LLM实战:LLM微调加速神器-Unsloth + LLama3
1. 背景
五一结束后,本qiang~又投入了LLM的技术海洋中,本期将给大家带来LLM微调神器:Unsloth。
正如Unsloth官方的对外宣贯:Easily finetune & train LLMs; Get faster with unsloth。微调训练LLM,可以显著提升速度,其次显存占用也会显著减少。
但有一点需要说明:unsloth目前开源部分只支持单机版微调,更高效微调只能交费使用unsloth pro。
2. Unsloth简介
2.1 主要特性
(1) 所有的内核均以OpenAI的Triton语言实现,并且手动实现反向传播引擎。Triton语言是面向LLM训练加速。
(2) 准确率0损失,没有近似方法,方法完全一致。
(3) 硬件层面无需变动。支持18年之后的Nvidia GPU(V100, T4, Titan V, RTX20,30,40x, A100, H100, L40等,GTX1070,1080也支撑,但比较慢),Cuda最低兼容版本是7.0
(4) 通过WSL适用于Linux和Windows
(5) 基于bisandbytes包,支持4bit和16bit的 QLoRA/LoRA微调
(6) 开源代码有5倍的训练效率提升, Unsloth Pro可以提升至30倍
2.2 目前支撑的模型
由于底层算子需要使用triton重写,因此部分开源模型的适配工作周期可能较长。当前unsloth支持的模型包含Qwen 1.5(7B, 14B, 32B, 72B), Llama3-8B, Mistral-7B, Gemma-7B, ORPO, DPO Zephyr, Phi-3(3.8B), TinyLlama
2.3 模型加速效果
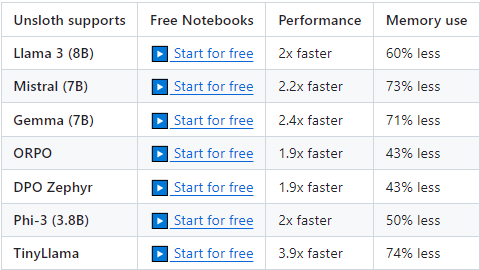
Qwen1.5-7B的集成是由Firefly作者封装并验证,性能提升30%+,显卡减少40%+,详见地址。
2.4 安装教程
conda create --name unsloth_env python=3.10 conda activate unsloth_env conda install pytorch-cuda=<12.1/11.8> pytorch cudatoolkit xformers -c pytorch -c nvidia -c xformers pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git" pip install --no-deps trl peft accelerate bitsandbytes
3. 实战
本着眼过千遍不如手过一遍的宗旨,本qiang~针对Unsloth做了一个对比实现。对比的实验环境分别为:P40, A40, A800,对比的模型使用的是出锅热乎的Llama3(8B)。
3.1 比对维度
|
维度 |
说明 |
|
显卡 |
是否支持bf16 |
|
最大文本长度 |
max_seq_length |
|
批次大小 |
per_device_train_batch_size |
|
梯度累加步长 |
gradient_accumulation_steps |
|
秩 |
LoRA的rank |
|
dropout |
lora_droput |
3.2 源码
针对使用unsloth和非unsloth得显卡及训练加速的对比代码,可以参考地址:https://zhuanlan.zhihu.com/p/697557062
4 实验结果
4.1 P40

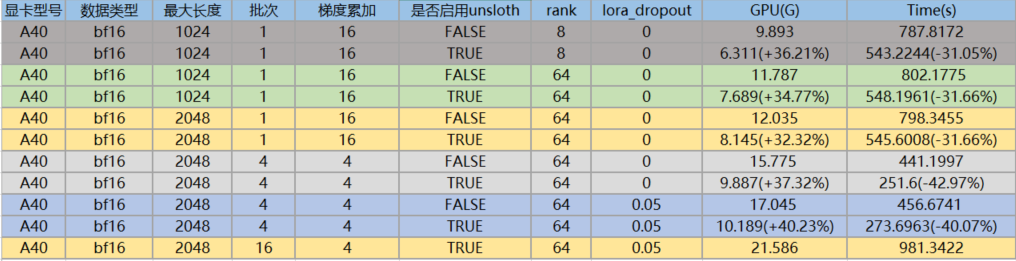
4.2 A40
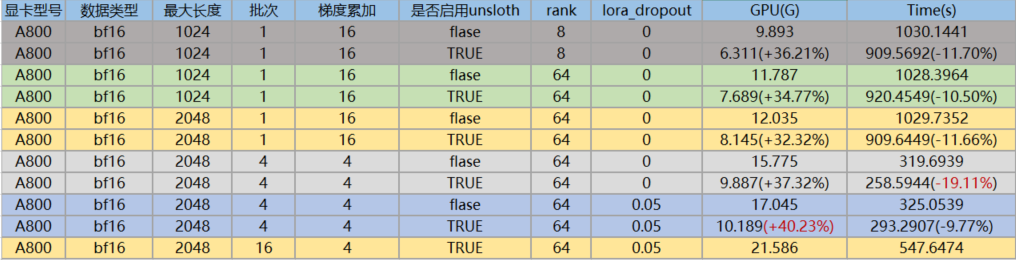
4.3 A800
4.4 结论
针对于llama3-8B进行unsloth训练,与基于transformers框架训练进行比对,结论如下:
(1) 集成unsloth后,显卡占用确实更少,训练效率确实更快,不管是哪种维度。
(2) P40增加batch_size后,显卡的内存占用提升,但训练的时间也更长,说明P40针对大批次的数据处理,性能会降低; 但A40, A800增加batch_size后,显卡内存占用虽然提升,但训练的时间更短。
(3) A800的batch_size为1时,训练效率不如A40,当batch_size增加到16时,A800的训练效率比A40快接近一倍。因此,A800更适合处理大批次的场景,对于小batch_size,杀鸡不能用牛刀。
5. 总结
一句话足矣~
本文主要是使用unsloth框架针对llama3的高效微调实验,提供了详细的对比代码以及不同维度的对比分析结果。
之后会写一篇关于Qwen1.5的对比实验,敬请期待~
6. 参考
1. unsloth: https://github.com/unslothai/unsloth
2. Qwen1.5+Unsloth: https://github.com/unslothai/unsloth/pull/428

LLM实战:LLM微调加速神器-Unsloth + LLama3的更多相关文章
- 内核融合:GPU深度学习的“加速神器”
编者按:在深度学习"红透"半边天的同时,当前很多深度学习框架却面临着共同的性能问题:被频繁调用的代数运算符严重影响模型的执行效率. 本文中,微软亚洲研究院研究员薛继龙将为大家介绍 ...
- (数据科学学习手札86)全平台支持的pandas运算加速神器
本文示例代码已上传至我的Github仓库https://github.com/CNFeffery/DataScienceStudyNotes 1 简介 随着其功能的不断优化与扩充,pandas已然成为 ...
- Python爬虫加速神器的小试
大名鼎鼎的aiohttp,相信如果你学习Python或者爬虫的时候,肯定听说过这个东西.没听过也不要紧,今天看完文章,只要记住,aiohttp这个东西,在写爬虫的时候,很牛逼就行了. aiohttp ...
- 巧用MySQL AHI加速神器,让你的InnoDB查询飞起来!
DBAPLUS http://mp.weixin.qq.com/s/cIjQIz-ZngSYJ3k2ZBBSsg
- 推荐一个github国内访问加速神器GitHub520
一.介绍 对 GitHub 说"爱"太难了:访问慢.图片加载不出来. 注: 本项目还处于测试阶段,仅在本机测试通过,如有问题欢迎提 issues 本项目无需安装任何程序,通过修改本 ...
- 在一张 24 GB 的消费级显卡上用 RLHF 微调 20B LLMs
我们很高兴正式发布 trl 与 peft 的集成,使任何人都可以更轻松地使用强化学习进行大型语言模型 (LLM) 微调!在这篇文章中,我们解释了为什么这是现有微调方法的有竞争力的替代方案. 请注意, ...
- TensorRT基础笔记
一,概述 TensorRT 是 NVIDIA 官方推出的基于 CUDA 和 cudnn 的高性能深度学习推理加速引擎,能够使深度学习模型在 GPU 上进行低延迟.高吞吐量的部署.采用 C++ 开发,并 ...
- JVM难学?那是因为你没认真看完这篇文章
一:虚拟机内存图解 JAVA程序运行与虚拟机之上,运行时需要内存空间.虚拟机执行JAVA程序的过程中会把它管理的内存划分为不同的数据区域方便管理. 虚拟机管理内存数据区域划分如下图: 数据区域分类: ...
- JVM 一套卷,助你快速掌握优化法则
一:虚拟机内存图解 JAVA 程序运行与虚拟机之上,运行时需要内存空间.虚拟机执行 JAVA 程序的过程中会把它管理的内存划分为不同的数据区域方便管理. 虚拟机管理内存数据区域划分如下图: 数据区域分 ...
- JVM难学?那是因为你没认真看完这篇文章(转)
一:虚拟机内存图解 JAVA程序运行与虚拟机之上,运行时需要内存空间.虚拟机执行JAVA程序的过程中会把它管理的内存划分为不同的数据区域方便管理. 虚拟机管理内存数据区域划分如下图: 数据区域分类: ...
随机推荐
- 20 JavaScript和HTML交互
20 JavaScript和HTML交互 在HTML中可以直接在标签上给出一些事件的触发. 例如, 页面上的一个按钮. <input type="button" value= ...
- 体验Semantic Kernel图片内容识别
前言 前几日在浏览devblogs.microsoft.com的时候,看到了一篇名为Image to Text with Semantic Kernel and HuggingFace的文章.这篇文章 ...
- CircleIndicator组件,使指示器风格更加多样化
UI界面是应用程序可视化必不可少的部分.设计精致的UI界面可以使得整个可视化应用程序给用户留下深刻的印象,是改善用户界面体验最直接的方式. ArkUI开发框架为开发者提供了丰富的UI原生组件,如Nav ...
- C# 面试问答
引用:https://www.cnblogs.com/zh7791/p/13705434.html 1.什么是 COM? COM 代表组件对象模型.COM 是微软技术之一.使用这项技术,我们可以开 ...
- 华为运动健康服务Health Kit 6.10.0版本新增功能速览!
华为运动健康服务(HUAWEI Health Kit)6.10.0 版本新增的能力有哪些? 阅读本文寻找答案,一起加入运动健康服务生态大家庭! 一. 支持三方应用查询用户测量的连续血糖数据 符合申请H ...
- 华为会员开放服务(Membership Kit),助力移动应用快速建设会员生态
会员开放服务(Membership Kit)是华为面向开发者提供的券码开放能力,开发者可以通过Membership Kit开展灵活多样的营销活动,助力开发者建设会员生态,实现用户运营与增量创收的目标. ...
- Linux:vscode扩展无法下载,报错:Error while fetching extensions : XHR failed
在Linux系统上下载安装好vscode以后,发现扩展里面无法下载安装,报错:Error while fetching extensions : XHR failed 解决办法:修改 hosts 文件 ...
- 本周三晚19:00Hello HarmonyOS应用篇第7课—分布式应用开发
6月15日19:00 Hello HarmonyOS系列应用篇迎来的本系列直播课的最后一课,将会有怎样的精彩呈现呢? 万物互联的时代已经来临,如果你想运用过往的技术,开发一个有"跨设备操 ...
- 7月27日19:30直播预告:HarmonyOS3及华为全场景新品发布会
7月27日 19:30 HarmonyOS 3 及华为全场景新品发布会 高能来袭! 在HarmonyOS开发者社区企微直播间 一起见证HarmonyOS的又一次智慧进化 扫码预约直播,与您不见不散!
- 树莓派和esp8266在局域网下使用UDP通信,esp8266采集adc数据传递给树莓派,树莓派在web上显示结果
树莓派和esp8266需要在同一局域网下 esp8266使用arduino开发: 接入一个电容土壤湿度传感器,采集湿度需要使用adc #include <ESP8266WiFi.h> #i ...