFLOP/s),这是一个典型的训练加速器。 2.0 GHz的Intel Xeon 6138 CPU,这是数据中心中的典型服务器。PyTorch针对此配置进行了很好的优化,使用MKL和AVX2指令(16 个向量寄存器,每个寄存器 256 位)。ARM Graviton2 CPU(Amazon C6g实例),这是移动电话和其他边缘设备运行的处理器类型。Graviton2有 32 个内核,支持带有 32 个 128 位向量寄存器 (NEON) 的NEON矢量指令集。
Training LeViT
论文使用 32 个GPU在 3 到 5 天内训练 1000 个周期,这比卷积网络的通常时间表要多,但是ViT本身就需要长时间的训练才能有更好的性能。论文使用类似于DeiT的蒸馏训练,这意味着LeViT使用两个具有交叉熵损失的分类头进行训练:第一个头接受来自真实类的监督,第二个来自在ImageNet上训练的RegNetY-16GF模型。实际上,LeViT的训练时间主要由教师网络的推理时间决定。
Speed-accuracy tradeoffs
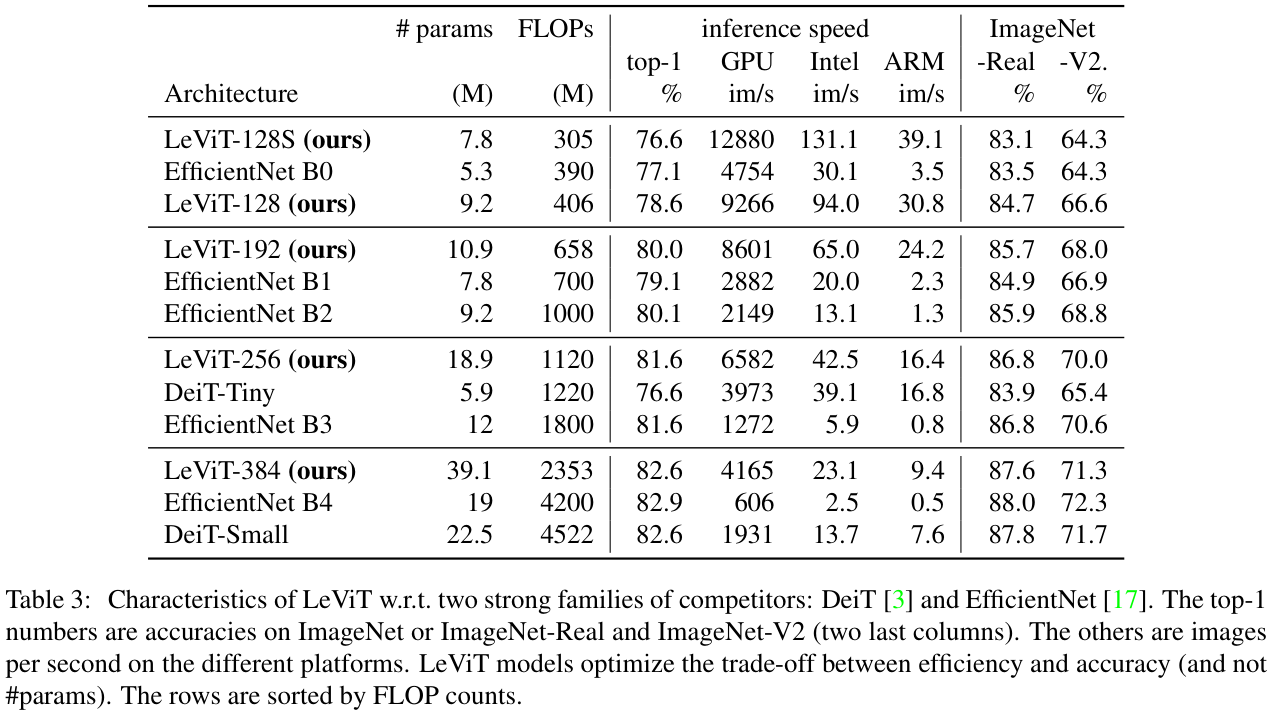
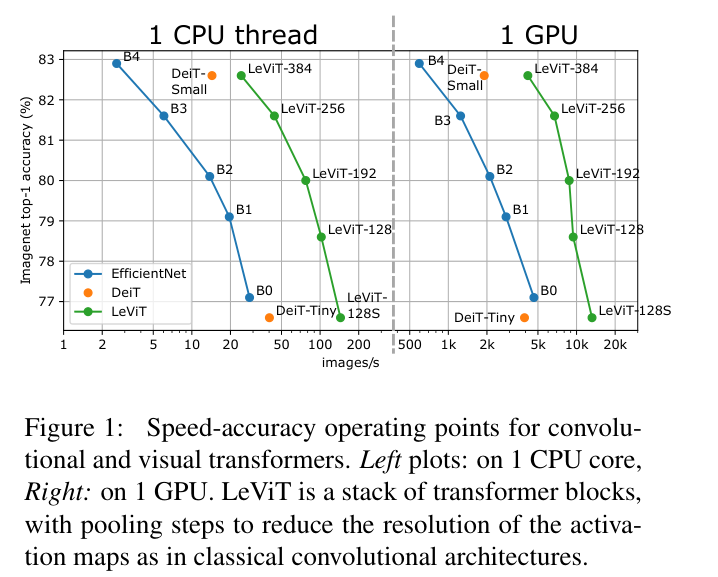
表 3 显示了论文使用LeViT在速度和精度之间的权衡,图 1 则绘制了一些显着数字。在同级别的速度下,LeViT的速度都要优异一些。
在表 3 中,测试集还有Imagenet Real和Imagenet V2(matched-frequency),两个数据集使用与ImageNet相同的一组类和训练集。Imagenet-Real对图片重新标签,每个图像可能有多个类别,Imagenet-V2则使用新的测试图。通过模型在这两个数据集上的性能,可以验证超参数调整有没有对ImageNet验证集过度拟合。
Comparison with the state of the art
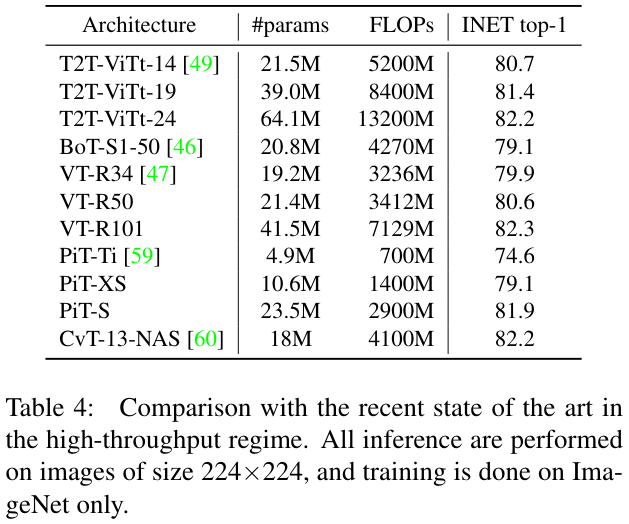
表 4 展示其他基于Transformer架构的结果进行了对比,可以与LeViT(表 3)进行比较,实验不包括速度慢的大模型。为了方便,论文直接以FLOPs作为速度标准,不实测时间。
Ablations
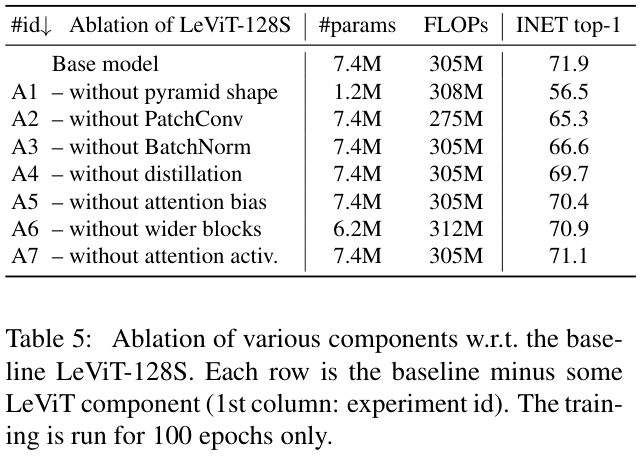
为了评估对LeViT性能有贡献的因素,论文使用默认设置进行实验,每次实验替换一个因素。实验仅运行 100 个训练周期以放大差异并减少训练时间,表 5 的结果展示了所有替换都会导致准确性的降低。
Conclusion
论文介绍了受卷积网络启发的Transformer架构LeViT,使用DeiT中的训练技术。LeViT的核心是在精度和速度之间进行权衡,在相当的精度下能够快 1.5 到 5 倍。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

LeViT:Facebook提出推理优化的混合ViT主干网络 | ICCV 2021的更多相关文章
- 天猫精灵业务如何使用机器学习PAI进行模型推理优化
引言 天猫精灵(TmallGenie)是阿里巴巴人工智能实验室(Alibaba A.I.Labs)于2017年7月5日发布的AI智能语音终端设备.天猫精灵目前是全球销量第三.中国销量第一的智能音箱品牌 ...
- 【翻译】借助 NeoCPU 在 CPU 上进行 CNN 模型推理优化
本文翻译自 Yizhi Liu, Yao Wang, Ruofei Yu.. 的 "Optimizing CNN Model Inference on CPUs" 原文链接: h ...
- 基于TensorRT车辆实时推理优化
基于TensorRT车辆实时推理优化 Optimizing NVIDIA TensorRT Conversion for Real-time Inference on Autonomous Vehic ...
- 腾讯云TKE-基于 Cilium 统一混合云容器网络(下)
前言 在 腾讯云TKE - 基于 Cilium 统一混合云容器网络(上) 中,我们介绍 TKE 混合云的跨平面网络互通方案和 TKE 混合云 Overlay 网络方案.公有云 TKE 集群添加第三方 ...
- 百度APP移动端网络深度优化实践分享(二):网络连接优化篇
本文由百度技术团队“蔡锐”原创发表于“百度App技术”公众号,原题为<百度App网络深度优化系列<二>连接优化>,感谢原作者的无私分享. 一.前言 在<百度APP移动端网 ...
- 看Facebook是如何优化React Native性能
原文出处: facebook 译文出处:@Siva海浪高 该文章翻译自Facebook官方博客,传送门 React Native 允许我们运用 React 和 Relay 提供的声明式的编程模型, ...
- [评测]低配环境下,PostgresQL和Mysql读写性能简单对比(欢迎大家提出Mysql优化意见)
[评测]低配环境下,PostgresQL和Mysql读写性能简单对比 原文链接:https://www.cnblogs.com/blog5277/p/10658426.html 原文作者:博客园--曲 ...
- Facebook提出DensePose数据集和网络架构:可实现实时的人体姿态估计
https://baijiahao.baidu.com/s?id=1591987712899539583 选自arXiv 作者:Rza Alp Güler, Natalia Neverova, Ias ...
- 拳打Adam,脚踢SGD:北大提出全新优化算法AdaBound
https://mp.weixin.qq.com/s/el1E-61YjLkhFd6AgFUc7w
- 自己封装的php Curl并发处理,欢迎提出问题优化。
因为项目需要,发现一个一个发送请求实在太慢,无奈之下,我们可以封装一个并发处理的curl请求批处理句柄来减少重复创建句柄的问题 代码如下: /* *@param array $data url的参数 ...
随机推荐
- 记一次 .NET某酒店后台服务 卡死分析
一:背景 1. 讲故事 停了一个月没有更新文章了,主要是忙于写 C#内功修炼系列的PPT,现在基本上接近尾声,可以回头继续更新这段时间分析dump的一些事故报告,有朋友微信上找到我,说他们的系统出现了 ...
- Wpf UI框架 MaterialDesign 的使用记录
近期公司有桌面客户端的开发需求,并且对样式和界面反馈有一定的要求,对比各种开源UI框架后确认使用MaterialDesign . 1.引入框架MaterialDesignThemes,注意下对应的版本 ...
- 【Azure App Service】.NET代码实验App Service应用中获取TLS/SSL 证书 (App Service Windows)
在使用App Service服务部署业务应用,因为有些第三方的接口需要调用者携带TLS/SSL证书(X509 Certificate),在官方文档中介绍了两种方式在代码中使用证书: 1) 直接使用证书 ...
- 基于WebSocket的modbus通信(一)- 服务器
ModbusTcp协议是基于tcp的,但不是说一定要通过tcp协议才能传输,只要能传输二进制的地方都可以.比如WebSocket协议. 但由于目前我只有tcp上面的modbus服务器实现,所以我必须先 ...
- redhat8连接xshell命令卡顿
取消下方 转发x11连接到(X) 再重新连接一遍 就好了
- 鸿蒙HarmonyOS实战-ArkTS语言基础类库(并发)
一.并发 并发是指在一个时间段内,多个事件.任务或操作同时进行或者交替进行的方式.在计算机科学中,特指多个任务或程序同时执行的能力.并发可以提升系统的吞吐量.响应速度和资源利用率,并能更好地处理多用户 ...
- php分页查询 子查询
分页查询 将查询结果只显示一部分 通过两个参数:参数1 起始数据的索引下标 参 ...
- Vue 3与ESLint、Prettier:构建规范化的前端开发环境
title: Vue 3与ESLint.Prettier:构建规范化的前端开发环境 date: 2024/6/11 updated: 2024/6/11 publisher: cmdragon exc ...
- ftl生成模板并从前台下载
1.生成模板的工具类 package com.jesims.busfundcallnew.util; import freemarker.template.Configuration; import ...
- OAuth + Security - 7 - 异常翻译
认证异常翻译 默认情况下,当我们在获取令牌时输入错误的用户名或密码,系统返回如下格式响应: { "error": "invalid_grant", " ...