go中context源码解读
context
前言
之前浅读过,不过很快就忘记了,再次深入学习下。
本文的是在go version go1.13.15 darwin/amd64进行的
什么是context
go在Go 1.7 标准库引入context,主要用来在goroutine之间传递上下文信息,包括:取消信号、超时时间、截止时间、k-v 等。
为什么需要context呢
在并发程序中,由于超时、取消或者一些异常的情况,我们可能要抢占操作或者中断之后的操作。
在Go里,我们不能直接杀死协程,协程的关闭一般会用 channel+select 方式来控制,但是如果某一个操作衍生出了很多的协程,并且相互关联。或者某一个协程层级很深,有很深的子子协程,这时候使用channel+select就比较头疼了。
所以context的适用机制
- 上层任务取消后,所有的下层任务都会被取消;
- 中间某一层的任务取消后,只会将当前任务的下层任务取消,而不会影响上层的任务以及同级任务。
同时context也可以传值,不过这个很少用到,使用context.Context进行传递参数请求的所有参数一种非常差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求ID。
context底层设计
context的实现
type Context interface {
// 返回context被取消的时间
// 当没有设置Deadline时间,返回false
Deadline() (deadline time.Time, ok bool)
// 当context被关闭,返回一个被关闭的channel
Done() <-chan struct{}
// 在 channel Done 关闭后,返回 context 取消原因
Err() error
// 获取key对应的value
Value(key interface{}) interface{}
}
Deadline返回Context被取消的时间,第一个返回式是截止时间,到了这个时间点,Context会自动发起取消请求;第二个返回值ok==false时表示没有设置截止时间,如果需要取消的话,需要调用取消函数进行取消。
Done返回一个只读的channel,类型为struct{},当该context被取消的时候,该channel会被关闭。对于只读的channel,只有被关闭的时候,才能通过select读出对应的零值,字协程监听这个channel,只要能读出值(对应的零值),就可以进行收尾工作了。
Err返回context结束的原因,只有在context被关闭的时候才会返回非空的值。
1、如果context被取消,会返回Canceled错误;
2、如果context超时,会返回DeadlineExceeded错误;
Value获取之前存入key对应的value值。里面的值可以多次拿取。
几种context
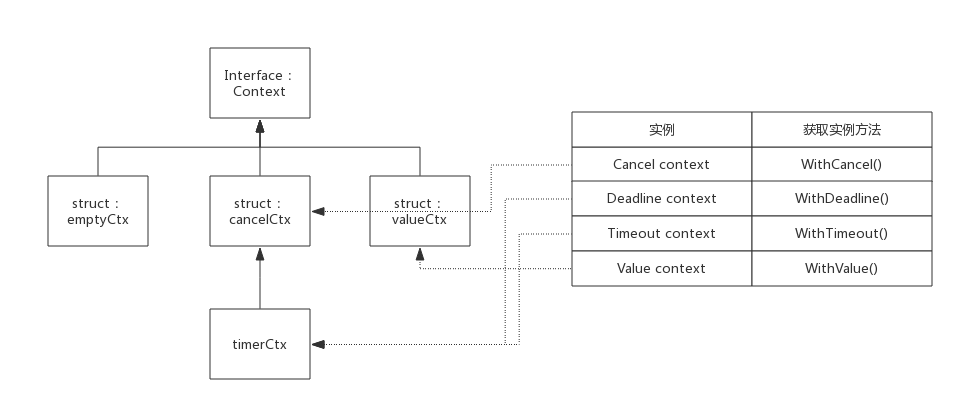
emptyCtx
context之源头
// An emptyCtx is never canceled, has no values, and has no deadline. It is not
// struct{}, since vars of this type must have distinct addresses.
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}
func (e *emptyCtx) String() string {
switch e {
case background:
return "context.Background"
case todo:
return "context.TODO"
}
return "unknown empty Context"
}
emptyCtx以do nothing的方式实现了Context接口。
同时有两个emptyCtx的全局变量
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
通过下面两个导出的函数(首字母大写)对外公开:
func Background() Context {
return background
}
func TODO() Context {
return todo
}
这两个我们在使用的时候如何区分呢?
先来看下官方的解释
// Background returns a non-nil, empty Context. It is never canceled, has no
// values, and has no deadline. It is typically used by the main function,
// initialization, and tests, and as the top-level Context for incoming
// requests.
// TODO returns a non-nil, empty Context. Code should use context.TODO when
// it's unclear which Context to use or it is not yet available (because the
// surrounding function has not yet been extended to accept a Context
// parameter).
Background 适用于主函数、初始化以及测试中,作为一个顶层的context。
TODO适用于不知道传递什么context的情形。
也就是在未考虑清楚是否传递、如何传递context时用TODO,作为发起点的时候用Background。
cancelCtx
cancel机制的灵魂
cancelCtx的cancel机制是手工取消、超时取消的内部实现
// A cancelCtx can be canceled. When canceled, it also cancels any children
// that implement canceler.
type cancelCtx struct {
Context
mu sync.Mutex // protects following fields
done chan struct{} // created lazily, closed by first cancel call
children map[canceler]struct{} // set to nil by the first cancel call
err error // set to non-nil by the first cancel call
}
看下Done
func (c *cancelCtx) Done() <-chan struct{} {
// 加锁
c.mu.Lock()
// 如果done为空,创建make(chan struct{})
if c.done == nil {
c.done = make(chan struct{})
}
d := c.done
c.mu.Unlock()
return d
}
这是个懒汉模式的函数,第一次调用的时候c.done才会被创建。
重点看下cancel
// 关闭 channel,c.done;递归地取消它的所有子节点;从父节点从删除自己。
func (c *cancelCtx) cancel(removeFromParent bool, err error) {
if err == nil {
panic("context: internal error: missing cancel error")
}
// 加锁
c.mu.Lock()
// 已经取消了
if c.err != nil {
c.mu.Unlock()
return // already canceled
}
c.err = err
// 关闭channel
// channel没有初始化
if c.done == nil {
// 赋值一个关闭的channel,closedchan
c.done = closedchan
} else {
// 初始化了channel,直接关闭
close(c.done)
}
// 递归子节点,一层层取消
for child := range c.children {
// NOTE: acquiring the child's lock while holding parent's lock.
child.cancel(false, err)
}
// 将子节点置空
c.children = nil
c.mu.Unlock()
if removeFromParent {
// 从父节点中移除自己
removeChild(c.Context, c)
}
}
// 从父节点删除context
func removeChild(parent Context, child canceler) {
p, ok := parentCancelCtx(parent)
if !ok {
return
}
p.mu.Lock()
if p.children != nil {
// 删除child
delete(p.children, child)
}
p.mu.Unlock()
}
// closedchan is a reusable closed channel.
var closedchan = make(chan struct{})
func init() {
close(closedchan)
}
这个函数的作用就是关闭channel,递归地取消它的所有子节点;从父节点从删除自己。达到的效果是通过关闭channel,将取消信号传递给了它的所有子节点。
再来看下propagateCancel
// broadcastCancel安排在父级被取消时取消子级。
func propagateCancel(parent Context, child canceler) {
if parent.Done() == nil {
return // parent is never canceled
}
// 找到可以取消的父 context
if p, ok := parentCancelCtx(parent); ok {
p.mu.Lock()
// 父节点取消了
if p.err != nil {
// 取消子节点
child.cancel(false, p.err)
// 父节点没有取消
} else {
if p.children == nil {
p.children = make(map[canceler]struct{})
}
// 挂载
p.children[child] = struct{}{}
}
p.mu.Unlock()
// 没有找到父节点
} else {
// 启动一个新的节点监听父节点和子节点的取消信息
go func() {
select {
// 如果父节点取消了
case <-parent.Done():
child.cancel(false, parent.Err())
case <-child.Done():
}
}()
}
}
func parentCancelCtx(parent Context) (*cancelCtx, bool) {
for {
switch c := parent.(type) {
case *cancelCtx:
return c, true
case *timerCtx:
return &c.cancelCtx, true
case *valueCtx:
parent = c.Context
default:
return nil, false
}
}
}
这个函数的作用是在parent和child之间同步取消和结束的信号,保证在parent被取消时child也会收到对应的信号,不会出现状态不一致的情况。
上面可以看到,对于指定的几种context是直接cancel方法递归地取消所有的子上下文这可以节省开启新goroutine监听父context是否结束的开销;
对于非指定的也就是自定义的context,运行时会通过启动goroutine来监听父Context是否结束,并在父context结束时取消自己,然而启动新的goroutine是相对昂贵的开销;
对外暴露的WithCancel就是对cancelCtx的应用
func WithCancel(parent Context) (ctx Context, cancel CancelFunc) {
// 将传入的上下文包装成私有结构体 context.cancelCtx
c := newCancelCtx(parent)
// 构建父子上下文之间的关联
propagateCancel(parent, &c)
return &c, func() { c.cancel(true, Canceled) }
}
// newCancelCtx returns an initialized cancelCtx.
func newCancelCtx(parent Context) cancelCtx {
return cancelCtx{Context: parent}
}
使用WithCancel传入一个context,会对这个context进行重新包装。
当WithCancel函数返回的CancelFunc被调用或者是父节点的done channel被关闭(父节点的 CancelFunc 被调用),此 context(子节点)的 done channel 也会被关闭。
timerCtx
在来看下timerCtx
type timerCtx struct {
cancelCtx
timer *time.Timer // Under cancelCtx.mu.
deadline time.Time
}
func (c *timerCtx) cancel(removeFromParent bool, err error) {
// 调用context.cancelCtx.cancel
c.cancelCtx.cancel(false, err)
if removeFromParent {
// Remove this timerCtx from its parent cancelCtx's children.
removeChild(c.cancelCtx.Context, c)
}
c.mu.Lock()
// 关掉定时器,减少资源浪费
if c.timer != nil {
c.timer.Stop()
c.timer = nil
}
c.mu.Unlock()
}
在cancelCtx的基础之上多了个timer和deadline。它通过停止计时器来实现取消,然后通过cancelCtx.cancel,实现取消。
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc) {
// 调用WithDeadline,传入时间
return WithDeadline(parent, time.Now().Add(timeout))
}
func WithDeadline(parent Context, d time.Time) (Context, CancelFunc) {
// 判断结束时间,是否到了
if cur, ok := parent.Deadline(); ok && cur.Before(d) {
// The current deadline is already sooner than the new one.
return WithCancel(parent)
}
// 构建timerCtx
c := &timerCtx{
cancelCtx: newCancelCtx(parent),
deadline: d,
}
// 构建父子上下文之间的关联
propagateCancel(parent, c)
// 计算当前距离 deadline 的时间
dur := time.Until(d)
if dur <= 0 {
c.cancel(true, DeadlineExceeded) // deadline has already passed
return c, func() { c.cancel(false, Canceled) }
}
c.mu.Lock()
defer c.mu.Unlock()
if c.err == nil {
// d 时间后,timer 会自动调用 cancel 函数。自动取消
c.timer = time.AfterFunc(dur, func() {
c.cancel(true, DeadlineExceeded)
})
}
return c, func() { c.cancel(true, Canceled) }
}
context.WithDeadline在创建context.timerCtx的过程中判断了父上下文的截止日期与当前日期,并通过time.AfterFunc创建定时器,当时间超过了截止日期后会调用context.timerCtx.cancel同步取消信号。
valueCtx
type valueCtx struct {
Context
key, val interface{}
}
func (c *valueCtx) Value(key interface{}) interface{} {
if c.key == key {
return c.val
}
return c.Context.Value(key)
}
func WithValue(parent Context, key, val interface{}) Context {
if key == nil {
panic("nil key")
}
if !reflectlite.TypeOf(key).Comparable() {
panic("key is not comparable")
}
return &valueCtx{parent, key, val}
}
如果context.valueCtx中存储的键值对与context.valueCtx.Value方法中传入的参数不匹配,就会从父上下文中查找该键对应的值直到某个父上下文中返回nil或者查找到对应的值。
因为查找方向是往上走的,所以,父节点没法获取子节点存储的值,子节点却可以获取父节点的值。
context查找的时候是向上查找,找到离得最近的一个父节点里面挂载的值。
所以context查找的时候会存在覆盖的情况,如果一个处理过程中,有若干个函数和若干个子协程。在不同的地方向里面塞值进去,对于取值可能取到的不是自己放进去的值。
所以在使用context进行传值的时候我们应该慎用,使用context传值是一个比较差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求 ID。
防止内存泄露
goroutine是很轻量的,但是不合理的使用就会导致goroutine的泄露,也就是内存泄露,具体的内存泄露可参考go中内存泄露的发现与排查
使用context.WithTimeout可以防止内存泄露
func TimeoutCancelContext() {
ctx, cancel := context.WithTimeout(context.Background(), time.Duration(time.Millisecond*800))
go func() {
// 具体的业务逻辑
// 取消超时
defer cancel()
}()
select {
case <-ctx.Done():
fmt.Println("time out!!!")
return
}
}
1、通过context的WithTimeout设置一个有效时间为1000毫秒的context。
2、业务逻辑完成会调用cancel(),取消超时,如果在设定的超时时间内,业务阻塞没有完成,就会触发超时的退出。
总结
1、context是并发安全的
2、context可以进行传值,但是在使用context进行传值的时候我们应该慎用,使用context传值是一个比较差的设计,比较常见的使用场景是传递请求对应用户的认证令牌以及用于进行分布式追踪的请求 ID。
3、对于context的传值查询,context查找的时候是向上查找,找到离得最近的一个父节点里面挂载的值,所以context在查找的时候会存在覆盖的情况,如果一个处理过程中,有若干个函数和若干个子协程。在不同的地方向里面塞值进去,对于取值可能取到的不是自己放进去的值。
4、当使用 context 作为函数参数时,直接把它放在第一个参数的位置,并且命名为 ctx。另外,不要把 context 嵌套在自定义的类型里。
参考
【Go Context的踩坑经历】https://zhuanlan.zhihu.com/p/34417106
【深度解密Go语言之context】https://www.cnblogs.com/qcrao-2018/p/11007503.html
【深入理解Golang之context】https://juejin.cn/post/6844904070667321357
【上下文 Context】https://draveness.me/golang/docs/part3-runtime/ch06-concurrency/golang-context/
【Golang Context深入理解】https://juejin.cn/post/6844903555145400334
【《Go专家编程》Go 并发控制context实现原理剖析】https://my.oschina.net/renhc/blog/2249581
go中context源码解读的更多相关文章
- go中panic源码解读
panic源码解读 前言 panic的作用 panic使用场景 看下实现 gopanic gorecover fatalpanic 总结 参考 panic源码解读 前言 本文是在go version ...
- etcd中watch源码解读
etcd中watch的源码解析 前言 client端的代码 Watch newWatcherGrpcStream run newWatchClient serveSubstream server端的代 ...
- go中waitGroup源码解读
waitGroup源码刨铣 前言 WaitGroup实现 noCopy state1 Add Wait 总结 参考 waitGroup源码刨铣 前言 学习下waitGroup的实现 本文是在go ve ...
- java中jdbc源码解读
在jdbc中一个重要的接口类就是java.sql.Driver,其中有一个重要的方法:Connection connect(String url, java.util.Propeties info); ...
- go中errgroup源码解读
errgroup 前言 如何使用 实现原理 WithContext Go Wait 错误的使用 总结 errgroup 前言 来看下errgroup的实现 如何使用 func main() { var ...
- Mybatis源码解读-SpringBoot中配置加载和Mapper的生成
本文mybatis-spring-boot探讨在springboot工程中mybatis相关对象的注册与加载. 建议先了解mybatis在spring中的使用和springboot自动装载机制,再看此 ...
- 【原】Spark中Job的提交源码解读
版权声明:本文为原创文章,未经允许不得转载. Spark程序程序job的运行是通过actions算子触发的,每一个action算子其实是一个runJob方法的运行,详见文章 SparkContex源码 ...
- HttpServlet中service方法的源码解读
前言 最近在看<Head First Servlet & JSP>这本书, 对servlet有了更加深入的理解.今天就来写一篇博客,谈一谈Servlet中一个重要的方法-- ...
- AbstractCollection类中的 T[] toArray(T[] a)方法源码解读
一.源码解读 @SuppressWarnings("unchecked") public <T> T[] toArray(T[] a) { //size为集合的大小 i ...
- go 中 sort 如何排序,源码解读
sort 包源码解读 前言 如何使用 基本数据类型切片的排序 自定义 Less 排序比较器 自定义数据结构的排序 分析下源码 不稳定排序 稳定排序 查找 Interface 总结 参考 sort 包源 ...
随机推荐
- 声明式调用 —— SpringCloud OpenFeign
Feign 简介 Spring Cloud Feign 是一个 HTTP 请求调用的轻量级框架,可以以 Java 接口注解的方式调用 HTTP 请求,而不用通过封装 HTTP 请求报文的方式直接调用 ...
- Appium常用定位方法讲解
Appium常用定位方法讲解 对象定位是自动化测试中很关键的一步,也可以说是 最关键的一步,毕竟你对象都没定位那么你想操作也不行,下面我们来看常用的一些定位方式. ID定位(取resource-id的 ...
- 阿里云 AI 编辑部获 CCBN 创新奖,揭秘传媒行业解决方案背后的黑科技
5 月 27 日,CCBN(第二十八届中国国际广播电视信息网络展览会)在北京隆重召开,在本次的 "CCBN 年度创新奖" 评选中,阿里云视频云凭借AI 编辑部的传媒行业专业解决方案 ...
- WCF 动态调用 动态代理
关键词:WCF动态调用.动态调用WCF.WCF使用动态代理精简代码架构.使用反射执行WCF接口 代码地址: https://gitee.com/s0611163/DynamicWCF https:// ...
- # 0x56 动态规划-状态压缩DP
0x56 动态规划-状态压缩DP Mondriaan's Dream Description Squares and rectangles fascinated the famous Dutch pa ...
- 打破监控壁垒,棉花厂3D可视化建设让生产加工更加智能化
前言 现在的棉花加工行业还停留在传统的反应式维护模式当中,当棉花加下厂的设备突然出现故障时,控制程序需要更换.这种情况下,首先需要客户向设备生产厂家请求派出技术人员进行维护,然后生产厂家才能根据情况再 ...
- SpringCloud学习 系列十、服务熔断与降级(3-类级别的服务降级)
系列导航 SpringCloud学习 系列一. 前言-为什么要学习微服务 SpringCloud学习 系列二. 简介 SpringCloud学习 系列三. 创建一个没有使用springCloud的服务 ...
- vue如何实现v-model
- 线性代数 · 矩阵 · Matlab | 满秩分解代码实现
背景 - 矩阵的满秩分解: 若 A 为 m×n 矩阵,rank(A) = r,则存在 F m×r.G r×n,使得 A = FG. 其中,F 列满秩,G 行满秩. 求满秩分解的方法: 得到 A 的行最 ...
- webflux 的使用总结
本文为博主原创,未经允许不得转载: 1. Servlet 3.0 简介 2. WebFlux 简介 及 特点 3. 基于函数式的 WebFlux 开发 4. webFlux 全局异常 5. webF ...