python全栈学习--day8
一,文件操作基本流程。
计算机系统分为:计算机硬件,操作系统,应用程序三部分。
我们用python或其他语言编写的应用程序若想要把数据永久保存下来,必须要保存于硬盘中,这就涉及到应用程序要操作硬件,众所周知,应用程序是无法直接操作硬件的,这就用到了操作系统。操作系统把复杂的硬件操作封装成简单的接口给用户/应用程序使用,其中文件就是操作系统提供给应用程序来操作硬盘虚拟概念,用户或应用程序通过操作文件,可以将自己的数据永久保存下来。
有了文件的概念,我们无需再去考虑操作硬盘的细节,只需要关注操作文件的流程:
#1. 打开文件,得到文件句柄并赋值给一个变量
f=open('a.txt','r',encoding='utf-8') #默认打开模式就为r #2. 通过句柄对文件进行操作
data=f.read() #3. 关闭文件
f.close()
打开一个文件包含两部分资源:操作系统级打开的文件+应用程序的变量。在操作完毕一个文件时,必须把与该文件的这两部分资源一个不落地回收,回收方法为:
1、f.close() #回收操作系统级打开的文件
2、del f #回收应用程序级的变量 其中del f一定要发生在f.close()之后,否则就会导致操作系统打开的文件还没有关闭,白白占用资源,
而python自动的垃圾回收机制决定了我们无需考虑del f,这就要求我们,在操作完毕文件后,一定要记住f.close() 虽然我这么说,但是很多人是会忘记f.close(),这里我们推荐傻瓜式操作方式:使用with关键字来帮我们管理上下文
with open('a.txt','w') as f:
pass with open('a.txt','r') as read_f,open('b.txt','w') as write_f:
data=read_f.read()
write_f.write(data) 注意
二,文件编码
f=open(...)是由操作系统打开文件,那么如果我们没有为open指定编码,那么打开文件的默认编码很明显是操作系统说了算了,操作系统会用自己的默认编码去打开文件,在windows下是gbk,在linux下是utf-8。
三,文件的打开模式
#1.打开文件的模式有(默认为文本模式:)
r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
w,只写模式【不可读;不存在则创建;存在则清空内容】
a, 只追加写模式【不可读;不存在则创建;存在则只追加内容】
#1. 全部读出来f.read()
f = open('log.txt',encoding='utf-8',mode='r')
content = f.read()
print(content)
f.close() #2. 一行行的读
f = open('log.txt',encoding='utf-8')
print(f.readline())
print(f.readline())
print(f.readline())
f.close() #3: 将原文件的每一行作为一个列表的元素
f = open('log.txt',encoding='utf-8')
print(f.readlines())
f.close() #4:读取一部分read(n)
#在r模式下,read(n) 按照字符去读取。
f = open('log.txt',encoding='utf-8')
print(f.read(3))
f.close()
##5.循环读取
f = open('log.txt',encoding='utf-8')
for i in f:
print(i.strip())
f.close()
#2. 对于非文本文件,我们只能使用b模式,"b"表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb
wb
ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
#非文字类的文件时,用rb
f = open('log.txt',encoding='utf-8')
content = f.read()
f.close() #w
#没有文件,创建一个文件写入内容
f = open('log1.txt',encoding='utf-8',mode='w')
f.write('wefjiwnadihewgasdj')
f.close()
#有文件,将原文件内容清空,在写入内容。
f = open('log1',mode='w')
f.write('66666'.encode('utf-8'))
f.close()
#wb #二进制方式写入
f = open('log1',mode='wb')
f.write('weiwnsfd'.encode('utf-8'))
f.close()
#a
f = open('log2',encoding='utf-8',mode='a')
f.write('24we')
f.close()
#有文件,直接追加内容。
f = open('log2',encoding='utf-8',mode='a')
f.write('2242w')
f.close()
#3,‘+’模式(就是增加了一个功能) r+, 读写【可读,可写】 w+,写读【可写,可读】 a+, 写读【可写,可读】
# r+ 先读,后追加 一定要先读后写
f = open('log2',encoding='utf-8',mode='r+')
content = f.read()
print(content)
f.write('eweeafda')
f.close()
#4,以bytes类型操作的读写,写读,写读模式 r+b, 读写【可读,可写】 w+b,写读【可写,可读】 a+b, 写读【可写,可读】
#w+ 先写后读
f = open('log2',encoding='utf-8',mode='w+')
f.write('中国')
# print(f.tell()) #按字节去读取光标位置
f.seek(3) #按照字节调整光标位置
print(f.read())
f.close()
#a+ 追加读
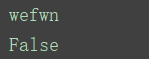
f = open('log',encoding='utf-8',mode='a+')
f.write('wefwn')
content = f.read()
print(content)
f.close()
#其他方法
f = open('log',encoding='utf-8')
print(f.read())
print(f.writable())
f.close()
执行后输出的结果:
总结:
功能一:自动关闭文件句柄
功能二:一次性操作多个文件句柄
with open('log',encoding='utf-8') as f:
print(f.read())
with open('log1',encoding='utf-8')as f1:
print(f1.read())
with open('log',encoding='utf-8') as f1,\
open('log1',encoding='utf-8')as f2:
print(f1.read())
print(f2.read())
所有的文件操作步骤:
# 1,将原文件读取到内存。
# 2,在内存中进行修改,形成新的内容。
# 3,将新的字符串写入新文件。
# 4,将原文件删除。
# 5,将新文件重命名成原文件。
###本章练习--案例
1. 文件a.txt内容:每一行内容分别为商品名字,价钱,个数。
apple 10 3
tesla 100000 1
mac 3000 2
lenovo 30000 3
chicken 10 3
通过代码,将其构建成这种数据类型:
[{'name':'apple','price':10,'amount':3},{'name':'tesla','price':1000000,'amount':1}......] 并计算出总价钱。
'''
#总列表
li = []
#总价格
the_sum = 0
with open('a.txt',encoding='utf-8') as f:
for i in f:
#默认使用空格分割
i = i.strip().split()
#将字典追加到列表中
li.append({'name': i[0], 'price': i[1], 'amount': i[2]})
#遍历列表
for i in li:
#计算总价格(单价*个数)
the_sum += int(i['price']) * int(i['amount']) print(li)
print('总价钱为: {}'.format(the_sum))
文件a2.txt内容:
文件内容:
序号 部门 人数 平均年龄 备注
1 python 30
26 单身狗
2 Linux 26
30 没对象
3 运营部 20
24 女生多
通过代码,将其构建成这种数据类型:
[{'序号':'1','部门':Python,'人数':30,'平均年龄':26,'备注':'单身狗'},
......]
li = []
count = 0
with open('a2', encoding='utf-8') as f1:
for i in f1:
count += 1
if count == 1:
l2 = i.strip().split()
else:
l1 = i.strip().split()
li.append({l2[0]: l1[0], l2[1]: l1[1], l2[2]: l1[2], l2[3]: l1[3], l2[4]: l1[4]})
print(li)
执行输出:
[{'序号': '1', '人数': '30', '部门': 'python', '备注': '单身狗', '平均年龄': '26'}, {'序号': '2', '人数': '26', '部门': 'Linux', '备注': '没对象', '平均年龄': '30'}, {'序号': '3', '人数': '20', '部门': '运营部', '备注': '女生多', '平均年龄': '24'}]
python全栈学习--day8的更多相关文章
- python全栈学习路线
python全栈学习路线-查询笔记 查询目录 一,硬件 十一,数据 ...
- python全栈学习--day4
列表 说明:列表是python中的基础数据类型之一,它是以[]括起来,每个元素以逗号隔开,而且他里面可以存放各种数据类型比如: 1 li = ['alex',123,Ture,(1,2,3,'wu ...
- python全栈学习--day3
一.基础数据类型 基础数据类型,有7种类型,存在即合理. 1.int 整数 主要是做运算的 .比如加减乘除,幂,取余 + - * / ** %...2.bool 布尔值 判断真假以及作为条件变量3. ...
- python全栈学习--day2
一.in的使用 说明:in有相当多的用处,比如判断,循环for 等. 实例一:in 操作符用于判断关键字是否存在于变量中 s = '男人john' print('男孩' in s) print('男孩 ...
- python全栈学习--day1
计算机基础 CPU:中央处理器 内存:4GB,8GB,临时处理事务的地方,供给CPU数据. 硬盘:相当于电脑的数据库,存储着大量的数据,文件,电影等. 操作系统:执行者,支配所有关系 window ...
- Python全栈学习_day002知识点
今日大纲: . while循环 . 格式化输出 . 运算符 . 编码初识 1. while循环 - while 无限循环: while True: # 死循环 print('大悲咒') print(' ...
- Python全栈开发day8
一.python生成/迭代器 yiled生成数据 python迭代器, 访问数据(通过next一次一次去取) 二.反射 通过字符串的形式,导入模块 通过字符串的形式,到模块中,寻找指定的函数,并执行 ...
- python全栈开发-Day8 函数基础
python全栈开发-Day8 函数 一 .引子 1. 为何要用函数之不用函数的问题 #1.代码的组织结构不清晰,可读性差 #2.遇到重复的功能只能重复编写实现代码,代码冗余 #3.功能需要扩展时,需 ...
- python全栈学习--day11(函数高级应用)
一,函数名是什么? 函数名是函数的名字,本质:变量,特殊的变量. 函数名()执行此函数 ''' 在函数的执行(调用)时:打散. *可迭代对象(str,tuple,list,dict(key))每一个元 ...
随机推荐
- JavaScript通过ID和name设置样式
JavaScript通过ID和name设置样式 1.说明 (1)根据所提供的元素的id值,返回对该元素的引用或节点 document.getElementById("tr_th") ...
- directX视频播放------手动连接
IGraphBuilder *pigb = NULL; IMediaControl *pimc = NULL; IMediaEventEx *pimex = NULL; IVideoWindow *p ...
- textarea的不可拉伸和不可编辑
不可拉伸: textarea { resize: none; } 不可编辑: 第一种方法: <textarea disabled></textarea> 第二种方法: < ...
- Mybatis if test 中int判断非空的坑
Mybatis 中,alarmType 是int类型.如果alarmType 为0的话,条件判断返回结果为false,其它值的话,返回true. <if test="alarmType ...
- HttpServletResponse,HttpServletRequest详解
1.相关的接口 HttpServletRequest HttpServletRequest接口最常用的方法就是获得请求中的参数,这些参数一般是客户端表单中的数据.同时,HttpServletReq ...
- 实例 find
2011/09/08 12:00 时间开始找一天內的,会列出 2011/09/07 12:00 ~ 2011/09/08 12:00 时间內的文件3天前被改动过的文件 (前第三天以前 → 2011/0 ...
- jquery 实现拖动文件上传加进度条
通过对文件的拖动实现文件的上传,主要用到的是HTML5的ondrop事件,上传内容通道FormData传输: //进度条 <div class="parent-dlg" &g ...
- A Dream (PKUWC 2018)
A Dream (PKUWC 2018) 这是一个梦. 从没有几分节日气氛的圣诞,做到了大雪纷飞的数九寒天. 忘了罢! 不记得时间,不记得地点.随着记忆的褪去,一切也只会不复存在. Day-34? D ...
- [SDOI2010]粟粟的书架
题目大意: 网址:https://daniu.luogu.org/problemnew/show/2468 大意:本题有两问: [1] 给定一个\(R*C\)的带权矩阵,询问\(2×10^5\)次在一 ...
- Idea工具开发 SpringBoot整合JSP(毕设亲测可用)
因为,临近毕业了,自己虽然也学了很多框架.但是,都是在别人搭建好的基础上进行项目开发.但是springboot的官方文档上明确指出不提倡使用jsp进行前端开发,但是在校期间只学了jsp作为前端页面.所 ...