mysql(2)—— 由笛卡尔积现象分析数据库表的连接
首先,先简单解释一下笛卡尔积。
现在,我们有两个集合A和B。
A = {0,1} B = {2,3,4}
集合 A×B 和 B×A的结果集就可以分别表示为以下这种形式:
A×B = {(0,2),(1,2),(0,3),(1,3),(0,4),(1,4)};
B×A = {(2,0),(2,1),(3,0),(3,1),(4,0),(4,1)};
以上A×B和B×A的结果就可以叫做两个集合相乘的‘笛卡尔积’。
从以上的数据分析我们可以得出以下两点结论:
1,两个集合相乘,不满足交换率,既 A×B ≠ B×A;
2,A集合和B集合相乘,包含了集合A中元素和集合B中元素相结合的所有的可能性。既两个集合相乘得到的新集合的元素个数是 A集合的元素个数 × B集合的元素个数;
数据库表连接数据行匹配时所遵循的算法就是以上提到的笛卡尔积,表与表之间的连接可以看成是在做乘法运算。
比如现在数据库中有两张表,student表和 student_subject表,如下所示:
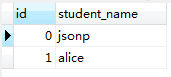
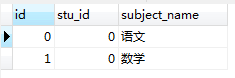
我们执行以下的sql语句,只是纯粹的进行表连接。
SELECT * from student JOIN student_subject;
SELECT * from student_subject JOIN student;
看一下执行结果:
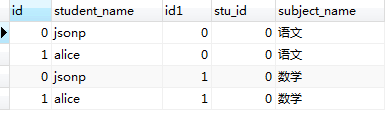
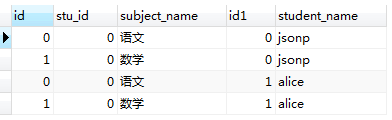
表1.0 表1.1
从执行结果上来看,结果符合我们以上提出的两点结论(红线标注部分);
以第一条sql语句为例我们来看一下他的执行流程,
1,from语句把student表 和 student_subject表从数据库文件加载到内存中。
2,join语句相当于对两张表做了乘法运算,把student表中的每一行记录按照顺序和student_subject表中记录依次匹配。
3,匹配完成后,我们得到了一张有 (student中记录数 × student_subject表中记录数)条的临时表。 在内存中形成的临时表如表1.0所示。我们又把内存中表1.0所示的表称为‘笛卡尔积表’。
针对以上的理论,我们提出一个问题,难道表连接的时候都要先形成一张笛卡尔积表吗,如果两张表的数据量都比较大的话,那样就会占用很大的内存空间这显然是不合理的。所以,我们在进行表连接查询的时候一般都会使用JOIN xxx ON xxx的语法,ON语句的执行是在JOIN语句之前的,也就是说两张表数据行之间进行匹配的时候,会先判断数据行是否符合ON语句后面的条件,再决定是否JOIN。
因此,有一个显而易见的SQL优化的方案是,当两张表的数据量比较大,又需要连接查询时,应该使用 FROM table1 JOIN table2 ON xxx的语法,避免使用 FROM table1,table2 WHERE xxx 的语法,因为后者会在内存中先生成一张数据量比较大的笛卡尔积表,增加了内存的开销。
根据上一篇博客(http://www.cnblogs.com/cdf-opensource-007/p/6502556.html),及本篇博客的分析,我们可以总结出一条查询sql语句的执行流程。
From
ON
JOIN
WHERE
GROUP BY
SELECT
HAVING
ORDER BY
LIMIT
最后,针对两张数据库表连接的底层实现,我用java代码模拟了一下,感兴趣的可以看一下,能够帮助我们理解:
package com.opensource.util;
import java.util.Arrays;
public class DecareProduct {
public static void main(String[] args) {
//使用二维数组,模拟student表
String[][] student ={
{"0","jsonp"},
{"1","alice"}
};
//使用二维数组,模拟student_subject表
String[][] student_subject2 ={
{"0","0","语文"},
{"1","0","数学"}
};
//模拟 SELECT * from student JOIN student_subject;
String[][] resultTowArray1 = getTwoDimensionArray(student,student_subject2);
//模拟 SELECT * from student_subject JOIN student;
String[][] resultTowArray2 = getTwoDimensionArray(student_subject2,student);
int length1 = resultTowArray1.length;
for (int i = 0; i <length1 ; i++) {
System.out.println(Arrays.toString(resultTowArray1[i]));
}
System.err.println("-----------------------------------------------");
int length2 = resultTowArray2.length;
for (int i = 0; i <length2 ; i++) {
System.out.println(Arrays.toString(resultTowArray2[i]));
}
}
/**
* 模拟两张表连接的操作
* @param towArray1
* @param towArray2
* @return
*/
public static String[][] getTwoDimensionArray(String[][] towArray1,String[][] towArray2){
//获取二维数组的高(既该二维数组中有几个一维数组,用来指代数据库表中的记录数)
int high1 = towArray1.length;
int high2 = towArray2.length;
//获取二维数组的宽度(既二位数组中,一维数组的长度,用来指代数据库表中的列)
int wide1 = towArray1[0].length;
int wide2 = towArray2[0].length;
//计算出两个二维数组进行笛卡尔乘积运算后获得的结果集数组的高度和宽度,既笛卡尔积表的行数和列数
int resultHigh = high1 * high2;
int resultWide = wide1 + wide2;
//初始化结果集数组,既笛卡尔积表
String[][] resultArray = new String[resultHigh][resultWide];
//迭代变量
int index = 0;
//先对第二二维数组遍历
for (int i = 0; i < high2; i++) {
//拿出towArray2这个二维数组的元素
String[] tempArray = towArray2[i];
//循环嵌套,对第towArray1这个二维数组遍历
for (int j = 0; j < high1; j++) {
//初始化一个长度为'resultWide'的数组,作为结果集数组的元素,既笛卡尔积表中的一行
String[] tempExtened = new String[resultWide];
//拿出towArray1这个二维数组的元素
String[] tempArray1 = towArray1[j];
//把tempArray1和tempArray两个数组的元素拷贝到结果集数组的元素中去。(这里用到了数组扩容)
System.arraycopy(tempArray1, 0, tempExtened, 0, tempArray1.length);
System.arraycopy(tempArray, 0, tempExtened, tempArray1.length, tempArray.length);
//把tempExtened放入结果集数组中
resultArray[index] = tempExtened;
//迭代加一
index++;
}
}
return resultArray;
}
}
执行结果:

最后说一点,我们作为程序员,研究问题还是要仔细深入一点的。当你对原理了解的有够透彻,开发起来也就得心应手了,很多开发中的问题和疑惑也就迎刃而解了,而且在面对其他问题的时候也可做到触类旁通。当然在开发中没有太多的时间让你去研究原理,开发中要以实现功能为前提,可等项目上线的后,你有大把的时间或者空余的时间,你大可去刨根问底,深入的去研究一项技术,我觉得这对一名程序员的成长是很重要的事情。
A6J{[VI}J.png)
mysql(2)—— 由笛卡尔积现象分析数据库表的连接的更多相关文章
- MySQL,SQLSERVER,ORACLE获取数据库表名及字段名
1.MySQL 获取表名: 用“show tables”命令.在程序中也可以采用该命令获取,在返回的RowSet中的“Tables_in_db”读出来.其中“db”是指你的数据库的名称,比如说Tabl ...
- MySQL必知必会-官方数据库表及SQL脚本导入生成
最近在复习SQL语句,看的是MySQL必知必会这本书,但是发现附录中只有表设计,没有表的具体数据.所以在学习相应的语句中体验不是很好,去网上查了数据库的内容,自己慢慢导入到了数据库中.把表放出来作为参 ...
- Mysql使用information.shema.tables查询数据库表大小
简介: information_schema数据库中的表都是只读的,不能进行更新.删除和插入等操作,也不能加触发器,因为它们实际只是一个视图,不是基本表,没有关联的文件. 元数据描述数据的数据,用于描 ...
- mysql远程访问另一台主机数据库表,实现小表广播功能
1.打开navicat,打开任意一个连接,新建一个查询,输入命令 show engines,出现如下界面 2. 如果FEDERATED对应的Support值为NO,则找到C:\ProgramData\ ...
- mysql快速生成truncate脚本清空数据库表记录
语句格式: select CONCAT('truncate TABLE ',table_schema,'.',TABLE_NAME, ';') from INFORMATION_SCHEMA.TABL ...
- T-SQL实用查询之分析数据库表的大小
IF OBJECT_ID('tempdb..#TB_TEMP_SPACE') IS NOT NULL DROP TABLE #TB_TEMP_SPACE GO CREATE TABLE #TB_TEM ...
- 数据库表的连接(Left join , Right Join, Inner Join)用法详解
转自:http://blog.csdn.net/jetjetlinuxsystem/article/details/6663218 Left Join, Inner Join 的相关内容,非常实用,对 ...
- MySQL数据库表的设计和优化(上)
一.单表设计与优化: (1)设计规范化表,消除数据冗余(以使用正确字段类型最明显):数据库范式是确保数据库结构合理,满足各种查询需要.避免数据库操作异常的数据库设计方式.满足范式要求的表,称为规范化表 ...
- 【SQL server初级】数据库性能优化二:数据库表优化
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第二部分 数据库性能优化二:数据库表优化 优化①:设计规范化表,消除数据冗余 数据库范式是确保数据库结构合理,满足各种查询 ...
随机推荐
- 【Unity3D与23种设计模式】单例模式(Singleton)
GoF中定义: "确认类只有一个对象,并提供一个全局的方法来获取这个对象" 使用单例模式的前提 它只能产生一个对象且不能够被继承 单例模式的优点: 提供方便获取唯一对象的方法 可以 ...
- Python基本知识
python是一门编程语言,这是我们学习python首先要了解的内容,那么编程语言又是什么,我们为什么需要编程语言 我们讲的话是汉语,英语或者其他语言,计算机也可以讲话,但是他只会说0,1,也只能看懂 ...
- QC的使用简介
目录一.站点管理员的操作(后台)1.登录2.创建域3.创建项目4.新建用户5.QC的一些其他信息的修改(非 常用)二.项目管理员对项目的配置管理(前台)1.登录2.修改用户个人信息及密码3.项目成员设 ...
- 前端水印图片及文字js教程
前端水印图片文字教程如下,复制代码修改图片地址即可看到效果,工作中遇到总结的,喜欢就关注下哦: <!DOCTYPE html><html> <head> <m ...
- 笔记:Eclipse 安装 m2eclipse 插件
M2eclipse 插件 Eclipse 下一款十分强大的 Maven 插件,可以访问 http://m2eclipse.sonatype.org 了解更多该项目的信息,如果需要安装该插件可以按照如下 ...
- npm包使用语义化版本号
npm 采用语义版本管理软件包.所谓语义版本,就是指版本号为a.b.c的形式,其中a是大版本号,b是小版本号,c是补丁号. 一个软件发布的时候,默认就是1.0.0版.如果以后发布补丁,就增加最后一位数 ...
- NodeJS定时任务
在实际开发项目中,会遇到很多定时任务的工作.比如:定时导出某些数据.定时发送消息或邮件给用户.定时备份什么类型的文件等等 一般可以写个定时器,来完成相应的需求,在node.js中自已实现也非常容易,接 ...
- APS期刊投稿准备: REVTex格式
APS是American Physics Society的简称.旗下比较有影响力的期刊有: "pra, prb, prc, prd, pre, prl, prstab, prstper, o ...
- 使用Python的requests模块编写请求脚本
requests模块可用来编写请求脚本. 比如,使用requests的post函数可以模拟post请求: resp = requests.post(url, data = content) url即为 ...
- IntelliJ IDEA的入门使用
1 修改背景颜色 点击File,Settings 2 修改字体格式,以及字体大小 我个人习惯Eclipse的默认字体,所有把字体修改成Eclipse默认的Consolas 同上点击File,Setti ...