智能工作流:Spring AI高效批量化提示访问方案
基于SpringAI搭建系统,依靠线程池\负载均衡等技术进行请求优化,用于解决科研&开发过程中对GPT接口进行批量化接口请求中出现的问题。
github地址:https://github.com/linkcao/springai-wave
大语言模型接口以OpenAI的GPT 3.5为例,JDK版本为17,其他依赖版本可见仓库pom.xml
拟解决的问题
在处理大量提示文本时,存在以下挑战:
- API密钥请求限制: 大部分AI服务提供商对API密钥的请求次数有限制,单个密钥每分钟只能发送有限数量的请求。
- 处理速度慢: 大量的提示文本需要逐条发送请求,处理速度较慢,影响效率。
- 结果保存和分析困难: 处理完成的结果需要保存到本地数据库中,并进行后续的数据分析,但这一过程相对复杂。
解决方案
为了解决上述问题,本文提出了一种基于Spring框架的批量化提示访问方案,如下图所示:
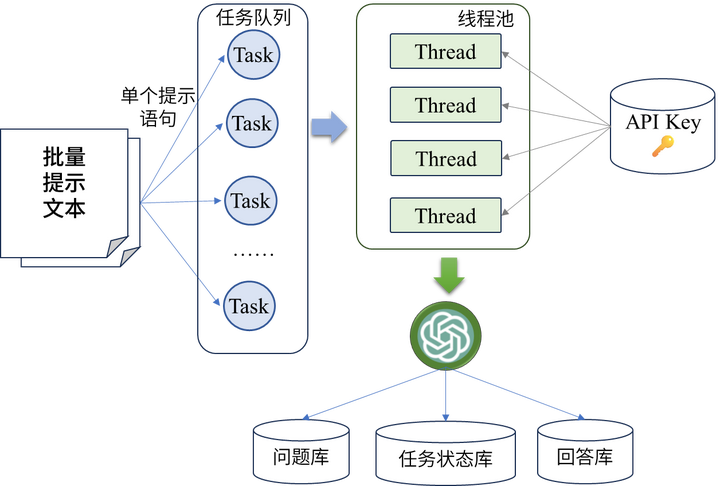
其中具体包括以下步骤:
- 多线程处理提示文本: 将每个提示文本看作一个独立的任务,采用线程池的方式进行多线程处理,提高处理效率。
- 动态分配API密钥: 在线程池初始化时,通过读取本地数据库中存储的API密钥信息,动态分配每个线程单元所携带的密钥,实现负载均衡。
- 结果保存和管理: 在请求完成后,将每个请求的问题和回答保存到本地数据库中,以便后续的数据分析和管理。
- 状态实时更新: 将整个批量请求任务区分为进行中、失败和完成状态,并通过数据库保存状态码实时更新任务状态,方便监控和管理。
关键代码示例
- 多线程异步请求提示信息(所在包: ChatService)
// 线程池初始化
private static final ExecutorService executor = Executors.newFixedThreadPool(10);
/**
* 多线程请求提示
* @param prompts
* @param user
* @param task
* @return
*/
@Async
public CompletableFuture<Void> processPrompts(List<String> prompts, Users user, Task task) {
for (int i = 0; i < prompts.size();i++) {
int finalI = i;
// 提交任务
executor.submit(() -> processPrompt(prompts.get(finalI), user, finalI));
}
// 设置批量任务状态
task.setStatus(TaskStatus.COMPLETED);
taskService.setTask(task);
return CompletableFuture.completedFuture(null);
}
如上所示,利用了Spring框架的
@Async注解和线程池的功能,实现了多线程异步处理提示信息。首先,使用了
ExecutorService创建了一个固定大小的线程池,以便同时处理多个提示文本。然后,通过
CompletableFuture来实现异步任务的管理。在处理每个提示文本时,通过
executor.submit()方法提交一个任务给线程池,让线程池来处理。处理完成后,将批量任务的状态设置为已完成,并更新任务状态。
一个线程任务需要绑定请求的用户以及所在的批量任务,当前任务所分配的key由任务所在队列的下标决定。
- 处理单条提示信息(所在包: ChatService)
/**
* 处理单条提示文本
* @param prompt 提示文本
* @param user 用户
* @param index 所在队列下标
*/
public void processPrompt(String prompt, Users user, int index) {
// 获取Api Key
OpenAiApi openAiApi = getApiByIndex(user, index);
assert openAiApi != null;
ChatClient client = new OpenAiChatClient(openAiApi);
// 提示文本请求
String response = client.call(prompt);
// 日志记录
log.info("提示信息" + prompt );
log.info("输出" + response );
// 回答保存数据库
saveQuestionAndAnswer(user, prompt, response);
}
- 首先根据任务队列的下标获取对应的API密钥
- 然后利用该密钥创建一个与AI服务进行通信的客户端。
- 接着,使用客户端发送提示文本请求,并获取AI模型的回答。
- 最后,将问题和回答保存到本地数据库和日志中,以便后续的数据分析和管理。
- Api Key 负载均衡(所在包: ChatService)
/**
* 采用任务下标分配key的方式进行负载均衡
* @param index 任务下标
* @return OpenAiApi
*/
private OpenAiApi getApiByIndex(int index){
List<KeyInfo> keyInfoList = keyRepository.findAll();
if (keyInfoList.isEmpty()) {
return null;
}
// 根据任务队列下标分配 Key
KeyInfo keyInfo = keyInfoList.get(index % keyInfoList.size());
return new OpenAiApi(keyInfo.getApi(),keyInfo.getKeyValue());
}
- 首先从本地数据库中获取所有可用的API密钥信息
- 然后根据任务队列的下标来动态分配API密钥。
- 确保每个线程单元都携带了不同的API密钥,避免了因为某个密钥请求次数达到限制而导致的请求失败问题。
- 依靠线程池批量请求GPT整体方法(所在包: ChatController)
/**
* 依靠线程池批量请求GPT
* @param promptFile 传入的批量提示文件,每一行为一个提示语句
* @param username 调用的用户
* @return 处理状态
*/
@PostMapping("/batch")
public String batchPrompt(MultipartFile promptFile, String username){
if (promptFile.isEmpty()) {
return "上传的文件为空";
}
// 批量请求任务
Task task = new Task();
try {
BufferedReader reader = new BufferedReader(new InputStreamReader(promptFile.getInputStream()));
List<String> prompts = new ArrayList<>();
String line;
while ((line = reader.readLine()) != null) {
prompts.add(line);
}
// 用户信息请求
Users user = userService.findByUsername(username);
// 任务状态设置
task.setFileName(promptFile.getName());
task.setStartTime(LocalDateTime.now());
task.setUserId(user.getUserId());
task.setStatus(TaskStatus.PROCESSING);
// 线程池处理
chatService.processPrompts(prompts, user, task);
return "文件上传成功,已开始批量处理提示";
} catch ( IOException e) {
// 处理失败
e.printStackTrace();
task.setStatus(TaskStatus.FAILED);
return "上传文件时出错:" + e.getMessage();
} finally {
// 任务状态保存
taskService.setTask(task);
}
}
- 首先,接收用户上传的批量提示文件和用户名信息。
- 然后,读取文件中的每一行提示文本,并将它们存储在一个列表中。
- 接着,根据用户名信息找到对应的用户,并创建一个任务对象来跟踪批量处理的状态。
- 最后,调用
ChatService中的processPrompts()方法来处理提示文本,并返回处理状态给用户。
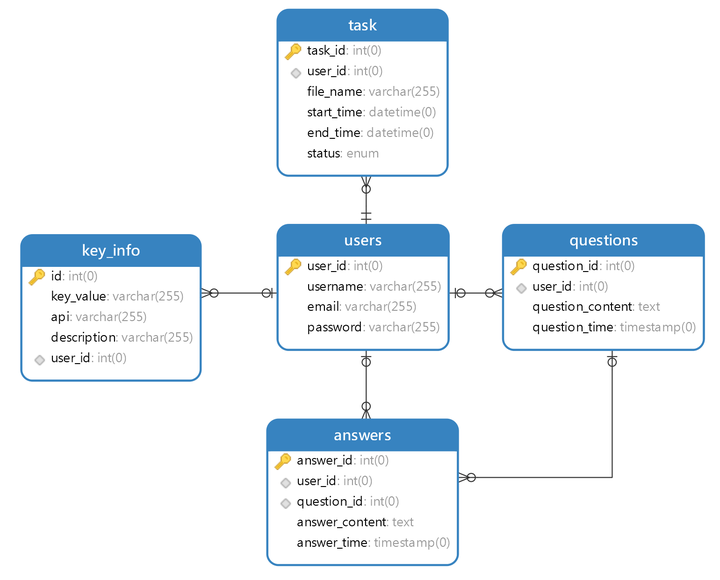
数据库ER图
所有信息都与用户ID强绑定,便于管理和查询,ER图如下所示:
演示示例
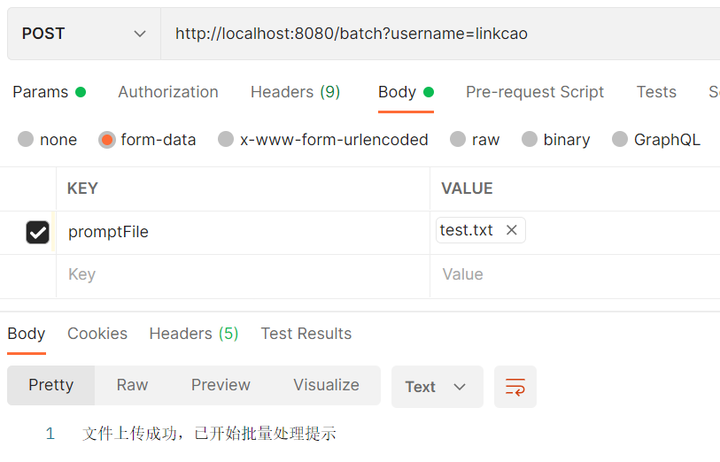
- 通过postman携带
批量请求文件和username信息进行Post请求访问localhost:8080/batch接口:
- 在实际应用中,可以根据具体需求对提示文本进行定制和扩展,以满足不同场景下的需求,演示所携带的请求文件内容如下:
请回答1+2=?
请回答8*12=?
请回答12*9=?
请回答321-12=?
请回答12/4=?
请回答32%2=?
- 最终返回的数据库结果,左为问题库,右为回答库:
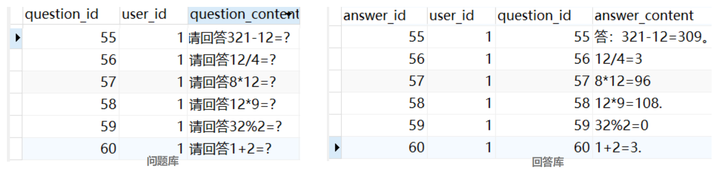
- 问题库和答案库通过
question_id和user_id进行绑定,由于一个问题可以让GPT回答多次,因此两者的关系为多对一,将问题和答案分在两个独立的表中也便于后续的垂域定制和扩展。
智能工作流:Spring AI高效批量化提示访问方案的更多相关文章
- .net core中的高效动态内存管理方案
.net core在新增的System.Buffers中引入了一大堆高效内存管理的类,如span和memory.内存池.本文今天这里介绍一个高效动态内存访问方案. ReadOnlySequenceSe ...
- Spring源码分析——资源访问利器Resource之实现类分析
今天来分析Spring的资源接口Resource的各个实现类.关于它的接口和抽象类,参见上一篇博文——Spring源码分析——资源访问利器Resource之接口和抽象类分析 一.文件系统资源 File ...
- 如何通过Spring Boot配置动态数据源访问多个数据库
之前写过一篇博客<Spring+Mybatis+Mysql搭建分布式数据库访问框架>描述如何通过Spring+Mybatis配置动态数据源访问多个数据库.但是之前的方案有一些限制(原博客中 ...
- myeclipse中配置spring xml自己主动提示
版权声明: https://blog.csdn.net/zdp072/article/details/24582173 这是一篇分享技巧的文章:myeclipse中配置spring xml自己主动提示 ...
- 腾讯毛华:智能交互,AI助力下的新生态
欢迎大家前往腾讯云+社区,获取更多腾讯海量技术实践干货哦~ 演讲人:毛华 腾讯云语音云总经理 背景:5月23-24日,以"焕启"为主题的腾讯"云+未来"峰会在广 ...
- 报告题目:HAO智能:HI + AI + OI
报告题目:HAO智能:HI + AI + OI 报告摘要:大数据面向异构自治的多源海量数据, 旨在挖掘数据间复杂且演化的关联.大数据知识工程(BigKE)从大数据的 HACE定理开始, 从大知识建模 ...
- spring boot 开静态资源访问,配置视图解析器
配置视图解析器spring.mvc.view.prefix=/pages/spring.mvc.view.suffiix= spring boot 开静态资源访问application.proerti ...
- Spring Boot Actuator未授权访问
当我们发现某一个网页的logo是一篇叶子或者报错信息如下图所示的话,就可以尝试Spring Boot Actuator未授权访问. /dump - 显示线程转储(包括堆栈跟踪) /autoconfig ...
- Spring配置XML本地提示
Spring配置XML本地提示:点击eclipse属性-->选择XML Catalog 这里有一点要注意:要选择schema location
- 解决提示“配色方案已更改为Windows7 Basic”
WIN7是很多用户都用过的系统,是由微软推出的.下面就说一个小技巧. 如何解决Win7系统提示:“配色方案已更改为Windows 7 Basic”解决方案. 更改Win7配色方案 首先,右击桌面空 ...
随机推荐
- SQL DELETE 语句:删除表中记录的语法和示例,以及 SQL SELECT TOP、LIMIT、FETCH FIRST 或 ROWNUM 子句的使用
SQL DELETE 语句 SQL DELETE 语句用于删除表中的现有记录. DELETE 语法 DELETE FROM 表名 WHERE 条件; 注意:在删除表中的记录时要小心!请注意DELETE ...
- C++调用Python-2:调用Python函数,返回数字
# mytest.py def hello(): print("this is test python print hello world") return 123 #includ ...
- HarmonyOS传感器开发指南
HarmonyOS系统传感器是应用访问底层硬件传感器的一种设备抽象概念.开发者根据传感器提供的Sensor接口,可以查询设备上的传感器,订阅传感器数据,并根据传感器数据定制相应的算法开发各类应用, ...
- HarmonyOS数据管理与应用数据持久化(一)
一. 数据管理概述 功能介绍 数据管理为开发者提供数据存储.数据管理能力,比如联系人应用数据可以保存到数据库中,提供数据库的安全.可靠等管理机制. ● 数据存储:提供通用数据持久化能力,根据数据特 ...
- navicat连接mysql8报错
mysql8采用更安全的加密方式,navicat不支持,网上大多办法都是采用的更改数据库加密方式为外部加密 个人觉得这样它不太合适 so,终于找到一个办法: 把mysql8安装后的lib文件夹里的 l ...
- Windows 系统上如何安装 Python 环境(详细教程)
Windows 系统上如何安装 Python 环境(详细教程) 目前,Python有两个版本,一个是2.x版,一个是3.x版,这两个版本是不兼容的.由于2.x版官方只维护到2020年,所以以3.x版作 ...
- 力扣165(java)-比较版本号(中等)
题目: 给你两个版本号 version1 和 version2 ,请你比较它们. 版本号由一个或多个修订号组成,各修订号由一个 '.' 连接.每个修订号由 多位数字 组成,可能包含 前导零 .每个版本 ...
- Log4j漏洞不仅仅是修复,更需要构建有效预警机制
简介:软件的漏洞有时不可避免,根据Gartner的相关统计,到 2025 年,30% 的关键信息基础设施组织将遇到安全漏洞.日志服务SLS,可帮助快速部署一个预警机制,使得漏洞被利用时可以快速发现并 ...
- OceanBase首次阐述战略:继续坚持自研开放之路 开源300万行核心代码
简介: 在数据库OceanBase3.0峰会上,蚂蚁集团自主研发的分布式数据库OceanBase首次从技术.商业和生态三个维度对未来发展战略进行了系统性阐述.同时,OceanBase宣布正式开源,并成 ...
- [FE] WebStorm, ESLint: Trailing spaces not allowed
在 WebStorm 中搜索文件 .eslintrc.js 在里面的 rules 项中追加规则: 'no-trailing-spaces' : ['off', { 'skipBlankLines': ...