linux文本三剑客之awk详解
linux文本三剑客之awk详解
1.awk命令详解
awk是一个强大的文本处理工具,用于格式化输出文本,善于对列进行操作。而sed命令擅长对行进行操作。
和 sed 命令类似,awk 命令也是逐行扫描文件(从第 1 行到最后一行),寻找含有目标文本的行,如果匹配成功,则会在该行上执行用户想要的操作;反之,则不对行做任何处理。
awk命令的语法如下:
awk [options] ‘program’ var=value file …
awk [options] –f programfile var=value file …
awk [optonns] ‘BEGIN{action;…} pattern{action;…} END {action;…}’ file…
其中program由pattern{action;…}两部分组成。
pattern代表匹配规则,指定action可以作用到文本内容中的具体范围或action的执行条件,可以使用字符串或者正则表达式或者逻辑判断等条件。如果不指定匹配规则,则默认匹配文本中所有的行;
action则为执行的操作,多个操作之间使用分号";"连接,需要使用大括号{}括起来,如果没有指定执行命令,则默认打印本行;
BEGIN:表示在处理文本第一行前需要预先执行的操作,只执行一次,例如打印表头;
END:表示在处理完文本的最后一行后需要执行的动作,只执行一次,例如执行统计动作;
awk的常见选项如下:
选项 说明 -F fs 指定以 fs 作为输入一行中域的分隔符,awk 命令默认分隔符为空格或制表符。 -f file 从脚本文件中读取 awk 脚本指令,以取代直接在命令行中输入指令。 -v var=val 在执行处理过程之前,设置一个变量 var,并给其设备初始值为 val。 record:记录,在AWK中行称为记录,默认的记录分隔符为换行\n;
field:域,awl中列称为字段或域,默认的列分隔符为空格或tab,支持自动识别多个空格或tab为一个分隔符;
1.1 awk的处理流程
awk的处理流程图如下:
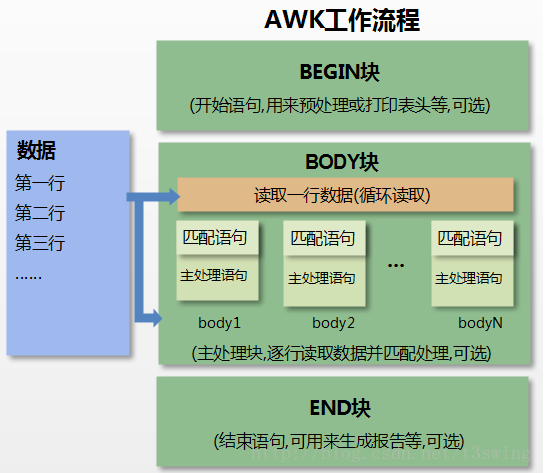
awk的处理流程为:
- 通过关键字 BEGIN 执行 BEGIN 块的内容,即 BEGIN 后花括号 {} 的内容。
- 完成 BEGIN 块的执行,开始执行body块。
- 依次读入有 \n 换行符分割的记录。
- 将记录按指定的域分隔符划分域,填充域,并未每个域使用变量表示,$0 则表示所有域(即本行内容),\(1 表示第一个域,\)n 表示第 n 个域。
- 依次执行各 BODY 块,pattern 部分匹配该行内容成功后,才会执行 awk-commands 的内容。
- 循环读取并执行各行直到文件结束,完成body块执行。
- 开始 END 块执行,END 块可以输出最终结果。
1.2 awk中的变量
awk中可以使用变量来存取值,分为内置变量和自定义变量。
1.2.1 内置变量
常用内置变量如下:
$0:代表整个文本行;
[root@xuzhichao ~]# awk -F: '/^\<root\>/{print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
$n:代表一行中的第 n 个数据字段;
#打印root行的用户名和UID
[root@xuzhichao ~]# awk -F: '/^\<root\>/{print $1,$3}' /etc/passwd
root 0
FS:输入字段分隔符,默认为空格或tab;
OFS:输出字段分隔符;
#指定输入和输出的分隔符都为分号:print 命令会自动将 OFS 变量的值放置在输出中的每个字段间。通过设置 OFS 变量,可以在输出中使用任意字符串来分隔字段。
[root@xuzhichao ~]# awk -v FS=: -v OFS=: '/^\<root\>/{print $1,$3}' /etc/passwd
root:0
RS:指定输入记录换行符,默认是回车
ORS :输出的换行符,默认是回车
#对于如下文件,前三行代表一个人的信息,后三行代表另一个人的信息,需要把每个人的信息作文一个整体进行处理,使用默认的RS无法实现,此时需要把RS设置为空行“”,然后把NS设置为回车\n,则能把每个人的信息作为一个整体,姓名,电话,地址分别作为一个字段处理。
[root@xuzhichao ~]# cat f1
xiaoming
17345332343
zhengzhou xiaohong
13459872309
beijing
[root@xuzhichao ~]# awk -v FS="\n" -v RS="" '{print $1,$3}' f1
xiaoming zhengzhou
xiaohong beijing #把RS设置为;把ORS设置为=
[root@xuzhichao ~]# awk -v RS=";" -v ORS="=" '{print $1}'
1;2;3;4;
1=2=3=4=
NF:一行的字段的数量
#显示/etc/passwd文件每行有多少个字段
[root@xuzhichao ~]# head -n 3 /etc/passwd |awk -F: '{print NF}'
7
7
7 #显示/etc/passwd文件的最后一列
[root@xuzhichao ~]# head -n 3 /etc/passwd |awk -F: '{print $NF}'
/bin/bash
/sbin/nologin
/sbin/nologin #显示/etc/passwd文件的倒数第二列
[root@xuzhichao ~]# head -n 3 /etc/passwd |awk -F: '{print $(NF-1)}'
/root
/bin
/sbin
NR:文件的行号,记录号
#显示行号和USER
[root@xuzhichao ~]# head -n 3 /etc/passwd |awk -F: '{print NR,$1}'
1 root
2 bin
3 daemon
FNR:与NR一样,都是文件的行号,区别在于当处理多个文件时,NR会对这些文件统一编行号,FNR则会针对每个文件单独编行号
[root@xuzhichao ~]# head -n 3 /etc/passwd > f1
[root@xuzhichao ~]# tail -n 3 /etc/passwd > f2
[root@xuzhichao ~]# cat f1
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
[root@xuzhichao ~]# cat f2
apache:x:48:48:Apache:/usr/share/httpd:/sbin/nologin
admroot:x:1001:1001::/home/admroot:/bin/bash
rooter:x:1002:1002::/home/rooter:/bin/bash
#NR对f1和f2两个文件统一编写行号
[root@xuzhichao ~]# awk -F: '{print NR,$1}' f1 f2
1 root
2 bin
3 daemon
4 apache
5 admroot
6 rooter
#FNR会对f1和f2两个文件单独编写行号
[root@xuzhichao ~]# awk -F: '{print FNR,$1}' f1 f2
1 root
2 bin
3 daemon
1 apache
2 admroot
3 rooter
FILENAME:处理的文件名
[root@xuzhichao ~]# awk -F: '{print FNR,FILENAME,$1}' f1 f2
1 f1 root
2 f1 bin
3 f1 daemon
1 f2 apache
2 f2 admroot
3 f2 rooter
ARGC:awk命令中命令行参数个数
ARGV:表示一个数组,存放的是awk命令中命令行所有的参数,ARGV[0]代表第一个参数,ARGV[1]代表第二个参数
#以下示例中表示以下awk命令中共有三个参数,第一个参数时awk命令自身,第二个参数时f1,第三个参数是f2
[root@xuzhichao ~]# awk -F: 'BEGIN{print ARGC,ARGV[0],ARGV[1],ARGV[2]}' f1 f2
3 awk f1 f2
1.2.2 自定义变量
awk中还可以自定义变量,可以定义的地方为:
- 使用-v参数在awk选项中定义变量;
- 在action中直接定义变量,例如var="name";
调用变量时直接调用变量名字即可,不需要像bash中使用$符号。
#使用两种种方法定义变量
[root@xuzhichao ~]# head -n 3 /etc/passwd | awk -v FS=: -v var="name" '{print var,$1}'
name root
name bin
name daemon
[root@xuzhichao ~]# head -n 3 /etc/passwd | awk -F: '{var="name";print var,$1}'
name root
name bin
name daemon
1.3 awk脚本
awk 允许将脚本命令存储到文件中,然后再在命令行中引用。
请看如下示例:
#示例一:
[root@xuzhichao ~]# cat awk.txt
/^\<root\>/{print $1,$3}
[root@xuzhichao ~]# awk -F: -f awk.txt /etc/passwd
root 0
#示例二:
[root@xuzhichao ~]# cat awk.txt
#!/bin/awk -f
/^\<root\>/{print $1,$3}
[root@xuzhichao ~]# chmod +x awk.txt
[root@xuzhichao ~]# ./awk.txt -F: /etc/passwd
root 0
在awk程序文件中,可以指定多条命令,一条命令放一行即可,之间不需要用分号。
[root@xuzhichao ~]# cat awk.txt
#!/bin/awk -f
BEGIN{print "user uid"}
/^\<root\>/{print $1,$3}
[root@xuzhichao ~]# ./awk.txt -F: /etc/passwd
user uid
root 0
awk脚本中可以直接引用一个变量名称,然后在awk命令中进行赋值,即时改变变量的值,例如:
[root@xuzhichao ~]# cat awk.txt
{if($3 >= min && $3 <=max)print $1,$3}
#在awk命令中对变量赋值
[root@xuzhichao ~]# awk -F: -f awk.txt min=0 max=3 /etc/passwd
root 0
bin 1
daemon 2
adm 3
注意:为脚本的变量赋值时,上面这种赋值的方法对BEGIN代码块中的变量无法赋值,如果需要对BEGIN代码块中的变量赋值。需要使用-v参数,看下面的示例:
[root@xuzhichao ~]# cat awk.txt
BEGIN{print var,str}
{if($3 >= min && $3 <=max)print $1,$3}
#无法输出BEGIN中的变量值
[root@xuzhichao ~]# awk -F: -f awk.txt min=0 max=3 var=user str=uid /etc/passwd
root 0
bin 1
daemon 2
adm 3
#使用-v参数对变量赋值时可以对BEGIN中的变量成功赋值
[root@xuzhichao ~]# awk -F: -f awk.txt -v min=0 -v max=3 -v var=user -v str=uid /etc/passwd
user uid
root 0
bin 1
daemon 2
adm 3
1.4 printf命令:格式化输出
printf命令用于格式化输出文本,使用格式如下:
printf "FORMAT" ,item1,iterm2,iterm3,...
注意:
1."FORMAT"为必须项,需要分别为后面的iterm指定格式符;
2.iterm为变量名称;
3.不会自动换行,需要使用\n进行换行;
4."FORMAT"中普通字符串直接给出即可,无需使用引号;
“FORMAT”中的定义iterm的格式符如下:
格式符 意义 %d或%i 显示十进制整数 %s 显示字符串 %f 显示浮点数 %u 无符号整数 %% 显示%自身 以上格式符需要结合修饰符使用,常用修饰符如下:
修饰符 意义 #[.#] 第一个#表示整个浮点数的宽度,第二个#表示小数点后的精度,例如%3.1f # 在整数类型或字符串类型中表示整数或字符串的宽度,例如%5s - 左对齐,默认为右对齐,例如%-5d + 表示数值的正负号,例如%+d
printf的使用示例如下:
[root@xuzhichao ~]# head -n 3 /etc/passwd | awk -F: 'BEGIN{var="username";str="uid";printf "%10s | %5s\n",var,str} {printf "%10s | %5d\n",$1,$3}'
username | uid
root | 0
bin | 1
daemon | 2
[root@xuzhichao ~]# head -n 3 /etc/passwd | awk -F: 'BEGIN{var="username";str="uid";printf "%-10s | %-5s\n",var,str} {printf "%-10s | %-5d\n",$1,$3}'
username | uid
root | 0
bin | 1
daemon | 2
1.5 awk的pattern部分说明
awk命令中的pattern部分用于定义匹配规则,支持的pattern形式有如下几种:
/regular expression/:支持扩展正则表达式,仅处理被模式匹配的行。
#示例一:取出以UUID开头的行的第一个字段
[root@xuzhichao ~]# awk '/^UUID/{print $1}' /etc/fstab
UUID=d643dd72-da0b-4f07-bae0-7f98b7e69f59 #示例二:取反操作,即取出不以UUID开头的行的第一个字段
[root@xuzhichao ~]# awk '!/^UUID/{print $1}' /etc/fstab #示例三:去除/etc/httpd/conf/httpd.conf中所有注释行,默认action为打印本行
[root@xuzhichao ~]# awk '!/^[[:space:]]*#/' /etc/httpd/conf/httpd.conf
关系表达式:结果为真则处理后面的action,结果为假则不处理action。
- 结果为真:表示结果为非0值,或非空字符串;
- 结果为假:表示结果为0或为空字符串;
#示例一:!0为真,执行action;!1为假,不执行action
[root@xuzhichao ~]# head -n 1 /etc/passwd | awk -F: '!0{print $1,$3}'
root 0
[root@xuzhichao ~]# head -n 1 /etc/passwd | awk -F: '!1{print $1,$3}' #示例二:打印奇数行和偶数行
#默认i为0,执行i=!i后i为1,打印第一行,然后执行i=!i后i为0,不执行第二行,依次类推。
[root@xuzhichao ~]# seq 6 |awk 'i=!i'
1
3
5
[root@xuzhichao ~]# seq 6 |awk -v i=1 'i=!i'
2
4
6
[root@xuzhichao ~]# seq 6 |awk '!(i=!i)'
2
4
6 #示例三:打印/etc/passwd文件中shell类型为/bin/bash的用户名和shell类型
[root@xuzhichao ~]# awk -F: '$NF=="/bin/bash"{print $1,$NF}' /etc/passwd
root /bin/bash
xu /bin/bash
匹配行范围:/pattern1/,/pattern2/,表示从pattern1匹配的将到pattern2匹配的行之间的范围,不支持像sed那样直接给出行号。
#示例一:打印/etc/passwd文件从root用户到xu用户之间的行的用户名和UID
[root@xuzhichao ~]# awk -F: '/^\<root\>/,/^\<xu\>/{print $1,$3}' /etc/passwd #示例二:打印/etc/passwd文件5行到8行之间的行和行号
[root@xuzhichao ~]# awk -F: '(NR>=5 && NR<=8){print NR,$0}' /etc/passwd
5 lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
6 sync:x:5:0:sync:/sbin:/bin/sync
7 shutdown:x:6:0:shutdown:/sbin:/sbin/shutdown
8 halt:x:7:0:halt:/sbin:/sbin/halt #示例三:打印/etc/passwd文件第1行的行和行号
[root@xuzhichao ~]# awk -F: 'NR==1{print NR,$0}' /etc/passwd
1 root:x:0:0:root:/root:/bin/bash
未指定pattern,则匹配每一行内容。
1.6 awk的操作符
awk中支持各种类型的操作符,下面一一说明。
算术操作符
操作符 说明 + 加法 - 减法 * 乘法 / 除法 % 取模,即取余数 ^ 指数运算 #示例:
[root@xuzhichao ~]# awk 'BEGIN{i=1+10;print i}'
11
[root@xuzhichao ~]# awk 'BEGIN{i=2^10;print i}'
1024
[root@xuzhichao ~]# awk 'BEGIN{i=10/3;print i}'
3.33333
[root@xuzhichao ~]# awk 'BEGIN{i=10%3;print i}'
1
赋值操作符
操作符 说明 = 等于 += i+=1表示i=i+1 -= i-=1表示i=i-1 *= i*=1表示i=i*1 /= i/=1表示i=i/1 ++ i++,表示i=i+1 -- i--,表示i=i-1 #示例一:
[root@xuzhichao ~]# awk 'BEGIN{i=1;i+=2;print i}'
3 #示例二:i++和++i的区别:
#i++表示先把i输出,让后再执行i+1操作;++i表示先执行i+1,然后再输出i;
[root@xuzhichao ~]# awk 'BEGIN{i=1;print i++,i}'
1 2
[root@xuzhichao ~]# awk 'BEGIN{i=1;print ++i,i}'
2 2
比较操作符
操作符 说明 == 等于 > 大于 < 小于 >= 大于等于 <= 小于等于 != 不等于 #示例一:删除uid在2000和3000之间的用户
[root@xuzhichao ~]# awk -F ':' '$3>2000 && $3<3000{print $1}' /etc/passwd | xargs userdel -r
[root@xuzhichao ~]# awk -F ':' '$3>2000 && $3<3000{print $1}' /etc/passwd | sed -r 's/(.*)/userdel -r \1/' | bash #示例二:输出系统中所有的普通用户
[root@xuzhichao ~]# awk -F ':' '$3!=0{print $1}' /etc/passwd #示例三:显示uid为0的行
[root@xuzhichao ~]# awk -F ':' '$3==0 {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
模式匹配符
匹配符 说明 ~ 左边内容包含右边内容,右边内容支持正则表达式,使用//即可 !~ 左边内容不包含右边内容 #示例一:打印文件中含有root的用户
[root@xuzhichao ~]# awk -F ':' '$0 ~ "root" {print $0}' /etc/passwd
root:x:0:0:root:/root:/bin/bash
operator:x:11:0:operator:/root:/sbin/nologin
admroot:x:1001:1001::/home/admroot:/bin/bash
rooter:x:1002:1002::/home/rooter:/bin/bas #示例二:
[root@xuzhichao ~]# awk -F ':' '$1 ~ /\<root\>/ {print $0}' /etc/passwd
[root@xuzhichao ~]# awk -F ':' '$1 !~ /\<root\>/ {print $0}' /etc/passwd #示例三:显示磁盘利用率
[root@xuzhichao ~]# df | awk -F% '$0~/^\/dev\//{print $1}' | awk '{print $1,$NF}'
/dev/mapper/centos-root 10
/dev/sda1 34
逻辑操作符
操作符 说明 && 逻辑“与”,表示前后两个表达式都为真,则结果为真。 || 逻辑“或”,表示前后两个表达式有任意一个为真,则结果为真。 ! 逻辑“非”,取反操作 #示例一:去除/etc/httpd/conf/httpd.conf中所有注释行和空行
[root@xuzhichao ~]# awk '$0 !~ /^[[:space:]]*#/ && $0 !~ /^$/' /etc/httpd/conf/httpd.conf #示例二:
[root@xuzhichao ~]# awk -F: '$3==0 || $3>1000' /etc/passwd
[root@xuzhichao ~]# awk -F: '!($3==0)' /etc/passwd
条件表达式(三目表达式)
selector?if-true-expression:if-false-expression
上述表达式中selector是一个判断语句,如果该判断语句结果为真,则执行if-true-expression,为假则执行if-false-expression
#判断系统中的用户是系统用户还是普通用户
[root@xuzhichao ~]# awk -F: '{$3>1000?usertype="common user":usertype="system user";printf "%-20s | %-20s\n",$1,usertype}' /etc/passwd
root | system user
bin | system user
...(省略部分内容)...
apache | system user
admroot | common user
rooter | common user
1.7 awk的控制语句
awk脚本中支持复杂的控制语句,如同编程语言一样,支持判断,循环等语法。
1.7.1 if-else判断语句
语法格式为:
if(condition){statement1}else{statement2}
if(condition1){statement1}else if(condition2){statement2}else{statement3}
说明:如果符合condition1的条件,则执行statement1,若符合condition2的条件,则执行statement2的动作,否则执行statement3动作。
if-else判断语句使用示例如下:
#示例一:打印UID大于100的用户和UID
[root@xuzhichao ~]# awk '{if($3>=100)print $1,$3}' /etc/passwd
#示例二:
[root@xuzhichao ~]# awk 'BEGIN{test=100;if(test>=90){print "very good"}else if(test<90 && test>=60){print "good"}else{print "bad"}}'
very good
1.7.2 while循环语句
while循环语句的语法为:
while (condition){statement}
说明:符合条件condition则进入循环体statement中
#示例:统计/etc/grub2.cfg文件linux16这一行所有大于10个字符的单词和其字符数
[root@xuzhichao ~]# awk '/^[[:space:]]+linux16/{i=1;while(i<=NF){if(length($i)>10){print $i,length($i)};i++}}' /etc/grub2.cfg
/vmlinuz-3.10.0-1127.el7.x86_64 31
root=/dev/mapper/centos-root 28
crashkernel=auto 16
spectre_v2=retpoline 20
rd.lvm.lv=centos/root 21
rd.lvm.lv=centos/swap 21
net.ifnames=0 13
/vmlinuz-0-rescue-d9abb103c9b943b0bfbbb212ed3dee7f 50
root=/dev/mapper/centos-root 28
crashkernel=auto 16
spectre_v2=retpoline 20
rd.lvm.lv=centos/root 21
rd.lvm.lv=centos/swap 21
net.ifnames=0 13
1.7.3 do while循环语句
do while循环语句的语法为:
do {statement}while(condition)
说明:无论条件真假,先执行一次statement,如果符合条件condition则进入循环体statement中
#示例一:从1加到100的所有数字之和
[root@xuzhichao ~]# awk 'BEGIN{i=1;do{total+=i;i++}while(i<=100);print total}'
5050
1.7.4 for循环语句
for循环语句的语法为:
for(变量;条件;计数器) {运行代码;}
说明:变量用于定义变量初始值;
条件为设定进入循环的条件;
计数器用于对变量的值改变;
运行代码为循环体
#示例一:计算从1加到100的数字之和。
[root@xuzhichao ~]# awk 'BEGIN{for(i=1;i<=100;i++){total+=i};print total}'
5050
#示例二:使用time命令查看命令执行的时间
[root@xuzhichao ~]# time (for((i=1;i<=100000;i++));do let total+=i;done;echo $total )
5000050000
real 0m0.681s
user 0m0.630s
sys 0m0.052s
[root@xuzhichao ~]# time (awk 'BEGIN{for(i=1;i<=100000;i++){total+=i};print total}')
5000050000
real 0m0.013s
user 0m0.009s
sys 0m0.004s
[root@xuzhichao ~]# time (seq -s "+" 100000 |bc )
5000050000
real 0m0.045s
user 0m0.032s
sys 0m0.015s
#使用以上三种方式的结论为awk的执行效率要高于shell脚本方式
1.7.5 break和continue的用法
break:退出正在执行的循环体。
Continue:仅退出正在执行的循环体的本次循环,继续执行下一次循环。
break [n] :退出正在执行的n层循环体。
continue [n] : 退出n层循环。
#示例一:计算1到100之间的所有奇数的总和
[root@xuzhichao ~]# awk 'BEGIN{for(i=1;i<=100;i++){if(i%2==0)continue;total+=i};print total}'
2500 #示例二:计算1到100之间的所有奇数的总和
[root@xuzhichao ~]# awk 'BEGIN{for(i=1;i<=100;i++){if(i%2==1)continue;total+=i};print total}'
2550 #示例三:如果使用break,则会直接退出循环体
[root@xuzhichao ~]# awk 'BEGIN{for(i=1;i<=100;i++){if(i%2==0)break;total+=i};print total}'
1
1.7.6 next的用法
next的作用是提前结束对本行的处理而直接进入下一行,即退出awk自身的循环。
#示例一:只输出UID为奇数的用户和UID
[root@xuzhichao ~]# awk -F: '{if($3%2==0)next;print $1,$3}' /etc/passwd
bin 1
adm 3
sync 5
halt 7
operator 11
nobody 99
dbus 81
1.8 awk的数组
awk中可以使用数组完成一些高级功能,例如计数。
数组的格式
array[index-expression],例如weekday["mon"]="monday"
array为数组名字,index-expression为数组索引,可以使用任意字符串,字符串需要使用双引号括起来,变量的值若为字符串,也需要使用双引号括起来;
数组中的元素若事先不存在,在引用时会对其赋予一个空字符串;
数组的使用示例:
#示例一:事先定义的变量可以显示出对用的值,但是事先没有定义的变量则显示为空值。
#注意:若array["name"]="abc"中的abc没有使用双引号括起来,array["name"]可以回无法显示出内容。
[root@xuzhichao ~]# awk 'BEGIN{array["name"]="abc";array["sex"]="man";print array["name"],array["sex"],array["address"]}'
abc man #示例二:去除重复行
#实现原理为arr[$0]每次读取一行,若该行为第一次读取,则arr[$0]值为0,取反为1,打印改行,然后执行arr[$0]++后行arr[$0]的值变为1,若该行第二次出现,则因为arr[$0]已经为1,取反则为0,不打印该行,这样就只有一行第一次出现才输出,即可实现去重的效果。
[root@xuzhichao ~]# cat f1
aaa
bbb
ccc
aaa
aaa
bbb
[root@xuzhichao ~]# awk '!arr[$0]++' f1
aaa
bbb
ccc
#arr[$0]中的$0为每一行的值,数组的值为该行出现的次数,++操作可以实现对每一个出现的次数进行计数
[root@xuzhichao ~]# awk '{!arr[$0]++;print $0,arr[$0]}' f1
aaa 1
bbb 1
ccc 1
aaa 2
aaa 3
bbb 2
数组的遍历用法
遍历数组中的内容时需要使用for循环,使用格式为:
for (var in array){for-body} 说明:var为自定义的变量,array为要遍历的数组名;
var会遍历数组中的所有元素,这样var即为数组索引,array[var]即是数组的值
数组的遍历应用比较广泛,经常用于实现对数据的统计,使用示例如下:
#示例一:统计当前时段TCP各个状态的数量
[root@xuzhichao ~]# netstat -ant
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:52756 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN
tcp 0 52 192.168.20.17:22 192.168.20.1:54257 ESTABLISHED
tcp6 0 0 :::111 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:631 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
tcp6 0 0 ::1:6010 :::* LISTEN
tcp6 0 0 :::54524 :::* LISTEN
[root@xuzhichao ~]# netstat -ant | awk '/^tcp/{state[$6]++}END{for(i in state){print i,state[i]}}'
LISTEN 12
ESTABLISHED 1 #示例二:统计/var/log/httpd/access_log文件中对访问网站的IP地址进行排序
[root@xuzhichao ~]# cat /var/log/httpd/access_log
192.168.20.1 - - [23/May/2021:21:55:02 +0800] "GET /favicon.ico HTTP/1.1" 404 209 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
192.168.20.1 - - [23/May/2021:21:55:02 +0800] "GET / HTTP/1.1" 200 5 "-" "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36 SE 2.X MetaSr 1.0"
192.168.20.17 - - [23/May/2021:21:55:17 +0800] "GET / HTTP/1.1" 200 5 "-" "curl/7.29.0"
192.168.20.17 - - [23/May/2021:21:55:41 +0800] "GET / HTTP/1.1" 200 5 "-" "curl/7.29.0"
192.168.20.17 - - [23/May/2021:21:55:41 +0800] "GET / HTTP/1.1" 200 5 "-" "curl/7.29.0"
...(省略部分内容)...
[root@xuzhichao ~]# awk '{ip[$1]++}END{for(i in ip){print i,ip[i]}}' /var/log/httpd/access_log
192.168.20.1 9
192.168.20.17 10 #示例三:对访问网站次数超过10次的ip地址进行限制,加入防火墙中禁止其访问本站,system为函数,用于执行shell中的命令。
[root@xuzhichao ~]# awk '{ip[$1]++}END{for(i in ip){if(ip[i]>=10){system("iptables -A INPUT -s " i " -j REJECT")}}}' /var/log/httpd/access_log
[root@xuzhichao ~]# iptables -vnL
Chain INPUT (policy ACCEPT 42 packets, 2772 bytes)
pkts bytes target prot opt in out source destination
0 0 REJECT all -- * * 192.168.20.17 0.0.0.0/0 reject-with icmp-port-unreachable Chain FORWARD (policy ACCEPT 0 packets, 0 bytes)
pkts bytes target prot opt in out source destination Chain OUTPUT (policy ACCEPT 22 packets, 2184 bytes)
pkts bytes target prot opt in out source destination #示例四:统计一篇文章中每个单词出现的次数,单词都是以空格作为分隔符的字母或数字。
[root@xuzhichao ~]# awk '{for(i=1;i<=NF;i++){word[$i]++}}END{for(j in word){if(j ~ /\<[[:alnum:]]+\>/){print j,word[j]}}}' /etc/fstab #示例五:分别统计男生和女生的平均成绩
[root@xuzhichao ~]# cat f1
name score age
a 100 w
b 90 m
c 89 w
d 80 w
c 78 m
e 70 m
[root@xuzhichao ~]# awk 'BEGIN{printf "sex avescore\n"} !/^name/{sum[$3]+=$2;num[$3]++} END{for(i in sum){printf "%-3s %-4.2f\n",i,sum[i]/num[i]}}' f1
sex avescore
w 89.67
m 79.33
1.9 awk的函数
awk支持函数,分为内置函数和自定义函数。
1.9.1 awk内置函数
awk常用的内置函数如下:
length([s]):返回字符串 s 的长度;如果没有指定的话,返回 $0 的长度。
[root@xuzhichao ~]# awk -v var="abcdefg" 'BEGIN{print length(var)}'
7
rand():返回0和1之间的一个随机数
int():返回一个整数
#示例:取0-100之间的整数,取5次。int()函数用于取整。
[root@xuzhichao ~]# awk 'BEGIN{srand();for(i=1;i<=5;i++){print int(rand()*100)}}'
11
98
67
75
67
sub(r,s,[t]):在变量 $0 或目标字符串 t 中查找正则表达式 r 的匹配。如果找到了,就用字符串 s 替换掉第一处匹配。
gsub(r,s,[t]):查找变量 $0 或目标字符串 t(如果提供了的话)来匹配正则表达式 r。如果找到了,就全部替换成字符串 s。
#示例一:转化MAC地址显示格式
[root@xuzhichao ~]# echo "00.01.7a.8b.4f.6e" | awk 'sub(/\./,"-",$1)'
00-01.7a.8b.4f.6e
[root@xuzhichao ~]# echo "00.01.7a.8b.4f.6e" | awk 'gsub(/\./,"-",$1)'
00-01-7a-8b-4f-6e
[root@xuzhichao ~]# echo "00.01.7a.8b.4f.6e" | awk 'gsub(/\./,"-")'
00-01-7a-8b-4f-6e #示例二:对字符串asdasfd131234afsr*^^只保留数字
[root@xuzhichao ~]# echo "asdasfd131234afsr*^^" | awk '{gsub(/[^0-9]/,"",$0);print $0}'
131234
[root@xuzhichao ~]# echo "asdasfd131234afsr*^^" | awk 'gsub(/[^0-9]/,"",$0)'
131234
substr(s, i [,n]):返回 s 中从索引值 i 开始的 n 个字符组成的子字符串。如果未提供 n,则返回 s 剩下的部分。
#示例:
awk -F ',' '{print substr($3,6)}' <== 表示是从第3个字段里的第6个字符开始,一直到设定的分隔符","结束.
substr($3,10,8) <== 表示是从第3个字段里的第10个字符开始,截取8个字符结束.
[root@xuzhichao ~]# echo "123" | awk '{print substr($0,1,1)}'
1
split(s, a [,r]):将 s 用 FS 字符或正则表达式 r(如果指定了的话)分开放到数组 a 中,并返回字段的总数。
#示例一:统计netstat命令中远端主机ip地址及次数
[root@xuzhichao ~]# netstat -ant
Active Internet connections (servers and established)
Proto Recv-Q Send-Q Local Address Foreign Address State
tcp 0 0 0.0.0.0:111 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:52756 0.0.0.0:* LISTEN
tcp 0 0 0.0.0.0:22 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6010 0.0.0.0:* LISTEN
tcp 0 0 127.0.0.1:6011 0.0.0.0:* LISTEN
tcp 0 52 192.168.20.17:22 192.168.20.1:65084 ESTABLISHED
tcp 0 0 192.168.20.17:22 192.168.20.1:54257 ESTABLISHED
tcp6 0 0 :::111 :::* LISTEN
tcp6 0 0 :::80 :::* LISTEN
tcp6 0 0 :::22 :::* LISTEN
tcp6 0 0 ::1:631 :::* LISTEN
tcp6 0 0 ::1:25 :::* LISTEN
tcp6 0 0 ::1:6010 :::* LISTEN
tcp6 0 0 ::1:6011 :::* LISTEN
tcp6 0 0 :::54524 :::* LISTEN
[root@xuzhichao ~]# netstat -ant | awk '/^tcp\>/{split($5,ip,":");count[ip[1]]++}END{for(i in count)print i,count[i]}'
192.168.20.1 2
0.0.0.0 7
system():用于在awk脚本中执行shell中的命令
shell的命令内容使用双引号括起来,如果要使用awk的变量,变量不使用引号。
使用示例如下:
#示例一:
[root@xuzhichao ~]# awk 'BEGIN{system("who")}'
root pts/0 May 22 11:04 (192.168.20.1)
root pts/1 May 23 21:53 (192.168.20.1) #示例二:注意is后面的空格符不可省略。
[root@xuzhichao ~]# awk 'BEGIN{value=100;system("echo your score is " value)}'
your score is 100
1.9.2 awk自定义函数
除了awk 中的内建函数,还可以在 awk 脚本程序中自定义函数,创建自定义函数的基本格式为:
function 函数名(参数1,参数2,…){
运行代码;
return expression;
}
return用于定义函数的返回值
注意:在定义函数时,函数必须出现在所有代码块之前,包括 BEGIN 和 END代码块。
函数的使用示例如下:
#示例:其中var1,var2为形参,v1,v2为实参。
[root@xuzhichao ~]# cat awk.txt
function max(var1,var2){
var1>var2?var=var1:var=var2
return var
}
BEGIN{max(v1,v2);print var}
[root@xuzhichao ~]# awk -v v1=100 -v v2=200 -f awk.txt
200
linux文本三剑客之awk详解的更多相关文章
- Linux文本编译工具VIM详解
Linux文本编译工具VIM详解 作者:尹正杰 版权声明:原创作品,谢绝转载!否则将追究法律责任. 一.VIM概述 1>.vim简介 >.vi: 全称Visual editor,即文本编辑 ...
- Linux 文本对比 diff 命令详解(整理)
diff 命令详解 1.概述 windows系统下面就有不错的文本对比工具可以使用,例如常用的Beyond Compare,WinMerge都是图形界面的比较工具而且使用非常方便,如果你仅仅是在win ...
- Linux 文本三剑客之 awk
Linux 系统中一切皆文件. 文件是个文本.可以读.可以写,如果是二进制文件,还能执行. 在使用Linux的时候,大都是要和各式各样文件打交道.熟悉文本的读取.编辑.筛选就是linux系统管理员的必 ...
- linux脚本Shell之awk详解
一.基本介绍1.awk: awk是一个强大的文本分析工具,在对文本文件的处理以及生成报表,awk是无可替代的.awk认为文本文件都是结构化的,它将每一个输入行定义为一个记录,行中的每个字符串定义为一个 ...
- linux脚本Shell之awk详解(二)
三.printf的使用 print format 生成报表 %d 十进制有符号整数 %u 十进制无符号整数 %f 浮点数 %s 字符串 %c ...
- 【linux】linux命令grep + awk 详解
linux命令grep + awk 详解 grep:https://www.cnblogs.com/flyor/p/6411140.html awk:https://www.cnblogs.com ...
- linux PHP 编译安装参数详解
linux PHP 编译安装参数详解 ./configure --prefix=/usr/local/php --with-config-file-path=/usr/local/php/etc -- ...
- Linux CAT与ECHO命令详解 <<EOF EOF
Linux CAT与ECHO命令详解 cat命令是Linux下的一个文本输出命令,通常是用于观看某个文件的内容的: cat主要有三大功能: .一次显示整个文件. $ cat filename .从键盘 ...
- [r]Ubuntu Linux系统下apt-get命令详解
Ubuntu Linux系统下apt-get命令详解(via|via) 常用的APT命令参数: apt-cache search package 搜索包 apt-cache show package ...
- Linux下tomcat的安装详解
Linux下tomcat的安装详解 来源: ChinaUnix博客 日期: 2007.01.21 22:59 (共有0条评论) 我要评论 一,安装前的准备:1,Linux版本:我的是企业版.(至于红帽 ...
随机推荐
- SPEL表达式注入分析
环境依赖 <dependencies> <dependency> <groupId>org.springframework</groupId> < ...
- layui框架使用单页面弹出层组件layer
layui实现单页面弹出层 首先需要导入layui的js和css: <link rel="stylesheet" href="layui/css/layui.css ...
- Scala 特质(Trait)
1 package chapter06 2 3 object Test13_Trait { 4 def main(args: Array[String]): Unit = { 5 val studen ...
- 【已解决】(MySQL)SQL注入绕过登陆验证直接登陆---用户名输入框注释sql密码语句段
今天学习了一种sql注入方法,通过注释密码验证部分的sql语句. 这是登陆界面 在用户名如果输入 15284206891' and 1=1 # 密码可以随意输入即可登陆成功 原理如下: 在sql可视化 ...
- 使用OHOS SDK构建zstd
参照OHOS IDE和SDK的安装方法配置好开发环境. 从github下载源码. 执行如下命令: git clone https://github.com/facebook/zstd.git 进入源码 ...
- 80+产品正通过兼容性测试,OpenHarmony生态蓬勃发展
4 月 25 日,开放原子开源基金会举办了 OpenAtom OpenHarmony(以下简称"OpenHarmony")技术日活动,OpenHarmony PMC 委员代表首次对 ...
- C#对接部标JT808协议实现北斗定位设备数据接收服务端
一.前言介绍 开发一套能够支撑几万台北斗定位设备数据接收的服务端,用于接收北斗定位器定位数据的平台.项目基于windows平台,C#语言开发框架Net Framework4.8,TCP主要基于Supe ...
- Docker 12 Dockerfile
简介 Dockerfile 是用来构建 Docker 镜像的文件,可以理解为命令参数脚本. Dockerfile 是面向开发的,想要打包项目,就要编写 Dockerfile 文件. 由于 Docker ...
- Discovery直播 | 移动应用“通行证”——钥匙环,解锁管家式安全出行服务
用户在登录环节的直接诉求是:别让我等.别让我想.别让我烦.而帐号输入.繁琐验证,以及由此带来的安全风险,总会让很多人望而却步. 如何在简化登录流程的同时保障登录凭证安全?如何帮助用户一键免密登录同一开 ...
- web 报表工具如何自适应
现在的报表用户已经不再将报表作为一个单纯的报表工具看待了,有时候也会当作页面工具来使用,这时为了页面显示工整美观,就需要报表能够自适应宽度.下面我们就基于润乾报表来讲一下是如何做到自适应展现报表. 产 ...