项目实战14—ELK 企业内部日志分析系统
本文收录在Linux运维企业架构实战系列
一、els、elk 的介绍
1、els,elk
els:ElasticSearch,Logstash,Kibana,Beats
elk:ElasticSearch,Logstash,Kibana
① ElasticSearch 搜索引擎
ElasticSearch 是一个基于Lucene的搜索引擎,提供索引,搜索功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
② Logstash 接收,处理,转发日志的工具
Logstash 是一个开源的服务器端数据处理流水线,它可以同时从多个数据源获取数据,并将其转换为最喜欢的"存储"(Ours is Elasticsearch, naturally.)
③ Beats:采集日志信息(加上beats 就是els),GO开发的,所以高效、很快
Filebeat:Log Files
Metricbeat:Metrics
Packetbeat:Network Data
Winlogbeat:Windows Event Logs
Heartbeat:Uptime Monitoring
④ Kibana:独立的、美观的图形数据展示界面
Kibana 让你可视化你的Elasticsearch数据并导航Elastic Stack,所以你可以做任何事情,从凌晨2:00分析为什么你得到分页,了解雨水可能对你的季度数字造成的影响。
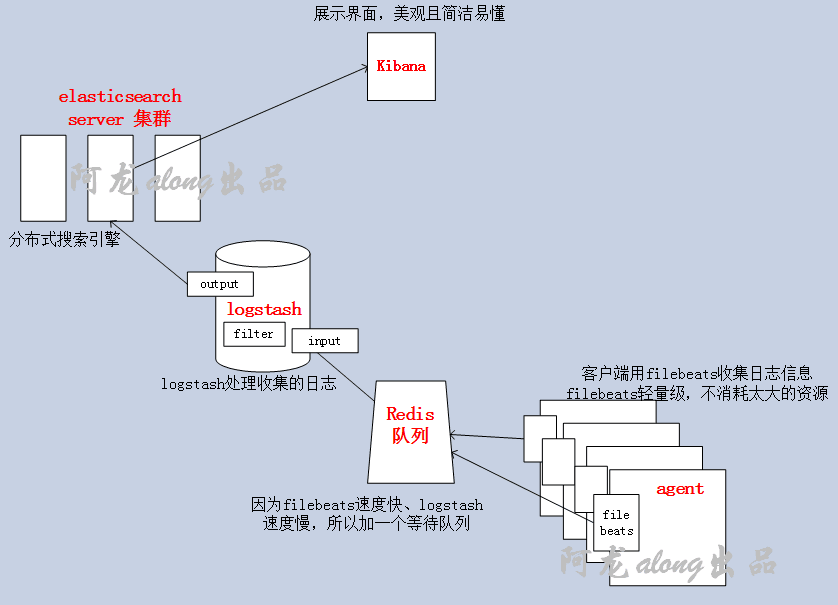
2、实验前准备
实验所需要的包(我用的是5.5.1版本),都放在我的网盘里了,需要的私聊 https://pan.baidu.com/s/1c2An0Co
① 环境准备
|
机器名称 |
IP配置 |
服务角色 |
|
els |
192.168.1.101(私) 192.168.10.101(公) |
elasticsearch(搜索引擎) |
|
logstash |
192.168.1.102(私) 192.168.10.102(公) |
logstash(日志处理) redis(缓冲队列) |
|
filebeat |
192.168.1.103(私) 192.168.10.103(公) |
filebeat(日志收集) httpd/mysql(生成日志) |
|
kibana |
192.168.1.104(私) 192.168.10.104(公) |
kibana(展示界面) |
② 修改主机名、hosts文件,确保节点直接能通过主机名连通
[root@els ~]# hostnamectl set-hostname els.along.com
[root@logstash ~]# hostnamectl set-hostname logstash.along.com
[root@filebeat ~]# hostnamectl set-hostname filebeat.along.com
[root@kibana ~]# hostnamectl set-hostname kibana.along.com
centos7 修改主机名:
[root@els ~]# hostnamectl set-hostname 主机名
③ 修改hosts
[root@els ~]# vim /etc/hosts
192.168.1.101 els.along.com
192.168.1.102 logstash.along.com
192.168.1.103 filebeat.along.com
192.168.1.104 kibana.along.com
互相测试
[root@els ~]# ping filebeat.along.com
④ 关闭防火墙、selinux
[root@els ~]# iptables -F
[root@els ~]# setenforce 0
⑤ 同步时间
[root@els ~]# systemctl restart chronyd
二、安装搭建elasticsearch 和head 插件
1、安装elasticsearch
Elasticsearch 是一个分布式的 RESTful 风格的搜索和数据分析引擎,能够解决不断涌现出的各种用例。作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况
(1)官网下载,各种版本
(2)安装java 环境
安装JDK,至少1.8 以上的版本
因为是java 语言编写的,需安装JDK
[root@els ~]# yum install java-1.8.0-openjdk-devel -y
(3)安装els
在网上找自己需要的版本,我下好了5.5.1 版本,在网盘里
[root@els ~]# rpm -ivh elasticsearch-5.5.1.rpm
2、配置elasticsearch
(1)修改JVM 的配置
[root@els ~]# vim /etc/elasticsearch/jvm.options 修改分配的空间大小
-Xms1g #初始化大小
-Xmx1g #最大大小
注意:不要超过32G,如果空间大,多跑几个实例,不要让一个实例太大内存
生产环境,建议都给32;为了实验方便,我直接改成了1g
(2)配置els
[root@els ~]# vim /etc/elasticsearch/elasticsearch.yml
- cluster.name: alongels #集群名字
- node.name: els #节点名
- path.data: /els/data #索引路径
- path.logs: /els/logs #日志存储路径
- network.host: 192.168.10.101 #对外通信的地址,依次修改为自己机器对外的IP
- #http.port: #默认端口
(3)创建出所需的路径,并修改权限
[root@els ~]# mkdir -pv /els/{data,logs} && chown -R elasticsearch.elasticsearch /els/*
(4)开启服务
[root@els ~]# systemctl start elasticsearch.service
(5)测试elasticsearch
① 开启服务,会打开9200 端口
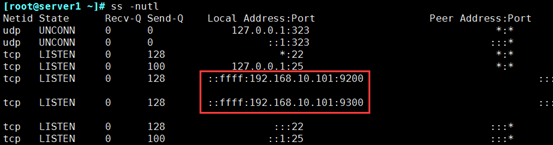
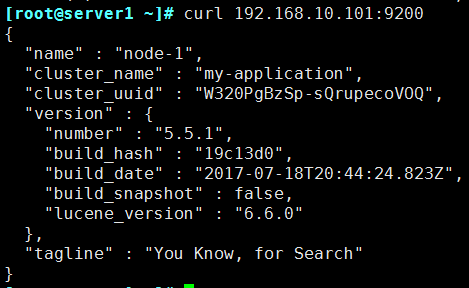
② [root@els ~]# curl 192.168.10.101:9200
3、搭建elasticsearch 集群(自己选择)
我因机器缺少,所以没有做集群;若机器够用,建议做集群
(1)配置els
[root@els ~]# vim /etc/elasticsearch/elasticsearch.yml
- cluster.name: alongels #集群名字
- node.name: els #节点名,依次修改为els2,els3
- path.data: /els/data #索引路径
- path.logs: /els/logs #日志存储路径
- network.host: 192.168.10.101 #对外通信的地址,依次修改为自己机器对外的IP
- #http.port: #默认端口
- discovery.zen.ping.unicast.hosts: ["els", "els2","els3"] #发现方式,采用单播
- discovery.zen.minimum_master_nodes: #数量要大于集群中节点的半数
(2)创建出所需的路径,并修改权限
[root@els ~]# mkdir -pv /els/{data,logs} && chown -R elasticsearch.elasticsearch /els/*
[root@els2 ~]# mkdir -pv /els/{data,logs} && chown -R elasticsearch.elasticsearch /els/*
[root@els3 ~]# mkdir -pv /els/{data,logs} && chown -R elasticsearch.elasticsearch /els/*
(3)开启3个节点的服务
[root@els3 ~]# systemctl start elasticsearch.service
4、安装elasticsearch 的head插件(Web前端)
https://github.com/mobz/elasticsearch-head 这里有github上的详细步骤
(1)安装head 插件
① 下载git 环境
[root@els ~]$ cd /usr/local/
[root@els local]$ yum -y install git
② git 克隆
[root@els local]$ git clone git://github.com/mobz/elasticsearch-head.git
[root@els local]$ cd elasticsearch-head/
③ 安装npm 包
[root@els elasticsearch-head]$ yum -y install npm
④ 安装npm 的各种模块
[root@els elasticsearch-head]$ npm install
注意:需连网,安装需一段时间
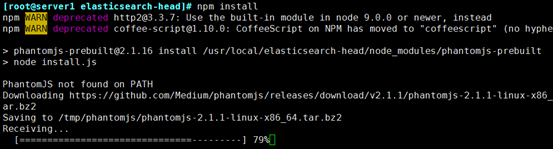
⑤ 中间会出错,提示解压一个包失败,手动解开就好
Error: Command failed: tar jxf /tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2
解决办法:
bunzip2 /tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar.bz2
tar -xvf /tmp/phantomjs/phantomjs-2.1.1-linux-x86_64.tar
再次执行[root@els elasticsearch-head]$ npm install
成功

(2)再次修改配置文件,在最后加一个配置段
[root@els ~]$ vim /etc/elasticsearch/elasticsearch.yml
- # ------------------------ Enable CORS in elasticsearch -------------------------
- http.cors.enabled: true
- http.cors.allow-origin: "*" #授所有权限
(3)运行head
① 重启elasticsearch 服务,打开了9100 端口
[root@els ~]$ service elasticsearch restart
② 启动head
[root@els ~]# cd /usr/local/elasticsearch-head/
[root@els elasticsearch-head]# npm run start 前端运行
[root@els elasticsearch-head]# nohup npm run start & 后台运行
[root@els elasticsearch-head]# jobs 查看后台运行的任务
[1]+ Running nohup npm run start &
5、测试elasticsearch-head
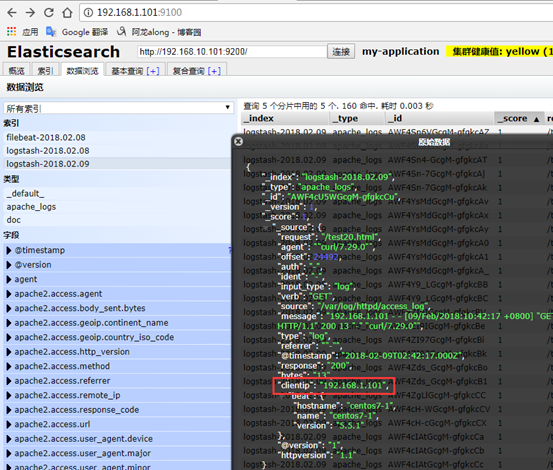
网页访问http://192.168.1.101:9100/
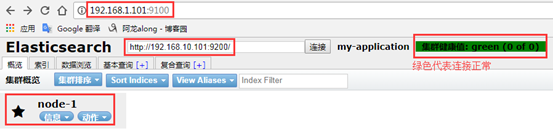
6、elasticsearch-head 的全功能文本搜索引擎库:lucene
https://lucene.apache.org/core/ 下载地址
Apache Lucene 是一个完全用Java编写的高性能,全功能的文本搜索引擎库。它几乎适用于任何需要全文搜索的应用程序,特别是跨平台的应用程序。
有经典的查询分析器语法结构,根据自己需要安装。
三、安装介绍logstash
1、介绍
(1)定义
查看官方文档 https://www.elastic.co/cn/products/logstash
① 官方介绍:Logstash is an open source data collection engine with real-time pipelining capabilities。简单来说logstash就是一根具备实时数据传输能力的管道,负责将数据信息从管道的输入端传输到管道的输出端;与此同时这根管道还可以让你根据自己的需求在中间加上滤网,Logstash提供里很多功能强大的滤网以满足你的各种应用场景。
② Logstash的事件(logstash将数据流中等每一条数据称之为一个event)处理流水线有三个主要角色完成:inputs –> filters –> outputs:
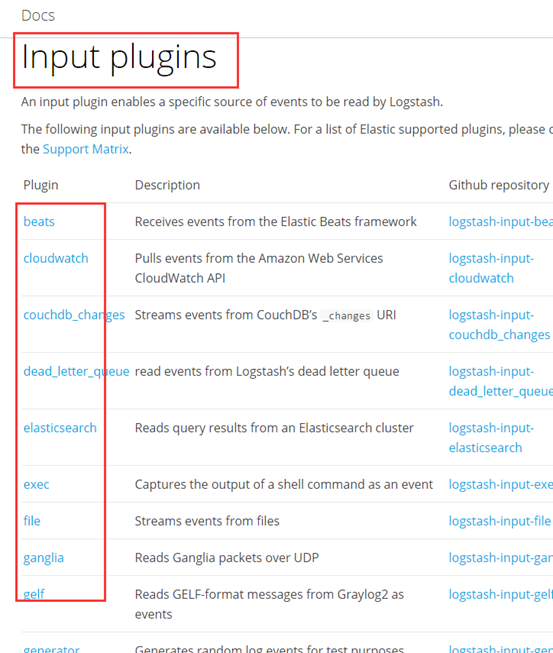
- inpust:必须,负责产生事件(Inputs generate events),常用:File、syslog、redis、beats(如:Filebeats)
- filters:可选,负责数据处理与转换(filters modify them),常用:grok、mutate、drop、clone、geoip
- outpus:必须,负责数据输出(outputs ship them elsewhere),常用:elasticsearch、file、graphite、statsd
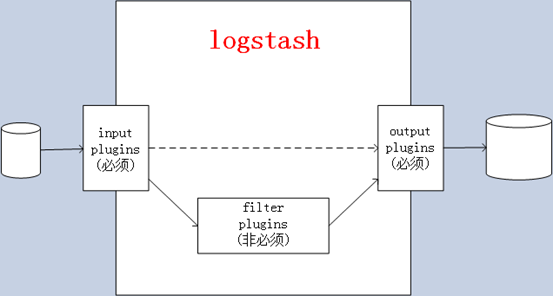
(2)有自己的搜索模式,事先定义好的
所谓的搜索模式就是像变量一样,把用的较多的事先定义好,便于多次引用
[root@centos7-1 conf.d]# rpm -ql logstash |grep pattern
[root@centos7-1 conf.d]# less /usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns/grok-patterns
/usr/share/logstash/vendor/bundle/jruby/1.9/gems/logstash-patterns-core-4.1.1/patterns
例如:httpd 的搜索模式
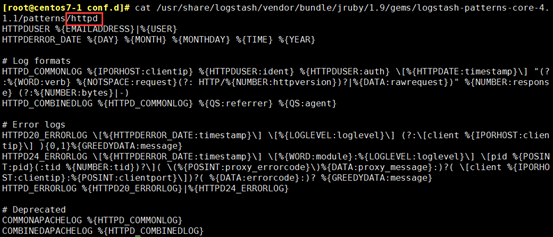
(3)文档,有较详细的用法介绍
选择对应版本
① input
② filter
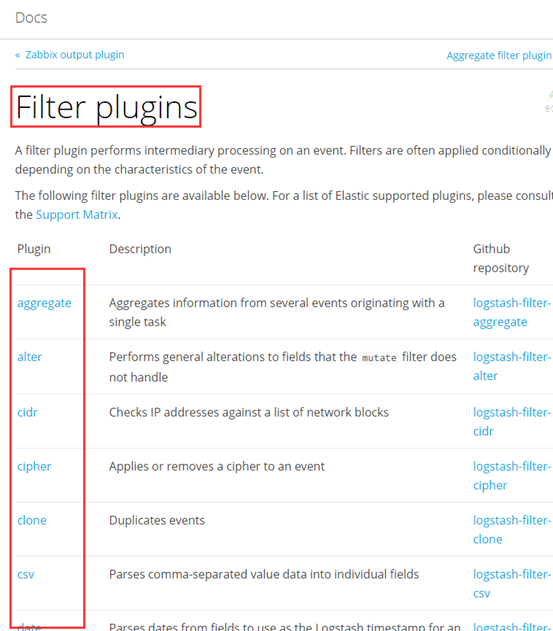
③ output
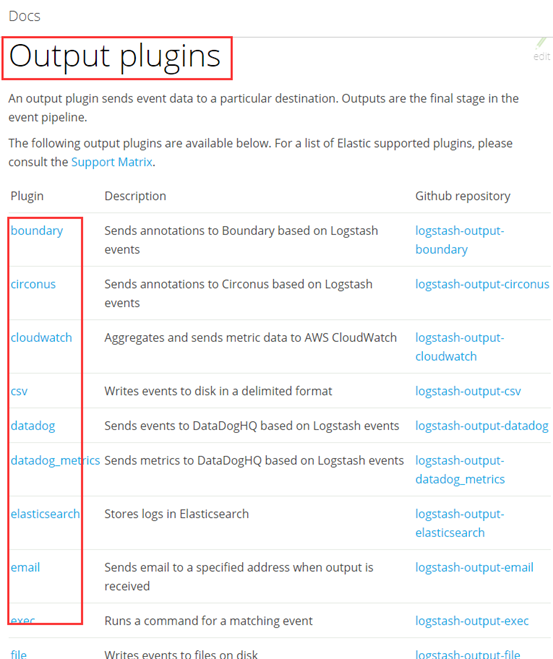
2、下载安装
① 去官网下载对应版本的logstash ,我下载的是5.5.1版本
https://www.elastic.co/cn/downloads/logstash
[root@centos7-1 els]# rpm -ivh logstash-5.5.1.rpm
② 修改环境变量,可以直接使用logstash 命令
[root@centos7-1 els]# vim /etc/profile.d/logstash.sh
- export PATH=$PATH:/usr/share/logstash/bin/
[root@centos7-1 els]# . /etc/profile.d/logstash.sh
四、logstash 演示用法
进入自配置文件的目录
[root@centos7-1 logstash]# cd /etc/logstash/conf.d/
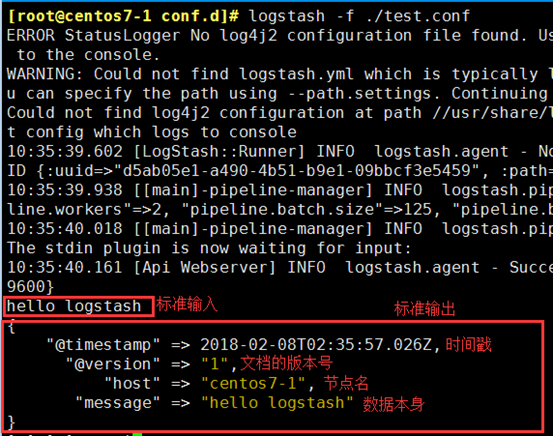
1、示例1:标准输入输出
input => 标准输入
filter => 无
output => 标准输出
① 编辑配置文件
[root@centos7-1 conf.d]# vim test.conf
- input {
- stdin {}
- }
- output {
- stdout {
- codec => rubydebug
- }
- }
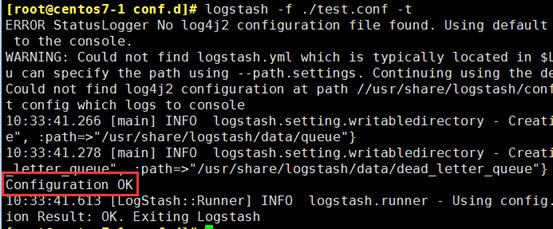
② -t 测试语法,这个命令级慢
[root@centos7-1 conf.d]# logstash -f ./test.conf -t
③ 执行
[root@centos7-1 conf.d]# logstash -f ./test.conf
2、示例2:从文件输入数据,经grok 拆分插件过滤之后输出至标准输出
input => 文件输入
filter => grok、date 模块
grok:拆分字段
date:修改时间格式
output => 标准输出
(1)事前准备,生成日志
① 下载开启httpd 服务
[root@centos7-1 ~]# yum install httpd
[root@centos7-1 ~]# systemctl start httpd
② 生成一个主页
[root@centos7-1 ~]# vim /var/www/html/index.html
Home Page
③ 生成20个测试页面
[root@centos7-1 ~]# for i in {1..20}; do echo "Test Page ${i}" > /var/www/html/test${i}.html; done

④ 测试页面正常访问

⑤ 循环生成httpd 日志
[root@centos7-1 ~]# for i in {1..200}; do j=$[$RANDOM%20+1]; curl http://192.168.1.102:80/test${j}.html; done
(2)编辑配置文件
[root@centos7-1 conf.d]# vim test2.conf
- input {
- file {
- path => ["/etc/httpd/logs/access_log"]
- start_position => "beginning"
- }
- filter {
- grok { #拆分message 字段
- match => { #指定匹配哪个字段
- "message" => "%{COMBINEDAPACHELOG}" #引用定义好的搜索模式
- }
- remove_field => "message" #删除message 字段
- }
- date { #改变时间格式
- match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
- remove_field => "timestamp" #删除原有的时间字段
- }
- }
- output {
- stdout {
- codec => rubydebug
- }
- }
(3)执行
[root@centos7-1 conf.d]# logstash -f test2.conf -t
[root@centos7-1 conf.d]# logstash -f test2.conf
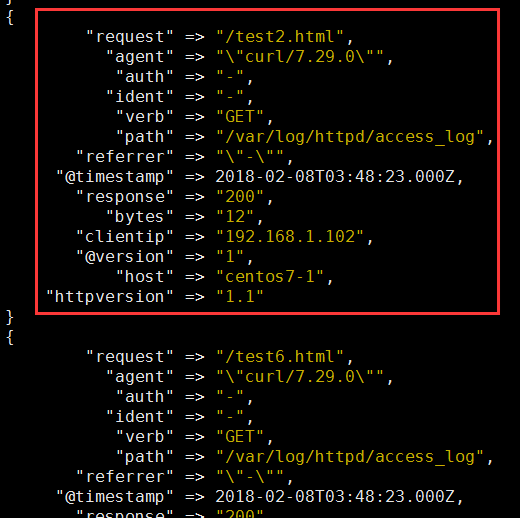
3、示例3:filter 的date、mutate 插件
input => 标准输入
filter => date、mutate 模块
mutate:修改字段
output => 标准输出
① 编辑配置文件,由于input、output还是标准输入输出,就没有贴出
[root@centos7-1 conf.d]# vim test3.conf
- filter {
- grok {
- match => {
- "message" => "%{HTTPD_COMBINEDLOG}"
- }
- }
- date {
- match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
- }
- mutate {
- rename => {
- "agent" => "user_agent"
- }
- }
- }
② 执行
[root@centos7-1 conf.d]# logstash -f test3.conf -t
[root@centos7-1 conf.d]# logstash -f test3.conf
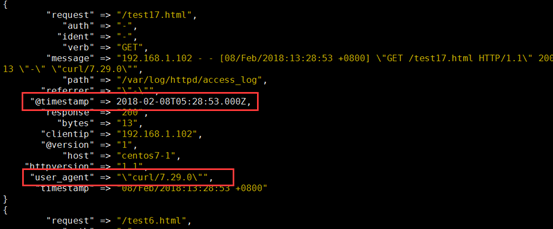
4、示例4:filter 的geoip 模块
input => 标准输入
filter => geoip 模块
geoip:利用这个模块解析ip的地址,利于后边kibana 的地理位置展示图
output => 标准输出
(1)准备ip 数据库
网上下载数据库,因为是记录世界的IP 地址,所以经常有变动,可以写一个计划任务,每隔一周去网上下载一次,解包,链接到maxmind 下
[root@centos7-1]# tar -xvf GeoLite2-City.tar.gz
[root@centos7-1]# mv GeoLite2-City_20170704/ /etc/logstash/
[root@centos7-1 logstash]# mv GeoLite2-City_20170704/ maxmind
(2)模拟一个公网ip 访问
[root@centos7-1 ~]# echo '112.168.1.102 - - [08/Feb/2018:15:28:53 +0800] "GET /test6.html HTTP/1.1" 200 12 "-" "curl/7.29.0"' >> /var/log/httpd/access_log
(3)执行
① 编辑配置文件,由于input、output还是标准输入输出,就没有贴出
[root@centos7-1 conf.d]# vim tes4.conf
- filter {
- grok {
- match => {
- "message" => "%{HTTPD_COMBINEDLOG}"
- }
- }
- geoip {
- source => "clientip" #哪个源ip 字段,转换为地理位置
- target => "geoip" #目标信息存储时的健名
- database => "/etc/logstash/maxmind/GeoLite2-City.mmdb" #数据库路径
- }
- }
② 执行
[root@centos7-1 conf.d]# logstash -f test4.conf -t
[root@centos7-1 conf.d]# logstash -f test4.conf
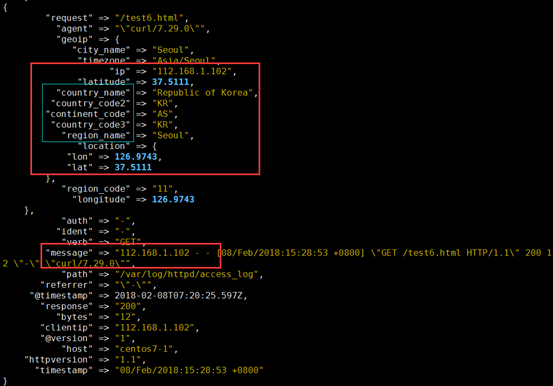
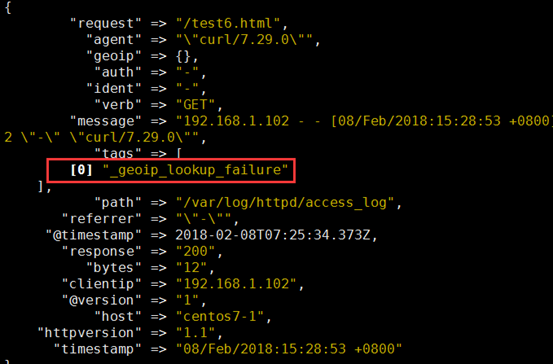
③ 如果是内网地址,会显示失败
[root@centos7-1 ~]# echo '192.168.1.102 - - [08/Feb/2018:15:28:53 +0800] "GET /test6.html HTTP/1.1" 200 12 "-" "curl/7.29.0"' >> /var/log/httpd/access_log
5、示例5:output 输出给elasticsearch
input => 来自httpd 的访问日志
filter => geoip 模块
output => 输出给elasticsearch
(1)执行
① 编辑配置文件
[root@centos7-1 conf.d]# vim test5.conf
- input {
- file {
- path => ["/var/log/httpd/access_log"]
- start_position => "beginning"
- }
- }
- filter {
- grok {
- match => {
- "message" => "%{HTTPD_COMBINEDLOG}"
- }
- }
- geoip {
- source => "clientip"
- target => "geoip"
- database => "/etc/logstash/maxmind/GeoLite2-City.mmdb"
- }
- }
- output {
- elasticsearch {
- hosts => ["http://192.168.10.101:9200/"] #主机
- index => "logstash-%{+YYYY.MM.dd}" #索引
- document_type => "apache_logs" #文档类型标识,自己定义
- }
- }
② 执行
logstash -f test5.conf
(2)验证
① 网页登录到elasticsearch,可以查看到
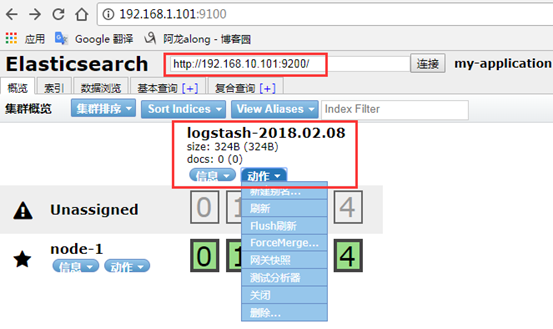
② 搜索查询的演示
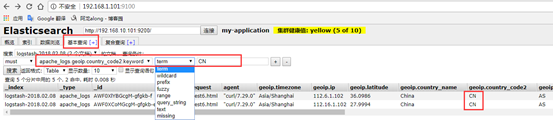
(a)基于2个字段CN 的搜索
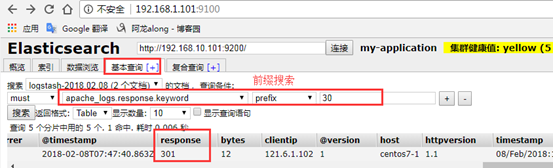
(b)响应码前缀搜索
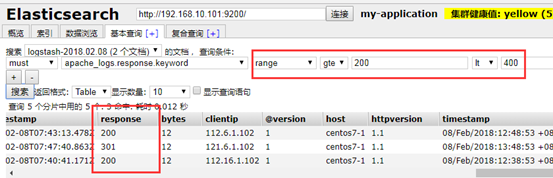
(c)范围搜索
6、示例6:output 输出给redis
input => 来自httpd 的访问日志
filter => geoip 模块
output => 输出给redis
(1)准备redis 服务
[root@logstash]# vim /etc/redis.conf
bind 0.0.0.0 #监听所有端口
requirepass ilinux.io #加密码,为了安全运行
其他一些优化配置:
① 只做队列,没必要持久存储,性能更好
② 把内存的淘汰策略关掉
③ 把内存空间最大,调大一点
④ 把所有持久化功能关掉:AOF 快照
开启redis
[root@centos7-1 conf.d]# systemctl start redis 打开6379 端口
(2)运行logstash
① 配置文件
[root@centos7-1 conf.d]# vim test6.conf
- output {
- redis {
- batch => true #批量写入
- host => "192.168.10.102" #主机
- password => "ilinux.io" #密码
- port => 6379 #端口
- #db => 0 #默认就是0号库
- data_type => "list" #数据格式,列表
- key => "apachelogs" #自己定义的键
- }
- }
② [root@logstash]# logstash -f test6.conf
(3)测试
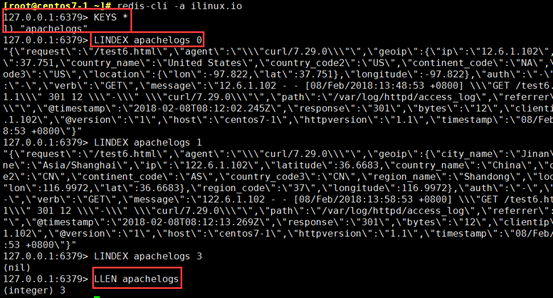
[root@centos7-1 ~]# redis-cli -a ilinux.io
127.0.0.1:6379> KEYS *
127.0.0.1:6379> LLEN apachelogs
127.0.0.1:6379> LINDEX apachelogs 1
(4)注:logstash 开启的方法:
① logstash 指令指定配置文件启动
logstash -f test.conf
② systemctl start logstash 命令启动
此命令启动,要确保/etc/logstash/conf.d 目录下没有其他多余的配置文件。
五、Beats 轻量型数据采集器
Beats 平台集合了多种单一用途数据采集器。这些采集器安装后可用作轻量型代理,从成百上千或成千上万台机器向 Logstash 或 Elasticsearch 发送数据。

1、下载
去官网下载对应版本
[root@centos7-1 ~]# rpm -ivh filebeat-5.5.1-x86_64.rpm
2、示例1:配置filebeats,目标elasticsearch
源 => 本机httpd 的日志
目标 => 直接给elasticsearch
(1)配置文件
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
- #================= Filebeat prospectors =====================
- filebeat.prospectors:
- paths:
- - /var/log/httpd/*log
- #exclude_lines: ["^DBG"] 黑名单
- #include_lines: ["^ERR", "^WARN"] 白名单
- #-------------------------- Elasticsearch output ------------------------------
- output.elasticsearch:
- # Array of hosts to connect to.
- hosts: ["192.168.10.101:9200"] #主机和端口
- #protocol: "https" #如果是https
- #username: "elastic" #用户,如果elasticsearch设置的有的话
- #password: "changeme" #密码
(2)启动服务
[root@centos7-1 filebeat]# systemctl start filebeat.service
(3)生成httpd 日志
① 下载开启httpd 服务
[root@centos7-1 ~]# yum install httpd
[root@centos7-1 ~]# systemctl start httpd
② 生成一个主页
[root@centos7-1 ~]# vim /var/www/html/index.html
Home Page
③ 生成20个测试页面
[root@centos7-1 ~]# for i in {1..20}; do echo "Test Page ${i}" > /var/www/html/test${i}.html; done

④ 测试页面正常访问

⑤ 循环生成httpd 日志
[root@centos7-1 ~]# for i in {1..20}; do j=$[$RANDOM%20+1]; curl http://192.168.1.102:80/test${j}.html; done
(4)测试
直接访问elasticsearch 页面,可以查看到
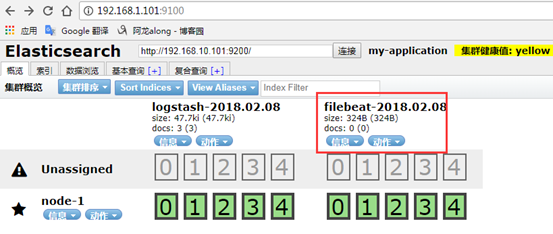
3、示例2:完整的ELK —> 配置filebeat,目标给logstash
(1)配置filebeat
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
- filebeat.prospectors:
- - input_type: log
- paths:
- - /var/log/httpd/*log
- output.logstash:
- hosts: ["192.168.10.102:5044"]
启动服务
[root@centos7-1 filebeat]# systemctl start filebeat.service
(2)在logstash 服务器上配置
input => 来自filebeat
filter => geoip 模块
output => 输出给elasticsearch
① 配置
[root@logstash conf.d]# vim /etc/logstash/conf.d/apachelogs.conf
- input {
- beats {
- port => 5044
- }
- }
- filter {
- grok {
- match => {
- "message" => "%{HTTPD_COMBINEDLOG}"
- }
- }
- }
- output {
- elasticsearch {
- hosts => ["http://192.168.10.101:9200/"]
- index => "logstash-%{+YYYY.MM.dd}"
- document_type => "apache_logs"
- }
- }
② 运行logstash
[root@centos7-1 conf.d]# logstash -f apachelogs.conf -t 测试
重启filebeat
[root@centos7-1 filebeat]# systemctl restart filebeat.service
(3)测试
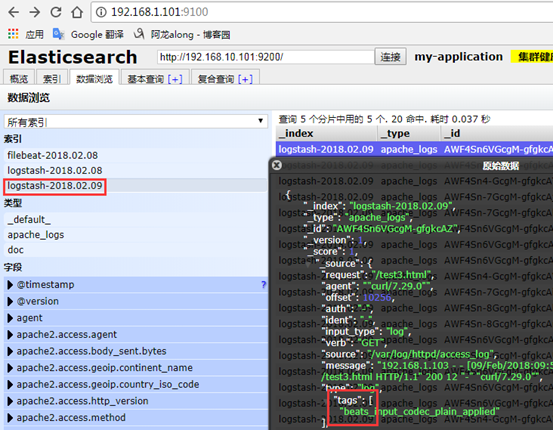
4、示例3:完整的els搭建
(1)配置filebeat,目标给redis
[root@filebeat ~]# vim /etc/filebeat/filebeat.yml
- filebeat.prospectors:
- - input_type: log
- paths:
- - /var/log/httpd/*log
- #----------------------------- Redis output --------------------------------
- output.redis:
- hosts: ["192.168.10.102"]
- password: "ilinux.io"
- key: "httpdlogs"
- datatype: "list"
- db: 0
- timeout: 5
(2)redis 服务器查询测试
[root@centos7-1 conf.d]# redis-cli -a ilinux.io 查询有key值,有数据
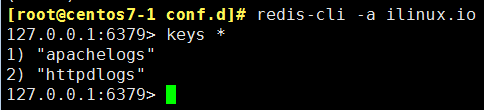
(3)配置logstash
input => 来自redis
filter => geoip 模块
output => 输出给elasticsearch
① 配置
[root@logstash conf.d]# vim /etc/logstash/conf.d/apachelogs.conf
- input {
- redis {
- host => "192.168.10.102"
- port => ""
- password => "ilinux.io"
- data_type => "list"
- key => "httpdlogs"
- threads => 2
- }
- }
- filter {
- grok {
- match => {
- "message" => "%{HTTPD_COMBINEDLOG}"
- }
- }
- date {
- match => ["timestamp","dd/MMM/YYYY:H:m:s Z"]
- remove_field => "timestamp"
- }
- }
- output {
- elasticsearch {
- hosts => ["http://192.168.10.101:9200/"]
- index => "logstash-%{+YYYY.MM.dd}"
- document_type => "apache_logs"
- }
- }
② 启动logstash
[root@filebeat ~]# systemctl start logstash
(4)用192.168.1.101 机器生成访问日志,测试
六、kibana
1、介绍
kibana 是您走进 Elastic Stack 的窗口,Kibana 让您能够可视化 Elasticsearch 中的数据并操作Elastic Stack,因此您可以在这里解开任何疑问:例如,为何会在凌晨 2:00 被传呼,雨水会对季度数据造成怎样的影响。
① 一张图片胜过千万行日志
Kibana 让您能够自由地选择如何呈现您的数据。或许您一开始并不知道自己想要什么。不过借助Kibana 的交互式可视化,您可以先从一个问题出发,看看能够从中发现些什么。
② 从基础入手
Kibana 核心搭载了一批经典功能:柱状图、线状图、饼图、环形图,等等。它们充分利用了Elasticsearch 的聚合功能。
③ 将地理数据融入任何地图
利用我们的 Elastic Maps Services 来实现地理空间数据的可视化,或者发挥创意,在您自己的地图上实现自定义位置数据的可视化。
④ 时间序列也在菜单之列
您可以利用 Timelion,对您 Elasticsearch 中的数据执行高级时间序列分析。您可以利用功能强大、简单易学的表达式来描述查询、转换和可视化。
⑤ 利用 graph 功能探索关系
凭借搜索引擎的相关性功能,结合 graph 探索,揭示您 Elasticsearch 数据中极其常见的关系。
2、安装搭建
(1)安装
从官网上下载对应的版本https://www.elastic.co/cn/downloads/kibana
[root@kibana ~]#rpm -ivh kibana-5.5.1-x86_64.rpm
(2)配置
vim /etc/kibana/kibana.yml
- server.port: 5601
- server.host: "0.0.0.0"
- server.name: "kibana.along.com"
- elasticsearch.url: "http://192.168.10.101:9200"
(3)开启服务
[root@kibana ~]# systemctl start kibana.service
3、配置使用kibana
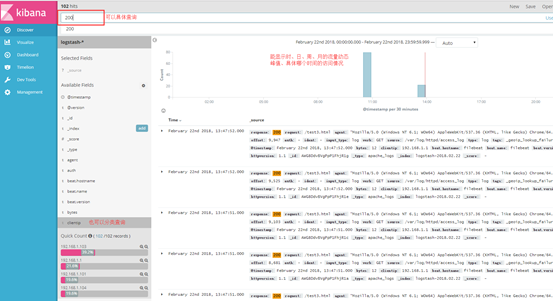
(1)打开网页 http://192.168.1.104:5601,选择logstash 发送的日志,就直接显示效果了
(2)设置效果展示图
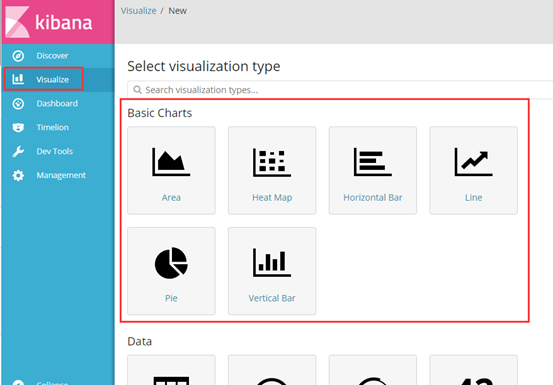
① 可以创建各种图形,面积图,线装图,饼状图......
我以饼状图为例,创建top5 来源ip、top10 请求点击页面 的饼状图
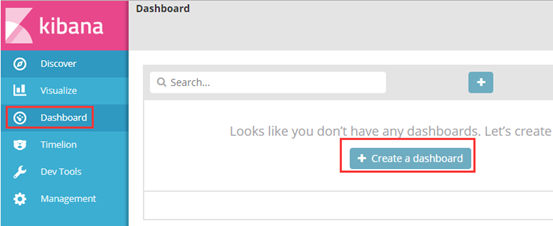
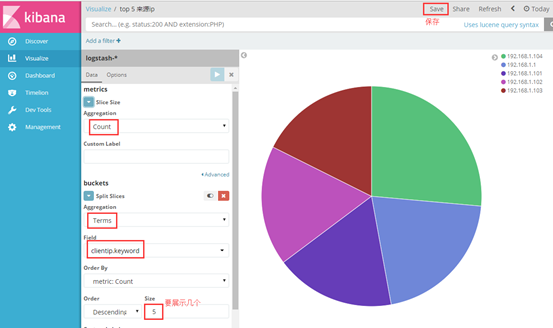
② 做出top5 来源ip 的饼状图
选择对什么进行聚合图形,我选择对自己设置的terms 词条进行聚合,再选择clientip.keyword 的key键值,最后展示
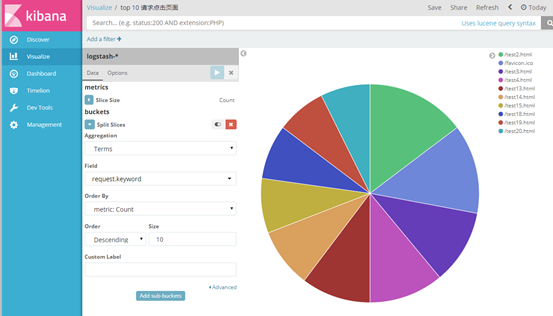
③ 同理,做出top10 请求点击页面的饼状图
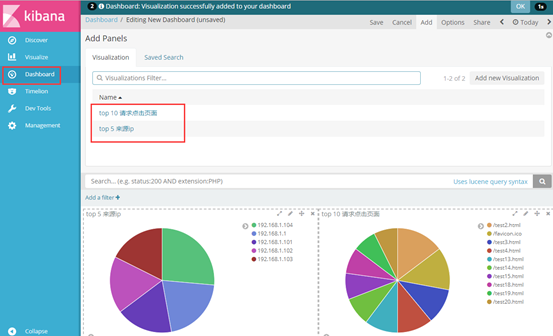
④ 可以将多个图形呈现在一个仪表盘上
点击仪表盘,添加所需要展示的图形即可
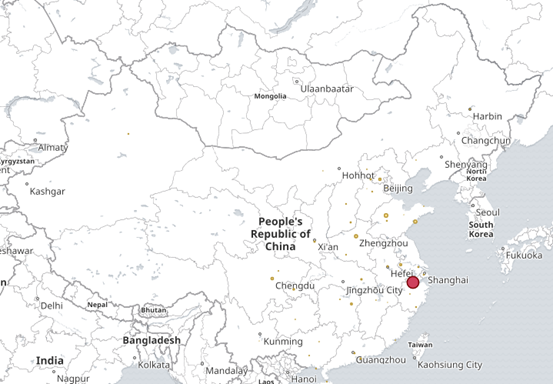
⑤ 根据ip 显示地理位置
(3)其他字段都可进行设置,多种图案,也可将多个图形放在一起展示
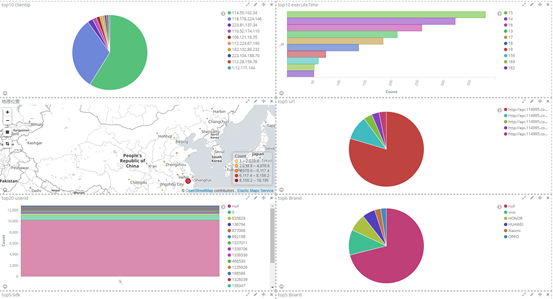
4、kibana 用法详解
可参考http://blog.csdn.net/qq_23598037/article/details/79560639
有什么问题,欢迎讨论~
项目实战14—ELK 企业内部日志分析系统的更多相关文章
- 项目实战14.1—ELK 企业内部日志分析系统
本文收录在Linux运维企业架构实战系列 一.els.elk 的介绍 1.els,elk els:ElasticSearch,Logstash,Kibana,Beats elk:ElasticSear ...
- 项目实战14—ELK 企业内部搜索引擎
一.els.elk 的介绍 1.els,elk els:ElasticSearch,Logstash,Kibana,Beats elk:ElasticSearch,Logstash,Kibana ① ...
- ELK 企业内部日志分析系统
生产环境配置 亿级规模,建议64G内存+8核CPU ES JVM占用一半内存 生产环境的3节点的集群 https://blog.csdn.net/xuduorui/article/details/79 ...
- centos7搭建ELK开源实时日志分析系统
Elasticsearch 是个开源分布式搜索引擎它的特点有分布式零配置自动发现索引自动分片索引副本机制 restful 风格接口多数据源自动搜索负载等. Logstash 是一个完全开源的工具他可以 ...
- ELK大流量日志分析系统搭建
1.首先说下EKL到底是什么吧? ELK是Elasticsearch(相当于仓库).Logstash(相当于旷工,挖矿即采集数据).Kibana(将采集的数据展示出来)的简称,这三者是核心套件,但并非 ...
- ELK系列--实时日志分析系统ELK 部署与运行中的问题汇总
前记: 去年测试了ELK,今年测试了Storm,最终因为Storm需要过多开发介入而放弃,选择了ELK.感谢互联网上各路大神,目前总算是正常运行了. logstash+elasticsearch+ki ...
- Docker笔记(十):使用Docker来搭建一套ELK日志分析系统
一段时间没关注ELK(elasticsearch —— 搜索引擎,可用于存储.索引日志, logstash —— 可用于日志传输.转换,kibana —— WebUI,将日志可视化),发现最新版已到7 ...
- 《ElasticSearch6.x实战教程》之实战ELK日志分析系统、多数据源同步
第十章-实战:ELK日志分析系统 ElasticSearch.Logstash.Kibana简称ELK系统,主要用于日志的收集与分析. 一个完整的大型分布式系统,会有很多与业务不相关的系统,其中日志系 ...
- ELK+Kafka集群日志分析系统
ELK+Kafka集群分析系统部署 因为是自己本地写好的word文档复制进来的.格式有些出入还望体谅.如有错误请回复.谢谢! 一. 系统介绍 2 二. 版本说明 3 三. 服务部署 3 1) JDK部 ...
随机推荐
- CentOS7修改主机名(hostname)
Linux中的hostname在大多数应用中至为重要,例如有些应用强制使用主机名称而不能使用IP地址,如果默认主机名称都为localhost.localdomain 的话那一定会出现问题,而且看起来也 ...
- 二级缓存:EHCache的使用
EHCache的使用 在开发高并发量,高性能的网站应用系统时,缓存Cache起到了非常重要的作用.本文主要介绍EHCache的使用,以及使用EHCache的实践经验. 笔者使用过多种基于Java的开源 ...
- CentOS 下做端口映射/端口转发
CentOS 下做端口映射/端口转发==[实现目标]==================[服务器A]有2块网卡,一块接内网,一块接外网,[服务器B]只有一块内网网卡:访问[服务器A]的7890端口跳转 ...
- Django中不返回QuerySets的API -- Django从入门到精通系列教程
该系列教程系个人原创,并完整发布在个人官网刘江的博客和教程 所有转载本文者,需在顶部显著位置注明原作者及www.liujiangblog.com官网地址. Python及Django学习QQ群:453 ...
- python数据类型之元组、字典、集合
python数据类型元组.字典.集合 元组 python的元组与列表类似,不同的是元组是不可变的数据类型.元组使用小括号,列表使用方括号.当元组里只有一个元素是必须要加逗号: >>> ...
- 看图说话,P2P 分享率 90% 以上的 P2P-CDN 服务,来了!
事情是这样的:今年年初的时候,公司准备筹划一个直播项目,在原有的 APP 中嵌入直播模块,其中的一个问题就是直播加速服务的选取. 老板让我负责直播加速的产品选型,那天老板把我叫到办公室,语重心长地说: ...
- hive权威指南<一>
一.ETL介绍: 数据抽取:把不同的数据源数据抓取过来,存到某个地方 数据清洗:过滤那些不符合要求的数据或者修正数据之后再进行抽取 不完整的数据:比如数据里一些应该有的信息缺失,需要补全后再写入数据仓 ...
- UOJ Round #15 [构造 | 计数 | 异或哈希 kmp]
UOJ Round #15 大部分题目没有AC,我只是水一下部分分的题解... 225[UR #15]奥林匹克五子棋 题意:在n*m的棋盘上构造k子棋的平局 题解: 玩一下发现k=1, k=2无解,然 ...
- BZOJ 3790: 神奇项链 [Manacher 贪心]
3790: 神奇项链 Time Limit: 10 Sec Memory Limit: 64 MBSubmit: 405 Solved: 200[Submit][Status][Discuss] ...
- Linux设置DNS地址及清理DNS缓存方法
1.设置DNS地址 编辑vim /etc/resolv.conf 文件. 增加DNS地址:nameserver ip. 2.清理DNS缓存 清理dns缓存: 通过重启nscd服务来达到清理dns缓存的 ...