转 Caffe学习系列(4):激活层(Activiation Layers)及参数
在激活层中,对输入数据进行激活操作(实际上就是一种函数变换),是逐元素进行运算的。从bottom得到一个blob数据输入,运算后,从top输入一个blob数据。在运算过程中,没有改变数据的大小,即输入和输出的数据大小是相等的。
输入:n*c*h*w
输出:n*c*h*w
常用的激活函数有sigmoid, tanh,relu等,下面分别介绍。
1、Sigmoid
对每个输入数据,利用sigmoid函数执行操作。这种层设置比较简单,没有额外的参数。
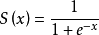
层类型:Sigmoid
示例:
layer {
name: "encode1neuron"
bottom: "encode1"
top: "encode1neuron"
type: "Sigmoid"
}
2、ReLU / Rectified-Linear and Leaky-ReLU
ReLU是目前使用最多的激活函数,主要因为其收敛更快,并且能保持同样效果。
标准的ReLU函数为max(x, 0),当x>0时,输出x; 当x<=0时,输出0
f(x)=max(x,0)
层类型:ReLU
可选参数:
negative_slope:默认为0. 对标准的ReLU函数进行变化,如果设置了这个值,那么数据为负数时,就不再设置为0,而是用原始数据乘以negative_slope
layer {
name: "relu1"
type: "ReLU"
bottom: "pool1"
top: "pool1"
}
RELU层支持in-place计算,这意味着bottom的输出和输入相同以避免内存的消耗。
3、TanH / Hyperbolic Tangent
利用双曲正切函数对数据进行变换。
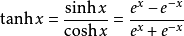
层类型:TanH
layer {
name: "layer"
bottom: "in"
top: "out"
type: "TanH"
}
4、Absolute Value
求每个输入数据的绝对值。
f(x)=Abs(x)
层类型:AbsVal
layer {
name: "layer"
bottom: "in"
top: "out"
type: "AbsVal"
}
5、Power
对每个输入数据进行幂运算
f(x)= (shift + scale * x) ^ power
层类型:Power
可选参数:
power: 默认为1
scale: 默认为1
shift: 默认为0

layer {
name: "layer"
bottom: "in"
top: "out"
type: "Power"
power_param {
power: 2
scale: 1
shift: 0
}
}
6、BNLL
binomial normal log likelihood的简称
f(x)=log(1 + exp(x))
层类型:BNLL
layer {
name: "layer"
bottom: "in"
top: "out"
type: “BNLL”
}
转 Caffe学习系列(4):激活层(Activiation Layers)及参数的更多相关文章
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化. 如果还没有学会的,请自行细细阅读: caffe学习系列:http:/ ...
随机推荐
- IO (三)
1 转换流 1.1 InputStreamReader 1.1.1 InputStreamReader简介 InputStreamReader是字节流通向字符流的桥梁.它使用指定的charset读取字 ...
- awk匹配以aaa开头,以bbb结尾的内容,同时aaa和bbb之间还包含ccc
如果是匹配以A开头,以B结尾的内容,同时A和B之间还包含C的这种怎么做?比如 [root@localhost ~]#cat file aaa grge ddd bbb aaa gege ccc bbb ...
- Git 2.0 更改 push default
近期更新了git,项目push时会提示这样的信息: warning: push.default 尚未设置,它的默认值在 Git 2.0 已从 'matching' 变更为 'simple'.若要不再显 ...
- 前端通过Nginx反向代理解决跨域问题
在前面写的一篇文章SpringMVC 跨域,我们探讨了什么是跨域问题以及SpringMVC怎么解决跨域问题,解决方式主要有如下三种方式: JSONP CORS WebSocket 可是这几种方式都是基 ...
- 关键字voltale
***volatile在多线程用的最多.*** #include<stdio.h> #include<stdlib.h> int main() { ; i < ; i++ ...
- c#基础(一)
一. C#与.Net的关系 C#是一种相当新的编程语言.C#的重要性体现在以下两个方法: 1).它是专门为Microsoft的.net FrameWork一起使用而设计的 (.net FrameWor ...
- Animations and transitions
在交互式可视化中,有一个词叫reactive,指的是以可视化的方式来响应用户的行为,帮助用户进行可视化并理解其结果.这个很有用.那如何来实现这种交互呢?通过动画. 如果处理得当,动画可以展现出不错的可 ...
- Springboot security cas整合方案-原理篇
前言:网络中关于Spring security整合cas的方案有很多例,对于Springboot security整合cas方案则比较少,且有些仿制下来运行也有些错误,所以博主在此篇详细的分析cas原 ...
- json和xml的两者区别
服务器端返回给客户端的数据一般都是JSON格式,JSON数据以键值的形式保存,数据之间以逗号分隔,{}表示对象,[]表示数组.JSON数据解析方案有四种,JSONKit,SBJson,TouchJso ...
- BZOJ 3544: [ONTAK2010]Creative Accounting [set]
给定一个长度为N的数组a和M,求一个区间[l,r],使得$(\sum_{i=l}^{r}{a_i}) mod M$的值最大,求出这个值,注意这里的mod是数学上的mod 这道题真好,题面连LaTeX都 ...