kaggle入门项目:Titanic存亡预测(四)模型拟合
原kaggle比赛地址:https://www.kaggle.com/c/titanic
原kernel地址:A Data Science Framework: To Achieve 99% Accuracy
Step 5: Model Data
数据科学是交叉学科,我们仅仅称他为计算机科学的一部分是有失公正的,它包含了数学,cs,商业管理,统计学等等方向。
机器学习被分为监督学习,无监督学习和强化学习,强化学习是前两者的混合。
算法被归为四类:分类、回归、聚类、降维,此kernel专注于分类与回归,因为我们通过题目得知我们需要的是有监督学习的分类算法,这样就能缩小我们的算法选择了。
那么再看机器学习的分类算法:
- Ensemble Methods(集成算法)
- Generalized Linear Models (GLM)(广义线性模型)
- Naive Bayes(朴素贝叶斯)
- Nearest Neighbors(最邻近算法)
- Support Vector Machines (SVM)(支持向量机)
- Decision Trees(决策树)
- Discriminant Analysis(判别分析)
Data Science 101: How to Choose a Machine Learning Algorithm (MLA)
如何选取及其学习算法呢?初学者一定要知道 No Free Lunch Theorem (NFLT) 概念。即没有任何一种算法比其他算法更优秀,或者“如果一个算法对于某个类型的问题比另外的算法效率高,那么它一定不具有普适性”。不同的问题使用不同的算法是肯定的,所以最佳方法是尝试多种算法并调试(可能这也是model ensemble和stacking如此重要的原因吧)。
所以作者建议初学者从 Trees, Bagging, Random Forests, and Boosting.这三种方法开始(都是决策树形式)
首先构建一个list命名为MLA,里面包含了多种算法
MLA = [
#Ensemble Methods
ensemble.AdaBoostClassifier(),
ensemble.BaggingClassifier(),
ensemble.ExtraTreesClassifier(),
ensemble.GradientBoostingClassifier(),
ensemble.RandomForestClassifier(), #Gaussian Processes
gaussian_process.GaussianProcessClassifier(), #GLM
linear_model.LogisticRegressionCV(),
linear_model.PassiveAggressiveClassifier(),
linear_model.RidgeClassifierCV(),
linear_model.SGDClassifier(),
linear_model.Perceptron(), #Navies Bayes
naive_bayes.BernoulliNB(),
naive_bayes.GaussianNB(), #Nearest Neighbor
neighbors.KNeighborsClassifier(), #SVM
svm.SVC(probability=True),
svm.NuSVC(probability=True),
svm.LinearSVC(), #Trees
tree.DecisionTreeClassifier(),
tree.ExtraTreeClassifier(), #Discriminant Analysis
discriminant_analysis.LinearDiscriminantAnalysis(),
discriminant_analysis.QuadraticDiscriminantAnalysis(), #xgboost: http://xgboost.readthedocs.io/en/latest/model.html
XGBClassifier()
]
MLA
然后关键的一部来了,我们将训练数据集分割。使用ShuffleSplit()将数据集打乱并以60/30分开(留下1/10弃用)并且该过程迭代10次
cv_split = model_selection.ShuffleSplit(n_splits = 10, test_size = .3, train_size = .6, random_state = 0 )
构建MLA_compare的dataframe用来对比不同算法在该问题上的优劣
MLA_columns = ['MLA Name', 'MLA Parameters','MLA Train Accuracy Mean', 'MLA Test Accuracy Mean', 'MLA Test Accuracy 3*STD' ,'MLA Time']
MLA_compare = pd.DataFrame(columns = MLA_columns)
然后就是尝试每一种算法,并对他们进行评分对比。核心函数是cross_validate()函数。
MLA_name = alg.__class__.__name__
MLA_compare.loc[row_index, 'MLA Name'] = MLA_name
MLA_compare.loc[row_index, 'MLA Parameters'] = str(alg.get_params()) #score model with cross validation: http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_validate.html#sklearn.model_selection.cross_validate
cv_results = model_selection.cross_validate(alg, data1[data1_x_bin], data1[Target], cv = cv_split) MLA_compare.loc[row_index, 'MLA Time'] = cv_results['fit_time'].mean()
MLA_compare.loc[row_index, 'MLA Train Accuracy Mean'] = cv_results['train_score'].mean()
MLA_compare.loc[row_index, 'MLA Test Accuracy Mean'] = cv_results['test_score'].mean()
#if this is a non-bias random sample, then +/-3 standard deviations (std) from the mean, should statistically capture 99.7% of the subsets
MLA_compare.loc[row_index, 'MLA Test Accuracy 3*STD'] = cv_results['test_score'].std()*3 #let's know the worst that can happen! #save MLA predictions - see section 6 for usage
alg.fit(data1[data1_x_bin], data1[Target])
MLA_predict[MLA_name] = alg.predict(data1[data1_x_bin]) row_index+=1
最终我们的前三名分别是 XGB 随机森林 SVC

使用barplot展示每个算法的准确度

5.1 Evaluate Model Performance
我认为这一部分的论述很有启发
那么现在的结论是,在进行了基础的数据挖掘过程后,我们的准确率达到了82%左右,但是我们如何能做的更好呢?其实更重要的是提升效率问题,可能用几个月来提升百分之几的准确率在学术研究上很值得,但是商业分析是不允许这种情况的。
换一个角度思考,作为一个二元问题,只有两种可能的情况下我们即使随机赋值也能达到50%的准确率,所以50%的准确率是最坏的模型性能,如果有模型的准确率比50%还低,那我们还不如扔硬币。
再进一步,如果我们简单分析一下,有1502/2224的人死亡(67.5%),那么我们粗暴的预测100%的人死亡,也会有67.5%的准确率,所以再次将68%的准确率作为最坏性能模型(可能接受的准确率下限)。
Data Science 101: How-to Create Your Own Model
接下来我们构建自己的决策树模型,作者用了我认为并不直白的语言解释了决策树:将存活于死亡分开放在两个篮子中,如果分类后的大部分样本存活了,我们就认为这个分类里所有人都存活了,反之亦然。也可能是我英语略有苦手,建议初学者还是去搜一搜决策树的相关知识才能更好的理解决策树。
但是接下来作者的论证就非常简单易懂了,他以一系列问题的方式手动构建了决策树:
Question 1: Were you on the Titanic?
如果我们假设所有人死亡,准确率为62%
Question 2: Are you male or female?
男性81%死亡,女性74%存活,准确率提升到了79%
Question 3A (going down the female branch with count = 314): Are you in class 1, 2, or 3?
若为女性,头等舱97%存活,二等舱92%存活,因为在这里死亡组的人数已经小于10了,所以决策树的分支到这里结束。接着三等舱女性的存活率为50%,没有其他信息能提升准确率了。
Question 4A (going down the female class 3 branch with count = 144): Did you embark from port C, Q, or S?
目的地提供的信息不多,C和Q大部分存活,所以我们不改变判别且子组小于10,停止分类。至于S大部分(63%)死亡,所以我们将三等舱、女性、目的地S的乘客判别为死亡,最终我们的准确率为81%
Question 5A (going down the female class 3 embarked S branch with count = 88):
到了这个分支我们的提升已经很艰难了,只能通过其他features了。发现船费0-8的旅客大部分存活,我们由此做出调整,准确率到达82%
Question 3B (going down the male branch with count = 577):
作者表示,因为绝大多数男性死亡,我们很难找出features来提升男性分支的准确率了。因此我们判定所有男性死亡,并停止分裂决策树,我们的最终准确率定在了82%
(换句话说,男性的死亡率太高了,你没法用任何一个feature将里面仅有的几个幸存者分类出来)
我们可以看到,根本没有用任何的复杂算法,仅仅靠人脑手推,我们也确定了82%的准确率!但是我们肯定不会止步于此,因此我们将82%的结果判定为‘good’,但是显然我们可以做的更好。
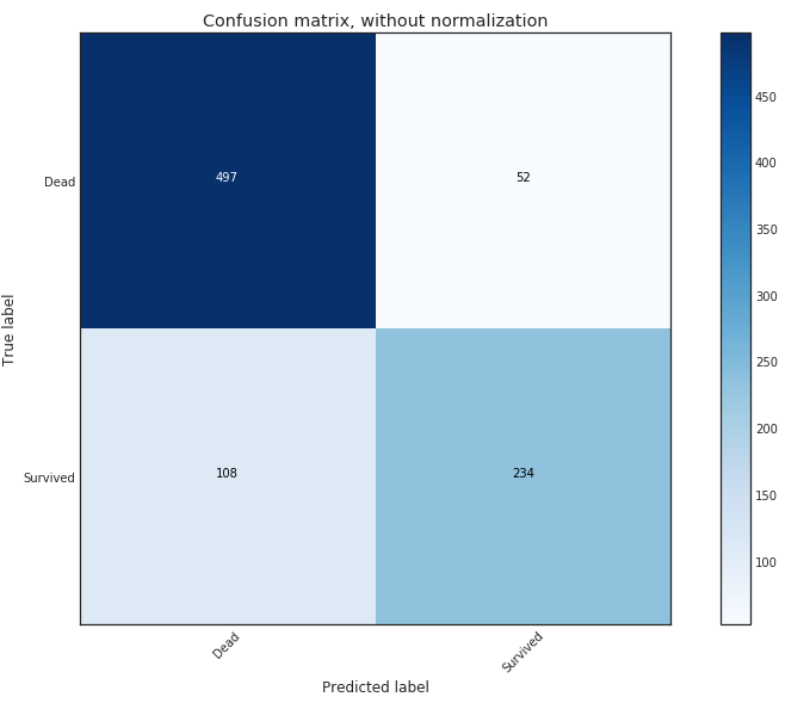
这是我们手工决策树的confusion matrix。
5.11 Model Performance with Cross-Validation (CV)
终于到了用交叉检验来验证我们的model表现了,CV最大的作用是防止过拟合,我们通过用不同的训练集分割来训练模型,这样就能避免算法在训练集上杀神斩魔,测试集上吃瘪。同时我们也可以很直观的评价我们的算法,即便有点耗费计算资源,但这肯定是值得的。
在这里我们使用决策树分类器,这是sklearn里已经给出的函数。接下来的一部分我们将通过这个例子体会超参数组合是如何影响模型准确性的。
5.12 Tune Model with Hyper-Parameters
调整超参数是训练的非常重要的一环,我们使用 ParameterGrid, GridSearchCV, customized sklearn scoring用来进行超参的选取(核心是GridSearchCV)。
GridSearchCV()函数简单来讲就是对所有可能的参数组合进行cv计算,并寻找出最佳的超参数组合,是一种暴力搜索的算法。
param_grid = {'criterion': ['gini', 'entropy'], #scoring methodology; two supported formulas for calculating information gain - default is gini
#'splitter': ['best', 'random'], #splitting methodology; two supported strategies - default is best
'max_depth': [2,4,6,8,10,None], #max depth tree can grow; default is none
#'min_samples_split': [2,5,10,.03,.05], #minimum subset size BEFORE new split (fraction is % of total); default is 2
#'min_samples_leaf': [1,5,10,.03,.05], #minimum subset size AFTER new split split (fraction is % of total); default is 1
#'max_features': [None, 'auto'], #max features to consider when performing split; default none or all
'random_state': [0] #seed or control random number generator: https://www.quora.com/What-is-seed-in-random-number-generation
}
这段代码中将所有可能的parameter储存在字典里,实际运行只使用了max_depth和criterion两个参数,我们当然可以将其他的参数也加入其中,只是会增加运行负担。

我们发现search后的结果提高了不少。
5.13 Tune Model with Feature Selection
如果我们不设前提的话,变量越多预测更准是没有问题的。但是最简单的现实问题也比理想化问题复杂,因此更多的变量并不能带来更好的模型,所以我们要选取最好的变量进行模型拟合。
此处选用feature_selection的RFECV()方法,此函数可以自动的选取最佳的特征数量和特征
其下属fit()方法进行运算,get_support()方法取得运算后的最佳参数。
这一步我们先按照上面的方法选取最佳参数,然后直接进行超参选取,最终我们得出了最佳的结果

更直观的体会这颗决策树就肯定要可视化了,我们引入graphviz,这是一个开源工具包,提供多种语言的使用库,我们用它来绘制决策树。
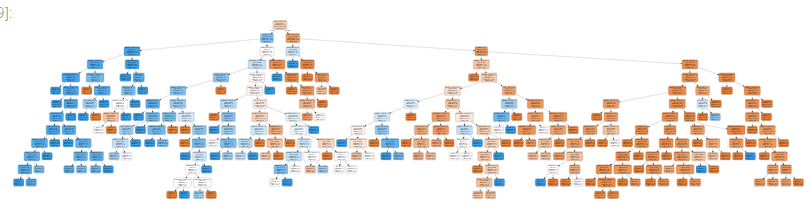
(如果在jupternotebook上绘制的话会十分巨大,其实决策树本身就已经很庞大了。)
未完待续。。
kaggle入门项目:Titanic存亡预测(四)模型拟合的更多相关文章
- kaggle入门项目:Titanic存亡预测 (一)比赛简介
自从入了数据挖掘的坑,就在不停的看视频刷书,但是总觉得实在太过抽象,在结束了coursera上Andrew Ng 教授的机器学习课程还有刷完一整本集体智慧编程后更加迷茫了,所以需要一个实践项目来扎实之 ...
- kaggle入门项目:Titanic存亡预测(二)数据处理
原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Achieve 99% Accu ...
- kaggle入门项目:Titanic存亡预测(三)数据可视化与统计分析
---恢复内容开始--- 原kaggle比赛地址:https://www.kaggle.com/c/titanic 原kernel地址:A Data Science Framework: To Ach ...
- kaggle入门题Titanic
集成开发环境:Pycharm python版本:2.7(anaconda库) 用到的库:科学计算库numpy,数据分析包pandas,画图包matplotlib,机器学习库sklearn 大体步骤分为 ...
- Kaggle入门——泰坦尼克号生还者预测
前言 这个是Kaggle比赛中泰坦尼克号生存率的分析.强烈建议在做这个比赛的时候,再看一遍电源<泰坦尼克号>,可能会给你一些启发,比如妇女儿童先上船等.所以是否获救其实并非随机,而是基于一 ...
- Kaggle入门
Kaggle入门 1:竞赛 我们将学习如何为Kaggle竞赛生成一个提交答案(submisson).Kaggle是一个你通过完成算法和全世界机器学习从业者进行竞赛的网站.如果你的算法精度是给出数据集中 ...
- Kaggle入门——使用scikit-learn解决DigitRecognition问题
Kaggle入门--使用scikit-learn解决DigitRecognition问题 @author: wepon @blog: http://blog.csdn.net/u012162613 1 ...
- Spring Cloud 入门 之 Hystrix 篇(四)
原文地址:Spring Cloud 入门 之 Hystrix 篇(四) 博客地址:http://www.extlight.com 一.前言 在微服务应用中,服务存在一定的依赖关系,如果某个目标服务调用 ...
- SpringMVC_入门项目
本项目是SpringMVC的入门项目,用于演示SpringMVC的项目配置.各层结构,功能较简单 一.Eclipse中创建maven项目 二.pom.xml添加依赖 1 2 3 4 5 6 7 8 9 ...
随机推荐
- android:padding和android:margin的区别 详解
转载请说明博客地址:http://blog.csdn.net/qq_32059827/article/details/51487997 看了网上的类似博客,并没有给出确定的区别.现在具体分析一下pad ...
- Java接口interface
Java接口interface 1.多个无关的类可以实现同一个接口. 2.一个类可以实现多个无关的接口. 3.与继承关系类似,接口与实现类之间存在多态性. 接口(interface)是抽象方法和常量值 ...
- 海量数据挖掘MMDS week4: 推荐系统之数据降维Dimensionality Reduction
http://blog.csdn.net/pipisorry/article/details/49231919 海量数据挖掘Mining Massive Datasets(MMDs) -Jure Le ...
- jsp自动编译机制
总的来说,Jasper的自动检测实现的机制比较简单,依靠某后台线程不断检测JSP文件与编译后的class文件的最后修改时间是否相同,若相同则认为没有改动,但倘若不同则需要重新编译.实际上由于在Tomc ...
- redis简单测试用例(内存不足,可以使用redis)
Redis本质上是一个Key-Value类型的内存数据库,很像memcached,听说他的性能远高于memcached,所以想自己搞个玩下.看到底有什么好处. 在windows下使用redis首先要 ...
- Git版本控制:Git分支处理
http://blog.csdn.net/pipisorry/article/details/46958699分支的意义创建分支可以避免提交代码后对主分支的影响,同时也使你有了相对独立的开发环境. 假 ...
- cygwin 下安装python MySQLdb
cygwin 下安装python MySQLdb 1) cygwin 更新 运行 cygwin/setup-x86_64.exe a 输入mysql,选择下面的包安装: libmysqlclient- ...
- Linux 内核配置机制(make menuconfig、Kconfig、makefile)讲解
前面我们介绍模块编程的时候介绍了驱动进入内核有两种方式:模块和直接编译进内核,并介绍了模块的一种编译方式--在一个独立的文件夹通过makefile配合内核源码路径完成 那么如何将驱动直接编译进内核呢? ...
- i++是否原子操作?并解释为什么???????
不是原子操作.理由: 1.i++分为三个阶段: 内存到寄存器 寄存器自增 写回内存 这三个阶段中间都可以被中断分离开. 2.++i首先要看编译器是怎么编译的, 某些编译器比如VC在非优化版本中会编译 ...
- 修改Tomcat访问的端口号
修改Tomcat端口号步骤: 1.找到Tomcat目录下的conf文件夹 2.进入conf文件夹里面找到server.xml文件 3.打开server.xml文件 4.在server.xml文件里面找 ...