Redux的中间件原理分析
redux的中间件对于使用过redux的各位都不会感到陌生,通过应用上我们需要的所有要应用在redux流程上的中间件,我们可以加强dispatch的功能。最近抽了点时间把之前整理分析过的中间件有关的东西放在这里分享分享。本文只对中间件涉及到的createStore、applyMiddleware以及典型常用中间的的源码做解析,让大家了解redux的内部模块:createStore.js、applyMiddleware.js,以及redux的中间件之间是怎么串联在一起并协作工作的。文章内容特别是源码部分对函数式编程思想有一定要求,比如:柯里化、compose等,源码中会大量涉及到这些概念,如果读者对此是不熟悉,可先学习这方面相关资料。
一、thunk作为一个典型redux中间件,它做了什么事?
简单的thunk使用方式如下:
// action
const getUserInfo = (id) => {
return function (dispatch, getState, extraArgument){
return reqGet({id: id})
.then(res => res.json().data)
.then(info => {
dispatch({
type: "GET_USER_INFO",
info
})
})
.catch(err => console.log('reqGet error: ' + err));
}
}; // dispatch action
dispatch(getUserInfo(1));
在上述使用实例中,我们应用thunk中间到redux后,可以dispatch一个方法,在方法内部我们想要真正dispatch一个action对象的时候再执行dispatch即可,特别是异步操作时非常方便。当然支持异步操作的redux中间件也并非只有thunik,还有更专业的其他中间件,这非本文内容,这里不再多讲。
二、thunk中间件内部是什么样的?
thunk源码如下(为了方便阅读,源码中的箭头函数在这里换成了普通函数):
function createThunkMiddleware (extraArgument){
return function ({dispatch, getState}){
return function (next){
return function (action){
if (typeof action === 'function'){
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
}
}
let thunk = createThunkMiddleware();
thunk.withExtraArgument = createThunkMiddleware;
export default thunk;
thunk是一个很常用的redux中间件,应用它之后,我们可以dispatch一个方法,而不仅限于一个纯的action对象。它的源码也很简单,如上所示,除去语法固定格式也就区区几行。
下面我们就来看看源码(为了方便阅读,源码中的箭头函数在这里换成了普通函数),首先是这三层柯里化:
// 外层
function createThunkMiddleware (extraArgument){
// 第一层
return function ({dispatch, getState}){
// 第二层
return function (next){
// 第三层
return function (action){
if (typeof action === 'function'){
return action(dispatch, getState, extraArgument);
}
return next(action);
};
}
}
}
首先是外层,从thunk最后两行源码可知,这一层存在的主要目的是支持在调用applyMiddleware并传入thunk的时候时候可以不直接传入thunk本身,而是先调用包裹了thunk的函数(第一层柯里化的父函数)并传入需要的额外参数,再将该函数调用的后返回的值(也就是真正的thunk)传给applyMiddleware,从而实现对额外参数传入的支持,使用方式如下:
const store = createStore(reducer, applyMiddleware(thunk.withExtraArgument({api, whatever})));
如果无需额外参数则用法如下:
const store = createStore(reducer, applyMiddleware(thunk));
接下来来看第一层,这一层是真正applyMiddleware能够调用的一层,从形参来看,这个函数接收了一个类似于store的对象,因为这个对象被结构以后获取了它的dispatch和getState这两个方法,巧的是store也有这两方法,但这个对象到底是不是store,还是只借用了store的这两方法合成的一个新对象?这个问题在我们后面分析applyMiddleware源码时,自会有分晓。
再来看第二层,在第二层这个函数中,我们接收的一个名为next的参数,并在第三层函数内的最后一行代码中用它去调用了一个action对象,感觉有点 dispatch({type: 'XX_ACTION', data: {}}) 的意思,因为我们可以怀疑它就是一个dispatch方法,或者说是其他中间件处理过的dispatch方法,似乎能通过这行代码链接上所有的中间件,并在所有只能中间件自身逻辑处理完成后,最终调用真实的store.dispath去dispatch一个action对象,再走到下一步,也就是reducer内。
最后我们看看第三层,在这一层函数的内部源码中首先判断了action的类型,如果action是一个方法,我们就调用它,并传入dispatch、getState、extraArgument三个参数,因为在这个方法内部,我们可能需要调用到这些参数,至少dispatch是必须的。这三行源码才是真正的thunk核心所在,简直是太简单了。所有中间件的自身功能逻辑也是在这里实现的。如果action不是一个函数,就走之前解析第二层时提到的步骤。
三层的初步解析就到这里,通过这个分析,其实也没有得出很重要的结论,对于想要了解applyMiddleware到底干了啥,我们还是很懵逼的。但至少我们可以初步判断出第一层到第三层均为applyMiddleware对一个redux中间件的基本写法要求,也就是说无论一个中间件要实现一个怎样的功能,其固定格式必须是这个,在第三层函数内部才是自己功能逻辑实现的地方。
记住这三层做的事情很重要(虽然凭借着这极少的信息,我们依然很懵逼),但在下一个段落中,我们将再次提到它们,并详细说明为什么会有这三层柯里化的存在。
三、applyMiddleware内部是怎样的?createStore又干了什么?
直接上applyMiddleware源码,为方便阅读和理解,部分ES6箭头函数已修改为ES5的普通函数形式,如下:
function applyMiddleware (...middlewares){
return function (createStore){
return function (reducer, preloadedState, enhancer){
const store = createStore(reducer, preloadedState, enhancer);
let dispatch = function (){
throw new Error('Dispatching while constructing your middleware is not allowed. Other middleware would not be applied to this dispatch.')
};
const middlewareAPI = {
getState: store.getState,
dispatch: (...args) => dispatch(...args)
};
const chain = middlewares.map(middleware => middleware(middlewareAPI));
dispatch = compose(...chain)(store.dispatch);
return {
...store,
dispatch
};
}
}
}
从其源码可以看出,applyMiddleware内部一开始也是两层柯里化,我们从thunk过来本来是为了寻找答案的,这让我们一过来就又处于懵逼之中,为啥这么多柯里化?哈哈,解铃还须系铃人,让我们先来看看和applyMiddleware最有关系的createStore的主要源码:
export default function createStore(reducer, preloadedState, enhancer) {
if (typeof preloadedState === 'function' && typeof enhancer === 'undefined') {
enhancer = preloadedState
preloadedState = undefined
}
if (typeof enhancer !== 'undefined') {
if (typeof enhancer !== 'function') {
throw new Error('Expected the enhancer to be a function.')
}
return enhancer(createStore)(reducer, preloadedState)
}
if (typeof reducer !== 'function') {
throw new Error('Expected the reducer to be a function.')
}
var currentReducer = reducer;
var currentState = preloadedState;
var currentListeners = [];
var nextListeners = currentListeners;
var isDispatching = false;
function ensureCanMutateNextListeners (){
// ...
}
function dispatch (){
// ...
}
function subscribe (){
// ...
}
function getState (){
// ...
}
function replaceReducer (){
// ...
}
function observable (){
// ...
}
dispatch({ type: ActionTypes.INIT })
return {
dispatch,
subscribe,
getState,
replaceReducer,
[$$observable]: observable
}
}
对于createStore的源码我们只需要关注和applyMiddleware有关的地方,其他和store有关的不是本文的重点。从其内部前面一部分代码来看,其实很简单,就是对调用createStore时传入的参数进行一个判断,并对参数做矫正,再决定以哪种方式来执行后续代码。据此可以得出createStore有多种使用方法,根据第一段参数判断规则,我们可以得出createStore的两种使用方式,它们和第一章节中的使用方式相同:
const store = createStore(reducer, {a: 1, b: 2}, applyMiddleware(...));
以及:
const store = createStore(reducer, applyMiddleware(...));
同时根据第一段参数判断规则,我们还可以肯定的是:applyMiddleware返回的一定是一个函数,在上述章节中我们曾猜想过,经过了各个中间件处理以后,原始的store.dispatch会被改造,但最终还是会返回一个经过改造后的dispatch,这里可以确定至少一半是正确了的。
经过createStore中的第一个参数判断规则后,对参数进行了校正,得到了新的enhancer得值,如果新的enhancer的值不为undeifined,便将createStore传入enhancer(即applyMiddleware调用后返回的函数)内,让enhancer执行创建store的过程。也就时说这里的:
enhancer(createStore)(reducer, preloadedState);
实际上等同于:
applyMiddleware(mdw1, mdw2, mdw3)(createStore)(reducer, preloadedState);
这也解释了为啥applyMiddleware会有两层柯里化,同时表明它还有一种很函数式编程的用法,即 :
const store = applyMiddleware(mdw1, mdw2, mdw3)(createStore);
这种方式将创建store的步骤完全放在了applyMiddleware内部,并在其内第二层柯里化的函数内执行创建store的过程即调用createStore,调用后程序将跳转至createStore走参数判断流程最后再创建store。
无论哪一种执行createStore的方式,我们都终将得到store,也就是在creaeStore内部最后返回的那个包含dispatch、subscribe、getState等方法的对象。
四、回过头对applyMiddleware做深入分析
applyMiddleware源码和中间件thunk的源码在第三章节和第一章节中有提到,这里就不再贴出来了,回看前面章节中的源码即可。对于applyMiddleware开头的两层柯里化的出现原因以及和createStore有关的方面,在上述章节章节中已有分析。这里主要针对本文的重点,也就是中间件是如何通过applyMiddleware的工作起来并实现挨个串联的原因做分析。
在第二章节中,我们提到过怀疑在thunk的第一层柯里化中传入的对象是一个类似于store的对象,通过上个章节中applyMiddleware的确实可以确认了,确实如我们所想一样。
接下来这几段代码是整个applyMiddleware的核心部分,也解释了在第二章节中,我们对thunk中间件为啥有三层柯里化的疑虑,把这些代码单独贴出来,如下:
// ...
const chain = middlewares.map(middleware => middleware(middlewareAPI));
dispatch = compose(...chain)(store.dispatch);
return {
...store,
dispatch
};
// ...
首先,applyMiddleware的执行结果最终是返回store的所有方法和一个dispatch方法。这个dispatch方法是怎么来的呢?我们来看头两行代码,这两行代码也是所有中间件被串联起来的核心部分实现,它们也决定了中间件内部为啥会有我们在之前章节中提到的三层柯里化的固定格式,先看第一行代码:
const chain = middlewares.map(middleware => middleware(middlewareAPI));
遍历所有的中间件,并调用它们,传入那个类似于store的对象middlewareAPI,这会导致中间件中第一层柯里化函数被调用,并返回一个接收next(即dispatch)方法作为参数的新函数。为什么会有这一层柯里化呢,主要原因还是考虑到中间件内部会有调用store方法的需求,所以我们需要在此注入相关的方法,其内存函数可以通过闭包的方式来获取并调用,若有需要的话。
遍历结束以后,我们拿到了一个包含所有中间件新返回的函数的一个数组,将其赋值给变量chain,译为函数链。
再来看第二句代码:
dispatch = compose(...chain)(store.dispatch);
我们展开了这个数组,并将其内部的元素(函数)传给了compose函数,compose函数又返回了我们一个新函数。然后我们再调用这个新函数并传入了原始的未经任何修改的dispatch方法,
最后返回一个经过了修改的新的dispatch方法。
有几点疑惑:
1. 什么是compose?在函数式编程中,compose指接收多个函数作为参数,并返回一个新的函数的方式。调用新函数后传入一个初始的值作为参数,该参数经最后一个函数调用,将结果返回并作为倒数第二个函数的入参,倒数第二个函数调用完后,将其结果返回并作为倒数第三个函数的入参,依次调用,知道最后调用完传入compose的所有的函数后,返回一个最后的结果。这个结果就是把初始的值经过传入compose中的个函数改造后的结果,一个简易的compose实现如下:
function compose (...fncs){
fncs = fncs.reverse();
let result;
return function (arg){
result = arg;
for (let fnc of fncs){
result = fnc(result);
}
return result;
}
}
compose是从右到昨依次调用传入其内部的函数链,还有一种从左到右的方式叫做pipe,即去掉compose源码中的对函数链数组的reverse即可。
从上面对compose的分析中,不难看出,它就实现了对我们中间件的串联,并对原始的dispatch方法的改造。
在第二章节中,thunk中间件的第二层柯里化函数即在compose内部被调用,并接收了经其右边那个中间函数改造并返回dispatch方法作为入参,并返回一个新的函数,再在该函数内部添加自己的逻辑,最后调用右边那个中间函数改造并返回dispatch方法接着执行前一个中间件的逻辑。当然如果只有一个thunk中间件被应用了,或者他出入传入compose时的最后一个中间件,那么传入的dispatch方法即为原始的store.dispatch方法。
thunk的第三层柯里化函数,即为被thunk改造后的dispatch方法:
// ...
return function (action){
// thunk的内部逻辑
if (typeof action === 'function'){
return action(dispatch, getState, extraArgument);
}
// 调用经下一个中间件(在compose中为之前的中间件)改造后的dispatch方法(本层洋葱壳的下一层),并传入action
return next(action);
};
// ...
这个改造后的dispatch函数将通过compose传入thunk左边的那个中间件作为入参。
经上述分析,我们可以得出一个中间件的串联和执行时的流程,以下面这段使用applyMiddleware的代码为例:
export default createStore(reducer, applyMiddleware(middleware1, middleware2, middleware3));
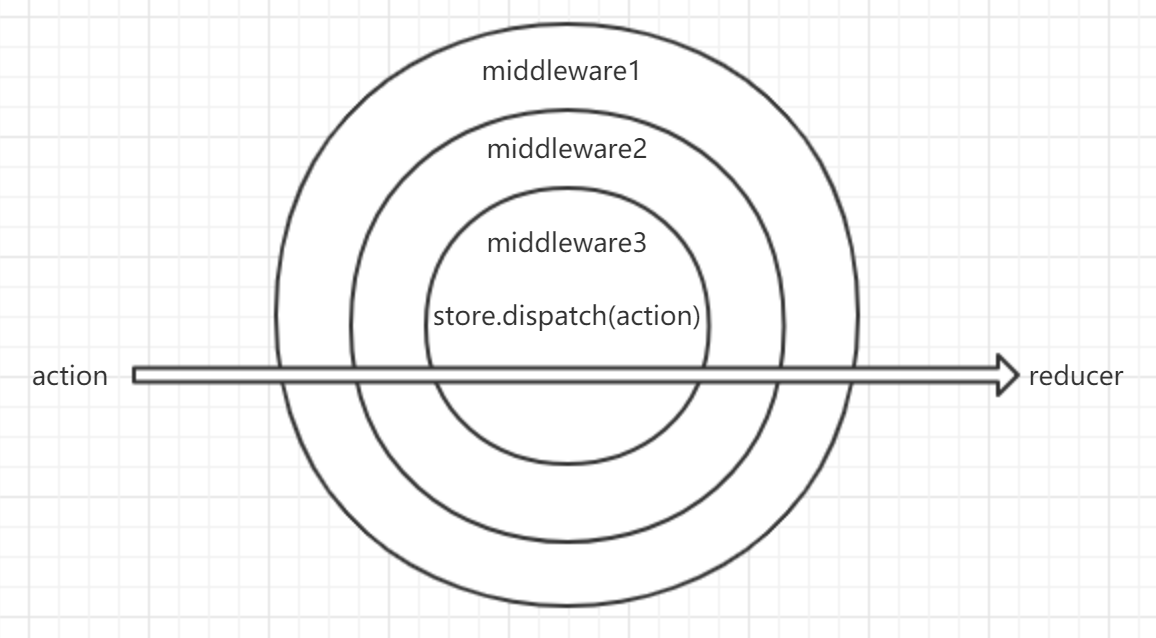
在applyMiddlware内部的compose串联中间件时,顺序是从右至左,就是先调用middleware3、再middleware2、最后middleware1。middleware3最开始接收真正的store.dispatch作为入参,并返回改造的的dispatch函数作为入参传给middleware2,这个改造后的函数内部包含有对原始store.dispatch的调用。依次内推知道从右到左走完所有的中间件。整个过程就像是给原始的store.dispatch方法套上了一层又一层的壳子,最后得到了一个类似于洋葱结构的东西,也就是下面源码中的dispatch,这个经过中间件改造并返回的dispatch方法将替换store被展开后的原始的dispatch方法:
// ...
return {
...store,
dispatch
};
// ...
而原始的store.dispatch就像这洋葱内部的芯,被覆盖在了一层又一层的壳的最里面。
而当我们剥壳的时候,剥一层壳,执行一层的逻辑,即走一层中间件的功能,直至调用藏在最里边的原始的store.dispatch方法去派发action。这样一来我们就不需要在每次派发action的时候再写单独的代码逻辑的。
总结来说就是:
在中间件串联的时候,middleware1-3的串联顺序是从右至左的,也就是middleware3被包裹在了最里面,它内部含有对原始的store.dispatch的调用,middleware1被包裹在了最外边。
当我们在业务代码中dispatch一个action时,也就是中间件执行的时候,middleware1-3的执行顺序是从左至右的,因为最后被包裹的中间件,将被最先执行。
如图所示:
至此为止,关于applyMiddleware和thunk中间件的分析就完成了,如果问题和不清楚之处烦请指出。
Redux的中间件原理分析的更多相关文章
- tomcat原理分析与简单实现
tomcat原理分析与简单实现 https://blog.csdn.net/u014795347/article/details/52328221 2016年08月26日 14:48:18 卫卫羊习习 ...
- Tomcat源码分析——请求原理分析(上)
前言 谈起Tomcat的诞生,最早可以追溯到1995年.近20年来,Tomcat始终是使用最广泛的Web服务器,由于其使用Java语言开发,所以广为Java程序员所熟悉.很多人早期的J2EE项目,由程 ...
- RocketMQ延迟消息的代码实战及原理分析
RocketMQ简介 RocketMQ是一款开源的分布式消息系统,基于高可用分布式集群技术,提供低延时的.高可靠.万亿级容量.灵活可伸缩的消息发布与订阅服务. 它前身是MetaQ,是阿里基于Kafka ...
- RocketMQ原理分析&场景问题
硬核干货分享,欢迎关注[Java补习课]成长的路上,我们一起前行 ! <高可用系列文章> 已收录在专栏,欢迎关注! 一.RocketMQ的基本原理 RocketMQ基本架构图如下 从这个架 ...
- Spring Cloud之负载均衡组件Ribbon原理分析
目录 前言 一个问题引发的思考 Ribbon的简单使用 Ribbon 原理分析 @LoadBalanced 注解 @Qualifier注解 LoadBalancerAutoConfiguration ...
- go-micro集成链路跟踪的方法和中间件原理
前几天有个同学想了解下如何在go-micro中做链路跟踪,这几天正好看到wrapper这块,wrapper这个东西在某些框架中也称为中间件,里边有个opentracing的插件,正好用来做链路追踪.o ...
- Handler系列之原理分析
上一节我们讲解了Handler的基本使用方法,也是平时大家用到的最多的使用方式.那么本节让我们来学习一下Handler的工作原理吧!!! 我们知道Android中我们只能在ui线程(主线程)更新ui信 ...
- Java NIO使用及原理分析(1-4)(转)
转载的原文章也找不到!从以下博客中找到http://blog.csdn.net/wuxianglong/article/details/6604817 转载自:李会军•宁静致远 最近由于工作关系要做一 ...
- 原子类java.util.concurrent.atomic.*原理分析
原子类java.util.concurrent.atomic.*原理分析 在并发编程下,原子操作类的应用可以说是无处不在的.为解决线程安全的读写提供了很大的便利. 原子类保证原子的两个关键的点就是:可 ...
随机推荐
- RocketMQ源码 — 九、 RocketMQ延时消息
上一节消息重试里面提到了重试的消息可以被延时消费,其实除此之外,用户发送的消息也可以指定延时时间(更准确的说是延时等级),然后在指定延时时间之后投递消息,然后被consumer消费.阿里云的ons还支 ...
- html5 标签在 IE 下使用
(function(){if(!/*@cc_on!@*/0)return;var e = "abbr,article,aside,audio,bb,canvas,datagrid,datal ...
- JAVA之单源最短路径(Single Source Shortest Path,SSSP问题)dijkstra算法求解
题目简介:给定一个带权有向图,再给定图中一个顶点(源点),求该点到其他所有点的最短距离,称为单源最短路径问题. 如下图,求点1到其他各点的最短距离 准备工作:以下为该题所需要用到的数据 int N; ...
- SSM博客 前端页面样式不显示
<!-- 由于在web.xml中定义的url拦截形式为“/”表示拦截所有的url请求, 包括静态资源例如css.js等.所以需要在springmvc.xml中添加资源映射标 --> < ...
- Nginx+uwsgi部署django
0. 登录远程服务器并准备 ssh 用户@IP -p 端口 回车后,要求输入服务器密码,再输入密码 更新软件源 sudo apt-get update sudo apt-get upgrade 1. ...
- composer安装laravel指定版本
版权声明:本文为博主原创文章,未经博主允许不得转载. http://blog.csdn.net/qq_38125058/article/details/79126051 首先安装composer,附安 ...
- resteasy上传文件写法
resteasy服务器代码 @Path(value = "file") public class UploadFileService { private final String ...
- Base64 image
[前端攻略]:玩转图片Base64编码 什么是 base64 编码? 我不是来讲概念的,直接切入正题,图片的 base64 编码就是可以将一副图片数据编码成一串字符串,使用该字符串代替图像地址. 这样 ...
- MQTT, XMPP, WebSockets还是AMQP?泛谈实时通信协议选型 good
Wolfram Hempel 是 deepstreamIO 的联合创始人.deepstreamIO 是一家位于德国的技术创业公司,为移动客户端.及物联网设备提供高性能.安全和可扩展的实时通信服务.文本 ...
- Mybatis通过注解方式实现批量插入数据库 及 常见的坑
原文地址:http://f0rb.iteye.com/blog/1207384 MyBatis中通过xml文件配置数据库批量操作的文章很多,比如这篇http://www.cnblogs.com/xcc ...