MySQL 查询重复数据,删除重复数据保留id最小的一条作为唯一数据
开发背景:
最近在做一个批量数据导入到MySQL数据库的功能,从批量导入就可以知道,这样的数据在插入数据库之前是不会进行重复判断的,因此只有在全部数据导入进去以后在执行一条语句进行删除,保证数据唯一性。
实战:
表结构如下图所示:
表明:brand

操作:
使用SQL语句查询重复的数据有哪些:
SELECT * from brand WHERE brandName IN(
select brandName from brand GROUP BY brandName HAVING COUNT(brandName)> #条件是数量大于1的重复数据
)
使用SQL删除多余的重复数据,并保留Id最小的一条唯一数据:
注意点:
错误SQL:DELETE FROM brand WHERE brandName IN (select brandName from brand GROUP BY brandName HAVING COUNT(brandName)>)
AND Id NOT IN (select MIN(Id) from brand GROUP BY brandName HAVING COUNT(brandName)>)
提示: You can't specify target table 'brand' for update in FROM clause 不能为FROM子句中的更新指定目标表“brand”
原因是:不能将直接查处来的数据当做删除数据的条件,我们应该先把查出来的数据新建一个临时表,然后再把临时表作为条件进行删除功能
正确SQL写法:
DELETE FROM brand WHERE brandName IN (SELECT brandName FROM (SELECT brandName FROM brand GROUP BY brandName HAVING COUNT(brandName)>) e)
AND Id NOT IN (SELECT Id FROM (SELECT MIN(Id) AS Id FROM brand GROUP BY brandName HAVING COUNT(brandName)>) t)
#查询显示重复的数据都是显示最前面的几条,因此不需要查询是否最小值
更加简单快捷的方式:
这是老飞飞的前辈给了一个更加方便,简洁的写法(非常感谢大佬的方法):
DELETE FROM brand WHERE Id NOT IN (SELECT Id FROM (SELECT MIN(Id) AS Id FROM brand GROUP BY brandName) t)
这句的意思其实就是,通过分组统计出数据库中不重复的最小数据id编号,让后通过 not in 去删除其他重复多余的数据。
结果如下图:
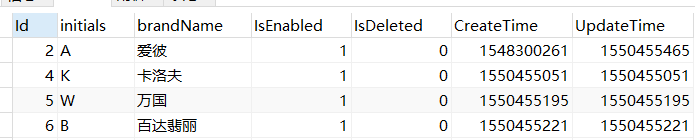
总结:
很多东西都是需要自己一步一步的去探究的,当然网上的建议也是非常宝贵的借鉴和资源,无论做什么开发我们都需要理解它的工作原理才能够更好的掌握它。
MySQL 查询重复数据,删除重复数据保留id最小的一条作为唯一数据的更多相关文章
- sql 多个字段分组,删除重复记录,保留ID最小的一条
IF OBJECT_ID('cardDetail') IS NOT NULL DROP TABLE cardDetail CREATE TABLE cardDetail ( id ,) PRIMARY ...
- Mysql删除重复记录,保留id最小的一条
mysql 查询重复字段,及删除重复记录的方法MySQL, 数据库, 数据库, 字段, 服务器数据库中有个大表,需要查找其中的名字有重复的记录id,以便比较.如果仅仅是查找数据库中name不重复的字段 ...
- 删除oracle 表中重复数据sql语句、保留rowid最小的一条记录
delete from tablename a where rowid > ( select min(rowid) from table_name b where b.id = a.id and ...
- 删除重复数据并保留id最小的一条记录
delete from test where id not in ( select a.id from (select min(id) as id from test group by form_i ...
- 【MySQL】测试MySQL表中安全删除重复数据只保留一条的相关方法
第二篇文章测试说明 开发测试中,难免会存在一些重复行数据,因此常常会造成一些测试异常. 下面简单测试mysql表删除重复数据行的相关操作. 主要通过一下三个大标题来测试说明: 02.尝试删除dept_ ...
- 【方法1】删除Map中Value反复的记录,而且仅仅保留Key最小的那条记录
介绍 晚上无聊的时候,我做了一个測试题,測试题的大体意思是:删除Map中Value反复的记录,而且仅仅保留Key最小的那条记录. 比如: I have a map with duplicate val ...
- Mysql 查询表中某字段的重复值,删除重复值保留id最小的数据
1 查询重复值 ); 2 删除重复值 -- 创建临时表 ) ); -- 把重复数据放进临时表 INSERT Hb_Student_a SELECT id,studentNumber FROM Hb_S ...
- Mysql开发技巧之删除重复数据
Mysql利用联表查询和分组来删除重复数据 //删除表中重复的id,保留最大的id mysql> select * from user; +----+------+ | id | name | ...
- Mysql中查找并删除重复数据的方法
(一)单个字段 1.查找表中多余的重复记录,根据(question_title)字段来判断 代码如下 复制代码 select * from questions where question_title ...
随机推荐
- Python报错:SyntaxError: Non-ASCII character '\xe5' in file 1.py on line 6, but no encoding declared...
本文由荒原之梦原创,原文链接:http://zhaokaifeng.com/?p=686 具体报错内容: File "1.py", line 6 SyntaxError: Non- ...
- C++/C实现各种排序算法(持续更新)--冒泡排序,选择排序,归并排序
2018 3 17 今日总结一下C++中的排序算法: 1冒泡排序 它重复地走访过要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.走访数列的工作是重复地进行直到没有再需要交换,也就是 ...
- 应用服务器性能优化 之 消息队列(MQ:Message Queue)
一,消息队列基本概念 借用百科的一句话:消息队列就是在消息的传输过程中,保存消息的容器. 从图-1和图-2对比,可以很清晰的明白,消息队列服务器,是位于应用服务器和数据库服务器之间的一个服务器.消息队 ...
- Spring Boot整合Quartz实现定时任务表配置
最近有个小项目要做,spring mvc下的task设置一直不太灵活,因此在Spring Boot上想做到灵活的管理定时任务.需求就是,当项目启动的时候,如果有定时任务则加载进来,生成schedule ...
- Shell 起停脚本 专题
To list any process listening to the port 8080: lsof -i:8080To kill any process listening to the por ...
- 基于 WebRTC 创建一款多人联机游戏
本项目的目标旨在尽可能少用服务器资源的前提下研发一款在线多人游戏,同时期望在一个用户的浏览器上运行游戏,同时让另一个玩家来连接.此外还希望程序尽可能简单以便于在博客中分析. 运用的技术 在我刚接触 P ...
- java,maven工程打tar.gz包执行main方法
一,需要在pom.xml文件添加plugin, 项目目录结构 <build> <plugins> <plugin> <artifactId>maven- ...
- 玩转web之ligerui(一)---ligerGrid重新指定url
请珍惜小编劳动成果,该文章为小编原创,转载请注明出处. 在特定情况下,我们需要重新指定ligerGrid的url来获取不同的数据,在这里我说一下我用的方法: 首先先定义一个全局变量,然后定义liger ...
- HTTP状态码的详细解释,供参考
HTTP状态码详解 常用对照表 状态码 含义 100 客户端应当继续发送请求.这个临时响应是用来通知客户端它的部分请求已经被服务器接收,且仍未被拒绝.客户端应当继续发送请求的剩余部分,或者如果请求已经 ...
- 树莓派.安装Firefox浏览器
sudo apt-get install firefox-esr 要做全屏效果的话, 可以加装插件FF Fullscreen 插件地址: https://addons.mozilla.org/en-U ...