从零开始学习PYTHON3讲义(九)字典类型和插入排序

《从零开始PYTHON3》第九讲
第六讲、上一讲我们都介绍了列表类型。列表类型是编程中最常用的一种类型,但也有挺明显的缺陷,比如:
data = [5,22,34,12,87,67,3,43,56,23]
还记得让程序更友好的概念吗?上一条语句所定义的列表,我们没办法很容易的知道这些值代表什么、有什么用、附加什么样的操作对这个列表来说才有意义。
在现实的场景中,往往应当是类似这样的情形,比如有一份学习成绩单:
Harry:87分
Joe:90分
Yolanda:67分
Aaron:88分
Charles:79分
Fred:93分
为了有意义的描述这个成绩单,我们可能需要用类似这样的方法:
name = ['Harry','Joe','Yolanda','Aaron','Charles','Fred']
score = [87,90,67,88,79,93]
这样,想显示第3个同学的考试成绩,我们可以使用这样的方式:
print(name[2],score[2]) #数组下标从0开始计数
利用Python同一个列表中可以保存不同数据类型的特征,还可以使用这样的方案:
students = ["Harry",87,"Joe",90,"Yolanda",67,"Aaron",88,"Charles",79,"Fred",93]
这样想显示一个同学的成绩,可以这样做(i在这里代表从0计数,显示第i个学生):
print(students[i*2],students[i*2+1])
除此之外,还可以使用多维列表的方法。多位列表指的是2维以及2维以上的列表,我们之前学习的,都是1维列表。先举一个另外的例子,比如我们有这样一个数学矩阵:
\begin{matrix}
2 & 3 & 4 \\
5 & 6 & 7 \\
8 & 9 & 10
\end{matrix}
\right\}\tag{1}
\]
想使用列表来表示,可以用这样的形式:
A = [[2, 3, 4], [5, 6, 7], [8, 9, 10]]
也就是列表中的列表,或者称2维列表。
矩阵的概念如果有的同学还没有学习过,可以先不用管,这不是本课程的重点,不影响你学习编程的概念。不过还是要强调一下,数学中的矩阵运算是非常重要的部分,在人工智能、图形、图像、视频、声音的处理中,都非常频繁的使用。
话题再拉回刚才讲到的学生成绩单,如果使用2维列表的方法,可以这样处理:
students = [["Harry",87],["Joe",90],["Yolanda",67],["Aaron",88],["Charles",79],["Fred",93]]
显示学生成绩则使用(i的含义同上):
print(students[i][0],students[i][1])
我们已经讲述了三种方法,让列表的使用,更有实际的意义,同时也更友好。
如果只是处理类似这样学生成绩单的问题,Python中有一个更适用的数据类型,也是我们学的第四种数据类型,字典。
字典类型
使用字典来表示我们上面讲过的程序单,简直不能更合适:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
跟列表的区别,首先使用的是“{}”大括号将立即数数据包裹起来。
其次,列表的每一个元素,是一对儿值,而不是列表中的一个值。一对儿值之间,使用“:”分割。冒号前面的部分称为key,或者叫“关键字”;冒号后面的部分称为value,或者称为“值”。这样的一对儿值习惯上称为key-value对儿。
注意别把字典中的关键字,跟Python中指命令的关键字弄混。后者就是关键字,前者更类似列表中的下标。
访问数据的时候,使用下面的形式:
>>> print(students["Harry"])
87 #使用学生名称,直接获取到学生的成绩
上面语句中,访问字典类型跟访问列表很像,只是列表强制规定下标必须是以0开始的连续整数数字;而字典则使用该项的名称部分,也就是关键字部分。当然啦,关键字也可以使用数字变量,这时候会跟列表类型非常像,要留神别搞混了。
同列表一样,字典类型,也是可以修改的类型。Python只有列表、字典两种类型允许修改。其它类型都是只读类型。修改字典中的数据使用:
students["Harry"] = 91
对于一个已经存在的字典变量,还可以为其增加数据,比如:
students["Andrew"] = 91
当字典中当前不存在“Andrew”这个学生的话,上面语句将在字典中新增一个元素,其关键字为“Andrew”,值是91。
本例中我们使用学生的名字作为字典的关键字来举例,但前面说了,字典并非必须使用字符串作为“下标”名。比如:
dict1 = { 1:"abcd",4:"789a",6:"point" }
这个字典跟“成绩单”的例子相反,使用数字作为关键字,使用字符串当做值。访问的时候使用这种形式:
>>> print(dict1[4])
'789a'
访问的方法跟列表一模一样,如果不看赋值的部分,太容易弄混了。不过不用担心,两种数据类型通常都应用在不同的场景,只要你的变量名起的比较易记、易读,通常不会出现你担心的情况。
获取字典中元素的个数同样使用len函数,不过要注意,字典中的每个元素指的是一对儿。就是说关键字和值一起记为1个元素:
len(students)
字典看起来很像序列类型,但实际本身并不是。原因是,字典并没有列表下标这样的概念来天然的为字典指定一个固有的顺序。想有序的访问字典,需要使用内置的函数转换,以for循环遍历为例:
for k,v in students.items(): #items()返回的是序列类型
print(k,v)
items内置函数返回的序列并不是单个值,而是用逗号隔开的一对儿值,也就是一个元组。
元组是Python六个基本类型中的第5个。其实我们前面也见到过了很多次元组的应用,只是并不知道元组这个名字。
比如多重赋值就是元组:
a,b,c = 1,2,3
元组类型也是一种序列类型,可以使用for来遍历。但元组类型是只读类型,不能更改其内容。
元组虽然经常用到,但并没有过多的附加概念和难以理解的内容。我们还是继续讲述字典的常用操作。
字典的初始化(赋值)有两种形式:
#第一种形式我们前面一直在用
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
#第二种形式实际是一组关键字、值的元组,然后使用dict函数转换成字典
students = dict(Harry=87,Joe=90,Yolanda=67,Aaron=88,Charles=79,Fred=93)
注意第二种形式实际也是我们平常使用函数调用时候参数所使用的方式,可能看起来并不完全相同,但实际就是一回事。不过这个概念不用着急理解,你慢慢的会习惯。
再来看看列表和字典两种类型的区别:
| 列表类型 | 字典类型 |
|---|---|
| 以下标顺序为序 | 以加入的顺序为序 |
| 使用数字(下标)访问 | 使用关键字(标志字)访问 |
因为字典中元素加入是有顺序的,但实际这种顺序有很大的随机性。所以在使用字典的时候,除非你很清楚元素添加的逻辑,否则你应当假定字典是乱序的,或者说没有顺序。前面也已经说过,字典类型不是序列类型。
*匿名函数
匿名函数很有用,但是有一点学习难度,我们只是为了继续引出关于列表和字典的一些操作概念。所以如果这一节和下一节中,不能马上看懂的话,可以先做了解,能记住多少就算多少。将来真正操作用的多了,自然可以慢慢理解。
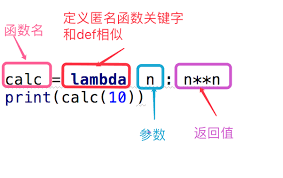
概念上说,匿名函数可以说是普通函数的简写形式,比如:
#传统的函数定义方式:
def calc(x)
return x ** x
#匿名函数的定义方式:
calc1 = lambda x : x**x
#调用起来是一样的
print(calc(10))
print(calc1(10))
注意匿名函数的声明方式,首先是使用lambda关键字,而不是def,接着是函数的参数,冒号之后就是函数本身。
匿名函数适合用在非常简单的小函数中,这样这种简写的形式,往往一行就完成,才显示出来匿名函数的优势。我们前面还讲过,函数其实也是变量的一种,现在使用匿名函数这种写法,你可能理解了这句话了。
我们再看一个例子:
#传统的函数定义方式:
def add(x,y)
return x+y
#匿名函数的定义方式:
add = lambda x,y : x+y
匿名函数还适用把函数当做参数的场合中,毕竟函数本身也是变量,变量当做参数我们已经一再见到了。函数当做变量的例子我们后面会看到。
*列表生成表达式
匿名函数就讲这些,我们继续讲列表和字典。
讲for循环的时候,我们曾经讲过了range函数,用于生成一个连续序列。当然range函数生成的还不是列表,所以如果希望当做列表使用,还需要使用list()函数转换一下,比如:
>>> list(range(10)) #实际上是序列转换成列表
[0, 1, 2, 3, 4, 5, 6, 7, 8, 9]
这样的使用方法可以叫“列表生成式”,或者完整的名字“列表生成表达式”。我们来看个更复杂的例子:
>>> a = [x**2 for x in range(10)]
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
这个例子的关键在当做列表值来使用的部分,把这部分用大家熟悉了的代码重写一下可能看上去更清楚:
a=[]
for x in range(10):
a.append(x ** 2)
列表生成式的形式,很类似匿名函数的形式,但更抽象。
字典也有生成表达式:
>>> a={x:x**2 for x in range(10)}
{0: 0, 1: 1, 2: 4, 3: 9, 4: 16, 5: 25, 6: 36, 7: 49, 8: 64, 9: 81}
这个字典生成表达式,相当于下面的语句:
a={}
for x in range(10):
a[x]=x**2 #因为"关键字"选取了数字,看上去很类似列表,但并不是
挑战
今天的挑战是:
有一个字典,其中保存着学生的成绩单:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
请将这个成绩单按照成绩的多少,从低到高排列。
上面讲过,字典实际上是“无序”的类型,想容纳有序的数据应当先转换为其它有序的数据类型,比如列表。
转换的方法可以使用for循环遍历的方法,完整的遍历整个字典。
因为在遍历的时候每次都是拿到一组新数据,插入到数组中,所以这种请境况下使用插入排序法,比冒泡排序效果更好。
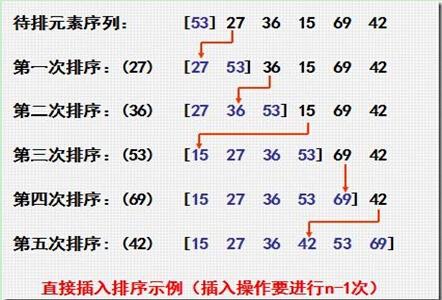
对照上图,我们来说说插入排序的方法。在一开始,我们假设列表中只有一个值,比如53。然后每次循环,我们加入1个新的元素,把这个元素,同当前表中的数据逐个比对,根据大小放到合适的位置。
这样循环,直至所有数据都插入列表中。因为每次插入的时候都对数据做了比较,并且放入了合适位置。插入结束,就等于排序结束。通常情况下插入排序都比冒泡排序效率要高。
看完了原理,思考一下,理清思路,弄明白核心的理念,然后我们继续看插入排序的源代码。
#排序字典版
#作者:andrew
#原始数据
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[1]>b[1]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序后:",sortedLists)
程序一开始初始化了字典,定义的sortedLists变量是一个空的列表,用于保存排序后的值,原因刚才说了,是因为字典不擅长保存有序的内容。
程序最后的部分是主流程,先显示排序前的字典,随后遍历整个字典,每获取到一对儿值,则调用插入排序函数插入到列表中合适的位置。
插入函数中,b参数是一个列表参数,但其内容实际是原来的关键字-值对儿。因为被封装在列表变量中,所以b[0]是关键字,b[1]是值。此外这里使用列表类型的原因,是因为我们排序完成后,保存在了一个列表类型中,实际是列表中的列表的形式。
排序方法使用for循环,遍历所有的数据,记住第一次调用插入函数的时候,列表中实际上没有任何元素;第二次调用,列表中有1个元素;第三次调用,列表中有2个元素,并且排好了序。后续的调用都是如此。
因此这里只要逐个比较列表中已经存在的值,就能找到新插入值应当插入的位置。这个列表是“列表中的列表”形式,所以遍历用的变量x,实际上也是一个包含两个值的列表,也就是一个关键字-值对儿,跟插入的类型完全相同。
因为我们使用学生成绩来排序,所以比较都是比较第二个元素,下标是1。第0个元素是学生的名字。
最后如果循环完也没有找到比新插入值更大的元素,说明要插入的元素已经是最大,应当添加在列表的最后。
程序的执行结果如下:
排序前: {'Harry': 87, 'Joe': 90, 'Yolanda': 67, 'Aaron': 88, 'Charles': 79, 'Fred': 93}
排序后: [['Yolanda', 67], ['Charles', 79], ['Harry', 87], ['Aaron', 88], ['Joe', 90], ['Fred', 93]]
Python内置的排序同样可以对字典类型进行排序,但因为字典类型每个元素是两个值,需要使用一个匿名函数来指定对哪个值进行排序:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sorted(students.items(),key = lambda x:x[1],reverse = True)
三点需要说明:1.因为字典不能保存有序数据,所以使用内置的items()函数转换成了元组列表类型(列表的元素为元组);2.使用匿名函数,函数参数x会被赋予每一个元素当做参数,刚才说了,每一个元素是一个元组,匿名函数中使用x[1]返回了成绩部分,表示使用成绩排序;3.reverse=True表示逆序排序,这种逆序的方法在列表排序或者其它排序中都能使用。
再次说明,匿名函数相关的部分,难度有点高,但并没有完全超出我们的课程的范围。如果在学习中理解有困难的同学,可以先死记几种形式来使用。逐渐通过动手操作和练习慢慢理解。
练习时间
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
1.请将上面学生成绩表由高分到低分排序排列
2.请将上面学生成绩表按照学生姓名的字母顺序排列
*3.第五讲,象棋麦粒问题中,(国际象棋有8行8列共64格,第1个格子放1粒麦子,第2个格子放2粒麦子,以后每格都比前面格子数量多一倍)
请使用一行代码,生成一个字典,字典的关键字为格子编号(1-64),值为该格子中的麦粒数量(提示,使用列表生成表达式)
本讲小结
- 本讲从列表的实际应用开始,导出了Python的字典类型,并以学生成绩单为例讲解了基本应用
- 元组是Python的另外一种数据类型,也是序列性的,但不可更改其中的值。元组的应用往往是不知不觉的,一般不用特殊记忆
- Python的常用数据类型到这一讲就完成了,还有一种集合类型,在我们的课程中用的少,我们不再讲解。更复杂的数据结构就是这些基本类型的组合。不管多么复杂的实际场景,通过多层次的基本数据类型组合都是能达成的。
- 匿名函数是高级语言的一个特征,也是函数化编程的较新成果。但匿名元素比较抽象,无法马上掌握的同学不要急,先用背的方法记住一些常用方式,以后在练习中慢慢理解
- 插入排序是另外一种常用的排序方式,速度更快,但有一定的使用条件约束。
练习答案
练习1:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[1]<b[1]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序后:",sortedLists)
练习2:
students = { "Harry":87,"Joe":90,"Yolanda":67,"Aaron":88,"Charles":79,"Fred":93}
sortedLists =[]
#插入排序
def insert(l,b):
i=0
for x in l:
if x[0]<b[0]:
l.insert(i,b)
return
i += 1
l.append(b)
print("排序前:",students)
for k,v in students.items():
insert(sortedLists,[k,v])
print("排序后:",sortedLists)
*练习3
{i+1:2**i for i in range(64)}
匿名函数,列表、字典生成表达式都比较抽象,但能量巨大。
延伸一下,使用一行代码完成“棋盘麦粒问题”:
sum([2**i for i in range(64)])
从零开始学习PYTHON3讲义(九)字典类型和插入排序的更多相关文章
- 从零开始学习PYTHON3讲义(一)认识Python
课程名称 从零开始PYTHON3 课程长度 15讲 适用年龄 15-20岁(初三-大一) 本讲名称 认识Python 时长 90分钟 教学内容分析 Python是时下最流行的计算机编程语言之一.本课程 ...
- 从零开始学习PYTHON3讲义(八)列表类型跟冒泡排序
<从零开始PYTHON3>第八讲 前面我们见过了不少的小程序,也见过了不少不同类型的变量使用的方法.但目前我们涉及到的,还都是单个的变量和单个的立即数.以变量来说,目前我们见到的,基本都 ...
- 从零开始学习PYTHON3讲义(五)while循环和棋盘麦粒问题
<从零开始PYTHON3>第五讲 上一节课重点学习了字符串,并且传递了一个重要的理念,就是程序要对开发人员自己和用户都足够友好.在这个过程中,利用字符串给出充分.完整.准确的提示是非常重 ...
- 从零开始学习PYTHON3讲义(十三)记事本的升级版:网络记事本
<从零开始PYTHON3>第十三讲 网络编程的火热和重要性这里就不多说了,我们直接来看看Python在互联网编程方面的表现. Python有很多网络编程的第三方扩展包,这里推荐一个我认为最 ...
- 从零开始学习PYTHON3讲义(十二)画一颗心送给你
(内容需要,本讲使用了大量在线公式,如果因为转帖网站不支持公式无法显示的情况,欢迎访问原始博客.) <从零开始PYTHON3>第十二讲 上一节课我们主要讲解了数值计算和符号计算.数值计算的 ...
- 从零开始学习PYTHON3讲义(十一)计算器升级啦
(内容需要,本讲中再次使用了大量在线公式,如果因为转帖网站不支持公式无法显示的情况,欢迎访问原始博客.) <从零开始PYTHON3>第十一讲 第二讲的时候,我们通过Python的交互模式来 ...
- 从零开始学习PYTHON3讲义(十)自己做一个“电子记事本”
<从零开始PYTHON3>第十讲 截至上一讲,我们已经完成了Python语言的基本部分.我们用了三讲来讨论Python语言的控制结构,用了两讲来介绍Python的基本数据类型.可以说仅就语 ...
- 从零开始学习PYTHON3讲义(六)for循环跟斐波那契数列
<从零开始PYTHON3>第六讲 几乎但凡接触过一点编程的人都知道for循环,在大多数语言的学习中,这也是第一个要学习的循环模式. 但是在Python中,我们把for循环放到了while循 ...
- 从零开始学习PYTHON3讲义(四)让程序更友好
<从零开始PYTHON3>第四讲 先看看上一讲的练习答案. 程序完成的是功能,功能来自于"程序需求"("需求"这个词忘记了什么意思的去复习一下第二讲 ...
随机推荐
- python:解析js中常见的 不带引号的key的 json
首先要明晰一点,json标准中,key是必须要带引号的,所以标准json模块解析不带引号的key的 json就会抛错 不过有一些lib可以帮我们解析 如:demjson(链接) >>> ...
- .net core使用Apollo做统一配置管理
做开发这么多年,经常因配置的问题引发生产环境的bug.有些年久的项目,几百个密密麻麻的配置项,经常容易搞混,有时好几个项目有好多同样的配置项,配置工作也不厌其烦.所幸,携程开源了新一代配置中心 - A ...
- NOIP 2017 游记?
Day -1 晚上被dg谈了谈人生,没有卵用 Day 0 早上又被老吕教训了一遍,想打板子,打印机还坏了,老吕又奶了一波题,后来发现一个都没中.之后就出发了,中午吃了点肯德基,妈妈来了,给我了个小袋子 ...
- [Usaco2009 Jan]安全路经Travel BZOJ1576 Dijkstra+树链剖分+线段树
分析: Dijkstra求最短路树,在最短路树上进行操作,详情可见上一篇博客:http://www.cnblogs.com/Winniechen/p/9042937.html 我觉得这个东西不压行写出 ...
- 【游戏开发】在Lua中实现面向对象特性——模拟类、继承、多态
一.简介 Lua是一门非常强大.非常灵活的脚本语言,自它从发明以来,无数的游戏使用了Lua作为开发语言.但是作为一款脚本语言,Lua也有着自己的不足,那就是它本身并没有提供面向对象的特性,而游戏开发是 ...
- 大白话5分钟带你走进人工智能-第十四节过拟合解决手段L1和L2正则
第十四节过拟合解决手段L1和L2正则 第十三节中, ...
- 第四次作业—— 性能测试(含JMeter实验)
一.回答下述问题 1.性能测试有几种类型?它们之间什么关系? 答:性能测试根据其不同的测试目的分为以下几类. (1)性能验证测试:验证系统是否达到事先已定义的系统性能指标.能否满足系统的性能需求.这种 ...
- mysql怎样配置ODBC数据源
一个基于ODBC的应用程序对数据库的操作不依赖任何DBMS,不直接与DBMS打交道,所有的数据库操作由对应的DBMS的ODBC驱动程序完成.所以说mysql配置ODBC数据源也很重要. 工具/原料 ...
- 【ODI】| 数据ETL:从零开始使用Oracle ODI完成数据集成(一)
0. 环境说明及软件准备 ODI(Oracle Data Integrator)是Oracle公司提供的一种数据集成工具,能高效地实现批量数据的抽取.转换和加载.ODI可以实现当今大多数的主流关系型数 ...
- 服务部署到Swarm Cluster中
对于已存在的镜像,将其部署到服务器中并开始对外服务,便是它的职责,而我们要做的便是帮助它完成职责,前两个应用环节都已产生了相应的镜像,在这一环节,将完成服务部署到容器集群的工作,对于这一过程,实际执行 ...