ElasticSearch深度解析入门篇:高效搜索解决方案的介绍与实战案例讲解,带你避坑
ElasticSearch深度解析入门篇:高效搜索解决方案的介绍与实战案例讲解,带你避坑
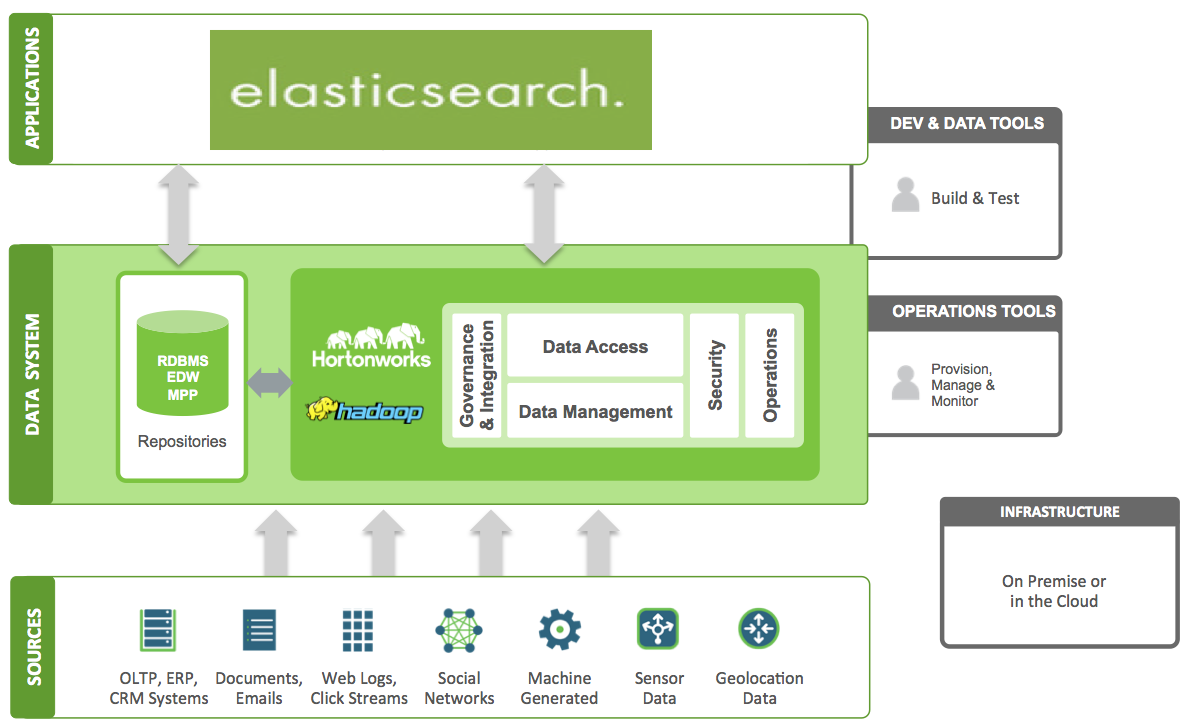
1.Elasticsearch 产生背景
- 大规模数据如何检索
如:当系统数据量上了 10 亿、100 亿条的时候,我们在做系统架构的时候通常会从以下角度去考虑问题: 1)用什么数据库好?(mysql、oracle、mongodb、hbase…) 2)如何解决单点故障;(lvs、F5、A10、Zookeep、MQ) 3)如何保证数据安全性;(热备、冷备、异地多活) 4)如何解决检索难题;(数据库代理中间件:mysql-proxy、Cobar、MaxScale 等;) 5)如何解决统计分析问题;(离线、近实时)
- 传统数据库的应对解决方案
对于关系型数据,我们通常采用以下或类似架构去解决查询瓶颈和写入瓶颈: 解决要点: 1)通过主从备份解决数据安全性问题; 2)通过数据库代理中间件心跳监测,解决单点故障问题; 3)通过代理中间件将查询语句分发到各个 slave 节点进行查询,并汇总结果
- 非关系型数据库解决方案
对于 Nosql 数据库,以 mongodb 为例,其它原理类似: 解决要点: 1)通过副本备份保证数据安全性; 2)通过节点竞选机制解决单点问题; 3)先从配置库检索分片信息,然后将请求分发到各个节点,最后由路由节点合并汇总结果
- 内存数据库解决方案
完全把数据放在内存中是不可靠的,实际上也不太现实,当我们的数据达到 PB 级别时,按照每个节点 96G 内存计算,在内存完全装满的数据情况下,我们需要的机器是:1PB=1024T=1048576G 节点数 = 1048576/96=10922 个 实际上,考虑到数据备份,节点数往往在 2.5 万台左右。成本巨大决定了其不现实!
所以把数据放在内存也好,不放在内存也好,都不能完完全全解决问题。 全部放在内存速度问题是解决了,但成本问题上来了。 为解决以上问题,从源头着手分析,通常会从以下方式来寻找方法: 1、存储数据时按有序存储; 2、将数据和索引分离; 3、压缩数据; 这就引出了 Elasticsearch
2.Elasticsearch 介绍
- Elasticsearch 是什么
Elasticsearch 是一个基于 Lucene 的分布式搜索和分析引擎。
ES 是 elaticsearch 简写, Elasticsearch 是一个开源的高扩展的分布式全文检索引擎,它可以近乎实时的存储、检索数据;本身扩展性很好,可以扩展到上百台服务器,处理 PB 级别的数据。 Elasticsearch 使用 Java 开发,在 Apache 许可条款下开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,使得全文检索变得简单
设计用途:用于分布式全文检索,通过 HTTP 使用 JSON 进行数据索引,速度快
- ** Lucene 与 Elasticsearch 关系**
1)Lucene 只是一个库。想要使用它,你必须使用 Java 来作为开发语言并将其直接集成到你的应用中,更糟糕的是,Lucene 非常复杂,你需要深入了解检索的相关知识来理解它是如何工作的。
2)Elasticsearch 也使用 Java 开发并使用 Lucene 作为其核心来实现所有索引和搜索的功能,但是它的目的是通过简单的 RESTful API 来隐藏 Lucene 的复杂性,从而让全文搜索变得简单。
- Elasticsearch vs solr
1)Solr 是 Apache Lucene 项目的开源企业搜索平台。其主要功能包括全文检索、命中标示、分面搜索、动态聚类、数据库集成,以及富文本(如 Word、PDF)的处理。
2)Solr 是高度可扩展的,并提供了分布式搜索和索引复制。Solr 是最流行的企业级搜索引擎,Solr4 还增加了 NoSQL 支持。
3)Solr 是用 Java 编写、运行在 Servlet 容器(如 Apache Tomcat 或 Jetty)的一个独立的全文搜索服务器。 Solr 采用了 Lucene Java 搜索库为核心的全文索引和搜索,并具有类似 REST 的 HTTP/XML 和 JSON 的 API。
4)Solr 强大的外部配置功能使得无需进行 Java 编码,便可对 其进行调整以适应多种类型的应用程序。Solr 有一个插件架构,以支持更多的高级定制
Elasticsearch 与 Solr 的比较总结
- 二者安装都很简单
- Solr 利用 Zookeeper 进行分布式管理,而 Elasticsearch 自身带有分布式协调管理功能
- Solr 支持更多格式的数据,而 Elasticsearch 仅支持 json 文件格式
- Solr 官方提供的功能更多,而 Elasticsearch 本身更注重于核心功能,高级功能多有第三方插件提供
- Solr 在传统的搜索应用中表现好于 Elasticsearch,但在处理实时搜索应用时效率明显低于 Elasticsearch
- Solr 是传统搜索应用的有力解决方案,但 Elasticsearch 更适用于新兴的实时搜索应用
2.1 Elasticsearch 核心概念
- Cluster:集群
ES 可以作为一个独立的单个搜索服务器。不过,为了处理大型数据集,实现容错和高可用性,ES 可以运行在许多互相合作的服务器上。这些服务器的集合称为集群。
- Node:节点
形成集群的每个服务器称为节点。
- Shard:分片
当有大量的文档时,由于内存的限制、磁盘处理能力不足、无法足够快的响应客户端的请求等,一个节点可能不够。这种情况下,数据可以分为较小的分片。每个分片放到不同的服务器上。 当你查询的索引分布在多个分片上时,ES 会把查询发送给每个相关的分片,并将结果组合在一起,而应用程序并不知道分片的存在。即:这个过程对用户来说是透明的。
- Replia:副本
为提高查询吞吐量或实现高可用性,可以使用分片副本。 副本是一个分片的精确复制,每个分片可以有零个或多个副本。ES 中可以有许多相同的分片,其中之一被选择更改索引操作,这种特殊的分片称为主分片。 当主分片丢失时,如:该分片所在的数据不可用时,集群将副本提升为新的主分片。
- 全文检索
全文检索就是对一篇文章进行索引,可以根据关键字搜索,类似于 mysql 里的 like 语句。 全文索引就是把内容根据词的意义进行分词,然后分别创建索引,例如”今日是周日我们出去玩” 可能会被分词成:“今天 “,” 周日 “,“我们“,” 出去玩“ 等 token,这样当你搜索“周日” 或者 “出去玩” 都会把这句搜出来。
2.2 与关系型数据库 Mysql 对比
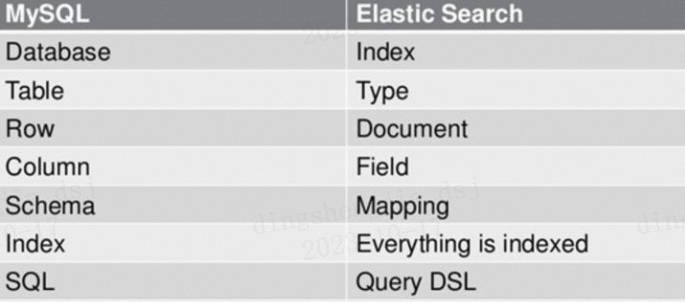
1)关系型数据库中的数据库(DataBase),等价于 ES 中的索引(Index)
2)一个数据库下面有 N 张表(Table),等价于 1 个索引 Index 下面有 N 多类型(Type),
3)一个数据库表(Table)下的数据由多行(ROW)多列(column,属性)组成,等价于 1 个 Type 由多个文档(Document)和多 Field 组成。
4)在一个关系型数据库里面,schema 定义了表、每个表的字段,还有表和字段之间的关系。 与之对应的,在 ES 中:Mapping 定义索引下的 Type 的字段处理规则,即索引如何建立、索引类型、是否保存原始索引 JSON 文档、是否压缩原始 JSON 文档、是否需要分词处理、如何进行分词处理等。
5)在数据库中的增 insert、删 delete、改 update、查 search 操作等价于 ES 中的增 PUT/POST、删 Delete、改_update、查 GET.1.7
2.3 ES 逻辑设计(文档 --> 类型 --> 索引)
一个索引类型中,包含多个文档,比如说文档 1,文档 2。 当我们索引一篇文档时,可以通过这样的顺序找到它:索引▷类型▷文档ID,通过这个组合我们就能索引到某个具体的文档。 注意:ID 不必是整数,实际上它是个字符串。
- 文档
之前说 elasticsearch 是面向文档的,那么就意味着索引和搜索数据的最小单位是文档,elasticsearch 中,文档有几个重要属性:
- 自我包含,一篇文档同时包含字段和对应的值,也就是同时包含
key:value - 可以是层次型的,一个文档中包含自文档,复杂的逻辑实体就是这么来的
- 灵活的结构,文档不依赖预先定义的模式,我们知道关系型数据库中,要提前定义字段才能使用,在 elasticsearch 中,对于字段是非常灵活的,有时候,我们可以忽略该字段,或者动态的添加一个新的字段。
- 文档是无模式的,也就是说,字段对应值的类型可以是不限类型的。
尽管我们可以随意的新增或者忽略某个字段,但是,每个字段的类型非常重要,比如一个年龄字段类型,可以是字符串也可以是整型。因为 elasticsearch 会保存字段和类型之间的映射及其他的设置。这种映射具体到每个映射的每种类型(详见扩展阅读:17 - 扩展阅读 - 删除映射类型. md),这也是为什么在 elasticsearch 中,类型有时候也称为映射类型。
- 类型
类型是文档的逻辑容器,就像关系型数据库一样,表格是行的容器。 类型中对于字段的定义称为映射,比如name映射为字符串类型。 我们说文档是无模式的,它们不需要拥有映射中所定义的所有字段,比如新增一个字段,那么 elasticsearch 是怎么做的呢?elasticsearch 会自动的将新字段加入映射,但是这个字段的不确定它是什么类型,elasticsearch 就开始猜,如果这个值是 18,那么 elasticsearch 会认为它是整型。 但是 elasticsearch 也可能猜不对,所以最安全的方式就是提前定义好所需要的映射,这点跟关系型数据库殊途同归了,先定义好字段,然后再使用,别整什么幺蛾子。后面在讨论更多关于映射的东西。
3.索引
索引是映射类型的容器,elasticsearch 中的索引是一个非常大的文档集合。索引存储了映射类型的字段和其他设置。然后它们被存储到了各个分片上了。
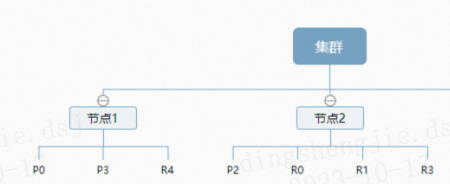
- ES 物理设计
一个集群包含至少一个节点,而一个节点就是一个elasticsearch进程。节点内可以有多个索引。
默认的,如果你创建一个索引,那么这个索引将会有5个分片(primary shard,又称主分片)构成,而每个分片又有一个副本(replica shard,又称复制分片),这样,就有了10个分片。
那么这个索引是如何存储在集群中的呢?
图中有3个节点的集群,可以看到主分片和对应的复制分片都不会在同一个节点内,这样有利于某个节点挂掉了,数据也不至于丢失。
实际上,一个分片是一个Lucene索引,一个包含倒排索引的文件目录,倒排索引的结构使得elasticsearch在不扫描全部文档的情况下,就能告诉你哪些文档包含特定的关键字
- ELK 是什么
ELK=elasticsearch+Logstash+kibana elasticsearch:后台分布式存储以及全文检索 logstash: 日志加工、“搬运工” kibana:数据可视化展示。 ELK 架构为数据分布式存储、可视化查询和日志解析创建了一个功能强大的管理链。 三者相互配合,取长补短,共同完成分布式大数据处理工作。
- Elasticsearch 特点和优势
1)分布式实时文件存储,可将每一个字段存入索引,使其可以被检索到。
2)实时分析的分布式搜索引擎。 分布式:索引分拆成多个分片,每个分片可有零个或多个副本。集群中的每个数据节点都可承载一个或多个分片,并且协调和处理各种操作; 负载再平衡和路由在大多数情况下自动完成。
3)可以扩展到上百台服务器,处理 PB 级别的结构化或非结构化数据。也可以运行在单台 PC 上
4)支持插件机制,分词插件、同步插件、Hadoop 插件、可视化插件等。
4.Elasticsearch使用场景
4.1 国内外优秀案例
1) 2013 年初,GitHub 抛弃了 Solr,采取 ElasticSearch 来做 PB 级的搜索。 “GitHub 使用 ElasticSearch 搜索 20TB 的数据,包括 13 亿文件和 1300 亿行代码”。
2)维基百科:启动以 elasticsearch 为基础的核心搜索架构。 3)SoundCloud:“SoundCloud 使用 ElasticSearch 为 1.8 亿用户提供即时而精准的音乐搜索服务”。 4)百度:百度目前广泛使用 ElasticSearch 作为文本数据分析,采集百度所有服务器上的各类指标数据及用户自定义数据,通过对各种数据进行多维分析展示,辅助定位分析实例异常或业务层面异常。目前覆盖百度内部 20 多个业务线(包括 casio、云分析、网盟、预测、文库、直达号、钱包、风控等),单集群最大 100 台机器,200 个 ES 节点,每天导入 30TB + 数据。
5)新浪 ES 如何分析处理 32 亿条实时日志 6)阿里 ES 构建挖财自己的日志采集和分析体系 7)有赞 ES 业务日志处理
4.2业务场景
实际项目开发实战中,几乎每个系统都会有一个搜索的功能,当搜索做到一定程度时,维护和扩展起来难度就会慢慢变大,所以很多公司都会把搜索单独独立出一个模块,用 ElasticSearch 等来实现。
近年 ElasticSearch 发展迅猛,已经超越了其最初的纯搜索引擎的角色,现在已经增加了数据聚合分析(aggregation)和可视化的特性,如果你有数百万的文档需要通过关键词进行定位时,ElasticSearch 肯定是最佳选择。当然,如果你的文档是 JSON 的,你也可以把 ElasticSearch 当作一种 “NoSQL 数据库”, 应用 ElasticSearch 数据聚合分析(aggregation)的特性,针对数据进行多维度的分析。
尝试使用 ES 来替代传统的 NoSQL,它的横向扩展机制太方便了
应用场景:
1)新系统开发尝试使用 ES 作为存储和检索服务器; 2)现有系统升级需要支持全文检索服务,需要使用 ES
4.3 Elasticsearch 索引到底能处理多大数据
单一索引的极限取决于存储索引的硬件、索引的设计、如何处理数据以及你为索引备份了多少副本。
通常来说,一个 Lucene 索引(也就是一个 elasticsearch 分片,一个 es 索引默认 5 个分片)不能处理多于 21 亿篇文档,或者多于 2740 亿的唯一词条。但达到这个极限之前,我们可能就没有足够的磁盘空间了! 当然,一个分片如何很大的话,读写性能将会变得非常差
ElasticSearch深度解析入门篇:高效搜索解决方案的介绍与实战案例讲解,带你避坑的更多相关文章
- 最新版本elasticsearch本地搭建入门篇
最新版本elasticsearch本地搭建入门篇 项目介绍 最近工作用到elasticsearch,主要是用于网站搜索,和应用搜索. 工欲善其事,必先利其器. 自己开始关注elasticsearch, ...
- Elasticsearch学习记录(入门篇)
Elasticsearch学习记录(入门篇) 1. Elasticsearch的请求与结果 请求结构 curl -X<VERB> '<PROTOCOL>://<HOST& ...
- [WebKit内核] JavaScript引擎深度解析--基础篇(一)字节码生成及语法树的构建详情分析
[WebKit内核] JavaScript引擎深度解析--基础篇(一)字节码生成及语法树的构建详情分析 标签: webkit内核JavaScriptCore 2015-03-26 23:26 2285 ...
- [WebKit内核] JavaScriptCore深度解析--基础篇(一)字节码生成及语法树的构建
看到HorkeyChen写的文章<[WebKit] JavaScriptCore解析--基础篇(三)从脚本代码到JIT编译的代码实现>,写的很好,深受启发.想补充一些Horkey没有写到的 ...
- ElasticSearch学习,入门篇(一)
概念解析 1.什么是搜索 搜索就是在任何场景下,找寻你想要的信息,这个时候你会输入一段要搜索的关键字,然后期望找到这个关键字相关的有效信息. 2.如果用数据库做搜素会怎么样 select * from ...
- 深度学习入门篇--手把手教你用 TensorFlow 训练模型
欢迎大家前往腾讯云技术社区,获取更多腾讯海量技术实践干货哦~ 作者:付越 导语 Tensorflow在更新1.0版本之后多了很多新功能,其中放出了很多用tf框架写的深度网络结构(https://git ...
- Linux下的fdlisk - l 用法解析-入门篇
fdlisk - l 的含义是查看linux下面的磁盘分区大小.这个大小包含了很多信息. 我们来看度娘的一则介绍: FDISK进行硬盘分区从实质上说就是对硬盘的一种格式化.当我们创建分区时,就已经设置 ...
- [STemWin教程入门篇] 第一期:emWin介绍
转自:http://bbs.armfly.com/read.php?tid=1544 SEGGER公司介绍 了解emWin之前,先了解一下SEGGER这家公司,了解生产商才能对emWin有更加全面的认 ...
- SaltStack入门篇(七)之架构部署实战
模块:https://docs.saltstack.com/en/2016.11/ref/states/all/index.html 实战架构图: 实验环境设置: 主机名 IP地址 角色 linux- ...
- spring5 源码深度解析----- @Transactional注解的声明式事物介绍(100%理解事务)
面的几个章节已经分析了spring基于@AspectJ的源码,那么接下来我们分析一下Aop的另一个重要功能,事物管理. 事务的介绍 1.数据库事物特性 原子性多个数据库操作是不可分割的,只有所有的操作 ...
随机推荐
- Nginx--upstream健康检查
nginx 判断节点失效状态: Nginx 默认判断失败节点状态以connect refuse和time out状态为准,不以HTTP错误状态进行判断失败,因为HTTP只要能返回状态说明该节点还可以正 ...
- QA32增强
一.QA32报表新增字段 二.QA32报表程序RQEEAL10 结构增加字段,该结构就是报表展示字段列的结构 表新增字段 找到报表展示的子例程 找到程序RQEEAL10,子例程中新增隐式增强 隐式增强 ...
- POJ - 3180 The Cow Prom ( korasaju 算法模板)
The Cow Prom POJ - 3180 题意: 奶牛圆舞:N头牛,M条有向绳子,能组成几个歌舞团(团内奶牛数 n >= 2)?要求顺时针逆时针都能带动舞团内所有牛. 分析: 所谓能带动, ...
- L3-001. 凑零钱-PAT团体程序设计天梯赛GPLT(01背包,动态规划)
韩梅梅喜欢满宇宙到处逛街.现在她逛到了一家火星店里,发现这家店有个特别的规矩:你可以用任何星球的硬币付钱,但是绝不找零,当然也不能欠债.韩梅梅手边有 104 枚来自各个星球的硬币,需要请你帮她盘算一下 ...
- C语言常用字符串操作函数整理(详细全面)
目录 字符串相关 1.char *gets(char *s); #include<stdio.h> 2.char *fgets(char *s, intsize, FILE *stream ...
- Delete `␍`eslint(prettier/prettier)错误
最佳实践: 现在VScode,Notepad++编辑器都能够自动识别文件的换行符是LF还是CRLF. 如果你用的是windows,文件编码是UTF-8且包含中文,最好全局将autocrlf设置为fal ...
- js判断null最标准写法
- 基于React开发的chatgpt网页版(仿chatgpt)
在浏览github的时候发现了一个好玩的项目本项目,是github大神Yidadaa开发的chatgpt网页版,该开源项目是跨平台的,Web / PWA / Linux / Win / MacOS都可 ...
- 在Linux上安装和使用免费版本的PyMol
技术背景 PyMol是一个类似于VMD的分子可视化工具,也是在PyQt的基础上开发的.但是由于其商业化运营,软件分为了教育版.开源版和商业版三个版本.其中教育版会有水印,商业版要收费,但是官方不提供开 ...
- AMBA Bus介绍_01
AMBA总线概述 系统总线简介 AMBA 2.0 AHB - 高性能Bus APB - 外设Bus AHB ASB APB AHB 组成部分 APB组成部分 AMBA协议其他有关问题 DMA DMA ...